Questo documento è la terza parte di una serie che descrive il disaster recovery (RE) in Google Cloud. Questa parte illustra gli scenari per il backup e il recupero dei dati.
La serie è composta dalle seguenti parti:
- Guida alla pianificazione del ripristino di emergenza
- Componenti di base per il ripristino di emergenza
- Scenari di ripristino di emergenza dei dati (questo documento)
- Scenari di ripristino di emergenza per le applicazioni
- Progettazione ripristino di emergenza per i workload con limitazioni a livello di località
- Casi d'uso di ripristino di emergenza: applicazioni di analisi dei dati con limitazioni di località
- Progettazione ripristino di emergenza per interruzioni dell'infrastruttura cloud
Introduzione
I piani di ripristino di emergenza devono specificare come evitare la perdita di dati durante un'emergenza. Il termine dati qui copre due scenari. Il backup e il successivo recupero del database, dei dati di log e di altri tipi di dati rientrano in uno dei seguenti scenari:
- Backup dei dati. Il backup dei dati prevede la copia di una quantità discreta di dati da una posizione all'altra. I backup vengono eseguiti nell'ambito di un piano di ripristino per recuperare i dati danneggiati in modo da poterli ripristinare a uno stato buono noto direttamente nell'ambiente di produzione oppure per poter ripristinare i dati nell'ambiente di RE se l'ambiente di produzione non è disponibile. In genere, i backup dei dati hanno un RTO da piccolo a medio e un RPO piccolo.
- Backup dei database. I backup del database sono leggermente più complessi, perché in genere comportano il recupero fino al punto nel tempo. Pertanto, oltre a considerare come eseguire il backup e il ripristino dei backup del database e a garantire che il sistema di database di recupero rispecchi la configurazione di produzione (stessa versione, configurazione del disco speculare), devi anche considerare come eseguire il backup dei log delle transazioni. Durante il ripristino, dopo aver ripristinato la funzionalità del database, devi applicare l'ultimo backup del database e poi i log delle transazioni recuperati di cui è stato eseguito il backup dopo l'ultimo backup. A causa dei fattori di complicazione inerenti ai sistemi di database (ad esempio, la necessità di abbinare le versioni tra i sistemi di produzione e di ripristino), l'adozione di un approccio che privilegia l'alta disponibilità per ridurre al minimo il tempo di ripristino da una situazione che potrebbe causare l'indisponibilità del server di database consente di ottenere valori RTO e RPO più piccoli.
Quando esegui carichi di lavoro di produzione su Google Cloud, potresti utilizzare un sistema distribuito a livello globale in modo che, se si verifica un problema in una regione, l'applicazione continui a fornire il servizio anche se è meno disponibile. In sostanza, l'applicazione richiama il proprio piano di RE.
Il resto di questo documento illustra esempi di come progettare alcuni scenari per dati e database che possono aiutarti a raggiungere i tuoi obiettivi di RTO e RPO.
L'ambiente di produzione è on-premise
In questo scenario, l'ambiente di produzione è on-premise e il piano di ripristino di emergenza prevede l'utilizzo di Google Cloud come sito di ripristino.
Backup e recupero dei dati
Puoi utilizzare diverse strategie per implementare un processo di backup regolare dei dati on-premise su Google Cloud. Questa sezione esamina due delle soluzioni più comuni.
Soluzione 1: esegui il backup su Cloud Storage utilizzando un'attività pianificata
Questo pattern utilizza i seguenti componenti di base di RE:
- Cloud Storage
Un'opzione per il backup dei dati è creare un'attività pianificata che esegue uno script
o un'applicazione per trasferire i dati a Cloud Storage. Puoi automatizzare
un processo di backup in Cloud Storage utilizzando il
comando Google Cloud CLI gcloud storage
o una delle
librerie client di Cloud Storage.
Ad esempio, il seguente comando gcloud storage copia tutti i file da una directory di origine a un bucket specificato.
gcloud storage cp -r SOURCE_DIRECTORY gs://BUCKET_NAME
Sostituisci SOURCE_DIRECTORY con il percorso della directory di origine
e BUCKET_NAME con un nome a tua scelta per il bucket.
Il nome deve soddisfare i requisiti per i nomi dei bucket.
I passaggi seguenti descrivono come implementare una procedura di backup e ripristino
utilizzando il comando gcloud storage.
- Installa
gcloud CLIsul computer on-premise che utilizzi per caricare i file di dati. - Crea un bucket come destinazione per il backup dei dati.
- Crea un account di servizio.
- Crea un
criterio IAM
per limitare l'accesso al bucket e ai relativi oggetti. Includi l'account di servizio
creato appositamente per questo scopo. Per informazioni dettagliate sulle autorizzazioni
per l'accesso a Cloud Storage, consulta Autorizzazioni IAM per
gcloud storage. - Utilizza l'Impersonificazione service account per fornire l'accesso al tuo utente Google Cloud locale (o account di servizio) per impersonare il account di servizio che hai creato in precedenza. In alternativa, puoi creare un nuovo utente appositamente per questo scopo.
- Verifica di poter caricare e scaricare file nel bucket di destinazione.
- Configura una pianificazione per lo script che utilizzi per caricare i backup utilizzando strumenti come Linux
crontabe l'Utilità di pianificazione di Windows. - Configura una procedura di ripristino che utilizzi il comando
gcloud storageper recuperare i dati nell'ambiente di ripristino di emergenza su Google Cloud.
Puoi anche utilizzare il comando gcloud storage rsync per eseguire sincronizzazioni incrementali in tempo reale tra i tuoi dati e un bucket Cloud Storage.
Ad esempio, il seguente comando gcloud storage rsync
rende i contenuti di un bucket Cloud Storage uguali a quelli
della directory di origine copiando i file o gli oggetti mancanti o quelli i cui
dati sono stati modificati. Se il volume di dati modificati tra sessioni di backup successive è piccolo rispetto al volume totale dei dati di origine, l'utilizzo di gcloud storage rsync può essere più efficiente dell'utilizzo del comando gcloud storage cp. Utilizzando gcloud storage rsync, puoi implementare una pianificazione di backup più frequente e ottenere un RPO inferiore.
gcloud storage rsync -r SOURCE_DIRECTORY gs:// BUCKET_NAME
Per saperne di più, consulta il
comando gcloud storage per trasferimenti più piccoli di dati on-premise.
Soluzione 2: esegui il backup su Cloud Storage utilizzando Transfer Service for On Premises Data
Questo pattern utilizza i seguenti componenti di base di RE:
- Cloud Storage
- Transfer Service for On Premises Data
Il trasferimento di grandi quantità di dati su una rete spesso richiede una pianificazione accurata e strategie di esecuzione solide. Sviluppare script personalizzati scalabili, affidabili e gestibili non è un'attività banale. Gli script personalizzati possono spesso comportare valori RPO inferiori e persino maggiori rischi di perdita di dati.
Per indicazioni sullo spostamento di grandi volumi di dati da località on-premise a Cloud Storage, consulta Spostare o eseguire il backup dei dati dall'archiviazione on-premise.
Soluzione 3: esegui il backup su Cloud Storage utilizzando una soluzione gateway partner
Questo pattern utilizza i seguenti componenti di base di RE:
- Cloud Interconnect
- Archiviazione a più livelli di Cloud Storage
Le applicazioni on-premise sono spesso integrate con soluzioni di terze parti che possono essere utilizzate nell'ambito della strategia di backup e ripristino dei dati. Le soluzioni spesso utilizzano un pattern di archiviazione a livelli in cui i backup più recenti si trovano su uno spazio di archiviazione più veloce e i backup meno recenti vengono migrati lentamente a uno spazio di archiviazione più economico (più lento). Quando utilizzi Google Cloud come destinazione, hai a disposizione diverse opzioni di classe di archiviazione da utilizzare come equivalente del livello più lento.
Un modo per implementare questo pattern è utilizzare un gateway partner tra lo spazio di archiviazione on-premise e Google Cloud per facilitare il trasferimento dei dati a Cloud Storage. Il seguente diagramma illustra questa disposizione, con una soluzione partner che gestisce il trasferimento dall'appliance NAS on-premise o SAN.

In caso di errore, i dati di cui è stato eseguito il backup devono essere recuperati nell'ambiente di RE. L'ambiente di ripristino di emergenza viene utilizzato per gestire il traffico di produzione finché non è possibile ripristinare l'ambiente di produzione. Il modo in cui raggiungi questo obiettivo dipende dalla tua applicazione, dalla soluzione partner e dalla sua architettura. Alcuni scenari end-to-end sono descritti nel documento di richiesta di DR.
Puoi anche utilizzare i database Google Cloud gestiti come destinazioni di RE. Ad esempio, Cloud SQL per SQL Server supporta le importazioni dei log delle transazioni. Puoi esportare i log delle transazioni dall'istanza SQL Server on-premise, caricarli in Cloud Storage e importarli in Cloud SQL per SQL Server.
Per ulteriori indicazioni sui modi per trasferire i dati on-premise a Google Cloud, consulta Trasferimento di set di big data a Google Cloud.
Per saperne di più sulle soluzioni dei partner, consulta la pagina Partner sul sito web Google Cloud .
Backup e ripristino del database
Puoi utilizzare diverse strategie per implementare una procedura per il recupero di un sistema di database on-premise in Google Cloud. Questa sezione esamina due delle soluzioni più comuni.
In questo documento non vengono descritti in dettaglio i vari meccanismi di backup e ripristino integrati inclusi nei database di terze parti. Questa sezione fornisce indicazioni generali, che vengono implementate nelle soluzioni discusse qui.
Soluzione 1: backup e ripristino utilizzando un server di ripristino su Google Cloud
- Crea un backup del database utilizzando i meccanismi di backup integrati del sistema di gestione del database.
- Collega la tua rete on-premise e la tua rete Google Cloud .
- Crea un bucket Cloud Storage come destinazione per il backup dei dati.
- Copia i file di backup in Cloud Storage utilizzando
gcloud storagegcloud CLI o una soluzione gateway partner (vedi i passaggi descritti in precedenza nella sezione Backup e ripristino dei dati). Per informazioni dettagliate, vedi Eseguire la migrazione a Google Cloud: trasferire i tuoi set di dati di grandi dimensioni. - Copia i log delle transazioni nel sito di recupero su Google Cloud. Un backup dei log delle transazioni consente di mantenere bassi i valori RPO.
Dopo aver configurato questa topologia di backup, devi assicurarti di poter eseguire il ripristino sul sistema che si trova su Google Cloud. Questo passaggio in genere prevede non solo il ripristino del file di backup nel database di destinazione, ma anche la riproduzione dei log delle transazioni per ottenere il valore RTO più piccolo. Una tipica sequenza di recupero è la seguente:
- Crea un'immagine personalizzata del server di database su Google Cloud. Il server di database deve avere la stessa configurazione dell'immagine del server di database on-premise.
- Implementa una procedura per copiare i file di backup on-premise e i file di log delle transazioni in Cloud Storage. Per un esempio di implementazione, vedi la soluzione 1.
- Avvia un'istanza di dimensioni minime dall'immagine personalizzata e collega i dischi permanenti necessari.
- Imposta il flag di eliminazione automatica su false per i dischi permanenti.
- Applica l'ultimo file di backup copiato in precedenza in Cloud Storage, seguendo le istruzioni del sistema di database per il recupero dei file di backup.
- Applica l'ultimo set di file di log delle transazioni copiati in Cloud Storage.
- Sostituisci l'istanza minima con un'istanza più grande in grado di accettare il traffico di produzione.
- Passa ai client per puntare al database recuperato in Google Cloud.
Quando l'ambiente di produzione è in esecuzione e in grado di supportare i carichi di lavoro di produzione, devi invertire i passaggi che hai seguito per eseguire il failover nell'ambiente di ripristinoGoogle Cloud . Una sequenza tipica per tornare all'ambiente di produzione è la seguente:
- Esegui un backup del database in esecuzione su Google Cloud.
- Copia il file di backup nell'ambiente di produzione.
- Applica il file di backup al sistema di database di produzione.
- Impedisci ai client di connettersi al sistema di database in Google Cloud, ad esempio interrompendo il servizio del sistema di database. Da questo momento in poi, la tua applicazione non sarà disponibile finché non avrai terminato il ripristino dell'ambiente di produzione.
- Copia tutti i file di log delle transazioni nell'ambiente di produzione e applicali.
- Reindirizza le connessioni client all'ambiente di produzione.
Soluzione 2: replica su un server di standby su Google Cloud
Un modo per ottenere valori RTO e RPO molto piccoli è replicare (non solo eseguire il backup) i dati e, in alcuni casi, lo stato del database in tempo reale in una replica del server di database.
- Collega la tua rete on-premise e la tua rete Google Cloud .
- Crea un'immagine personalizzata del server di database su Google Cloud. Il server di database deve avere la stessa configurazione sull'immagine del server di database on-premise.
- Avvia un'istanza dall'immagine personalizzata e collega tutti i dischi permanenti necessari.
- Imposta il flag di eliminazione automatica su false per i dischi permanenti.
- Configura la replica tra il server di database on-premise e il server di database di destinazione in Google Cloud seguendo le istruzioni specifiche per il software del database.
- I client sono configurati in modo da puntare al server di database on-premise durante il normale funzionamento.
Dopo aver configurato questa topologia di replica, passa ai client per puntare al server di standby in esecuzione nella tua rete Google Cloud .
Quando l'ambiente di produzione è di nuovo attivo e in grado di supportare i carichi di lavoro di produzione, devi sincronizzare di nuovo il server di database di produzione con il server di databaseGoogle Cloud e poi fare in modo che i client puntino di nuovo all'ambiente di produzione.
L'ambiente di produzione è Google Cloud
In questo scenario, sia l'ambiente di produzione sia l'ambiente di ripristino di emergenza vengono eseguiti su Google Cloud.
Backup e recupero dei dati
Un pattern comune per i backup dei dati è l'utilizzo di un pattern di archiviazione a livelli. Quando il workload di produzione è attivo Google Cloud, il sistema di archiviazione a livelli è simile al seguente diagramma. Migri i dati a un livello con costi di archiviazione inferiori, perché è meno probabile che sia necessario accedere ai dati di cui è stato eseguito il backup.
Questo pattern utilizza i seguenti componenti di base di RE:
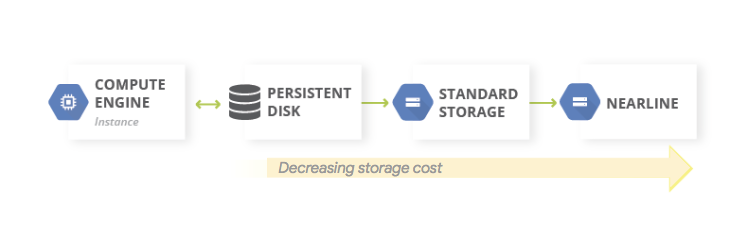
Poiché le classi di archiviazione Nearline, Coldline e Archive sono destinate all'archiviazione di dati a cui si accede di rado, sono previsti costi aggiuntivi associati al recupero dei dati o dei metadati archiviati in queste classi, oltre a durate minime di archiviazione per le quali vengono addebitati dei costi.
Backup e ripristino del database
Quando utilizzi un database autogestito (ad esempio, hai installato MySQL, PostgreSQL o SQL Server su un'istanza di Compute Engine), si applicano le stesse preoccupazioni operative della gestione dei database di produzione on-premise, ma non devi più gestire l'infrastruttura sottostante.
Backup and DR Service è una soluzione cloud-native centralizzata per il backup e il ripristino di carichi di lavoro cloud e ibridi. Offre un rapido recupero dei dati e facilita la rapida ripresa delle operazioni aziendali essenziali.
Per saperne di più sull'utilizzo di Backup e RE per scenari di database autogestiti su Google Cloud, consulta quanto segue:
In alternativa, puoi configurare le configurazioni HA utilizzando le funzionalità di base di DR appropriate per mantenere basso l'RTO. Puoi progettare la configurazione del database in modo da rendere fattibile il recupero a uno stato il più vicino possibile a quello pre-disastro; in questo modo i valori RPO rimangono bassi. Google Cloud offre un'ampia gamma di opzioni per questo scenario.
In questa sezione vengono illustrati due approcci comuni alla progettazione dell'architettura di recupero del database per i database autogestiti su Google Cloud .
Recupero di un server di database senza sincronizzare lo stato
Un pattern comune consiste nell'abilitare il recupero di un server di database che non richiede la sincronizzazione dello stato del sistema con una replica di standby aggiornata.
Questo pattern utilizza i seguenti componenti di base di RE:
- Compute Engine
- Gruppi di istanze gestite
- Cloud Load Balancing (bilanciamento del carico interno)
Il seguente diagramma illustra un'architettura di esempio che affronta lo scenario. Implementando questa architettura, avrai un piano di RE che reagisce automaticamente a un errore senza richiedere il ripristino manuale.

I passaggi seguenti descrivono come configurare questo scenario:
- Crea una rete VPC.
Crea un'immagine personalizzata configurata con il server di database nel seguente modo:
- Configura il server in modo che i file di database e i file di log vengano scritti su un disco permanente standard collegato.
- Crea uno snapshot dal disco permanente collegato.
- Configura uno script di avvio per creare un disco permanente dallo snapshot e per montarlo.
- Crea un'immagine personalizzata del disco di avvio.
Crea un template di istanza che utilizza l'immagine.
Utilizzando il modello di istanza, configura un gruppo di istanze gestite con una dimensione di destinazione pari a 1.
Configura il controllo di integrità utilizzando le metriche di Cloud Monitoring.
Configura il bilanciamento del carico interno utilizzando il gruppo di istanze gestite.
Configura un'attività pianificata per creare snapshot regolari del disco permanente.
Nel caso in cui sia necessaria un'istanza di database sostitutiva, questa configurazione esegue automaticamente le seguenti operazioni:
- Visualizza un altro server di database della versione corretta nella stessa zona.
- Collega un disco permanente con i file di backup e di log delle transazioni più recenti all'istanza del server di database appena creata.
- Riduce la necessità di riconfigurare i client che comunicano con il server di database in risposta a un evento.
- Garantisce che i Google Cloud controlli di sicurezza (criteri IAM, impostazioni firewall) che si applicano al server di database di produzione si applichino al server di database recuperato.
Poiché l'istanza di sostituzione viene creata da un modello di istanza, i controlli applicati all'istanza originale vengono applicati all'istanza di sostituzione.
Questo scenario sfrutta alcune delle funzionalità di HA disponibili in Google Cloud; non devi avviare alcun passaggio di failover, perché si verificano automaticamente in caso di emergenza. Il bilanciatore del carico interno garantisce che, anche quando è necessaria un'istanza di sostituzione, venga utilizzato lo stesso indirizzo IP per il server di database. Il modello di istanza e l'immagine personalizzata assicurano che l'istanza di sostituzione sia configurata in modo identico all'istanza che sostituisce. Se esegui regolarmente snapshot dei dischi permanenti, ti assicuri che quando i dischi vengono ricreati dagli snapshot e collegati all'istanza di sostituzione, quest'ultima utilizzi i dati recuperati in base a un valore RPO dettato dalla frequenza degli snapshot. In questa architettura, vengono ripristinati automaticamente anche i file di log delle transazioni più recenti scritti sul disco permanente.
Il gruppo di istanze gestite fornisce l'alta affidabilità in modo approfondito. Fornisce meccanismi per reagire agli errori a livello di applicazione o istanza e non devi intervenire manualmente se si verifica uno di questi scenari. L'impostazione di una dimensione target pari a uno garantisce che ci sia sempre una sola istanza attiva che viene eseguita nel gruppo di istanze gestite e che gestisce il traffico.
I dischi permanenti standard sono a livello di zona, quindi in caso di errore a livello di zona, gli snapshot sono necessari per ricreare i dischi. Gli snapshot sono disponibili anche in più regioni, il che ti consente di ripristinare un disco non solo all'interno della stessa regione, ma anche in una regione diversa.
Una variante di questa configurazione consiste nell'utilizzare dischi permanenti regionali al posto di dischi permanenti standard. In questo caso, non è necessario ripristinare lo snapshot nell'ambito del passaggio di ripristino.
La variazione che scegli è determinata dal budget e dai valori di RTO e RPO.
Recupero da danneggiamento parziale in database di grandi dimensioni
La replica asincrona del disco permanente offre una replica dell'archiviazione a blocchi con RPO e RTO bassi per RE attivo-passivo tra regioni. Questa opzione di archiviazione ti consente di gestire la replica dei workload di Compute Engine a livello di infrastruttura anziché a livello di workload.
Se utilizzi un database in grado di archiviare petabyte di dati, potresti riscontrare un'interruzione che influisce su alcuni dati, ma non su tutti. In questo caso, devi ridurre al minimo la quantità di dati da ripristinare; non devi (o vuoi) recuperare l'intero database solo per ripristinare alcuni dati.
Esistono diverse strategie di mitigazione che puoi adottare:
- Archivia i dati in tabelle diverse per periodi di tempo specifici. Questo metodo garantisce che devi ripristinare solo un sottoinsieme di dati in una nuova tabella, anziché un intero set di dati.
Archivia i dati originali su Cloud Storage. Questo approccio ti consente di creare una nuova tabella e ricaricare i dati non danneggiati. Da qui, puoi modificare le tue applicazioni in modo che puntino alla nuova tabella.
Inoltre, se il tuo RTO lo consente, puoi impedire l'accesso alla tabella contenente i dati danneggiati lasciando le applicazioni offline finché i dati non danneggiati non vengono ripristinati in una nuova tabella.
Servizi di database gestiti su Google Cloud
Questa sezione illustra alcuni metodi che puoi utilizzare per implementare meccanismi di backup e ripristino appropriati per i servizi di database gestiti su Google Cloud.
I database gestiti sono progettati per la scalabilità, quindi i meccanismi tradizionali di backup e ripristino che vedi con i sistemi RDBMS tradizionali di solito non sono disponibili. Come nel caso dei database autogestiti, se utilizzi un database in grado di archiviare petabyte di dati, devi ridurre al minimo la quantità di dati da ripristinare in uno scenario di RE. Esistono diverse strategie per ogni database gestito per aiutarti a raggiungere questo obiettivo.
Bigtable fornisce la replica Bigtable. Un database Bigtable replicato può fornire una disponibilità maggiore rispetto a un singolo cluster, una velocità effettiva di lettura aggiuntiva e una durabilità e resilienza maggiori in caso di errori a livello di zona o regione.
I backup di Bigtable sono un servizio completamente gestito che ti consente di salvare una copia dello schema e dei dati di una tabella e di ripristinarli dal backup in una nuova tabella in un secondo momento.
Puoi anche esportare le tabelle da Bigtable come una serie di file di sequenza Hadoop. Puoi quindi archiviare questi file in Cloud Storage o utilizzarli per importare i dati in un'altra istanza di Bigtable. Puoi replicare il set di dati Bigtable in modo asincrono tra le zone all'interno di una regione Google Cloud .
BigQuery. Se vuoi archiviare i dati, puoi usufruire dell'archiviazione a lungo termine di BigQuery. Se una tabella non viene modificata per 90 giorni consecutivi, il relativo prezzo di archiviazione si riduce automaticamente del 50%. L'archiviazione a lungo termine di una tabella non comporta alcuna penalizzazione in termini di prestazioni, durabilità, disponibilità o qualsiasi altra funzionalità. Se la tabella viene modificata, vengono ripristinati i prezzi dell'archiviazione standard e il conto alla rovescia di 90 giorni riprende il conteggio da zero.
BigQuery viene replicato in due zone di una singola regione, ma questo non ti aiuterà in caso di danneggiamento delle tabelle. Pertanto, devi avere un piano per poter ripristinare la situazione. Ad esempio, puoi eseguire le seguenti operazioni:
- Se il danneggiamento viene rilevato entro 7 giorni, esegui una query sulla tabella fino a un punto nel tempo precedente per recuperarla prima del danneggiamento utilizzando i decoratori snapshot.
- Esporta i dati da BigQuery e crea una nuova tabella che contenga i dati esportati, ma escluda quelli danneggiati.
- Archivia i dati in tabelle diverse per periodi di tempo specifici. Questo metodo garantisce che dovrai ripristinare solo un sottoinsieme di dati in una nuova tabella, anziché un intero set di dati.
- Crea copie del set di dati in periodi di tempo specifici. Puoi utilizzare queste copie se si è verificato un evento di danneggiamento dei dati oltre a quanto può acquisire una query point-in-time (ad esempio, più di 7 giorni fa). Puoi anche copiare un set di dati da una regione all'altra per garantire la disponibilità dei dati in caso di errori a livello di regione.
- Archivia i dati originali su Cloud Storage, che ti consente di creare una nuova tabella e ricaricare i dati non danneggiati. Da qui, puoi modificare le tue applicazioni in modo che puntino alla nuova tabella.
Firestore. Il servizio di importazione ed esportazione gestito ti consente di importare ed esportare le entità Firestore utilizzando un bucket Cloud Storage. Puoi quindi implementare un processo che può essere utilizzato per il recupero dall'eliminazione accidentale dei dati.
Cloud SQL. Se utilizzi Cloud SQL, il database MySQLGoogle Cloud completamente gestito, devi abilitare i backup automatici e la registrazione binaria per le tue istanze Cloud SQL. Questo approccio ti consente di eseguire un recupero point-in-time, che ripristina il database da un backup e lo recupera in una nuova istanza Cloud SQL. Per saperne di più, consulta Informazioni sui backup di Cloud SQL e Informazioni sul ripristino di emergenza (RE) in Cloud SQL.
Puoi anche configurare Cloud SQL in una configurazione HA e repliche tra regioni per massimizzare il tempo di attività in caso di errore a livello di zona o regione.
Se hai attivato la manutenzione pianificata con tempi di inattività quasi azzerati per Cloud SQL, puoi valutare l'impatto degli eventi di manutenzione sulle tue istanze simulando eventi di manutenzione pianificata con tempi di inattività quasi azzerati su Cloud SQL per MySQL e su Cloud SQL per PostgreSQL.
Per Cloud SQL Enterprise Plus, puoi utilizzare il recupero di ripristino di emergenza (RE) avanzato per semplificare i processi di recupero e failback senza perdita di dati dopo aver eseguito un failover cross-regionale.
Spanner. Puoi utilizzare i modelli Dataflow per eseguire un'esportazione completa del database in un insieme di file Avro in un bucket Cloud Storage e utilizzare un altro modello per reimportare i file esportati in un nuovo database Spanner.
Per backup più controllati, il connettore Dataflow consente di scrivere codice per leggere e scrivere dati in Spanner in una pipeline Dataflow. Ad esempio, puoi utilizzare il connettore per copiare i dati da Spanner a Cloud Storage come destinazione di backup. La velocità con cui i dati possono essere letti da Spanner (o riscritti) dipende dal numero di nodi configurati. Ciò ha un impatto diretto sui valori RTO.
La funzionalità timestamp di commit di Spanner può essere utile per i backup incrementali, in quanto consente di selezionare solo le righe aggiunte o modificate dall'ultimo backup completo.
Per i backup gestiti, Spanner Backup and Restore ti consente di creare backup coerenti che possono essere conservati per un massimo di un anno. Il valore RTO è inferiore rispetto all'esportazione perché l'operazione di ripristino monta direttamente il backup senza copiare i dati.
Per valori RTO ridotti, puoi configurare un'istanza Spanner in standby attivo configurata con il numero minimo di nodi richiesti per soddisfare i requisiti di archiviazione e velocità effettiva di lettura e scrittura.
Il recupero point-in-time (PITR) di Spanner ti consente di recuperare i dati da un momento specifico del passato. Ad esempio, se un operatore scrive inavvertitamente dati o il lancio di un'applicazione danneggia il database, con PITR puoi recuperare i dati da un momento specifico del passato, fino a un massimo di 7 giorni.
Cloud Composer. Puoi utilizzare Cloud Composer (una versione gestita di Apache Airflow) per pianificare backup regolari di più databaseGoogle Cloud . Puoi creare un grafo diretto aciclico (DAG) da eseguire in base a una pianificazione (ad esempio, giornaliera) per copiare i dati in un altro progetto, set di dati o tabella (a seconda della soluzione utilizzata) oppure per esportarli in Cloud Storage.
L'esportazione o la copia dei dati può essere eseguita utilizzando i vari operatori Cloud Platform.
Ad esempio, puoi creare un DAG per eseguire una delle seguenti operazioni:
- Esporta una tabella BigQuery in Cloud Storage utilizzando l'BigQueryToCloudStorageOperator.
- Esporta Firestore in modalità Datastore (Datastore) in Cloud Storage utilizzando DatastoreExportOperator.
- Esporta le tabelle MySQL in Cloud Storage utilizzando MySqlToGoogleCloudStorageOperator.
- Esporta le tabelle Postgres in Cloud Storage utilizzando PostgresToGoogleCloudStorageOperator.
L'ambiente di produzione è un altro cloud
In questo scenario, l'ambiente di produzione utilizza un altro cloud provider e il tuo piano di ripristino di emergenza prevede l'utilizzo di Google Cloud come sito di recupero.
Backup e recupero dei dati
Il trasferimento di dati tra object store è un caso d'uso comune per gli scenari di RE. Storage Transfer Service è compatibile con Amazon S3 ed è il modo consigliato per trasferire oggetti da Amazon S3 a Cloud Storage.
Puoi configurare un job di trasferimento per pianificare la sincronizzazione periodica dall'origine dati al sink dati, con filtri avanzati basati sulle date di creazione dei file, sui filtri dei nomi dei file e sull'ora del giorno che preferisci per trasferire i dati. Per ottenere l'RPO che desideri, devi considerare i seguenti fattori:
Tasso di variazione. La quantità di dati generati o aggiornati per un determinato periodo di tempo. Maggiore è il tasso di variazione, più risorse sono necessarie per trasferire le modifiche alla destinazione in ogni periodo di trasferimento incrementale.
Rendimento dei trasferimenti. Il tempo necessario per trasferire i file. Per i trasferimenti di file di grandi dimensioni, questo valore è in genere determinato dalla larghezza di banda disponibile tra origine e destinazione. Tuttavia, se un job di trasferimento è costituito da un numero elevato di file di piccole dimensioni, QPS può diventare un fattore limitante. In questo caso, puoi pianificare più job simultanei per scalare le prestazioni, a condizione che sia disponibile una larghezza di banda sufficiente. Ti consigliamo di misurare il rendimento del trasferimento utilizzando un sottoinsieme rappresentativo dei tuoi dati reali.
Frequenza. L'intervallo tra i job di backup. L'aggiornamento dei dati nella destinazione è recente come l'ultima volta che è stato pianificato un job di trasferimento. Pertanto, è importante che gli intervalli tra i job di trasferimento successivi non siano più lunghi dell'obiettivo RPO. Ad esempio, se l'obiettivo RPO è 1 giorno, il job di trasferimento deve essere pianificato almeno una volta al giorno.
Monitoraggio e avvisi. Storage Transfer Service fornisce notifiche Pub/Sub su una varietà di eventi. Ti consigliamo di iscriverti a queste notifiche per gestire errori imprevisti o modifiche ai tempi di completamento dei job.
Backup e ripristino del database
Questo documento non ha lo scopo di descrivere in dettaglio i vari meccanismi di backup e ripristino integrati inclusi nei database di terze parti o le tecniche di backup e ripristino utilizzate su altri provider di servizi cloud. Se gestisci database non gestiti sui servizi di calcolo, puoi usufruire delle funzionalità di HA disponibili nel tuo fornitore di servizi cloud di produzione. Puoi estenderli per incorporare un deployment HA in Google Cloudo utilizzare Cloud Storage come destinazione finale per l'archiviazione a freddo dei file di backup del database.
Passaggi successivi
- Scopri di più su aree geografiche e regioni.Google Cloud
Leggi altri documenti di questa serie di RE:
- Guida alla pianificazione del ripristino di emergenza
- Componenti di base per il ripristino di emergenza
- Scenari di ripristino di emergenza per le applicazioni
- Progettazione ripristino di emergenza per i workload con limitazioni a livello di località
- Casi d'uso di ripristino di emergenza: applicazioni di analisi dei dati con limitazioni di località
- Progettazione ripristino di emergenza per interruzioni dell'infrastruttura cloud
- Architetture per l'alta affidabilità dei cluster MySQL su Compute Engine
Esplora architetture, diagrammi e best practice di riferimento su Google Cloud. Consulta il nostro Cloud Architecture Center.