Esta página descreve como executar transformações no BigQuery em vez do Spark no Cloud Data Fusion.
Para mais informações, consulte a Vista geral da transferência de transformações.
Antes de começar
O envio de transformações está disponível na versão 6.5.0 e posteriores. Se o seu pipeline for executado num ambiente anterior, pode atualizar a sua instância para a versão mais recente.
Ative o pushdown de transformação no seu pipeline
Consola
Para ativar o pushdown de transformação num pipeline implementado, faça o seguinte:
Aceda à sua instância:
Na Google Cloud consola, aceda à página do Cloud Data Fusion.
Para abrir a instância no Cloud Data Fusion Studio, clique em Instâncias e, de seguida, em Ver instância.
Clique em Menu > Lista.
É aberto o separador do pipeline implementado.
Clique no pipeline implementado pretendido para o abrir no Pipeline Studio.
Clique em Configurar > Transferência de transformações.
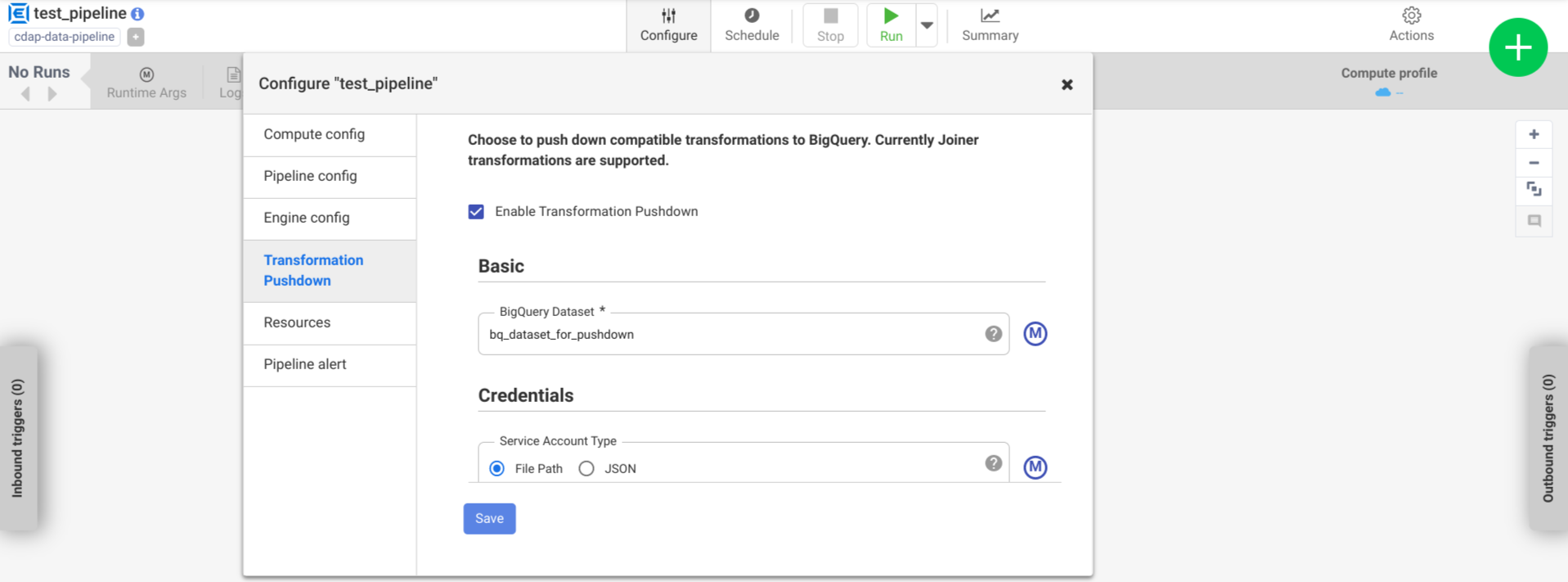
Clique em Ativar pushdown de transformação.
No campo Conjunto de dados, introduza um nome para o conjunto de dados do BigQuery.
Opcional: para usar uma macro, clique em M. Para mais informações, consulte o artigo Conjuntos de dados.
Opcional: configure as opções, se necessário.
Clique em Guardar.
Configurações opcionais
.| Propriedade | Suporta macros | Versões do Cloud Data Fusion suportadas | Descrição |
|---|---|---|---|
| Use a ligação | Não | 6.7.0 e posterior | Se deve usar uma associação existente. |
| Connection | Sim | 6.7.0 e posterior | O nome da associação. Esta associação fornece informações do projeto e da conta de serviço. Opcional: use a função de macro ${conn(connection_name)}. |
| ID do projeto do conjunto de dados | Sim | 6.5.0 | Se o conjunto de dados estiver num projeto diferente daquele onde o trabalho do BigQuery é executado, introduza o ID do projeto do conjunto de dados. Se não for indicado nenhum valor, é usado por predefinição o ID do projeto onde a tarefa é executada. |
| ID do projeto | Sim | 6.5.0 | O Google Cloud ID do projeto. |
| Tipo de conta de serviço | Sim | 6.5.0 | Selecione uma das seguintes opções:
|
| Caminho do ficheiro da conta de serviço | Sim | 6.5.0 | O caminho no sistema de ficheiros local para a chave da conta de serviço usada
para autorização. Está definido como auto-detect quando é executado
num cluster do Dataproc. Quando executado noutros clusters,
o ficheiro tem de estar presente em todos os nós do cluster. A predefinição é
auto-detect. |
| JSON da conta de serviço | Sim | 6.5.0 | O conteúdo do ficheiro JSON da conta de serviço. |
| Nome do contentor temporário | Sim | 6.5.0 | O contentor do Cloud Storage que armazena os dados temporários. É criado automaticamente se não existir, mas não é eliminado automaticamente. Os dados do Cloud Storage são eliminados depois de serem carregados para o BigQuery. Se este valor não for fornecido, é criado um contentor único e, em seguida, eliminado após a conclusão da execução do pipeline. A conta de serviço tem de ter autorização para criar contentores no projeto configurado. |
| Localização | Sim | 6.5.0 | A localização onde o conjunto de dados do BigQuery é criado.
Este valor é ignorado se o conjunto de dados ou o contentor temporário já existir. A predefinição é a
US
multirregião. |
| Nome da chave de encriptação | Sim | 6.5.1/0.18.1 | A chave de encriptação gerida pelo cliente (CMEK) que encripta os dados escritos em qualquer contentor, conjunto de dados ou tabela criados pelo plug-in. Se o contentor, o conjunto de dados ou a tabela já existir, este valor é ignorado. |
| Mantenha as tabelas do BigQuery após a conclusão | Sim | 6.5.0 | Se deve manter todas as tabelas temporárias do BigQuery criadas durante a execução do pipeline para fins de depuração e validação. A predefinição é Não. |
| TTL da tabela temporária (em horas) | Sim | 6.5.0 | Defina o TTL da tabela para tabelas temporárias do BigQuery, em horas. Isto é útil como uma salvaguarda caso o pipeline seja cancelado e o processo de limpeza seja interrompido (por exemplo, se o cluster de execução for encerrado abruptamente). Se definir este valor como
0, desativa o TTL da tabela. A predefinição é
72 (3 dias). |
| Prioridade do trabalho | Sim | 6.5.0 | A prioridade usada para executar tarefas do BigQuery. Selecione
uma das seguintes opções:
|
| Fases para forçar a transferência | Sim | 6.7.0 | Fases suportadas para execução sempre no BigQuery. Cada nome artístico tem de estar numa linha separada. |
| Fases para ignorar a inserção | Sim | 6.7.0 | Fases suportadas para nunca executar no BigQuery. Cada nome artístico tem de estar numa linha separada. |
| Use a API BigQuery Storage Read | Sim | 6.7.0 | Se deve usar a API BigQuery Storage Read ao extrair registos do BigQuery durante a execução do pipeline. Esta opção pode melhorar o desempenho do envio de transformações, mas acarreta custos adicionais. Isto requer que o Scala 2.12 esteja instalado no ambiente de execução. |
Monitorize as alterações de desempenho nos registos
Os registos de tempo de execução do pipeline incluem mensagens que mostram as consultas SQL executadas no BigQuery. Pode monitorizar que fases no pipeline são enviadas para o BigQuery.
O exemplo seguinte mostra as entradas do registo quando a execução do pipeline começa. Os registos indicam que as operações JOIN no seu pipeline foram enviadas para o BigQuery para execução:
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'Users' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'Users'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'UserPurchases' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'Purchases'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'UserPurchases'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'MostPopularNames' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'FirstNameCounts'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'MostPopularNames'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@193] - Starting pull for dataset 'MostPopularNames'
O exemplo seguinte mostra os nomes das tabelas que vão ser atribuídos a cada um dos conjuntos de dados envolvidos na execução pushdown:
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset Purchases stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserDetails stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset FirstNameCounts stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserProfile stored in table <TABLE_ID>
À medida que a execução continua, os registos mostram a conclusão das fases de envio e, eventualmente, a execução das operações JOIN. Por exemplo:
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@235] - Executing join operation for dataset Users
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@118] - Creating table `<TABLE_ID>` using job: <JOB_ID> with SQL statement: SELECT `UserDetails`.id AS `id` , `UserDetails`.first_name AS `first_name` , `UserDetails`.last_name AS `last_name` , `UserDetails`.email AS `email` , `UserProfile`.phone AS `phone` , `UserProfile`.profession AS `profession` , `UserProfile`.age AS `age` , `UserProfile`.address AS `address` , `UserProfile`.score AS `score` FROM `your_project.your_dataset.<DATASET_ID>` AS `UserProfile` LEFT JOIN `your_project.your_dataset.<DATASET_ID>` AS `UserDetails` ON `UserProfile`.id = `UserDetails`.id
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@151] - Created BigQuery table `<TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@245] - Executed join operation for dataset Users
Quando todas as fases estiverem concluídas, é apresentada uma mensagem a indicar que a operação Pull foi concluída. Isto indica que o processo de exportação do BigQuery foi acionado e os registos vão começar a ser lidos no pipeline após o início desta tarefa de exportação. Por exemplo:
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@196] - Completed pull for dataset 'MostPopularNames'
Se a execução do pipeline encontrar erros, estes são descritos nos registos.
Para ver detalhes sobre a execução das operações do BigQuery, como a utilização de recursos, o tempo de execução e as causas de erros, pode ver os dados da tarefa do BigQuery através do ID da tarefa, que aparece nos registos de tarefas.JOIN
Reveja as métricas do pipeline
Para mais informações acerca das métricas que o Cloud Data Fusion fornece para a parte do pipeline que é executada no BigQuery, consulte as métricas de pipeline de pushdown do BigQuery.
O que se segue?
- Saiba mais acerca do Transformation Pushdown no Cloud Data Fusion.