このページでは、Cloud Trace を使用したトレースデータのエクスポートのコンセプトについて概要を説明します。トレースデータをエクスポートする理由は次のとおりです。
- デフォルト保持期間の 30 日より長い期間のトレースデータを保存する場合。
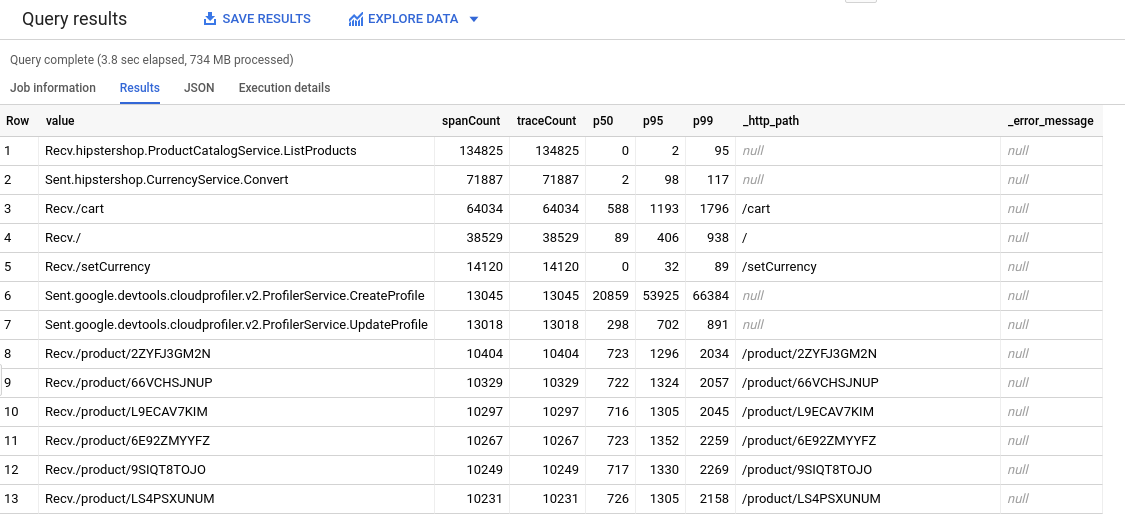
BigQuery ツールを使用してトレースデータを分析できるようにする場合。たとえば、BigQuery を使用すると、スパン数と変位値を識別できます。次の表を生成するために使用されるクエリについては、HipsterShop クエリをご覧ください。
エクスポートの仕組み
エクスポートには、 Google Cloud プロジェクトのシンクを作成する必要があります。シンクにより、宛先としての BigQuery データセットが定義されます。
シンクは、Cloud Trace API か Google Cloud CLI を使用して作成できます。
シンクのプロパティと用語
シンクは Google Cloud プロジェクトに対して定義され、次のプロパティがあります。
名前: シンクの名前。たとえば、名前は次のようになります。
"projects/PROJECT_NUMBER/traceSinks/my-sink"
ここで、
PROJECT_NUMBERはシンクの Google Cloud プロジェクト番号、my-sinkはシンク ID です。Parent: シンクを作成するリソース。親は Google Cloud プロジェクトである必要があります。
"projects/PROJECT_ID"
PROJECT_IDは、 Google Cloud プロジェクト ID または番号です。Destination: トレーススパンを送信する 1 つの場所。Trace は、BigQuery へのトレースのエクスポートをサポートしています。宛先は、シンクの Google Cloud プロジェクト、または同じ組織内にある他の Google Cloud プロジェクトです。
たとえば、有効な Destination は次のようになります。
bigquery.googleapis.com/projects/DESTINATION_PROJECT_NUMBER/datasets/DATASET_ID
ここで、
DESTINATION_PROJECT_NUMBERは宛先のGoogle Cloud プロジェクト番号、DATASET_IDは BigQuery のデータセット識別子です。Writer ID: サービス アカウント名。エクスポート先のオーナーは、このサービス アカウントにエクスポート先への書き込み権限を付与する必要があります。トレースをエクスポートするとき、Trace はこの ID を承認に使用します。セキュリティを高めるために、新しいシンクは一意のサービス アカウントを取得します。
export-PROJECT_NUMBER-GENERATED_VALUE@gcp-sa-cloud-trace.iam.gserviceaccount.com
ここで、
PROJECT_NUMBERは Google Cloud プロジェクト番号(16 進数)で、GENERATED_VALUEはランダムに生成された値です。シンクの書き込み ID で識別されるサービス アカウントの作成、所有、管理は行いません。シンクを作成すると、Trace はシンクに必要なサービス アカウントを作成します。このサービス アカウントは、少なくとも 1 つの Identity and Access Management バインディングが付与されるまで、プロジェクトのサービス アカウントのリストに含まれません。このバインディングは、シンクの宛先を構成するときに追加します。
Writer ID の使用方法については、エクスポート先の権限をご覧ください。
シンクの仕組み
トレーススパンがプロジェクトに到達するたびに、Trace はスパンのコピーをエクスポートします。
シンクが作成される前に Trace が受信したトレースはエクスポートできません。
アクセス制御
シンクを作成または変更するには、次のいずれかの Identity and Access Management ロールが必要です。
- Trace 管理者
- Trace ユーザー
- プロジェクト所有者
- プロジェクト編集者
詳細については、アクセス制御をご覧ください。
トレースを宛先にエクスポートするには、シンクのライター サービス アカウントが宛先への書き込みを許可されている必要があります。ライター ID の詳細については、このページのシンク プロパティをご覧ください。
割り当てと上限
Cloud Trace は、BigQuery ストリーミング API を使用して、宛先にトレーススパンを送信します。Cloud Trace は API 呼び出しをバッチ処理します。Cloud Trace は、再試行またはスロットリングのメカニズムを実装しません。データの量が宛先の割り当てを超える場合、トレーススパンが正常にエクスポートされないことがあります。
BigQuery の割り当てと上限について詳しくは、割り当てと上限をご覧ください。
料金
トレースをエクスポートしても、Cloud Trace の料金はかかりません。ただし、BigQuery の料金がかかることがあります。詳細については、BigQuery の料金をご覧ください。
費用の見積もり
BigQuery では、データの取り込みとストレージに対して料金がかかります。BigQuery の毎月の費用を見積もるには、次のようにします。
1 か月に取り込まれるトレーススパンの合計数を見積もります。
使用状況を確認する方法については、請求先アカウント別の使用状況を表示するをご覧ください。
取り込まれたトレーススパンの数に基づいてストリーミングの要件を見積もります。
各スパンはテーブル行に書き込まれます。BigQuery の各行には 1,024 バイト以上が必要です。したがって、BigQuery ストリーミングの要件の下限は、各スパンに 1, 024 バイトを割り当てることです。たとえば、 Google Cloudプロジェクトに 200 のスパンが取り込まれている場合、それらのスパンにはストリーミング挿入に少なくとも 20,400 バイトが必要になります。
料金計算ツールを使うと、ストレージ、ストリーミング挿入、クエリによる BigQuery の費用を見積もることができます。
BigQuery の使用状況の表示と管理
Metrics Explorer を使用して、BigQuery の使用状況を表示できます。BigQuery の使用量が事前定義された上限を超えた場合に通知するアラート ポリシーを作成することもできます。次の表に、アラート ポリシーを作成する場合の設定を示します。グラフを作成するときや、Metrics Explorer を使用するときは、ターゲット ペイン表の設定を使用できます。
取り込まれた BigQuery 指標がユーザー定義レベルを超えた場合にトリガーされるアラート ポリシーを作成するには、次の設定を使用します。
| [New condition] フィールド |
値 |
|---|---|
| リソースと指標 | [リソース] メニューで [BigQuery データセット] を選択します。 [指標カテゴリ] メニューで、[ストレージ] を選択します。 [指標] メニューから指標を選択します。 Stored bytes、Uploaded bytes、Uploaded bytes billed など、使用に固有の指標。利用可能な指標の完全なリストについては、BigQuery 指標をご覧ください。 |
| フィルタ | project_id: 実際の Google Cloud プロジェクト ID。 dataset_id: データセット ID。 |
| 時系列全体 時系列のグループ化の基準 |
dataset_id: データセット ID。 |
| 時系列全体 時系列集計 |
sum |
| ローリング ウィンドウ | 1 m |
| ローリング ウィンドウ関数 | mean |
| [アラート トリガーの構成] フィールド |
値 |
|---|---|
| 条件タイプ | Threshold |
| Alert trigger | Any time series violates |
| しきい値の位置 | Above threshold |
| しきい値 | 許容値を決定します。 |
| 再テスト ウィンドウ | 1 minute |
次のステップ
シンクを構成するには、トレースのエクスポートをご覧ください。