Vision AI
Informationen aus Bildern, Dokumenten und Videos extrahieren
Über APIs können Sie auf fortschrittliche Vision-Modelle zugreifen, um Visionsaufgaben zu automatisieren, Analysen zu optimieren und umsetzbare Informationen zu gewinnen. Oder entwickeln Sie benutzerdefinierte Anwendungen mit programmierfreiem Modelltraining und geringen Kosten in einer verwalteten Umgebung.
Neukunden erhalten ein Guthaben von bis zu 300 $, um Vision AI und andere Google Cloud-Produkte auszuprobieren.
Sie können auch versuchen, von Google empfohlene Lösungen zur Zusammenfassung von Dokumenten und zur KI-/ML-Bildverarbeitung bereitzustellen.
Überblick
Was ist maschinelles Sehen?
Maschinelles Sehen ist ein Bereich der künstlichen Intelligenz (KI), der es Computern und Systemen ermöglicht, visuelle Daten zu interpretieren und zu analysieren und aus digitalen Bildern, Videos und anderen visuellen Elementen aussagekräftige Informationen abzuleiten. Zu den typischen Anwendungen in der Praxis gehören: Objekterkennung, Verarbeitung visueller Inhalte (Bilder, Dokumente, Videos), Verständnis und Analyse, Produktsuche, Bildklassifizierung und -suche sowie Inhaltsmoderation.
Fortschrittliche multimodale generative KI
Vertex AI von Google Cloud bietet Zugriff auf Gemini, ein hochmodernes, multimodales Modell, das praktisch jede Eingabe verstehen, verschiedene Arten von Informationen kombinieren und fast jede Ausgabe generieren kann. Gemini ist zwar am besten für Aufgaben geeignet, bei denen Bilder, Text und Code kombiniert werden, aber Gemini Pro Vision eignet sich hervorragend für eine Vielzahl von Aufgaben im Zusammenhang mit Sehvermögen, z. B. Objekterkennung, Verstehen von digitalen Inhalten sowie Untertitelung/Beschreibung. Der Zugriff ist über eine API möglich.
Generative KI mit Fokus auf Vision
Imagen in Vertex AI stellt Anwendungsentwicklern über eine API die hochmodernen Funktionen für generative KI von Google zur Verfügung. Zu den wichtigsten Funktionen gehören die Bildgenerierung (eingeschränkte GA) mit Text-Prompts, Bildbearbeitung (eingeschränkte GA) mit Text-Prompts, beschreiben eines Bildes in Text (auch als „visuelle Untertitel“ bezeichnet) und Feinabstimmung des Themenmodells (eingeschränkte GA). Weitere Informationen zu den wichtigsten Funktionen und Markteinführungsphasen
Sofort einsatzbereite Vision AI
Die Cloud Vision API basiert auf vortrainierten ML-Modellen für maschinelles Sehen von Google und ist eine sofort verfügbare API (REST und RPC), mit der Entwickler gängige Funktionen zur visuellen Erkennung einfach in Anwendungen einbinden können. Dazu gehören: Bildbeschriftung, Erkennung von Gesichtern und Sehenswürdigkeiten, optische Zeichenerkennung (Optical Character Recognition, OCR) und Taggen von anstößigen Inhalten.
Jede Funktion, die Sie auf ein Bild anwenden, ist eine kostenpflichtige Einheit. Mit der Cloud Vision API können Sie jeden Monat 1.000 Funktionen des Features kostenlos nutzen. Beachten Sie die Preisangaben.
Dokumentverständnis – Generative KI
Document AI ist eine Plattform zum Verstehen von Dokumenten, die maschinelles Sehen und andere Technologien wie Natural Language Processing kombiniert, um Text und Daten aus gescannten Dokumenten zu extrahieren und unstrukturierte Daten in strukturierte Informationen und Geschäftseinblicke umzuwandeln.
Es bietet eine breite Palette vortrainierter Prozessoren, die für verschiedene Arten von Dokumenten optimiert sind. Außerdem lassen sich damit ganz einfach benutzerdefinierte Prozessoren zum Klassifizieren, Aufteilen und Extrahieren strukturierter Daten aus Dokumenten über Document AI Workbench erstellen.

Sofort einsatzbereite Vision AI für Videos
Mit der Technologie für maschinelles Sehen im Kern stellt die Video Intelligence API eine einfache Möglichkeit dar, Videoinhalte zu verarbeiten, zu analysieren und zu verstehen.
Die vortrainierten ML-Modelle erkennen automatisch eine Vielzahl von Objekten, Orten und Aktionen in gespeicherten und gestreamten Videos in außergewöhnlicher Qualität. Diese Lösung ist äußerst effizient bei häufigen Anwendungsfällen wie Inhaltsmoderation und -empfehlung, Medienarchiven und kontextbezogene Werbung. Sie können auch benutzerdefinierte ML-Modelle mit Vertex AI Vision für Ihre spezifischen Anforderungen trainieren.

Visual Inspection AI
Visual Inspection AI automatisiert visuelle Inspektionsaufgaben in der Fertigung und in anderen industriellen Umgebungen. Dabei kommen fortschrittliche Techniken für maschinelles Sehen und Deep Learning zum Einsatz, um Bilder und Videos zu analysieren, Anomalien zu identifizieren, Fehler zu erkennen und zu lokalisieren sowie fehlende und defekte Teile in montierten Produkten zu prüfen.
Sie können benutzerdefinierte Modelle ohne technisches Fachwissen und mit minimalen Labels für Bilder trainieren, Inferenzen an Produktionslinien effizient ausführen und Modelle kontinuierlich mit aktuellen Daten aus der Fabrik aktualisieren.

Unified Vision AI Platform
Vertex AI Vision ist eine vollständig verwaltete Umgebung für die Anwendungsentwicklung, mit der Entwicklerinnen und Entwickler ganz einfach Anwendungen für maschinelles Sehen erstellen, bereitstellen und verwalten können, um unterschiedliche Datenmodalitäten wie Texte, Bilder, Video- und tabellarische Daten zu verarbeiten. Sie verkürzt die Dauer von Tagen auf Minuten bei einem Zehntel der Kosten der aktuellen Angebote.
Sie können Ihre eigenen benutzerdefinierten Modelle erstellen und bereitstellen sowie mit CI/CD-Pipelines verwalten und skalieren. Sie lässt sich auch in beliebte Open-Source-Tools wie TensorFlow und PyTorch einbinden.

Daten, Datenschutz und Sicherheit
Google Cloud bietet branchenführende Funktionen, die Ihnen – unseren Kunden – die Kontrolle über Ihre Daten geben und Transparenz bieten, wann und wie auf sie zugegriffen wird.
Als Google Cloud-Kunde sind Sie der Inhaber Ihrer Kundendaten. Wir setzen strenge Sicherheitsmaßnahmen ein, um Ihre Kundendaten zu schützen und stellen Ihnen Tools und Funktionen zur Verfügung, mit denen Sie Ihre Kundendaten selbst kontrollieren können. Kundendaten gehören Ihnen und nicht Google. Wir verarbeiten Ihre Daten nur gemäß den mit Ihnen geschlossenen Vereinbarungen.
Weitere Informationen findest du in unserem Datenschutz-Center.
Produkte für maschinelles Sehen vergleichen
| Angebot | Optimal für | Wichtige Features |
|---|---|---|
Einfache Integration grundlegender Sehfunktionen | Vordefinierte Funktionen wie Bildbeschriftung, Erkennung von Gesichtern und Sehenswürdigkeiten, OCR, SafeSearch. Kostengünstig, nutzungsabhängig. | |
Extrahieren von Informationen aus gescannten Dokumenten und Bildern zur Automatisierung von Dokument-Workflows | OCR (unterstützt durch generative KI), NLP, ML für das Verstehen von Dokumenten, Textextraktion, Entitätsidentifikation, Dokumentkategorisierung. | |
Analyse von Videoinhalten, Inhaltsmoderation und -empfehlungen, Medienarchiven und kontextbezogenen Anzeigen. | Objekterkennung und -verfolgung, Szenenerkennung, Aktivitätserkennung, Gesichtserkennung und -analyse, Texterkennung. | |
Aufgaben der visuellen Inspektionen in der Fertigungs- und Industriebranche automatisieren | Anomalien erkennen, Mängel erkennen und lokalisieren sowie die Montage prüfen. | |
Benutzerdefinierte Modelle für bestimmte Anforderungen erstellen und bereitstellen | Tools zur Datenvorbereitung, Modelltraining und -bereitstellung, vollständige Kontrolle über Ihre Lösung. Technisches Fachwissen erforderlich. | |
Visuelle Analyse und Verständnis, multimodale Fragenbeantwortung. | Informationssuche, Objekterkennung, Verständnis digitaler Inhalte, Generieren strukturierter Inhalte, Untertitelung/Beschreibung und Extrapolation. | |
Automatische Bildbeschreibungen nutzen Bildklassifizierung und -suche Moderation von Inhalten und Empfehlungen | Bildgenerierung, Bildbearbeitung, visuelle Untertitel und multimodale Einbettung Eine vollständige Liste der Funktionen und ihrer Einführungsphasen finden Sie hier. |
Diese Produkte sind für verschiedene Zwecke optimiert und bieten Ihnen die Möglichkeit, vortrainierte ML-Modelle zu nutzen und sofort durchzustarten, mit der Möglichkeit einer einfachen Feinabstimmung.
Einfache Integration grundlegender Sehfunktionen
Vordefinierte Funktionen wie Bildbeschriftung, Erkennung von Gesichtern und Sehenswürdigkeiten, OCR, SafeSearch.
Kostengünstig, nutzungsabhängig.
Extrahieren von Informationen aus gescannten Dokumenten und Bildern zur Automatisierung von Dokument-Workflows
OCR (unterstützt durch generative KI), NLP, ML für das Verstehen von Dokumenten, Textextraktion, Entitätsidentifikation, Dokumentkategorisierung.
Analyse von Videoinhalten, Inhaltsmoderation und -empfehlungen, Medienarchiven und kontextbezogenen Anzeigen.
Objekterkennung und -verfolgung, Szenenerkennung, Aktivitätserkennung, Gesichtserkennung und -analyse, Texterkennung.
Aufgaben der visuellen Inspektionen in der Fertigungs- und Industriebranche automatisieren
Anomalien erkennen, Mängel erkennen und lokalisieren sowie die Montage prüfen.
Benutzerdefinierte Modelle für bestimmte Anforderungen erstellen und bereitstellen
Tools zur Datenvorbereitung, Modelltraining und -bereitstellung, vollständige Kontrolle über Ihre Lösung. Technisches Fachwissen erforderlich.
Visuelle Analyse und Verständnis, multimodale Fragenbeantwortung.
Informationssuche, Objekterkennung, Verständnis digitaler Inhalte, Generieren strukturierter Inhalte, Untertitelung/Beschreibung und Extrapolation.
Automatische Bildbeschreibungen nutzen
Bildklassifizierung und -suche
Moderation von Inhalten und Empfehlungen
Bildgenerierung, Bildbearbeitung, visuelle Untertitel und multimodale Einbettung
Eine vollständige Liste der Funktionen und ihrer Einführungsphasen finden Sie hier.
Diese Produkte sind für verschiedene Zwecke optimiert und bieten Ihnen die Möglichkeit, vortrainierte ML-Modelle zu nutzen und sofort durchzustarten, mit der Möglichkeit einer einfachen Feinabstimmung.
Funktionsweise
Die Vision AI-Tools von Google Cloud kombinieren maschinelles Sehen mit anderen Technologien, um Videos zu verstehen und zu analysieren und Funktionen zur visuellen Erkennung einfach in Anwendungen zu integrieren. Dazu gehören die Erkennung von Bildlabels, Gesichtern und Sehenswürdigkeiten, die optische Zeichenerkennung (Optical Character Recognition, OCR) sowie das Tagging expliziter Inhalte.
Diese Tools sind über APIs verfügbar und können gleichzeitig an bestimmte Anforderungen angepasst werden.
Die Vision AI-Tools von Google Cloud kombinieren maschinelles Sehen mit anderen Technologien, um Videos zu verstehen und zu analysieren und Funktionen zur visuellen Erkennung einfach in Anwendungen zu integrieren. Dazu gehören die Erkennung von Bildlabels, Gesichtern und Sehenswürdigkeiten, die optische Zeichenerkennung (Optical Character Recognition, OCR) sowie das Tagging expliziter Inhalte.
Diese Tools sind über APIs verfügbar und können gleichzeitig an bestimmte Anforderungen angepasst werden.

Demo
So funktioniert maschinelles Sehen bei Dateien
Gängige Einsatzmöglichkeiten
Text in Rohdateien erkennen und automatisch zusammenfassen
Große Dokumente mit generativer KI zusammenfassen
Mit der im Architekturdiagramm rechts dargestellten Lösung wird eine Pipeline bereitgestellt, die ausgelöst wird, wenn Sie Ihrem Cloud Storage-Bucket ein neues PDF-Dokument hinzufügen. Die Pipeline extrahiert Text aus Ihrem Dokument, erstellt eine Zusammenfassung aus dem extrahierten Text und speichert die Zusammenfassung in einer Datenbank, damit Sie sie ansehen und durchsuchen können.
Sie können die Anwendung aufrufen, indem Sie Dateien entweder über ein Jupyter Notebook oder direkt in Cloud Storage in der Google Cloud Console hochladen.

Geschätzte Bereitstellungszeit: 11 Min. (1 Min. für die Konfiguration, 10 Min. für die Bereitstellung).
Anleitungen
Große Dokumente mit generativer KI zusammenfassen
Mit der im Architekturdiagramm rechts dargestellten Lösung wird eine Pipeline bereitgestellt, die ausgelöst wird, wenn Sie Ihrem Cloud Storage-Bucket ein neues PDF-Dokument hinzufügen. Die Pipeline extrahiert Text aus Ihrem Dokument, erstellt eine Zusammenfassung aus dem extrahierten Text und speichert die Zusammenfassung in einer Datenbank, damit Sie sie ansehen und durchsuchen können.
Sie können die Anwendung aufrufen, indem Sie Dateien entweder über ein Jupyter Notebook oder direkt in Cloud Storage in der Google Cloud Console hochladen.
Geschätzte Bereitstellungszeit: 11 Min. (1 Min. für die Konfiguration, 10 Min. für die Bereitstellung).
Bildverarbeitungspipeline erstellen
Skalierbare Bildverarbeitung in einer serverlosen Architektur
Die im Diagramm rechts dargestellte Lösung nutzt vortrainierte Modelle für maschinelles Lernen, um von Nutzern bereitgestellte Bilder zu analysieren und Bildanmerkungen zu generieren. Durch die Bereitstellung dieser Lösung wird ein Bildverarbeitungsdienst erstellt, der Sie dabei unterstützt, unsichere oder schädliche von Nutzern erstellte Inhalte zu verarbeiten, Text aus physischen Dokumenten zu digitalisieren, Objekte in Bildern zu erkennen und zu klassifizieren und vieles mehr.
Sie können sich die Konfigurations- und Sicherheitseinstellungen ansehen und nachvollziehen, wie Sie den Bildverarbeitungsdienst an verschiedene Anforderungen anpassen können.

Geschätzte Bereitstellungszeit: 12 Minuten (2 Minuten für die Konfiguration, 10 Minuten für die Bereitstellung).
Anleitungen
Skalierbare Bildverarbeitung in einer serverlosen Architektur
Die im Diagramm rechts dargestellte Lösung nutzt vortrainierte Modelle für maschinelles Lernen, um von Nutzern bereitgestellte Bilder zu analysieren und Bildanmerkungen zu generieren. Durch die Bereitstellung dieser Lösung wird ein Bildverarbeitungsdienst erstellt, der Sie dabei unterstützt, unsichere oder schädliche von Nutzern erstellte Inhalte zu verarbeiten, Text aus physischen Dokumenten zu digitalisieren, Objekte in Bildern zu erkennen und zu klassifizieren und vieles mehr.
Sie können sich die Konfigurations- und Sicherheitseinstellungen ansehen und nachvollziehen, wie Sie den Bildverarbeitungsdienst an verschiedene Anforderungen anpassen können.
Geschätzte Bereitstellungszeit: 12 Minuten (2 Minuten für die Konfiguration, 10 Minuten für die Bereitstellung).
Automatisierte Bildbeschreibungen mit generativer KI erhalten
Mit der Funktion Visuelle Untertitel von Imagen können Sie eine relevante Beschreibung für ein Bild generieren. Sie können sie verwenden, um detailliertere Metadaten zu Bildern zum Speichern und Suchen zu erhalten und automatische Untertitel zu erstellen, um Anwendungsfälle für Barrierefreiheit zu unterstützen und Kurzbeschreibungen von Produkten und visuellen Assets zu erhalten.
Die Funktion ist auf Deutsch, Englisch, Französisch, Italienisch und Spanisch verfügbar und kann über die Google Cloud Console oder über einen API-Aufruf aufgerufen werden.
Anleitungen
Mit der Funktion Visuelle Untertitel von Imagen können Sie eine relevante Beschreibung für ein Bild generieren. Sie können sie verwenden, um detailliertere Metadaten zu Bildern zum Speichern und Suchen zu erhalten und automatische Untertitel zu erstellen, um Anwendungsfälle für Barrierefreiheit zu unterstützen und Kurzbeschreibungen von Produkten und visuellen Assets zu erhalten.
Die Funktion ist auf Deutsch, Englisch, Französisch, Italienisch und Spanisch verfügbar und kann über die Google Cloud Console oder über einen API-Aufruf aufgerufen werden.
Streamverarbeitung von Videos
Mit Vertex AI Vision Informationen aus gestreamten Videos gewinnen
Bevor Sie die Videodaten mit Ihrer Anwendung analysieren, erstellen Sie eine Pipeline für den kontinuierlichen Datenfluss mit dem Streams-Dienst in Vertex AI Vision. Die aufgenommenen Daten werden dann von den vortrainierten Modellen von Google oder Ihrem benutzerdefinierten Modell analysiert. Die Analyseergebnisse der Streams werden dann im Vertex AI Vision Warehouse gespeichert. Dort können Sie mit erweiterten KI-gestützten Suchfunktionen unstrukturierte Medieninhalte abfragen.
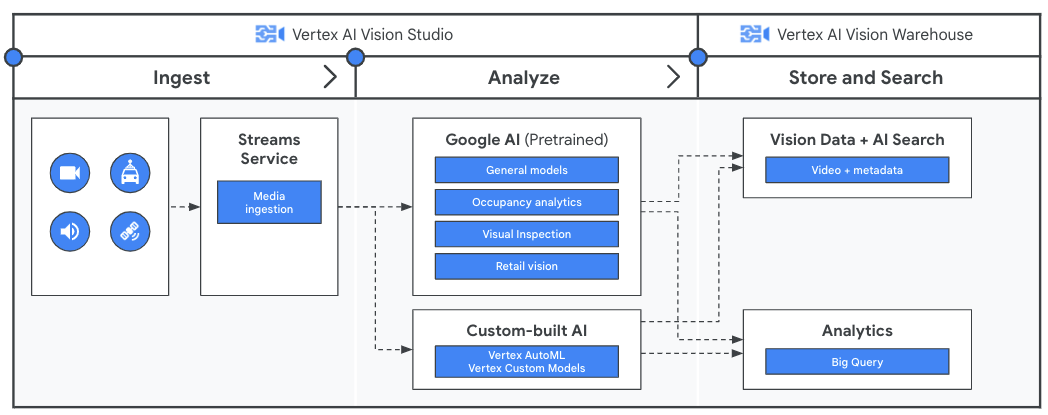
Anleitungen
Mit Vertex AI Vision Informationen aus gestreamten Videos gewinnen
Bevor Sie die Videodaten mit Ihrer Anwendung analysieren, erstellen Sie eine Pipeline für den kontinuierlichen Datenfluss mit dem Streams-Dienst in Vertex AI Vision. Die aufgenommenen Daten werden dann von den vortrainierten Modellen von Google oder Ihrem benutzerdefinierten Modell analysiert. Die Analyseergebnisse der Streams werden dann im Vertex AI Vision Warehouse gespeichert. Dort können Sie mit erweiterten KI-gestützten Suchfunktionen unstrukturierte Medieninhalte abfragen.
Mit generativer KI Text und Informationen aus Dokumenten extrahieren
Mit Document AI Erkenntnisse aus differenzierten Dokumenten gewinnen
Document AI Custom Extractor basiert auf einem grundlegenden Modell und extrahiert Text und Daten aus generischen und fachspezifischen Dokumenten schneller und mit höherer Genauigkeit. Mit nur 5–10 Dokumenten können Sie ganz einfach Anpassungen vornehmen – für noch bessere Leistung.
Wenn Sie ein eigenes Modell trainieren möchten, können Sie den Datasets mit dem Basismodell automatische Labels hinzufügen, um die Produktion zu beschleunigen.
Sie können auch vortrainierte spezialisierte Prozessoren verwenden. Hier finden Sie eine vollständige Liste der Prozessoren.
Anleitungen
Mit Document AI Erkenntnisse aus differenzierten Dokumenten gewinnen
Document AI Custom Extractor basiert auf einem grundlegenden Modell und extrahiert Text und Daten aus generischen und fachspezifischen Dokumenten schneller und mit höherer Genauigkeit. Mit nur 5–10 Dokumenten können Sie ganz einfach Anpassungen vornehmen – für noch bessere Leistung.
Wenn Sie ein eigenes Modell trainieren möchten, können Sie den Datasets mit dem Basismodell automatische Labels hinzufügen, um die Produktion zu beschleunigen.
Sie können auch vortrainierte spezialisierte Prozessoren verwenden. Hier finden Sie eine vollständige Liste der Prozessoren.
Präzise Sichtprüfung
Qualitätsprüfung mit Visual Inspection AI automatisieren
Visual Inspection AI wird bei jedem Schritt optimiert. Die Einrichtung ist einfach und der ROI lässt sich schnell erkennen. Mit bis zu 300-mal weniger beschrifteten Bildern zum Trainieren von Hochleistungsinspektionsmodellen als bei ML-Plattformen für allgemeine Zwecke liefert es nachweislich eine bis zu zehnmal höhere Genauigkeit. Sie können Modelle auch ohne technisches Fachwissen trainieren und sie werden lokal ausgeführt. Das Beste daran ist, dass die Modelle kontinuierlich mit Daten aus der Fabrik aktualisiert werden können, was die Genauigkeit erhöht, wenn Sie neue Anwendungsfälle entdecken.
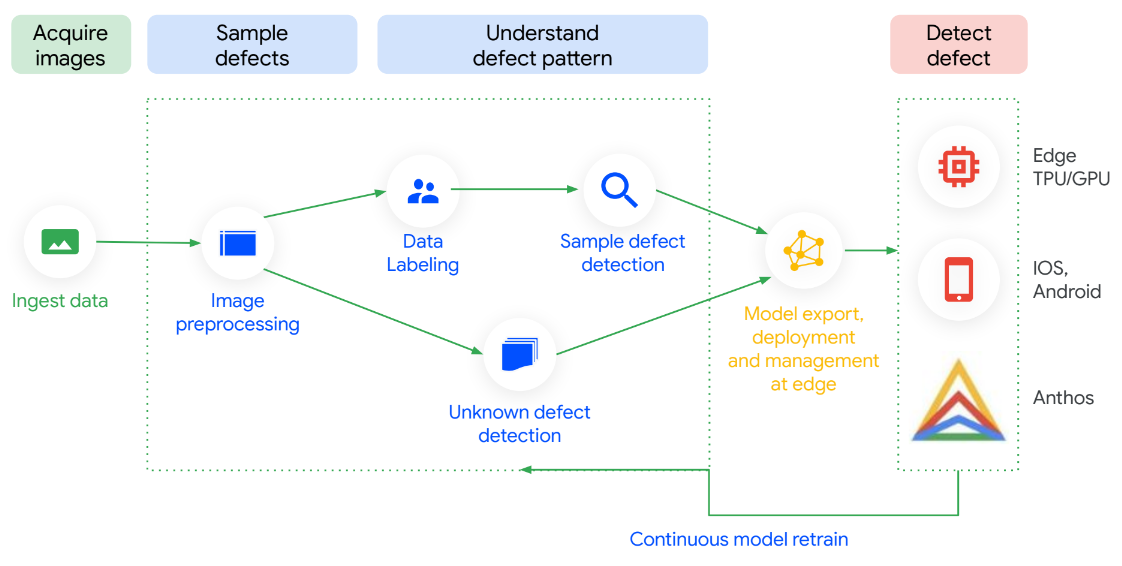
Anleitungen
Qualitätsprüfung mit Visual Inspection AI automatisieren
Visual Inspection AI wird bei jedem Schritt optimiert. Die Einrichtung ist einfach und der ROI lässt sich schnell erkennen. Mit bis zu 300-mal weniger beschrifteten Bildern zum Trainieren von Hochleistungsinspektionsmodellen als bei ML-Plattformen für allgemeine Zwecke liefert es nachweislich eine bis zu zehnmal höhere Genauigkeit. Sie können Modelle auch ohne technisches Fachwissen trainieren und sie werden lokal ausgeführt. Das Beste daran ist, dass die Modelle kontinuierlich mit Daten aus der Fabrik aktualisiert werden können, was die Genauigkeit erhöht, wenn Sie neue Anwendungsfälle entdecken.
Preise
| Preisgestaltung von Vision AI | Jedes Vision-Angebot umfasst eine Reihe von Features oder Prozessoren zu unterschiedlichen Preisen. Weitere Informationen finden Sie auf der Seite mit den detaillierten Preisen. | ||
|---|---|---|---|
| Kostenlose Stufe | Product/Service | Ermäßigte Preise | Details |
Vision API | Erste 1.000 Einheiten pro Monat kostenlos | > 5.000.001 Einheiten pro Monat | |
Document AI | – Die Preise richten sich nach dem Prozessor. | 5.000.001+ Seiten pro Monat für Enterprise Document OCR-Prozessor | |
Video Intelligence API | Die ersten 1.000 Minuten pro Monat sind kostenlos. | 100.000+ Minuten pro Monat | |
Vertex AI Vision | – Die Preise sind funktionsspezifisch. |
| |
Imagen – multimodale Einbettungen |
|
| 0,0001 $ pro Bildeingabe |
Imagen – visuelle Untertitel |
|
| 0,0015 $ pro Bild |
Gemini Pro Vision | |||
Preisgestaltung von Vision AI
Jedes Vision-Angebot umfasst eine Reihe von Features oder Prozessoren zu unterschiedlichen Preisen. Weitere Informationen finden Sie auf der Seite mit den detaillierten Preisen.
Vision API
Erste 1.000 Einheiten
pro Monat kostenlos
> 5.000.001 Einheiten
pro Monat
Document AI
–
Die Preise richten sich nach dem Prozessor.
5.000.001+ Seiten
pro Monat für Enterprise Document OCR-Prozessor
Die ersten 1.000 Minuten
pro Monat sind kostenlos.
100.000+ Minuten
pro Monat
Vertex AI Vision
–
Die Preise sind funktionsspezifisch.
Imagen – multimodale Einbettungen
0,0001 $
pro Bildeingabe
Imagen – visuelle Untertitel
0,0015 $
pro Bild











