Vision AI
Extraia insights de imagens, documentos e vídeos
Acesse modelos de visão avançados usando APIs para automatizar tarefas de visão, simplificar análises e desbloquear insights úteis. Ou crie apps personalizados com treinamento de modelo sem código e baixo custo em um ambiente gerenciado.
Novos clientes ganham até US$ 300 em créditos para testar a Vision AI e outros produtos do Google Cloud.
Além disso, tente implantar soluções de resumo de documentos e de processamento de imagens de IA/ML recomendadas pelo Google.
Visão geral
O que é visão computacional?
A visão computacional é um campo da inteligência artificial (IA) que permite que computadores e sistemas interpretem e analisem dados visuais e extraiam informações significativas de imagens digitais, vídeos e outras entradas visuais. Algumas de suas aplicações típicas no mundo real incluem: detecção de objetos, processamento de conteúdo visual (imagens, documentos, vídeos), compreensão e análise, pesquisa de produtos, classificação e pesquisa de imagens e moderação de conteúdo.
IA generativa multimodal avançada
A Vertex AI do Google Cloud oferece acesso ao Gemini, uma família de modelos multimodais modernos que entendem praticamente qualquer entrada, combinando diferentes tipos de informações e gerando praticamente qualquer resultado. Embora o Gemini seja mais adequado para tarefas que combinam recursos visuais, texto e código, o Gemini Pro Vision se destaca em uma ampla variedade de tarefas relacionadas à visão, como reconhecimento de objetos, compreensão de conteúdo digital e legendagem/descrição. Ele pode ser acessado usando uma API.
IA generativa com foco em visão
O Imagen na Vertex AI oferece os recursos modernos de IA generativa de imagens do Google para desenvolvedores de aplicativos usando uma API. Alguns dos principais recursos incluem geração de imagens (GA restrito) com comandos de texto e edição de imagens (GA restrito) com comandos de texto, descrever uma imagem em texto (também conhecido como legenda visual, GA) e ajuste do modelo de assunto (GA restrito). Saiba mais sobre os principais recursos e as etapas de lançamento.
Vision AI pronta para usar
Com a tecnologia dos modelos de ML de visão computacional pré-treinados do Google, a API Cloud Vision é uma API prontamente disponível (REST e RPC) que permite aos desenvolvedores integrar facilmente recursos comuns de detecção de visão nos aplicativos, incluindo: rotulagem de imagens, detecção facial e de pontos de referência, reconhecimento óptico de caracteres (OCR) e marcação de conteúdo explícito.
Cada recurso que você aplica a uma imagem é uma unidade faturável. A API Cloud Vision permite usar 1.000 unidades dos recursos dela gratuitamente todos os meses. Veja a Tabela de preços.
Compreensão de documentos da IA generativa
A Document AI é uma plataforma de compreensão de documentos que combina visão computacional e outras tecnologias, como o processamento de linguagem natural, para extrair textos e dados de documentos digitalizados e transformar dados não estruturados em informações estruturadas e insights de negócios.
Ela oferece uma ampla variedade de processadores pré-treinados otimizados para diferentes tipos de documentos. Ela também facilita a criação de processadores personalizados para classificar, dividir e extrair dados estruturados de documentos por meio do Document AI Workbench.

Vision AI pronta para usar em vídeos
Com a tecnologia de visão computacional como foco, a API Video Intelligence é uma maneira fácil de processar, analisar e entender o conteúdo de vídeo.
Os modelos de ML pré-treinados reconhecem automaticamente um grande número de objetos, lugares e ações em vídeos armazenados e via streaming com qualidade excepcional. Ele é altamente eficiente para casos de uso comuns, como moderação e recomendação de conteúdo, arquivos de mídia e anúncios contextuais. Também é possível treinar modelos personalizados de ML com a Vertex AI Vision para suas necessidades específicas.

Visual Inspection AI
A Visual Inspection AI automatiza tarefas de inspeção visual em manufaturas e outros ambientes industriais. Ela aproveita técnicas avançadas de visão computacional e aprendizado profundo para analisar imagens e vídeos, identificar anomalias, detectar e localizar defeitos e verificar peças ausentes e defeituosas em produtos montados.
É possível treinar modelos personalizados sem conhecimento técnico e com um mínimo de imagens rotuladas, executar inferências em linhas de produção de maneira eficiente e atualizar continuamente os modelos com dados novos extraídos do chão de fábrica.

Plataforma unificada da Vision AI
A Vertex AI Vision é um ambiente de desenvolvimento de aplicativos totalmente gerenciado que permite aos desenvolvedores criar, implantar e gerenciar com facilidade aplicativos de visão computacional para processar várias modalidades de dados, como texto, imagem, vídeo e dados tabulares. Ela reduz o tempo de criação de dias para minutos por um décimo do custo das ofertas atuais.
É possível criar e implantar seus próprios modelos personalizados, além de gerenciá-los e escaloná-los com pipelines de CI/CD. Ela também se integra a ferramentas de código aberto conhecidas, como TensorFlow e PyTorch.

Privacidade e segurança de dados
O Google Cloud tem recursos líderes do setor que permitem que você (nossos clientes) controle seus dados e saiba quando e como eles são acessados.
Como cliente do Google Cloud, os dados do cliente são propriedade sua. Temos medidas de segurança rigorosas para proteger seus dados de cliente e para oferecer ferramentas e recursos que permitam controlar esses dados do jeito que você acha melhor. Os dados do cliente são seus, e não do Google. Só processamos seus dados de acordo com seus contratos.
Saiba mais na nossa Central de recursos de privacidade.
Comparar produtos de visão computacional
| Ofertas | Ideal para | Principais recursos |
|---|---|---|
Integração rápida e fácil dos recursos básicos de visão. | Recursos predefinidos como rotulagem de imagens, detecção facial e de pontos de referência, OCR e pesquisa segura. Econômico e com pagamento conforme o uso. | |
Extração de insights de documentos e imagens digitalizados, automatizando fluxos de trabalho de documentos. | OCR (com tecnologia de IA generativa), PLN, ML para compreensão de documentos, extração de texto, identificação de entidades e categorização de documentos. | |
Análise de conteúdo em vídeo, moderação e recomendação de conteúdo, arquivos de mídia e anúncios contextuais. | Detecção e rastreamento de objetos, compreensão de cena, reconhecimento de atividades, detecção e análise facial, detecção e reconhecimento de texto. | |
Automatizar tarefas de inspeção visual em ambientes industriais e de manufatura | Detecção de anomalias, detecção e localização de defeitos e verificação da montagem. | |
Criar e implantar modelos personalizados para necessidades específicas. | Ferramentas de preparação de dados, treinamento e implantação de modelos, controle total sobre sua solução. Requer conhecimento técnico. | |
Análise e compreensão visuais, resposta a perguntas multimodais. | Busca de informações, reconhecimento de objetos, compreensão de conteúdo digital, geração de conteúdo estruturado, legendagem/descrição e extrapolação. | |
Receba descrições automatizadas de imagens. Classificação e pesquisa de imagens. Moderação e recomendações de conteúdo. | Geração de imagens, edição de imagens, legenda visual e embedding multimodal. Confira a lista completa de recursos e as etapas de lançamento deles. |
Otimizados para diferentes finalidades, esses produtos permitem que você aproveite os modelos de ML pré-treinados e comece a trabalhar, com a capacidade de fazer ajustes facilmente.
Integração rápida e fácil dos recursos básicos de visão.
Recursos predefinidos como rotulagem de imagens, detecção facial e de pontos de referência, OCR e pesquisa segura.
Econômico e com pagamento conforme o uso.
Extração de insights de documentos e imagens digitalizados, automatizando fluxos de trabalho de documentos.
OCR (com tecnologia de IA generativa), PLN, ML para compreensão de documentos, extração de texto, identificação de entidades e categorização de documentos.
Análise de conteúdo em vídeo, moderação e recomendação de conteúdo, arquivos de mídia e anúncios contextuais.
Detecção e rastreamento de objetos, compreensão de cena, reconhecimento de atividades, detecção e análise facial, detecção e reconhecimento de texto.
Automatizar tarefas de inspeção visual em ambientes industriais e de manufatura
Detecção de anomalias, detecção e localização de defeitos e verificação da montagem.
Criar e implantar modelos personalizados para necessidades específicas.
Ferramentas de preparação de dados, treinamento e implantação de modelos, controle total sobre sua solução. Requer conhecimento técnico.
Análise e compreensão visuais, resposta a perguntas multimodais.
Busca de informações, reconhecimento de objetos, compreensão de conteúdo digital, geração de conteúdo estruturado, legendagem/descrição e extrapolação.
Receba descrições automatizadas de imagens.
Classificação e pesquisa de imagens.
Moderação e recomendações de conteúdo.
Geração de imagens, edição de imagens, legenda visual e embedding multimodal.
Confira a lista completa de recursos e as etapas de lançamento deles.
Otimizados para diferentes finalidades, esses produtos permitem que você aproveite os modelos de ML pré-treinados e comece a trabalhar, com a capacidade de fazer ajustes facilmente.
Como funciona
O pacote de ferramentas da Vision AI do Google Cloud combina visão computacional com outras tecnologias para entender e analisar vídeos e integrar facilmente recursos de detecção de visão a aplicativos, incluindo rotulagem de imagens, detecção facial e de pontos de referência, reconhecimento óptico de caracteres (OCR) e inclusão de tags em conteúdo explícito.
Essas ferramentas estão disponíveis por APIs, mas ainda podem ser personalizadas para necessidades específicas.
O pacote de ferramentas da Vision AI do Google Cloud combina visão computacional com outras tecnologias para entender e analisar vídeos e integrar facilmente recursos de detecção de visão a aplicativos, incluindo rotulagem de imagens, detecção facial e de pontos de referência, reconhecimento óptico de caracteres (OCR) e inclusão de tags em conteúdo explícito.
Essas ferramentas estão disponíveis por APIs, mas ainda podem ser personalizadas para necessidades específicas.

Demonstração
Saiba como a visão computacional funciona com seus próprios arquivos
Usos comuns
Detecta texto em arquivos brutos e faz resumos automáticos
Resuma documentos grandes com a IA generativa
A solução descrita no diagrama de arquitetura à direita implanta um pipeline que é acionado quando você adiciona um novo documento PDF ao bucket do Cloud Storage. O pipeline extrai o texto do documento, cria um resumo a partir do texto extraído e o armazena em um banco de dados para visualização e pesquisa.
Você pode invocar o aplicativo fazendo upload de arquivos pelo Notebook do Jupyter ou diretamente para o Cloud Storage no console do Google Cloud.

Tempo estimado de implantação: 11 minutos (1 minuto para configurar, 10 minutos para implantar).
Tutoriais
Resuma documentos grandes com a IA generativa
A solução descrita no diagrama de arquitetura à direita implanta um pipeline que é acionado quando você adiciona um novo documento PDF ao bucket do Cloud Storage. O pipeline extrai o texto do documento, cria um resumo a partir do texto extraído e o armazena em um banco de dados para visualização e pesquisa.
Você pode invocar o aplicativo fazendo upload de arquivos pelo Notebook do Jupyter ou diretamente para o Cloud Storage no console do Google Cloud.
Tempo estimado de implantação: 11 minutos (1 minuto para configurar, 10 minutos para implantar).
Criar um pipeline de processamento de imagem
Processamento de imagens escalonável em uma arquitetura sem servidor
A solução, representada no diagrama à direita, usa modelos de machine learning pré-treinados para analisar imagens fornecidas pelos usuários e gerar anotações. A implantação dessa solução cria um serviço de processamento de imagens que ajuda você a lidar com conteúdo não seguro ou nocivo gerado pelo usuário, digitalizar textos de documentos físicos, detectar e classificar objetos em imagens e muito mais.
Você poderá revisar as definições de configuração e segurança para saber como adaptar o serviço de processamento de imagens às diferentes necessidades.

Tempo estimado de implantação: 12 minutos (2 minutos para configurar, 10 minutos para implantar).
Tutoriais
Processamento de imagens escalonável em uma arquitetura sem servidor
A solução, representada no diagrama à direita, usa modelos de machine learning pré-treinados para analisar imagens fornecidas pelos usuários e gerar anotações. A implantação dessa solução cria um serviço de processamento de imagens que ajuda você a lidar com conteúdo não seguro ou nocivo gerado pelo usuário, digitalizar textos de documentos físicos, detectar e classificar objetos em imagens e muito mais.
Você poderá revisar as definições de configuração e segurança para saber como adaptar o serviço de processamento de imagens às diferentes necessidades.
Tempo estimado de implantação: 12 minutos (2 minutos para configurar, 10 minutos para implantar).
Receba descrições automatizadas de imagens com a IA generativa
O recurso de legenda visual do Imagen permite gerar uma descrição relevante para uma imagem. Você pode usá-lo para ver metadados mais detalhados sobre imagens, armazenar e pesquisar, gerar legendas automáticas para oferecer suporte a casos de uso de acessibilidade e receber descrições rápidas de produtos e recursos visuais.
Disponível em inglês, francês, alemão, italiano e espanhol, esse recurso pode ser acessado no console do Google Cloud ou por uma chamada de API.
Tutoriais
O recurso de legenda visual do Imagen permite gerar uma descrição relevante para uma imagem. Você pode usá-lo para ver metadados mais detalhados sobre imagens, armazenar e pesquisar, gerar legendas automáticas para oferecer suporte a casos de uso de acessibilidade e receber descrições rápidas de produtos e recursos visuais.
Disponível em inglês, francês, alemão, italiano e espanhol, esse recurso pode ser acessado no console do Google Cloud ou por uma chamada de API.
Processar vídeos em streaming
Receba insights de streaming de vídeos com a Vertex AI Vision
Antes de analisar os dados de vídeo com o aplicativo, crie um pipeline para o fluxo contínuo de dados com o serviço Streams na Vertex AI Vision. Depois, os dados ingeridos são analisados pelos modelos pré-treinados do Google ou seu modelo personalizado. A saída da análise dos streams é armazenada no Vertex AI Vision Warehouse, onde é possível usar recursos avançados de pesquisa com tecnologia de IA para consultar conteúdo de mídia não estruturado.
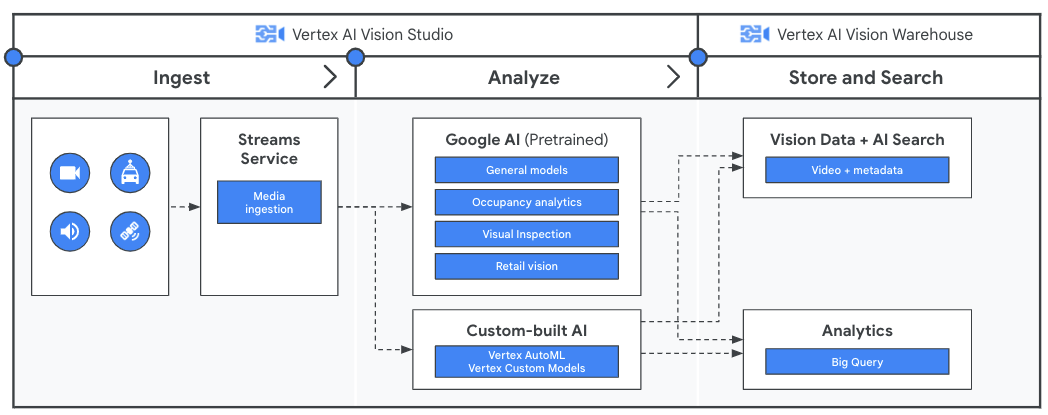
Tutoriais
Receba insights de streaming de vídeos com a Vertex AI Vision
Antes de analisar os dados de vídeo com o aplicativo, crie um pipeline para o fluxo contínuo de dados com o serviço Streams na Vertex AI Vision. Depois, os dados ingeridos são analisados pelos modelos pré-treinados do Google ou seu modelo personalizado. A saída da análise dos streams é armazenada no Vertex AI Vision Warehouse, onde é possível usar recursos avançados de pesquisa com tecnologia de IA para consultar conteúdo de mídia não estruturado.
Extraia textos e insights de documentos com a IA generativa
Descubra insights de documentos diferenciados com a Document AI
Com base em um modelo de fundação, o Extrator personalizado do Document AI extrai textos e dados de documentos genéricos e específicos do domínio com mais rapidez e acurácia. Ajuste facilmente com apenas de 5 a 10 documentos para um desempenho ainda melhor.
Se você quiser treinar seu próprio modelo, rotule automaticamente seus conjuntos de dados com o modelo de fundação para acelerar o tempo de produção.
Também é possível usar processadores especializados pré-treinados. Confira a lista completa de processadores.
Tutoriais
Descubra insights de documentos diferenciados com a Document AI
Com base em um modelo de fundação, o Extrator personalizado do Document AI extrai textos e dados de documentos genéricos e específicos do domínio com mais rapidez e acurácia. Ajuste facilmente com apenas de 5 a 10 documentos para um desempenho ainda melhor.
Se você quiser treinar seu próprio modelo, rotule automaticamente seus conjuntos de dados com o modelo de fundação para acelerar o tempo de produção.
Também é possível usar processadores especializados pré-treinados. Confira a lista completa de processadores.
Inspeção visual de alta precisão
Automatizar a inspeção de qualidade com a Visual Inspection AI
A Visual Inspection AI é otimizada em todas as etapas para que seja fácil de configurar e rápida para conferir o ROI. Com até 300 vezes menos imagens rotuladas para começar a treinar modelos de inspeção de alto desempenho do que as plataformas de ML de uso geral, ela oferece uma acurácia até 10 vezes maior. É possível treinar modelos sem conhecimento técnico e eles são executados no local. O melhor de tudo é que os modelos podem ser atualizados continuamente com dados vindos da fábrica, oferecendo maior precisão à medida que você descobre novos casos de uso.
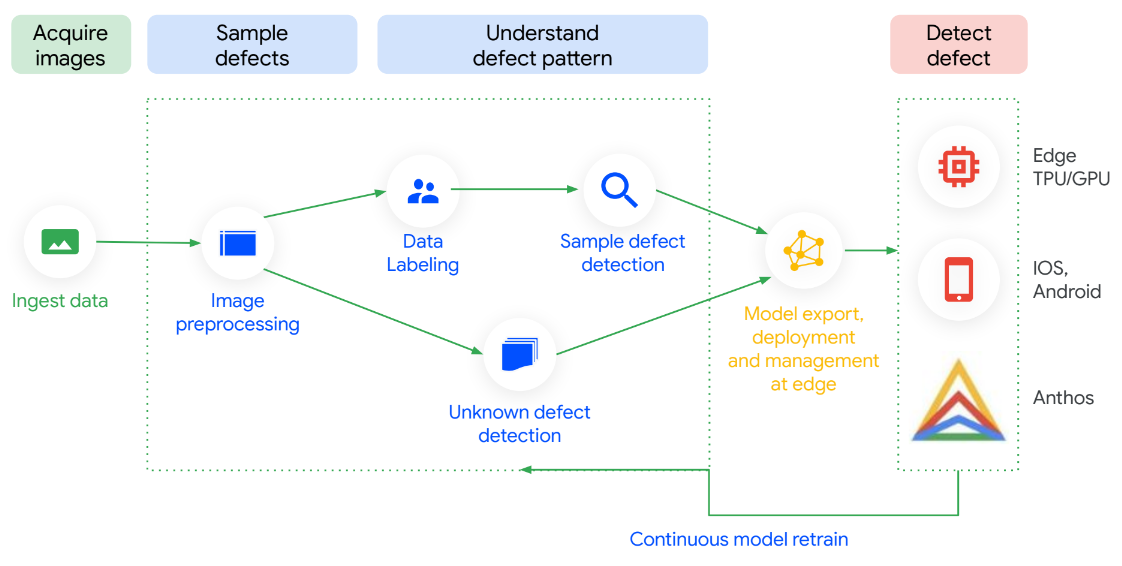
Tutoriais
Automatizar a inspeção de qualidade com a Visual Inspection AI
A Visual Inspection AI é otimizada em todas as etapas para que seja fácil de configurar e rápida para conferir o ROI. Com até 300 vezes menos imagens rotuladas para começar a treinar modelos de inspeção de alto desempenho do que as plataformas de ML de uso geral, ela oferece uma acurácia até 10 vezes maior. É possível treinar modelos sem conhecimento técnico e eles são executados no local. O melhor de tudo é que os modelos podem ser atualizados continuamente com dados vindos da fábrica, oferecendo maior precisão à medida que você descobre novos casos de uso.
Preços
| Como funcionam os preços da Vision AI | Cada oferta de visão tem um conjunto de recursos ou processadores com preços diferentes. Consulte as páginas de preços detalhadas para mais detalhes. | ||
|---|---|---|---|
| Nível gratuito | Produto/Serviço | Preço com desconto | Detalhes |
Vision API | Primeiras 1.000 unidades todos os meses são gratuitos | Mais de 5.000,001 unidades por mês | |
Document AI | N/A Os preços dependem do processador. | mais de 5.000.001 páginas por mês para o processador Enterprise Document OCR | |
API Video Intelligence | Primeiros 1.000 minutos por mês são gratuitos | mais de 100.000 minutos por mês | |
Vision da Vertex AI | N/A O preço depende de recursos. |
| |
Imagem — embeddings multimodais |
|
| US$ 0,0001 por entrada de imagem |
Imagen – legenda visual |
|
| US$ 0,0015 por imagem |
Gemini Pro Vision | |||
Como funcionam os preços da Vision AI
Cada oferta de visão tem um conjunto de recursos ou processadores com preços diferentes. Consulte as páginas de preços detalhadas para mais detalhes.
Vision API
Primeiras 1.000 unidades
todos os meses são gratuitos
Mais de 5.000,001 unidades
por mês
Document AI
N/A
Os preços dependem do processador.
mais de 5.000.001 páginas
por mês para o processador Enterprise Document OCR
Primeiros 1.000 minutos
por mês são gratuitos
mais de 100.000 minutos
por mês
Vision da Vertex AI
N/A
O preço depende de recursos.
Imagem — embeddings multimodais
US$ 0,0001
por entrada de imagem
Imagen – legenda visual
US$ 0,0015
por imagem











