Cette page fournit des détails sur les configurations par défaut et personnalisées de l'agent Cloud Logging.
La plupart des utilisateurs n'ont pas besoin de lire cette page. Lisez-la si :
vous souhaitez obtenir des détails techniques approfondis sur la configuration de l'agent Cloud Logging ;
vous souhaitez modifier la configuration de l'agent Cloud Logging.
Configuration par défaut
L'agent Logging google-fluentd est une version modifiée du collecteur de données de journal fluentd.
L'agent Logging est fourni avec une configuration par défaut. Dans la plupart des cas, aucune configuration supplémentaire n'est requise.
Dans sa configuration par défaut, l'agent Logging transmet à Cloud Logging les journaux figurant dans la liste des journaux par défaut. Vous pouvez configurer l'agent pour qu'il diffuse des journaux supplémentaires. Pour en savoir plus, consultez la section Personnaliser la configuration de l'agent Logging sur cette page.
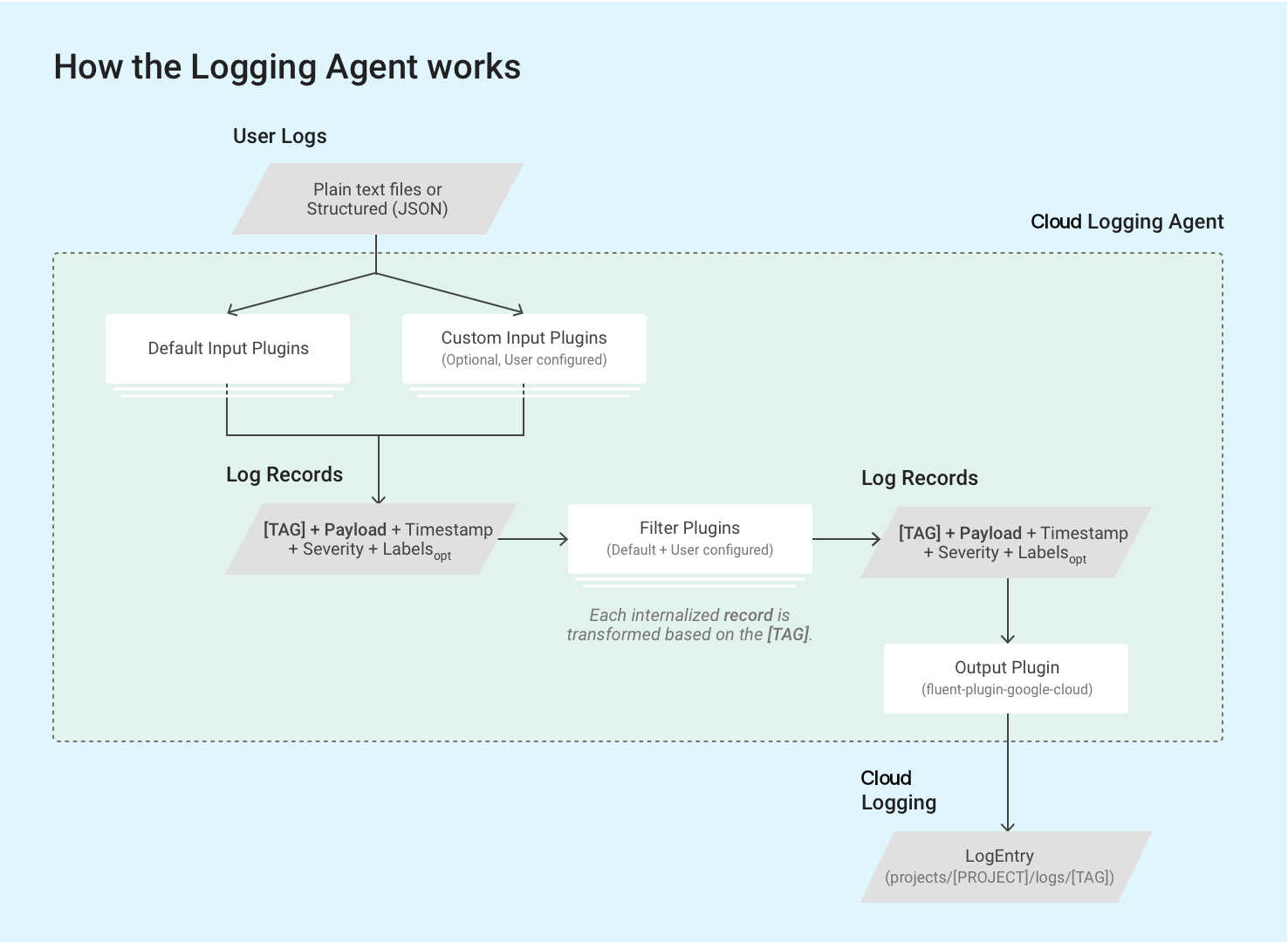
L'agent Logging utilise des plug-ins d'entrée fluentd pour récupérer et extraire des journaux d'événements à partir de sources externes, telles que des fichiers sur disque, ou pour analyser les enregistrements de journaux entrants. Les plug-ins d'entrée sont fournis avec l'agent ou peuvent être installés séparément en tant que gems Ruby. Consultez la liste des plug-ins fournis avec l'agent.
L'agent lit les enregistrements de journal stockés dans les fichiers journaux à l'aide de l'instance de VM via le plug-in intégré in_tail de fluentd. Chaque enregistrement de journal est converti en une structure d'entrée de journal pour Cloud Logging. Le contenu de chaque enregistrement de journal représente la majeure partie de la charge utile des entrées de journal, mais celles-ci contiennent également des éléments standards tels que l’horodatage et le niveau de gravité. L'agent Logging requiert que chaque enregistrement de journal soit tagué avec un tag au format de chaîne. Toutes les requêtes et tous les plug-ins de sortie correspondent à un ensemble de tags spécifique. Le nom du journal suit généralement le format projects/[PROJECT-ID]/logs/[TAG]. Par exemple, le nom de journal suivant inclut le tag structured-log :
projects/my-sample-project-12345/logs/structured-log
Le plug-in de sortie transforme chaque message structuré internalisé en une entrée de journal dans Cloud Logging. La charge utile devient la charge utile de type texte ou JSON.
Les sections suivantes de cette page présentent en détail la configuration par défaut.
Définitions de configuration par défaut
Les sections suivantes décrivent les définitions de configuration par défaut pour syslog, le plug-in d'entrée de transfert, les configurations d'entrée pour les journaux d'applications tierces, comme ceux figurant dans la liste des journaux par défaut et notre plug-in de sortie Google Cloud fluentd.
Emplacement du fichier de configuration racine
Linux :
/etc/google-fluentd/google-fluentd.confCe fichier de configuration racine importe également tous les fichiers de configuration du dossier
/etc/google-fluentd/config.d.Windows :
C:\Program Files (x86)\Stackdriver\LoggingAgent\fluent.confSi vous exécutez une version de l'agent Logging antérieure à la version v1-5, l'emplacement est le suivant :
C:\GoogleStackdriverLoggingAgent\fluent.conf
Configuration de Syslog
Emplacements des fichiers de configuration :
/etc/google-fluentd/config.d/syslog.confDescription : ce fichier inclut la configuration nécessaire pour spécifier syslog en tant qu'entrée de journal.
Consultez le dépôt de configuration.
| Nom de la configuration | Type | Par défaut | Description |
|---|---|---|---|
format |
chaîne | /^(?<message>(?<time>[^ ]*\s*[^ ]* [^ ]*) .*)$/ |
Format du fichier syslog. |
path |
chaîne | /var/log/syslog |
Chemin du fichier syslog. |
pos_file |
chaîne | /var/lib/google-fluentd/pos/syslog.pos |
Chemin du fichier de position pour cette entrée de journal. fluentd enregistre la dernière position lue dans ce fichier. Consultez la documentation détaillée de fluentd. |
read_from_head |
Bool | true |
Indique s'il faut commencer à lire les journaux à partir du haut du fichier plutôt qu'à partir du bas. Consultez la documentation détaillée de fluentd. |
tag |
chaîne | syslog |
Tag de journal pour cette entrée de journal. |
Configuration du plug-in d'entrée in_forward
Emplacements des fichiers de configuration :
/etc/google-fluentd/config.d/forward.confDescription : ce fichier inclut la configuration nécessaire au plug-in d'entrée
in_forwarddefluentd. Le plug-in d'entréein_forwardvous permet de transmettre des journaux via un socket TCP.Consultez la documentation détaillée de
fluentdpour en savoir plus sur ce plug-in et le dépôt de configuration.
| Nom de la configuration | Type | Par défaut | Description |
|---|---|---|---|
port |
int | 24224 |
Port à surveiller |
bind |
chaîne | 127.0.0.1 |
Adresse de liaison à surveiller. Par défaut, seules les connexions de localhost sont acceptées. Pour ouvrir cette adresse, cette configuration doit être définie sur 0.0.0.0. |
Configuration des entrées de journal des applications tierces
Emplacements des fichiers de configuration :
/etc/google-fluentd/config.d/[APPLICATION_NAME].confDescription : ce répertoire inclut des fichiers de configuration permettant de spécifier les fichiers journaux des applications tierces en tant qu'entrées de journal. Chaque fichier, à l'exception de
syslog.confetforward.conf, représente une application (par exemple,apache.confpour l'application Apache).Consultez le dépôt de configuration.
| Nom de la configuration | Type | Par défaut | Description |
|---|---|---|---|
format1 |
chaîne | Varie selon l'application | Format du journal. Consultez la documentation détaillée de fluentd. |
path |
chaîne | Varie selon l'application | Chemin du ou des fichiers journaux. Plusieurs chemins peuvent être spécifiés, séparés par une virgule. L'astérisque (*) et le format "strftime" peuvent être inclus pour ajouter/supprimer le fichier de manière dynamique. Consultez la documentation détaillée de fluentd. |
pos_file |
chaîne | Varie selon l'application | Chemin du fichier de position pour cette entrée de journal. fluentd enregistre la dernière position lue dans ce fichier. Consultez la documentation détaillée de fluentd. |
read_from_head |
Bool | true |
Indique s'il faut commencer à lire les journaux à partir du haut du fichier plutôt qu'à partir du bas. Consultez la documentation détaillée de fluentd. |
tag |
chaîne | Varie selon le nom de l'application. | Tag de journal pour cette entrée de journal. |
1 Si vous utilisez le stanza <parse>, spécifiez le format du journal à l'aide de @type.
Configuration du plug-in de sortieGoogle Cloud fluentd
Emplacements des fichiers de configuration :
- Linux :
/etc/google-fluentd/google-fluentd.conf Windows :
C:\Program Files (x86)\Stackdriver\LoggingAgent\fluent.confSi vous exécutez une version de l'agent Logging antérieure à la version v1-5, l'emplacement est le suivant :
C:\GoogleStackdriverLoggingAgent\fluent.conf
- Linux :
Description: ce fichier inclut des options de configuration permettant de contrôler le comportement du plug-in de sortieGoogle Cloud
fluentd.Accédez au dépôt de configuration.
| Nom de la configuration | Type | Par défaut | Description |
|---|---|---|---|
buffer_chunk_limit |
chaîne | 512KB |
Au fur et à mesure de l'arrivée des enregistrements de journal, ceux qui ne peuvent pas être écrits assez rapidement sur les composants en aval sont envoyés dans une file d'attente de fragments. Cette configuration définit une taille limite pour chaque fragment. Par défaut, nous définissons la taille limite des fragments avec prudence pour éviter de dépasser la taille de fragment recommandée de 5 Mo par requête d'écriture dans l'API Logging. Les entrées de journal figurant dans la requête API peuvent être cinq à huit fois plus volumineuses que l'entrée de journal d'origine, en raison de toutes les métadonnées supplémentaires associées. Un fragment de mémoire tampon est vidé si l'une des deux conditions est remplie : 1. flush_interval est impliqué. 2. La taille de la mémoire tampon atteint la limite définie dans la configuration buffer_chunk_limit. |
flush_interval |
chaîne | 5s |
Au fur et à mesure de l'arrivée des enregistrements de journal, ceux qui ne peuvent pas être écrits assez rapidement sur les composants en aval sont envoyés dans une file d'attente de fragments. La configuration définit le délai avant de pouvoir vider un fragment de mémoire tampon. Un fragment de mémoire tampon est vidé si l'une des deux conditions est remplie : 1. flush_interval est impliqué. 2. La taille de la mémoire tampon atteint la limite définie dans la configuration buffer_chunk_limit. |
disable_retry_limit |
Bool | false |
Applique une limite au nombre de tentatives de vidage des fragments de mémoire tampon en cas d'échec. Consultez les spécifications détaillées dans retry_limit, retry_wait et max_retry_wait. |
retry_limit |
int | 3 |
Lorsqu'un fragment de mémoire tampon ne peut pas être vidé, fluentd réessaie plus tard, par défaut. Cette configuration définit le nombre de tentatives à effectuer avant de supprimer un fragment de mémoire tampon problématique. |
retry_wait |
int | 10s |
Lorsqu'un fragment de mémoire tampon ne peut pas être vidé, fluentd réessaie plus tard, par défaut. Cette configuration définit l'intervalle d'attente en secondes avant de réessayer une première fois. L'intervalle d'attente est doublé à chaque nouvelle tentative (20 s, 40 s,…), jusqu'à atteindre retry_ limit ou max_retry_wait. |
max_retry_wait |
int | 300 |
Lorsqu'un fragment de mémoire tampon ne peut pas être vidé, fluentd réessaie plus tard, par défaut. L'intervalle d'attente double à chaque nouvelle tentative (20 s, 40 s,...). Cette configuration définit la durée maximale d'un intervalle d'attente en secondes. Si l'intervalle d'attente atteint cette limite, le doublement s'arrête. |
num_threads |
int | 8 |
Nombre de vidages de journaux pouvant être traités simultanément par le plug-in de sortie. |
use_grpc |
Bool | true |
Indique si gRPC doit être utilisé à la place de REST/JSON pour communiquer avec l'API Logging. Avec gRPC activé, l'utilisation du processeur est généralement moindre. |
grpc_compression_algorithm |
enum | none |
Si vous utilisez gRPC, définit le schéma de compression à utiliser. Il peut s'agir de none ou gzip. |
partial_success |
Bool | true |
Indique la compatibilité avec l'ingestion partielle des journaux. Si ce paramètre est défini sur true, les entrées de journal non valides d'un ensemble complet sont supprimées et les entrées de journal valides sont correctement ingérées dans l'API Logging. S'il est défini sur false, l'ensemble complet est supprimé s'il contient des entrées de journal non valides. |
enable_monitoring |
Bool | true |
Si ce paramètre est défini sur true, l'agent Logging exporte la télémétrie interne. Pour en savoir plus, consultez la section Télémétrie du plug-in de sortie. |
monitoring_type |
chaîne | opencensus |
Type de surveillance. Les options acceptées sont opencensus et prometheus. Pour en savoir plus, consultez la section Télémétrie du plug-in de sortie. |
autoformat_stackdriver_trace |
Bool | true |
Si ce paramètre est défini sur true, la trace est reformatée lorsque la valeur du champ de charge utile structurée logging.googleapis.com/trace correspond au format traceId de ResourceTrace. Les détails concernant le formatage automatique sont disponibles sur cette page à la section Champs spéciaux dans les charges utiles structurées. |
Configuration de la surveillance
Télémétrie du plug-in de sortie
L'option enable_monitoring détermine si le plug-in de sortie Google Cloud fluentd collecte sa télémétrie interne. Lorsque ce paramètre est défini sur true, l'agent Logging enregistre le nombre d'entrées de journal à envoyer à Cloud Logging et le nombre réel d'entrées de journal ingérées avec succès par Cloud Logging. Lorsque la valeur est false, aucune métrique n'est collectée par le plug-in de sortie.
L'option monitoring_type contrôle la manière dont cette télémétrie est exposée par l'agent. Pour obtenir la liste des métriques, consultez la section suivante.
Lorsqu'il est défini sur prometheus, l'agent Logging expose les métriques au format Prometheus sur le point de terminaison Prometheus (localhost:24231/metrics par défaut). Consultez la page Prometheus et configuration du plug-in prometheus_monitor pour en savoir plus sur la personnalisation de cette méthode. Sur les VM Compute Engine, pour que ces métriques soient écrites dans l'API Monitoring, l'agent de surveillance doit également être installé et exécuté.
Lorsque ce paramètre est défini sur opencensus (valeur par défaut depuis la version v1.6.25), l'agent Logging écrit directement ses propres métriques d'état dans l'API Monitoring. Cette opération nécessite que le rôle roles/monitoring.metricWriter soit attribué au compte de service Compute Engine par défaut, même si l'agent Monitoring n'est pas installé.
Les métriques suivantes sont écrites dans l'API Monitoring par l'agent Monitoring et par l'agent Logging en mode opencensus :
agent.googleapis.com/agent/uptimeavec un libelléversion: temps d'activité de l'agent Logging.agent.googleapis.com/agent/log_entry_countavec une libelléresponse_code: nombre d'entrées de journal écrites par l'agent Logging.agent.googleapis.com/agent/log_entry_retry_countavec une libelléresponse_code: nombre d'entrées de journal écrites par l'agent Logging.agent.googleapis.com/agent/request_countavec un libelléresponse_code: nombre de requêtes API de l'agent Logging.
Ces métriques sont décrites plus en détail sur la page Métriques d'agent.
De plus, les métriques Prometheus suivantes sont exposées par le plug-in de sortie en mode prometheus :
uptimeavec un libelléversion: temps d'activité de l'agent Logging.stackdriver_successful_requests_countavec les libellésgrpcetcode: nombre de requêtes réussies adressées à l'API Logging.stackdriver_failed_requests_countavec les libellésgrpcetcode: nombre de requêtes infructueuses pour l'API Logging, réparties par code d'erreur.stackdriver_ingested_entries_countavec les libellésgrpcetcode: nombre d'entrées de journal ingérées par l'API Logging.stackdriver_dropped_entries_countavec les libellésgrpcetcode: nombre d'entrées de journal rejetées par l'API Logging.stackdriver_retried_entries_countavec les libellésgrpcetcode: nombre d'entrées de journal qui n'ont pas pu être ingérées par le plug-in de sortie Google Cloudfluentden raison d'une erreur temporaire et ont fait l'objet d'une nouvelle tentative.
Prometheus et configuration du plug-in prometheus_monitor
Emplacements des fichiers de configuration :
/etc/google-fluentd/google-fluentd.confDescription : ce fichier inclut des options de configuration permettant de contrôler le comportement des plug-ins
prometheusetprometheus_monitor. Le plug-inprometheus_monitorsurveille l'infrastructure principale de Fluentd. Le plug-inprometheusexpose les métriques, y compris celles du plug-inprometheus_monitoret celles du plug-ingoogle_cloudci-dessus via un port local au format Prometheus. Pour en savoir plus, consultez la page https://docs.fluentd.org/deployment/monitoring-prometheus.Accédez au dépôt de configuration.
Pour la surveillance de Fluentd, le serveur de métriques HTTP Prometheus intégré est activé par défaut. Vous pouvez supprimer la section suivante de la configuration pour éviter le démarrage de ce point de terminaison :
# Prometheus monitoring.
<source>
@type prometheus
port 24231
</source>
<source>
@type prometheus_monitor
</source>
Traiter les charges utiles
La plupart des journaux compatibles avec la configuration par défaut de l'agent Logging proviennent de fichiers journaux et sont ingérés en tant que charges utiles non structurées (texte) dans les entrées de journal.
La seule exception est que le plug-in d'entrée in_forward, qui est également activé par défaut, accepte uniquement les journaux structurés et les ingère en tant que charges utiles structurées (JSON) dans les entrées de journal. Pour plus d'informations, consultez la section Diffuser des enregistrements de journal structurés (JSON) via le plug-in in_forward sur cette page.
Lorsque la ligne de journal est un objet JSON sérialisé et que l'option detect_json est activée, le plug-in de sortie transforme l'entrée de journal en charge utile structurée (JSON). Cette option est activée par défaut dans les instances de VM s'exécutant dans un environnement flexible App Engine ou Google Kubernetes Engine. Cette option n'est pas activée par défaut dans les instances de VM s'exécutant dans l'environnement standard App Engine. Les objets JSON analysés avec l'option detect_json sont toujours ingérés en tant que jsonPayload.
Vous pouvez personnaliser la configuration des agents pour qu'ils soient compatibles avec l'ingestion de journaux structurés à partir de ressources supplémentaires. Pour en savoir plus, consultez la section Diffuser des enregistrements de journal structurés (JSON) dans Cloud Logging.
La charge utile des enregistrements de journal diffusés par un agent Logging personnalisé peut être un message texte non structuré unique (textPayload) ou un message JSON structuré (jsonPayload).
Champs spéciaux dans les charges utiles structurées
Lorsque l'agent Logging reçoit un enregistrement de journal structuré, il déplace les clés correspondant à la table suivante dans le champ correspondant de l'objet LogEntry. Dans le cas contraire, la clé fait partie du champ LogEntry.jsonPayload. Ce comportement vous permet de définir des champs spécifiques dans l'objet LogEntry, qui est écrit dans l'API Logging.
Par exemple, si l'enregistrement de journal structuré contient une clé de severity, l'agent Logging renseigne le champ LogEntry.severity.
| Champ de journal JSON |
LogEntry
champ
|
Fonction de l'agent Cloud Logging | Exemple de valeur |
|---|---|---|---|
severity
|
severity
|
L'agent Logging tente de faire correspondre différentes chaînes de gravité courantes, qui incluent la liste des chaînes LogSeverity reconnues par l'API Logging. | "severity":"ERROR"
|
message
|
textPayload (ou partie de jsonPayload)
|
Message qui s'affiche sur la ligne d'entrée de journal dans l'explorateur de journaux. | "message":"There was an error in the application." Remarque : Le champ message est enregistré en tant que textPayload s'il s'agit du seul champ restant après le déplacement des autres champs spécifiques par l'agent Logging et si detect_json était désactivé. Sinon, message reste dans jsonPayload. detect_json ne s'applique pas aux environnements de journalisation gérés tels que Google Kubernetes Engine. Si votre entrée de journal contient une trace de la pile d'exception, celle-ci doit être définie dans le champ de journal JSON message, de sorte qu'elle puisse être analysée et enregistrée dans Error Reporting. |
log (ancienne version de Google Kubernetes Engine uniquement) |
textPayload
|
Ne s'applique qu'à l'ancienne version de Google Kubernetes Engine : si après déplacement des champs spéciaux, il ne reste plus qu'un champ log, ce champ est enregistré en tant que textPayload. |
|
httpRequest
|
httpRequest
|
Un enregistrement structuré au format du champ HttpRequest de LogEntry. |
"httpRequest":{"requestMethod":"GET"}
|
| champs liés au temps | timestamp
|
Pour en savoir plus, consultez la section Champs liés au temps. | "time":"2020-10-12T07:20:50.52Z"
|
logging.googleapis.com/insertId
|
insertId
|
Pour en savoir plus, consultez la section insertId de la page LogEntry. |
"logging.googleapis.com/insertId":"42"
|
logging.googleapis.com/labels
|
labels
|
La valeur de ce champ doit être un enregistrement structuré.
Pour en savoir plus, consultez la section labels de la page LogEntry. |
"logging.googleapis.com/labels":
{"user_label_1":"value_1","user_label_2":"value_2"}
|
logging.googleapis.com/operation
|
operation
|
La valeur de ce champ est également utilisée par l'explorateur de journaux pour regrouper les entrées de journal associées.
Pour en savoir plus, consultez la section operation de la page LogEntry. |
"logging.googleapis.com/operation":
{"id":"get_data","producer":"github.com/MyProject/MyApplication",
"first":"true"}
|
logging.googleapis.com/sourceLocation
|
sourceLocation
|
Les informations d'emplacement du code source associées à l'entrée de journal, le cas échéant.
Pour en savoir plus, consultez la section LogEntrySourceLocation de la page LogEntry. |
"logging.googleapis.com/sourceLocation":
{"file":"get_data.py","line":"142","function":"getData"}
|
logging.googleapis.com/spanId
|
spanId
|
ID de délai dans la trace associée à l'entrée de journal.
Pour en savoir plus, consultez la section spanId de la page LogEntry. |
"logging.googleapis.com/spanId":"000000000000004a"
|
logging.googleapis.com/trace
|
trace
|
Nom de ressource de la trace associée à l'entrée de journal, le cas échéant.
Pour en savoir plus, consultez la section trace de la page LogEntry.
|
"logging.googleapis.com/trace":"projects/my-projectid/traces/0679686673a" Remarque : Si vous n'écrivez pas dans stdout ou stderr, la valeur de ce champ doit être au format projects/[PROJECT-ID]/traces/[TRACE-ID]. Cela permet à l'explorateur de journaux et au lecteur de traces de regrouper les entrées de journal et de les afficher en parallèle avec les traces.
Si le paramètre autoformat_stackdriver_trace est défini sur "true" et que [V] correspond au format traceId de ResourceTrace, le champ trace de LogEntry possède la valeur projects/[PROJECT-ID]/traces/[V]. |
logging.googleapis.com/trace_sampled
|
traceSampled
|
La valeur de ce champ doit être true ou false.
Pour en savoir plus, consultez la section traceSampled de la page LogEntry. |
"logging.googleapis.com/trace_sampled": false
|
Champs liés au temps
En général, les informations temporelles concernant une entrée de journal sont stockées dans le champ timestamp de l'objet LogEntry:
{
insertId: "1ad8d08f-6529-47ea-832e-467f869a2da4"
...
resource: {2}
timestamp: "2023-10-30T16:33:15.505196Z"
}
Lorsque la source d'une entrée de journal est une donnée structurée, l'agent Logging utilise les règles suivantes pour rechercher des informations temporelles dans les champs de l'entrée jsonPayload :
Recherchez un champ
timestampqui est un objet JSON incluant les champssecondsetnanos, qui représentent respectivement un nombre de secondes signé de l'époque UTC et un nombre non négatif de secondes fractionnaires :jsonPayload: { ... "timestamp": { "seconds": CURRENT_SECONDS, "nanos": CURRENT_NANOS } }Si la recherche précédente échoue, recherchez une paire de champs
timestampSecondsettimestampNanos:jsonPayload: { ... "timestampSeconds": CURRENT_SECONDS, "timestampNanos": CURRENT_NANOS }Si la recherche précédente échoue, recherchez un champ
timequi est une chaîne au format RFC 3339 :jsonPayload: { ... "time": CURRENT_TIME_RFC3339 }
Lorsque des informations temporelles sont trouvées, l'agent Logging les utilise pour définir la valeur de LogEntry.timestamp et ne copie pas ces informations depuis l'enregistrement structuré dans l'objet LogEntry.jsonPayload.
Les champs d'informations temporelles qui ne sont pas utilisés pour définir la valeur du champ LogEntry.timestamp sont copiés à partir de l'enregistrement structuré dans l'objet LogEntry.jsonPayload. Par exemple, si l'enregistrement structuré contient un objet JSON timestamp et un champ time, les données de l'objet JSON timestamp sont utilisées pour définir LogEntry.timestamp. L'objet LogEntry.jsonPayload contient un champ time, car ce champ n'a pas été utilisé pour définir la valeur LogEntry.timestamp.
Personnaliser la configuration de l'agent
Outre la liste des journaux par défaut diffusés par l'agent Logging, vous pouvez personnaliser ce dernier pour qu'il envoie des journaux supplémentaires à Logging ou pour ajuster les paramètres de l'agent en ajoutant des configurations d'entrée.
Les définitions de configuration figurant dans ces sections ne s'appliquent qu'au plug-in de sortie fluent-plugin-google-cloud et spécifient la manière dont les journaux sont transformés et ingérés dans Cloud Logging.
Emplacement principal des fichiers de configuration :
- Linux :
/etc/google-fluentd/google-fluentd.conf Windows :
C:\Program Files (x86)\Stackdriver\LoggingAgent\fluent.confSi vous exécutez une version de l'agent Logging antérieure à la version v1-5, l'emplacement est le suivant :
C:\GoogleStackdriverLoggingAgent\fluent.conf
- Linux :
Description : ce fichier inclut des options de configuration permettant de contrôler le comportement du plug-in de sortie
fluent-plugin-google-cloud.Consultez le dépôt de configuration.
Diffuser des journaux à partir d'entrées supplémentaires
Vous pouvez personnaliser l'agent Logging pour envoyer des journaux supplémentaires à Logging en ajoutant des configurations d'entrée.
Diffuser des journaux non structurés (texte) via des fichiers journaux
Dans l'invite de commande Linux, créez un fichier journal :
touch /tmp/test-unstructured-log.logCréez un fichier de configuration nommé
test-unstructured-log.confdans le répertoire de configuration supplémentaire/etc/google-fluentd/config.d:sudo tee /etc/google-fluentd/config.d/test-unstructured-log.conf <<EOF <source> @type tail <parse> # 'none' indicates the log is unstructured (text). @type none </parse> # The path of the log file. path /tmp/test-unstructured-log.log # The path of the position file that records where in the log file # we have processed already. This is useful when the agent # restarts. pos_file /var/lib/google-fluentd/pos/test-unstructured-log.pos read_from_head true # The log tag for this log input. tag unstructured-log </source> EOFPour créer un fichier, vous pouvez également ajouter les informations de configuration à un fichier de configuration existant.
Redémarrez l'agent pour appliquer les modifications de la configuration :
sudo service google-fluentd restartGénérez un enregistrement de journal dans le fichier journal :
echo 'This is a log from the log file at test-unstructured-log.log' >> /tmp/test-unstructured-log.logConsultez l'explorateur de journaux pour afficher l'entrée de journal ingérée :
{ insertId: "eps2n7g1hq99qp" labels: { compute.googleapis.com/resource_name: "add-unstructured-log-resource" } logName: "projects/my-sample-project-12345/logs/unstructured-log" receiveTimestamp: "2018-03-21T01:47:11.475065313Z" resource: { labels: { instance_id: "3914079432219560274" project_id: "my-sample-project-12345" zone: "us-central1-c" } type: "gce_instance" } textPayload: "This is a log from the log file at test-unstructured-log.log" timestamp: "2018-03-21T01:47:05.051902169Z" }
Diffuser des journaux structurés (JSON) via des fichiers journaux
Vous pouvez configurer l'agent Logging pour exiger que certaines entrées de journal soient structurées. Vous pouvez également personnaliser l'agent Logging pour qu'il ingère du contenu au format JSON à partir d'un fichier journal. Lorsque l'agent est configuré pour ingérer du contenu JSON, l'entrée doit être mise en forme de sorte que chaque objet JSON se trouve sur une nouvelle ligne :
{"name" : "zeeshan", "age" : 28}
{"name" : "reeba", "age" : 15}
Pour que l'agent Logging ingère du contenu au format JSON, procédez comme suit :
Dans l'invite de commande Linux, créez un fichier journal :
touch /tmp/test-structured-log.logCréez un fichier de configuration nommé
test-structured-log.confdans le répertoire de configuration supplémentaire/etc/google-fluentd/config.d:sudo tee /etc/google-fluentd/config.d/test-structured-log.conf <<EOF <source> @type tail <parse> # 'json' indicates the log is structured (JSON). @type json </parse> # The path of the log file. path /tmp/test-structured-log.log # The path of the position file that records where in the log file # we have processed already. This is useful when the agent # restarts. pos_file /var/lib/google-fluentd/pos/test-structured-log.pos read_from_head true # The log tag for this log input. tag structured-log </source> EOFPour créer un fichier, vous pouvez également ajouter les informations de configuration à un fichier de configuration existant.
Redémarrez l'agent pour appliquer les modifications de la configuration :
sudo service google-fluentd restartGénérez un enregistrement de journal dans le fichier journal :
echo '{"code": "structured-log-code", "message": "This is a log from the log file at test-structured-log.log"}' >> /tmp/test-structured-log.logConsultez l'explorateur de journaux pour afficher l'entrée de journal ingérée :
{ insertId: "1m9mtk4g3mwilhp" jsonPayload: { code: "structured-log-code" message: "This is a log from the log file at test-structured-log.log" } labels: { compute.googleapis.com/resource_name: "add-structured-log-resource" } logName: "projects/my-sample-project-12345/logs/structured-log" receiveTimestamp: "2018-03-21T01:53:41.118200931Z" resource: { labels: { instance_id: "5351724540900470204" project_id: "my-sample-project-12345" zone: "us-central1-c" } type: "gce_instance" } timestamp: "2018-03-21T01:53:39.071920609Z" }Dans l'explorateur de journaux, filtrez le type de ressource et définissez logName sur
structured-log.
Pour accéder à d'autres options permettant de personnaliser le format des entrées de journal pour les applications tierces courantes, consultez la section Formats de journaux courants et comment les analyser.
Diffuser des journaux structurés (JSON) via le plug-in in_forward
Vous pouvez également envoyer des journaux via le plug-in fluentd in_forward.
fluentd-cat est un outil intégré qui permet d'envoyer facilement des journaux au plug-in in_forward. Consultez la documentation de fluentd pour en savoir plus sur cet outil.
Pour envoyer des journaux via le plug-in fluentd in_forward, suivez les instructions ci-dessous :
Exécutez la commande suivante sur la VM où l'agent Logging est installé :
echo '{"code": "send-log-via-fluent-cat", "message": "This is a log from in_forward plugin."}' | /opt/google-fluentd/embedded/bin/fluent-cat log-via-in-forward-pluginConsultez l'explorateur de journaux pour afficher l'entrée de journal ingérée :
{ insertId: "1kvvmhsg1ib4689" jsonPayload: { code: "send-log-via-fluent-cat" message: "This is a log from in_forward plugin." } labels: { compute.googleapis.com/resource_name: "add-structured-log-resource" } logName: "projects/my-sample-project-12345/logs/log-via-in-forward-plugin" receiveTimestamp: "2018-03-21T02:11:27.981020900Z" resource: { labels: { instance_id: "5351724540900470204" project_id: "my-sample-project-12345" zone: "us-central1-c" } type: "gce_instance" } timestamp: "2018-03-21T02:11:22.717692494Z" }
Diffuser des enregistrements de journal structurés (JSON) à partir du code de l'application
Vous pouvez activer des connecteurs dans différents langages pour envoyer des journaux structurés à partir du code de l'application. Pour plus d'informations, consultez la documentation de fluentd.
Ces connecteurs sont basés sur le plug-in in_forward.
Définir des étiquettes d'entrée de journal
Les options de configuration ci-dessous vous permettent de remplacer les étiquettes de LogEntry et de MonitoredResource lors de l'ingestion de journaux dans Cloud Logging. Toutes les entrées de journal sont associées à des ressources surveillées. Pour plus d'informations, consultez la liste des types de ressources surveillées Cloud Logging.
| Nom de la configuration | Type | Par défaut | Description |
|---|---|---|---|
label_map |
hash | nil | label_map (spécifié en tant qu'objet JSON) est un ensemble non ordonné de noms de champs fluentd dont les valeurs sont envoyées sous forme d'étiquettes plutôt que comme éléments de la charge utile structurée. Chaque entrée de la table de correspondances est une association {field_name : label_name}. Lorsque l'occurrence field_name (analysée par le plug-in d'entrée) se présente, une étiquette avec le label_name correspondant est ajoutée à l'entrée de journal. La valeur du champ est utilisée comme valeur du libellé. La table de correspondances vous offre une flexibilité supplémentaire dans la spécification des noms d'étiquettes, y compris la possibilité d'utiliser des caractères qui ne sont pas autorisés dans les noms de champs fluentd. Pour obtenir un exemple, consultez la section Définir des étiquettes dans des entrées de journal structurées. |
labels |
hash | nil | labels (spécifié en tant qu'objet JSON) est un ensemble d'étiquettes personnalisées fournies au moment de la configuration. Il vous permet d'injecter des informations environnementales supplémentaires dans chaque message ou de personnaliser automatiquement les étiquettes détectées d'une autre manière. Chaque entrée de la table de correspondances est une association {label_name : label_value}. |
Le plug-in de sortie de l'agent Logging accepte trois méthodes pour définir les étiquettes de LogEntry :
- Dynamiquement, en remplaçant des étiquettes spécifiques dans une entrée structurée par des étiquettes différentes. Pour plus d'informations, consultez la section Définir des étiquettes dans des entrées de journal structurées sur cette page.
- Statiquement, en associant un libellé à toutes les occurrences d'une valeur. Pour en savoir plus, consultez la section Définition des étiquettes statistiquement sur cette page.
Définir des étiquettes dans des entrées de journal structurées
Supposons que vous ayez écrit une charge utile d'entrée de journal structurée comme ceci :
{ "message": "This is a log message", "timestamp": "Aug 10 20:07:00", "env": "production" }
Et supposons que vous souhaitiez traduire le champ de charge utile env en une étiquette de métadonnées environment. Pour cela, ajoutez ce qui suit à la configuration de votre plug-in de sortie dans le fichier de configuration principal (/etc/google-fluentd/google-fluentd.conf sous Linux ou C:\Program Files (x86)\Stackdriver\LoggingAgent\fluent.conf sous Windows) :
# Configure all sources to output to Cloud Logging
<match **>
@type google_cloud
label_map {
"env": "environment"
}
...
</match>
Le paramètre label_map remplace ici l'étiquette env par environment dans la charge utile, de sorte que l'entrée de journal résultante aura une étiquette environment avec la valeur production.
Définir des étiquettes statiquement
Si vous ne disposez pas de ces informations dans la charge utile et que vous souhaitez simplement ajouter une étiquette de métadonnées statique appelée environment, ajoutez ce qui suit à la configuration de votre plug-in de sortie dans le fichier de configuration principal (/etc/google-fluentd/google-fluentd.conf sous Linux ou C:\Program Files (x86)\Stackdriver\LoggingAgent\fluent.conf sous Windows) :
# Configure all sources to output to Cloud Logging
<match **>
@type google_cloud
labels {
"environment": "production"
}
...
</match>
Dans ce cas, au lieu d'utiliser une table de correspondances pour remplacer une étiquette par une autre, nous utilisons un paramètre labels pour associer une étiquette avec une valeur littérale donnée à une entrée de journal, que celle-ci comporte déjà une étiquette ou pas. Cette approche peut être utilisée même si vous envoyez des journaux non structurés.
Pour plus d'informations sur la configuration du paramètre labels, du paramètre label_map et des autres paramètres de l'agent Logging, consultez la section Définir des étiquettes d'entrée de journal sur cette page.
Modifier des enregistrements de journal
Fluentd fournit des plug-ins de filtrage intégrés pouvant être utilisés pour modifier les entrées de journal.
Le plug-in de filtrage le plus couramment utilisé est filter_record_transformer. Il vous permet :
- d'ajouter de nouveaux champs aux entrées de journal ;
- de mettre à jour les champs dans les entrées de journal ;
- de supprimer des champs dans les entrées de journal.
Certains plug-ins de sortie permettent également de modifier les entrées de journal.
Le plug-in de sortie fluent-plugin-record-reformer fournit des fonctionnalités similaires au plug-in de filtrage filter_record_transformer, et permet en plus de modifier les tags de journaux.
Ce plug-in devrait conduire à une utilisation plus importante des ressources : à chaque fois qu'un tag de journal est mis à jour, une nouvelle entrée de journal est générée avec le nouveau tag.
Notez que le champ tag est requis dans la configuration. Nous vous recommandons également de modifier ce champ pour éviter d'introduire une boucle morte.
Le plug-in de sortie fluent-plugin-detect-exceptions analyse un flux de journal (enregistrements de journal non structurés (texte) ou au format JSON) afin de rechercher des traces de la pile d'exception multilignes. Si une séquence consécutive d'entrées de journal forme une trace de la pile d'exceptions, les entrées de journal sont transférées sous la forme d'un seul message de journaux combinés. Sinon, l'entrée de journal est transférée telle quelle.
Définitions de configuration avancées (autres que par défaut)
Si vous souhaitez personnaliser la configuration de votre agent Logging au-delà de sa configuration par défaut, consultez les sections suivantes.
Options de configuration liées à la mémoire tampon
Les options de configuration suivantes vous permettent d'ajuster le mécanisme de mise en mémoire tampon interne de l'agent Logging.
| Nom de la configuration | Type | Par défaut | Description |
|---|---|---|---|
buffer_type |
chaîne | buf_memory |
Les enregistrements qui ne peuvent pas être écrits suffisamment rapidement dans l'API Logging seront placés dans une mémoire tampon. Le tampon peut se trouver en mémoire ou dans des fichiers réels. Valeur recommandée : buf_file. La valeur par défaut de buf_memory est rapide, mais pas persistante. Il existe un risque de perte de journaux. Si le paramètre buffer_type est défini sur buf_file, le paramètre buffer_path doit également être spécifié. |
buffer_path |
chaîne | Spécifié par l'utilisateur | Chemin où les fragments de mémoire tampon sont stockés. Ce paramètre est obligatoire si le paramètre buffer_type est défini sur file. Cette configuration doit être unique pour éviter une condition de concurrence. |
buffer_queue_limit |
int | 64 |
Spécifie la longueur maximale de la file d'attente. Lorsque la file d'attente de tampon atteint ce nombre de fragments, le comportement de la mémoire tampon est contrôlé par le paramètre buffer_queue_full_action. Par défaut, des exceptions sont générées. Cette option associée à buffer_chunk_limit détermine l'espace disque maximal autorisé par fluentd pour la mise en mémoire tampon. |
buffer_queue_full_action |
chaîne | exception |
Contrôle le comportement de la mémoire tampon lorsque la file d'attente est pleine. Valeurs possibles : 1. exception : renvoie BufferQueueLimitError lorsque la file d'attente est pleine. La manière dont BufferQueueLimitError est traité dépend des plug-ins d'entrée. Par exemple, le plug-in d'entrée in_tail arrête de lire de nouvelles lignes alors que le plug-in d'entrée in_forward renvoie une erreur. 2. block : ce mode arrête le thread du plug-in d'entrée jusqu'à ce que la mémoire tampon soit vidée. Cette action est utile pour les cas d'utilisation par lot. fluentd déconseille d'utiliser une action de blocage afin d'éviter l'erreur BufferQueueLimitError. Si BufferQueueLimitError est fréquemment renvoyé, cela signifie que votre capacité de destination est insuffisante pour votre trafic. 3. drop_oldest_chunk : ce mode supprime les fragments obsolètes. |
Options de configuration liées aux projets et aux ressources surveillées
Les options de configuration suivantes vous permettent de spécifier manuellement un projet et certains champs à partir de l'objet MonitoredResource. Ces valeurs sont automatiquement collectées par l'agent Logging ; il est déconseillé de les spécifier manuellement.
| Nom de la configuration | Type | Par défaut | Description |
|---|---|---|---|
project_id |
chaîne | nil | Si elle est spécifiée, cette valeur remplace la valeur de project_id en identifiant le projet Google Cloud ou AWS sous-jacent dans lequel l'agent Logging est exécuté. Google Cloud |
zone |
chaîne | nil | Si elle est spécifiée, cette valeur remplace la zone. |
vm_id |
chaîne | nil | Si elle est spécifiée, cette valeur remplace l'ID de la VM. |
vm_name |
chaîne | nil | Si elle est spécifiée, cette valeur remplace le nom de la VM. |
Autres options de configuration du plug-in de sortie
| Nom de la configuration | Type | Par défaut | Description |
|---|---|---|---|
detect_json1 |
Bool | false |
Indique s'il faut essayer de détecter si l'enregistrement de journal est une entrée de journal de type texte avec un contenu JSON qui doit être analysé. Si ce paramètre est défini sur true, et qu'une entrée de journal non structurée (texte) est détectée comme étant au format JSON, elle est analysée et envoyée en tant que charge utile structurée (JSON). |
coerce_to_utf8 |
Bool | true |
Indique s'il faut autoriser ou non les caractères non UTF-8 dans les journaux d'utilisateurs. Si ce paramètre est défini sur true, tout caractère non UTF-8 sera remplacé par la chaîne spécifiée par non_utf8_replacement_string. S'il est défini sur false, tout caractère non UTF-8 déclenche une erreur du plug-in. |
require_valid_tags |
Bool | false |
Indique s'il faut rejeter les entrées de journal avec des tags non valides. Si ce paramètre est défini sur false, les tags seront validés en convertissant tout tag qui n'est pas de type chaîne en chaîne, et en supprimant tout caractère non UTF-8 et d'autres caractères non valides. |
non_utf8_replacement_string |
chaîne | ""(espace) |
Si le paramètre coerce_to_utf8 est défini sur true, tout caractère non UTF-8 sera remplacé par la chaîne spécifiée ici. |
1Cette fonctionnalité est activée par défaut dans les instances de VM s'exécutant dans un environnement flexible App Engine ou Google Kubernetes Engine.
Appliquer la configuration d'agent personnalisée
La personnalisation de l'agent Logging vous permet d'ajouter vos propres fichiers de configuration fluentd :
Instance Linux
Copiez vos fichiers de configuration dans le répertoire suivant :
/etc/google-fluentd/config.d/Le script d'installation de l'agent Logging remplit ce répertoire avec les fichiers de configuration "catch-all" par défaut. Pour en savoir plus, consultez la section Obtenir le code source de l'agent Logging.
Facultatif Validez votre modification de configuration en exécutant la commande suivante :
sudo service google-fluentd configtestRedémarrez l'agent en exécutant la commande suivante :
sudo service google-fluentd force-reload
Instance Windows
Copiez vos fichiers de configuration dans le sous-répertoire
config.ddu répertoire d'installation de l'agent. Si vous avez accepté le répertoire d'installation par défaut, ce répertoire est le suivant :C:\Program Files (x86)\Stackdriver\LoggingAgent\config.d\Redémarrez l'agent en exécutant les commandes suivantes dans une interface système de ligne de commande :
net stop StackdriverLogging net start StackdriverLogging
Pour en savoir plus sur les fichiers de configuration fluentd, consultez la documentation sur la syntaxe des fichiers de configuration de fluentd.