Questa pagina descrive come trovare e risolvere gli errori di esaurimento della memoria (OOM) in Dataflow.
Trovare errori di memoria
Per determinare se la pipeline sta esaurendo la memoria, utilizza uno dei seguenti metodi.
- Nella pagina Dettagli job, nel riquadro Log, visualizza la scheda Diagnostica. Questa scheda mostra gli errori relativi ai problemi di memoria e la frequenza con cui si verificano.
- Nell'interfaccia di monitoraggio di Dataflow, utilizza il grafico Utilizzo della memoria per monitorare la capacità e l'utilizzo della memoria dei worker.
- Nella pagina Dettagli job, nel riquadro Log, seleziona Log worker per trovare errori di memoria insufficiente nei log worker.
Nei log di sistema potrebbero essere visualizzati anche errori di memoria insufficiente. Per visualizzarli, vai a Esplora log e utilizza la seguente query:
resource.type="dataflow_step" resource.labels.job_id="JOB_ID" "out of memory" OR "OutOfMemory" OR "Shutting down JVM"Sostituisci JOB_ID con l'ID del tuo job.
Per i job Java, Java Memory Monitor segnala periodicamente le metriche di garbage collection. Se la frazione di tempo della CPU utilizzata per la garbage collection supera una soglia del 50% per un periodo di tempo prolungato, l'SDK harness non funziona. Potresti visualizzare un errore simile al seguente esempio:
Shutting down JVM after 8 consecutive periods of measured GC thrashing. Memory is used/total/max = ...Questo errore può verificarsi quando la memoria fisica è ancora disponibile e di solito indica che l'utilizzo della memoria della pipeline è inefficiente. Per risolvere questo problema, ottimizza la pipeline.
Il monitor della memoria Java viene configurato dall'interfaccia
MemoryMonitorOptions.
Se il tuo job ha un utilizzo elevato della memoria o errori di esaurimento della memoria, segui i consigli in questa pagina per ottimizzare l'utilizzo della memoria o per aumentare la quantità di memoria disponibile.
Risolvere gli errori di memoria insufficiente
Le modifiche alla pipeline Dataflow potrebbero risolvere gli errori di memoria insufficiente o ridurre l'utilizzo della memoria. Le possibili modifiche includono le seguenti azioni:
- Ottimizzare la pipeline
- Ridurre il numero di thread
- Utilizza un tipo di macchina con più memoria per vCPU
Il seguente diagramma mostra il flusso di lavoro per la risoluzione dei problemi di Dataflow descritto in questa pagina.
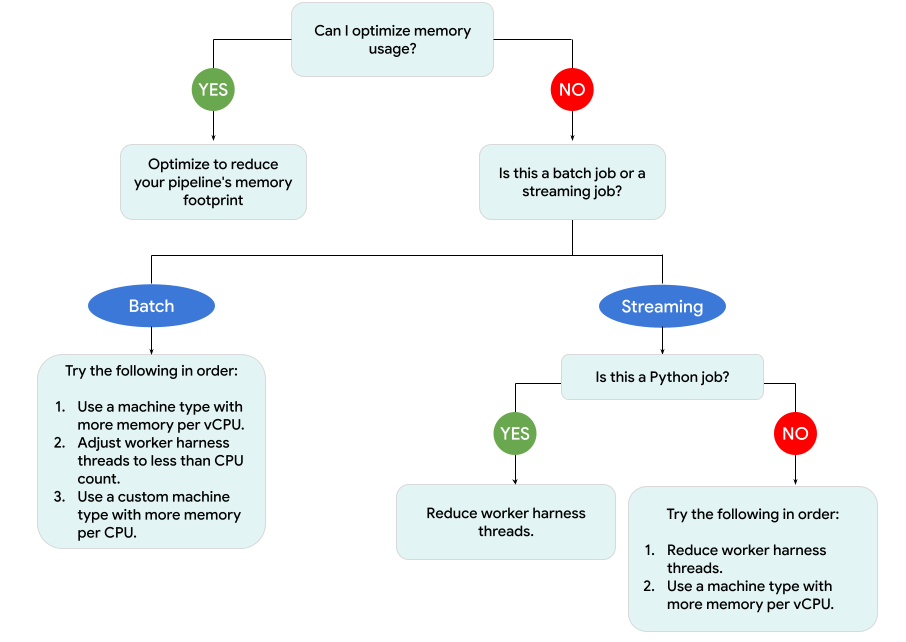
Prova le seguenti soluzioni:
- Se possibile, ottimizza la pipeline per ridurre l'utilizzo della memoria.
- Se il job è un job batch, prova a svolgere i seguenti passaggi nell'ordine indicato:
- Utilizza un tipo di macchina con più memoria per vCPU.
- Riduci il numero di thread a un valore inferiore al numero di vCPU per worker.
- Utilizza un tipo di macchina personalizzata con più memoria per vCPU.
- Se il job è un job di streaming che utilizza Python, riduci il numero di thread a meno di 12.
- Se il job è un job di streaming che utilizza Java o Go, prova a seguire questi passaggi:
- Riduci il numero di thread a meno di 500 per i job Runner v2 o a meno di 300 per i job che non utilizzano Runner v2.
- Utilizza un tipo di macchina con più memoria.
Ottimizzare la pipeline
Diverse operazioni della pipeline possono causare errori di esaurimento della memoria. Questa sezione fornisce opzioni per ridurre l'utilizzo della memoria della pipeline. Per identificare le fasi della pipeline che consumano più memoria, utilizza Cloud Profiler per monitorare le prestazioni della pipeline.
Per ottimizzare la pipeline, puoi utilizzare le seguenti best practice:
- Utilizzare i connettori I/O integrati di Apache Beam per leggere i file
- Riprogettare le operazioni quando si utilizzano le trasformazioni
GroupByKey - Ridurre i dati in entrata da origini esterne
- Condividere oggetti tra thread
- Utilizzare rappresentazioni degli elementi efficienti in termini di memoria
- Ridurre le dimensioni degli input laterali
- Utilizzare le DoFn divisibili di Apache Beam
Utilizza i connettori I/O integrati di Apache Beam per leggere i file
Non aprire file di grandi dimensioni all'interno di un DoFn. Per leggere i file, utilizza i connettori I/O integrati di Apache Beam.
I file aperti in un DoFn devono rientrare nella memoria. Poiché più istanze di DoFn vengono eseguite
contemporaneamente, i file di grandi dimensioni aperti in DoFn possono causare errori di memoria insufficiente.
Riprogettare le operazioni quando si utilizzano PTransform GroupByKey
Quando utilizzi una PTransform GroupByKey in Dataflow, i valori per chiave e per finestra risultanti vengono elaborati su un singolo thread. Poiché questi dati vengono trasmessi come flusso dal servizio di backend Dataflow ai worker, non devono rientrare nella memoria worker. Tuttavia, se i valori vengono
raccolti in memoria, la logica di elaborazione potrebbe causare errori di memoria insufficiente.
Ad esempio, se hai una chiave che contiene dati per una finestra e aggiungi i valori chiave a un oggetto in memoria, ad esempio un elenco, potrebbero verificarsi errori di memoria insufficiente. In questo scenario, il worker potrebbe non disporre di capacità di memoria sufficiente per contenere tutti gli oggetti.
Per saperne di più sulle trasformazioni PTransform GroupByKey, consulta la documentazione di Apache Beam
Python GroupByKey
e Java GroupByKey.
Il seguente elenco contiene suggerimenti per progettare la pipeline in modo da ridurre al minimo
il consumo di memoria quando utilizzi le trasformazioni GroupByKey.
- Per ridurre la quantità di dati per chiave e per finestra, evita le chiavi con molti valori, note anche come chiavi attive.
- Per ridurre la quantità di dati raccolti per finestra, utilizza una dimensione della finestra più piccola.
- Se utilizzi i valori di una chiave in una finestra per calcolare un numero, utilizza una
trasformazione
Combine. Non eseguire il calcolo in una singola istanzaDoFndopo aver raccolto i valori. - Filtra i valori o i duplicati prima dell'elaborazione. Per saperne di più, consulta la documentazione relativa alla trasformazione di Python
Filtere JavaFilter.
Ridurre i dati in entrata da origini esterne
Se effettui chiamate a un'API esterna o a un database per l'arricchimento dei dati,
i dati restituiti devono rientrare nella memoria del worker.
Se raggruppi le chiamate, ti consigliamo di utilizzare una trasformazione GroupIntoBatches.
Se si verificano errori di memoria insufficiente, riduci la dimensione del batch. Per ulteriori informazioni
sul raggruppamento in batch, consulta la
documentazione sulla trasformazione di Python GroupIntoBatches
e Java GroupIntoBatches.
Condividere oggetti tra thread
La condivisione di un oggetto dati in memoria tra le istanze di DoFn può migliorare l'efficienza dello spazio e
dell'accesso. Gli oggetti dati creati in qualsiasi metodo di DoFn, inclusi
Setup, StartBundle, Process, FinishBundle e Teardown, vengono richiamati
per ogni DoFn. In Dataflow, ogni worker potrebbe avere diverse istanze DoFn. Per un utilizzo più efficiente della memoria, passa un oggetto dati come singleton per
condividerlo tra più DoFn. Per ulteriori informazioni, consulta il post del blog
Riutilizzo della cache tra DoFn.
Utilizzare rappresentazioni degli elementi efficienti in termini di memoria
Valuta se puoi utilizzare rappresentazioni per gli elementi PCollection
che utilizzano meno memoria. Quando utilizzi i codificatori nella pipeline, considera non solo le rappresentazioni degli elementi codificati, ma anche quelle decodificate.PCollection Le matrici
sparse possono spesso trarre vantaggio da questo tipo di ottimizzazione.
Ridurre le dimensioni degli input secondari
Se i tuoi DoFn utilizzano input laterali, riduci le dimensioni dell'input laterale. Per gli input
laterali che sono raccolte di elementi, valuta la possibilità di utilizzare viste iterabili, ad esempio
AsIterable
o AsMultimap, anziché viste che materializzano l'intero input laterale contemporaneamente, ad esempio
AsList.
Riduci il numero di thread
Puoi aumentare la memoria disponibile per thread riducendo il numero massimo
di thread che eseguono istanze DoFn. Questa modifica riduce il parallelismo, ma
rende disponibile più memoria per ogni DoFn.
La seguente tabella mostra il numero predefinito di thread creati da Dataflow:
| Tipo di job | SDK Python | SDK Java/Go |
|---|---|---|
| Batch | 1 thread per vCPU | 1 thread per vCPU |
| Streaming con Runner v2 | 12 thread per vCPU | 500 thread per VM worker |
| Streaming senza Runner v2 | 12 thread per vCPU | 300 thread per VM worker |
Per ridurre il numero di thread dell'SDK Apache Beam, imposta la seguente opzione della pipeline:
Java
Utilizza l'opzione della pipeline --numberOfWorkerHarnessThreads.
Python
Utilizza l'opzione della pipeline --number_of_worker_harness_threads.
Vai
Utilizza l'opzione della pipeline --number_of_worker_harness_threads.
Per i job batch, imposta il valore su un numero inferiore al numero di vCPU.
Per i job di streaming, inizia riducendo il valore alla metà di quello predefinito. Se questo passaggio non risolve il problema, continua a ridurre il valore della metà, osservando i risultati a ogni passaggio. Ad esempio, quando utilizzi Python, prova i valori 6, 3 e 1.
Utilizza un tipo di macchina con più memoria per vCPU
Per selezionare un worker con più memoria per vCPU, utilizza uno dei seguenti metodi.
- Utilizza un tipo di macchina con memoria elevata nella famiglia di macchine per uso generico. I tipi di macchine con memoria elevata hanno più memoria per vCPU rispetto ai tipi di macchine standard. L'utilizzo di un tipo di macchina con memoria elevata aumenta sia la memoria disponibile per ogni worker sia la memoria disponibile per thread, perché il numero di vCPU rimane invariato. Di conseguenza, l'utilizzo di un tipo di macchina con memoria elevata può essere un modo conveniente per selezionare un worker con più memoria per vCPU.
- Per una maggiore flessibilità nella specifica del numero di vCPU e della quantità di memoria, puoi utilizzare un tipo di macchina personalizzata. Con i tipi di macchine personalizzate, puoi aumentare la memoria in incrementi di 256 MB. Questi tipi di macchine hanno prezzi diversi rispetto ai tipi di macchine standard.
- Alcune famiglie di macchine ti consentono di utilizzare tipi di macchine personalizzate con memoria estesa. La memoria estesa consente un rapporto memoria per vCPU più elevato. Il costo è più elevato.
Per impostare i tipi di worker, utilizza la seguente opzione della pipeline. Per ulteriori informazioni, vedi Impostare le opzioni della pipeline e Opzioni della pipeline.
Java
Utilizza l'opzione della pipeline --workerMachineType.
Python
Utilizza l'opzione della pipeline --machine_type.
Vai
Utilizza l'opzione della pipeline --worker_machine_type.
Utilizza un solo processo SDK Apache Beam
Per le pipeline di streaming Python e le pipeline Python che utilizzano Runner v2, puoi forzare Dataflow ad avviare un solo processo SDK Apache Beam per worker. Prima di provare questa opzione, prova prima a risolvere il problema utilizzando gli altri metodi. Per configurare le VM worker Dataflow in modo che avviino un solo processo Python in container, utilizza la seguente opzione della pipeline:
--experiments=no_use_multiple_sdk_containers
Con questa configurazione, le pipeline Python creano un processo SDK Apache Beam per worker. Questa configurazione impedisce la replica più volte degli oggetti e dei dati condivisi per ogni processo dell'SDK Apache Beam. Tuttavia, limita l'uso efficiente delle risorse di calcolo disponibili sul worker.
La riduzione del numero di processi Apache Beam SDK a uno non riduce necessariamente il numero totale di thread avviati sul worker. Inoltre, se tutti i thread si trovano in un unico processo dell'SDK Apache Beam, l'elaborazione potrebbe essere lenta o la pipeline potrebbe bloccarsi. Pertanto, potresti anche dover ridurre il numero di thread, come descritto nella sezione Ridurre il numero di thread di questa pagina.
Puoi anche forzare i worker a utilizzare un solo processo SDK Apache Beam utilizzando un tipo di macchina con una sola vCPU.
Comprendere l'utilizzo della memoria di Dataflow
Per risolvere i problemi di memoria insufficiente, è utile capire come le pipeline Dataflow utilizzano la memoria.
Quando Dataflow esegue una pipeline, l'elaborazione viene distribuita
su più macchine virtuali (VM) Compute Engine, spesso chiamate worker.
I worker elaborano gli elementi di lavoro dal servizio Dataflow
e li delegano ai processi dell'SDK Apache Beam. Un processo SDK
Apache Beam crea istanze
di DoFn. DoFn è una classe SDK Apache Beam che definisce una funzione di elaborazione distribuita.
Dataflow avvia diversi thread su ogni worker e la memoria di ogni worker è condivisa tra tutti i thread. Un thread è una singola attività eseguibile in esecuzione all'interno di un processo più grande. Il numero predefinito di thread dipende da più fattori e varia tra i job batch e di streaming.
Se la pipeline ha bisogno di più memoria della quantità predefinita disponibile sui worker, potresti riscontrare errori di esaurimento della memoria.
Le pipeline Dataflow utilizzano principalmente la memoria dei worker in tre modi:
Memoria operativa del worker
I nodi worker di Dataflow hanno bisogno di memoria per i sistemi operativi e i processi di sistema. L'utilizzo della memoria del worker in genere non supera 1 GB. L'utilizzo è in genere inferiore a 1 GB.
- Diversi processi sul worker utilizzano la memoria per garantire che la pipeline funzioni correttamente. Ciascuno di questi processi potrebbe riservare una piccola quantità di memoria per il suo funzionamento.
- Quando la pipeline non utilizza Streaming Engine, i processi di lavoro aggiuntivi utilizzano la memoria.
Memoria del processo SDK
I processi dell'SDK Apache Beam potrebbero creare oggetti e dati condivisi tra i thread all'interno del processo, indicati in questa pagina come oggetti e dati condivisi dell'SDK. L'utilizzo della memoria di questi oggetti e dati condivisi dell'SDK viene definito memoria di processo dell'SDK. Il seguente elenco include esempi di oggetti e dati condivisi dell'SDK:
- Input aggiuntivi
- Modelli di machine learning
- Oggetti singleton in memoria
- Oggetti Python creati con il modulo
apache_beam.utils.shared - Dati caricati da origini esterne, come Cloud Storage o BigQuery
I job di streaming che non utilizzano Streaming Engine memorizzano gli input secondari in memoria. Per le pipeline Java e Go, ogni worker ha una copia dell'input secondario. Per le pipeline Python, ogni processo dell'SDK Apache Beam ha una copia dell'input secondario.
I job di streaming che utilizzano Streaming Engine hanno un limite di dimensioni dell'input secondario di 80 MB. Gli input secondari vengono archiviati al di fuori della memoria del worker.
L'utilizzo della memoria da parte degli oggetti e dei dati condivisi dell'SDK aumenta in modo lineare con il numero di processi dell'SDK Apache Beam. Nelle pipeline Java e Go, viene avviato un processo SDK Apache Beam per ogni worker. Nelle pipeline Python, viene avviato un processo SDK Apache Beam per vCPU. Gli oggetti e i dati condivisi dell'SDK vengono riutilizzati nei thread all'interno dello stesso processo dell'SDK Apache Beam.
Utilizzo memoria DoFn
DoFn è una classe SDK Apache Beam che definisce una funzione di elaborazione distribuita.
Ogni worker può eseguire DoFn istanze simultanee. Ogni thread esegue un'istanza di DoFn. Quando valuti l'utilizzo totale della memoria, il calcolo delle dimensioni del working set o la quantità di memoria necessaria per il funzionamento di un'applicazione potrebbe essere utile. Ad esempio, se un singolo DoFn utilizza
un massimo di 5 MB di memoria e un worker ha 300 thread, l'utilizzo della memoria DoFn
potrebbe raggiungere un picco di 1,5 GB, ovvero il numero di byte di memoria moltiplicato per
il numero di thread. A seconda di come i worker utilizzano la memoria, un picco di utilizzo della memoria
potrebbe causare l'esaurimento della memoria dei worker.
È difficile stimare il numero di istanze di un
DoFn
che Dataflow crea. Il numero dipende da vari fattori, come l'SDK,
il tipo di macchina e così via. Inoltre, DoFn potrebbe essere utilizzato da più thread in successione.
Il servizio Dataflow non garantisce il numero di volte in cui viene richiamato un DoFn,
né il numero esatto di istanze DoFn create nel corso di una pipeline.
Tuttavia, la tabella seguente fornisce alcune informazioni sul livello
di parallelismo che puoi aspettarti e stima un limite superiore al
numero di istanze DoFn.
SDK Python di Beam
| Batch | Streaming senza Streaming Engine | Streaming Engine | |
|---|---|---|---|
| Parallelismo |
1 processo per vCPU 1 thread per processo 1 thread per vCPU
|
1 processo per vCPU 12 thread per processo 12 thread per vCPU |
1 processo per vCPU 12 thread per processo 12 thread per vCPU
|
Numero massimo di istanze DoFn simultanee (tutti questi numeri sono soggetti a modifica in qualsiasi momento). |
1 DoFn per thread
1
|
1 DoFn per thread
12
|
1 DoFn per thread
12
|
SDK Beam Java/Go
| Batch | Streaming Appliance e Streaming Engine senza runner v2 | Streaming Engine con Runner v2 | |
|---|---|---|---|
| Parallelismo |
1 processo per VM worker 1 thread per vCPU
|
1 processo per VM worker 300 thread per processo 300 thread per VM worker
|
1 processo per VM worker 500 thread per processo 500 thread per VM worker
|
Numero massimo di istanze DoFn simultanee (tutti questi numeri sono soggetti a modifica in qualsiasi momento). |
1 DoFn per thread
1
|
1 DoFn per thread
300
|
1 DoFn per thread
500
|
Ad esempio, quando utilizzi l'SDK Python con un worker Dataflow n1-standard-2, si applica quanto segue:
- Job batch: Dataflow avvia un processo per vCPU (due in questo
caso). Ogni processo utilizza un thread e ogni thread crea un'istanza
DoFn. - Job di streaming con Streaming Engine: Dataflow avvia un processo per vCPU (due in totale). Tuttavia, ogni processo può generare fino a 12 thread, ognuno con la propria istanza DoFn.
Quando progetti pipeline complesse, è importante comprendere il
ciclo di vita di DoFn.
Assicurati che le funzioni DoFn siano serializzabili ed evita di modificare l'argomento
dell'elemento direttamente al loro interno.
Quando hai una pipeline multilingue e sul worker è in esecuzione più di un SDK Apache Beam, il worker utilizza il grado di parallelismo thread per processo più basso possibile.
Differenze tra Java, Go e Python
Java, Go e Python gestiscono processi e memoria in modo diverso. Di conseguenza, l'approccio da adottare per la risoluzione dei problemi relativi agli errori di memoria esaurita varia a seconda che la pipeline utilizzi Java, Go o Python.
Pipeline Java e Go
Nelle pipeline Java e Go:
- Ogni worker avvia un processo dell'SDK Apache Beam.
- Gli oggetti e i dati condivisi dell'SDK, come input laterali e cache, vengono condivisi tra tutti i thread del worker.
- La memoria utilizzata dagli oggetti e dai dati condivisi dell'SDK di solito non viene scalata in base al numero di vCPU sul worker.
Pipeline Python
Nelle pipeline Python:
- Ogni worker avvia un processo SDK Apache Beam per vCPU.
- Gli oggetti e i dati condivisi dell'SDK, come input secondari e cache, vengono condivisi tra tutti i thread all'interno di ogni processo dell'SDK Apache Beam.
- Il numero totale di thread sul worker viene scalato in modo lineare in base al numero di vCPU. Di conseguenza, la memoria utilizzata dagli oggetti e dai dati condivisi dell'SDK aumenta in modo lineare con il numero di vCPU.
- I thread che eseguono il lavoro sono distribuiti tra i processi. Le nuove unità di lavoro vengono assegnate a un processo senza elementi di lavoro o al processo con il minor numero di elementi di lavoro attualmente assegnati.