Cloud TPU VM のモニタリング
このガイドでは、Google Cloud Monitoring を使用して Cloud TPU VM をモニタリングする方法について説明します。 Google Cloud Monitoring は、Cloud TPU とそのホストの Compute Engine から指標とログを自動的に収集します。これらのデータを使用して、Cloud TPU と Compute Engine の状態をモニタリングできます。
指標を使用すると、CPU 使用率、ネットワーク使用量、TensorCore のアイドル期間など、時間の経過に伴う数値を追跡できます。ログは特定の時点でのイベントをキャプチャします。ログエントリは、独自のコード、 Google Cloudサービス、サードパーティ アプリケーション、 Google Cloud インフラストラクチャによって作成されます。ログベースの指標を作成して、ログエントリに存在するデータから指標を生成することもできます。指標値またはログエントリに基づいてアラート ポリシーを設定することもできます。
このガイドでは、 Google Cloud Monitoring と次の方法について説明します。
- Cloud TPU の指標を表示する
- Cloud TPU の指標アラート ポリシーを設定する
- Cloud TPU ログのクエリを実行する
- ログに基づく指標を作成し、アラートを設定してダッシュボードを可視化する
TPU をモニタリングするには、キャパシティ プランナー(プレビュー)も使用できます。キャパシティ プランナーを使用すると、プロジェクト、フォルダ、組織の TPU の使用状況と予測データを表示できます。このデータは 24 時間ごとに更新され、使用状況の傾向を分析して、今後の容量ニーズを計画するために使用できます。詳細については、キャパシティ プランナーの概要をご覧ください。
このドキュメントは、Google CloudMonitoring に関する基本的な知識があることを前提としています。 Google Cloud Monitoring の操作を開始する前に、Compute Engine VM リソースと Cloud TPU リソースを作成する必要があります。詳細については、Cloud TPU のクイックスタートをご覧ください。
指標
Google Cloud 指標は、Compute Engine VM と Cloud TPU ランタイムによって自動的に生成されます。次の指標は Cloud TPU VM によって生成されます。
memory/usagenetwork/received_bytes_countnetwork/sent_bytes_countcpu/utilizationtpu/tensorcore/idle_durationaccelerator/tensorcore_utilizationaccelerator/memory_bandwidth_utilizationaccelerator/duty_cycleaccelerator/memory_totalaccelerator/memory_used
指標値が生成されて Metrics Explorer に表示されるまでに、最大で 180 秒かかることがあります。
Cloud TPU によって生成される指標の完全なリストについては、Google Cloud Cloud TPU の指標をご覧ください。
メモリ使用量
memory/usage 指標は TPU Worker リソースに対して生成され、TPU VM で使用されるメモリを追跡します(バイト単位)。この指標は 60 秒ごとにサンプリングされます。
ネットワークで受信したバイト数
network/received_bytes_count 指標は TPU Worker リソースに対して生成され、TPU VM がネットワーク経由で特定の時点で受信したデータの累積バイト数を追跡します。
ネットワークで送信されたバイト数
network/sent_bytes_count 指標は TPU Worker リソースに対して生成され、TPU VM がネットワーク経由で特定の時点で送信した累積バイト数を追跡します。
CPU 使用率
cpu/utilization 指標は TPU Worker リソースに対して生成され、TPU ワーカーの現在の CPU 使用率を追跡します。これは、1 分ごとにサンプリングされ、割合で表されます。値は通常、0.0~100.0 ですが、100.0 を超える場合もあります。
TensorCore のアイドル期間
tpu/tensorcore/idle_duration 指標は TPU Worker リソースに対して生成され、各 TPU チップの TensorCore がアイドル状態だった秒数を追跡します。この指標は、使用しているすべての TPU の各チップで利用できます。TensorCore が使用されると、アイドル状態の期間の値はゼロにリセットされます。TensorCore が使用されなくなった場合、アイドル状態の期間の値が増え始めます。
次のグラフは、1 つのワーカーを持つ v2-8 TPU VM の tpu/tensorcore/idle_duration 指標を示しています。各ワーカーには 4 つのチップがあります。この例では、4 つのチップすべてで tpu/tensorcore/idle_duration に同じ値があるため、グラフが重なり合って表示されます。
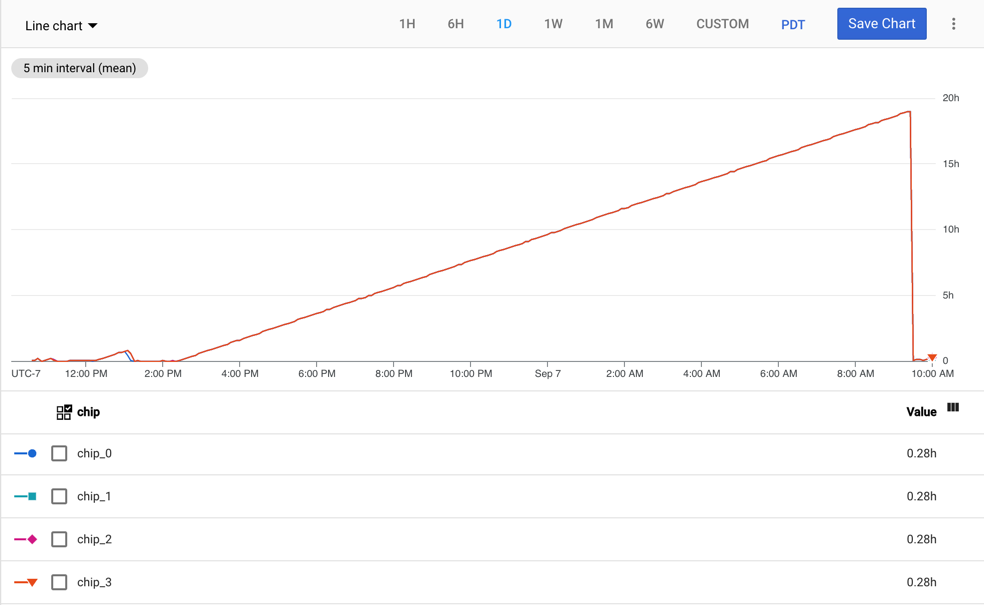
TensorCore の使用率
accelerator/tensorcore_utilization 指標は GCE TPU
Worker リソースに対して生成され、使用されている TensorCore の現在の割合を追跡します。この指標は、サンプル期間に実行された TensorCore オペレーションの数を、同じサンプル期間に実行できるオペレーションの最大数で割って計算されます。値が大きいほど、使用率が高いことを表します。TensorCore 使用率の指標は、v4 以降の TPU 世代でサポートされています。
メモリ帯域幅の使用率
accelerator/memory_bandwidth_utilization 指標は GCE TPU Worker リソースに対して生成され、使用されているアクセラレータ メモリ帯域幅の現在の割合を追跡します。この指標は、サンプル期間で使用されたメモリ帯域幅を、同じサンプル期間でサポートされる最大帯域幅で割って計算されます。値が大きいほど、使用率が高いことを表します。メモリ帯域幅使用率の指標は、v4 以降の TPU 世代でサポートされています。
アクセラレータのデューティ サイクル
accelerator/duty_cycle 指標は GCE TPU Worker リソースに対して生成され、サンプル期間中にアクセラレータ TensorCore がアクティブに処理していた時間の割合を追跡します。値の範囲は 0~100 です。値が大きいほど、TensorCore の使用率が高いことを表します。この指標は、ML ワークロードが TPU VM で実行されているときに報告されます。アクセラレータ デューティ サイクル指標は、JAX 0.4.14 以降、PyTorch 2.1 以降、TensorFlow 2.14.0 以降でサポートされています。
アクセラレータの合計メモリ量
accelerator/memory_total 指標は GCE TPU Worker リソースに対して生成され、割り当てられたアクセラレータの合計メモリ量(バイト単位)を追跡します。この指標は、ML ワークロードが TPU VM で実行されているときに報告されます。アクセラレータの合計メモリ量指標は、JAX 0.4.14 以降、PyTorch 2.1 以降、TensorFlow 2.14.0 以降でサポートされています。
アクセラレータのメモリ使用量
accelerator/memory_used 指標は GCE TPU Worker リソースに対して生成され、使用されたアクセラレータの合計メモリ量(バイト単位)を追跡します。この指標は、ML ワークロードが TPU VM で実行されているときに報告されます。アクセラレータのメモリ使用量指標は、JAX 0.4.14 以降、PyTorch 2.1 以降、TensorFlow 2.14.0 以降でサポートされています。
指標の表示
指標は、 Google Cloud コンソールの Metrics Explorer を使用して表示できます。
Metrics Explorer で [指標を選択] をクリックし、関心のある指標に応じて TPU Worker または GCE TPU Worker を検索します。リソースを選択すると、そのリソースで使用可能なすべての指標が表示されます。[アクティブ] が有効になっている場合は、過去 25 時間の時系列データを持つ指標のみが表示されます。[アクティブ] を無効にして、すべての指標を一覧表示します。
アラートの作成
条件が満たされたときにアラートを送信するように Cloud Monitoring に指示するアラート ポリシーを作成できます。
このセクションの手順は、TensorCore のアイドル期間指標のアラート ポリシーを追加する方法の例を示しています。この指標が 24 時間を超えると、Cloud Monitoring は登録されたメールアドレスにメールを送信します。
- コンソールの Monitoring に移動します。
- ナビゲーション パネルで [アラート] をクリックします。
- [Edit notification channels] をクリックします。
- [メール] で [新規追加] をクリックします。メールアドレスと表示名を入力し、[保存] をクリックします。
- [アラート] ページで、[ポリシーを作成] をクリックします。
- [指標を選択] をクリックして、[Tensorcore Idle Duration] を選択し、[適用] をクリックします。
- [次へ]、[しきい値] の順にクリックします。
- [Alert trigger] で [任意の時系列の違反] を選択します。
- [しきい値の位置] で [しきい値より上] を選択します。
- [しきい値] に「
86400000」と入力します。 - [次へ] をクリックします。
- [通知チャンネル] でメール通知チャンネルを選択し、[OK] をクリックします。
- アラート ポリシーの名前を入力します。
- [次へ]、[ポリシーを作成] の順にクリックします。
TensorCore のアイドル時間が 24 時間を超えると、指定したメールアドレスにメールが送信されます。
ロギング
ログエントリは、 Google Cloud サービス、サードパーティ サービス、ML フレームワーク、またはコードによって書き込まれます。ログ エクスプローラまたは Logs API を使用してログを表示できます。 Google Cloud ロギングの詳細については、Google Cloud Logging をご覧ください。
TPU ワーカーのログには、Cloud TPU ワーカーで使用可能なメモリ量(system_available_memory_GiB)など、特定のゾーンの特定の Cloud TPU ワーカーに関する情報が含まれます。
監査対象リソースログには、特定の Cloud TPU API の呼び出し日時と呼び出しを行ったユーザーに関する情報が記録されます。たとえば、CreateNode、UpdateNode、DeleteNode API の呼び出しに関する情報を確認できます。
ML フレームワークは、標準出力と標準エラーにログを生成できます。これらのログは環境変数で制御され、トレーニング スクリプトによって読み取られます。
コードでログを Google Cloud Logging に書き込むことができます。詳細については、標準ログを書き込むと構造化ログを書き込むをご覧ください。
シリアルポートのロギング
Cloud TPU は、トラブルシューティング、モニタリング、デバッグにシリアルポート ロギングを使用します。デフォルトでは、シリアルポート ロギングは有効になっています。シリアルポート ロギングが有効になっていない場合、TPU VM の作成プロセスが失敗し、次のエラー メッセージが生成されます。
"Cloud TPU received a bad request. Constraint
`constraints/compute.disableSerialPortLogging` violated. Create TPUs with
serial port logging enabled or remove the Organization Policy Constraint."
このメッセージは、制約 constraints/compute.disableSerialPortLogging が違反されたことを示します。このエラーを防ぐには、TPU プロジェクトでシリアルポート ロギングが許可されていることを確認する必要があります。ベスト プラクティスは、プロジェクト レベルで組織のポリシーをオーバーライドすることです。
シリアルポート ロギングの有効化の詳細については、シリアルポート出力のロギングを有効または無効にするをご覧ください。
Google Cloud ログをクエリする
Google Cloud コンソールでログを表示すると、そのページでデフォルトのクエリが実行されます。クエリを表示するには、Show query 切り替えスイッチを選択します。デフォルト クエリを変更することも、新しいクエリを作成することもできます。詳細については、ログ エクスプローラでクエリを作成するをご覧ください。
監査対象リソースログ
監査対象リソースログを表示するには:
- Google Cloud ログ エクスプローラに移動します。
- [すべてのリソース] プルダウンをクリックします。
- [監査対象リソース]、[Cloud TPU] の順にクリックします。
- 関心のある Cloud TPU API を選択します。
- [適用] をクリックします。ログはクエリ結果に表示されます。
任意のログエントリをクリックして開きます。各ログエントリには、次のような複数のフィールドがあります。
- logName: ログの名前
- protoPayload -> @type: ログの種類
- protoPayload -> resourceName: Cloud TPU の名前
- protoPayload -> methodName: 呼び出されたメソッドの名前(監査ログのみ)
- protoPayload -> request -> @type: リクエストのタイプ
- protoPayload -> request -> node: Cloud TPU ノードの詳細
- protoPayload -> request -> node_id: TPU の名前
- severity: ログの重大度
TPU ワーカーログ
TPU ワーカーのログを表示するには:
- Google Cloud ログ エクスプローラに移動します。
- [すべてのリソース] プルダウンをクリックします。
- [TPU ワーカー] をクリックします。
- ゾーンを選択します。
- 目的の Cloud TPU を選択します。
- [適用] をクリックします。ログはクエリ結果に表示されます。
任意のログエントリをクリックして開きます。各ログエントリには jsonPayload というフィールドがあります。jsonPayload を開くと、次のような複数のフィールドが表示されます。
- accelerator_type: アクセラレータ タイプ
- consumer_project: Cloud TPU が存在するプロジェクト
- evententry_timestamp: ログが生成された時刻
- system_available_memory_GiB: Cloud TPU ワーカーの使用可能なメモリ(0~350 GiB)
ログベースの指標を作成する
このセクションでは、モニタリング ダッシュボードとアラートの設定に使用するログベースの指標の作成方法について説明します。プログラムでログベースの指標を作成する方法については、Cloud Logging REST API を使用してプログラムでログベースの指標を作成するをご覧ください。
次の例では、system_available_memory_GiB サブフィールドを使用して、Cloud TPU ワーカーで利用できるメモリをモニタリングするためのログベースの指標を作成する方法を示します。
- Google Cloud ログ エクスプローラに移動します。
クエリボックスに次のクエリを入力して、プライマリ Cloud TPU ワーカーで system_available_memory_GiB が定義されているすべてのログエントリを抽出します。
resource.type=tpu_worker resource.labels.project_id=your-project resource.labels.zone=your-tpu-zone resource.labels.node_id=your-tpu-name resource.labels.worker_id=0 logName=projects/your-project/logs/tpu.googleapis.com%2Fruntime_monitor jsonPayload.system_available_memory_GiB:*
[指標を作成] をクリックして、Metric Editor を表示します。
[指標タイプ] で [分布] を選択します。
指標の名前、説明(省略可)、測定単位を入力します。この例では、[名前] フィールドと [説明] フィールドにそれぞれ「matrix_unit_utilization_percent」、「MXU 使用率」と入力します。フィルタには、ログ エクスプローラに入力したスクリプトが事前に入力されています。
[指標を作成] をクリックします。
[Metrics Explorer で表示する] をクリックして、新しい指標を表示します。指標が表示されるまでに数分かかることがあります。
Cloud Logging REST API を使用してログベースの指標を作成する
Cloud Logging API を使用してログベースの指標を作成することもできます。詳細については、分布指標の作成をご覧ください。
ログベースの指標を使用してダッシュボードとアラートを作成する
ダッシュボードは指標を可視化するのに役立ちます(最大 2 分遅れ)。アラートは、エラーの発生時に通知を送信するのに役立ちます。詳細については、次のトピックをご覧ください。
ダッシュボードの作成
Cloud Monitoring で Tensorcore のアイドル期間指標用にダッシュボードを作成するには、次の手順を実施します。
- コンソールの Monitoring に移動します。
- ナビゲーション パネルで [ダッシュボード] をクリックします。
- [ダッシュボードを作成]、[ウィジェットを追加] の順にクリックします。
- 追加するグラフのタイプを選択します。この例では、[折れ線] を選択します。
- ウィジェットのタイトルを入力します
- [指標を選択] プルダウン メニューをクリックして、フィルタ フィールドに「Tensorcore idle duration」と入力します。
- 指標のリストで、[TPU ワーカー] -> [TPU] -> [Tensorcore idle duration] を選択します。
- ダッシュボードの内容をフィルタするには、[フィルタ] プルダウン メニューをクリックします。
- [リソースラベル] で、[project_id] を選択します。
- コンパレータを選択し、[値] フィールドに値を入力します。
- [適用] をクリックします。