Vision AI
Dégagez des insghts à partir d'images, de documents et de vidéos
Accédez à des modèles de vision avancés via des API pour automatiser les tâches de vision, simplifier les analyses et obtenir des insights exploitables. Vous pouvez aussi créer des applications personnalisées à faible coût pour entraîner votre modèle sans code dans un environnement géré.
Les nouveaux clients peuvent obtenir jusqu'à 300 $ de crédits gratuits pour essayer Vision AI et d'autres produits Google Cloud
Vous pouvez également essayer de déployer les solutions de résumé de documents et de traitement d'images par IA/ML recommandées par Google.
Présentation
Qu'est-ce que la vision par ordinateur ?
La vision par ordinateur est un domaine de l'intelligence artificielle (IA) qui permet aux ordinateurs et aux systèmes d'interpréter et d'analyser des données visuelles, et de dégager des informations pertinentes à partir d'images numériques, de vidéos et d'autres entrées visuelles. Voici quelques-unes de ses applications typiques du monde réel : détection d'objets, traitement de contenu visuel (images, documents, vidéos), compréhension et analyse, recherche de produits, classification et recherche d'images, et modération de contenu.
IA générative multimodale avancée
Vertex AI de Google Cloud permet d'accéder à Gemini, une famille de modèles multimodals de pointe capables de comprendre quasiment n'importe quelle entrée, de combiner différents types d'informations et de générer presque toutes les sorties. Si Gemini convient mieux aux tâches qui combinent visuels, texte et code, Gemini Pro Vision excelle dans de nombreuses tâches liées à la vision, comme la reconnaissance d'objets, la compréhension de contenu numérique et le sous-titrage/la description. Il est accessible via une API.
IA générative axée sur la vision
Imagen sur Vertex AI permet aux développeurs d'applications d'utiliser les fonctionnalités d'IA générative d'images de pointe de Google via une API. Certaines de ses fonctionnalités principales incluent la génération d'images (disponibilité générale restreinte) avec des invites textuelles, et la modification d'images (disponibilité générale restreinte) avec des requêtes textuelles, la description d'une image dans du texte (également appelée "sous-titrage visuel" ou "DG") et l'affinage du modèle d'objet (disponibilité générale restreinte). Découvrez ses fonctionnalités clés et les étapes de lancement.
Vision AI prête à l'emploi
Basée sur les modèles de ML pré-entraînés de vision par ordinateur de Google, l'API Cloud Vision est une API facilement accessible (REST et RPC). Elle permet aux développeurs d'intégrer facilement des fonctionnalités courantes de détection visuelle dans des applications, y compris l'étiquetage d'images, la détection de visages et de points de repère, la reconnaissance optique des caractères (OCR) et l'ajout de tags au contenu explicite.
Chaque fonctionnalité que vous appliquez à une image est une unité facturable : l'API Cloud Vision vous permet d'utiliser gratuitement 1 000 unités de ses caractéristiques chaque mois. Veuillez consulter les informations tarifaires.
IA générative pour la reconnaissance de documents
Document AI est une plate-forme de compréhension de documents qui combine la vision par ordinateur et d'autres technologies telles que le traitement du langage naturel pour extraire le texte et les données de documents scannés, et transformer les données non structurées en informations structurées et en insights métier.
La solution propose une large gamme de processeurs pré-entraînés optimisés pour différents types de documents. Elle permet également de créer facilement des processeurs personnalisés pour classer, diviser et extraire des données structurées à partir de documents via Document AI Workbench.

Vision AI prête à l'emploi pour les vidéos
Basée sur la technologie de vision par ordinateur, l'API Video Intelligence permet de traiter, d'analyser et de comprendre facilement le contenu vidéo.
Ses modèles de ML pré-entraînés reconnaissent automatiquement un grand nombre d'objets, de lieux et d'actions dans les vidéos stockées et en streaming, avec une qualité exceptionnelle. Elle est très efficace pour les cas d'utilisation courants tels que la modération et les recommandations de contenus, les archives multimédias et les publicités contextuelles. Vous pouvez également entraîner des modèles de ML personnalisés en fonction de vos besoins spécifiques avec Vertex AI Vision.

Visual Inspection AI
Visual Inspection AI automatise les tâches d'inspection visuelle dans l'industrie manufacturière et d'autres environnements industriels. Il s'appuie sur des techniques avancées de vision par ordinateur et de deep learning pour analyser des images et des vidéos, identifier les anomalies, détecter et localiser les défauts, et vérifier les pièces manquantes et défectueuses dans les produits assemblés.
Vous pouvez entraîner des modèles personnalisés sans expertise technique et sans avoir à ajouter trop d'images étiquetées, exécuter efficacement des inférences sur les lignes de production et actualiser en permanence les modèles avec de nouvelles données de l'usine.

Plate-forme Vision AI unifiée
Vertex AI Vision est un environnement de développement d'applications entièrement géré qui permet aux développeurs de créer, déployer et gérer facilement des applications de vision par ordinateur afin de traiter différents types de données, comme du texte, des images, des vidéos et des données tabulaires. Il réduit le temps de développement de quelques jours à quelques minutes, et correspond à un dixième du coût des solutions actuelles.
Vous pouvez créer et déployer vos propres modèles personnalisés, et les gérer et les faire évoluer à l'aide de pipelines CI/CD. Il s'intègre également à des outils Open Source courants tels que TensorFlow et PyTorch.

Confidentialité des données et sécurité
Google Cloud dispose de fonctionnalités de pointe qui vous permettent, à nos clients, de contrôler vos données et de savoir quand et comment elles sont consultées.
En tant que client Google Cloud, vous êtes propriétaire de vos données client. Nous mettons en place des mesures de sécurité strictes pour protéger vos données client et vous fournissons des outils et des fonctionnalités qui vous permettent de les contrôler selon vos conditions. Les données client sont vos données, pas celles de Google. Nous traitons toujours vos données conformément aux accords que vous avez conclus.
Pour en savoir plus, consultez notre Centre de ressources sur la confidentialité.
Comparer les produits de vision par ordinateur
| Offres | Application idéale | Principales fonctionnalités |
|---|---|---|
Intégration simple et rapide des fonctionnalités de vision de base. | Fonctionnalités intégrées comme l'étiquetage d'images, la détection de visages et de points de repère, la reconnaissance optique des caractères et la recherche sécurisée Économique et facturé à l'utilisation. | |
Automatisez les workflows de documents : extrayez des insights à partir de documents scannés et d'images. | OCR (optimisé par l'IA générative), TLN, ML pour la compréhension de documents, l'extraction de texte, l'identification d'entités et la catégorisation des documents. | |
Analyse du contenu vidéo, de la modération et des recommandations de contenus, des archives multimédias et des annonces contextuelles. | Détection et suivi d'objets, compréhension de scènes, reconnaissance de l'activité, détection et analyse de visages, détection et reconnaissance de texte | |
Automatiser les tâches d'inspection visuelle dans les environnements industriels et de fabrication | Détectez et localisez les défauts, et vérifiez l'assemblage. | |
Créer et déployer des modèles personnalisés pour des besoins spécifiques | Outils de préparation des données, entraînement et déploiement des modèles, contrôle total de votre solution. Requiert des compétences techniques. | |
Compréhension visuelle et réponse à des questions multimodales. | Recherche d'informations, reconnaissance d'objets, compréhension du contenu numérique, génération de contenus structurés, sous-titres/description et extrapolation. | |
Obtenez des descriptions d'images automatiques. Classification et recherche d'images. Modération et recommandations de contenus. | Génération et modification d'images, sous-titres visuels et représentations vectorielles continues multimodales. Consultez la liste complète des fonctionnalités et de leurs étapes de lancement. |
Optimisés pour différentes utilisations, ces produits vous permettent d'exploiter les modèles de ML pré-entraînés et de vous lancer immédiatement, avec la possibilité de les ajuster facilement.
Intégration simple et rapide des fonctionnalités de vision de base.
Fonctionnalités intégrées comme l'étiquetage d'images, la détection de visages et de points de repère, la reconnaissance optique des caractères et la recherche sécurisée
Économique et facturé à l'utilisation.
Automatisez les workflows de documents : extrayez des insights à partir de documents scannés et d'images.
OCR (optimisé par l'IA générative), TLN, ML pour la compréhension de documents, l'extraction de texte, l'identification d'entités et la catégorisation des documents.
Analyse du contenu vidéo, de la modération et des recommandations de contenus, des archives multimédias et des annonces contextuelles.
Détection et suivi d'objets, compréhension de scènes, reconnaissance de l'activité, détection et analyse de visages, détection et reconnaissance de texte
Automatiser les tâches d'inspection visuelle dans les environnements industriels et de fabrication
Détectez et localisez les défauts, et vérifiez l'assemblage.
Créer et déployer des modèles personnalisés pour des besoins spécifiques
Outils de préparation des données, entraînement et déploiement des modèles, contrôle total de votre solution. Requiert des compétences techniques.
Compréhension visuelle et réponse à des questions multimodales.
Recherche d'informations, reconnaissance d'objets, compréhension du contenu numérique, génération de contenus structurés, sous-titres/description et extrapolation.
Obtenez des descriptions d'images automatiques.
Classification et recherche d'images.
Modération et recommandations de contenus.
Génération et modification d'images, sous-titres visuels et représentations vectorielles continues multimodales.
Consultez la liste complète des fonctionnalités et de leurs étapes de lancement.
Optimisés pour différentes utilisations, ces produits vous permettent d'exploiter les modèles de ML pré-entraînés et de vous lancer immédiatement, avec la possibilité de les ajuster facilement.
Fonctionnement
La suite d'outils Vision AI de Google Cloud associe la vision par ordinateur à d'autres technologies pour comprendre et analyser des vidéos, et intégrer facilement des fonctionnalités de détection visuelle dans des applications, telles que l'étiquetage d'images, la détection de visages et de points de repère, la reconnaissance optique des caractères et l'ajout de tags au contenu explicite.
Ces outils sont disponibles via des API tout en restant personnalisables en fonction de besoins spécifiques.
La suite d'outils Vision AI de Google Cloud associe la vision par ordinateur à d'autres technologies pour comprendre et analyser des vidéos, et intégrer facilement des fonctionnalités de détection visuelle dans des applications, telles que l'étiquetage d'images, la détection de visages et de points de repère, la reconnaissance optique des caractères et l'ajout de tags au contenu explicite.
Ces outils sont disponibles via des API tout en restant personnalisables en fonction de besoins spécifiques.

Démonstration
Découvrir comment la vision par ordinateur fonctionne avec vos propres fichiers
Utilisations courantes
Détecter le texte dans les fichiers bruts et le résumer automatiquement
Résumer des documents volumineux avec l'IA générative
La solution représentée dans le schéma d'architecture à droite déploie un pipeline qui se déclenche lorsque vous ajoutez un document PDF à votre bucket Cloud Storage. Le pipeline extrait le texte de votre document, crée un résumé à partir du texte extrait et le stocke dans une base de données que vous pouvez consulter et rechercher.
Vous pouvez appeler l'application en important des fichiers via un notebook Jupyter ou directement dans Cloud Storage depuis la console Google Cloud.

Durée de déploiement estimée : 11 min (1 min pour la configuration, 10 min pour le déploiement).
Guides pratiques
Résumer des documents volumineux avec l'IA générative
La solution représentée dans le schéma d'architecture à droite déploie un pipeline qui se déclenche lorsque vous ajoutez un document PDF à votre bucket Cloud Storage. Le pipeline extrait le texte de votre document, crée un résumé à partir du texte extrait et le stocke dans une base de données que vous pouvez consulter et rechercher.
Vous pouvez appeler l'application en important des fichiers via un notebook Jupyter ou directement dans Cloud Storage depuis la console Google Cloud.
Durée de déploiement estimée : 11 min (1 min pour la configuration, 10 min pour le déploiement).
Créer un pipeline de traitement d'images
Traitement d'images évolutif sur une architecture sans serveur
La solution, représentée dans le schéma de droite, utilise des modèles de machine learning pré-entraînés pour analyser les images fournies par les utilisateurs et générer des annotations d'image. Le déploiement de cette solution permet de créer un service de traitement d'images capable de vous aider à gérer les contenus générés par les utilisateurs non sécurisés ou nuisibles, à numériser le texte de documents physiques, à détecter et classer des objets dans des images, et plus encore.
Vous serez en mesure d'examiner la configuration et les paramètres de sécurité afin de comprendre comment adapter le service de traitement d'images à différents besoins.

Durée de déploiement estimée : 12 minutes (2 minutes pour la configuration et 10 minutes pour le déploiement).
Guides pratiques
Traitement d'images évolutif sur une architecture sans serveur
La solution, représentée dans le schéma de droite, utilise des modèles de machine learning pré-entraînés pour analyser les images fournies par les utilisateurs et générer des annotations d'image. Le déploiement de cette solution permet de créer un service de traitement d'images capable de vous aider à gérer les contenus générés par les utilisateurs non sécurisés ou nuisibles, à numériser le texte de documents physiques, à détecter et classer des objets dans des images, et plus encore.
Vous serez en mesure d'examiner la configuration et les paramètres de sécurité afin de comprendre comment adapter le service de traitement d'images à différents besoins.
Durée de déploiement estimée : 12 minutes (2 minutes pour la configuration et 10 minutes pour le déploiement).
Obtenez des descriptions d'images automatisées avec l'IA générative
La fonctionnalité Visual Captioning d'Imagen vous permet de générer une description pertinente d'une image. Elle vous permet d'obtenir des métadonnées plus détaillées sur les images à stocker et de rechercher, et de générer des sous-titres automatiques pour prendre en charge les cas d'utilisation de l'accessibilité, et recevoir une description rapide des produits et des ressources visuelles.
Disponible en allemand, anglais, espagnol, français et italien, cette fonctionnalité est accessible dans la console Google Cloud ou via un appel d'API.
Guides pratiques
La fonctionnalité Visual Captioning d'Imagen vous permet de générer une description pertinente d'une image. Elle vous permet d'obtenir des métadonnées plus détaillées sur les images à stocker et de rechercher, et de générer des sous-titres automatiques pour prendre en charge les cas d'utilisation de l'accessibilité, et recevoir une description rapide des produits et des ressources visuelles.
Disponible en allemand, anglais, espagnol, français et italien, cette fonctionnalité est accessible dans la console Google Cloud ou via un appel d'API.
Vidéos de traitement par flux
Dégager des insights à partir de vidéos en streaming avec Vertex AI Vision
Avant d'analyser vos données vidéo avec votre application, créez un pipeline pour le flux continu de données avec le service "Flux" de Vertex AI Vision. Les données ingérées sont ensuite analysées par les modèles pré-entraînés de Google ou par votre modèle personnalisé. Les résultats d'analyse des flux sont ensuite stockés dans Vertex AI Vision Warehouse, où vous pouvez utiliser des fonctionnalités de recherche avancées basées sur l'IA pour interroger du contenu multimédia non structuré.
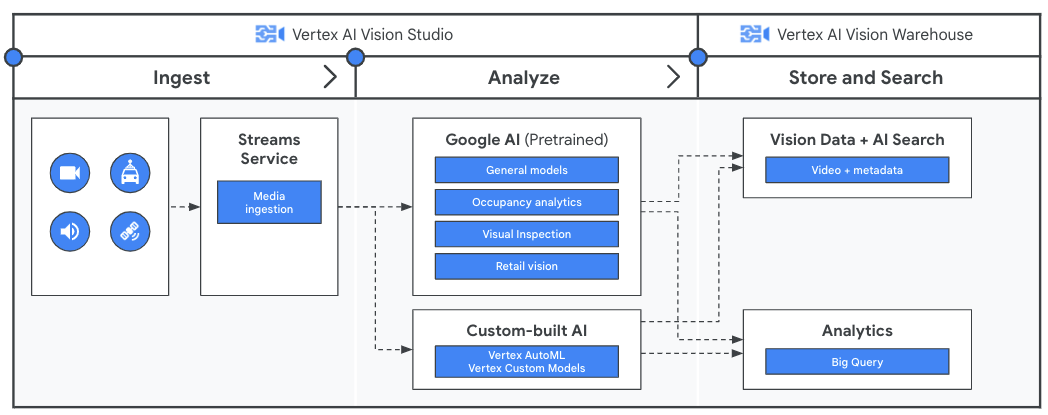
Guides pratiques
Dégager des insights à partir de vidéos en streaming avec Vertex AI Vision
Avant d'analyser vos données vidéo avec votre application, créez un pipeline pour le flux continu de données avec le service "Flux" de Vertex AI Vision. Les données ingérées sont ensuite analysées par les modèles pré-entraînés de Google ou par votre modèle personnalisé. Les résultats d'analyse des flux sont ensuite stockés dans Vertex AI Vision Warehouse, où vous pouvez utiliser des fonctionnalités de recherche avancées basées sur l'IA pour interroger du contenu multimédia non structuré.
Extrayez du texte et des insights de documents grâce à l'IA générative
Dégager des insights à partir de documents nuancés avec Document AI
S'appuyant sur un modèle de fondation, l'extracteur personnalisé Document AI extrait le texte et les données de documents, aussi bien génériques que spécifiques à un domaine, avec davantage de précision et de rapidité. Réglez l'extracteur facilement avec 5 à 10 documents seulement pour des performances encore supérieures.
Si vous souhaitez entraîner votre propre modèle, étiquetez automatiquement vos ensembles de données avec le modèle de fondation pour accélérer la mise en production.
Vous pouvez également choisir d'utiliser des processeurs spécialisés pré-entraînés. Consultez la liste complète des processeurs.
Guides pratiques
Dégager des insights à partir de documents nuancés avec Document AI
S'appuyant sur un modèle de fondation, l'extracteur personnalisé Document AI extrait le texte et les données de documents, aussi bien génériques que spécifiques à un domaine, avec davantage de précision et de rapidité. Réglez l'extracteur facilement avec 5 à 10 documents seulement pour des performances encore supérieures.
Si vous souhaitez entraîner votre propre modèle, étiquetez automatiquement vos ensembles de données avec le modèle de fondation pour accélérer la mise en production.
Vous pouvez également choisir d'utiliser des processeurs spécialisés pré-entraînés. Consultez la liste complète des processeurs.
Inspection visuelle haute précision
Automatiser le contrôle qualité avec Visual Inspection AI
Visual Inspection AI étant optimisée à chaque étape, elle est facile à configurer et permet d'évaluer rapidement votre ROI. Avec jusqu'à 300 fois moins d'images étiquetées pour commencer à entraîner des modèles d'inspection hautes performances que les plates-formes de ML à usage général, cette solution offre une précision jusqu'à 10 fois supérieure. Vous pouvez entraîner des modèles sans aucune expertise technique. Ils fonctionnent sur site. Et ce n'est pas tout : les modèles peuvent être actualisés en continu en fonction des données collectées depuis l'usine. Vous gagnez ainsi en précision lorsque vous découvrez de nouveaux cas d'utilisation.
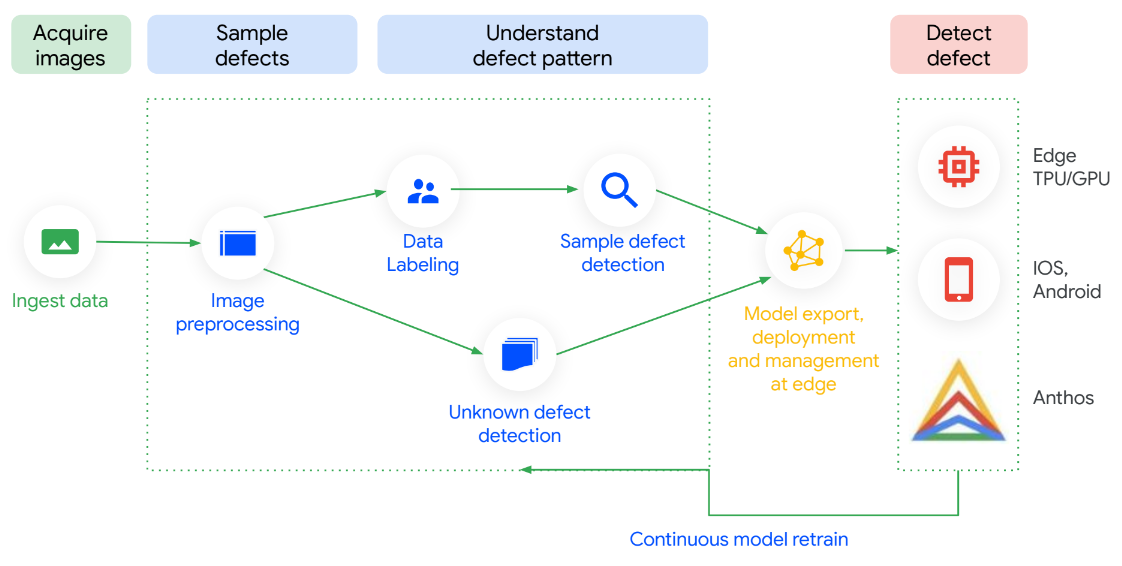
Guides pratiques
Automatiser le contrôle qualité avec Visual Inspection AI
Visual Inspection AI étant optimisée à chaque étape, elle est facile à configurer et permet d'évaluer rapidement votre ROI. Avec jusqu'à 300 fois moins d'images étiquetées pour commencer à entraîner des modèles d'inspection hautes performances que les plates-formes de ML à usage général, cette solution offre une précision jusqu'à 10 fois supérieure. Vous pouvez entraîner des modèles sans aucune expertise technique. Ils fonctionnent sur site. Et ce n'est pas tout : les modèles peuvent être actualisés en continu en fonction des données collectées depuis l'usine. Vous gagnez ainsi en précision lorsque vous découvrez de nouveaux cas d'utilisation.
Tarification
| Fonctionnement des tarifs de Vision AI | Chaque offre Vision est associée à un ensemble de fonctionnalités ou de processeurs, associés à des tarifs différents. Consultez les pages des tarifs détaillés pour en savoir plus. | ||
|---|---|---|---|
| Version gratuite | Produit/Service | Prix réduit | Détails |
API Vision | 1 000 premières unités tous les mois sont gratuits | 5 000 001 unités par mois | |
Document AI | N/A La tarification dépend du processeur. | Plus de 5 000 001 pages par mois pour le processeur Enterprise Document OCR | |
API Video Intelligence | 1 000 premières minutes par mois sont gratuits | Plus de 100 000 minutes par mois | |
Vertex AI Vision | N/A La tarification dépend des fonctionnalités. |
| |
Imagen : représentations vectorielles continues multimodales |
|
| 0,0001 $ US par entrée d'image |
Imagen : description d'images |
|
| 0,0015 $ US par image |
Gemini Pro Vision | |||
Fonctionnement des tarifs de Vision AI
Chaque offre Vision est associée à un ensemble de fonctionnalités ou de processeurs, associés à des tarifs différents. Consultez les pages des tarifs détaillés pour en savoir plus.
API Vision
1 000 premières unités
tous les mois sont gratuits
5 000 001 unités
par mois
Document AI
N/A
La tarification dépend du processeur.
Plus de 5 000 001 pages
par mois pour le processeur Enterprise Document OCR
1 000 premières minutes
par mois sont gratuits
Plus de 100 000 minutes
par mois
Vertex AI Vision
N/A
La tarification dépend des fonctionnalités.
Imagen : représentations vectorielles continues multimodales
0,0001 $ US
par entrée d'image
Imagen : description d'images
0,0015 $ US
par image











