Questo articolo fa parte di una serie che illustra il disaster recovery (RE) in Google Cloud. Questa parte descrive il processo di progettazione dei carichi di lavoro utilizzando Google Cloud e i componenti di base resilienti alle interruzioni dell'infrastruttura cloud.
La serie è composta dalle seguenti parti:
- Guida alla pianificazione del ripristino di emergenza
- Componenti di base per il ripristino di emergenza
- Scenari di ripristino di emergenza dei dati
- Scenari di ripristino di emergenza per le applicazioni
- Progettazione ripristino di emergenza per i workload con limitazioni a livello di località
- Casi d'uso di ripristino di emergenza: applicazioni di analisi dei dati con limitazioni di località
- Progettazione del ripristino di emergenza per interruzioni dell'infrastruttura cloud (questo documento)
Introduzione
Man mano che le aziende spostano i carichi di lavoro sul cloud pubblico, devono tradurre la loro comprensione della creazione di sistemi on-premise resilienti nell'infrastruttura hyperscale di fornitori di servizi cloud come Google Cloud. Questo articolo mappa i concetti standard del settore relativi al ripristino di emergenza, come RTO (Recovery Time Objective) e RPO (Recovery Point Objective), all'infrastruttura Google Cloud.
Le indicazioni contenute in questo documento seguono uno dei principi chiave di Google per ottenere una disponibilità del servizio estremamente elevata: pianificare gli errori. Sebbene Google Cloud offra un servizio estremamente affidabile, i disastri si verificheranno: catastrofi naturali, interruzioni della fibra e guasti complessi e imprevedibili dell'infrastruttura, che causano interruzioni. La pianificazione delle interruzioni consente ai clienti diGoogle Cloud creare applicazioni che funzionano in modo prevedibile durante questi eventi inevitabili, utilizzando prodotti con meccanismi di ripristino di emergenza "integrati" Google Cloud .
Il ripristino di emergenza è un argomento ampio che copre molto più dei guasti all'infrastruttura, come bug software o danneggiamento dei dati, e dovresti avere un piano end-to-end completo. Tuttavia, questo articolo si concentra su una parte di un piano diRER complessivo: come progettare applicazioni resilienti alle interruzioni dell'infrastruttura cloud. Nello specifico, questo articolo illustra:
- L'infrastruttura Google Cloud , come si manifestano gli eventi catastrofici come Google Cloud interruzioni e come Google Cloud è progettato per ridurre al minimo la frequenza e l'ambito delle interruzioni.
- Una guida alla pianificazione dell'architettura che fornisce un framework per classificare e progettare applicazioni in base ai risultati di affidabilità desiderati.
- Un elenco dettagliato di prodotti Google Cloud selezionati che offrono funzionalità di RE integrate che potresti voler utilizzare nella tua applicazione.
Per ulteriori dettagli sulla pianificazione generale RE e sull'utilizzo di Google Cloud come componente della tua strategia di RE on-premise, consulta la Guida alla pianificazione del disaster recovery. Inoltre, sebbene l'alta disponibilità sia un concetto strettamente correlato al ripristino di emergenza, non è trattato in questo articolo. Per ulteriori dettagli sulla progettazione per l'alta affidabilità, consulta il framework Well-Architected.
Una nota sulla terminologia: questo articolo si riferisce alla disponibilità quando discute della possibilità di accedere e utilizzare in modo significativo un prodotto nel tempo, mentre l'affidabilità si riferisce a un insieme di attributi che includono la disponibilità, ma anche elementi come la durata e la correttezza.
Come Google Cloud è progettato per la resilienza
Data center di Google
I data center tradizionali si basano sulla massimizzazione della disponibilità dei singoli componenti. Nel cloud, la scalabilità consente a operatori come Google di distribuire i servizi su molti componenti utilizzando tecnologie di virtualizzazione e superando così l'affidabilità tradizionale dei componenti. Ciò significa che puoi abbandonare la mentalità dell'architettura di affidabilità che ti preoccupava in locale. Anziché preoccuparti delle varie modalità di guasto dei componenti, come il raffreddamento e l'alimentazione, puoi pianificare in base ai Google Cloud prodotti e alle relative metriche di affidabilità dichiarate. Queste metriche riflettono il rischio di interruzione aggregato dell'intera infrastruttura sottostante. In questo modo, puoi concentrarti molto di più sulla progettazione, sul deployment e sulle operazioni delle applicazioni anziché sulla gestione dell'infrastruttura.
Google progetta la sua infrastruttura per soddisfare obiettivi di disponibilità aggressivi in base alla nostra vasta esperienza nella creazione e nella gestione di data center moderni. Google è un leader mondiale nella progettazione di data center. Dall'alimentazione al raffreddamento alle reti, ogni tecnologia del data center ha le proprie ridondanze e mitigazioni, inclusi i piani FMEA. I data center di Google sono costruiti in modo da bilanciare questi numerosi rischi diversi e presentare ai clienti un livello di disponibilità previsto coerente per i prodotti Google Cloud . Google utilizza la propria esperienza per modellare la disponibilità dell'architettura complessiva del sistema fisico e logico per garantire che la progettazione del data center soddisfi le aspettative. Gli ingegneri di Google si impegnano molto a livello operativo per contribuire a garantire che queste aspettative vengano soddisfatte. La disponibilità effettiva misurata supera normalmente i nostri obiettivi di progettazione di un margine confortevole.
Riassumendo tutti questi rischi e mitigazioni dei data center in prodotti rivolti agli utenti, Google Cloud ti esonera da queste responsabilità di progettazione e operative. Puoi invece concentrarti sull'affidabilità progettata per le regioni e le zoneGoogle Cloud .
Regioni e zone
Le regioni sono aree geografiche indipendenti costituite da zone. Zone e regioni sono astrazioni logiche delle risorse fisiche sottostanti. Per saperne di più sulle considerazioni specifiche per le regioni, consulta Area geografica e regioni.
I prodottiGoogle Cloud sono suddivisi in risorse a livello di zona, risorse regionali o risorse multiregionali.
Le risorse di zona sono ospitate all'interno di una singola zona. Un'interruzione del servizio in quella zona può influire su tutte le risorse al suo interno. Ad esempio, un'istanza Compute Engine viene eseguita in una singola zona specificata; se un guasto hardware interrompe il servizio in quella zona, l'istanza Compute Engine non è disponibile per la durata dell'interruzione.
Le risorse regionali vengono distribuite in modo ridondante in più zone all'interno di una regione. Ciò offre loro una maggiore affidabilità rispetto alle risorse di zona.
Le risorse multiregionali sono distribuite all'interno e tra le regioni. In generale, le risorse multiregionali hanno un'affidabilità maggiore rispetto a quelle regionali. Tuttavia, a questo livello i prodotti devono ottimizzare la disponibilità, le prestazioni e l'efficienza delle risorse. Di conseguenza, è importante comprendere i compromessi fatti da ogni prodotto multiregionale che decidi di utilizzare. Questi compromessi sono documentati in base al prodotto più avanti in questo documento.
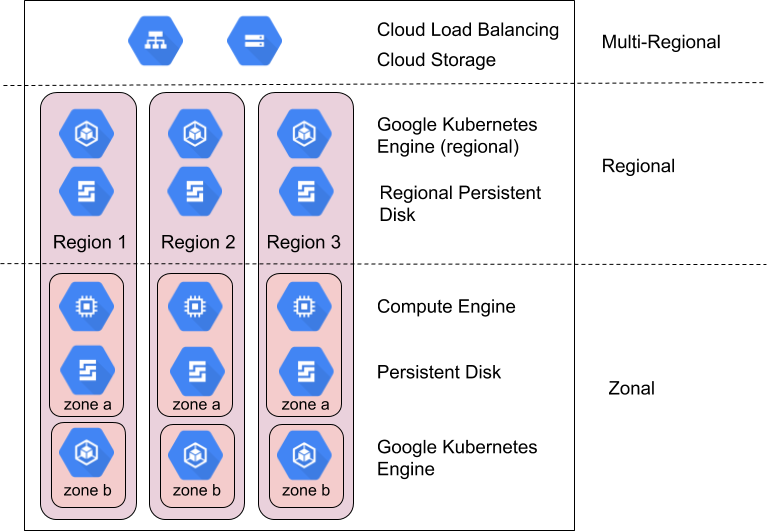
Come sfruttare zone e regioni per ottenere affidabilità
Gli SRE di Google gestiscono e scalano prodotti per utenti globali altamente affidabili come Gmail e la Ricerca attraverso una serie di tecniche e tecnologie che sfruttano in modo ottimale l'infrastruttura di computing in tutto il mondo. Ciò include il reindirizzamento del traffico dalle località non disponibili utilizzando il bilanciamento del carico globale, l'esecuzione di più repliche in molte località in tutto il mondo e la replica dei dati tra le località. Queste stesse funzionalità sono disponibili per i clienti Google Cloud tramite prodotti come Cloud Load Balancing, Google Kubernetes Engine (GKE) e Spanner.
Google Cloud progetta generalmente i prodotti per offrire i seguenti livelli di disponibilità per zone e regioni:
| Risorsa | Esempi | Obiettivo di progettazione della disponibilità | Tempo di inattività implicito |
|---|---|---|---|
| A livello di zona | Compute Engine, Persistent Disk | 99,9% | 8,75 ore / anno |
| Regionale | Cloud Storage regionale, Persistent Disk replicato, GKE regionale | 99,99% | 52 minuti / anno |
Confronta gli obiettivi di progettazione della disponibilità di Google Cloud con il livello di downtime accettabile per identificare le risorse Google Cloud appropriate. Mentre i progetti tradizionali si concentrano sul miglioramento della disponibilità a livello di componente per migliorare la disponibilità dell'applicazione risultante, i modelli cloud si concentrano invece sulla composizione dei componenti per raggiungere questo obiettivo. Molti prodotti all'interno di Google Cloud utilizzano questa tecnica. Ad esempio, Spanner offre un database multiregionale che comprende più regioni per garantire una disponibilità del 99,999%.
La composizione è importante perché, senza di essa, la disponibilità dell'applicazione non può superare quella dei Google Cloud prodotti che utilizzi; infatti, a meno che la tua applicazione non abbia mai esito negativo, avrà una disponibilità inferiore rispetto ai Google Cloud prodotti sottostanti. Il resto di questa sezione mostra in generale come utilizzare una composizione di prodotti zonali e regionali per ottenere una disponibilità delle applicazioni superiore a quella che fornirebbe una singola zona o regione. La sezione successiva fornisce una guida pratica per applicare questi principi alle tue applicazioni.
Pianificazione degli ambiti di interruzione del servizio a livello di zona
Gli errori dell'infrastruttura di solito causano interruzioni del servizio in una singola zona. All'interno di una regione, le zone sono progettate per ridurre al minimo il rischio di errori correlati con altre zone e un'interruzione del servizio in una zona di solito non influisce sul servizio di un'altra zona nella stessa regione. Un'interruzione limitata a una zona non significa necessariamente che l'intera zona non è disponibile, ma definisce solo il confine dell'incidente. È possibile che un'interruzione a livello di zona non abbia effetti tangibili sulle tue risorse specifiche in quella zona.
È un evento più raro, ma è anche fondamentale notare che più zone alla fine subiranno comunque un'interruzione correlata a un certo punto all'interno di una singola regione. Quando si verifica un'interruzione in due o più zone, si applica la strategia di ambito dell'interruzione regionale riportata di seguito.
Le risorse regionali sono progettate per resistere alle interruzioni di zona fornendo il servizio da una composizione di più zone. Se una delle zone che supportano una risorsa di regione viene interrotta, la risorsa si rende automaticamente disponibile da un'altra zona. Per ulteriori dettagli, controlla attentamente la descrizione della funzionalità del prodotto nell'appendice.
Google Cloud offre solo alcune risorse di zona, ovvero macchine virtuali (VM) Compute Engine e Persistent Disk. Se prevedi di utilizzare risorse zonali, dovrai eseguire la composizione delle risorse progettando, creando e testando il failover e il ripristino tra le risorse zonali situate in più zone. Alcune strategie includono:
- Instradamento rapido del traffico alle macchine virtuali in un'altra zona utilizzando Cloud Load Balancing quando un controllo di integrità determina che una zona sta riscontrando problemi.
- Utilizza i modelli di istanza Compute Engine e/o i gruppi di istanze gestite per eseguire e scalare istanze VM identiche in più zone.
- Utilizza un Persistent Disk regionale per replicare in modo sincrono i dati in un'altra zona di una regione. Per ulteriori dettagli, consulta Opzioni di alta affidabilità utilizzando i dischi permanenti regionali.
Pianificazione degli ambiti di interruzione regionali
Un'interruzione regionale è un'interruzione del servizio che interessa più di una zona in una singola regione. Si tratta di interruzioni su larga scala, meno frequenti e che possono essere causate da catastrofi naturali o guasti su larga scala dell'infrastruttura.
Per un prodotto regionale progettato per fornire una disponibilità del 99,99%, un'interruzione può comunque tradursi in quasi un'ora di inattività per un determinato prodotto ogni anno. Pertanto, le tue applicazioni critiche potrebbero richiedere un piano di RE multiregionale se questa durata dell'interruzione non è accettabile.
Le risorse multiregionali sono progettate per resistere alle interruzioni a livello di regione fornendo il servizio da più regioni. Come descritto sopra, i prodotti multiregionali trovano un compromesso tra latenza, coerenza e costi. Il compromesso più comune riguarda la replica dei dati sincrona e asincrona. La replica asincrona offre una latenza inferiore a costo del rischio di perdita di dati durante un'interruzione. Pertanto, è importante controllare la descrizione delle funzionalità del prodotto nell'appendice per ulteriori dettagli.
Se vuoi utilizzare risorse regionali e rimanere resiliente alle interruzioni regionali, devi eseguire la composizione delle risorse progettando, creando e testando il failover e il ripristino tra le risorse regionali situate in più regioni. Oltre alle strategie zonali descritte sopra, che puoi applicare anche a più regioni, considera:
- Le risorse regionali devono replicare i dati in una regione secondaria, in un'opzione di archiviazione multiregionale come Cloud Storage o in un'opzione di cloud ibrido come GKE e Google Distributed Cloud.
- Dopo aver implementato una mitigazione delle interruzioni regionali, testala regolarmente. Non c'è niente di peggio che pensare di essere resistenti a un'interruzione di una singola regione e scoprire che non è così quando si verifica realmente.
Google Cloud Approccio alla resilienza e alla disponibilità
Google Cloud supera regolarmente i target di progettazione della disponibilità, ma non devi presumere che questo solido rendimento passato sia la disponibilità minima che puoi progettare. In alternativa, devi selezionare Google Cloud dipendenze i cui target "Progettato per" superano l'affidabilità prevista della tua applicazione, in modo che il tempo di inattività della tua applicazione più il tempo di inattività Google Cloud fornisca il risultato che stai cercando.
Un sistema ben progettato può rispondere alla domanda: "Cosa succede quando una zona o regione subisce un'interruzione di 1, 5, 10 o 30 minuti?" Questo aspetto deve essere preso in considerazione a molti livelli, tra cui:
- Cosa sperimenteranno i miei clienti durante un'interruzione?
- Come faccio a rilevare un'interruzione?
- Cosa succede alla mia applicazione durante un'interruzione?
- Cosa succede ai miei dati durante un'interruzione?
- Che cosa succede alle mie altre applicazioni a causa di un'interruzione (dovuta a dipendenze incrociate)?
- Che cosa devo fare per eseguire il recupero dopo la risoluzione di un'interruzione? Chi lo fa?
- Chi devo informare di un'interruzione e entro quale periodo di tempo?
Guida passo passo alla progettazione del ripristino di emergenza per le applicazioni in Google Cloud
Le sezioni precedenti hanno illustrato come Google crea l'infrastruttura cloud e alcuni approcci per gestire le interruzioni zonali e regionali.
Questa sezione ti aiuta a sviluppare un framework per applicare il principio di composizione alle tue applicazioni in base ai risultati di affidabilità che desideri.
Le applicazioni dei clienti in Google Cloud che hanno come target obiettivi di ripristino di emergenza come RTO e RPO devono essere progettate in modo che le operazioni business-critical, soggette a RTO/RPO, abbiano dipendenze solo dai componenti del data plane responsabili dell'elaborazione continua delle operazioni per il servizio. In altre parole, queste operazioni business critical dei clienti non devono dipendere dalle operazioni del management plane, che gestiscono lo stato della configurazione e la inviano al control plane e al data plane.
Ad esempio, Google Cloud i clienti che intendono raggiungere l'RTO per operazioni business-critical non devono dipendere da un'API di creazione di VM o dall'aggiornamento di un'autorizzazione IAM.
Passaggio 1: raccogli i requisiti esistenti
Il primo passaggio consiste nel definire i requisiti di disponibilità per le tue applicazioni. La maggior parte delle aziende ha già un certo livello di linee guida di progettazione in questo spazio, che possono essere sviluppate internamente o derivare da normative o altri requisiti legali. Queste linee guida di progettazione sono normalmente codificate in due metriche chiave: Recovery Time Objective (RTO) e Recovery Point Objective (RPO). In termini aziendali, RTO si traduce in "Quanto tempo dopo un disastro prima che io sia di nuovo operativo". L'RPO si traduce in "Quanti dati posso permettermi di perdere in caso di disastro".

Storicamente, le aziende hanno definito i requisiti RTO e RPO per un'ampia gamma di eventi di emergenza, dai guasti dei componenti ai terremoti. Ciò aveva senso nel mondo on-premise, in cui i pianificatori dovevano mappare i requisiti RTO/RPO nell'intero stack software e hardware. Nel cloud, non è più necessario definire i requisiti in modo così dettagliato perché se ne occupa il provider. Puoi invece definire i requisiti RTO e RPO in termini di ambito della perdita (intere zone o regioni) senza specificare i motivi sottostanti. Per Google Cloud questo motivo, la raccolta dei requisiti viene semplificata in tre scenari: un'interruzione a livello di zona, un'interruzione a livello di regione o l'interruzione estremamente improbabile di più regioni.
Poiché non tutte le applicazioni hanno la stessa criticità, la maggior parte dei clienti le classifica in livelli di criticità a cui può essere applicato un requisito RTO/RPO specifico. Se presi insieme, RTO/RPO e criticità dell'applicazione semplificano il processo di progettazione di una determinata applicazione rispondendo a:
- L'applicazione deve essere eseguita in più zone nella stessa regione o in più zone in più regioni?
- Da quali prodotti Google Cloud può dipendere l'applicazione?
Questo è un esempio dell'output dell'esercizio di raccolta dei requisiti:
RTO e RPO per criticità dell'applicazione per l'organizzazione di esempio Co:
| Criticità dell'applicazione | % di app | Esempi di app | Interruzione della zona | Interruzione a livello di regione |
|---|---|---|---|---|
| Livello 1
(più importante) |
5% | In genere applicazioni globali o esterne rivolte ai clienti, come pagamenti in tempo reale e vetrine e-commerce. | RTO Zero
RPO Zero |
RTO Zero
RPO Zero |
| Livello 2 | 35% | In genere applicazioni regionali o applicazioni interne importanti, come CRM o ERP. | RTO 15 minuti
RPO 15 minuti |
RTO 1 ora
RPO 1 ora |
| Livello 3
(meno importante) |
60% | In genere applicazioni di team o di reparto, come back office, prenotazione di ferie, viaggi interni, contabilità e RU. | RTO 1 ora
RPO 1 ora |
RTO 12 ore
RPO 12 ore |
Passaggio 2: mappatura delle funzionalità ai prodotti disponibili
Il secondo passaggio consiste nel comprendere le funzionalità di resilienza dei prodotti Google Cloud che verranno utilizzati dalle tue applicazioni. La maggior parte delle aziende esamina le informazioni sui prodotti pertinenti e poi aggiunge indicazioni su come modificare le architetture per colmare eventuali lacune tra le funzionalità del prodotto e i requisiti di resilienza. Questa sezione tratta alcune aree comuni e consigli sulle limitazioni di dati e applicazioni in questo spazio.
Come accennato in precedenza, i prodotti di Google con funzionalità di RE sono pensati per due tipi di ambiti di interruzione: regionale e di zona. I disservizi parziali devono essere pianificati allo stesso modo di un disservizio completo in termini diRER. In questo modo si ottiene una matrice iniziale di alto livello dei prodotti adatti a ogni scenario per impostazione predefinita:
Google Cloud Funzionalità generali del prodotto
(vedi l'appendice per le funzionalità specifiche del prodotto)
| Tutti i prodotti Google Cloud | Prodotti Google Cloud regionali con replica automatica tra le zone | Prodotti multiregionali o globali Google Cloud con replica automatica tra le regioni | |
|---|---|---|---|
| Guasto di un componente all'interno di una zona | Coperto* | Con copertura | Con copertura |
| Interruzione della zona | Non inclusi | Con copertura | Con copertura |
| Interruzione a livello di regione | Non inclusi | Non inclusi | Con copertura |
* Tutti Google Cloud i prodotti sono resistenti al guasto dei componenti, tranne in casi specifici indicati nella documentazione del prodotto. Si tratta in genere di scenari in cui il prodotto offre accesso diretto o mappatura statica a un componente hardware specializzato come memoria o unità a stato solido (SSD).
In che modo RPO limita le scelte di prodotto
Nella maggior parte delle implementazioni cloud, l'integrità dei dati è l'aspetto architettonico più significativo da considerare per un servizio. Almeno alcune applicazioni hanno un requisito RPO pari a zero, il che significa che non deve verificarsi alcuna perdita di dati in caso di interruzione. In genere, ciò richiede la replica sincrona dei dati in un'altra zona o regione. La replica sincrona presenta compromessi in termini di costi e latenza, pertanto, mentre molti prodotti forniscono la replica sincrona tra zone, solo alcuni la forniscono tra regioni. Google Cloud Questo compromesso tra costi e complessità significa che non è insolito che diversi tipi di dati all'interno di un'applicazione abbiano valori RPO diversi.
Per i dati con un RPO maggiore di zero, le applicazioni possono sfruttare la replica asincrona. La replica asincrona è accettabile quando i dati persi possono essere ricreati facilmente o recuperati da un'origine dati di riferimento se necessario. Può anche essere una scelta ragionevole quando una piccola perdita di dati è un compromesso accettabile nel contesto delle durate previste di interruzione zonale e regionale. È anche importante notare che durante un'interruzione temporanea, i dati scritti nella località interessata ma non ancora replicati in un'altra località diventano generalmente disponibili dopo la risoluzione dell'interruzione. Ciò significa che il rischio di perdita di dati permanente è inferiore al rischio di perdere l'accesso ai dati durante un'interruzione.
Azioni chiave:stabilisci se hai assolutamente bisogno di RPO zero e, in caso affermativo, se puoi farlo per un sottoinsieme dei tuoi dati. In questo modo, aumenterà notevolmente la gamma di servizi abilitati per il RE a tua disposizione. In Google Cloud, ottenere un RPO pari a zero significa utilizzare prevalentemente prodotti regionali per la tua applicazione, che per impostazione predefinita sono resilienti alle interruzioni a livello di zona, ma non a livello di regione.
In che modo i limiti RTO limitano le scelte di prodotto
Uno dei principali vantaggi del cloud computing è la possibilità di eseguire il deployment dell'infrastruttura on demand. Tuttavia, non si tratta di un deployment istantaneo. Il valore RTO per la tua applicazione deve tenere conto dell'RTO combinato dei prodotti Google Cloud utilizzati dall'applicazione e di qualsiasi azione che i tuoi ingegneri o SRE devono intraprendere per riavviare le VM o i componenti dell'applicazione. Un RTO misurato in minuti significa progettare un'applicazione che recuperi automaticamente da un disastro senza intervento umano o con passaggi minimi, ad esempio premendo un pulsante per il failover. Il costo e la complessità di questo tipo di sistema sono sempre stati molto elevati, ma i prodotti Google Cloud come i bilanciatori del carico e i gruppi di istanze rendono questo design molto più economico e semplice. Pertanto, devi prendere in considerazione il failover e il ripristino automatici per la maggior parte delle applicazioni. Tieni presente che la progettazione di un sistema per questo tipo di failover attivo tra regioni è complessa e costosa; solo una piccolissima parte dei servizi critici giustifica questa funzionalità.
La maggior parte delle applicazioni avrà un RTO compreso tra un'ora e un giorno, il che consente un failover caldo in uno scenario di emergenza, con alcuni componenti dell'applicazione in esecuzione in modalità standby, come i database, mentre altri vengono scalati in caso di emergenza reale, come i server web. Per queste applicazioni, ti consigliamo vivamente di prendere in considerazione l'automazione per gli eventi di scalabilità orizzontale. I servizi con un RTO superiore a un giorno hanno la criticità più bassa e spesso possono essere ripristinati da un backup o ricreati da zero.
Azioni chiave: stabilisci se hai assolutamente bisogno di un RTO pari a (quasi) zero per il failover regionale e, in caso affermativo, se puoi farlo per un sottoinsieme dei tuoi servizi. In questo modo, cambiano i costi di esecuzione e manutenzione del servizio.
Passaggio 3: sviluppa le tue architetture di riferimento e guide
Il passaggio finale consigliato è la creazione di pattern di architettura specifici per la tua azienda per aiutare i tuoi team a standardizzare il loro approccio alripristino di emergenzay. La maggior parte dei clienti Google Cloud produce una guida per i propri team di sviluppo che abbina le proprie aspettative individuali di resilienza aziendale alle due principali categorie di scenari di interruzione su Google Cloud. In questo modo, i team possono classificare facilmente i prodotti abilitati al RE in base al livello di criticità.
Creare linee guida per i prodotti
Se esaminiamo di nuovo la tabella RTO/RPO di esempio riportata sopra, abbiamo una guida ipotetica che elenca i prodotti consentiti per impostazione predefinita per ogni livello di criticità. Tieni presente che, laddove alcuni prodotti sono stati identificati come non adatti per impostazione predefinita, puoi sempre aggiungere i tuoi meccanismi di replica e failover per attivare la sincronizzazione tra zone o regioni, ma questo esercizio non rientra nell'ambito di questo articolo. Le tabelle contengono anche link a ulteriori informazioni su ciascun prodotto per aiutarti a comprenderne le funzionalità in relazione alla gestione delle interruzioni di zona o regione.
Modelli di architettura di esempio per l'organizzazione di esempio Co. - Interruzione della zona Resilienza
| Google Cloud Prodotto | Il prodotto soddisfa i requisiti di interruzione zonale per l'organizzazione di esempio (con la configurazione del prodotto appropriata) | ||
|---|---|---|---|
| Livello 1 | Livello 2 | Livello 3 | |
| Compute Engine | No | No | No |
| Dataflow | No | No | No |
| BigQuery | No | No | Sì |
| GKE | Sì | Sì | Sì |
| Cloud Storage | Sì | Sì | Sì |
| Cloud SQL | No | Sì | Sì |
| Spanner | Sì | Sì | Sì |
| Cloud Load Balancing | Sì | Sì | Sì |
Questa tabella è solo un esempio basato sui livelli ipotetici mostrati sopra.
Modelli di architettura di esempio per l'organizzazione di esempio Co: resilienza alle interruzioni della regione
| Google Cloud Prodotto | Il prodotto soddisfa i requisiti di interruzione del servizio per regione per l'organizzazione di esempio (con la configurazione del prodotto appropriata) | ||
|---|---|---|---|
| Livello 1 | Livello 2 | Livello 3 | |
| Compute Engine | Sì | Sì | Sì |
| Dataflow | No | No | No |
| BigQuery | No | No | Sì |
| GKE | Sì | Sì | Sì |
| Cloud Storage | No | No | No |
| Cloud SQL | No | Sì | Sì |
| Spanner | Sì | Sì | Sì |
| Cloud Load Balancing | Sì | Sì | Sì |
Questa tabella è solo un esempio basato sui livelli ipotetici mostrati sopra.
Per mostrare come verrebbero utilizzati questi prodotti, le sezioni seguenti descrivono alcune architetture di riferimento per ciascuno dei livelli di criticità ipotetici dell'applicazione. Si tratta di descrizioni di alto livello per illustrare le decisioni architetturali chiave e non sono rappresentative di una progettazione completa della soluzione.
Architettura di esempio di livello 3
| Criticità dell'applicazione | Interruzione della zona | Interruzione a livello di regione |
|---|---|---|
| Livello 3 (meno importante) |
RTO 12 ore RPO 24 ore |
RTO 28 giorni RPO 24 ore |
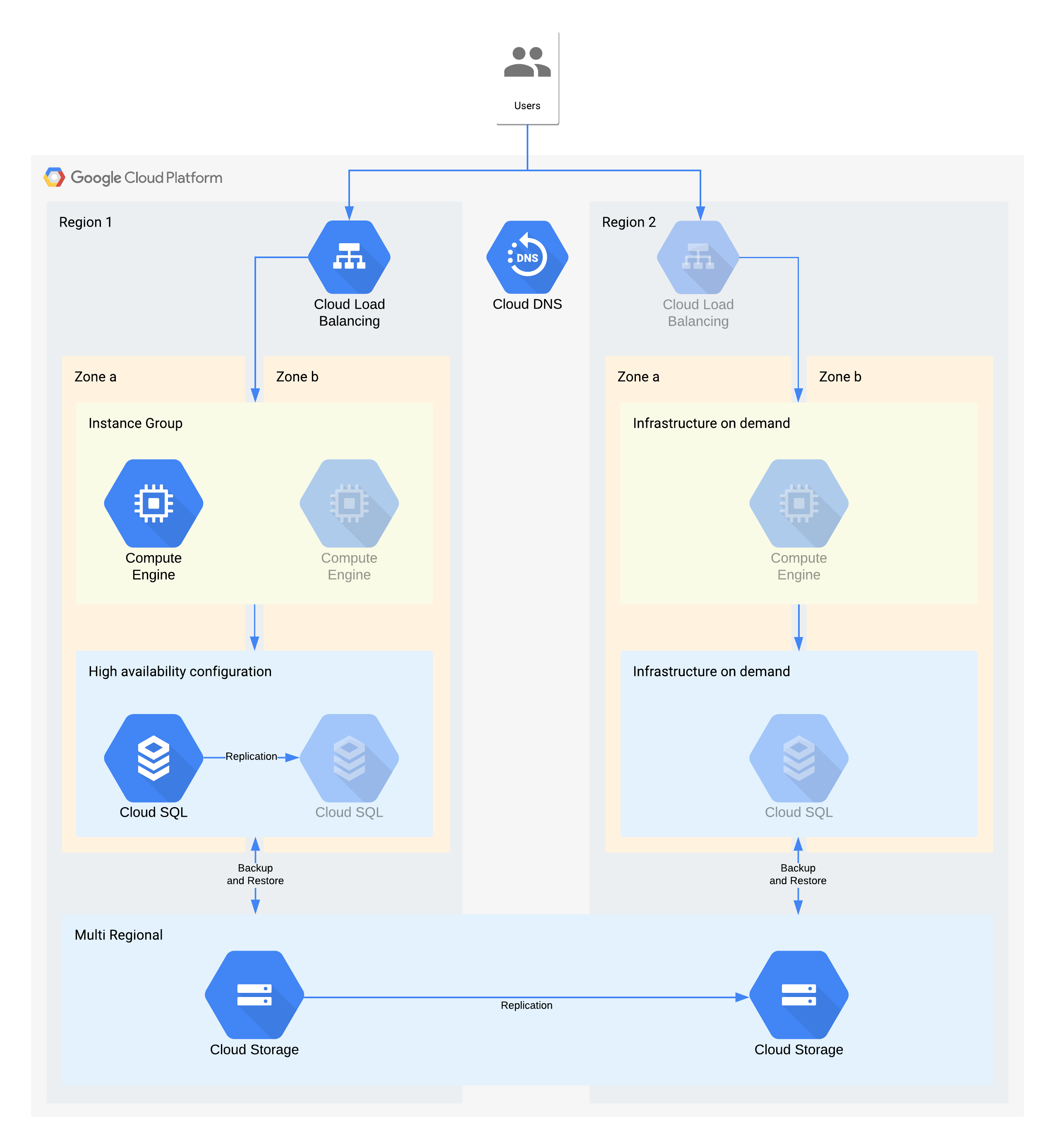
(Le icone in grigio indicano l'infrastruttura da attivare per il recupero)
Questa architettura descrive una tradizionale applicazione client/server: gli utenti interni si connettono a un'applicazione in esecuzione su un'istanza di calcolo supportata da un database per l'archiviazione permanente.
È importante notare che questa architettura supporta valori RTO e RPO migliori di quelli richiesti. Tuttavia, dovresti anche valutare l'eliminazione di passaggi manuali aggiuntivi quando potrebbero rivelarsi costosi o inaffidabili. Ad esempio, il recupero di un database da un backup notturno potrebbe supportare l'RPO di 24 ore, ma in genere è necessario un professionista esperto come un amministratore di database, che potrebbe non essere disponibile, soprattutto se più servizi sono stati interessati contemporaneamente. Con l'infrastruttura on demand di Google Cloud, puoi creare questa funzionalità senza dover scendere a compromessi sui costi e quindi questa architettura utilizza Cloud SQL HA anziché un backup/ripristino manuale per le interruzioni zonali.
Decisioni architetturali chiave per l'interruzione di zona: RTO di 12 ore e RPO di 24 ore:
- Un bilanciatore del carico interno viene utilizzato per fornire un punto di accesso scalabile per gli utenti, che consente il failover automatico in un'altra zona. Anche se il RTO è di 12 ore, le modifiche manuali agli indirizzi IP o persino gli aggiornamenti DNS possono richiedere più tempo del previsto.
- Un gruppo di istanze gestite a livello di regione è configurato con più zone, ma risorse minime. Questa opzione ottimizza i costi, ma consente comunque di scalare rapidamente le macchine virtuali nella zona di backup.
- Una configurazione Cloud SQL ad alta disponibilità prevede il failover automatico in un'altra zona. I database sono molto più difficili da ricreare e ripristinare rispetto alle macchine virtuali di Compute Engine.
Decisioni architetturali chiave per l'interruzione della regione: RTO di 28 giorni e RPO di 24 ore:
- Un bilanciatore del carico verrebbe costruito nella regione 2 solo in caso di interruzione a livello di regione. Cloud DNS viene utilizzato per fornire una funzionalità di failover regionale orchestrata ma manuale, poiché l'infrastruttura nella regione 2 sarebbe disponibile solo in caso di interruzione del servizio nella regione.
- Un nuovo gruppo di istanze gestite verrebbe creato solo in caso di interruzione della regione. In questo modo si ottimizzano i costi ed è improbabile che venga richiamato, data la breve durata della maggior parte delle interruzioni regionali. Tieni presente che, per semplicità, il diagramma non mostra gli strumenti associati necessari per il nuovo deployment o la copia delle immagini Compute Engine necessarie.
- Verrà ricreata una nuova istanza Cloud SQL e i dati verranno ripristinati da un backup. Anche in questo caso, il rischio di un'interruzione prolungata di una regione è estremamente basso, quindi si tratta di un altro compromesso per l'ottimizzazione dei costi.
- Cloud Storage multiregionale viene utilizzato per archiviare questi backup. In questo modo si ottiene la resilienza automatica a livello di zona e regione entro l'RTO e l'RPO.
Architettura di esempio di livello 2
| Criticità dell'applicazione | Interruzione della zona | Interruzione a livello di regione |
|---|---|---|
| Livello 2 | RTO 4 ore RPO zero |
RTO 24 ore RPO 4 ore |
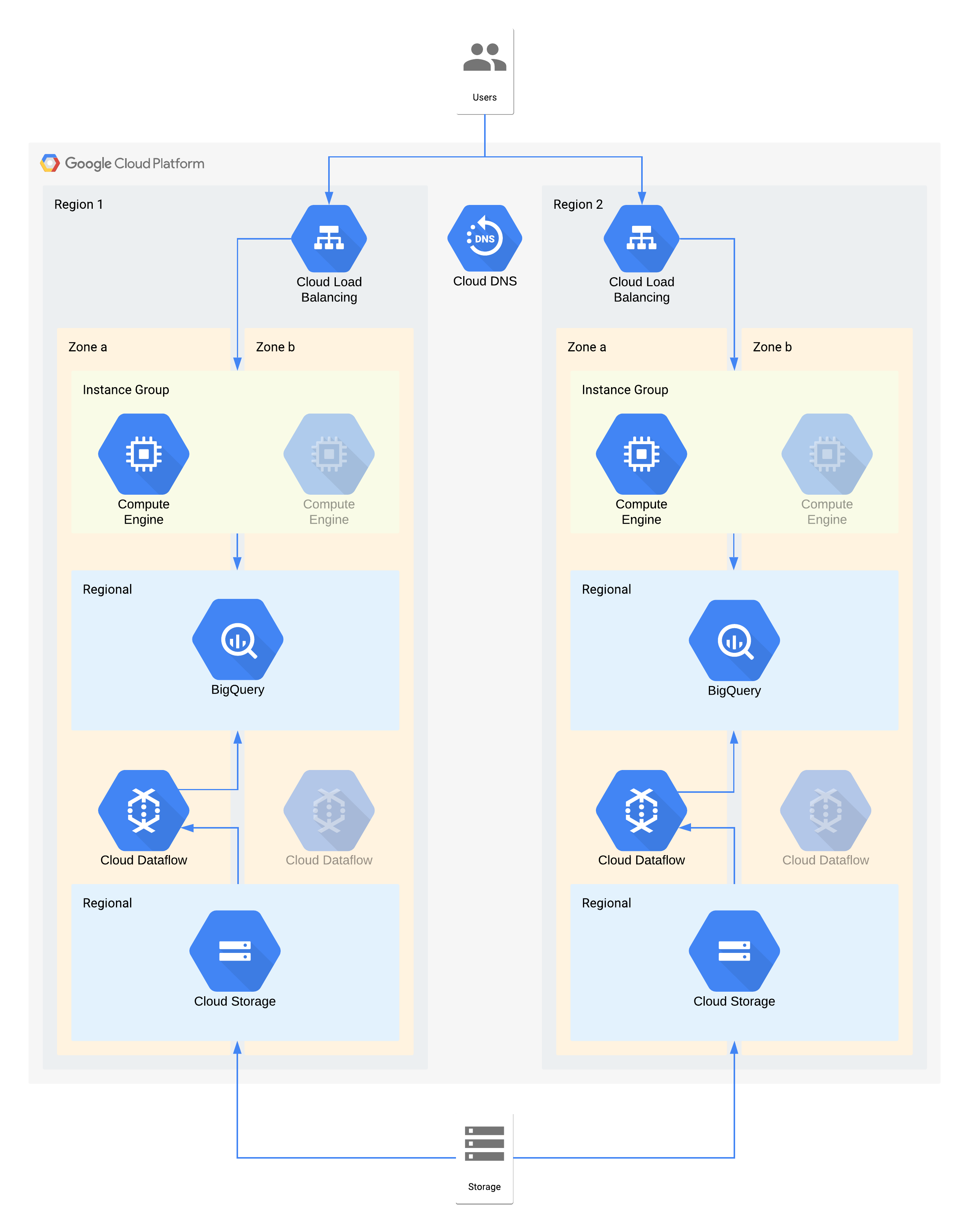
Questa architettura descrive un data warehouse con utenti interni che si connettono a un livello di visualizzazione dell'istanza di calcolo e a un livello di importazione e trasformazione dei dati che popola il data warehouse di backend.
Alcuni singoli componenti di questa architettura non supportano direttamente l'RPO richiesto per il loro livello. Tuttavia, a causa del modo in cui vengono utilizzati insieme, il servizio complessivo soddisfa l'RPO. In questo caso, poiché Dataflow è un prodotto zonale, segui i consigli per la progettazione ad alta disponibilità per evitare la perdita di dati durante un'interruzione. Tuttavia, il livello Cloud Storage è l'origine principale di questi dati e supporta un RPO di zero. Di conseguenza, puoi reimportare i dati persi in BigQuery utilizzando la zona b in caso di interruzione nella zona a.
Decisioni architetturali chiave per l'interruzione di zona: RTO di 4 ore e RPO pari a zero:
- Un bilanciatore del carico viene utilizzato per fornire un punto di accesso scalabile per gli utenti, che consente il failover automatico in un'altra zona. Anche se il RTO è di 4 ore, le modifiche manuali agli indirizzi IP o persino gli aggiornamenti DNS possono richiedere più tempo del previsto.
- Un gruppo di istanze gestite a livello di regione per il livello di calcolo della visualizzazione dei dati è configurato con più zone ma risorse minime. Questa opzione è ottimizzata per i costi, ma consente comunque di scalare rapidamente le macchine virtuali.
- Cloud Storage regionale viene utilizzato come livello di gestione temporanea per l'importazione iniziale dei dati, fornendo resilienza automatica della zona.
- Dataflow viene utilizzato per estrarre i dati da Cloud Storage e trasformarli prima di caricarli in BigQuery. In caso di interruzione a livello di zona, si tratta di un processo stateless che può essere riavviato in un'altra zona.
- BigQuery fornisce il backend del data warehouse per il front-end di visualizzazione dei dati. In caso di interruzione di una zona, tutti i dati persi verranno reingestiti da Cloud Storage.
Decisioni architetturali chiave per l'interruzione della regione: RTO di 24 ore e RPO di 4 ore:
- Un bilanciatore del carico in ogni regione viene utilizzato per fornire un punto di accesso scalabile per gli utenti. Cloud DNS viene utilizzato per fornire una funzionalità di failover regionale orchestrata ma manuale, poiché l'infrastruttura nella regione 2 sarebbe resa disponibile solo in caso di interruzione della regione.
- Un gruppo di istanze gestite a livello di regione per il livello di calcolo della visualizzazione dei dati è configurato con più zone ma risorse minime. Non è accessibile finché il bilanciatore del carico non viene riconfigurato, ma non richiede altrimenti un intervento manuale.
- Cloud Storage regionale viene utilizzato come livello di gestione temporanea per l'importazione iniziale dei dati. Viene caricato contemporaneamente in entrambe le regioni per soddisfare i requisiti RPO.
- Dataflow viene utilizzato per estrarre i dati da Cloud Storage e trasformarli prima di caricarli in BigQuery. In caso di interruzione della regione, BigQuery verrà compilato con i dati più recenti di Cloud Storage.
- BigQuery fornisce il backend del data warehouse. Durante il normale funzionamento, questo valore viene aggiornato a intervalli regolari. In caso di interruzione di una regione, i dati più recenti verranno re-importati tramite Dataflow da Cloud Storage.
Architettura di esempio di livello 1
| Criticità dell'applicazione | Interruzione della zona | Interruzione a livello di regione |
|---|---|---|
| Livello 1 (il più importante) |
RTO zero RPO zero |
RTO 4 ore RPO 1 ora |
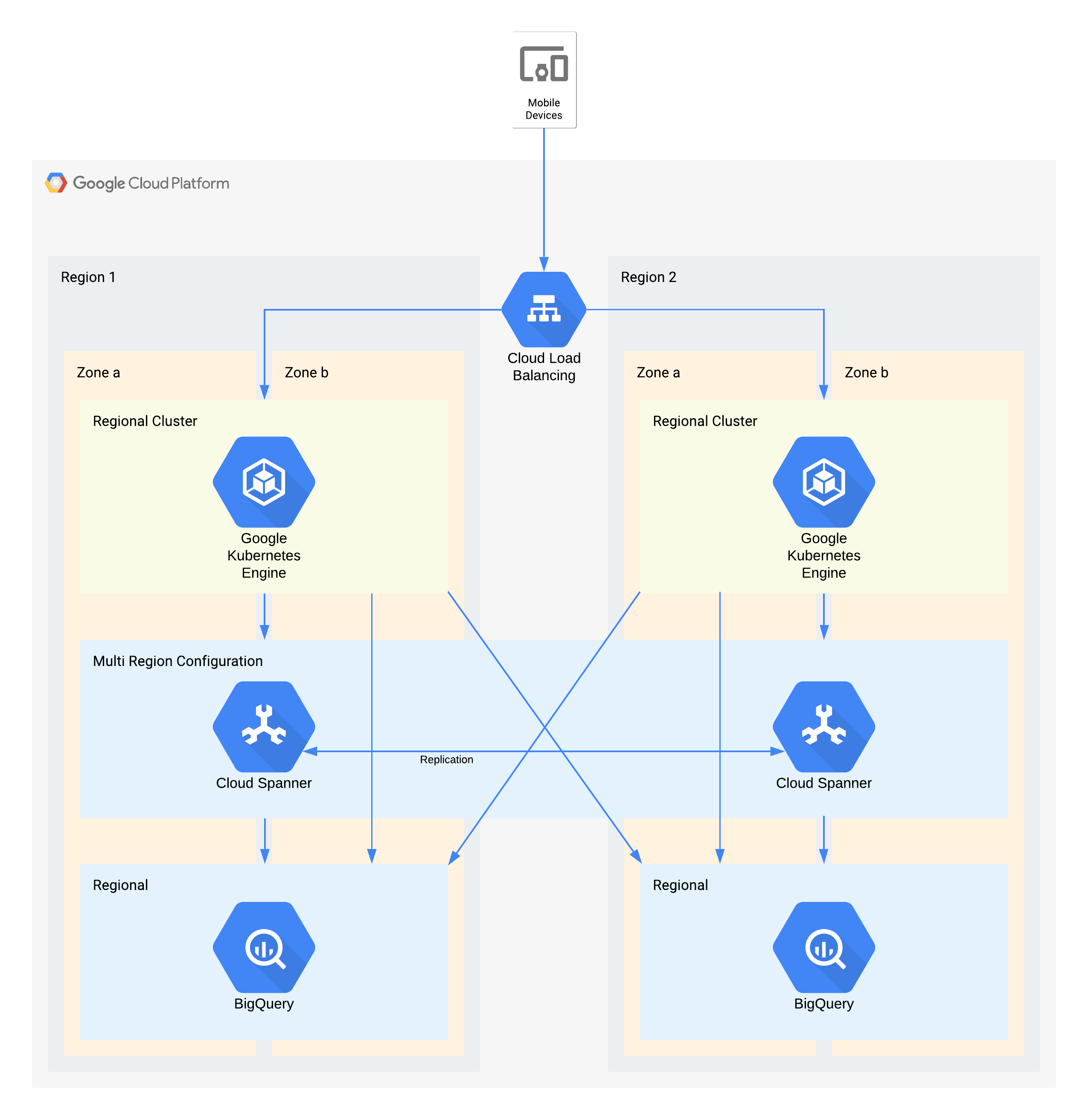
Questa architettura descrive un'infrastruttura di backend di app mobile con utenti esterni che si connettono a un insieme di microservizi in esecuzione in GKE. Spanner fornisce il livello di archiviazione dei dati di backend per i dati in tempo reale e i dati storici vengono trasmessi in streaming a un data lake BigQuery in ogni regione.
Anche in questo caso, alcuni singoli componenti di questa architettura non supportano direttamente l'RPO richiesto per il loro livello, ma grazie al modo in cui vengono utilizzati insieme il servizio complessivo lo supporta. In questo caso, BigQuery viene utilizzato per le query analitiche. Ogni regione viene alimentata contemporaneamente da Spanner.
Decisioni architetturali chiave per l'interruzione di zona: RTO pari a zero e RPO pari a zero:
- Un bilanciatore del carico viene utilizzato per fornire un punto di accesso scalabile per gli utenti, che consente il failover automatico in un'altra zona.
- Un cluster GKE regionale viene utilizzato per il livello applicazione, configurato con più zone. In questo modo si ottiene un RTO pari a zero in ogni regione.
- Spanner multiregionale viene utilizzato come livello di persistenza dei dati, fornendo resilienza automatica dei dati di zona e coerenza delle transazioni.
- BigQuery fornisce la funzionalità di analisi per l'applicazione. Ogni regione riceve i dati in modo indipendente da Spanner e l'applicazione vi accede in modo indipendente.
Decisioni architetturali chiave per l'interruzione della regione: RTO di 4 ore e RPO di 1 ora:
- Un bilanciatore del carico viene utilizzato per fornire un punto di accesso scalabile per gli utenti, che consente il failover automatico in un'altra regione.
- Un cluster GKE regionale viene utilizzato per il livello applicazione, configurato con più zone. In caso di interruzione di una regione, il cluster nella regione alternativa viene scalato automaticamente per gestire il carico di elaborazione aggiuntivo.
- Spanner multiregionale viene utilizzato come livello di persistenza dei dati, fornendo resilienza automatica dei dati regionali e coerenza delle transazioni. Questo è il componente chiave per raggiungere l'RPO tra regioni di 1 ora.
- BigQuery fornisce la funzionalità di analisi per l'applicazione. Ogni regione riceve i dati in modo indipendente da Spanner e l'applicazione vi accede in modo indipendente. Questa architettura compensa il componente BigQuery, consentendogli di soddisfare i requisiti generali dell'applicazione.
Appendice: Riferimento prodotto
Questa sezione descrive l'architettura e le funzionalità di RE dei prodotti Google Cloud più comunemente utilizzati nelle applicazioni dei clienti e che possono essere sfruttati facilmente per soddisfare i tuoi requisiti di RE.
Temi comuni
Molti Google Cloud prodotti offrono configurazioni regionali o multiregionali. I prodotti regionali sono resilienti alle interruzioni di zona, mentre i prodotti multiregionali e globali sono resilienti alle interruzioni di regione. In generale, ciò significa che durante un'interruzione, la tua applicazione subisce interruzioni minime. Google raggiunge questi risultati attraverso alcuni approcci architetturali comuni, che rispecchiano le indicazioni architetturali riportate sopra.
Deployment ridondante:i backend dell'applicazione e l'archiviazione dei dati vengono implementati in più zone all'interno di una regione e in più regioni all'interno di una località multiregionale. Per saperne di più sulle considerazioni specifiche per le regioni, consulta Area geografica e regioni.
Replica dei dati:i prodotti utilizzano la replica sincrona o asincrona nelle posizioni ridondanti.
La replica sincrona significa che quando la tua applicazione effettua una chiamata API per creare o modificare i dati archiviati dal prodotto, riceve una risposta positiva solo dopo che il prodotto ha scritto i dati in più posizioni. La replica sincrona garantisce che tu non perda l'accesso ai tuoi dati durante un'interruzione dell'infrastruttura perché tutti i tuoi dati sono disponibili in una delle posizioni di backend disponibili. Google Cloud
Sebbene questa tecnica fornisca la massima protezione dei dati, può comportare compromessi in termini di latenza e prestazioni. I prodotti multiregionali che utilizzano la replica sincrona risentono maggiormente di questo compromesso, in genere con un aumento della latenza di decine o centinaia di millisecondi.
La replica asincrona significa che quando la tua applicazione effettua una chiamata API per creare o modificare i dati archiviati dal prodotto, riceve una risposta positiva una volta che il prodotto ha scritto i dati in una singola posizione. Dopo la richiesta di scrittura, il prodotto replica i dati in posizioni aggiuntive.
Questa tecnica offre una latenza inferiore e un throughput più elevato nell'API rispetto alla replica sincrona, ma a scapito della protezione dei dati. Se la località in cui hai scritto i dati subisce un'interruzione prima che la replica sia completata, perdi l'accesso a questi dati finché l'interruzione della località non viene risolta.
Gestione delle interruzioni con il bilanciamento del carico: Google Cloud utilizza il bilanciamento del carico software per instradare le richieste ai backend dell'applicazione appropriati. Rispetto ad altri approcci come il bilanciamento del carico DNS, questo approccio riduce il tempo di risposta del sistema a un'interruzione. Quando si verifica un'interruzione della Google Cloud posizione, il bilanciatore del carico rileva rapidamente che il backend di cui è stato eseguito il deployment in quella posizione è diventato "non integro" e indirizza tutte le richieste a un backend in una posizione alternativa. Ciò consente al prodotto di continuare a gestire le richieste della tua applicazione durante un'interruzione del servizio di localizzazione. Quando l'interruzione della località viene risolta, il bilanciatore del carico rileva la disponibilità dei backend di prodotto in quella località e riprende a inviare traffico.
Gestore contesto accesso
Gestore contesto accesso consente alle aziende di configurare livelli di accesso che corrispondono a una norma definita negli attributi della richiesta. I criteri vengono replicati a livello regionale.
In caso di interruzione a livello di zona, le richieste alle zone non disponibili vengono gestite automaticamente e in modo trasparente dalle altre zone disponibili nella regione.
In caso di interruzione a livello regionale, i calcoli dei criteri dell'area geografica interessata non sono disponibili finché l'area geografica non torna disponibile.
Access Transparency
Access Transparency consente agli amministratori dell'organizzazione Google Cloud di definire un controllo dell'accesso granulare e basato sugli attributi per progetti e risorse in Google Cloud. Di tanto in tanto, Google deve accedere ai dati dei clienti per scopi amministrativi. Quando accediamo ai dati dei clienti, Access Transparency fornisce i log di accesso ai clienti Google Cloudinteressati. Questi log di Access Transparency contribuiscono a garantire l'impegno di Google per la sicurezza dei dati e la trasparenza nella gestione dei dati.
Access Transparency è resiliente alle interruzioni zonali e regionali. Se si verifica un'interruzione a livello di zona o regionale, Access Transparency continua a elaborare i log di accesso amministrativo in un'altra zona o regione.
AlloyDB per PostgreSQL
AlloyDB per PostgreSQL è un servizio di database completamente gestito e compatibile con PostgreSQL. AlloyDB per PostgreSQL offre alta disponibilità in una regione tramite i nodi ridondanti dell'istanza principale, che si trovano in due zone diverse della regione. L'istanza principale mantiene la disponibilità regionale attivando un failover automatico nella zona di standby se la zona attiva riscontra un problema. L'archiviazione regionale garantisce la durabilità dei dati in caso di perdita di una singola zona.
Come ulteriore metodo di ripristino di emergenza, AlloyDB per PostgreSQL utilizza la replica tra regioni per fornire funzionalità di ripristino di emergenza replicando in modo asincrono i dati del cluster primario nei cluster secondari che si trovano in regioni Google Cloud separate.
Interruzione zonale: durante il normale funzionamento, è attivo solo uno dei due nodi di un'istanza principale ad alta disponibilità e gestisce tutte le scritture di dati. Questo nodo attivo archivia i dati nel livello di archiviazione regionale separato del cluster.
AlloyDB per PostgreSQL rileva automaticamente gli errori a livello di zona e attiva un failover per ripristinare la disponibilità del database. Durante il failover, AlloyDB per PostgreSQL avvia il database sul nodo di standby, che è già provisionato in una zona diversa. Le nuove connessioni al database vengono automaticamente indirizzate a questa zona.
Dal punto di vista di un'applicazione client, un'interruzione zonale assomiglia a un'interruzione temporanea della connettività di rete. Al termine del failover, un client può riconnettersi all'istanza allo stesso indirizzo, utilizzando le stesse credenziali, senza perdita di dati.
Interruzione a livello di regione: la replica tra regioni utilizza la replica asincrona, che consente all'istanza principale di eseguire il commit delle transazioni prima che venga eseguito il commit sulle repliche. La differenza di tempo tra il momento in cui una transazione viene commitata sull'istanza primaria e il momento in cui viene commitata sulla replica è nota come ritardo della replica. La differenza di tempo tra il momento in cui il primario genera il log write-ahead (WAL) e il momento in cui il WAL raggiunge la replica è nota come flush lag. Il ritardo di replica e il ritardo di svuotamento dipendono dalla configurazione dell'istanza del database e dal carico di lavoro generato dall'utente.
In caso di interruzione a livello di regione, puoi promuovere i cluster secondari in un'altra regione a cluster primario autonomo scrivibile. Questo cluster promosso non replica più i dati dal cluster primario originale a cui era precedentemente associato. A causa del ritardo di svuotamento, potrebbe verificarsi una perdita di dati perché potrebbero esserci transazioni nel cluster primario originale che non sono state propagate al cluster secondario.
L'RPO della replica tra regioni è influenzato sia dall'utilizzo della CPU del cluster primario sia dalla distanza fisica tra la regione del cluster primario e quella del cluster secondario. Per ottimizzare l'RPO, ti consigliamo di testare il tuo carico di lavoro con una configurazione che includa una replica per stabilire un limite sicuro di transazioni al secondo (TPS), ovvero il TPS sostenuto più elevato che non accumula ritardo di svuotamento. Se il tuo workload supera il limite di TPS sicuro, si accumula un ritardo di svuotamento, che può influire sull'RPO. Per limitare il ritardo di rete, scegli coppie di regioni all'interno dello stesso continente.
Per saperne di più sul monitoraggio del ritardo di rete e di altre metriche di AlloyDB per PostgreSQL, consulta Monitorare le istanze.
Anti Money Laundering AI
Anti Money Laundering AI (AML AI) fornisce un'API per aiutare gli istituti finanziari globali a rilevare in modo più efficace ed efficiente il riciclaggio di denaro. L'AI antiriciclaggio è un'offerta regionale, il che significa che i clienti possono scegliere la regione, ma non le zone che la compongono. I dati e il traffico vengono bilanciati automaticamente tra le zone all'interno di una regione. Le operazioni (ad esempio, per creare una pipeline o eseguire una previsione) vengono scalate automaticamente in background e bilanciate tra le zone in base alle necessità.
Interruzione zonale:AML AI archivia i dati per le sue risorse a livello regionale, replicati in modo sincrono. Quando un'operazione a lunga esecuzione viene completata correttamente, è possibile fare affidamento sulle risorse indipendentemente dagli errori di zona. L'elaborazione viene replicata anche tra le zone, ma questa replica ha lo scopo di bilanciare il carico e non di garantire l'alta disponibilità, pertanto un errore a livello di zona durante un'operazione può comportare un errore dell'operazione. In questo caso, riprovare l'operazione può risolvere il problema. Durante un'interruzione zonale, i tempi di elaborazione potrebbero essere interessati.
Interruzione regionale: i clienti scelgono la regione Google Cloud in cui vogliono creare le risorse AML AI. I dati non vengono mai replicati tra regioni. Il traffico dei clienti non viene mai indirizzato a un'altra regione da AML AI. In caso di errore a livello di regione, AML AI tornerà disponibile non appena l'interruzione verrà risolta.
Chiavi API
Le chiavi API forniscono una gestione scalabile delle risorse delle chiavi API per un progetto. Le chiavi API sono un servizio globale, il che significa che le chiavi sono visibili e accessibili da qualsiasi Google Cloud posizione. I relativi dati e metadati vengono archiviati in modo ridondante in più zone e regioni.
Le chiavi API sono resilienti alle interruzioni zonali e regionali. In caso di interruzione a livello di zona o regione, le chiavi API continuano a gestire le richieste provenienti da un'altra zona della stessa regione o di una regione diversa.
Per saperne di più sulle chiavi API, consulta la panoramica dell'API API Keys.
Apigee
Apigee fornisce una piattaforma sicura, scalabile e affidabile per lo sviluppo e la gestione delle API. Apigee offre deployment a livello di una o più regioni.
Interruzione zonale: i dati di runtime dei clienti vengono replicati in più zone di disponibilità. Pertanto, un'interruzione in una singola zona non influisce su Apigee.
Interruzione a livello regionale:per le istanze Apigee a una singola regione, se una regione non è più disponibile, le istanze Apigee non sono disponibili in quella regione e non possono essere ripristinate in regioni diverse. Per le istanze Apigee multiregionali, i dati vengono replicati in modo asincrono in tutte le regioni. Pertanto, l'errore di una regione non riduce completamente il traffico. Tuttavia, potresti non essere in grado di accedere ai dati non sottoposti a commit nella regione in cui si è verificato l'errore. Puoi deviare il traffico dalle regioni non integre. Per ottenere il failover automatico del traffico, puoi configurare il routing di rete utilizzando i gruppi di istanze gestite (MIG).
AutoML Translation
AutoML Translation è un servizio di traduzione automatica che ti consente di importare i tuoi dati (coppie di frasi) per addestrare modelli personalizzati per le tue esigenze specifiche del dominio.
Interruzione zonale:AutoML Translation dispone di server di calcolo attivi in più zone e regioni. Supporta anche la replica sincrona dei dati tra le zone all'interno delle regioni. Queste funzionalità aiutano AutoML Translation a eseguire il failover istantaneo senza alcuna perdita di dati in caso di errori di zona e senza richiedere input o aggiustamenti da parte del cliente.
Interruzione a livello di regione:in caso di errore a livello di regione, AutoML Translation non è disponibile.
AutoML Vision
AutoML Vision fa parte di Vertex AI. Offre un framework unificato per creare set di dati, importare dati, addestrare modelli e pubblicare modelli per la previsione online e la previsione batch.
AutoML Vision è un'offerta regionale. I clienti possono scegliere la regione da cui vogliono avviare un job, ma non possono scegliere le zone specifiche all'interno di quella regione. Il servizio bilancia automaticamente il carico dei workload in diverse zone all'interno della regione.
Interruzione zonale:AutoML Vision archivia i metadati per i job a livello regionale e scrive in modo sincrono tra le zone all'interno della regione. I job vengono avviati in una zona specifica, selezionata da Cloud Load Balancing.
Job di addestramento AutoML Vision: un'interruzione zonale causa l'interruzione di tutti i job in esecuzione e lo stato del job viene aggiornato a non riuscito. Se un job non va a buon fine, riprova immediatamente. Il nuovo job viene indirizzato a una zona disponibile.
Job di previsioni in batch AutoML Vision: le previsioni in batch si basano sulle previsioni in batch di Vertex AI. Quando si verifica un'interruzione zonale, il servizio riprova automaticamente il job indirizzandolo alle zone disponibili. Se più tentativi non vanno a buon fine, lo stato del job viene aggiornato a non riuscito. Le successive richieste degli utenti per eseguire il job vengono instradate a una zona disponibile.
Interruzione regionale:i clienti scelgono la regione Google Cloud in cui vogliono eseguire i job. I dati non vengono mai replicati tra regioni. In caso di errore regionale, il servizio AutoML Vision non è disponibile in quella regione. Tornerà disponibile quando l'interruzione verrà risolta. Per eseguire i job, consigliamo ai clienti di utilizzare più regioni. In caso di interruzione a livello di regione, indirizza i job a un'altra regione disponibile.
Batch
Batch è un servizio completamente gestito per mettere in coda, pianificare ed eseguire job batch su Google Cloud. Le impostazioni batch sono definite a livello di regione. I clienti devono scegliere una regione per inviare i job batch, non una zona in una regione. Quando viene inviato un job, Batch scrive in modo sincrono i dati dei clienti in più zone. Tuttavia, i clienti possono specificare le zone in cui le VM Batch eseguono i job.
Errore a livello di zona:quando si verifica un errore in una singola zona, anche le attività in esecuzione in quella zona non vanno a buon fine. Se le attività hanno impostazioni di ripetizione, Batch esegue automaticamente il failover di queste attività in altre zone attive della stessa regione. Il failover automatico è soggetto alla disponibilità di risorse nelle zone attive della stessa regione. I job che richiedono risorse di zona (come VM, GPU o dischi permanenti di zona) disponibili solo nella zona non riuscita vengono messi in coda finché la zona non viene ripristinata o finché non vengono raggiunti i timeout di accodamento dei job. Se possibile, consigliamo ai clienti di lasciare che Batch scelga le risorse zonali per eseguire i job. In questo modo, i job sono resilienti a un'interruzione di zona.
Errore regionale:in caso di errore regionale, il service control plane non è disponibile nella regione. Il servizio non replica i dati né reindirizza le richieste tra le regioni. Consigliamo ai clienti di utilizzare più regioni per eseguire i propri job e reindirizzarli a un'altra regione in caso di errore.
Protezione dei dati e tutela dalle minacce di Chrome Enterprise Premium
La protezione dei dati e dalle minacce di Chrome Enterprise Premium fa parte della soluzione Chrome Enterprise Premium. Estende Chrome con una serie di funzionalità di sicurezza, tra cui protezione da malware e phishing, prevenzione della perdita di dati (DLP), regole di filtro degli URL e report sulla sicurezza.
Gli amministratori di Chrome Enterprise Premium possono attivare l'archiviazione dei contenuti principali dei clienti che violano le norme DLP o relative ai malware negli eventi dei log delle regole di Google Workspace e/o in Cloud Storage per indagini future. Gli eventi del log delle regole di Google Workspace sono basati su un database Spanner multiregionale. Chrome Enterprise Premium può richiedere fino a diverse ore per rilevare le violazioni delle norme. Durante questo periodo, tutti i dati non elaborati sono soggetti a perdita di dati a causa di un'interruzione zonale o regionale. Una volta rilevata una violazione, i contenuti che violano le tue norme vengono scritti negli eventi del log delle regole di Google Workspace e/o in Cloud Storage.
Interruzione zonale e regionale: Poiché la protezione dalle minacce e dei dati di Chrome Enterprise Premium è multizonale e multiregionale, può sopravvivere a una perdita completa e non pianificata di una zona o di una regione senza perdita di disponibilità. Fornisce questo livello di affidabilità reindirizzando il traffico al suo servizio in altre zone o regioni attive. Tuttavia, poiché la protezione dalle minacce e dei dati di Chrome Enterprise Premium può richiedere diverse ore per rilevare violazioni di DLP e malware, tutti i dati non elaborati in una zona o regione specifica sono soggetti a perdita a causa di un'interruzione zonale o regionale.
BigQuery
BigQuery è un data warehouse su cloud serverless, a scalabilità elevata e dai costi contenuti, progettato per l'agilità aziendale. BigQuery supporta i seguenti tipi di località per i set di dati utente:
- Una regione: una posizione geografica specifica, ad esempio Iowa (
us-central1) o Montréal (northamerica-northeast1). - Una località a più regioni: una realtà geografica di grandi dimensioni che contiene due o più luoghi geografici, ad esempio gli Stati Uniti (
US) o l'Europa (EU).
In entrambi i casi, i dati vengono archiviati in modo ridondante in due zone all'interno di una singola regione nella località selezionata. I dati scritti in BigQuery vengono scritti in modo sincrono sia nella zona primaria che in quella secondaria. Questa protezione impedisce l'indisponibilità di una singola zona all'interno della regione, ma non di un'interruzione a livello regionale.
Autorizzazione binaria
Autorizzazione binaria è un prodotto per la sicurezza della catena di fornitura del software per GKE e Cloud Run.
Tutti i criteri di Autorizzazione binaria vengono replicati in più zone all'interno di ogni regione. La replica aiuta le operazioni di lettura dei criteri di Autorizzazione binaria a ripristinarsi in seguito a errori in altre regioni. La replica rende anche le operazioni di lettura tolleranti agli errori a livello di zona all'interno di ogni regione.
Le operazioni di applicazione di Autorizzazione binaria sono resilienti alle interruzioni a livello di zona, ma non a quelle a livello di regione. Le operazioni di applicazione vengono eseguite nella stessa regione del cluster GKE o del job Cloud Run che effettua la richiesta. Pertanto, in caso di interruzione del servizio a livello regionale, non è in esecuzione alcun processo per effettuare richieste di applicazioneAutorizzazione binarian.
Certificate Manager
Certificate Manager ti consente di acquisire e gestire i certificati Transport Layer Security (TLS) da utilizzare con diversi tipi di Cloud Load Balancing.
In caso di interruzione zonale, Certificate Manager regionale e globale sono resilienti agli errori zonali perché i job e i database sono ridondanti in più zone all'interno di una regione. In caso di interruzione regionale, Certificate Manager globale è resiliente agli errori regionali perché i job e i database sono ridondanti in più regioni. Certificate Manager regionale è un prodotto regionale, quindi non può resistere a un errore regionale.
Cloud Intrusion Detection System
Cloud Intrusion Detection System (Cloud IDS) è un servizio di zona che fornisce endpoint IDS con ambito di zona, che elaborano il traffico delle VM in una zona specifica e quindi non tollerano interruzioni zonali o regionali.
Interruzione a livello di zona:Cloud IDS è collegato alle istanze VM. Se un cliente intende mitigare le interruzioni zonali eseguendo il deployment di VM in più zone (manualmente o tramite gruppi di istanze gestite regionali), dovrà eseguire il deployment anche degli endpoint Cloud IDS in queste zone.
Interruzione a livello di regione:Cloud IDS è un prodotto regionale. Non fornisce alcuna funzionalità cross-regionale. Un errore regionale interromperà tutte le funzionalità di Cloud IDS in tutte le zone della regione.
Google Security Operations SIEM
Google Security Operations SIEM (che fa parte di Google Security Operations) è un servizio completamente gestito che aiuta i team di sicurezza a rilevare, analizzare e rispondere alle minacce.
Google Security Operations SIEM offre servizi regionali e multiregionali.
Nelle offerte regionali, il bilanciamento del carico di dati e traffico viene eseguito automaticamente tra le zone all'interno della regione scelta e i dati vengono archiviati in modo ridondante tra le zone di disponibilità all'interno della regione.
Le regioni multiple sono ridondanti a livello geografico. Questa ridondanza offre una gamma più ampia di protezioni rispetto allo spazio di archiviazione regionale. Inoltre, contribuisce a garantire che il servizio continui a funzionare anche in caso di perdita di un'intera regione.
La maggior parte dei percorsi di importazione dati replica i dati dei clienti in modo sincrono in più località. Quando i dati vengono replicati in modo asincrono, esiste un intervallo di tempo (un obiettivo del punto di ripristino o RPO) durante il quale i dati non vengono ancora replicati in più località. Questo è il caso dell'importazione con feed nei deployment in più regioni. Dopo l'RPO, i dati sono disponibili in più località.
Interruzione zonale:
Deployment regionali: le richieste vengono gestite da qualsiasi zona all'interno della regione. I dati vengono replicati in modo sincrono in più zone. In caso di interruzione dell'intera zona, le zone rimanenti continuano a gestire il traffico e a elaborare i dati. Il provisioning ridondante e lo scaling automatico per Google Security Operations SIEM contribuiscono a garantire che il servizio rimanga operativo nelle zone rimanenti durante questi spostamenti del carico.
Deployment multiregionali: le interruzioni a livello di zona sono equivalenti alle interruzioni regionali.
Interruzione regionale:
Implementazioni regionali: Google Security Operations SIEM archivia tutti i dati dei clienti in una singola regione e il traffico non viene mai instradato tra le regioni. In caso di interruzione a livello di regione, Google Security Operations SIEM non è disponibile nella regione finché l'interruzione non viene risolta.
Deployment multiregionali (senza feed): le richieste vengono gestite da qualsiasi regione del deployment multiregionale. I dati vengono replicati in modo sincrono in più regioni. In caso di interruzione a livello di regione, le regioni rimanenti continuano a gestire il traffico e a elaborare i dati. Il provisioning ridondante e lo scaling automatico per Google Security Operations SIEM contribuiscono a garantire che il servizio rimanga operativo nelle regioni rimanenti durante questi spostamenti del carico.
Deployment multiregionali (con feed): le richieste vengono gestite da qualsiasi regione del deployment multiregionale. I dati vengono replicati in modo asincrono in più regioni con l'RPO fornito. In caso di interruzione a livello di regione, solo i dati archiviati dopo l'RPO sono disponibili nelle regioni rimanenti. I dati all'interno della finestra RPO potrebbero non essere replicati.
Cloud Asset Inventory
Cloud Asset Inventory è un servizio globale ad alte prestazioni e resiliente che gestisce un repository di metadati di risorse e criteri. Google Cloud Cloud Asset Inventory fornisce strumenti di ricerca e analisi che ti aiutano a monitorare gli asset di cui è stato eseguito il deployment in organizzazioni, cartelle e progetti.
In caso di interruzione di una zona, Cloud Asset Inventory continua a gestire le richieste da un'altra zona nella stessa regione o in una regione diversa.
In caso di interruzione a livello di regione, Cloud Asset Inventory continua a gestire le richieste provenienti da altre regioni.
Bigtable
Bigtable è un servizio di database NoSQL ad alte prestazioni e completamente gestito per carichi di lavoro analitici e operativi di grandi dimensioni.
Panoramica della replica Bigtable
Bigtable offre una funzionalità di replica flessibile e completamente configurabile, che puoi utilizzare per aumentare la disponibilità e la durabilità dei tuoi dati copiandoli nei cluster in più regioni o più zone all'interno della stessa regione. Bigtable può anche fornire il failover automatico per le tue richieste quando utilizzi la replica.
Quando utilizzi configurazioni multizona o multiregionali con il routing multi-cluster, in caso di interruzione a livello di zona o regione, Bigtable reindirizza automaticamente il traffico e gestisce le richieste dal cluster disponibile più vicino. Poiché la replica Bigtable è asincrona e alla fine coerente, le modifiche più recenti ai dati nella località dell'interruzione potrebbero non essere disponibili se non sono ancora state replicate in altre località.
Considerazioni sulle prestazioni
Quando le richieste di risorse CPU superano la capacità del nodo disponibile, Bigtable dà sempre la priorità alla gestione delle richieste in entrata rispetto al traffico di replica.
Per ulteriori informazioni su come utilizzare la replica Bigtable con il tuo workload, consulta la panoramica della replica Cloud Bigtable e gli esempi di impostazioni di replica.
I nodi Bigtable vengono utilizzati sia per la gestione delle richieste in entrata sia per l'esecuzione della replica dei dati da altri cluster. Oltre a mantenere un numero sufficiente di nodi per cluster, devi anche assicurarti che le tue applicazioni utilizzino una progettazione dello schema corretta per evitare hotspot, che possono causare un utilizzo eccessivo o sbilanciato della CPU e una maggiore latenza di replica.
Per saperne di più sulla progettazione dello schema dell'applicazione per massimizzare le prestazioni e l'efficienza di Bigtable, consulta Best practice per la progettazione degli schemi.
Monitoraggio
Bigtable offre diversi modi per monitorare visivamente la latenza di replica delle istanze e dei cluster utilizzando i grafici per la replica disponibili in Google Cloud console.
Puoi anche monitorare in modo programmatico le metriche di replica Bigtable utilizzando l'API Cloud Monitoring.
Certificate Authority Service
Certificate Authority Service (CA Service) consente ai clienti di semplificare, automatizzare e personalizzare il deployment, la gestione e la sicurezza delle autorità di certificazione (CA) private e di emettere certificati in modo resiliente su larga scala.
Interruzione zonale: CA Service è resiliente ai guasti zonali perché il suo control plane è ridondante in più zone all'interno di una regione. In caso di interruzione a livello di zona, CA Service continua a gestire le richieste provenienti da un'altra zona della stessa regione senza interruzioni. Poiché i dati vengono replicati in modo sincrono, non si verificano perdite o danneggiamenti.
Interruzione a livello regionale: CA Service è un prodotto regionale, quindi non può resistere a un errore a livello regionale. Se hai bisogno di resilienza agli errori regionali, crea CA emittenti in due regioni diverse. Crea la CA emittente primaria nella regione in cui ti servono i certificati. Crea una CA di fallback in un'altra regione. Utilizza il fallback quando si verifica un'interruzione nella regione della CA subordinata principale. Se necessario, entrambe le CA possono essere concatenate alla stessa CA radice.
Cloud Billing
L'API Cloud Billing consente agli sviluppatori di gestire la fatturazione per i loro progettiGoogle Cloud a livello di programmazione. L'API Cloud Billing è progettata come sistema globale con aggiornamenti scritti in modo sincrono in più zone e regioni.
Errore zonale o regionale: l'API Cloud Billing eseguirà automaticamente il failover in un'altra zona o regione. Le singole richieste potrebbero non riuscire, ma un criterio di ripetizione dovrebbe consentire i tentativi successivi.
Cloud Build
Cloud Build è un servizio che esegue le tue build su Google Cloud.
Cloud Build è composto da istanze isolate a livello regionale che replicano i dati in modo sincrono tra le zone all'interno della regione. Ti consigliamo di utilizzare regioni specifiche Google Cloud anziché la regione globale e assicurati che le risorse utilizzate dalla build (inclusi bucket di log, repository Artifact Registry e così via) siano allineate alla regione in cui viene eseguita la build.
In caso di interruzione a livello di zona, le operazioni del control plane non sono interessate. Tuttavia, le build attualmente in esecuzione nella zona in errore verranno ritardate o perse definitivamente. Le build appena attivate verranno distribuite automaticamente alle zone funzionanti rimanenti.
In caso di errore regionale, il piano di controllo sarà offline e le build attualmente in esecuzione verranno ritardate o perse definitivamente. I trigger, i pool di worker e i dati di build non vengono mai replicati tra le regioni. Ti consigliamo di preparare trigger e pool di worker in più regioni per semplificare la mitigazione di un'interruzione.
Cloud CDN
Cloud CDN distribuisce e memorizza nella cache i contenuti in molte località della rete Google per ridurre la latenza di pubblicazione per i client. I contenuti memorizzati nella cache vengono pubblicati in base al miglior impegno possibile. Quando una richiesta non può essere gestita dalla cache di Cloud CDN, viene inoltrata ai server di origine, come le VM di backend o i bucket Cloud Storage, in cui sono archiviati i contenuti originali.
Quando una zona o una regione non funziona, le cache nelle località interessate non sono disponibili. Le richieste in entrata vengono instradate alle posizioni edge e alle cache di Google disponibili. Se queste cache alternative non possono soddisfare la richiesta, la inoltreranno a un server di origine disponibile. A condizione che il server possa soddisfare la richiesta con dati aggiornati, non si verificherà alcuna perdita di contenuti. Un aumento del tasso di fallimenti della cache farà sì che i server di origine registrino volumi di traffico superiori al normale man mano che le cache vengono riempite. Le richieste successive verranno servite dalle cache non interessate dall'interruzione del servizio nella zona o nella regione.
Per ulteriori informazioni su Cloud CDN e sul comportamento della cache, consulta la documentazione di Cloud CDN.
Cloud Composer
Cloud Composer è un servizio gestito per l'orchestrazione dei workflow che consente di creare, pianificare, monitorare e gestire workflow distribuiti su più cloud e sui data center on-premise. Gli ambienti Cloud Composer sono basati sul progetto open source Apache Airflow.
La disponibilità dell'API Cloud Composer non è interessata dall'indisponibilità zonale. Durante un'interruzione zonale, mantieni l'accesso all'API Cloud Composer, inclusa la possibilità di creare nuovi ambienti Cloud Composer.
Un ambiente Cloud Composer ha un cluster GKE come parte della sua architettura. Durante un'interruzione zonale, i workflow sul cluster potrebbero essere interrotti:
- In Cloud Composer 1, il cluster dell'ambiente è una risorsa di zona, pertanto un'interruzione del servizio a livello di zona potrebbe rendere il cluster non disponibile. Workflows in esecuzione al momento dell'interruzione potrebbero essere interrotti prima del completamento.
- In Cloud Composer 2, il cluster dell'ambiente è una risorsa regionale. Tuttavia, i flussi di lavoro eseguiti sui nodi nelle zone interessate da un'interruzione zonale potrebbero essere interrotti prima del completamento.
In entrambe le versioni di Cloud Composer, un'interruzione zonale potrebbe causare l'interruzione dell'esecuzione dei workflow eseguiti parzialmente, incluse le azioni esterne che hai configurato per il workflow. A seconda del flusso di lavoro, ciò può causare incoerenze a livello esterno, ad esempio se il flusso di lavoro si interrompe a metà di un'esecuzione in più passaggi per modificare gli archivi di dati esterni. Pertanto, devi considerare la procedura di ripristino quando progetti il workflow Airflow, incluso come rilevare gli stati del workflow eseguiti parzialmente e riparare eventuali modifiche parziali dei dati.
In Cloud Composer 1, durante un'interruzione di zona, puoi scegliere di avviare un nuovo ambiente Cloud Composer in un'altra zona. Poiché Airflow mantiene lo stato dei workflow nel suo database di metadati, il trasferimento di queste informazioni a un nuovo ambiente Cloud Composer può richiedere ulteriori passaggi e preparazione.
In Cloud Composer 2, puoi risolvere i problemi di interruzione zonale configurando in anticipo il recupero di emergenza con snapshot dell'ambiente. Durante un'interruzione del servizio a livello di zona, puoi passare a un altro ambiente trasferendo lo stato dei tuoi flussi di lavoro con uno snapshot dell'ambiente. Solo Cloud Composer 2 supporta il ripristino di emergenza con gli snapshot dell'ambiente.
Cloud Data Fusion
Cloud Data Fusion è un servizio di integrazione dei dati aziendali completamente gestito per creare e gestire rapidamente pipeline di dati. Offre tre edizioni.
Le interruzioni zonali interessano le istanze dell'edizione Developer.
Le interruzioni regionali interessano le istanze delle versioni Basic ed Enterprise.
Per controllare l'accesso alle risorse, puoi progettare ed eseguire pipeline in ambienti separati. Questa separazione ti consente di progettare una pipeline una sola volta e poi eseguirla in più ambienti. Puoi recuperare le pipeline in entrambi gli ambienti. Per ulteriori informazioni, vedi Eseguire il backup e il ripristino dei dati dell'istanza.
I seguenti consigli si applicano sia alle interruzioni regionali che a quelle zonali.
Interruzioni nell'ambiente di progettazione della pipeline
Nell'ambiente di progettazione, salva le bozze delle pipeline in caso di interruzione del servizio. A seconda dei requisiti specifici di RTO e RPO, puoi utilizzare le bozze salvate per ripristinare la pipeline in un'altra istanza di Cloud Data Fusion durante un'interruzione.
Interruzioni nell'ambiente di esecuzione della pipeline
Nell'ambiente di esecuzione, avvii la pipeline internamente con trigger o pianificazioni di Cloud Data Fusion oppure esternamente con strumenti di orchestrazione, come Cloud Composer. Per poter recuperare le configurazioni di runtime delle pipeline, esegui il backup delle pipeline e delle configurazioni, come plug-in e pianificazioni. In caso di interruzione, puoi utilizzare il backup per replicare un'istanza in una regione o zona non interessata.
Un altro modo per prepararsi alle interruzioni è avere più istanze nelle regioni con la stessa configurazione e lo stesso set di pipeline. Se utilizzi l'orchestrazione esterna, l'esecuzione delle pipeline può essere bilanciata automaticamente tra le istanze. Presta particolare attenzione per assicurarti che non ci siano risorse (come origini dati o strumenti di orchestrazione) associate a una singola regione e utilizzate da tutte le istanze, in quanto potrebbero diventare un punto centrale di errore in caso di interruzione. Ad esempio, puoi avere più istanze in regioni diverse e utilizzare Cloud Load Balancing e Cloud DNS per indirizzare le richieste di esecuzione della pipeline a un'istanza non interessata da un'interruzione (vedi gli esempi di architetture di livello 1 e livello 3).
Interruzioni di altri servizi di dati Google Cloud nella pipeline
L'istanza potrebbe utilizzare altri servizi Google Cloud come origini dati o ambienti di esecuzione della pipeline, come Dataproc, Cloud Storage o BigQuery. Questi servizi possono trovarsi in regioni diverse. Quando è necessaria l'esecuzione tra regioni, un errore in una delle due regioni comporta un'interruzione. In questo scenario, segui la procedura standard di recupero di emergenza, tenendo presente che la configurazione tra regioni con servizi critici in regioni diverse è meno resiliente.
Cloud Deploy
Cloud Deploy fornisce la distribuzione continua dei carichi di lavoro nei servizi di runtime come GKE e Cloud Run. Il servizio è composto da istanze regionali che replicano i dati in modo sincrono tra le zone all'interno della regione.
Interruzione zonale: le operazioni del control plane non sono interessate. Tuttavia, le build di Cloud Build (ad esempio, le operazioni di rendering o deployment) in esecuzione quando si verifica un errore in una zona vengono ritardate o perse definitivamente. Durante un'interruzione, la risorsa Cloud Deploy che ha attivato la build (una release o un rollout) mostra uno stato di errore che indica che l'operazione sottostante non è riuscita. Puoi ricreare la risorsa per avviare una nuova build nelle zone funzionanti rimanenti. Ad esempio, crea una nuova implementazione eseguendo nuovamente il deployment della release in una destinazione.
Interruzione a livello di regione:le operazioni del control plane non sono disponibili, così come i dati di Cloud Deploy, finché la regione non viene ripristinata. Per semplificare il ripristino del servizio in caso di interruzione regionale, ti consigliamo di archiviare la pipeline di distribuzione e le definizioni dei target nel controllo del codice sorgente. Puoi utilizzare questi file di configurazione per ricreare le pipeline Cloud Deploy in una regione funzionante. Durante un'interruzione, i dati sulle uscite esistenti vengono persi. Crea una nuova release per continuare a eseguire il deployment del software nei target.
Cloud DNS
Cloud DNS è un servizio DNS (Domain Name System) globale, resiliente e ad alte prestazioni che pubblica i tuoi nomi di dominio nel DNS globale in modo conveniente.
In caso di interruzione di servizio a livello di zona, Cloud DNS continua a gestire le richieste provenienti da un'altra zona della stessa regione o di una regione diversa senza interruzioni. Gli aggiornamenti ai record Cloud DNS vengono replicati in modo sincrono tra le zone all'interno della regione in cui vengono ricevuti. Pertanto, non si verifica alcuna perdita di dati.
In caso di interruzione a livello di regione, Cloud DNS continua a gestire le richieste provenienti da altre regioni. È possibile che gli aggiornamenti molto recenti ai record Cloud DNS non siano disponibili perché gli aggiornamenti vengono prima elaborati in una singola regione prima di essere replicati in modo asincrono in altre regioni.
API Cloud Healthcare
L'API Cloud Healthcare, un servizio per l'archiviazione e la gestione dei dati sanitari, è progettata per fornire alta disponibilità e offre protezione da errori zonali e regionali, a seconda della configurazione scelta.
Configurazione regionale: nella sua configurazione predefinita, l'API Cloud Healthcare offre protezione da errori di zona. Il servizio viene implementato in tre zone di una regione e i dati vengono triplicati in zone diverse all'interno della regione. In caso di errore a livello di zona, che interessa il livello di servizio o il livello di dati, le zone rimanenti prendono il controllo senza interruzioni. Con la configurazione regionale, se si verifica un'interruzione in un'intera regione in cui si trova il servizio, quest'ultimo non sarà disponibile finché la regione non tornerà online. Nell'improbabile caso di distruzione fisica di un'intera regione, i dati archiviati in quella regione andranno persi.
Configurazione multiregionale: nella sua configurazione multiregionale, l'API Cloud Healthcare viene implementata in tre zone appartenenti a tre regioni diverse. I dati vengono replicati anche in tre regioni. In questo modo si evita la perdita del servizio in caso di interruzione dell'intera regione, poiché le regioni rimanenti subentrano automaticamente. I dati strutturati, come FHIR, vengono replicati in modo sincrono in più regioni, quindi sono protetti dalla perdita di dati in caso di interruzione dell'intera regione. I dati archiviati nei bucket Cloud Storage, ad esempio DICOM e Dictation o oggetti HL7v2/FHIR di grandi dimensioni, vengono replicati in modo asincrono in più regioni.
Cloud Identity
I servizi Cloud Identity sono distribuiti in più regioni e utilizzano il bilanciamento del carico dinamico. Cloud Identity non consente agli utenti di selezionare un ambito delle risorse. Se una determinata zona o regione subisce un'interruzione, il traffico viene distribuito automaticamente ad altre zone o regioni.
I dati permanenti vengono sottoposti a mirroring in più regioni con replica sincrona nella maggior parte dei casi. Per motivi di prestazioni, alcuni sistemi, come le cache o le modifiche che interessano un numero elevato di entità, vengono replicati in modo asincrono tra le regioni. Se la regione principale in cui sono archiviati i dati più recenti subisce un'interruzione, Cloud Identity pubblica dati obsoleti da un'altra località finché la regione principale non torna disponibile.
Cloud Interconnect
Cloud Interconnect offre ai clienti l'accesso RFC 1918 alle reti Google Cloud dai loro data center on-premise, tramite cavi fisici collegati al peering edge di Google.
Cloud Interconnect offre ai clienti uno SLA del 99,9% se eseguono il provisioning delle connessioni a due domini di disponibilità edge (EAD) in un'area metropolitana. È disponibile uno SLA del 99,99% se il cliente esegue il provisioning delle connessioni in due EAD in due aree metropolitane a due regioni con routing globale. Per ulteriori informazioni, vedi Panoramica della topologia per applicazioni non critiche e Panoramica della topologia per applicazioni a livello di produzione.
Cloud Interconnect è indipendente dalla zona di calcolo e fornisce alta disponibilità sotto forma di EAD. In caso di errore EAD, la sessione BGP con l'EAD si interrompe e il traffico esegue il failover sull'altro EAD.
In caso di errore a livello di regione, le sessioni BGP con quella regione vengono interrotte e il traffico esegue il failover alle risorse nella regione funzionante. Ciò si applica quando è abilitato il routing globale.
Cloud Key Management Service
Cloud Key Management Service (Cloud KMS) fornisce una gestione scalabile e altamente durevole delle risorse delle chiavi di crittografia. Cloud KMS archivia tutti i suoi dati e metadati in database Spanner che forniscono elevata durabilità e disponibilità dei dati con replica sincrona.
Le risorse Cloud KMS possono essere create in una singola regione, in più regioni o a livello globale.
In caso di interruzione a livello di zona, Cloud KMS continua a gestire le richieste provenienti da un'altra zona della stessa regione o di una regione diversa senza interruzioni. Poiché i dati vengono replicati in modo sincrono, non si verificano perdite o danneggiamenti. Quando l'interruzione della zona viene risolta, viene ripristinata la ridondanza completa.
In caso di interruzione a livello di regione, le risorse regionali in quella regione sono offline finché la regione non torna disponibile. Tieni presente che anche all'interno di una regione vengono mantenute almeno tre repliche in zone separate. Quando è richiesta una disponibilità maggiore, le risorse devono essere archiviate in una configurazione multiregionale o globale. Le configurazioni multiregionali e globali sono progettate per rimanere disponibili durante un'interruzione regionale archiviando e pubblicando i dati con geo-ridondanza in più di una regione.
Cloud External Key Manager (Cloud EKM)
Cloud External Key Manager è integrato con Cloud Key Management Service per consentirti di controllare e accedere alle chiavi esterne tramite partner di terze parti supportati. Puoi utilizzare queste chiavi esterne per criptare i dati at-rest da utilizzare per altri servizi che supportano l'integrazione delle chiavi di crittografia gestite dal cliente (CMEK). Google Cloud
Interruzione zonale:Cloud External Key Manager è resiliente alle interruzioni zonali grazie alla ridondanza fornita da più zone in una regione. Se si verifica un'interruzione a livello di zona, il traffico viene reindirizzato ad altre zone all'interno della regione. Durante il reindirizzamento del traffico, potresti notare un aumento degli errori, ma il servizio è comunque disponibile.
Interruzione regionale:Cloud External Key Manager non è disponibile durante un'interruzione regionale nella regione interessata. Non esiste un meccanismo di failover che reindirizzi le richieste tra regioni. Consigliamo ai clienti di utilizzare più regioni per eseguire i propri job.
Cloud External Key Manager non archivia in modo permanente i dati dei clienti. Pertanto, non si verifica alcuna perdita di dati durante un'interruzione regionale all'interno del sistema Cloud External Key Manager. Tuttavia, Cloud External Key Manager dipende dalla disponibilità di altri servizi, come Cloud Key Management Service e fornitori esterni di terze parti. Se questi sistemi non funzionano durante un'interruzione a livello regionale, potresti perdere i dati. L'RPO/RTO di questi sistemi non rientra nell'ambito degli impegni di Cloud External Key Manager.
Cloud Load Balancing
Cloud Load Balancing è un servizio gestito completamente distribuito e software-defined. Con Cloud Load Balancing, un singolo indirizzo IP anycast può fungere da frontend per i backend nelle regioni di tutto il mondo. Non è basato su hardware, quindi non devi gestire un'infrastruttura fisica di bilanciamento del carico. I bilanciatori del carico sono una componente fondamentale della maggior parte delle applicazioni ad alta affidabilità.
Cloud Load Balancing offre bilanciatori del carico sia regionali che globali. Fornisce inoltre il bilanciamento del carico tra diverse regioni, compreso il failover automatico in più regioni, che trasferisce il traffico ai backend di failover se i backend principali sono in stato non integro.
I bilanciatori del carico globali sono resilienti alle interruzioni zonali e regionali. I bilanciatori del carico a livello di regione sono resilienti alle interruzioni del servizio a livello di zona, ma sono interessati dalle interruzioni del servizio nella loro regione. Tuttavia, in entrambi i casi, è importante capire che la resilienza dell'applicazione complessiva dipende non solo dal tipo di bilanciatore del carico che implementi, ma anche dalla ridondanza dei backend.
Per saperne di più su Cloud Load Balancing e sulle sue funzionalità, consulta la panoramica di Cloud Load Balancing.
Cloud Logging
Cloud Logging è costituito da due parti principali: il router di log e lo spazio di archiviazione Cloud Logging.
Il router dei log gestisce gli eventi di log di streaming e indirizza i log all'archiviazione Cloud Storage, Pub/Sub, BigQuery o Cloud Logging.
L'archiviazione di Cloud Logging è un servizio per l'archiviazione, l'interrogazione e la gestione della conformità per i log. Supporta molti utenti e workflow, tra cui sviluppo, conformità, risoluzione dei problemi e avvisi proattivi.
Router di log e log in entrata:durante un'interruzione zonale, l'API Cloud Logging instrada i log verso altre zone della regione. Normalmente, i log indirizzati dal router dei log a Cloud Logging, BigQuery o Pub/Sub vengono scritti nella destinazione finale il prima possibile, mentre i log inviati a Cloud Storage vengono memorizzati nel buffer e scritti in batch orari.
Voci di log:in caso di interruzione a livello di zona o regione, le voci di log memorizzate nel buffer nella zona o nella regione interessata e non scritte nella destinazione di esportazione diventano inaccessibili. Le metriche basate su log vengono calcolate anche nel router dei log e sono soggette agli stessi vincoli. Una volta consegnati alla posizione di esportazione dei log selezionata, i log vengono replicati in base al servizio di destinazione. I log esportati nell'archiviazione Cloud Logging vengono replicati in modo sincrono tra due zone di una regione. Per il comportamento di replica di altri tipi di destinazione, consulta la sezione pertinente di questo articolo. Tieni presente che i log esportati in Cloud Storage vengono raggruppati e scritti ogni ora. Pertanto, consigliamo di utilizzare l'archiviazione di Cloud Logging, BigQuery o Pub/Sub per ridurre al minimo la quantità di dati interessati da un'interruzione.
Metadati log:i metadati come la configurazione di sink ed esclusione vengono archiviati a livello globale, ma memorizzati nella cache a livello regionale, in modo che in caso di interruzione del servizio, le istanze regionali di Log Router funzionino. Le interruzioni di una singola regione non hanno alcun impatto al di fuori della regione.
Cloud Monitoring
Cloud Monitoring è costituito da una serie di funzionalità interconnesse, come dashboard (sia integrate che definite dall'utente), avvisi e monitoraggio dell'uptime.
Tutta la configurazione di Cloud Monitoring, inclusi dashboard, controlli di uptime e criteri di avviso, è definita a livello globale. Tutte le modifiche vengono replicate in modo sincrono in più regioni. Pertanto, durante le interruzioni a livello di zona e di regione, le modifiche alla configurazione riuscite sono permanenti. Inoltre, anche se possono verificarsi errori di lettura e scrittura temporanei quando una zona o una regione inizialmente non funziona, Cloud Monitoring reindirizza le richieste verso zone e regioni disponibili. In questo caso, puoi riprovare a modificare la configurazione con un backoff esponenziale.
Quando scrive le metriche per una risorsa specifica, Cloud Monitoring identifica prima la regione in cui si trova la risorsa. Quindi scrive tre repliche indipendenti dei dati delle metriche all'interno della regione. La scrittura della metrica regionale complessiva viene restituita come riuscita non appena una delle tre scritture va a buon fine. Non è garantito che le tre repliche si trovino in zone diverse all'interno della regione.
Zonale:durante un'interruzione zonale, le scritture e le letture delle metriche non sono disponibili per le risorse nella zona interessata. In pratica, Cloud Monitoring si comporta come se la zona interessata non esistesse.
Regionale: durante un'interruzione regionale, le scritture e le letture delle metriche non sono disponibili per le risorse nella regione interessata. In pratica, Cloud Monitoring si comporta come se la regione interessata non esistesse.
Cloud NAT
Cloud NAT (Network Address Translation) è un servizio gestito distribuito e software-defined che consente a determinate risorse senza indirizzi IP esterni di creare connessioni in uscita verso internet. Non si basa su VM o appliance proxy. Cloud NAT configura invece il software Andromeda che alimenta la tua rete Virtual Private Cloud in modo che fornisca la Network Address Translation di origine (NAT di origine o SNAT) per le VM senza indirizzi IP esterni. Cloud NAT fornisce anche la Network Address Translation di destinazione (destination NAT o DNAT) per i pacchetti di risposta in entrata stabiliti.
Per saperne di più sulla funzionalità di Cloud NAT, consulta la documentazione.
Interruzione zonale: Cloud NAT è resiliente agli errori zonali perché il control plane e il piano dati di rete sono ridondanti in più zone all'interno di una regione.
Interruzione a livello regionale: Cloud NAT è un prodotto regionale, pertanto non può resistere a un errore regionale.
Router Cloud
Router Cloud è un servizio Google Cloud completamente distribuito e gestito che utilizza il protocollo BGP (Border Gateway Protocol) per pubblicizzare gli intervalli di indirizzi IP. Programma le route dinamiche in base alle pubblicità BGP che riceve da un peer. Invece di un dispositivo o appliance fisico, ogni router Cloud è costituito da attività software che fungono da speaker e risponditori BGP.
In caso di interruzione a livello di zona, router Cloud con una configurazione ad alta disponibilità (HA) è resiliente agli errori di zona. In questo caso, una delle interfacce potrebbe perdere la connettività, ma il traffico viene reindirizzato all'altra interfaccia tramite il routing dinamico utilizzando BGP.
In caso di interruzione a livello regionale, router Cloud è un prodotto regionale, quindi non può resistere a un errore regionale. Se i clienti hanno attivato la modalità di routing globale, il routing tra la regione non riuscita e le altre regioni potrebbe essere interessato.
Cloud Run
Cloud Run è un ambiente di computing stateless in cui i clienti possono eseguire il proprio codice in container sull'infrastruttura di Google. Cloud Run è un'offerta regionale, il che significa che i clienti possono scegliere la regione, ma non le zone che la compongono. I dati e il traffico vengono bilanciati automaticamente tra le zone all'interno di una regione. Le istanze container vengono scalate automaticamente per soddisfare il traffico in entrata e vengono bilanciate tra le zone in base alle necessità. Ogni zona gestisce uno scheduler che fornisce questo autoscaling per zona. Inoltre, è consapevole del carico ricevuto dalle altre zone e fornirà capacità aggiuntiva all'interno della zona per consentire eventuali errori a livello di zona.
Se utilizzi le GPU Cloud Run, hai la possibilità di disattivare la ridondanza a livello di zona per il servizio e, invece, utilizzare l'affidabilità al meglio in caso di interruzione zonale, a un costo inferiore. Per i dettagli, consulta Opzioni di ridondanza a livello di zona delle GPU.
Interruzione zonale: Cloud Run archivia i metadati e il container di cui è stato eseguito il deployment. Questi dati vengono archiviati a livello regionale e scritti in modo sincrono. L'API Cloud Run Admin restituisce la chiamata API solo dopo che i dati sono stati inviati a un quorum all'interno di una regione. Poiché i dati vengono archiviati a livello regionale, le operazioni del data plane non sono interessate neanche dagli errori di zona. Il traffico verrà indirizzato ad altre zone in caso di errore a livello di zona.
Interruzione regionale: i clienti scelgono la regione Google Cloud in cui vogliono creare il proprio servizio Cloud Run. I dati non vengono mai replicati tra regioni. Il traffico dei clienti non verrà mai indirizzato a un'altra regione da Cloud Run. In caso di errore a livello di regione, Cloud Run tornerà disponibile non appena l'interruzione verrà risolta. I clienti sono invitati a eseguire il deployment in più regioni e a utilizzare Cloud Load Balancing per ottenere una disponibilità più elevata, se lo desiderano.
Cloud Shell
Cloud Shell fornisce agli utenti l'accesso a istanze Compute Engine monoutente preconfigurate per l'onboarding, l'istruzione, lo sviluppo e le attività dell'operatore. Google Cloud
Cloud Shell non è adatto per l'esecuzione di carichi di lavoro delle applicazioni ed è invece destinato a casi d'uso interattivi di sviluppo e didattici. Ha limiti di quota di runtime per utente, viene arrestato automaticamente dopo un breve periodo di inattività e l'istanza è accessibile solo all'utente assegnato.
Le istanze Compute Engine che supportano il servizio sono risorse di zona, quindi in caso di interruzione della zona, la Cloud Shell di un utente non è disponibile.
Cloud Source Repositories
Cloud Source Repositories consente agli utenti di creare e gestire repository privati di codice sorgente. Questo prodotto è progettato con un modello globale, quindi non devi configurarlo per la resilienza regionale o zonale.
Al contrario, le operazioni git push su Cloud Source Repositories replicano in modo sincrono l'aggiornamento del repository di origine in più zone di più regioni. Ciò significa che il servizio è resiliente alle interruzioni in una qualsiasi regione.
Se una zona o una regione specifica subisce un'interruzione, il traffico viene distribuito automaticamente ad altre zone o regioni.
La funzionalità di mirroring automatico dei repository da GitHub o Bitbucket può essere interessata da problemi in questi prodotti. Ad esempio, il mirroring è interessato se GitHub o Bitbucket non riescono ad avvisare Cloud Source Repositories dei nuovi commit oppure se Cloud Source Repositories non riesce a recuperare i contenuti dal repository aggiornato.
Spanner
Spanner è un database scalabile, ad alta disponibilità, multiversione, replicato in modo sincrono e fortemente coerente con semantica relazionale.
Le istanze Spanner regionali replicano i dati in modo sincrono in tre zone di una singola regione. Un'operazione di scrittura in un'istanza Spanner regionale viene inviata in modo sincrono a tutte e tre le repliche e confermata al client dopo che almeno due repliche (quorum di maggioranza di 2 su 3) hanno eseguito il commit dell'operazione di scrittura. In questo modo Spanner è resiliente a un errore di zona, in quanto fornisce l'accesso a tutti i dati, poiché gli ultimi dati scritti sono stati salvati in modo permanente e si può comunque raggiungere un quorum di maggioranza per le scritture con due repliche.
Le istanze multiregionali Spanner includono un quorum di scrittura che replica in modo sincrono i dati in 5 zone situate in tre regioni (due repliche di lettura/scrittura ciascuna nella regione leader predefinita e in un'altra regione e una replica nella regione di testimonianza). Una scrittura in un'istanza Spanner multiregionale viene riconosciuta dopo che almeno tre repliche (quorum di maggioranza di 3 su 5) hanno eseguito il commit della scrittura. In caso di errore di una zona o di una regione, Spanner ha accesso a tutti i dati (incluse le ultime scritture) e gestisce le richieste di lettura/scrittura poiché i dati vengono archiviati in almeno 3 zone in 2 regioni nel momento in cui la scrittura viene confermata al client.
Per ulteriori informazioni su queste configurazioni, consulta la documentazione sull'istanza di Spanner e la documentazione sulla replica per scoprire di più sul funzionamento della replica di Spanner.
Cloud SQL
Cloud SQL è un servizio di database relazionale completamente gestito per MySQL, PostgreSQL e SQL Server. Cloud SQL utilizza macchine virtuali Compute Engine gestite per eseguire il software del database. Offre una configurazione ad alta disponibilità per la ridondanza regionale, proteggendo il database da un'interruzione a livello di zona. È possibile eseguire il provisioning delle repliche tra regioni per proteggere il database da un'interruzione del servizio in una regione. Poiché il prodotto offre anche un'opzione zonale, che non è resiliente a un'interruzione a livello di zona o regione, devi prestare attenzione a selezionare la configurazione ad alta disponibilità, le repliche tra regioni o entrambe.
Interruzione a livello di zona:l'opzione alta disponibilità crea un'istanza VM primaria e una in standby in due zone separate all'interno di una regione. Durante il normale funzionamento, l'istanza VM principale gestisce tutte le richieste, scrivendo i file di database in un Persistent Disk regionale, che viene replicato in modo sincrono nelle zone principale e di standby. Se un'interruzione della zona interessa l'istanza principale, Cloud SQL avvia un failover durante il quale ilPersistent Diske viene collegato alla VM in standby e il traffico viene reindirizzato.
Durante questo processo, il database deve essere inizializzato, il che include l'elaborazione di tutte le transazioni scritte nel log delle transazioni ma non applicate al database. Il numero e il tipo di transazioni non elaborate possono aumentare il tempo di RTO. Un numero elevato di scritture recenti può portare a un backlog di transazioni non elaborate. Il tempo di RTO è maggiormente influenzato da (a) un'elevata attività di scrittura recente e (b) modifiche recenti agli schemi di database.
Infine, quando l'interruzione zonale è stata risolta, puoi attivare manualmente un'operazione di failback per riprendere la pubblicazione nella zona principale.
Per ulteriori dettagli sull'opzione di alta disponibilità, consulta la documentazione sull'alta disponibilità di Cloud SQL.
Interruzione a livello di regione:l'opzione replica tra regioni protegge il database da interruzioni a livello di regione creando repliche di lettura dell'istanza principale in altre regioni. La replica tra regioni utilizza la replica asincrona, che consente all'istanza principale di eseguire il commit delle transazioni prima che venga eseguito il commit sulle repliche. La differenza di tempo tra il momento in cui una transazione viene eseguita nell'istanza principale e il momento in cui viene eseguita nella replica è nota come "ritardo di replica" (che può essere monitorato). Questa metrica riflette sia le transazioni che non sono state inviate dal database primario alle repliche, sia le transazioni che sono state ricevute ma non sono state elaborate dalla replica. Le transazioni non inviate alla replica non sarebbero disponibili durante un'interruzione a livello di regione. Le transazioni ricevute ma non elaborate dalla replica influiscono sul tempo di recupero, come descritto di seguito.
Cloud SQL consiglia di testare il carico di lavoro con una configurazione che includa una replica per stabilire un limite di "transazioni al secondo (TPS) sicure", ovvero il TPS sostenuto più elevato che non accumula ritardo di replica. Se il tuo carico di lavoro supera il limite TPS sicuro, il ritardo di replica si accumula, influendo negativamente sui valori RPO e RTO. Come indicazione generale, evita di utilizzare configurazioni di istanze piccole (<2 core vCPU, <100 GB di dischi o DP-HDD), che sono soggette a ritardo di replica.
In caso di interruzione del servizio a livello di regione, devi decidere se promuovere manualmente una replica di lettura. Si tratta di un'operazione manuale perché la promozione può causare uno scenario di split brain in cui la replica promossa accetta nuove transazioni nonostante sia in ritardo rispetto all'istanza principale al momento della promozione. Ciò può causare problemi quando l'interruzione regionale viene risolta e devi riconciliare le transazioni che non sono mai state propagate dalle istanze principali a quelle di replica. Se questo è problematico per le tue esigenze, puoi prendere in considerazione un prodotto di database con replica sincrona tra regioni come Spanner.
Una volta attivato dall'utente, il processo di promozione segue passaggi simili all'attivazione di un'istanza di standby nella configurazione ad alta disponibilità. In questo processo, la replica di lettura deve elaborare il log delle transazioni, che determina il tempo di recupero totale. Poiché non è coinvolto alcun bilanciatore del carico integrato nella promozione della replica, reindirizza manualmente le applicazioni alla primaria promossa.
Per ulteriori dettagli sull'opzione di replica tra regioni, consulta la documentazione sulla replica tra regioni di Cloud SQL.
Per ulteriori informazioni sul ripristino di emergenza di Cloud SQL, consulta quanto segue:
- Ripristino di emergenza per database Cloud SQL per MySQL
- Ripristino di emergenza del database Cloud SQL per PostgreSQL
- Ripristino di emergenza per database Cloud SQL per SQL Server
Cloud Storage
Cloud Storage offre uno spazio di archiviazione di oggetti unificato a livello globale, scalabile e a elevata durabilità. I bucket Cloud Storage possono essere creati in uno dei tre diversi tipi di località: in una singola regione, in una doppia regione o in più regioni all'interno di un continente. Con i bucket regionali, gli oggetti vengono archiviati in modo ridondante in più zone di disponibilità in un'unica regione. I bucket a due regioni e multiregionali, invece, sono geo-ridondanti. Ciò significa che, dopo che i dati appena scritti sono stati replicati in almeno una regione remota, gli oggetti vengono archiviati in modo ridondante nelle regioni. Questo approccio offre ai dati nei bucket multiregionali e dual-region una serie più ampia di protezioni rispetto a quelle ottenibili con l'archiviazione regionale.
I bucket regionali sono progettati per essere resilienti in caso di interruzione in una singola zona di disponibilità. Se una zona subisce un'interruzione, gli oggetti nella zona non disponibile vengono serviti automaticamente e in modo trasparente da un'altra posizione della regione. I dati e i metadati vengono archiviati in modo ridondante in più zone a partire dalla scrittura iniziale. Nessuna scrittura viene persa se una zona non è più disponibile. In caso di interruzione a livello di regione, i bucket regionali in quella regione sono offline finché la regione non torna disponibile.
Se hai bisogno di una maggiore disponibilità, puoi archiviare i dati in una configurazione a due o più regioni. I bucket con due o più regioni sono bucket singoli (senza località primaria e secondaria separate), ma archiviano dati e metadati in modo ridondante in più regioni. In caso di interruzione a livello regionale, il servizio non viene interrotto. Puoi considerare i bucket multiregionali e in due regioni come attivi-attivi, in quanto puoi leggere e scrivere workload in più di una regione contemporaneamente, mentre il bucket rimane fortemente coerente. Ciò può essere particolarmente interessante per i clienti che vogliono dividere il proprio carico di lavoro tra le due regioni nell'ambito di un'architettura di ripristino di emergenza.
Le configurazioni a due e più regioni sono fortemente coerenti perché i metadati vengono sempre scritti in modo sincrono nelle regioni. Questo approccio consente al servizio di determinare sempre qual è l'ultima versione di un oggetto e da dove può essere pubblicata, incluse le regioni remote.
I dati vengono replicati in modo asincrono. Ciò significa che esiste una finestra temporale RPO in cui gli oggetti appena scritti iniziano a essere protetti come oggetti regionali, con ridondanza tra le zone di disponibilità all'interno di una singola regione. Il servizio replica quindi gli oggetti all'interno di questa finestra RPO in una o più regioni remote per renderli georidondanti. Una volta completata la replica, i dati possono essere pubblicati automaticamente e in modo trasparente da un'altra regione in caso di interruzione a livello regionale. La replica turbo è una funzionalità premium disponibile su un bucket a doppia regione per ottenere una finestra RPO più piccola, che ha come target il 100% degli oggetti appena scritti replicati e resi geograficamente ridondanti entro 15 minuti.
L'RPO è un aspetto importante da considerare, perché durante un'interruzione regionale, i dati scritti di recente nella regione interessata all'interno della finestra RPO potrebbero non essere ancora stati replicati in altre regioni. Di conseguenza, questi dati potrebbero non essere accessibili durante l'interruzione e potrebbero andare persi in caso di distruzione fisica dei dati nella regione interessata.
Cloud Translation
Cloud Translation dispone di server di calcolo attivi in più zone e regioni. Supporta anche la replica sincrona dei dati tra le zone all'interno delle regioni. Queste funzionalità consentono a Translation di eseguire il failover istantaneo senza alcuna perdita di dati in caso di errori di zona e senza richiedere input o aggiustamenti da parte del cliente. In caso di errore a livello di regione, Cloud Translation non è disponibile.
Compute Engine
Compute Engine è una delle opzioni di infrastructure as a service di Google Cloud. Utilizza l'infrastruttura mondiale di Google per offrire macchine virtuali (e servizi correlati) ai clienti.
Le istanze Compute Engine sono risorse di zona, quindi in caso di interruzione della zona le istanze non sono disponibili per impostazione predefinita. Compute Engine offre gruppi di istanze gestite (MIG) che possono scalare automaticamente le VM aggiuntive dai modelli di istanza preconfigurati, sia all'interno di una singola zona sia in più zone all'interno di una regione. I MIG sono ideali per le applicazioni che richiedono resilienza alla perdita di zona e sono stateless, ma richiedono pianificazione della configurazione e delle risorse. È possibile utilizzare più MIG a livello di regione per ottenere la resilienza in caso di interruzione a livello di regione per le applicazioni stateless.
Le applicazioni con workload stateful possono comunque utilizzare i MIG stateful, ma è necessario prestare particolare attenzione alla pianificazione della capacità, poiché non vengono scalati orizzontalmente. In entrambi gli scenari è importante configurare e testare correttamente i modelli di istanza Compute Engine e i MIG in anticipo per garantire funzionalità di failover funzionanti in altre zone. Per ulteriori informazioni, consulta la sezione Sviluppare architetture e guide di riferimento personalizzate riportata sopra.
Single-tenancy
La modalità single-tenancy ti consente di avere accesso esclusivo a un nodo single-tenant, ovvero un server Compute Engine fisico dedicato esclusivamente all'hosting delle VM del tuo progetto.
I nodi single-tenant, come le istanze Compute Engine, sono risorse di zona. Nell'improbabile caso di un'interruzione a livello di zona, non sono disponibili. Per mitigare gli errori a livello di zona, puoi creare un nodo single-tenant in un'altra zona. Poiché determinati workload potrebbero trarre vantaggio dai nodi single-tenant per scopi di contabilità delle licenze o CAPEX, devi pianificare in anticipo una strategia di failover.
La ricreazione di queste risorse in una posizione diversa potrebbe comportare costi di licenza aggiuntivi o violare i requisiti contabili CAPEX. Per indicazioni generali, consulta Sviluppare guide e architetture di riferimento personalizzate.
I nodi single-tenant sono risorse a livello di zona e non possono resistere a errori a livello di regione. Per scalare tra le zone, utilizza i gruppi di istanze gestite a livello di regione.
Networking per Compute Engine
Per informazioni sulle configurazioni ad alta disponibilità per le connessioni di interconnessione, consulta i seguenti documenti:
- Disponibilità del 99,99% per Dedicated Interconnect
- Disponibilità del 99,99% per Partner Interconnect
Puoi eseguire il provisioning degli indirizzi IP esterni in modalità globale o regionale, il che influisce sulla loro disponibilità in caso di errore regionale.
Resilienza di Cloud Load Balancing
I bilanciatori del carico sono una componente fondamentale della maggior parte delle applicazioni ad alta affidabilità. È importante capire che la resilienza dell'applicazione complessiva dipende non solo dall'ambito del bilanciatore del carico scelto (globale o regionale), ma anche dalla ridondanza dei servizi di backend.
La tabella seguente riepiloga la resilienza del bilanciatore del carico in base alla distribuzione o all'ambito del bilanciatore del carico.
| Ambito del bilanciatore del carico | Architettura | Resistente alle interruzioni a livello di zona | Resistente alle interruzioni regionali |
|---|---|---|---|
| Globale | Ogni bilanciatore del carico è distribuito in tutte le regioni | ||
| Tra regioni | Ogni bilanciatore del carico è distribuito in più regioni | ||
| Regionale | Ogni bilanciatore del carico è distribuito in più zone nella regione | Un'interruzione in una determinata regione influisce sui bilanciatori del carico a livello di regione in quella regione |
Per saperne di più sulla scelta di un bilanciatore del carico, consulta la documentazione di Cloud Load Balancing.
Connectivity Tests
Connectivity Tests è uno strumento di diagnostica che ti consente di verificare la connettività tra gli endpoint di rete. Analizza la tua configurazione e, in alcuni casi, esegue un'analisi del piano dati in tempo reale tra gli endpoint. Un endpoint è una sorgente o una destinazione di traffico di rete, ad esempio una VM, un cluster Google Kubernetes Engine (GKE), una regola di forwarding per il bilanciatore del carico o un indirizzo IP. Connectivity Tests è uno strumento di diagnostica senza componenti del piano dati. Non elabora né genera traffico utente.
Interruzione zonale:le risorse di Connectivity Tests sono globali. Puoi gestirli e visualizzarli in caso di interruzione zonale. Le risorse Connectivity Tests sono i risultati dei test di configurazione. Questi risultati potrebbero includere i dati di configurazione delle risorse di zona (ad esempio, le istanze VM) in una zona interessata. In caso di interruzione, i risultati dell'analisi non sono accurati perché si basano su dati obsoleti precedenti all'interruzione. Non fare affidamento su questo.
Interruzione regionale:in caso di interruzione regionale, puoi comunque gestire e visualizzare le risorse di Connectivity Tests. Le risorse Connectivity Tests potrebbero includere dati di configurazione di risorse regionali, come le subnet, in una regione interessata. In caso di interruzione, i risultati dell'analisi non sono accurati perché si basano su dati obsoleti precedenti all'interruzione. Non fare affidamento su questo.
Container Registry
Container Registry fornisce un'implementazione scalabile di Docker Registry ospitato che archivia in modo sicuro e privato le immagini dei container Docker. Container Registry implementa l'API HTTP Docker Registry.
Container Registry è un servizio globale che archivia in modo sincrono i metadati delle immagini in modo ridondante in più zone e regioni per impostazione predefinita. Le immagini container vengono archiviate in bucket multiregionali Cloud Storage. Con questa strategia di archiviazione, Container Registry offre la resilienza alle interruzioni zonali in tutti i casi e la resilienza alle interruzioni regionali per tutti i dati replicati in modo asincrono in più regioni da Cloud Storage.
Database Migration Service
Database Migration Service è un servizio Google Cloud completamente gestito per eseguire la migrazione dei database da altri cloud provider o da data center on-premise a Google Cloud.
Database Migration Service è progettato come un piano di controllo regionale. Il control plane non dipende da una singola zona in una determinata regione. Durante un'interruzione zonale, mantieni l'accesso alle API Database Migration Service, inclusa la possibilità di creare e gestire job di migrazione. Durante un'interruzione a livello di regione, perdi l'accesso alle risorse di Database Migration Service appartenenti a quella regione finché l'interruzione non viene risolta.
Database Migration Service dipende dalla disponibilità dei database di origine e di destinazione utilizzati per il processo di migrazione. Se un database di origine o di destinazione di Database Migration Service non è disponibile, le migrazioni smettono di avanzare, ma non vengono persi dati principali o dati dei job dei clienti. I job di migrazione riprendono quando i database di origine e di destinazione tornano disponibili.
Ad esempio, puoi configurare un database Cloud SQL di destinazione con l'alta disponibilità (HA) abilitata per ottenere un database di destinazione resiliente alle interruzioni zonali.
Le migrazioni di Database Migration Service si svolgono in due fasi:
- Dump completo: esegue una copia completa dei dati dall'origine alla destinazione in base alla specifica del job di migrazione.
- Change Data Capture (CDC): replica le modifiche incrementali dall'origine alla destinazione.
Interruzione zonale:se si verifica un errore zonale durante una di queste fasi, puoi comunque accedere e gestire le risorse in Database Migration Service. La migrazione dei dati è interessata come segue:
- Dump completo: la migrazione dei dati non riesce; devi riavviare il job di migrazione una volta che il database di destinazione completa l'operazione di failover.
- CDC: la migrazione dei dati è in pausa. Il job di migrazione riprende automaticamente una volta che il database di destinazione completa l'operazione di failover.
Interruzione regionale:Database Migration Service non supporta le risorse cross-region e pertanto non è resiliente agli errori regionali.
Dataflow
Dataflow è il servizio di elaborazione dei dati serverless e completamente gestito di Google Cloudper le pipeline di streaming e batch. Per impostazione predefinita, un endpoint regionale configura il pool di worker Dataflow in modo che utilizzi tutte le zone disponibili all'interno della regione. La selezione della zona viene calcolata per ogni worker al momento della creazione, ottimizzando l'acquisizione delle risorse e l'utilizzo delle prenotazioni inutilizzate. Nella configurazione predefinita per i job Dataflow, i dati intermedi vengono archiviati dal servizio Dataflow e lo stato del job viene archiviato nel backend. Se una zona non funziona, i job Dataflow possono continuare a essere eseguiti perché i worker vengono ricreati in altre zone.
Si applicano le seguenti limitazioni:
- Il posizionamento regionale è supportato solo per i job che utilizzano Streaming Engine o Dataflow Shuffle. I job che hanno disattivato Streaming Engine o Dataflow Shuffle non possono utilizzare il posizionamento regionale.
- Il posizionamento regionale si applica solo alle VM. Non si applica alle risorse correlate a Streaming Engine e Dataflow Shuffle.
- Le VM non vengono replicate in più zone. Se una VM non è più disponibile, i relativi elementi di lavoro vengono considerati persi e vengono rielaborati da un'altra VM.
- Se si verifica un esaurimento delle scorte a livello regionale, il servizio Dataflow non può creare altre VM.
Progettazione di pipeline Dataflow per l'alta disponibilità
Puoi eseguire più pipeline di streaming in parallelo per l'elaborazione dei dati ad alta disponibilità. Ad esempio, puoi eseguire due job di streaming paralleli in regioni diverse. L'esecuzione di pipeline parallele fornisce ridondanza geografica e tolleranza di errore per l'elaborazione dei dati. Se prendi in considerazione la disponibilità geografica delle origini e dei sink di dati, puoi gestire pipeline end-to-end in una configurazione multiregionale a disponibilità elevata. Per saperne di più, consulta Alta affidabilità e ridondanza geografica in "Progettare i flussi di lavoro della pipeline Dataflow".
In caso di interruzione a livello di zona o regione, puoi evitare la perdita di dati riutilizzando lo stesso abbonamento all'argomento Pub/Sub. Per garantire che i record non vengano persi durante l'operazione di rimescolamento, Dataflow utilizza il backup upstream, il che significa che il worker che invia i record ritenta le chiamate RPC finché non riceve una conferma positiva che il record è stato ricevuto e che gli effetti collaterali dell'elaborazione del record vengono salvati in modo permanente nello spazio di archiviazione downstream. Dataflow continua a riprovare le RPC se il worker che invia i record non è più disponibile. I nuovi tentativi di RPC garantiscono che ogni record venga consegnato esattamente una volta. Per saperne di più sulla garanzia exactly-once di Dataflow, vedi Exactly-once in Dataflow.
Se la pipeline utilizza il raggruppamento o le finestre temporali, puoi utilizzare la funzionalità di ricerca di Pub/Sub o la funzionalità di riproduzione di Kafka dopo un'interruzione zonale o regionale per rielaborare gli elementi di dati e ottenere gli stessi risultati di calcolo. Se la logica di business utilizzata dalla pipeline non si basa su dati precedenti all'interruzione, la perdita di dati degli output della pipeline può essere ridotta fino a 0 elementi. Se la logica di business della pipeline si basa su dati elaborati prima dell'interruzione (ad esempio, se vengono utilizzate finestre scorrevoli lunghe o se una finestra temporale globale memorizza contatori in continuo aumento), utilizza gli snapshot di Dataflow per salvare lo stato della pipeline di streaming e avviare una nuova versione del job senza perdere lo stato.
Dataproc
Dataproc fornisce funzionalità di elaborazione dei dati in modalità flusso e batch. Dataproc è progettato come un control plane regionale che consente agli utenti di gestire i cluster Dataproc. Il control plane non dipende da una singola zona in una determinata regione. Pertanto, durante un'interruzione di zona, mantieni l'accesso alle API Dataproc, inclusa la possibilità di creare nuovi cluster.
Puoi creare cluster Dataproc su:
Cluster Dataproc su Compute Engine
Poiché un cluster Dataproc su Compute Engine è una risorsa di zona, un'interruzione zonale rende il cluster non disponibile o lo distrugge. Dataproc non esegue automaticamente lo snapshot dello stato del cluster, pertanto un'interruzione della zona potrebbe causare la perdita dei dati in fase di elaborazione. Dataproc non conserva i dati utente all'interno del servizio. Gli utenti possono configurare le pipeline per scrivere i risultati in molti datastore. Devi considerare l'architettura del datastore e scegliere un prodotto che offra la resilienza al disaster recovery richiesta.
Se una zona subisce un'interruzione, puoi scegliere di ricreare una nuova istanza del cluster in un'altra zona selezionando una zona diversa o utilizzando la funzionalità di posizionamento automatico in Dataproc per selezionare automaticamente una zona disponibile. Una volta che il cluster è disponibile, l'elaborazione dei dati può riprendere. Puoi anche eseguire un cluster con la modalità ad alta affidabilità abilitata, riducendo la probabilità che un'interruzione parziale della zona influenzi un nodo master e, di conseguenza, l'intero cluster.
Cluster Dataproc su GKE
I cluster Dataproc su GKE possono essere zonali o regionali.
Per saperne di più sull'architettura e sulle funzionalità di RE dei cluster GKE zonali e regionali, consulta la sezione Google Kubernetes Engine più avanti in questo documento.
Datastream
Datastream è un servizio di replica e serverless Change Data Capture (CDC) che ti consente di sincronizzare i dati in modo affidabile e con latenza minima. Datastream fornisce la replica dei dati da database operativi in BigQuery e Cloud Storage. Inoltre, offre un'integrazione semplificata con i modelli Dataflow per creare flussi di lavoro personalizzati per il caricamento dei dati in un'ampia gamma di destinazioni, come Cloud SQL e Spanner.
Interruzione zonale:Datastream è un servizio multizonale. Può resistere a un'interruzione zonale completa e imprevista senza alcuna perdita di dati o disponibilità. In caso di errore a livello di zona, puoi comunque accedere e gestire le risorse in Datastream.
Interruzione a livello di regione:in caso di interruzione a livello di regione, Datastream torna disponibile non appena l'interruzione viene risolta.
Document AI
Document AI è una piattaforma di comprensione dei documenti che prende i dati non strutturati dai documenti e li trasforma in dati strutturati, rendendoli più facili da comprendere, analizzare e utilizzare. Document AI è un'offerta regionale. I clienti possono scegliere la regione, ma non le zone all'interno di quella regione. I dati e il traffico vengono bilanciati automaticamente tra le zone all'interno di una regione. I server vengono scalati automaticamente per soddisfare il traffico in entrata e vengono bilanciati tra le zone in base alle necessità. Ogni zona gestisce uno scheduler che fornisce questo scalabilità automatica per zona. Lo scheduler è anche a conoscenza del carico ricevuto dalle altre zone e fornisce capacità aggiuntiva all'interno della zona per consentire eventuali errori a livello di zona.
Interruzione zonale: Document AI archivia i documenti utente e i dati della versione del processore. Questi dati vengono archiviati a livello regionale e scritti in modo sincrono. Poiché i dati vengono archiviati a livello regionale, le operazioni del data plane non sono interessate da errori di zona. In caso di errore a livello di zona, il traffico viene indirizzato automaticamente ad altre zone, con un ritardo basato sul tempo necessario per il ripristino dei servizi dipendenti, come Vertex AI.
Interruzione regionale:i dati non vengono mai replicati tra le regioni. Durante un'interruzione regionale, Document AI non eseguirà il failover. I clienti scelgono la regione Google Cloud in cui vogliono utilizzare Document AI. Tuttavia, il traffico dei clienti non viene mai indirizzato a un'altra regione.
Verifica degli endpoint
La verifica degli endpoint consente agli amministratori e ai professionisti delle operazioni di sicurezza di creare un inventario dei dispositivi che accedono ai dati di un'organizzazione. La verifica degli endpoint fornisce anche controllo dell'accesso basato sulla sicurezza e sull'affidabilità dei dispositivi critici nell'ambito della soluzione Chrome Enterprise Premium.
Utilizza la verifica degli endpoint quando vuoi una panoramica della security posture dei laptop e dei computer desktop della tua organizzazione. Se abbinata alle offerte Chrome Enterprise Premium, la verifica degli endpoint consente di applicare controllo dell'accesso granulare alle tue risorse Google Cloud .
Verifica endpoint è disponibile per Google Cloud, Cloud Identity, Google Workspace Business e Google Workspace Enterprise.
Eventarc
Eventarc fornisce eventi distribuiti in modo asincrono da fornitori Google (proprietari), app utente (secondarie) e software come servizio (di terze parti) utilizzando servizi a basso accoppiamento che reagiscono ai cambiamenti di stato. Consente ai clienti di configurare le destinazioni (ad esempio un'istanza Cloud Run o una funzione Cloud Run di 2ª generazione) da attivare quando si verifica un evento in un servizio di provider di eventi o nel codice del cliente.
Interruzione zonale:Eventarc archivia i metadati relativi ai trigger. Questi dati vengono archiviati a livello regionale e scritti in modo sincrono. L'API Eventarc che crea e gestisce trigger e canali restituisce la chiamata API solo quando i dati sono stati inviati a un quorum all'interno di una regione. Poiché i dati vengono archiviati a livello regionale, le operazioni del data plane non sono interessate da errori zonali. In caso di errore a livello di zona, il traffico viene indirizzato automaticamente ad altre zone. I servizi Eventarc per la ricezione e la distribuzione di eventi di seconda e terza parte vengono replicati tra le zone. Questi servizi sono distribuiti a livello regionale. Le richieste alle zone non disponibili vengono gestite automaticamente dalle zone disponibili nella regione.
Interruzione regionale:i clienti scelgono la regione Google Cloud in cui vogliono creare i trigger Eventarc. I dati non vengono mai replicati tra regioni. Il traffico dei clienti non viene mai instradato da Eventarc a un'altra regione. In caso di errore regionale, Eventarc torna disponibile non appena l'interruzione viene risolta. Per ottenere una disponibilità più elevata, i clienti sono invitati a eseguire il deployment dei trigger in più regioni, se lo desiderano.
Tieni presente quanto segue:
- I servizi Eventarc per la ricezione e la distribuzione di eventi proprietari vengono forniti secondo il criterio del "best effort" e non sono coperti da RTO/RPO.
- La distribuzione di eventi Eventarc per i servizi Google Kubernetes Engine viene fornita in base al criterio del "best effort" e non è coperta da RTO/RPO.
Filestore
I livelli Basic e Zonale sono risorse a livello di zona. Non sono tolleranti ai guasti della zona o della regione di deployment.
Le istanze Filestore di livello regionale sono risorse regionali. Filestore adotta le norme di coerenza rigorose richieste da NFS. Quando un client scrive dati, Filestore non restituisce una conferma finché la modifica non viene resa persistente e replicata in due zone, in modo che le letture successive restituiscano i dati corretti.
In caso di errore a livello di zona, un'istanza del livello regionale continua a gestire i dati provenienti da altre zone e nel frattempo accetta nuove scritture. Sia le operazioni di lettura che quelle di scrittura potrebbero avere prestazioni ridotte; l'operazione di scrittura potrebbe non essere replicata. La crittografia non è compromessa perché la chiave verrà fornita da altre zone.
Consigliamo ai clienti di creare backup esterni in caso di ulteriori interruzioni in altre zone della stessa regione. Il backup può essere utilizzato per ripristinare l'istanza in altre regioni.
Firestore
Firestore è un database flessibile e scalabile per lo sviluppo mobile, web e server di Firebase e Google Cloud. Firestore offre replica automatica dei dati multiregione, garanzie di elevata coerenza, operazioni batch atomiche e transazioni ACID.
Firestore offre ai clienti località a regione singola e multiregionali. Il traffico viene bilanciato automaticamente tra le zone di una regione.
Le istanze Firestore regionali replicano i dati in modo sincrono in almeno tre zone. In caso di errore a livello di zona, le scritture possono comunque essere commitate dalle due (o più) repliche rimanenti e i dati di cui è stato eseguito il commit vengono salvati in modo permanente. Il traffico viene indirizzato automaticamente ad altre zone. Una località regionale offre costi inferiori, latenza di scrittura ridotta e collocamento insieme ad altre risorse Google Cloud.
Le istanze multiregionali Firestore replicano i dati in modo sincrono in cinque zone di tre regioni (due regioni di servizio e una regione di controllo) e sono robuste contro gli errori zonali e regionali. In caso di errore a livello di zona o di regione, i dati di cui è stato eseguito il commit vengono mantenuti. Il traffico viene indirizzato automaticamente alle zone/regioni di pubblicazione e gli impegni vengono comunque pubblicati da almeno tre zone nelle due regioni rimanenti. Le multiregioni massimizzano la disponibilità e la durabilità dei database.
Firewall Insights
Firewall Insights ti aiuta a comprendere e ottimizzare le tue regole firewall. Fornisce approfondimenti, suggerimenti e metriche sull'utilizzo delle regole firewall. Firewall Insights utilizza anche il machine learning per prevedere l'utilizzo futuro delle regole firewall. Firewall Insights ti consente di prendere decisioni migliori durante l'ottimizzazione delle regole firewall. Ad esempio, Firewall Insights identifica le regole che classifica come eccessivamente permissive. Puoi utilizzare queste informazioni per rendere più rigorosa la configurazione del firewall.
Interruzione zonale:poiché i dati di Firewall Insights vengono replicati in più zone, non sono interessati da un'interruzione zonale e il traffico dei clienti viene indirizzato automaticamente ad altre zone.
Interruzione regionale:poiché i dati di Firewall Insights vengono replicati in più regioni, non sono interessati da un'interruzione regionale e il traffico dei clienti viene indirizzato automaticamente ad altre regioni.
Parco risorse
I parchi risorse consentono ai clienti di gestire più cluster Kubernetes come gruppo e agli amministratori della piattaforma di utilizzare i servizi multi-cluster. Ad esempio, i parchi risorse consentono agli amministratori di applicare criteri uniformi in tutti i cluster o di configurare Ingress multicluster.
Quando registri un cluster GKE in un parco risorse, per impostazione predefinita il cluster ha un'appartenenza regionale nella stessa regione. Quando registri un cluster nonGoogle Cloud in un parco risorse, puoi scegliere qualsiasi regione o la posizione globale. La best practice consiste nello scegliere una regione vicina alla posizione fisica del cluster. Ciò garantisce una latenza ottimale quando utilizzi Connect Gateway per accedere al cluster.
In caso di interruzione a livello di zona, le funzionalità del parco risorse non sono interessate, a meno che il cluster sottostante non sia zonale e non sia più disponibile.
In caso di interruzione a livello di regione, le funzionalità del parco veicoli non funzionano in modo statico per i cluster di appartenenza nella regione. La mitigazione di un'interruzione regionale richiede il deployment in più regioni, come suggerito in Progettazione ripristino di emergenza per interruzioni dell'infrastruttura cloud.
Google Cloud Armor
Cloud Armor ti aiuta a proteggere i tuoi deployment e le tue applicazioni da diversi tipi di minacce, inclusi attacchi DDoS volumetrici e attacchi alle applicazioni come cross-site scripting e SQL injection. Cloud Armor filtra il traffico indesiderato nei bilanciatori del carico Google Cloud e impedisce a questo traffico di entrare nel tuo VPC e consumare risorse. Alcune di queste protezioni sono automatiche. Alcuni richiedono di configurare criteri di sicurezza e collegarli a servizi di backend o regioni. I criteri di sicurezza di Cloud Armor con ambito globale vengono applicati ai bilanciatori del carico globali. Le policy di sicurezza con ambito regionale vengono applicate ai bilanciatori del carico regionali.
Interruzione del servizio a livello di zona:in caso di interruzione del servizio a livello di zona, i bilanciatori del carico Google Cloud reindirizzano il traffico ad altre zone in cui sono disponibili istanze di backend integre. La protezione Cloud Armor è disponibile immediatamente dopo il failover del traffico perché le policy di sicurezza Cloud Armor vengono replicate in modo sincrono in tutte le zone di una regione.
Interruzione a livello di regione:in caso di interruzioni a livello di regione, i bilanciatori del carico globali Google Cloud reindirizzano il traffico ad altre regioni in cui sono disponibili istanze di backend integre. La protezione Cloud Armor è disponibile immediatamente dopo il failover del traffico perché i criteri di sicurezza Cloud Armor globali vengono replicati in modo sincrono in tutte le regioni. Per garantire la resilienza contro i guasti a livello regionale, devi configurare le policy di sicurezza regionali di Cloud Armor per tutte le tue regioni.
Google Kubernetes Engine
Google Kubernetes Engine (GKE) offre un servizio Kubernetes gestito semplificando il deployment delle applicazioni containerizzate su Google Cloud. Puoi scegliere tra topologie di cluster regionali o zonali.
- Quando crei un cluster zonale, GKE esegue il provisioning di una macchina del piano di controllo nella zona scelta, nonché di macchine worker (nodi) all'interno della stessa zona.
- Per i cluster regionali, GKE esegue il provisioning di tre macchine del piano di controllo in tre zone diverse all'interno della regione scelta. Per impostazione predefinita, i nodi sono distribuiti anche su tre zone, anche se puoi scegliere di creare un cluster regionale con nodi di cui è stato eseguito il provisioning solo in una zona.
- I cluster multizona sono simili ai cluster di zona in quanto includono una macchina master, ma offrono anche la possibilità di estendere i nodi su più zone.
Interruzione a livello di zona:per evitare interruzioni a livello di zona, utilizza i cluster regionali. Il piano di controllo e i nodi sono distribuiti in tre zone diverse all'interno di una regione. Un'interruzione della zona non influisce sul control plane e sui nodi worker di cui è stato eseguito il deployment nelle altre due zone.
Interruzione regionale: la mitigazione di un'interruzione regionale richiede il deployment in più regioni. Sebbene al momento non sia offerta come funzionalità integrata del prodotto, la topologia multiregionale è un approccio adottato oggi da diversi clienti GKE e può essere implementata manualmente. Puoi creare più cluster regionali per replicare i tuoi workload in più regioni e controllare il traffico verso questi cluster utilizzando Ingress multi-cluster.
VPN ad alta disponibilità
La VPN ad alta disponibilità è un'offerta Cloud VPN resiliente che cripta in modo sicuro il traffico dal tuo cloud privato on-premise, da un altro Virtual Private Cloud o da un'altra rete di un cloud service provider al tuo Virtual Private Cloud (VPC) di Google Cloud.
I gateway VPN ad alta disponibilità hanno due interfacce, ciascuna con un indirizzo IP proveniente da pool di indirizzi IP separati, suddivisi sia logicamente che fisicamente in diversi PoP e cluster, per garantire una ridondanza ottimale.
Interruzione zonale: in caso di interruzione zonale, un'interfaccia potrebbe perdere la connettività, ma il traffico viene reindirizzato all'altra interfaccia tramite il routing dinamico utilizzando il protocollo BGP (Border Gateway Protocol).
Interruzione a livello regionale: in caso di interruzione a livello regionale, entrambe le interfacce potrebbero perdere la connettività per un breve periodo.
Identity and Access Management
Identity and Access Management (IAM) è responsabile di tutte le decisioni di autorizzazione
per le azioni sulle risorse cloud. IAM conferma che un criterio concede
l'autorizzazione per ogni azione (nel piano dati) ed elabora gli aggiornamenti di questi criteri
tramite una chiamata SetPolicy (nel control plane).
Tutti i criteri IAM vengono replicati in più zone all'interno di ogni regione, contribuendo a ripristinare le operazioni del data plane IAM in caso di errori di altre regioni e tollerando gli errori di zona all'interno di ogni regione. La resilienza del piano dati IAM ai guasti di zona e di regione consente architetture multiregionali e multizona per l'alta disponibilità.
Le operazioni del piano di controllo IAM possono dipendere dalla replica tra regioni. Quando le chiamate SetPolicy hanno esito positivo, i dati vengono scritti in più regioni, ma la propagazione ad altre regioni è coerente nel tempo.
Il control plane IAM è resiliente agli errori di una singola regione.
Identity-Aware Proxy
Identity-Aware Proxy fornisce l'accesso alle applicazioni ospitate su Google Cloud, su altri cloud e on-premise. IAP è distribuito a livello regionale e le richieste alle zone non disponibili vengono gestite automaticamente da altre zone disponibili nella regione.
Le interruzioni regionali di IAP influiscono sull'accesso alle applicazioni ospitate nella regione interessata. Ti consigliamo di eseguire il deployment in più regioni e di utilizzare Cloud Load Balancing per ottenere una maggiore disponibilità e resilienza in caso di interruzioni a livello regionale.
Identity Platform
Identity Platform consente ai clienti di aggiungere alle proprie app una gestione di identità e accessi personalizzabile di livello Google. Identity Platform è un'offerta globale. I clienti non possono scegliere le regioni o le zone in cui vengono archiviati i loro dati.
Interruzione zonale: durante un'interruzione zonale, Identity Platform esegue il failover delle richieste alla cella più vicina successiva. Tutti i dati vengono salvati su scala globale, quindi non vengono persi.
Interruzione a livello di regione: durante un'interruzione a livello di regione, le richieste di Identity Platform alla regione non disponibile non vanno a buon fine temporaneamente mentre Identity Platform rimuove il traffico dalla regione interessata. Quando non c'è più traffico verso la regione interessata, un servizio di bilanciamento del carico del server globale indirizza le richieste alla regione integra disponibile più vicina. Tutti i dati vengono salvati a livello globale, quindi non si verifica alcuna perdita di dati.
Knative serving
Knative serving è un servizio globale che consente ai clienti di eseguire carichi di lavoro serverless sui cluster dei clienti. Il suo scopo è garantire che i carichi di lavoro di Knative Serving vengano implementati correttamente nei cluster dei clienti e che lo stato di installazione di Knative Serving venga riflesso nella risorsa della funzionalità dell'API GKE Fleet. Questo servizio interviene solo durante l'installazione o l'upgrade delle risorse Knative Serving sui cluster dei clienti. Non è coinvolto nell'esecuzione dei carichi di lavoro del cluster. I cluster dei clienti appartenenti a progetti in cui è abilitato Knative Serving sono distribuiti tra le repliche in più regioni e zone. Ogni cluster viene monitorato da una replica.
Interruzione zonale e regionale:i cluster monitorati dalle repliche ospitate in una località interessata da un'interruzione vengono ridistribuiti automaticamente tra le repliche integre in altre zone e regioni. Mentre il riassegnamento è in corso, potrebbe verificarsi un breve periodo di tempo in cui alcuni cluster non vengono monitorati da Knative Serving. Se durante questo periodo l'utente decide di attivare le funzionalità di Knative serving sul cluster, l'installazione delle risorse di Knative serving sul cluster inizierà dopo che il cluster si sarà riconnesso a una replica del servizio Knative serving integra.
Looker (Google Cloud core)
Looker (Google Cloud core) è una piattaforma di business intelligence che fornisce provisioning, configurazione e gestione semplificati e senza problemi di un'istanza di Looker dalla console Google Cloud . Looker (Google Cloud core) consente agli utenti di esplorare i dati, creare dashboard, configurare avvisi e condividere report. Inoltre, Looker (Google Cloud core) offre un IDE per i modellatori di dati e funzionalità di incorporamento e API avanzate per gli sviluppatori.
Looker (Google Cloud core) è composto da istanze isolate a livello regionale che replicano i dati in modo sincrono tra le zone all'interno della regione. Assicurati che le risorse utilizzate dall'istanza, ad esempio le origini dati a cui si connette Looker (Google Cloud core), si trovino nella stessa regione in cui viene eseguita l'istanza.
Interruzione zonale: le istanze di Looker (Google Cloud core) archiviano i metadati e i propri container di cui è stato eseguito il deployment. I dati vengono scritti in modo sincrono nelle istanze duplicate. In caso di interruzione a livello di zona, le istanze di Looker (Google Cloud core) continuano a gestire le altre zone disponibili della stessa regione. Qualsiasi transazione o chiamata API viene restituita dopo che i dati sono stati inviati a un quorum all'interno di una regione. Se la replica non riesce, la transazione non viene eseguita e l'utente viene informato dell'errore. Se si verifica un errore in più di una zona, anche le transazioni non vanno a buon fine e l'utente viene avvisato. Looker (Google Cloud core) interrompe qualsiasi pianificazione o query attualmente in esecuzione. Devi ripianificarli o metterli di nuovo in coda dopo aver risolto l'errore.
Interruzione regionale: le istanze di Looker (Google Cloud core) all'interno della regione interessata non sono disponibili. Looker (Google Cloud core) interrompe tutte le pianificazioni o le query attualmente in esecuzione. Dopo aver risolto l'errore, devi riprogrammare o mettere in coda di nuovo le query. Puoi creare manualmente nuove istanze in una regione diversa. Puoi anche recuperare le istanze utilizzando la procedura definita in Importa o esporta i dati da un'istanza di Looker (Google Cloud core). Ti consigliamo di configurare un processo di esportazione periodica dei dati per copiare gli asset in anticipo, nell'improbabile caso di un'interruzione del servizio in una regione.
Looker Studio
Looker Studio è un prodotto per la visualizzazione dei dati e la business intelligence. Consente ai clienti di collegarsi ai dati archiviati in altri sistemi, creare report e dashboard utilizzando questi dati e condividerli all'interno dell'organizzazione. Looker Studio è un servizio globale e non consente agli utenti di selezionare un ambito delle risorse.
In caso di interruzione a livello di zona, Looker Studio continua a gestire le richieste provenienti da un'altra zona della stessa regione o di una regione diversa senza interruzioni. Gli asset utente vengono replicati in modo sincrono tra le regioni. Pertanto, non si verifica alcuna perdita di dati.
In caso di interruzione a livello di regione, Looker Studio continua a gestire le richieste provenienti da un'altra regione senza interruzioni. Gli asset utente vengono replicati in modo sincrono tra le regioni. Pertanto, non si verifica alcuna perdita di dati.
Memorystore for Memcached
Memorystore for Memcached è l'offerta Memcached gestita di Google Cloud. Memorystore for Memcached consente ai clienti di creare cluster Memcached che possono essere utilizzati come database chiave-valore ad alta velocità effettiva per le applicazioni.
I cluster Memcached sono regionali, con nodi distribuiti in tutte le zone specificate dal cliente. Tuttavia, Memcached non replica i dati tra i nodi. Pertanto, un errore a livello di zona può causare la perdita di dati, descritta anche come svuotamento parziale della cache. Le istanze Memcached continueranno a funzionare, ma avranno meno nodi: il servizio non avvierà nuovi nodi durante un errore di zona. I nodi Memcached nelle zone non interessate continueranno a gestire il traffico, anche se l'errore a livello di zona comporterà una percentuale di successo della cache inferiore fino al ripristino della zona.
In caso di errore a livello di regione, i nodi Memcached non gestiscono il traffico. In questo caso, i dati vengono persi, il che comporta uno svuotamento completo della cache. Per mitigare un'interruzione regionale, puoi implementare un'architettura che esegue il deployment dell'applicazione e di Memorystore for Memcached in più regioni.
Memorystore for Redis
Memorystore per Redis è un servizio Redis completamente gestito per Google Cloud che può ridurre l'onere della gestione di deployment Redis complessi. Al momento offre due livelli: livello base e Standard. Per il livello Basic, un'interruzione a livello di zona o regione causerà la perdita di dati, nota anche come svuotamento completo della cache. Per il livello Standard, un'interruzione a livello regionale causerà la perdita di dati. Un'interruzione a livello di zona potrebbe causare una perdita parziale di dati per l'istanza di livello Standard a causa della replica asincrona.
Interruzione zonale:le istanze di livello standard replicano in modo asincrono le operazioni del set di dati dal set di dati nel nodo primario al nodo di replica. Quando si verifica l'interruzione all'interno della zona del nodo primario, il nodo di replica viene promosso a nodo primario. Durante la promozione, si verifica un failover e il client Redis deve riconnettersi all'istanza. Dopo la riconnessione, le operazioni riprendono. Per saperne di più sull'alta disponibilità delle istanze Memorystore for Redis nel livello Standard, consulta la pagina Alta disponibilità di Memorystore for Redis.
Se abiliti le repliche di lettura nell'istanza di livello standard e hai una sola replica, l'endpoint di lettura non è disponibile per la durata di un'interruzione zonale. Per saperne di più sul ripristino di emergenza delle repliche di lettura, consulta Modalità di errore per le repliche di lettura.
Interruzione regionale:Memorystore for Redis è un prodotto regionale, quindi una singola istanza non può resistere a un errore regionale. Puoi pianificare attività periodiche per esportare un'istanza Redis in un bucket Cloud Storage in una regione diversa. Quando si verifica un'interruzione a livello regionale, puoi ripristinare l'istanza Redis in una regione diversa dal set di dati che hai esportato.
Multi-Cluster Service Discovery e Ingress multi-cluster
GKE multi-cluster Services (MCS) è costituito da più componenti. I componenti includono l'hub Google Kubernetes Engine (che orchestra più cluster Google Kubernetes Engine utilizzando le appartenenze), i cluster stessi e i controller hub GKE (ingress multi-cluster, rilevamento del servizio multi-cluster). I controller hub orchestrano la configurazione del bilanciatore del carico di Compute Engine utilizzando i backend su più cluster.
In caso di interruzione a livello di zona, Multi-Cluster Service Discovery continua a gestire le richieste da un'altra zona o regione. In caso di interruzione a livello regionale, il servizio Service Discovery multi-cluster non esegue il failover.
In caso di interruzione a livello di zona per Ingress multi-cluster, se il cluster di configurazione è a livello di zona e rientra nell'ambito dell'errore, l'utente deve eseguire manualmente il failover. Il piano di dati è fail-static e continuerà a gestire il traffico finché l'utente non avrà eseguito il failover. Per evitare la necessità di un failover manuale, utilizza un cluster regionale per il cluster di configurazione.
In caso di interruzione a livello di regione, Ingress multi-cluster non esegue il failover. Gli utenti devono avere un pianoREa per il failover manuale del cluster di configurazione. Per maggiori informazioni, consulta Configurazione di Ingress multi-cluster e Configurazione dei servizi multi-cluster.
Per saperne di più su GKE, consulta la sezione "Google Kubernetes Engine" in Progettazione ripristino di emergenza per interruzioni dell'infrastruttura cloud.
Network Analyzer
Network Analyzer monitora automaticamente le configurazioni di rete VPC e rileva configurazioni errate e configurazioni non ottimali. Fornisce approfondimenti su topologia di rete, regole firewall, route, dipendenze di configurazione e connettività a servizi e applicazioni. Identifica gli errori di rete, fornisce informazioni sulla causa principale e suggerisce possibili soluzioni.
Network Analyzer viene eseguito continuamente e attiva analisi pertinenti in base agli aggiornamenti della configurazione quasi in tempo reale nella tua rete. Se Network Analyzer rileva un errore di rete, tenta di correlarlo alle recenti modifiche alla configurazione per identificare le cause principali. Ove possibile, fornisce consigli per suggerire dettagli su come risolvere i problemi.
Network Analyzer è uno strumento di diagnostica senza componenti del piano dati. Non elabora né genera traffico utente.
Interruzione a livello di zona: il servizio Network Analyzer viene replicato a livello globale e la sua disponibilità non è interessata da un'interruzione a livello di zona.
Se gli insight di Network Analyzer contengono configurazioni di una zona interessata da un'interruzione, la qualità dei dati ne risente. Le statistiche sulla rete che fanno riferimento alle configurazioni in quella zona diventano obsolete. Non fare affidamento sugli insight forniti da Network Analyzer durante le interruzioni.
Interruzione a livello di regione:il servizio Network Analyzer viene replicato a livello globale e la sua disponibilità non è interessata da un'interruzione a livello di regione.
Se gli insight di Network Analyzer contengono configurazioni di una regione interessata da un'interruzione, la qualità dei dati ne risente. Le statistiche sulla rete che si riferiscono alle configurazioni in quella regione diventano obsolete. Non fare affidamento sugli insight forniti da Network Analyzer durante le interruzioni.
Network Topology
Network Topology è uno strumento di visualizzazione che mostra la topologia dell'infrastruttura di rete. La visualizzazione Infrastruttura mostra le reti VPC (Virtual Private Cloud), la connettività ibrida da e verso le reti on-premise, la connettività ai servizi gestiti da Google e le metriche associate.
Interruzione a livello di zona:in caso di interruzione a livello di zona, i dati per quella zona non verranno visualizzati in Network Topology. I dati per le altre zone non sono interessati.
Interruzione a livello regionale:in caso di interruzione a livello regionale, i dati per quella regione non verranno visualizzati in Network Topology. I dati per altre regioni non sono interessati.
Performance Dashboard
Performance Dashboard ti offre visibilità sulle prestazioni dell'intera rete Google Cloud , nonché sulle prestazioni delle risorse del tuo progetto.
Grazie a queste funzionalità di monitoraggio delle prestazioni, puoi distinguere tra un problema nell'applicazione e un problema nella rete Google Cloud sottostante. Puoi anche esaminare i problemi storici di rendimento della rete. Performance Dashboard esporta anche i dati in Cloud Monitoring. Puoi utilizzare Monitoring per eseguire query sui dati e accedere a informazioni aggiuntive.
Interruzione zonale:
In caso di interruzione zonale, i dati relativi a latenza e perdita di pacchetti per il traffico dalla zona interessata non vengono visualizzati in Performance Dashboard. I dati sulla latenza e sulla perdita di pacchetti per il traffico proveniente da altre zone non sono interessati. Al termine dell'interruzione, i dati su latenza e perdita di pacchetti riprendono.
Interruzione regionale:
In caso di interruzione a livello regionale, i dati relativi a latenza e perdita di pacchetti per il traffico proveniente dalla regione interessata non vengono visualizzati in Performance Dashboard. I dati sulla latenza e sulla perdita di pacchetti per il traffico proveniente da altre regioni non sono interessati. Al termine dell'interruzione, i dati su latenza e perdita di pacchetti riprendono.
Network Connectivity Center
Network Connectivity Center è un prodotto per la gestione della connettività di rete che utilizza un'architettura hub e spoke. Con questa architettura, una risorsa di gestione centrale funge da hub e ogni risorsa di connettività funge da spoke. Gli spoke ibridi attualmente supportano VPN ad alta disponibilità, Dedicated Interconnect e Partner Interconnect e appliance router SD-WAN dei principali fornitori di terze parti. Con gli hub ibridi di Network Connectivity Center, le aziende possono connettere Google Cloud carichi di lavoro e servizi a data center on-premise, altri cloud e le loro filiali tramite la copertura globale della rete Google Cloud .
Interruzione zonale: un hub ibrido Network Connectivity Center con configurazione HA è resiliente agli errori zonali perché il control plane e il data plane di rete sono ridondanti in più zone all'interno di una regione.
Interruzione a livello di regione:uno spoke ibrido di Network Connectivity Center è una risorsa di regione, quindi non può resistere a un errore regionale.
Network Service Tiers
Network Service Tiers ti consente di ottimizzare la connettività tra i sistemi su internet e le tue istanze Google Cloud . Offre due livelli di servizio distinti: Premium e Standard. Con il livello Premium, un indirizzo IP anycast di livello Premium annunciato a livello globale può fungere da frontend per i backend regionali o globali. Con il livello Standard, un indirizzo IP di livello Standard annunciato a livello regionale può fungere da frontend per i backend regionali. La resilienza complessiva di un'applicazione è influenzata sia dal livello di servizio di rete sia dalla ridondanza dei backend a cui è associata.
Interruzione a livello di zona:sia il livello Premium che quello Standard offrono resilienza alle interruzioni a livello di zona se associati a backend con ridondanza a livello regionale. Quando si verifica un'interruzione zonale, il comportamento di failover per i casi che utilizzano backend ridondanti a livello di regione è determinato dai backend associati. Se associato a backend di zona, il servizio tornerà disponibile non appena l'interruzione verrà risolta.
Interruzione a livello di regione:il livello Premium offre resilienza alle interruzioni a livello di regione quando è associato a backend con ridondanza globale. Nel livello Standard, tutto il traffico verso la regione interessata non andrà a buon fine. Il traffico verso tutte le altre regioni non è interessato. Quando si verifica un'interruzione a livello di regione, il comportamento di failover per i casi che utilizzano il livello Premium con backend ridondanti a livello globale è determinato dai backend associati stessi. Quando utilizzi il livello Premium con backend regionali o il livello Standard, il servizio tornerà disponibile non appena l'interruzione verrà risolta.
Servizio Criteri dell'organizzazione
Il servizio Policy dell'organizzazione fornisce un controllo centralizzato e programmatico sulle risorse della tua organizzazione. Google Cloud In qualità di amministratore dei criteri dell'organizzazione, puoi configurare i vincoli nell'intera gerarchia delle risorse.
Interruzione zonale:tutti i criteri dell'organizzazione creati da Organization Policy Service vengono replicati in modo asincrono in più zone all'interno di ogni regione. I dati dei criteri dell'organizzazione e le operazioni del piano di controllo sono tolleranti agli errori di zona all'interno di ogni regione.
Interruzione a livello regionale: tutti i criteri dell'organizzazione creati da Organization Policy Service vengono replicati in modo asincrono in più regioni. Le operazioni del control plane di Organization Policy vengono scritte in più regioni e la propagazione ad altre regioni è coerente in pochi minuti. Il control plane di Organization Policy è resiliente al guasto di una singola regione. Le operazioni del piano dati di Organization Policy possono essere ripristinate in caso di errori in altre regioni e la resilienza del piano dati di Organization Policy a errori di zona e di regione consente architetture multiregionali e multizona per l'alta disponibilità.
Mirroring pacchetto
Mirroring pacchetto clona il traffico delle istanze specificate nella rete Virtual Private Cloud (VPC) e inoltra i dati clonati alle istanze dietro un bilanciatore del carico interno regionale per l'esame. Mirroring pacchetto acquisisce tutto il traffico e i dati dei pacchetti, inclusi payload e intestazioni.
Per ulteriori informazioni sulla funzionalità di Mirroring pacchetto, consulta la pagina di panoramica di Packet Mirroring.
Interruzione zonale:configura il bilanciatore del carico interno in modo che siano presenti istanze in più zone. In caso di interruzione a livello di zona, Mirroring pacchetto reindirizza i pacchetti clonati a una zona integra.
Interruzione regionale:Mirroring pacchetto è un prodotto regionale. Se si verifica un'interruzione regionale, i pacchetti nella regione interessata non vengono clonati.
Persistent Disk
I dischi permanenti sono disponibili in configurazioni a livello di zona e di regione.
I Persistent Disk a livello di zona sono ospitati in una singola zona. Se la zona del disco non è disponibile, il Persistent Disk non è disponibile finché l'interruzione della zona non viene risolta.
I dischi permanenti regionali forniscono la replica sincrona dei dati tra due zone in una regione. In caso di interruzione nella zona della macchina virtuale, puoi forzare il collegamento di un Persistent Disk regionale a un'istanza VM nella zona secondaria del disco. Per eseguire questa attività, devi avviare un'altra istanza VM in quella zona o mantenere un'istanza VM di standby attivo in quella zona.
Per replicare in modo asincrono i dati in un disco permanente tra regioni, puoi utilizzare la replica asincrona del disco permanente (PD Async Replication), che fornisce una replica dell'archiviazione a blocchi con RTO e RPO bassi per il RE attivo-passivo tra regioni. Nell'improbabile caso di un'interruzione in una regione, PD Async Replication consente di eseguire il failover dei dati in una regione secondaria e di riavviare il workload in quella regione.
Personalized Service Health
Personalized Service Health comunica le interruzioni del servizio pertinenti ai tuoi progetti Google Cloud . Fornisce più canali e processi per visualizzare o integrare eventi di interruzione (incidenti, manutenzione pianificata) nel processo di risposta agli incidenti, tra cui:
- Una dashboard nella console Google Cloud
- Un'API di servizio
- Avvisi configurabili
- Log generati e inviati a Cloud Logging
Interruzione zonale:i dati vengono forniti da un database globale senza dipendenza da località specifiche. Se si verifica un'interruzione a livello di zona, Service Health è in grado di gestire le richieste e reindirizzare automaticamente il traffico alle zone della stessa regione che funzionano ancora. Service Health può restituire le chiamate API correttamente se è in grado di recuperare i dati sugli eventi dal database Service Health.
Interruzione a livello regionale:i dati vengono pubblicati da un database globale senza dipendenza da località specifiche. In caso di interruzione regionale, Service Health è comunque in grado di gestire le richieste, ma potrebbe funzionare con capacità ridotta. Errori regionali nelle località di Logging potrebbero influire sugli utenti di Service Health che utilizzano i log o le notifiche di avviso del cloud.
Private Service Connect
Private Service Connect è una funzionalità di Google Cloud networking che consente ai consumer di accedere ai servizi gestiti privatamente dall'interno della propria rete VPC. Allo stesso modo, consente ai producer di servizi gestiti di ospitare questi servizi nelle proprie reti VPC separate e di offrire una connessione privata ai propri consumer.
Endpoint Private Service Connect per servizi pubblicati
Un endpoint Private Service Connect si connette ai servizi nella rete VPC dei producer di servizi utilizzando una regola di forwarding Private Service Connect. Il producer di servizi fornisce un servizio utilizzando la connettività privata a un consumer di servizi, esponendo un unico collegamento al servizio. Il consumer di servizi potrà quindi assegnare un indirizzo IP virtuale dalla propria VPC per questo servizio.
Interruzione zonale:il traffico Private Service Connect proveniente dal traffico VM generato dagli endpoint client VPC consumer può comunque accedere ai servizi gestiti esposti sulla rete VPC interna del producer di servizi. Questo accesso è possibile perché il traffico Private Service Connect esegue il failover su backend di servizio più integri in una zona diversa.
Interruzione a livello regionale: Private Service Connect è un prodotto regionale. Non è resiliente alle interruzioni del servizio a livello di regione. I servizi gestiti multiregionali possono ottenere un'alta disponibilità durante un'interruzione regionale configurando endpoint Private Service Connect in più regioni.
Endpoint Private Service Connect per le API di Google
Un endpoint Private Service Connect si connette alle API di Google utilizzando una regola di forwarding Private Service Connect. Questa regola di forwarding consente ai clienti di utilizzare nomi di endpoint personalizzati con i propri indirizzi IP interni.
Interruzione zonale:il traffico Private Service Connect dagli endpoint client VPC consumer può comunque accedere alle API di Google perché la connettività tra la VM e l'endpoint eseguirà automaticamente il failover in un'altra zona funzionale nella stessa regione. Le richieste già in corso quando inizia un'interruzione dipenderanno dal comportamento di timeout e di nuovi tentativi TCP del client per il recupero.
Per maggiori dettagli, consulta Recupero di Compute Engine.
Interruzione a livello regionale: Private Service Connect è un prodotto regionale. Non è resiliente alle interruzioni del servizio a livello di regione. I servizi gestiti multiregionali possono ottenere un'alta disponibilità durante un'interruzione regionale configurando endpoint Private Service Connect in più regioni.
Per saperne di più su Private Service Connect, consulta la sezione "Endpoint" in Tipi di Private Service Connect.
Pub/Sub
Pub/Sub è un servizio di messaggistica per l'integrazione di applicazioni e l'analisi dei flussi di dati. Gli argomenti Pub/Sub sono globali, il che significa che sono visibili e accessibili da qualsiasi posizione. Google Cloud Tuttavia, ogni messaggio viene archiviato in una singola regione Google Cloud , la più vicina all'editore e consentita dal criterio di località delle risorse. Pertanto, un argomento può avere messaggi archiviati in diverse regioni in Google Cloud. Il criterio di archiviazione dei messaggi di Pub/Sub può limitare le regioni in cui vengono archiviati i messaggi.
Interruzione zonale:quando viene pubblicato un messaggio Pub/Sub, viene scritto in modo sincrono nell'archiviazione in almeno due zone all'interno della regione. Pertanto, se una singola zona non è più disponibile, non si verifica alcun impatto visibile ai clienti.
Interruzione a livello di regione: durante un'interruzione a livello di regione, i messaggi archiviati nella regione interessata non sono accessibili. Gli editori e gli abbonati che si connetterebbero alla regione interessata, tramite un endpoint regionale o l'endpoint globale, non possono connettersi. Gli editori e gli abbonati che si connettono ad altre regioni possono comunque connettersi e i messaggi disponibili in altre regioni vengono inviati agli abbonati più vicini alla rete che hanno capacità.
Se la tua applicazione si basa sull'ordine dei messaggi, esamina i suggerimenti dettagliati del team Pub/Sub. Le garanzie di ordinamento dei messaggi vengono fornite in base alla regione e possono essere interrotte se utilizzi un endpoint globale.
reCAPTCHA
reCAPTCHA è un servizio globale che rileva attività fraudolente, spam e comportamenti illeciti. Non richiede né consente la configurazione per la resilienza regionale o zonale. Gli aggiornamenti ai metadati di configurazione vengono replicati in modo asincrono in ogni regione in cui viene eseguito reCAPTCHA.
In caso di interruzione a livello di zona, reCAPTCHA continua a gestire le richieste provenienti da un'altra zona della stessa regione o di una regione diversa senza interruzioni.
In caso di interruzione a livello di regione, reCAPTCHA continua a gestire le richieste provenienti da un'altra regione senza interruzioni.
Secret Manager
Secret Manager è un prodotto di gestione di secret e credenziali perGoogle Cloud. Con Secret Manager, puoi controllare e limitare facilmente l'accesso ai secret, criptarli a riposo e assicurarti che le informazioni sensibili siano protette in Google Cloud.
Le risorse Secret Manager vengono normalmente create con la policy di replica automatica (consigliata), che ne causa la replica a livello globale. Se la tua organizzazione dispone di criteri che non consentono la replica globale dei dati secret, le risorse Secret Manager possono essere create con criteri di replica gestiti dall'utente, in cui vengono scelte una o più regioni in cui replicare un secret.
Interruzione a livello di zona:in caso di interruzione a livello di zona, Secret Manager continua a gestire le richieste provenienti da un'altra zona nella stessa regione o in una regione diversa senza interruzioni. All'interno di ogni regione, Secret Manager mantiene sempre almeno due repliche in zone separate (nella maggior parte delle regioni, tre repliche). Quando l'interruzione della zona viene risolta, la ridondanza completa viene ripristinata.
Interruzione a livello di regione:in caso di interruzione a livello di regione, Secret Manager continua a gestire le richieste provenienti da un'altra regione senza interruzioni, a condizione che i dati siano stati replicati in più di una regione (tramite replica automatica o tramite replica gestita dall'utente in più di una regione). Quando l'interruzione a livello di regione viene risolta, viene ripristinata la ridondanza completa.
Security Command Center
Security Command Center è la piattaforma globale di gestione dei rischi in tempo reale per Google Cloud. È composto da due componenti principali: i rilevatori e i risultati.
I rilevatori sono interessati da interruzioni regionali e di zona, in modi diversi. Durante un'interruzione a livello di regione, i rilevatori non possono generare nuovi risultati per le risorse regionali perché le risorse che dovrebbero analizzare non sono disponibili.
Durante un'interruzione zonale, i rilevatori possono impiegare da diversi minuti a ore per riprendere il normale funzionamento. Security Command Center non perderà i dati dei risultati. Inoltre, non genererà nuovi dati sui risultati per le risorse non disponibili. Nel peggiore scenario, gli agenti di Container Threat Detection potrebbero esaurire lo spazio del buffer durante la connessione a una cella integra, il che potrebbe comportare la perdita di rilevamenti.
I risultati sono resilienti sia alle interruzioni a livello regionale sia a livello di zona perché vengono replicati in modo sincrono nelle regioni.
Sensitive Data Protection (inclusa l'API DLP)
Sensitive Data Protection fornisce servizi di classificazione, profilazione, anonimizzazione, tokenizzazione e analisi del rischio per la privacy dei dati sensibili. Funziona in modo sincrono sui dati inviati nei corpi delle richieste o in modo asincrono sui dati già presenti nei sistemi dispazio di archiviazione sul cloudd. La protezione dei dati sensibili può essere richiamata tramite gli endpoint globali o specifici per regione.
Endpoint globale:il servizio è progettato per essere resiliente sia ai guasti regionali
sia a quelli di zona. Se il servizio è sovraccarico quando si verifica un errore, i dati
inviati al metodo
hybridInspect del servizio potrebbero andare persi.
Per creare un'architettura a prova di errore, includi la logica per esaminare il risultato di pre-errore più recente prodotto dal metodo hybridInspect. In
caso di interruzione, i dati inviati al metodo potrebbero essere persi, ma non
più di quelli degli ultimi 10 minuti prima dell'evento di errore. Se sono presenti
risultati più recenti di 10 minuti prima dell'inizio dell'interruzione, significa che i
dati che hanno generato il risultato non sono andati persi. In questo caso, non è necessario
riprodurre i dati precedenti al timestamp del risultato, anche se rientrano nell'intervallo
di 10 minuti.
Endpoint regionale: gli endpoint regionali non sono resilienti agli errori regionali. Se è necessaria la resilienza a un errore regionale, valuta la possibilità di eseguire il failover in altre regioni. Le caratteristiche di errore zonale sono le stesse indicate sopra.
Utilizzo dei servizi
L'API Service Usage è un servizio di infrastruttura di Google Cloud che ti consente di elencare e gestire API e servizi nei tuoi progetti Google Cloud . Puoi elencare e gestire API e servizi forniti da Google, Google Cloude produttori di terze parti. L'API Service Usage è un servizio globale e resiliente alle interruzioni a livello di zona e regione. In caso di interruzione a livello di zona o regione, l'API Service Usage continua a gestire le richieste provenienti da un'altra zona in diverse regioni.
Per ulteriori informazioni su Service Usage, consulta la documentazione di Service Usage.
Speech-to-Text
Speech-to-Text ti consente di convertire l'audio del parlato in testo utilizzando tecniche di machine learning come i modelli di rete neurale. L'audio viene inviato in tempo reale dal microfono di un'applicazione oppure viene elaborato come batch di file audio.
Interruzione zonale:
API Speech-to-Text v1: durante un'interruzione zonale, l'API Speech-to-Text versione 1 continua a gestire le richieste da un'altra zona nella stessa regione senza interruzioni. Tuttavia, tutti i job attualmente in esecuzione nella zona in errore vengono persi. Gli utenti devono riprovare a eseguire i job non riusciti, che verranno indirizzati automaticamente a una zona disponibile.
API Speech-to-Text v2: durante un'interruzione a livello di zona, l'API Speech-to-Text versione 2 continua a gestire le richieste provenienti da un'altra zona della stessa regione. Tuttavia, tutti i job attualmente in esecuzione nella zona in errore vengono persi. Gli utenti devono riprovare a eseguire i job non riusciti, che verranno indirizzati automaticamente a una zona disponibile. L'API Speech-to-Text restituisce la chiamata API solo dopo che i dati sono stati inviati a un quorum all'interno di una regione. In alcune regioni, gli acceleratori AI (TPU) sono disponibili solo in una zona. In questo caso, un'interruzione in questa zona causa un errore nel riconoscimento vocale, ma non si verifica alcuna perdita di dati.
Interruzione regionale:
API Speech-to-Text v1: la versione 1 dell'API Speech-to-Text non è interessata dall'errore regionale perché è un servizio globale multiregionale. Il servizio continua a gestire le richieste provenienti da un'altra regione senza interruzioni. Tuttavia, i job attualmente in esecuzione nella regione in errore vengono persi. Gli utenti devono riprovare i job non riusciti, che verranno indirizzati automaticamente a una regione disponibile.
API Speech-to-Text v2:
API Speech-to-Text multiregionale versione 2, il servizio continua a gestire le richieste provenienti da un'altra zona della stessa regione senza interruzioni.
API Speech-to-Text versione 2 a singola regione, il servizio limita l'esecuzione del job alla regione richiesta. La versione 2 dell'API Speech-to-Text non indirizza il traffico a un'altra regione e i dati non vengono replicati in un'altra regione. Durante un errore regionale, la versione 2 dell'API Speech-to-Text non è disponibile in quella regione. Tuttavia, torna disponibile quando l'interruzione viene risolta.
Storage Transfer Service
Storage Transfer Service gestisce i trasferimenti di dati da varie origini cloud a Cloud Storage, nonché da, verso e tra file system.
L'API Storage Transfer Service è una risorsa globale.
Storage Transfer Service dipende dalla disponibilità dell'origine e della destinazione di un trasferimento. Se un'origine o una destinazione del trasferimento non è disponibile, i trasferimenti smettono di avanzare. Tuttavia, non vengono persi dati principali o dati dei lavori dei clienti. I trasferimenti riprendono quando l'origine e la destinazione tornano disponibili.
Puoi utilizzare Storage Transfer Service con o senza un agente, nel seguente modo:
I trasferimenti senza agenti utilizzano i worker regionali per orchestrare i job di trasferimento.
I trasferimenti basati su agenti utilizzano agenti software installati sulla tua infrastruttura. I trasferimenti basati su agenti si basano sulla disponibilità degli agenti di trasferimento e sulla loro capacità di connettersi al file system. Quando decidi dove installare gli agenti di trasferimento, considera la disponibilità del file system. Ad esempio, se esegui agenti di trasferimento su più VM Compute Engine per trasferire dati a un'istanza Filestore di livello Enterprise (una risorsa di regione), devi prendere in considerazione la possibilità di posizionare le VM in zone diverse all'interno della regione dell'istanza Filestore.
Se gli agenti non sono più disponibili o se la loro connessione al file system viene interrotta, i trasferimenti non avanzano, ma non vengono persi dati. Se tutti i processi dell'agente vengono terminati, il job di trasferimento viene messo in pausa finché non vengono aggiunti nuovi agenti al pool di agenti del trasferimento.
Durante un'interruzione, il comportamento di Storage Transfer Service è il seguente:
Interruzione di servizio nella zona: durante un'interruzione di servizio nella zona, le API Storage Transfer Service rimangono disponibili e puoi continuare a creare job di trasferimento. Il trasferimento dei dati continua.
Interruzione a livello di regione:durante un'interruzione a livello di regione, le API Storage Transfer Service rimangono disponibili e puoi continuare a creare job di trasferimento. Se i worker del trasferimento si trovano nella regione interessata, il trasferimento dei dati si interrompe finché la regione non torna disponibile e il trasferimento riprende automaticamente.
Vertex ML Metadata
Vertex ML Metadata consente di registrare i metadati e gli artefatti prodotti dal sistema ML e di eseguire query su questi metadati per analizzare, eseguire il debug e controllare le prestazioni del sistema ML o degli artefatti che produce.
Interruzione zonale:nella configurazione predefinita, Vertex ML Metadata offre protezione da errori zonali. Il servizio viene implementato in più zone in ogni regione, con i dati replicati in modo sincrono in zone diverse all'interno di ogni regione. In caso di errore a livello di zona, le zone rimanenti subentrano con un'interruzione minima.
Interruzione a livello regionale:Vertex ML Metadata è un servizio regionalizzato. In caso di interruzione a livello regionale, Vertex ML Metadata non eseguirà il failover in un'altra regione.
Vertex AI Batch Prediction
La previsione batch consente agli utenti di eseguire la previsione batch rispetto ai modelli AI/ML sull'infrastruttura di Google. La previsione batch è un'offerta regionale. I clienti possono scegliere la regione in cui eseguire i job, ma non le zone specifiche all'interno di quella regione. Il servizio di previsione batch bilancia automaticamente il carico del job tra diverse zone all'interno della regione scelta.
Interruzione di zona:la previsione batch archivia i metadati per i job di previsione batch all'interno di una regione. I dati vengono scritti in modo sincrono in più zone all'interno della regione. In caso di interruzione zonale, la previsione batch perde parzialmente i worker che eseguono i job, ma li aggiunge automaticamente in altre zone disponibili. Se più tentativi di previsione batch non vanno a buon fine, l'interfaccia utente elenca lo stato del job come non riuscito nell'interfaccia utente e nelle richieste di chiamata API. Le successive richieste dell'utente di eseguire il job vengono instradate alle zone disponibili.
Interruzione regionale:i clienti scelgono la regione Google Cloud in cui vogliono eseguire i job di previsione batch. I dati non vengono mai replicati tra regioni. La previsione batch limita l'esecuzione del job alla regione richiesta e non indirizza mai le richieste di previsione a una regione diversa. Quando si verifica un errore a livello regionale, la previsione batch non è disponibile in quella regione. Tornerà disponibile quando l'interruzione verrà risolta. Consigliamo ai clienti di utilizzare più regioni per eseguire i propri job. In caso di interruzione regionale, indirizza i job a un'altra regione disponibile.
Vertex AI Model Registry
Vertex AI Model Registry consente agli utenti di semplificare la gestione, la governance e il deployment dei modelli ML in un repository centrale. Vertex AI Model Registry è un'offerta regionale con alta disponibilità e offre protezione contro le interruzioni zonali.
Interruzione zonale:Vertex AI Model Registry offre protezione dalle interruzioni zonali. Il servizio viene implementato in tre zone in ogni regione, con i dati replicati in modo sincrono in zone diverse all'interno della regione. Se una zona non funziona, le zone rimanenti subentrano senza perdita di dati e con un'interruzione minima del servizio.
Interruzione a livello regionale:Vertex AI Model Registry è un servizio regionalizzato. Se una regione non funziona, Model Registry non esegue il failover.
Vertex AI Online prediction
La previsione online consente agli utenti di eseguire il deployment di modelli AI/ML su Google Cloud. La previsione online è un'offerta regionale. I clienti possono scegliere la regione in cui eseguire il deployment dei modelli, ma non le zone specifiche all'interno di quella regione. Il servizio di previsione bilancerà automaticamente il carico di lavoro tra le diverse zone all'interno della regione selezionata.
Interruzione zonale:la previsione online non memorizza i contenuti dei clienti. Un'interruzione zonale comporta l'errore dell'esecuzione della richiesta di previsione corrente. La previsione online potrebbe riprovare automaticamente la richiesta di previsione a seconda del tipo di endpoint utilizzato. In particolare, un endpoint pubblico riproverà automaticamente, mentre un endpoint privato no. Per gestire meglio gli errori e migliorare la resilienza, incorpora la logica di ripetizione con backoff esponenziale nel codice.
Interruzione regionale:i clienti scelgono la regione Google Cloud in cui vogliono eseguire i propri modelli AI/ML e servizi di previsione online. I dati non vengono mai replicati tra regioni. La previsione online limita l'esecuzione del modello AI/ML alla regione richiesta e non instrada mai le richieste di previsione a un'altra regione. Quando si verifica un errore a livello di regione, il servizio di previsione online non è disponibile in quella regione. Tornerà disponibile quando l'interruzione verrà risolta. Consigliamo ai clienti di utilizzare più regioni per eseguire i propri modelli di AI/ML. In caso di interruzione a livello regionale, indirizza il traffico diretto a un'altra regione disponibile.
Vertex AI Pipelines
Vertex AI Pipelines è un servizio Vertex AI che ti consente di automatizzare, monitorare e gestire i tuoi flussi di lavoro di machine learning (ML) in modo serverless. Vertex AI Pipelines è progettato per fornire alta disponibilità e offre protezione contro gli errori a livello di zona.
Interruzione zonale:nella configurazione predefinita, Vertex AI Pipelines offre protezione da errori zonali. Il servizio viene implementato in più zone in ogni regione, con i dati replicati in modo sincrono in zone diverse all'interno della regione. In caso di errore a livello di zona, le zone rimanenti subentrano con un'interruzione minima.
Interruzione regionale:Vertex AI Pipelines è un servizio regionalizzato. In caso di interruzione a livello di regione, Vertex AI Pipelines non eseguirà il failover in un'altra regione. In caso di interruzione regionale, ti consigliamo di eseguire i job della pipeline in una regione di backup.
Vertex AI Search
Vertex AI Search è una soluzione di ricerca personalizzabile con funzionalità di AI generativa e conformità aziendale nativa. Vertex AI Search viene implementato e replicato automaticamente in più regioni all'interno di Google Cloud. Puoi configurare la posizione in cui vengono archiviati i dati scegliendo una regione multipla supportata, ad esempio: globale, Stati Uniti o UE.
Interruzione zonale e regionale: UserEvents caricato su
Vertex AI Search potrebbe non essere recuperabile a causa del ritardo di replica asincrona. Gli altri dati e servizi forniti da
Vertex AI Search rimangono disponibili grazie al failover
automatico e alla replica sincrona dei dati.
Vertex AI Training
Vertex AI Training consente agli utenti di eseguire job di addestramento personalizzati sull'infrastruttura di Google. Vertex AI Training è un'offerta regionale, il che significa che i clienti possono scegliere la regione in cui eseguire i job di addestramento. Tuttavia, i clienti non possono scegliere le zone specifiche all'interno di quella regione. Il servizio di addestramento potrebbe bilanciare automaticamente il carico dell'esecuzione del job in diverse zone all'interno della regione.
Interruzione zonale:Vertex AI Training archivia i metadati per il job di addestramento personalizzato. Questi dati vengono archiviati a livello regionale e scritti in modo sincrono. La chiamata all'API Vertex AI Training viene restituita solo dopo che questi metadati sono stati commitati a un quorum all'interno di una regione. Il job di addestramento potrebbe essere eseguito in una zona specifica. Un'interruzione zonale comporta l'errore dell'esecuzione del job corrente. In questo caso, il servizio riprova automaticamente il job indirizzandolo a un'altra zona. Se più tentativi non vanno a buon fine, lo stato del job viene aggiornato a Non riuscito. Le richieste successive degli utenti per eseguire il job vengono instradate a una zona disponibile.
Interruzione regionale:i clienti scelgono la regione in cui vogliono eseguire i job di addestramento. Google Cloud I dati non vengono mai replicati tra regioni. Vertex AI Training limita l'esecuzione del job alla regione richiesta e non indirizza mai i job di addestramento a una regione diversa. In caso di errore regionale, il servizio Vertex AI Training non è disponibile in quella regione e torna disponibile quando l'interruzione viene risolta. Consigliamo ai clienti di utilizzare più regioni per eseguire i propri job e, in caso di interruzione regionale, di indirizzare i job a un'altra regione disponibile.
Virtual Private Cloud (VPC)
VPC è un servizio globale che fornisce connettività di rete alle risorse (ad esempio le VM). Tuttavia, gli errori sono a livello di zona. In caso di errore a livello di zona, le risorse in quella zona non sono disponibili. Allo stesso modo, se una regione non funziona, viene interessato solo il traffico da e verso la regione non funzionante. La connettività delle regioni integre non è interessata.
Interruzione zonale:se una rete VPC copre più zone e una zona non funziona, la rete VPC sarà comunque integra per le zone integre. Il traffico di rete tra le risorse nelle zone integre continuerà a funzionare normalmente durante l'errore. Un errore a livello di zona influisce solo sul traffico di rete verso e dalle risorse nella zona in errore. Per ridurre l'impatto degli errori a livello di zona, ti consigliamo di non creare tutte le risorse in una singola zona. Quando crei le risorse, distribuiscile tra le zone.
Interruzione a livello di regione:se una rete VPC copre più regioni e una regione non funziona, la rete VPC sarà comunque integra per le regioni integre. Il traffico di rete tra le risorse nelle regioni integre continuerà a funzionare normalmente durante l'errore. Un errore regionale influisce solo sul traffico di rete da e verso le risorse nella regione in cui si è verificato l'errore. Per mitigare l'impatto di errori a livello di regione, ti consigliamo di distribuire le risorse su più regioni.
Controlli di servizio VPC
I Controlli di servizio VPC sono un servizio regionale. Utilizzando i Controlli di servizio VPC, i team di sicurezza aziendali possono definire controlli perimetrali granulari e applicare la strategia di sicurezza a numerosi servizi e progetti Google Cloud . Le policy dei clienti vengono replicate a livello regionale.
Interruzione a livello di zona:Controlli di servizio VPC continua a gestire le richieste provenienti da un'altra zona della stessa regione senza interruzioni.
Interruzione regionale: le API configurate per l'applicazione dei criteri di Controlli di servizio VPC nella regione interessata non sono disponibili finché la regione non torna disponibile. Se desiderano una maggiore disponibilità, i clienti sono invitati a eseguire il deployment dei servizi con Controlli di servizio VPC applicati in più regioni.
Workflow
Workflows è un prodotto di orchestrazione che consente ai clienti di: Google Cloud
- eseguire il deployment ed eseguire flussi di lavoro che connettono altri servizi esistenti utilizzando HTTP,
- automatizzare i processi, inclusa l'attesa delle risposte HTTP con nuovi tentativi automatici fino a un anno e
- implementare processi in tempo reale con esecuzioni a bassa latenza basate sugli eventi.
Un cliente di Workflows può eseguire il deployment di workflow che descrivono la logica di business che vuole eseguire, quindi eseguire i workflow direttamente con l'API o con trigger basati su eventi (attualmente limitati a Pub/Sub o Eventarc). Il workflow in esecuzione può manipolare le variabili, effettuare chiamate HTTP e archiviare i risultati oppure definire callback e attendere di essere ripreso da un altro servizio.
Interruzione zonale:il codice sorgente Workflows non è interessato dalle interruzioni zonali. Workflows archivia il codice sorgente dei workflow, insieme ai valori delle variabili e alle risposte HTTP ricevute dai workflow in esecuzione. Il codice sorgente viene archiviato a livello regionale e scritto in modo sincrono: l'API del control plane viene restituita solo dopo che questi metadati sono stati inviati a un quorum all'interno di una regione. Le variabili e i risultati HTTP vengono archiviati anche a livello regionale e scritti in modo sincrono, almeno ogni cinque secondi.
Se una zona non funziona, i workflow vengono ripresi automaticamente in base agli ultimi dati archiviati. Tuttavia, le richieste HTTP che non hanno ancora ricevuto risposte non vengono ritentate automaticamente. Utilizza i criteri di ripetizione per le richieste che possono essere ripetute in sicurezza, come descritto nella nostra documentazione.
Interruzione a livello regionale:Workflows è un servizio regionalizzato; in caso di interruzione a livello regionale, Workflows non eseguirà il failover. I clienti sono invitati a eseguire il deployment di Workflows in più regioni se è richiesta una disponibilità più elevata.
Cloud Service Mesh
Cloud Service Mesh consente di configurare un mesh di servizi gestiti che si estende su più cluster GKE. Questa documentazione riguarda solo Cloud Service Mesh gestito. La variante in-cluster è self-hosted e devono essere seguite le normali linee guida della piattaforma.
Interruzione a livello di zona:la configurazione mesh, essendo memorizzata nel cluster GKE, è resiliente alle interruzioni a livello di zona, a condizione che il cluster sia regionale. I dati utilizzati dal prodotto per la contabilità interna vengono archiviati a livello regionale o globale e non sono interessati se una singola zona è fuori servizio. Il control plane viene eseguito nella stessa regione del cluster GKE che supporta (per i cluster zonali è la regione contenente) e non è interessato dalle interruzioni all'interno di una singola zona.
Interruzione a livello regionale:Cloud Service Mesh fornisce servizi ai cluster GKE, che sono regionali o zonali. In caso di interruzione regionale, Cloud Service Mesh non esegue il failover. Nemmeno GKE. I clienti sono invitati a eseguire il deployment di mesh costituiti da cluster GKE che coprono diverse regioni.
Service Directory
Service Directory è una piattaforma per scoprire, pubblicare e connettere servizi. Fornisce informazioni in tempo reale, in un unico posto, su tutti i tuoi servizi. Service Directory ti consente di eseguire la gestione dell'inventario dei servizi su larga scala, sia che tu disponga di pochi endpoint di servizio o di migliaia.
Le risorse Service Directory vengono create a livello regionale, in base al parametro di località specificato dall'utente.
Interruzione zonale: durante un'interruzione zonale, Service Directory continua a gestire le richieste provenienti da un'altra zona della stessa regione o di una regione diversa senza interruzioni. All'interno di ogni regione, Service Directory gestisce sempre più repliche. Una volta risolto l'interruzione zonale, viene ripristinata la ridondanza completa.
Interruzione regionale:Service Directory non è resiliente alle interruzioni regionali.