L'I/O gestito consente a Dataflow di gestire connettori I/O specifici utilizzati nelle pipeline Apache Beam. L'I/O gestito semplifica la gestione delle pipeline che si integrano con origini e sink supportati.
L'I/O gestito è costituito da due componenti che funzionano insieme:
Una trasformazione Apache Beam che fornisce un'API comune per la creazione di connettori I/O (origini e sink).
Un servizio Dataflow che gestisce questi connettori I/O per tuo conto, inclusa la possibilità di eseguirne l'upgrade indipendentemente dalla versione di Apache Beam.
I vantaggi dell'I/O gestito includono:
Upgrade automatici. Dataflow esegue automaticamente l'upgrade dei connettori I/O gestiti nella pipeline. Ciò significa che la tua pipeline riceve correzioni di sicurezza, miglioramenti delle prestazioni e correzioni di bug per questi connettori, senza richiedere modifiche al codice. Per saperne di più, consulta Upgrade automatici.
API coerente. Tradizionalmente, i connettori I/O in Apache Beam hanno API distinte e ogni connettore è configurato in modo diverso. Managed I/O fornisce una singola API di configurazione che utilizza proprietà chiave-valore, con conseguente codice della pipeline più semplice e coerente. Per ulteriori informazioni, consulta API di configurazione.
Requisiti
I seguenti SDK supportano l'I/O gestito:
- Apache Beam SDK per Java versione 2.58.0 o successive.
- SDK Apache Beam per Python versione 2.61.0 o successive.
Il servizio di backend richiede Dataflow Runner v2. Se Runner v2 non è abilitato, la pipeline viene comunque eseguita, ma non usufruisce dei vantaggi del servizio di I/O gestito.
Upgrade automatici
Le pipeline Dataflow con connettori I/O gestiti utilizzano automaticamente l'ultima versione affidabile del connettore, come segue:
Quando invii un job, Dataflow utilizza la versione più recente del connettore che è stata testata e funziona correttamente.
Per i job di streaming, Dataflow verifica la presenza di aggiornamenti ogni volta che avvii un job di sostituzione e utilizza automaticamente l'ultima versione funzionante nota. Dataflow esegue questo controllo anche se non modifichi alcun codice nel job di sostituzione.
Non devi preoccuparti di aggiornare manualmente il connettore o la versione di Apache Beam della pipeline.
Il seguente diagramma mostra la procedura di upgrade. L'utente crea una pipeline Apache Beam utilizzando la versione dell'SDK X. Quando l'utente invia il job, Dataflow controlla la versione di Managed I/O ed esegue l'upgrade alla versione Y.
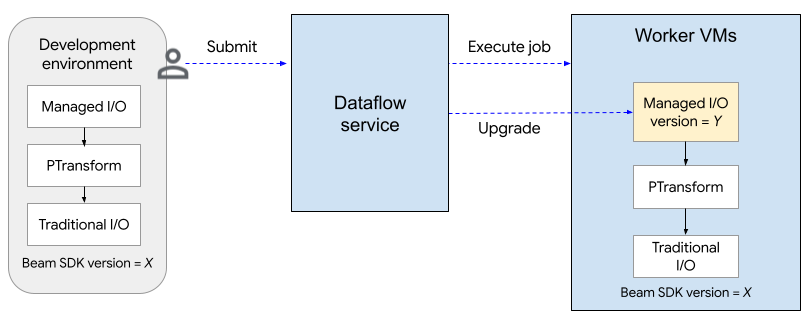
La procedura di upgrade aggiunge circa due minuti al tempo di avvio di un job. Per
controllare lo stato delle operazioni di I/O gestite, cerca
voci di log che includono la stringa
"Managed Transform(s)".
API di configurazione
Managed I/O è una trasformazione Apache Beam chiavi in mano che fornisce un'API coerente per configurare origini e sink.
Java
Per creare qualsiasi origine o sink supportato da Managed I/O, utilizza la
classe Managed. Specifica l'origine o il sink da istanziare
e passa un insieme di parametri di configurazione, simili ai seguenti:
Map config = ImmutableMap.<String, Object>builder()
.put("config1", "abc")
.put("config2", 1);
pipeline.apply(Managed.read(/*Which source to read*/).withConfig(config))
.getSinglePCollection();
Puoi anche passare i parametri di configurazione come file YAML. Per un esempio di codice completo, vedi Lettura da Apache Iceberg.
Python
Importa il modulo apache_beam.transforms.managed
e chiama il metodo managed.Read o managed.Write. Specifica l'origine o il
sink da istanziare e passa un insieme di parametri di configurazione, simili a
quanto segue:
pipeline
| beam.managed.Read(
beam.managed.SOURCE, # Example: beam.managed.KAFKA
config={
"config1": "abc",
"config2": 1
}
)
Puoi anche passare i parametri di configurazione come file YAML. Per un esempio di codice completo, consulta Lettura da Apache Kafka.
Destinazioni dinamiche
Per alcuni sink, il connettore I/O gestito può selezionare dinamicamente una destinazione in base ai valori dei campi nei record in entrata.
Per utilizzare le destinazioni dinamiche, fornisci una stringa modello per la destinazione. La
stringa modello può includere nomi di campi tra parentesi graffe, ad esempio
"tables.{field1}". In fase di runtime, il connettore sostituisce il valore del
campo per ogni record in entrata, per determinare la destinazione del record.
Ad esempio, supponiamo che i tuoi dati abbiano un campo denominato airport. Potresti impostare la
destinazione su "flights.{airport}". Se airport=SFO, il record viene scritto
in flights.SFO. Per i campi nidificati, utilizza la notazione con il punto. Ad esempio:
{top.middle.nested}.
Per un codice di esempio che mostra come utilizzare le destinazioni dinamiche, consulta Scrivere con destinazioni dinamiche.
Filtri
Potresti voler filtrare determinati campi prima che vengano scritti nella tabella di destinazione. Per le destinazioni che supportano le destinazioni dinamiche, puoi utilizzare
il parametro drop, keep o only a questo scopo. Questi parametri ti consentono di includere i metadati di destinazione nei record di input, senza scriverli nella destinazione.
Puoi impostare al massimo uno di questi parametri per un determinato sink.
| Parametro di configurazione | Tipo di dati | Descrizione |
|---|---|---|
drop |
elenco di stringhe | Un elenco di nomi di campi da eliminare prima di scrivere nella destinazione. |
keep |
elenco di stringhe | Un elenco di nomi di campi da conservare durante la scrittura nella destinazione. Gli altri campi vengono eliminati. |
only |
string | Il nome di esattamente un campo da utilizzare come record di primo livello da scrivere durante la scrittura nella destinazione. Tutti gli altri campi vengono eliminati. Questo campo deve essere di tipo riga. |
Origini e sink supportati
Managed I/O supporta le seguenti origini e destinazioni.
Per saperne di più, consulta la sezione Connettori I/O gestiti nella documentazione di Apache Beam.