Para melhorar o desempenho nos seus pipelines de dados, pode enviar algumas operações de transformação para o BigQuery em vez do Apache Spark. O pushdown de transformação refere-se a uma definição que permite que uma operação num pipeline de dados do Cloud Data Fusion seja enviada para o BigQuery como um motor de execução. Como resultado, a operação e os respetivos dados são transferidos para o BigQuery, e a operação é realizada aí.
O envio de transformações melhora o desempenho dos pipelines que têm
várias operações
JOIN complexas
ou outras transformações suportadas. A execução de algumas transformações no BigQuery pode ser mais rápida do que a execução no Spark.
As transformações não suportadas e todas as transformações de pré-visualização são executadas no Spark.
Transformações suportadas
O pushdown de transformações está disponível na versão 6.5.0 e posteriores do Cloud Data Fusion, mas algumas das seguintes transformações só são suportadas em versões posteriores.
JOIN operações
O pushdown de transformação está disponível para operações
JOINna versão 6.5.0 e posteriores do Cloud Data Fusion.As operações básicas (on-keys) e avançadas
JOINsão suportadas.As junções têm de ter exatamente duas fases de entrada para a execução ocorrer no BigQuery.
As junções configuradas para carregar uma ou mais entradas na memória são executadas no Spark em vez do BigQuery, exceto nos seguintes casos:
- Se alguma das entradas da junção já tiver sido enviada para baixo.
- Se configurou a junção para ser executada no motor SQL (consulte a opção Fases para forçar a execução ).
Destino do BigQuery
O envio de transformações está disponível para o destino do BigQuery na versão 6.7.0 e posteriores do Cloud Data Fusion.
Quando o BigQuery Sink segue uma fase que foi executada no BigQuery, a operação que escreve registos no BigQuery é realizada diretamente no BigQuery.
Para melhorar o desempenho com este destino, precisa do seguinte:
- A conta de serviço tem de ter autorização para criar e atualizar tabelas no conjunto de dados usado pelo BigQuery Sink.
- Os conjuntos de dados usados para o envio de transformações e o BigQuery Sink têm de ser armazenados na mesma localização.
- A operação tem de ser uma das seguintes:
Insert(a opçãoTruncate Tablenão é suportada)UpdateUpsert
GROUP BY agregações
O pushdown de transformações está disponível para agregações GROUP BY na versão 6.7.0 e posteriores do Cloud Data Fusion.
As agregações GROUP BYno BigQuery estão disponíveis para as seguintes operações:
AvgCollect List(os valores nulos são removidos da matriz de saída)Collect Set(os valores nulos são removidos da matriz de saída)ConcatConcat DistinctCountCount DistinctCount NullsLogical AndLogical OrMaxMinStandard DeviationSumSum of SquaresCorrected Sum of SquaresVarianceShortest StringLongest String
As agregações GROUP BY são executadas no BigQuery nos seguintes casos:
- Segue uma fase que já foi movida para baixo.
- Configurou-o para ser executado no motor SQL (consulte a opção Passos para forçar a execução ).
Remova duplicados de agregações
A funcionalidade Transformation Pushdown está disponível para agregações de remoção de duplicados na versão 6.7.0 e posterior do Cloud Data Fusion para as seguintes operações:
- Nenhuma operação de filtro especificada
ANY(um valor não nulo para o campo pretendido)MIN(o valor mínimo para o campo especificado)MAX(o valor máximo para o campo especificado)
As seguintes operações não são suportadas:
FIRSTLAST
As agregações de remoção de duplicados são executadas no motor SQL nos seguintes casos:
- Segue uma fase que já foi movida para baixo.
- Configurou-o para ser executado no motor SQL (consulte a opção Passos para forçar a execução ).
BigQuery Source Pushdown
O pushdown de origem do BigQuery está disponível nas versões 6.8.0 e posteriores do Cloud Data Fusion.
Quando uma origem do BigQuery segue uma fase compatível com o pushdown do BigQuery, o pipeline pode executar todas as fases compatíveis no BigQuery.
O Cloud Data Fusion copia os registos necessários para executar o pipeline no BigQuery.
Quando usa o pushdown de origem do BigQuery, as propriedades de particionamento e agrupamento em clusters de tabelas são preservadas, o que lhe permite usar estas propriedades para otimizar ainda mais as operações, como as junções.
Requisitos adicionais
Para usar o envio de dados do BigQuery, os seguintes requisitos têm de estar em vigor:
A conta de serviço configurada para o envio de transformações do BigQuery tem de ter autorizações para ler tabelas no conjunto de dados da origem do BigQuery.
Os conjuntos de dados usados na origem do BigQuery e o conjunto de dados configurado para o envio de transformações têm de ser armazenados na mesma localização.
Agregações de janelas
A funcionalidade Transformation Pushdown está disponível para agregações de janelas nas versões 6.9 e posteriores do Cloud Data Fusion. As agregações de janelas no BigQuery são suportadas para as seguintes operações:
RankDense RankPercent RankN tileRow NumberMedianContinuous PercentileLeadLagFirstLastCumulative distributionAccumulate
As agregações de janelas são executadas no BigQuery nos seguintes casos:
- Segue uma fase que já foi movida para baixo.
- Configurou-o para ser executado no motor SQL (consulte a opção Passos para forçar o pushdown).
Wrangler Filter Pushdown
O Wrangler Filter Pushdown está disponível nas versões 6.9 e posteriores do Cloud Data Fusion.
Quando usa o plug-in Wrangler, pode enviar filtros, conhecidos como Precondition
operações, para serem executados no BigQuery em vez do Spark.
O pushdown de filtros só é suportado com o modo SQL para Preconditions, que também foi lançado na versão 6.9. Neste modo, o plug-in aceita uma expressão de pré-condição em SQL padrão ANSI.
Se o modo SQL for usado para pré-condições, as diretivas e as diretivas definidas pelo utilizador são desativadas para o plug-in Wrangler, uma vez que não são suportadas com pré-condições no modo SQL.
O modo SQL para pré-condições não é suportado para plug-ins do Wrangler com várias entradas quando a funcionalidade Transformation Pushdown está ativada. Se for usado com várias entradas, esta fase do Wrangler com condições de filtro SQL é executada no Spark.
Os filtros são executados no BigQuery nos seguintes casos:
- Segue uma fase que já foi movida para baixo.
- Configurou-o para ser executado no motor SQL (consulte a opção Passos para forçar o pushdown).
Métrica
Para mais informações acerca das métricas que o Cloud Data Fusion fornece para a parte do pipeline que é executada no BigQuery, consulte as métricas de pipeline de pushdown do BigQuery.
Quando usar o envio de transformações
A execução de transformações no BigQuery envolve o seguinte:
- Escrever registos no BigQuery para fases suportadas no seu pipeline.
- Executar fases suportadas no BigQuery.
- Ler registos do BigQuery após a execução das transformações suportadas, a menos que sejam seguidas por um BigQuery Sink.
Consoante a dimensão dos seus conjuntos de dados, pode haver uma sobrecarga de rede considerável, o que pode ter um impacto negativo no tempo de execução geral do pipeline quando o envio de transformações está ativado.
Devido à sobrecarga da rede, recomendamos o envio de transformações nos seguintes casos:
- As várias operações suportadas são executadas em sequência (sem passos entre as fases).
- Os ganhos de desempenho do BigQuery na execução das transformações, em comparação com o Spark, superam a latência do movimento de dados para dentro e, possivelmente, para fora do BigQuery.
Como funciona
Quando executa um pipeline que usa o pushdown de transformações, o Cloud Data Fusion executa fases de transformação suportadas no BigQuery. Todas as outras fases no pipeline são executadas no Spark.
Quando executar transformações:
O Cloud Data Fusion carrega os conjuntos de dados de entrada para o BigQuery escrevendo registos no Cloud Storage e, em seguida, executando uma tarefa de carregamento do BigQuery.
As operações
JOINe as transformações suportadas são, em seguida, executadas como tarefas do BigQuery através de declarações SQL.Se for necessário um processamento adicional após a execução das tarefas, os registos podem ser exportados do BigQuery para o Spark. No entanto, se a opção Tentar copiar diretamente para os destinos do BigQuery estiver ativada e o destino do BigQuery seguir uma fase que foi executada no BigQuery, os registos são escritos diretamente na tabela de destino do BigQuery.
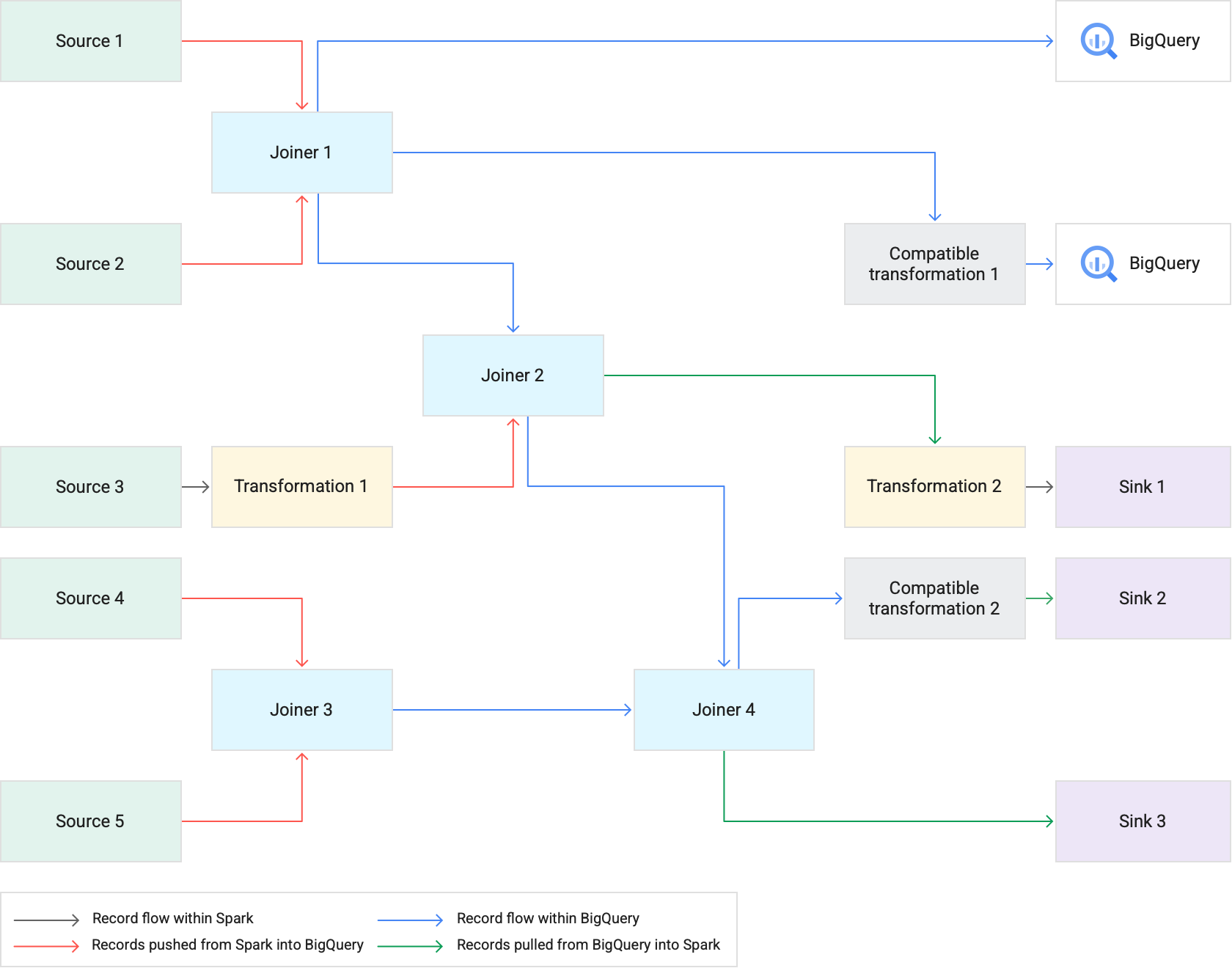
O diagrama seguinte mostra como o envio de transformações executa transformações suportadas no BigQuery em vez do Spark.
Práticas recomendadas
Ajuste os tamanhos dos clusters e dos executores
Para otimizar a gestão de recursos no seu pipeline, faça o seguinte:
Use o número correto de trabalhadores do cluster (nós) para uma carga de trabalho. Por outras palavras, tire o máximo partido do cluster do Dataproc aprovisionado usando totalmente a CPU e a memória disponíveis para a sua instância, ao mesmo tempo que beneficia da velocidade de execução do BigQuery para tarefas grandes.
Melhore o paralelismo nos seus pipelines usando clusters de escalamento automático.
Ajuste as configurações dos recursos nas fases do pipeline em que os registos são enviados ou extraídos do BigQuery durante a execução do pipeline.
Recomendado: experimente aumentar o número de núcleos da CPU para os recursos do executor (até ao número de núcleos da CPU que o nó de trabalho usa). Os executores otimizam a utilização da CPU durante os passos de serialização e desserialização à medida que os dados entram e saem do BigQuery. Para mais informações, consulte Dimensionamento de clusters.
Uma vantagem da execução de transformações no BigQuery é que os seus pipelines podem ser executados em clusters do Dataproc mais pequenos. Se as junções forem as operações que consomem mais recursos no seu pipeline, pode experimentar tamanhos de cluster mais pequenos, uma vez que as operações pesadas JOIN são agora realizadas no BigQuery, o que lhe permite reduzir potencialmente os custos de computação gerais.
Obtenha dados mais rapidamente com a API BigQuery Storage Read
Depois de o BigQuery executar as transformações, o seu pipeline pode ter fases adicionais para executar no Spark. Na versão 6.7.0 e posteriores do Cloud Data Fusion, o Transformation Pushdown suporta a API BigQuery Storage Read, o que melhora a latência e resulta em operações de leitura mais rápidas no Spark. Esta ação pode reduzir o tempo de execução geral do pipeline.
A API lê registos em paralelo, pelo que recomendamos que ajuste os tamanhos do executor em conformidade. Se forem executadas operações com utilização intensiva de recursos no BigQuery, reduza a atribuição de memória para os executores de modo a melhorar o paralelismo quando o pipeline é executado (consulte o artigo Ajuste os tamanhos dos clusters e dos executores).
A API BigQuery Storage Read está desativada por predefinição. Pode ativá-lo em ambientes de execução onde o Scala 2.12 está instalado (incluindo o Dataproc 2.0 e o Dataproc 1.5).
Considere o tamanho do conjunto de dados
Considere os tamanhos dos conjuntos de dados nas operações JOIN. Para operações que geram um número substancial de registos de saída, como algo semelhante a uma operação de junção cruzada, o tamanho do conjunto de dados resultante pode ser ordens de magnitude superior ao do conjunto de dados de entrada.JOINJOIN Além disso, considere a sobrecarga de extrair estes registos novamente para o Spark quando ocorre o processamento adicional do Spark para estes registos, como uma transformação ou um destino, no contexto do desempenho geral do pipeline.
Mitigue dados distorcidos
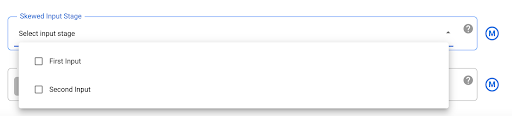
As operações JOIN para dados fortemente enviesados podem fazer com que a tarefa do BigQuery exceda os limites de utilização de recursos, o que faz com que a operação JOIN falhe. Para evitar esta situação, aceda às definições do plug-in Joiner e identifique a entrada distorcida no campo Skewed Input Stage. Isto permite que o Cloud Data Fusion organize as entradas de forma a reduzir o risco de a declaração do BigQuery exceder os limites.