Vision AI
Estrai insight da immagini, documenti e video
Accedi a modelli di visione artificiale avanzati tramite API per automatizzare le attività di visione, semplificare l'analisi e sbloccare insight strategici. Oppure crea app personalizzate con addestramento di modelli senza codice e a basso costo in un ambiente gestito.
I nuovi clienti ricevono fino a 300 $ di crediti gratuiti per provare Vision AI e altri prodotti Google Cloud.
Puoi anche provare a eseguire il deployment di soluzioni di riepilogo documenti ed elaborazione di immagini IA/ML consigliate da Google.
Panoramica
Che cos'è la visione artificiale?
La visione artificiale è un campo dell'intelligenza artificiale (IA) che consente a computer e sistemi di interpretare e analizzare dati visivi e ricavare informazioni significative da immagini digitali, video e altri input visivi. Alcune delle sue tipiche applicazioni nel mondo reale includono: rilevamento di oggetti, elaborazione di contenuti visivi (immagini, documenti, video), comprensione e analisi, ricerca di prodotti, classificazione e ricerca di immagini e moderazione dei contenuti.
AI generativa multimodale avanzata
Vertex AI di Google Cloud dà accesso a Gemini, una famiglia di modelli multimodali all'avanguardia in grado di comprendere praticamente qualsiasi input, combinare diversi tipi di informazioni e generare quasi ogni tipo di output.
IA generativa incentrata sulla visione artificiale
Imagen su Vertex AI offre agli sviluppatori di applicazioni le funzionalità di AI generativa all'avanguardia per le immagini di Google tramite un'API. Alcune delle sue funzionalità principali includono la generazione di immagini con prompt di testo, la modifica delle immagini con prompt di testo, la descrizione di un'immagine nel testo e l'ottimizzazione del modello del soggetto.
Vision AI pronta per l'uso
Basata sui modelli ML preaddestrati di Google per la visione artificiale, l'API Cloud Vision è un'API (REST e RPC) facilmente disponibile che consente agli sviluppatori di integrare facilmente funzionalità comuni di rilevamento visivo all'interno delle applicazioni, ad esempio: etichettatura di immagini, rilevamento di volti e punti di riferimento, riconoscimento ottico dei caratteri (OCR) e tagging dei contenuti espliciti.
Ogni funzionalità che applichi a un'immagine è un'unità fatturabile: l'API Cloud Vision ti consente di utilizzare senza costi 1000 unità delle sue funzionalità ogni mese. Visualizza dettagli dei prezzi.
IA generativa per la comprensione dei documenti
Document AI è una piattaforma per la comprensione di documenti che combina visione artificiale e altre tecnologie, come l'elaborazione del linguaggio naturale, per estrarre testo e dati da documenti scansionati, trasformando i dati non strutturati in informazioni strutturate e insight aziendali.
Offre un'ampia gamma di processori preaddestrati ottimizzati per diversi tipi di documenti. Inoltre, semplifica la creazione di processori personalizzati per classificare, suddividere ed estrarre dati strutturati dai documenti tramite Document AI Workbench.

Vision AI pronta all'uso per i video
L'API Video Intelligence, che è alla base della tecnologia di visione artificiale, è un modo semplice per elaborare, analizzare e comprendere i contenuti video.
I suoi modelli di ML preaddestrati riconoscono automaticamente un gran numero di oggetti, luoghi e azioni nei video archiviati e in streaming, con una qualità eccezionale. È estremamente efficace per i casi d'uso comuni come la moderazione e i consigli dei contenuti, gli archivi multimediali e le pubblicità contestuali. Puoi anche addestrare modelli ML personalizzati con Vertex AI Vision per le tue esigenze specifiche.

Visual Inspection AI
Visual Inspection AI automatizza le attività di ispezione visiva in ambito manifatturiero e in altri ambienti industriali. Sfrutta tecniche avanzate di visione artificiale e deep learning per analizzare immagini e video, identificare anomalie, rilevare e individuare i difetti e controllare le parti mancanti e con problemi nei prodotti assemblati.
Puoi addestrare modelli personalizzati senza competenza tecnica e ridurre al minimo le immagini etichettate, eseguire l'inferenza in modo efficiente sulle linee di produzione e aggiornare continuamente i modelli con dati aggiornati dallo stabilimento.

Piattaforma unificata di Vision AI
Vertex AI Vision è un ambiente di sviluppo di applicazioni completamente gestito che consente agli sviluppatori di creare, eseguire il deployment e gestire facilmente applicazioni di visione artificiale per elaborare una varietà di modalità di dati, come testo, immagini, video e dati tabulari. Riduce il tempo di creazione da giorni a minuti a un decimo del costo delle offerte attuali.
Puoi creare ed eseguire il deployment dei tuoi modelli personalizzati, nonché gestirli e scalarli con le pipeline CI/CD. Inoltre, si integra con i più diffusi strumenti open source come TensorFlow e PyTorch.

Dati, privacy e sicurezza
Google Cloud dispone di funzionalità leader del settore che offrono a te, ovvero ai nostri clienti, il controllo dei dati e la visibilità su quando e come viene effettuato l'accesso ai dati.
Come cliente Google Cloud, possiedi i dati dei clienti. Adottiamo rigorose misure di sicurezza per salvaguardare i dati dei clienti e ti offriamo strumenti e funzionalità per controllarli in base alle tue esigenze. I dati del cliente sono tuoi, non di Google. Trattiamo i tuoi dati solo in base a quanto stabilito dai contratti che hai sottoscritto.
Scopri di più nel nostro Centro risorse per la privacy.
Confronta i prodotti di visione artificiale
| Offerta | Ideale per | Funzionalità principali |
|---|---|---|
Integrazione facile e veloce delle funzionalità visive di base. | Funzionalità predefinite come etichettatura delle immagini, rilevamento di volti e punti di riferimento, OCR, ricerca sicura. Conveniente, pagamento in base al consumo. | |
Estrazione di insight da documenti e immagini scansionati, automatizzazione dei flussi di lavoro dei documenti. | OCR (basato sull'IA generativa), NLP, ML per la comprensione dei documenti, l'estrazione di testi, l'identificazione delle entità e la categorizzazione dei documenti. | |
Analisi dei contenuti video, della moderazione e dei consigli dei contenuti, degli archivi multimediali e degli annunci contestuali. | Rilevamento e tracciamento di oggetti, comprensione delle scene, riconoscimento delle attività, rilevamento e riconoscimento facciale, rilevamento e riconoscimento dei testi. | |
Automatizzare le attività di ispezione visiva in ambito manifatturiero e industriale | Rilevamento di anomalie, rilevamento e localizzazione dei difetti e controllo di assemblaggio. | |
Creazione e deployment di modelli personalizzati per esigenze specifiche. | Strumenti di preparazione dei dati, addestramento e deployment dei modelli, controllo completo sulla tua soluzione. Richiede competenze tecniche. | |
Ricevi descrizioni automatiche delle immagini. Classificazione e ricerca delle immagini. Consigli e moderazione dei contenuti. | Generazione di immagini, modifica delle immagini, didascalie visive e incorporamento multimodale. Consulta l'elenco completo delle funzionalità e delle relative fasi di lancio. |
Ottimizzati per scopi diversi, questi prodotti consentono di sfruttare modelli di ML preaddestrati e di iniziare subito a lavorare, con la possibilità di essere perfezionati facilmente.
Integrazione facile e veloce delle funzionalità visive di base.
Funzionalità predefinite come etichettatura delle immagini, rilevamento di volti e punti di riferimento, OCR, ricerca sicura.
Conveniente, pagamento in base al consumo.
Estrazione di insight da documenti e immagini scansionati, automatizzazione dei flussi di lavoro dei documenti.
OCR (basato sull'IA generativa), NLP, ML per la comprensione dei documenti, l'estrazione di testi, l'identificazione delle entità e la categorizzazione dei documenti.
Analisi dei contenuti video, della moderazione e dei consigli dei contenuti, degli archivi multimediali e degli annunci contestuali.
Rilevamento e tracciamento di oggetti, comprensione delle scene, riconoscimento delle attività, rilevamento e riconoscimento facciale, rilevamento e riconoscimento dei testi.
Automatizzare le attività di ispezione visiva in ambito manifatturiero e industriale
Rilevamento di anomalie, rilevamento e localizzazione dei difetti e controllo di assemblaggio.
Creazione e deployment di modelli personalizzati per esigenze specifiche.
Strumenti di preparazione dei dati, addestramento e deployment dei modelli, controllo completo sulla tua soluzione. Richiede competenze tecniche.
Ricevi descrizioni automatiche delle immagini.
Classificazione e ricerca delle immagini.
Consigli e moderazione dei contenuti.
Generazione di immagini, modifica delle immagini, didascalie visive e incorporamento multimodale.
Consulta l'elenco completo delle funzionalità e delle relative fasi di lancio.
Ottimizzati per scopi diversi, questi prodotti consentono di sfruttare modelli di ML preaddestrati e di iniziare subito a lavorare, con la possibilità di essere perfezionati facilmente.
Come funziona
La suite di strumenti Vision AI di Google Cloud combina la visione artificiale con altre tecnologie per comprendere e analizzare i video e integrare facilmente funzionalità di rilevamento visivo nelle applicazioni, tra cui etichettatura delle immagini, rilevamento di volti e punti di riferimento, riconoscimento ottico dei caratteri (OCR) e tagging dei contenuti espliciti.
Questi strumenti sono disponibili tramite API, ma rimangono personalizzabili per esigenze specifiche.
La suite di strumenti Vision AI di Google Cloud combina la visione artificiale con altre tecnologie per comprendere e analizzare i video e integrare facilmente funzionalità di rilevamento visivo nelle applicazioni, tra cui etichettatura delle immagini, rilevamento di volti e punti di riferimento, riconoscimento ottico dei caratteri (OCR) e tagging dei contenuti espliciti.
Questi strumenti sono disponibili tramite API, ma rimangono personalizzabili per esigenze specifiche.

Demo
Scopri come funziona la visione artificiale con i tuoi file
Utilizzi comuni
Rileva il testo nei file non elaborati e riassumi automaticamente
Riassumi documenti di grandi dimensioni con l'IA generativa
La soluzione raffigurata nel diagramma dell'architettura a destra esegue il deployment di una pipeline che viene attivata quando aggiungi un nuovo documento PDF al tuo bucket Cloud Storage. La pipeline estrae il testo dal documento, crea un riepilogo dal testo estratto e lo archivia in un database che puoi visualizzare e cercare.
Puoi richiamare l'applicazione caricando file tramite un blocco note Jupyter o direttamente in Cloud Storage nella console Google Cloud.

Tempo stimato per il deployment: 11 minuti (1 min per la configurazione, 10 min per il deployment).
Procedure
Riassumi documenti di grandi dimensioni con l'IA generativa
La soluzione raffigurata nel diagramma dell'architettura a destra esegue il deployment di una pipeline che viene attivata quando aggiungi un nuovo documento PDF al tuo bucket Cloud Storage. La pipeline estrae il testo dal documento, crea un riepilogo dal testo estratto e lo archivia in un database che puoi visualizzare e cercare.
Puoi richiamare l'applicazione caricando file tramite un blocco note Jupyter o direttamente in Cloud Storage nella console Google Cloud.
Tempo stimato per il deployment: 11 minuti (1 min per la configurazione, 10 min per il deployment).
Crea una pipeline di elaborazione delle immagini
Elaborazione delle immagini scalabile su un'architettura serverless
La soluzione, rappresentata nel diagramma a destra, utilizza modelli di machine learning preaddestrati per analizzare le immagini fornite dagli utenti e generare annotazioni delle immagini. L'implementazione di questa soluzione crea un servizio di elaborazione delle immagini che può aiutarti a gestire contenuti generati dagli utenti non sicuri o dannosi, digitalizzare il testo dei documenti fisici, rilevare e classificare oggetti nelle immagini e altro ancora.
Sarai in grado di rivedere le impostazioni di configurazione e sicurezza per capire come adattare il servizio di elaborazione delle immagini alle diverse esigenze.

Tutorial: crea una pipeline di analisi visiva per elaborare una grande quantità di immagini
Documentazione completa: Elaborazione di immagini IA/ML su Cloud Functions
Guida passo passo completa: Esegui il deployment della pipeline di elaborazione delle immagini utilizzando l'interfaccia a riga di comando di Terraform +
Tempo stimato per il deployment: 12 minuti (2 minuti per la configurazione, 10 minuti per il deployment).
Procedure
Elaborazione delle immagini scalabile su un'architettura serverless
La soluzione, rappresentata nel diagramma a destra, utilizza modelli di machine learning preaddestrati per analizzare le immagini fornite dagli utenti e generare annotazioni delle immagini. L'implementazione di questa soluzione crea un servizio di elaborazione delle immagini che può aiutarti a gestire contenuti generati dagli utenti non sicuri o dannosi, digitalizzare il testo dei documenti fisici, rilevare e classificare oggetti nelle immagini e altro ancora.
Sarai in grado di rivedere le impostazioni di configurazione e sicurezza per capire come adattare il servizio di elaborazione delle immagini alle diverse esigenze.
Tutorial: crea una pipeline di analisi visiva per elaborare una grande quantità di immagini
Documentazione completa: Elaborazione di immagini IA/ML su Cloud Functions
Guida passo passo completa: Esegui il deployment della pipeline di elaborazione delle immagini utilizzando l'interfaccia a riga di comando di Terraform +
Tempo stimato per il deployment: 12 minuti (2 minuti per la configurazione, 10 minuti per il deployment).
Ottieni descrizioni automatiche delle immagini con l'IA generativa
La funzionalità Didascalia visiva di Imagen ti consente di generare una descrizione pertinente per un'immagine. Puoi utilizzarla per ottenere metadati più dettagliati sulle immagini da archiviare e cercare, per generare sottotitoli automatici. per supportare casi d'uso di accessibilità e ricevere descrizioni rapide di prodotti e risorse visive.
Disponibile in inglese, francese, tedesco, italiano e spagnolo, è possibile accedere a questa funzionalità nella console Google Cloud o tramite una chiamata API.
Procedure
La funzionalità Didascalia visiva di Imagen ti consente di generare una descrizione pertinente per un'immagine. Puoi utilizzarla per ottenere metadati più dettagliati sulle immagini da archiviare e cercare, per generare sottotitoli automatici. per supportare casi d'uso di accessibilità e ricevere descrizioni rapide di prodotti e risorse visive.
Disponibile in inglese, francese, tedesco, italiano e spagnolo, è possibile accedere a questa funzionalità nella console Google Cloud o tramite una chiamata API.
Video per l'elaborazione dei flussi
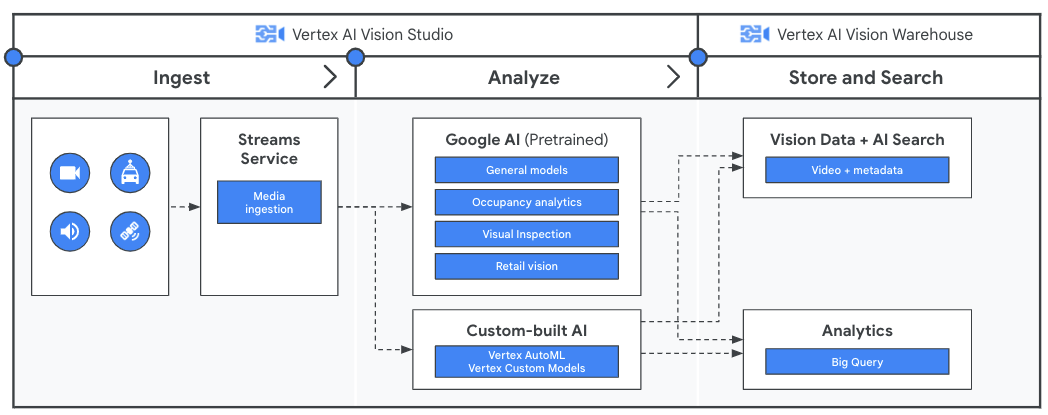
Ottieni insight dai video in streaming con Vertex AI Vision
Prima di analizzare i dati video con la tua applicazione, crea una pipeline per il flusso continuo di dati con il servizio Streams in Vertex AI Vision. I dati importati vengono poi analizzati dai modelli preaddestrati di Google o dal tuo modello personalizzato. L'output dell'analisi dai flussi viene quindi archiviato in Vertex AI Vision Warehouse, dove puoi utilizzare funzionalità di ricerca avanzate basate sull'IA per eseguire query su contenuti multimediali non strutturati.
Procedure
Ottieni insight dai video in streaming con Vertex AI Vision
Prima di analizzare i dati video con la tua applicazione, crea una pipeline per il flusso continuo di dati con il servizio Streams in Vertex AI Vision. I dati importati vengono poi analizzati dai modelli preaddestrati di Google o dal tuo modello personalizzato. L'output dell'analisi dai flussi viene quindi archiviato in Vertex AI Vision Warehouse, dove puoi utilizzare funzionalità di ricerca avanzate basate sull'IA per eseguire query su contenuti multimediali non strutturati.
Estrai testo e insight dai documenti con l'IA generativa
Estrai insight da documenti articolati con Document AI
Basato su un modello di base, Document AI Custom Extractor estrae testo e dati dai documenti, generici e specifici per il dominio, più velocemente e con maggiore accuratezza. Facile ottimizzazione con soli 5-10 documenti per prestazioni ancora migliori.
Se vuoi addestrare un modello personalizzato, etichetta automaticamente i set di dati con il modello di base per velocizzare i tempi di produzione.
Oppure puoi scegliere di utilizzare processori specializzati preaddestrati: consulta l'elenco completo dei processori.
Procedure
Estrai insight da documenti articolati con Document AI
Basato su un modello di base, Document AI Custom Extractor estrae testo e dati dai documenti, generici e specifici per il dominio, più velocemente e con maggiore accuratezza. Facile ottimizzazione con soli 5-10 documenti per prestazioni ancora migliori.
Se vuoi addestrare un modello personalizzato, etichetta automaticamente i set di dati con il modello di base per velocizzare i tempi di produzione.
Oppure puoi scegliere di utilizzare processori specializzati preaddestrati: consulta l'elenco completo dei processori.
Ispezione visiva ad alta precisione
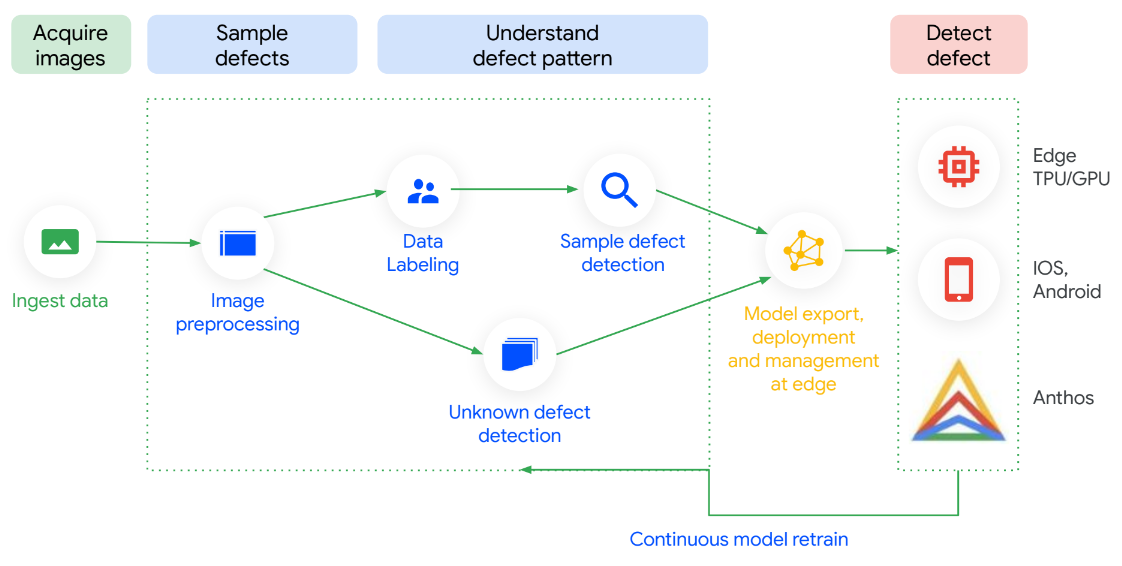
Automatizza l'ispezione della qualità con Visual Inspection AI
Visual Inspection AI è ottimizzata in ogni passaggio, quindi è facile da configurare e consente di calcolare rapidamente il ROI. Con un numero di immagini etichettate fino a 300 volte inferiore per iniziare ad addestrare modelli di ispezione ad alte prestazioni rispetto alle piattaforme ML per uso generico, ha dimostrato di offrire una precisione fino a 10 volte superiore. Puoi addestrare modelli senza competenze tecniche e vengono eseguiti on-premise. Inoltre, i modelli possono essere aggiornati continuamente con i dati che provengono dallo stabilimento di produzione, offrendoti una maggiore precisione man mano che scopri nuovi casi d'uso.
Procedure
Automatizza l'ispezione della qualità con Visual Inspection AI
Visual Inspection AI è ottimizzata in ogni passaggio, quindi è facile da configurare e consente di calcolare rapidamente il ROI. Con un numero di immagini etichettate fino a 300 volte inferiore per iniziare ad addestrare modelli di ispezione ad alte prestazioni rispetto alle piattaforme ML per uso generico, ha dimostrato di offrire una precisione fino a 10 volte superiore. Puoi addestrare modelli senza competenze tecniche e vengono eseguiti on-premise. Inoltre, i modelli possono essere aggiornati continuamente con i dati che provengono dallo stabilimento di produzione, offrendoti una maggiore precisione man mano che scopri nuovi casi d'uso.
Prezzi
| Come funzionano i prezzi di Vision AI | Ogni offerta di visione artificiale ha un insieme di funzionalità o processori, con prezzi diversi. Per i dettagli, consulta le pagine dei prezzi dettagliate. | ||
|---|---|---|---|
| Livello gratuito | Prodotto/servizio | Prezzo scontato | Dettagli |
API Vision | Prime 1000 unità sono gratuite ogni mese | Oltre 5.000.001 unità al mese | |
Document AI | N/A I prezzi sono basati sul processore. | 5.000.001+ pagine al mese per il processore Enterprise Document OCR | |
API Video Intelligence | Primi 1000 minuti al mese sono gratuiti | 100.000+ minuti al mese | |
Vertex AI Vision | N/A I prezzi sono influenzati dalle funzionalità. |
| |
Imagen: incorporamenti multimodali |
|
| US $0,0001 per input di immagine |
Imagen: didascalia visiva |
|
| US $0,0015 per immagine |
Gemini Pro Vision | |||
Come funzionano i prezzi di Vision AI
Ogni offerta di visione artificiale ha un insieme di funzionalità o processori, con prezzi diversi. Per i dettagli, consulta le pagine dei prezzi dettagliate.
API Vision
Prime 1000 unità
sono gratuite ogni mese
Oltre 5.000.001 unità
al mese
Document AI
N/A
I prezzi sono basati sul processore.
5.000.001+ pagine
al mese per il processore Enterprise Document OCR
Primi 1000 minuti
al mese sono gratuiti
100.000+ minuti
al mese
Vertex AI Vision
N/A
I prezzi sono influenzati dalle funzionalità.
Imagen: incorporamenti multimodali
US $0,0001
per input di immagine
Imagen: didascalia visiva
US $0,0015
per immagine











