Vision AI
Extrae información valiosa de imágenes, documentos y vídeos
Accede a modelos de visión avanzados a través de APIs para automatizar tareas de visión, optimizar los análisis y obtener métricas útiles. También puedes crear aplicaciones personalizadas sin código de preparación de modelos y de bajo coste en un entorno gestionado.
Los nuevos clientes reciben hasta 300 USD en crédito gratis para probar Vision AI y otros productos de Google Cloud.
También puedes probar a desplegar las soluciones de resumen de documentos y de procesamiento de imágenes con IA y aprendizaje automático recomendadas por Google.
Información general
¿Qué es la visión artificial?
La visión artificial es un campo de la inteligencia artificial (IA) que permite a los ordenadores y sistemas interpretar y analizar datos visuales y obtener información pertinente a partir de imágenes digitales, vídeos y otros datos visuales. Algunas de sus aplicaciones habituales en el mundo real son la detección de objetos, el procesamiento de contenido visual (imágenes, documentos, vídeos), la comprensión y el análisis, la búsqueda de productos, la clasificación y búsqueda de imágenes y la moderación de contenido.
IA generativa multimodal avanzada
Vertex AI de Google Cloud ofrece acceso a Gemini, una familia de modelos multimodales y vanguardistas que pueden comprender prácticamente cualquier tipo de entrada, combinar diferentes tipos de información y generar casi cualquier salida. Aunque Gemini es más adecuado para tareas que combinan elementos visuales, texto y código, Gemini Pro Vision destaca en una gran variedad de tareas relacionadas con la visión, como el reconocimiento de objetos, la comprensión de contenido digital, los subtítulos y las descripciones. Se puede acceder a él a través de una API.
IA generativa centrada en la visión
Imagen en Vertex AI ofrece a los desarrolladores de aplicaciones las funciones vanguardistas de IA generativa de imágenes de Google a través de una API. Algunas de sus funciones clave son la generación de imágenes (GA restringido) con peticiones de texto y la edición de imágenes (GA restringido) con peticiones de texto, la descripción de una imagen en texto (también llamada "descripción visual", GA) y ajuste del modelo sujeto (GA restringido). Consulta más información sobre sus funciones principales y las fases de lanzamiento.
Vision AI lista para usar
La API de Cloud Vision, que usa la tecnología de Google de modelos de aprendizaje automático de visión artificial entrenados previamente, es una API de disponibilidad inmediata (REST y RPC) que permite a los desarrolladores integrar fácilmente funciones habituales de detección de visión en sus aplicaciones, como etiquetado de imágenes, detección de caras y puntos de referencia, reconocimiento óptico de caracteres (OCR) y etiquetado de contenido explícito.
Cada función que aplicas a una imagen es una unidad facturable: la API de Cloud Vision te permite usar 1000 unidades de sus funciones de forma gratuita al mes. Consulta la información sobre precios.
IA generativa para interpretar documentos
Document AI es una plataforma de comprensión de documentos que combina la visión artificial y otras tecnologías, como el procesamiento del lenguaje natural, para extraer texto y datos de documentos escaneados y transformar los datos no estructurados en información estructurada y estadísticas empresariales.
Ofrece una amplia gama de procesadores entrenados previamente optimizados para diferentes tipos de documentos. También facilita la creación de procesadores personalizados para clasificar, dividir y extraer datos estructurados de documentos mediante Document AI Workbench.

Vision AI lista para usar en vídeos
La API de Video Intelligence, centrada en la tecnología de visión artificial, permite procesar, analizar y comprender fácilmente el contenido de vídeo.
Sus modelos de aprendizaje automático preentrenados reconocen automáticamente una gran cantidad de objetos, lugares y acciones en vídeos almacenados y en streaming con una calidad excepcional. Es muy eficaz en casos prácticos habituales, como la moderación y las recomendaciones de contenido, los archivos multimedia y los anuncios contextuales. También puedes entrenar modelos de aprendizaje automático personalizados con Vertex AI Vision según tus necesidades.

Visual Inspection AI
Visual Inspection AI automatiza las tareas de inspección visual en fábricas y otros entornos industriales. Utiliza técnicas avanzadas de visión artificial y aprendizaje profundo para analizar imágenes y vídeos, identificar anomalías, detectar y localizar defectos y comprobar piezas que falten o que tengan defectos en los productos ensamblados.
Puedes entrenar modelos personalizados sin conocimientos técnicos y usar un mínimo de imágenes etiquetadas, ejecutar inferencias de forma eficiente en las líneas de producción y actualizar continuamente los modelos con datos actualizados de la planta de producción.

Vision AI Platform unificada
Vertex AI Vision es un entorno de desarrollo de aplicaciones totalmente gestionado que permite a los desarrolladores crear, desplegar y gestionar fácilmente aplicaciones de visión artificial para procesar varias modalidades de datos, como texto, imágenes, vídeo y datos tabulares. Además, reduce el tiempo de desarrollo de días a minutos por una décima parte del coste de los productos actuales.
Puedes crear y desplegar tus propios modelos personalizados, así como gestionarlos y escalarlos con flujos de procesamiento de CI/CD. Además, se integra con herramientas populares de software libre, como TensorFlow y PyTorch.

Privacidad y seguridad de los datos
Google Cloud cuenta con funciones punteras en el sector que permiten a nuestros clientes controlar sus datos y saber cuándo y cómo se accede a ellos.
Como cliente de Google Cloud, tú eres el propietario de tus datos de clientes Por tanto, implementamos unas medidas de seguridad estrictas para proteger tus datos de clientes y te proporcionamos las herramientas y funciones para que puedas controlar esos datos como desees. Tú eres el propietario de los datos de clientes, no Google. A la hora de tratar tus datos, seguimos estrictamente tus contratos.
Consulta más información en nuestro centro de recursos de privacidad.
Compara productos de visión artificial
| Servicios ofrecidos | Usos recomendados | Características principales |
|---|---|---|
Integración rápida y sencilla de funciones de visión básicas. | Funciones predefinidas como el etiquetado de imágenes, la detección de caras y puntos de referencia, el OCR y la búsqueda segura. Es rentable y se paga por uso. | |
Extrae información valiosa de documentos e imágenes escaneados y automatiza los flujos de trabajo de los documentos. | OCR (con tecnología de IA generativa), PLN y aprendizaje automático para comprender documentos, extraer texto, identificar entidades y categoriza documentos. | |
Analizar el contenido de los vídeos, moderación y recomendación de contenido, archivos multimedia y anuncios contextuales. | Detección y seguimiento de objetos, comprensión de escenas, reconocimiento de actividades, análisis y detección de caras, detección y reconocimiento de texto. | |
Automatizar tareas de inspección visual en entornos industriales y de fabricación | Detectar anomalías, detectar y localizar defectos y comprobar el montaje. | |
Crear y desplegar modelos personalizados para necesidades concretas. | Herramientas de preparación de datos, entrenamiento y despliegue de modelos y control total sobre tu solución. Se requieren conocimientos técnicos. | |
Análisis y comprensión visuales, búsqueda de respuestas multimodal. | Búsqueda de información, reconocimiento de objetos, comprensión de contenido digital, generación de contenido estructurado, subtítulos y descripciones y extrapolación. | |
Obtén descripciones de imágenes de forma automática. Clasificación y búsqueda de imágenes. Recomendaciones y moderación de contenido. | Creación de imágenes, edición de imágenes, descripciones visuales e incrustaciones multimodales. Consulta la lista completa de funciones y sus fases de lanzamiento. |
Estos productos, optimizados para diferentes propósitos, te permiten aprovechar los modelos de aprendizaje automático preentrenados y dar los primeros pasos con la posibilidad de hacer ajustes fácilmente.
Integración rápida y sencilla de funciones de visión básicas.
Funciones predefinidas como el etiquetado de imágenes, la detección de caras y puntos de referencia, el OCR y la búsqueda segura.
Es rentable y se paga por uso.
Extrae información valiosa de documentos e imágenes escaneados y automatiza los flujos de trabajo de los documentos.
OCR (con tecnología de IA generativa), PLN y aprendizaje automático para comprender documentos, extraer texto, identificar entidades y categoriza documentos.
Analizar el contenido de los vídeos, moderación y recomendación de contenido, archivos multimedia y anuncios contextuales.
Detección y seguimiento de objetos, comprensión de escenas, reconocimiento de actividades, análisis y detección de caras, detección y reconocimiento de texto.
Automatizar tareas de inspección visual en entornos industriales y de fabricación
Detectar anomalías, detectar y localizar defectos y comprobar el montaje.
Crear y desplegar modelos personalizados para necesidades concretas.
Herramientas de preparación de datos, entrenamiento y despliegue de modelos y control total sobre tu solución. Se requieren conocimientos técnicos.
Análisis y comprensión visuales, búsqueda de respuestas multimodal.
Búsqueda de información, reconocimiento de objetos, comprensión de contenido digital, generación de contenido estructurado, subtítulos y descripciones y extrapolación.
Obtén descripciones de imágenes de forma automática.
Clasificación y búsqueda de imágenes.
Recomendaciones y moderación de contenido.
Creación de imágenes, edición de imágenes, descripciones visuales e incrustaciones multimodales.
Consulta la lista completa de funciones y sus fases de lanzamiento.
Estos productos, optimizados para diferentes propósitos, te permiten aprovechar los modelos de aprendizaje automático preentrenados y dar los primeros pasos con la posibilidad de hacer ajustes fácilmente.
Cómo funciona
El paquete de herramientas Vision AI de Google Cloud combina la visión artificial con otras tecnologías para comprender y analizar vídeos e integrar fácilmente funciones de detección de visión en las aplicaciones, como el etiquetado de imágenes, la detección de caras y puntos de referencia, el reconocimiento óptico de caracteres (OCR) y el etiquetado de contenido explícito.
Estas herramientas están disponibles mediante APIs, pero se pueden personalizar según necesidades concretas.
El paquete de herramientas Vision AI de Google Cloud combina la visión artificial con otras tecnologías para comprender y analizar vídeos e integrar fácilmente funciones de detección de visión en las aplicaciones, como el etiquetado de imágenes, la detección de caras y puntos de referencia, el reconocimiento óptico de caracteres (OCR) y el etiquetado de contenido explícito.
Estas herramientas están disponibles mediante APIs, pero se pueden personalizar según necesidades concretas.

Demo
Descubre cómo funciona la visión artificial con tus propios archivos
Usos habituales
Detecta texto en archivos sin procesar y resúmelo automáticamente
Resume documentos extensos con IA generativa
La solución que se muestra en el diagrama de arquitectura de la derecha despliega un flujo de procesamiento que se activa cuando añades un nuevo documento PDF a tu segmento de Cloud Storage. El flujo de procesamiento extrae el texto del documento, crea un resumen a partir del texto extraído y almacena el resumen en una base de datos para que puedas verlo y buscarlo.
Puedes invocar la aplicación subiendo archivos a través de Jupyter Notebook o directamente a Cloud Storage en la consola de Google Cloud.

Tiempo estimado del despliegue: 11 min (1 min para configurar, 10 min para desplegar).
Instrucciones
Resume documentos extensos con IA generativa
La solución que se muestra en el diagrama de arquitectura de la derecha despliega un flujo de procesamiento que se activa cuando añades un nuevo documento PDF a tu segmento de Cloud Storage. El flujo de procesamiento extrae el texto del documento, crea un resumen a partir del texto extraído y almacena el resumen en una base de datos para que puedas verlo y buscarlo.
Puedes invocar la aplicación subiendo archivos a través de Jupyter Notebook o directamente a Cloud Storage en la consola de Google Cloud.
Tiempo estimado del despliegue: 11 min (1 min para configurar, 10 min para desplegar).
Crea un flujo de procesamiento de imágenes
Procesamiento de imágenes escalable en una arquitectura sin servidor
La solución, que se muestra en el diagrama de la derecha, utiliza modelos de aprendizaje automático preentrenados para analizar imágenes proporcionadas por los usuarios y generar anotaciones de imágenes. Al desplegar esta solución, se crea un servicio de procesamiento de imágenes que puede ayudarte a gestionar contenido peligroso o dañino creado por los usuarios, digitalizar texto de documentos físicos, detectar y clasificar objetos en imágenes y mucho más.
Podrás revisar los ajustes de configuración y seguridad para saber cómo adaptar el servicio de procesamiento de imágenes a distintas necesidades.

Tutorial: crea un flujo de procesamiento de analíticas de visión para procesar una gran cantidad de imágenes
Documentación completa: procesamiento de imágenes con IA y aprendizaje automático en Cloud Functions
Guía completa paso a paso: desplegar el flujo de procesamiento de imágenes mediante la CLI de Terraform
Tiempo estimado del despliegue: 12 min (2 min para configurar, 10 min para desplegar).
Instrucciones
Procesamiento de imágenes escalable en una arquitectura sin servidor
La solución, que se muestra en el diagrama de la derecha, utiliza modelos de aprendizaje automático preentrenados para analizar imágenes proporcionadas por los usuarios y generar anotaciones de imágenes. Al desplegar esta solución, se crea un servicio de procesamiento de imágenes que puede ayudarte a gestionar contenido peligroso o dañino creado por los usuarios, digitalizar texto de documentos físicos, detectar y clasificar objetos en imágenes y mucho más.
Podrás revisar los ajustes de configuración y seguridad para saber cómo adaptar el servicio de procesamiento de imágenes a distintas necesidades.
Tutorial: crea un flujo de procesamiento de analíticas de visión para procesar una gran cantidad de imágenes
Documentación completa: procesamiento de imágenes con IA y aprendizaje automático en Cloud Functions
Guía completa paso a paso: desplegar el flujo de procesamiento de imágenes mediante la CLI de Terraform
Tiempo estimado del despliegue: 12 min (2 min para configurar, 10 min para desplegar).
Consigue descripciones de imágenes automatizadas con la IA generativa
La función de descripción visual de Imagen te permite generar una descripción pertinente de una imagen. Puedes utilizarla para obtener metadatos más detallados sobre las imágenes que puedes almacenar y buscar, o para crear subtítulos automáticos. en casos prácticos de accesibilidad y recibir descripciones rápidas de productos y recursos visuales.
Esta función está disponible en alemán, español, francés, inglés e italiano. Puedes acceder a ella en la consola de Google Cloud o a través de una llamada a la API.
Instrucciones
La función de descripción visual de Imagen te permite generar una descripción pertinente de una imagen. Puedes utilizarla para obtener metadatos más detallados sobre las imágenes que puedes almacenar y buscar, o para crear subtítulos automáticos. en casos prácticos de accesibilidad y recibir descripciones rápidas de productos y recursos visuales.
Esta función está disponible en alemán, español, francés, inglés e italiano. Puedes acceder a ella en la consola de Google Cloud o a través de una llamada a la API.
Vídeos procesados en streaming
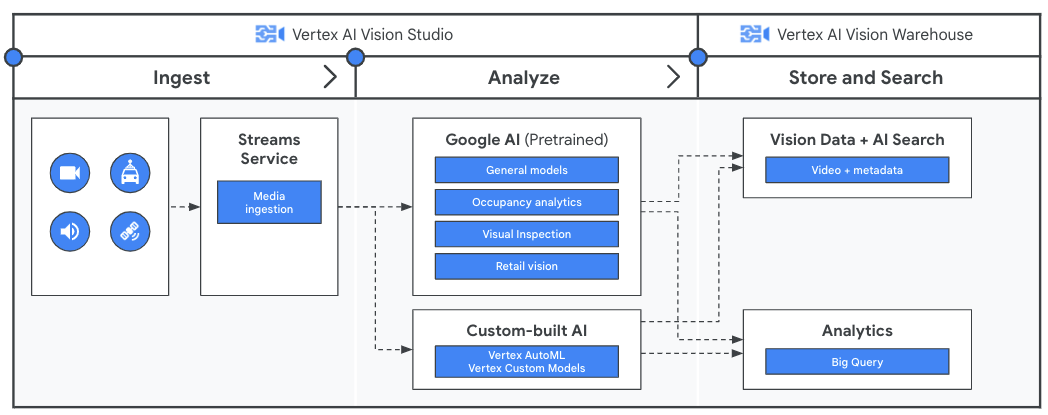
Extrae información valiosa de vídeos en streaming con Vertex AI Vision
Antes de analizar los datos de vídeo con tu aplicación, crea un flujo de procesamiento para el flujo continuo de datos con el servicio Streams de Vertex AI Vision. Los datos ingeridos los analizan los modelos entrenados previamente de Google o tu modelo personalizado. Los resultados del análisis de los flujos se almacenan en Vertex AI Vision Warehouse, donde puedes usar funciones avanzadas de búsqueda basadas en IA para consultar contenido multimedia sin estructurar.
Instrucciones
Extrae información valiosa de vídeos en streaming con Vertex AI Vision
Antes de analizar los datos de vídeo con tu aplicación, crea un flujo de procesamiento para el flujo continuo de datos con el servicio Streams de Vertex AI Vision. Los datos ingeridos los analizan los modelos entrenados previamente de Google o tu modelo personalizado. Los resultados del análisis de los flujos se almacenan en Vertex AI Vision Warehouse, donde puedes usar funciones avanzadas de búsqueda basadas en IA para consultar contenido multimedia sin estructurar.
Extrae texto y estadísticas de documentos con IA generativa
Descubre información valiosa a partir de documentos específicos con Document AI
El extractor personalizado de Document AI se basa en un modelo básico que extrae texto y datos de documentos genéricos y específicos de un dominio, de forma más rápida y precisa. Ajusta fácilmente entre 5 y 10 documentos para mejorar el rendimiento.
Si quieres entrenar tu propio modelo, etiqueta automáticamente tus conjuntos de datos con el modelo básico para agilizar la producción.
También puedes utilizar procesadores especializados entrenados previamente. Consulta la lista completa de procesadores.
Instrucciones
Descubre información valiosa a partir de documentos específicos con Document AI
El extractor personalizado de Document AI se basa en un modelo básico que extrae texto y datos de documentos genéricos y específicos de un dominio, de forma más rápida y precisa. Ajusta fácilmente entre 5 y 10 documentos para mejorar el rendimiento.
Si quieres entrenar tu propio modelo, etiqueta automáticamente tus conjuntos de datos con el modelo básico para agilizar la producción.
También puedes utilizar procesadores especializados entrenados previamente. Consulta la lista completa de procesadores.
Inspección visual de alta precisión
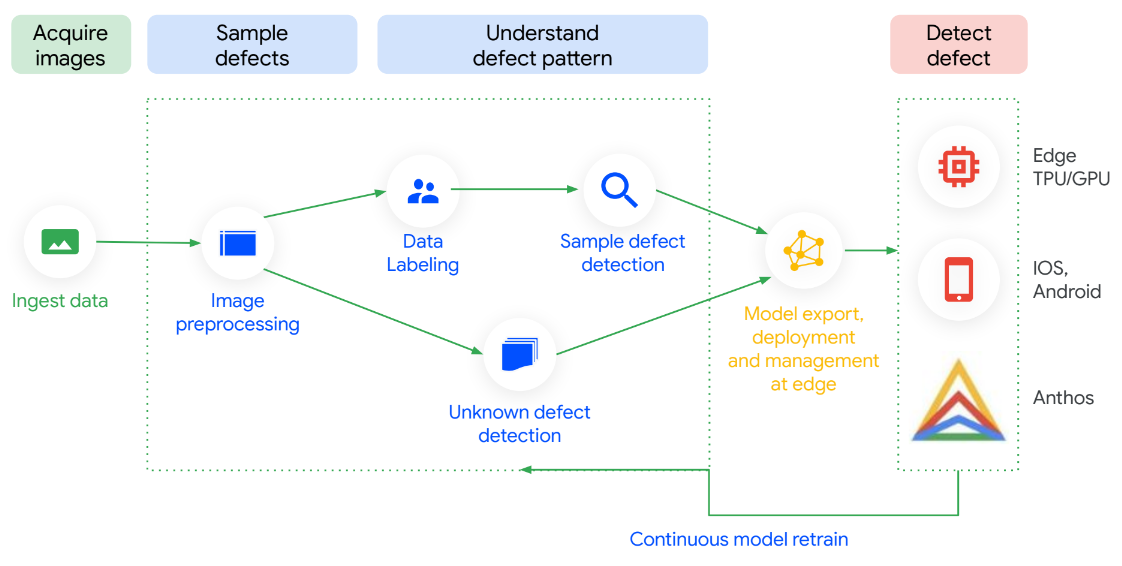
Automatiza las inspecciones de calidad con Visual Inspection AI
Visual Inspector AI se optimiza en cada paso para que puedas configurar el dispositivo fácilmente y comprobar el retorno de la inversión en un abrir y cerrar de ojos. Gracias a que ofrece hasta 300 veces menos imágenes etiquetadas para empezar a entrenar modelos de inspección de alto rendimiento en comparación con las plataformas de aprendizaje automático de uso general, ha demostrado que ofrece una precisión hasta 10 veces mayor. Puedes entrenar modelos que se ejecutan on-premise sin conocimientos técnicos. Y lo mejor de todo es que los modelos se pueden actualizar continuamente a medida que fluyen datos desde la fábrica, lo que ofrece una mayor precisión a medida que descubres nuevos casos prácticos.
Instrucciones
Automatiza las inspecciones de calidad con Visual Inspection AI
Visual Inspector AI se optimiza en cada paso para que puedas configurar el dispositivo fácilmente y comprobar el retorno de la inversión en un abrir y cerrar de ojos. Gracias a que ofrece hasta 300 veces menos imágenes etiquetadas para empezar a entrenar modelos de inspección de alto rendimiento en comparación con las plataformas de aprendizaje automático de uso general, ha demostrado que ofrece una precisión hasta 10 veces mayor. Puedes entrenar modelos que se ejecutan on-premise sin conocimientos técnicos. Y lo mejor de todo es que los modelos se pueden actualizar continuamente a medida que fluyen datos desde la fábrica, lo que ofrece una mayor precisión a medida que descubres nuevos casos prácticos.
Precios
| Cómo funcionan los precios de Vision AI | Cada oferta de Vision tiene un conjunto de funciones o procesadores con precios distintos. Consulta las páginas de precios detallados para obtener más información. | ||
|---|---|---|---|
| Nivel gratuito | Producto/servicio | Precio con descuento | Detalles |
API Vision | 1000 primeras unidades al mes son gratis | 5.000.001+ unidades al mes | |
Document AI | N/A Los precios dependen del procesador. | Más de 5.000.001 páginas al mes para un procesador de Enterprise Document OCR | |
API de Video Intelligence | Primeros 1000 minutos al mes gratis | Más de 100.000 minutos al mes | |
Vertex AI Vision | N/A Los precios dependen de las funciones. |
| |
Imagen: incrustaciones multimodales |
|
| 0,0001 $ por entrada de imagen |
Imagen: descripción visual |
|
| 0,0015 $ por imagen |
Gemini Pro Vision | |||
Cómo funcionan los precios de Vision AI
Cada oferta de Vision tiene un conjunto de funciones o procesadores con precios distintos. Consulta las páginas de precios detallados para obtener más información.
API Vision
1000 primeras unidades
al mes son gratis
5.000.001+ unidades
al mes
Document AI
N/A
Los precios dependen del procesador.
Más de 5.000.001 páginas
al mes para un procesador de Enterprise Document OCR
Primeros 1000 minutos
al mes gratis
Más de 100.000 minutos
al mes
Vertex AI Vision
N/A
Los precios dependen de las funciones.
Imagen: incrustaciones multimodales
0,0001 $
por entrada de imagen
Imagen: descripción visual
0,0015 $
por imagen











