이 문서에서는 관리형 컬렉션으로 Google Cloud Managed Service for Prometheus를 설정하는 방법을 설명합니다. 이 설정은 예시 애플리케이션을 모니터링하고 수집된 측정항목을 Monarch에 저장하는 Prometheus 배포를 사용하는 수집 작동에 대한 최소한의 예시입니다.
이 문서에서는 다음을 수행하는 방법을 보여줍니다.
- 환경 및 명령줄 도구를 설정합니다.
- 클러스터의 관리형 컬렉션을 설정합니다.
- 대상 스크래핑 및 측정항목 수집을 위해 리소스를 구성합니다.
- 기존 prometheus-operator 커스텀 리소스를 마이그레이션합니다.
수집기 배포, 확장, 샤딩, 구성, 유지보수의 복잡성을 줄여주므로, 관리형 컬렉션을 사용하는 것이 좋습니다. 관리형 컬렉션은 GKE 및 기타 모든 Kubernetes 환경에 지원됩니다.
관리형 컬렉션은 Prometheus 기반 수집기를 Daemonset으로 실행하고 코로케이션 노드에서 대상을 스크래핑하여 확장성을 보장합니다. 가져오기 컬렉션을 사용하여 내보내기를 스크래핑하도록 경량 커스텀 리소스로 수집기를 구성한 후 수집기가 스크래핑된 데이터를 중앙 데이터 스토어 Monarch로 푸시합니다. Google Cloud 는 클러스터에 직접 액세스하여 측정항목 데이터를 가져오거나 스크래핑하지 않습니다. 수집기가Google Cloud로 데이터를 내보냅니다. 관리형 및 자체 배포 데이터 수집에 대한 자세한 내용은 Managed Service for Prometheus를 사용한 데이터 수집과 관리형 및 자체 배포 컬렉션을 사용한 수집 및 쿼리를 참조하세요.
시작하기 전에
이 섹션에서는 이 문서에 설명된 태스크에 필요한 구성에 대해 설명합니다.
프로젝트 및 도구 설정
Google Cloud Managed Service for Prometheus를 사용하려면 다음 리소스가 필요합니다.
Cloud Monitoring API가 사용 설정된 Google Cloud 프로젝트
Google Cloud 프로젝트가 없으면 다음을 수행합니다.
Google Cloud 콘솔에서 새 프로젝트로 이동합니다.
프로젝트 이름 필드에서 프로젝트 이름을 입력한 후 만들기를 클릭합니다.
결제로 이동합니다.
페이지 상단에서 아직 선택하지 않았으면 바로 전에 만든 프로젝트를 선택합니다.
기존 결제 프로필을 선택하거나 새 결제 프로필을 만들라는 메시지가 표시됩니다.
Monitoring API는 새 프로젝트에 대해 기본적으로 사용 설정됩니다.
Google Cloud 프로젝트가 이미 있으면 Monitoring API가 사용 설정되었는지 확인합니다.
API 및 서비스로 이동합니다.
프로젝트를 선택합니다.
API 및 서비스 사용 설정을 클릭합니다.
'Monitoring'을 검색합니다.
검색 결과에서 'Cloud Monitoring API'를 클릭합니다.
'API 사용 설정'이 표시되지 않으면 사용 설정 버튼을 클릭합니다.
Kubernetes 클러스터가 필요합니다. Kubernetes 클러스터가 없으면 GKE 빠른 시작 안내를 따르세요.
또한 다음 명령줄 도구가 필요합니다.
gcloudkubectl
gcloud 및 kubectl 도구는 Google Cloud CLI의 일부입니다. 설치에 대한 자세한 내용은 Google Cloud CLI 구성요소 관리를 참조하세요. 설치한 gcloud CLI 구성요소를 보려면 다음 명령어를 실행하세요.
gcloud components list
환경 구성
프로젝트 ID 또는 클러스터 이름을 반복해서 입력하지 않으려면 다음 구성을 수행합니다.
다음과 같이 명령줄 도구를 구성합니다.
Google Cloud 프로젝트의 ID를 참조하도록 gcloud CLI를 구성합니다.
gcloud config set project PROJECT_ID
클러스터를 사용하도록
kubectlCLI를 구성합니다.kubectl config set-cluster CLUSTER_NAME
이러한 도구에 대한 자세한 내용은 다음을 참조하세요.
네임스페이스 설정
예시 애플리케이션의 일부로 만드는 리소스에 대해 NAMESPACE_NAME Kubernetes 네임스페이스를 만듭니다.
kubectl create ns NAMESPACE_NAME
관리형 컬렉션 설정
GKE 및 비GKE Kubernetes 클러스터 모두에서 관리형 컬렉션을 사용할 수 있습니다.
관리형 컬렉션이 사용 설정되면 클러스터 내 구성요소가 실행되지만 측정항목은 아직 생성되지 않습니다. PodMonitoring 또는 ClusterPodMonitoring 리소스는 측정항목 엔드포인트를 올바르게 스크래핑하는 이러한 구성요소에 필요합니다. 유효한 측정항목 엔드포인트를 사용하여 이러한 리소스를 배포하거나 GKE에 기본 제공되는 관리형 측정항목 패키지 중 하나(예: Kube 상태 측정항목)를 사용 설정해야 합니다. 문제 해결 정보는 수집 측 문제를 참조하세요.
관리형 컬렉션을 사용 설정하면 클러스터에 다음 구성요소가 설치됩니다.
gmp-operator배포: Managed Service for Prometheus의 Kubernetes 연산자 배포rule-evaluator배포: 알림 및 기록 규칙을 구성 및 실행하는 데 사용collectorDaemonSet: 각 수집기와 동일한 노드에서 실행되는 포드에서만 측정항목을 스크래핑하여 컬렉션을 수평 확장alertmanagerStatefulSet: 원하는 알림 채널로 트리거된 알림을 보내도록 구성
Managed Service for Prometheus 연산자에 대한 참고 문서는 매니페스트 페이지를 참조하세요.
관리형 컬렉션 사용 설정: GKE
관리형 컬렉션은 기본적으로 다음과 같이 사용 설정됩니다.
GKE 버전 1.25 이상 실행하는 GKE Autopilot 클러스터입니다.
GKE 버전 1.27 이상을 실행하는 GKE Standard 클러스터입니다. 이 기본값은 클러스터를 만들 때 재정의할 수 있습니다. 관리형 컬렉션 사용 중지를 참조하세요.
기본적으로 관리형 컬렉션을 사용 설정하지 않는 GKE 환경에서 실행하는 경우 수동으로 관리형 컬렉션 사용 설정을 참조하세요.
새로운 클러스터 내 구성요소 버전이 출시되면 GKE의 관리형 컬렉션이 자동으로 업그레이드됩니다.
GKE의 관리형 수집은 기본 Compute Engine 서비스 계정에 부여된 권한을 사용합니다. 기본 노드 서비스 계정에 대한 표준 권한을 수정하는 정책이 있는 경우 계속 진행하려면 Monitoring Metric Writer 역할을 추가해야 할 수 있습니다.
수동으로 관리형 컬렉션 사용 설정
기본적으로 관리형 컬렉션을 사용 설정하지 않는 GKE 환경에서 실행하는 경우 다음을 사용하여 관리형 컬렉션을 사용 설정할 수 있습니다.
- Cloud Monitoring의 관리형 Prometheus 일괄 클러스터 사용 설정 대시보드
- Google Cloud 콘솔의 Kubernetes Engine 페이지
- Google Cloud CLI gcloud CLI를 사용하려면 GKE 버전 1.21.4-gke.300 이상을 실행해야 합니다.
Google Kubernetes Engine용 Terraform Terraform을 사용하여 Prometheus에 관리형 서비스를 사용 설정하려면 GKE 버전 1.21.4-gke.300 이상을 실행해야 합니다.
관리형 Prometheus 일괄 클러스터 사용 설정 대시보드
Cloud Monitoring의 관리형 Prometheus 일괄 클러스터 사용 설정 대시보드를 사용하여 다음을 수행할 수 있습니다.
- 클러스터에 Managed Service for Prometheus가 사용 설정되어 있는지 여부와 관리형 또는 자체 배포 컬렉션을 사용하는지 여부를 확인합니다.
- 프로젝트의 클러스터에서 관리형 컬렉션을 사용 설정합니다.
- 클러스터에 대한 다른 정보를 봅니다.
관리형 Prometheus 일괄 클러스터 사용 설정 대시보드를 보려면 다음 단계를 따르세요.
-
Google Cloud 콘솔에서
 대시보드 페이지로 이동합니다.
대시보드 페이지로 이동합니다.
검색창을 사용하여 이 페이지를 찾은 경우 부제목이 Monitoring인 결과를 선택합니다.
필터 표시줄을 사용하여 관리형 Prometheus 일괄 클러스터 사용 설정 항목을 검색한 후 선택합니다.
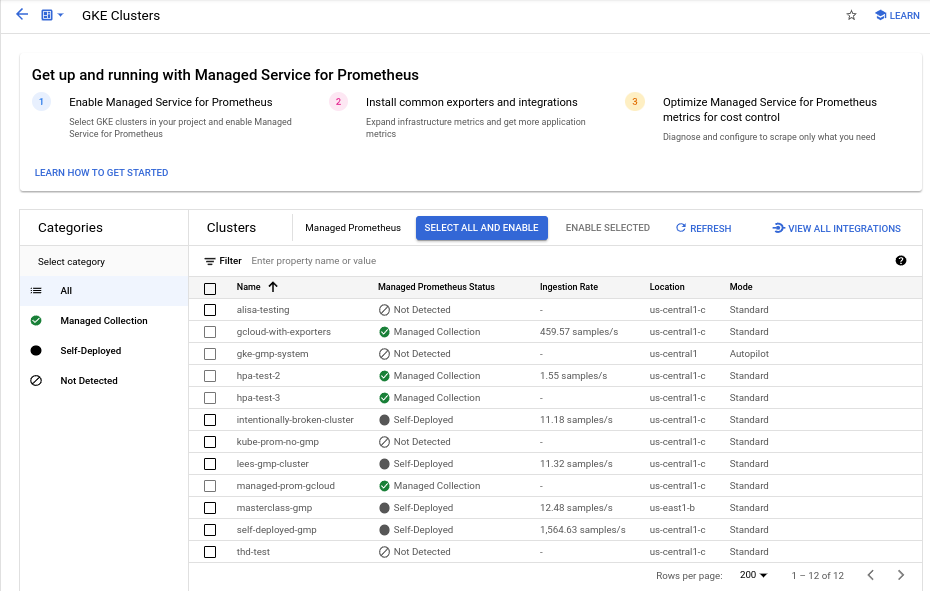
관리형 Prometheus 일괄 클러스터 사용 설정 대시보드를 사용하여 하나 이상의 GKE 클러스터에서 관리형 컬렉션을 사용 설정하려면 다음을 수행합니다.
관리형 컬렉션을 사용 설정할 각 GKE 클러스터의 체크박스를 선택합니다.
선택한 항목 사용 설정을 선택합니다.
Kubernetes Engine UI
Google Cloud 콘솔을 사용하여 다음을 수행할 수 있습니다.
- 기존 GKE 클러스터에서 관리형 컬렉션을 사용 설정합니다.
- 관리형 컬렉션이 사용 설정된 새 GKE 클러스터를 만듭니다.
기존 클러스터를 업데이트하려면 다음을 수행합니다.
-
Google Cloud 콘솔에서 Kubernetes 클러스터 페이지로 이동합니다.
검색창을 사용하여 이 페이지를 찾은 경우 부제목이 Kubernetes Engine인 결과를 선택합니다.
클러스터 이름을 클릭합니다.
기능 목록에서 Managed Service for Prometheus 옵션을 찾습니다. 사용 중지됨으로 표시되면 edit 수정을 클릭한 후 Managed Service for Prometheus 사용 설정을 선택합니다.
변경사항 저장을 클릭합니다.
관리형 컬렉션이 사용 설정된 클러스터를 만들려면 다음을 수행합니다.
-
Google Cloud 콘솔에서 Kubernetes 클러스터 페이지로 이동합니다.
검색창을 사용하여 이 페이지를 찾은 경우 부제목이 Kubernetes Engine인 결과를 선택합니다.
만들기를 클릭합니다.
표준 옵션에 대해 구성을 클릭합니다.
탐색 패널에서 기능을 클릭합니다.
작업 섹션에서 Managed Service for Prometheus 사용 설정을 선택합니다.
저장을 클릭합니다.
gcloud CLI
gcloud CLI를 사용하여 다음을 수행할 수 있습니다.
- 기존 GKE 클러스터에서 관리형 컬렉션을 사용 설정합니다.
- 관리형 컬렉션이 사용 설정된 새 GKE 클러스터를 만듭니다.
이 명령어를 완료하는 데 최대 5분이 걸릴 수 있습니다.
먼저 프로젝트를 설정합니다.
gcloud config set project PROJECT_ID
기존 클러스터를 업데이트하려면 영역별 또는 리전별 클러스터인지 여부에 따라 다음 update 명령어 중 하나를 실행합니다.
gcloud container clusters update CLUSTER_NAME --enable-managed-prometheus --zone ZONE
gcloud container clusters update CLUSTER_NAME --enable-managed-prometheus --region REGION
관리형 컬렉션이 사용 설정된 클러스터를 만들려면 다음 명령어를 실행합니다.
gcloud container clusters create CLUSTER_NAME --zone ZONE --enable-managed-prometheus
GKE Autopilot
관리형 컬렉션은 기본적으로 GKE 버전 1.25 이상을 실행하는 GKE Autopilot 클러스터에서 설정됩니다. 관리형 컬렉션은 사용 중지할 수 없습니다.
1.25로 업그레이드할 때 클러스터가 자동으로 관리형 컬렉션을 사용 설정하지 못하면 gcloud CLI 섹션에서 업데이트 명령어를 실행하여 수동으로 사용 설정할 수 있습니다.
Terraform
Terraform을 사용하여 관리형 컬렉션을 구성하는 방법은 google_container_cluster용 Terraform 레지스트리를 참조하세요.
Terraform과 함께 Google Cloud 를 사용하는 방법에 관한 일반적인 내용은 Google Cloud에서 Terraform을 참고하세요.
관리형 컬렉션 사용 중지
클러스터에서 관리형 컬렉션을 사용 중지하려면 다음 방법 중 하나를 사용합니다.
Kubernetes Engine UI
Google Cloud 콘솔을 사용하여 다음을 수행할 수 있습니다.
- 기존 GKE 클러스터에서 관리형 컬렉션을 사용 중지합니다.
- GKE 버전 1.27 이상을 실행하는 새 GKE Standard 클러스터를 만들 때 관리형 컬렉션의 자동 사용 설정을 재정의합니다.
기존 클러스터를 업데이트하려면 다음을 수행합니다.
-
Google Cloud 콘솔에서 Kubernetes 클러스터 페이지로 이동합니다.
검색창을 사용하여 이 페이지를 찾은 경우 부제목이 Kubernetes Engine인 결과를 선택합니다.
클러스터 이름을 클릭합니다.
기능 섹션에서 Managed Service for Prometheus 옵션을 찾습니다. edit 수정을 클릭하고 Managed Service for Prometheus 사용 설정을 선택 해제합니다.
변경사항 저장을 클릭합니다.
새 GKE Standard 클러스터(버전 1.27 이상)를 만들 때 관리형 컬렉션의 자동 사용 설정을 재정의하려면 다음을 수행합니다.
-
Google Cloud 콘솔에서 Kubernetes 클러스터 페이지로 이동합니다.
검색창을 사용하여 이 페이지를 찾은 경우 부제목이 Kubernetes Engine인 결과를 선택합니다.
만들기를 클릭합니다.
표준 옵션에 대해 구성을 클릭합니다.
탐색 패널에서 기능을 클릭합니다.
작업 섹션에서 Managed Service for Prometheus 사용 설정을 선택 해제합니다.
저장을 클릭합니다.
gcloud CLI
gcloud CLI를 사용하여 다음을 수행할 수 있습니다.
- 기존 GKE 클러스터에서 관리형 컬렉션을 사용 중지합니다.
- GKE 버전 1.27 이상을 실행하는 새 GKE Standard 클러스터를 만들 때 관리형 컬렉션의 자동 사용 설정을 재정의합니다.
이 명령어를 완료하는 데 최대 5분이 걸릴 수 있습니다.
먼저 프로젝트를 설정합니다.
gcloud config set project PROJECT_ID
기존 클러스터에서 관리형 컬렉션을 사용 중지하려면 클러스터가 영역 또는 리전인지 여부에 따라 다음 update 명령어 중 하나를 실행합니다.
gcloud container clusters update CLUSTER_NAME --disable-managed-prometheus --zone ZONE
gcloud container clusters update CLUSTER_NAME --disable-managed-prometheus --region REGION
새 GKE Standard 클러스터(버전 1.27 이상)를 만들 때 관리형 컬렉션의 자동 사용 설정을 재정의하려면 다음 명령어를 실행합니다.
gcloud container clusters create CLUSTER_NAME --zone ZONE --no-enable-managed-prometheus
GKE Autopilot
GKE 버전 1.25 이상을 실행하는 GKE Autopilot 클러스터에서는 관리형 컬렉션을 사용 중지할 수 없습니다.
Terraform
관리형 컬렉션을 사용 중지하려면 managed_prometheus 구성 블록의 enabled 속성을 false로 설정합니다. 이 구성 블럭에 대한 자세한 내용은 google_container_cluster용 Terraform 레지스트리를 참조하세요.
Terraform과 함께 Google Cloud 를 사용하는 방법에 관한 일반적인 내용은 Google Cloud에서 Terraform을 참고하세요.
관리형 컬렉션 사용 설정: 비GKE Kubernetes
비GKE 환경에서 실행하는 경우 다음을 사용하여 관리형 컬렉션을 사용 설정할 수 있습니다.
kubectlCLI:버전 1.12 이상을 실행하는 VMware 또는 베어메탈 온프레미스 배포
kubectl CLI
비GKE Kubernetes 클러스터를 사용할 때 관리형 수집기를 설치하려면 다음 명령어를 실행하여 설정 및 연산자 매니페스트를 설치합니다.
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/manifests/setup.yaml kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/manifests/operator.yaml
온프레미스
온프레미스 클러스터의 관리형 컬렉션 구성에 대한 자세한 내용은 배포 문서를 참고하세요.
예시 애플리케이션 배포
예시 애플리케이션은 metrics 포트에서 example_requests_total 카운터 측정항목 및 example_random_numbers 히스토그램 측정항목을 내보냅니다. 애플리케이션의 매니페스트에는 세 개의 복제본이 정의되어 있습니다.
예시 애플리케이션을 배포하려면 다음 명령어를 실행합니다.
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/example-app.yaml
PodMonitoring 리소스 구성
예시 애플리케이션이 내보내는 측정항목 데이터를 수집하려면 Managed Service for Prometheus는 대상 스크래핑을 사용합니다. 대상 스크래핑 및 측정항목 수집은 Kubernetes 커스텀 리소스를 사용하여 구성됩니다. 관리형 서비스는 PodMonitoring 커스텀 리소스(CR)를 사용합니다.
PodMonitoring CR은 CR이 배포된 네임스페이스에서만 대상을 스크래핑합니다.
여러 네임스페이스에서 대상을 스크래핑하려면 각 네임스페이스에 동일한 PodMonitoring CR을 배포합니다. kubectl get podmonitoring -A를 실행하면 PodMonitoring 리소스가 의도한 네임스페이스에 설치되었는지 확인할 수 있습니다.
모든 Managed Service for Prometheus CR에 대한 참고 문서는 prometheus-engine/doc/api 참조를 확인하세요.
다음 매니페스트는 NAMESPACE_NAME 네임스페이스에서 PodMonitoring 리소스 prom-example을 정의합니다. 이 리소스는 Kubernetes 라벨 선택기를 사용하여 네임스페이스에서 prom-example 값의 app.kubernetes.io/name 라벨이 있는 모든 포드를 찾습니다.
일치하는 포드는 /metrics HTTP 경로에서 30초 간격으로 metrics라는 포트로 스크래핑됩니다.
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: prom-example
spec:
selector:
matchLabels:
app.kubernetes.io/name: prom-example
endpoints:
- port: metrics
interval: 30s
이 리소스를 적용하려면 다음 명령어를 실행합니다.
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/pod-monitoring.yaml
관리형 수집기가 이제 일치하는 포드를 스크래핑합니다. 대상 상태 기능을 사용 설정하여 스크래핑 대상의 상태를 확인할 수 있습니다.
모든 네임스페이스의 포드 범위에 적용되는 수평 컬렉션을 구성하려면 ClusterPodMonitoring 리소스를 사용합니다. ClusterPodMonitoring 리소스는 PodMonitoring 리소스와 동일한 인터페이스를 제공하지만 검색된 포드를 지정된 네임스페이스로 제한하지 않습니다.
GKE에서 실행하는 경우 다음을 수행할 수 있습니다.
- Cloud Monitoring에서 PromQL을 사용하여 예시 애플리케이션에서 수집된 측정항목을 쿼리하려면 Cloud Monitoring을 사용하여 쿼리를 참조하세요.
- Grafana를 사용해서 예시 애플리케이션에서 수집된 측정항목을 쿼리하려면 Grafana 또는 Prometheus API 소비자를 사용하여 쿼리를 참조하세요.
- 내보낸 측정항목 필터링 및 prom-operator 리소스 조정에 대해 자세히 알아보려면 관리형 컬렉션 추가 주제를 참조하세요.
GKE 외부에서 실행하는 경우 다음 섹션의 설명에 따라 서비스 계정을 만들고 측정항목 데이터를 기록하도록 승인해야 합니다.
명시적으로 사용자 인증 정보 제공
GKE에서 실행할 경우 수집 Prometheus 서버가 노드의 서비스 계정을 기반으로 환경에서 사용자 인증 정보를 자동으로 검색합니다. 비GKE Kubernetes 클러스터에서 사용자 인증 정보는 gmp-public 네임스페이스에서 OperatorConfig 리소스를 통해 명시적으로 제공되어야 합니다.
컨텍스트를 대상 프로젝트에 설정합니다.
gcloud config set project PROJECT_ID
서비스 계정을 만듭니다.
gcloud iam service-accounts create gmp-test-sa
서비스 계정에 필요한 권한을 부여합니다.
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
서비스 계정에 대해 키를 만들고 다운로드합니다.
gcloud iam service-accounts keys create gmp-test-sa-key.json \ --iam-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
키 파일을 GKE 클러스터 외의 클러스터에 보안 비밀로 추가합니다.
kubectl -n gmp-public create secret generic gmp-test-sa \ --from-file=key.json=gmp-test-sa-key.json
수정을 위해 OperatorConfig 리소스를 엽니다.
kubectl -n gmp-public edit operatorconfig config
굵게 표시된 텍스트를 리소스에 추가합니다.
apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config collection: credentials: name: gmp-test-sa key: key.jsonrules섹션에 추가해야 합니다.파일을 저장하고 편집기를 닫습니다. 변경사항이 적용되고 포드가 다시 생성된 후 제공된 서비스 계정을 사용하여 측정항목 백엔드에 대해 인증을 시작합니다.
관리형 컬렉션 추가 주제
이 섹션에서는 다음 작업을 수행하는 방법을 설명합니다.
- 디버깅을 용이하게 하려면 대상 상태 기능을 사용 설정합니다.
- Terraform을 사용하여 대상 스크래핑을 구성합니다.
- 관리형 서비스로 내보내는 데이터를 필터링합니다.
- Kubelet 및 cAdvisor 측정항목을 스크래핑합니다.
- 기존 prom-operator 리소스를 관리형 서비스에 사용하도록 변환합니다.
- GKE 외부에서 관리형 컬렉션을 실행합니다.
대상 상태 기능 사용 설정
Managed Service for Prometheus는 수집기에서 대상을 올바르게 검색하고 스크래핑하는지 확인하는 방법을 제공합니다. 이 대상 상태 보고서는 심각한 문제를 디버그하는 도구로 사용됩니다. 즉시 문제를 조사하는 경우에만 이 기능을 사용 설정하는 것이 좋습니다. 대규모 클러스터에서 대상 상태 보고를 사용 설정하면 연산자의 메모리가 부족해지고 비정상 종료 루프가 발생할 수 있습니다.
다음과 같이 OperatorConfig 리소스 내에서
features.targetStatus.enabled값을true로 설정하여 PodMonitoring 또는 ClusterPodMonitoring 리소스에서 대상의 상태를 확인할 수 있습니다.apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config features: targetStatus: enabled: true몇 초 후 유효한 모든 PodMonitoring 또는 ClusterPodMonitoring 리소스(구성된 경우)에
Status.Endpoint Statuses필드가 나타납니다.NAMESPACE_NAME네임스페이스에 이름이prom-example인 PodMonitoring 리소스가 있으면 다음 명령어를 실행하여 상태를 확인할 수 있습니다.kubectl -n NAMESPACE_NAME describe podmonitorings/prom-example
출력은 다음과 같이 표시됩니다.
API Version: monitoring.googleapis.com/v1 Kind: PodMonitoring ... Status: Conditions: ... Status: True Type: ConfigurationCreateSuccess Endpoint Statuses: Active Targets: 3 Collectors Fraction: 1 Last Update Time: 2023-08-02T12:24:26Z Name: PodMonitoring/custom/prom-example/metrics Sample Groups: Count: 3 Sample Targets: Health: up Labels: Cluster: CLUSTER_NAME Container: prom-example Instance: prom-example-589ddf7f7f-hcnpt:metrics Job: prom-example Location: REGION Namespace: NAMESPACE_NAME Pod: prom-example-589ddf7f7f-hcnpt project_id: PROJECT_ID Last Scrape Duration Seconds: 0.020206416 Health: up Labels: ... Last Scrape Duration Seconds: 0.054189485 Health: up Labels: ... Last Scrape Duration Seconds: 0.006224887출력에는 다음 상태 필드가 포함됩니다.
- Managed Service for Prometheus에서 PodMonitoring 또는 ClusterPodMonitoring을 확인 및 처리하는 경우
Status.Conditions.Status는 true입니다. Status.Endpoint Statuses.Active Targets는 Managed Service for Prometheus가 이 PodMonitoring 리소스의 모든 수집기에서 집계하는 스크래핑 대상 수를 보여줍니다. 예시 애플리케이션에서prom-example배포에는 단일 측정항목 대상이 있는 복제본이 3개 있으므로 값은3입니다. 비정상 대상이 있으면Status.Endpoint Statuses.Unhealthy Targets필드가 표시됩니다.Status.Endpoint Statuses.Collectors Fraction은 Managed Service for Prometheus에서 모든 관리형 수집기에 연결할 수 있는 경우1값을 표시합니다(100%).Status.Endpoint Statuses.Last Update Time에는 마지막으로 업데이트된 시간이 표시됩니다. 최종 업데이트 시간이 원하는 스크래핑 간격보다 훨씬 긴 경우 그 차이는 대상 또는 클러스터에 문제가 있음을 나타낼 수 있습니다.Status.Endpoint Statuses.Sample Groups필드는 수집기에서 삽입한 일반적인 대상 라벨을 기준으로 그룹화된 샘플 대상을 보여줍니다. 이 값은 대상이 검색되지 않는 디버깅 상황에 유용합니다. 모든 대상이 정상이고 수집 중인 경우Health필드의 예상 값은up이고Last Scrape Duration Seconds필드 값은 일반적인 대상에 대한 일반적인 기간입니다.
이러한 필드에 대한 자세한 내용은 Managed Service for Prometheus API 문서를 참조하세요.
다음 중 하나라도 나타나면 구성에 문제가 있을 수 있습니다.
- PodMonitoring 리소스에
Status.Endpoint Statuses필드가 없습니다. Last Scrape Duration Seconds필드의 값이 너무 오래되었습니다.- 대상이 너무 적습니다.
Health필드의 값은 대상이down임을 나타냅니다.
대상 검색 문제 디버깅에 대한 자세한 내용은 문제 해결 문서의 수집 측 문제를 참조하세요.
승인된 스크래핑 엔드포인트 구성
스크래핑 대상에 승인이 필요하면 올바른 승인 유형을 사용하고 관련 보안 비밀을 제공하도록 수집기를 설정할 수 있습니다.
Google Cloud Managed Service for Prometheus는 다음 승인 유형을 지원합니다.
mTLS
mTLS는 일반적으로 Istio 서비스 메시 또는 Cloud Service Mesh와 같은 제로 트러스트 환경 내에서 구성됩니다.
mTLS로 보호되는 스크래핑 엔드포인트를 사용 설정하려면 PodMonitoring 리소스의
Spec.Endpoints[].Scheme필드를https로 설정합니다. 권장되지는 않지만 PodMonitoring 리소스의Spec.Endpoints[].tls.insecureSkipVerify필드를true로 설정하여 인증 기관 확인을 건너뛸 수 있습니다. 또는 Managed Service for Prometheus가 보안 비밀 리소스에서 인증서와 키를 로드하도록 구성할 수 있습니다.예를 들어 다음 보안 비밀 리소스에는 클라이언트(
cert), 비공개 키(key), 인증 기관(ca) 인증서의 키가 포함됩니다.kind: Secret metadata: name: secret-example stringData: cert: ******** key: ******** ca: ********
Managed Service for Prometheus 수집기에 해당 보안 비밀 리소스에 액세스할 수 있는 권한을 부여합니다.
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
GKE Autopilot 클러스터에서는 다음과 같이 표시됩니다.
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
이전 보안 비밀 리소스를 사용하는 PodMonitoring 리소스를 구성하려면
scheme및tls섹션이 추가되도록 리소스를 수정합니다.apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s scheme: https tls: ca: secret: name: secret-example key: ca cert: secret: name: secret-example key: cert key: secret: name: secret-example key: key모든 Managed Service for Prometheus mTLS 옵션에 대한 참고 문서는 API 참고 문서를 참조하세요.
BasicAuth
BasicAuth로 보호되는 스크래핑 엔드포인트를 사용 설정하려면 사용자 이름과 비밀번호를 사용하여 PodMonitoring 리소스에서
Spec.Endpoints[].BasicAuth필드를 설정합니다. 다른 HTTP 승인 헤더 유형은 HTTP 승인 헤더를 참조하세요.예를 들어 다음 보안 비밀 리소스에는 비밀번호를 저장하기 위한 키가 포함되어 있습니다.
kind: Secret metadata: name: secret-example stringData: password: ********
Managed Service for Prometheus 수집기에 해당 보안 비밀 리소스에 액세스할 수 있는 권한을 부여합니다.
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
GKE Autopilot 클러스터에서는 다음과 같이 표시됩니다.
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
이전 보안 비밀 리소스와
foo사용자 이름을 사용하는 PodMonitoring 리소스를 구성하려면 리소스를 수정하여basicAuth섹션을 추가합니다.apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s basicAuth: username: foo password: secret: name: secret-example key: password모든 Managed Service for Prometheus BasicAuth 옵션에 대한 참고 문서는 API 참고 문서를 참조하세요.
HTTP 승인 헤더
HTTP 승인 헤더로 보호되는 스크래핑 엔드포인트를 사용 설정하려면 유형 및 사용자 인증 정보를 사용하여 PodMonitoring 리소스에서
Spec.Endpoints[].Authorization필드를 설정합니다. BasicAuth 엔드포인트에는 대신 BasicAuth 구성을 사용합니다.예를 들어 다음 보안 비밀 리소스에는 사용자 인증 정보를 저장하기 위한 키가 포함되어 있습니다.
kind: Secret metadata: name: secret-example stringData: credentials: ********
Managed Service for Prometheus 수집기에 해당 보안 비밀 리소스에 액세스할 수 있는 권한을 부여합니다.
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
GKE Autopilot 클러스터에서는 다음과 같이 표시됩니다.
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
이전 보안 비밀 리소스와
Bearer유형을 사용하는 PodMonitoring 리소스를 구성하려면authorization섹션이 추가되도록 리소스를 수정합니다.apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s authorization: type: Bearer credentials: secret: name: secret-example key: credentials모든 Managed Service for Prometheus HTTP 승인 헤더 옵션에 대한 참고 문서는 API 참고 문서를 참조하세요.
OAuth 2
OAuth 2로 보호되는 스크래핑 엔드포인트를 사용 설정하려면 PodMonitoring 리소스에서
Spec.Endpoints[].OAuth2필드를 설정해야 합니다.예를 들어 다음 보안 비밀 리소스에는 클라이언트 보안 비밀번호를 저장하기 위한 키가 포함되어 있습니다.
kind: Secret metadata: name: secret-example stringData: clientSecret: ********
Managed Service for Prometheus 수집기에 해당 보안 비밀 리소스에 액세스할 수 있는 권한을 부여합니다.
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
GKE Autopilot 클러스터에서는 다음과 같이 표시됩니다.
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
클라이언트 ID가
foo이고 토큰 URL이example.com/token인 이전 보안 비밀 리소스를 사용하는 PodMonitoring 리소스를 구성하려면 리소스를 수정하여oauth2섹션을 추가합니다.apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s oauth2: clientID: foo clientSecret: secret: name: secret-example key: password tokenURL: example.com/token모든 Managed Service for Prometheus OAuth 2 옵션에 대한 참고 문서는 API 참고 문서를 참조하세요.
Terraform을 사용하여 대상 스크레이핑 구성
임의 커스텀 리소스를 지정할 수 있는
kubernetes_manifestTerraform 리소스 유형이나kubectl_manifestTerraform 리소스 유형을 사용하여 PodMonitoring, ClusterPodMonitoring 리소스를 자동으로 만들고 관리할 수 있습니다.Terraform과 함께 Google Cloud 를 사용하는 방법에 관한 일반적인 내용은 Google Cloud에서 Terraform을 참고하세요.
내보낸 측정항목 필터링
많은 데이터를 수집하는 경우 비용 절감을 위해 일부 시계열이 Managed Service for Prometheus에 전송되지 않도록 방지해야 할 수 있습니다. 허용 목록에
keep작업을, 차단 목록에drop작업을 사용하여 Prometheus 라벨 재지정 규칙을 사용하면 됩니다. 관리형 컬렉션의 경우 이 규칙은 PodMonitoring 또는 ClusterPodMonitoring 리소스의metricRelabeling섹션에서 다룹니다.예를 들어 다음 측정항목 라벨 재지정 규칙은
foo_bar_,foo_baz_,foo_qux_로 시작하는 모든 측정항목을 필터링합니다.metricRelabeling: - action: drop regex: foo_(bar|baz|qux)_.+ sourceLabels: [__name__]Cloud Monitoring 측정항목 관리 페이지에서는 모니터링 가능성에 영향을 주지 않고 청구 가능 측정항목에 지출하는 금액을 제어할 수 있는 정보를 제공합니다. 측정항목 관리 페이지에서는 다음 정보를 보고합니다.
- 측정항목 도메인 및 개별 측정항목의 바이트 기반 및 샘플 기반 청구에 대한 수집량
- 측정항목의 라벨 및 카디널리티에 대한 데이터
- 각 측정항목의 읽기 수
- 알림 정책 및 커스텀 대시보드의 측정항목 사용
- 측정항목 쓰기 오류의 비율
또한 측정항목 관리 페이지를 사용하면 불필요한 측정항목을 제외하여 수집 비용을 절감할 수 있습니다. 측정항목 관리 페이지에 대한 자세한 내용은 측정항목 사용량 보기 및 관리를 참조하세요.
비용을 절감하는 방법에 대한 추가 제안사항은 비용 관리 및 기여 분석을 참조하세요.
Kubelet 및 cAdvisor 측정항목 스크래핑
Kubelet은 자체에 대한 측정항목과 해당 노드에서 실행 중인 컨테이너에 대한 cAdvisor 측정항목을 노출합니다. OperatorConfig 리소스를 수정하여 Kubelet 및 cAdvisor 측정항목을 스크래핑하는 관리형 컬렉션을 구성할 수 있습니다. 자세한 내용은 Kubelet 및 cAdvisor의 내보내기 도구 문서를 참조하세요.
기존 prometheus-operator 리소스 변환
일반적으로 기존 prometheus-operator 리소스를 Prometheus 관리형 컬렉션 PodMonitoring 및 ClusterPodMonitoring 리소스용 관리형 서비스로 변환할 수 있습니다.
예를 들어 ServiceMonitor 리소스는 서비스 집합에 대해 모니터링을 정의합니다. PodMonitoring 리소스는 ServiceMonitor 리소스로 제공되는 필드의 하위 집합을 제공합니다. 다음 테이블에 설명된 대로 필드를 매핑하여 ServiceMonitor CR을 PodMonitoring CR로 변환할 수 있습니다.
monitoring.coreos.com/v1
ServiceMonitor호환성
monitoring.googleapis.com/v1
PodMonitoring.ServiceMonitorSpec.Selector동일 .PodMonitoringSpec.Selector.ServiceMonitorSpec.Endpoints[].TargetPort가.Port에 매핑됨
.Path: 호환 가능
.Interval: 호환 가능
.Timeout: 호환 가능.PodMonitoringSpec.Endpoints[].ServiceMonitorSpec.TargetLabelsPodMonitor가 다음을 지정해야 함:
.FromPod[].From포드 라벨
.FromPod[].To대상 라벨.PodMonitoringSpec.TargetLabels다음은 샘플 ServiceMonitor CR입니다. 굵게 표시된 콘텐츠는 변환 중에 대체되고, 기울임꼴 콘텐츠는 직접 매핑됩니다.
apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: example-app spec: selector: matchLabels: app: example-app endpoints: - targetPort: web path: /stats interval: 30s targetLabels: - foo다음은 서비스 및 포드가
app=example-app으로 라벨 지정되었다고 가정할 때 PodMonitoring CR과 동일합니다. 이 가정이 적용되지 않는 경우에는 기본 서비스 리소스의 라벨 선택기를 사용해야 합니다.굵게 표시된 콘텐츠는 변환 중에 대체되었습니다.
apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: example-app spec: selector: matchLabels: app: example-app endpoints: - port: web path: /stats interval: 30s targetLabels: fromPod: - from: foo # pod label from example-app Service pods. to: foo관리형 수집기 대신 자체 배포 수집기를 사용하여 언제든지 기존 prometheus-operator 리소스와 배포 구성을 계속 사용할 수 있습니다. 두 수집기 유형 모두에서 전송되는 측정항목을 쿼리할 수 있으므로, 기존 Prometheus 배포에 자체 배포 수집기를 사용하면서 새 Prometheus 배포에는 관리형 수집기를 사용할 수 있습니다.
예약된 라벨
Managed Service for Prometheus는 자동으로 다음 라벨을 수집된 모든 측정항목에 추가합니다. 다음 라벨은 Monarch에서 리소스를 고유하게 식별하는 데 사용됩니다.
project_id: 측정항목과 연결된 Google Cloud 프로젝트의 식별자location: 데이터가 저장되는 물리적 위치(Google Cloud 리전). 이 값은 일반적으로 GKE 클러스터 리전입니다. 데이터가 AWS 또는 온프레미스 배포에서 수집되는 경우 값이 가장 가까운 Google Cloud 리전일 수 있습니다.cluster: 측정항목과 연결된 Kubernetes 클러스터의 이름입니다.namespace: 측정항목과 연결된 Kubernetes 네임스페이스의 이름입니다.job: Prometheus 대상의 작업 라벨입니다(알려진 경우). 규칙 평가 결과의 경우 비어 있을 수 있습니다.instance: Prometheus 대상의 인스턴스 라벨입니다(알려진 경우). 규칙 평가 결과의 경우 비어 있을 수 있습니다.
Google Kubernetes Engine에서 실행할 때는 권장되지 않지만
project_id,location,cluster라벨을operator.yaml내 배포 리소스에args로 추가하여 재정의할 수 있습니다. 예약된 라벨을 측정항목 라벨로 사용하면 프리픽스exported_를 추가하여 Managed Service for Prometheus에서 자동으로 라벨을 다시 지정합니다. 이 동작은 업스트림 Prometheus가 예약된 라벨과 충돌을 처리하는 방법과 일치합니다.구성 압축
PodMonitoring 리소스가 많으면 ConfigMap 공간이 부족해질 수 있습니다. 이 문제를 해결하려면 OperatorConfig 리소스에서
gzip압축을 사용 설정합니다.apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config features: config: compression: gzip관리형 컬렉션에 수직형 포드 자동 확장(VPA) 사용 설정
클러스터의 수집기 포드에 메모리 부족(OOM) 오류가 발생하거나 수집기의 기본 리소스 요청 및 제한이 요구사항을 충족하지 않는 경우 수직형 포드 자동 확장을 사용하여 리소스를 동적으로 할당할 수 있습니다.
OperatorConfig리소스에scaling.vpa.enabled: true필드를 설정하면 연산자가 클러스터에VerticalPodAutoscaler매니페스트를 배포하여 사용량에 따라 수집기 포드의 리소스 요청 및 한도를 자동으로 설정할 수 있습니다.Managed Service for Prometheus의 수집기 포드에 VPA를 사용 설정하려면 다음 명령어를 실행합니다.
kubectl -n gmp-public patch operatorconfig/config -p '{"scaling":{"vpa":{"enabled":true}}}' --type=merge명령어가 성공적으로 완료되면 연산자가 수집기 포드의 수직형 포드 자동 확장을 설정합니다. 메모리 부족 오류가 발생하면 리소스 한도가 즉시 증가합니다. OOM 오류가 없으면 일반적으로 24시간 이내에 수집기 포드의 리소스 요청 및 제한에 대한 첫 번째 조정이 이루어집니다.
VPA를 사용 설정하려고 할 때 다음 오류가 발생할 수 있습니다.
vertical pod autoscaling is not available - install vpa support and restart the operator이 오류를 해결하려면 먼저 클러스터 수준에서 수직형 포드 자동 확장을 사용 설정해야 합니다.
Google Cloud 콘솔에서 Kubernetes Engine - 클러스터 페이지로 이동합니다.
Google Cloud 콘솔에서 Kubernetes 클러스터 페이지로 이동합니다.
검색창을 사용하여 이 페이지를 찾은 경우 부제목이 Kubernetes Engine인 결과를 선택합니다.
수정하려는 클러스터를 선택합니다.
자동화 섹션에서 수직형 포드 자동 확장 옵션의 값을 수정합니다.
수직형 포드 자동 확장 사용 설정 체크박스를 선택한 다음 변경사항 저장을 클릭합니다. 이 변경으로 클러스터가 다시 시작됩니다. 이 프로세스의 일환으로 연산자가 다시 시작됩니다.
Managed Service for Prometheus에 VPA를 사용 설정하려면
kubectl -n gmp-public patch operatorconfig/config -p '{"scaling":{"vpa":{"enabled":true}}}' --type=merge명령어를 다시 시도합니다.
OperatorConfig리소스가 수정되었는지 확인하려면kubectl -n gmp-public edit operatorconfig config명령어를 사용하여 엽니다. 성공하면OperatorConfig에 다음 섹션이 굵게 표시됩니다.apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config scaling: vpa: enabled: true클러스터 수준에서 수직형 포드 자동 확장을 이미 사용 설정했는데도
vertical pod autoscaling is not available - install vpa support and restart the operator오류가 계속 표시되면gmp-operator포드에서 클러스터 구성을 다시 평가해야 할 수 있습니다. Standard 클러스터를 실행하는 경우 다음 명령어를 실행하여 포드를 다시 만듭니다.kubectl -n gmp-system rollout restart deployment/gmp-operator
gmp-operator포드가 다시 시작되면 위의 단계에 따라OperatorConfig를 다시 패치합니다.Autopilot 클러스터를 실행하는 경우 지원팀에 문의하여 클러스터 재시작에 대한 도움을 받으세요.
수직형 포드 자동 확장은 노드 간에 균등하게 분할된 일정한 수의 샘플을 수집할 때 가장 효과적입니다. 측정항목 부하가 불규칙하거나 급증하는 경우 또는 노드 간에 측정항목 부하가 크게 달라지는 경우에는 VPA가 효율적인 솔루션이 아닐 수 있습니다.
자세한 내용은 GKE의 수직형 포드 자동 확장을 참조하세요.
중앙에서 측정항목을 보고하는 statsd_exporter 및 기타 내보내기 도구 구성
Prometheus용 statsd_exporter, Istio용 Envoy, SNMP 내보내기 도구, Prometheus Pushgateway, kube-state-metrics를 사용하거나 환경에서 실행 중인 다른 리소스를 대신하여 측정항목을 중간화하고 보고하는 유사한 내보내기 도구가 있는 경우, Managed Service for Prometheus에서 작동하도록 내보내기 도구를 약간 변경해야 합니다.
이러한 내보내기 도구를 구성하는 방법은 문제 해결 섹션의 이 참고사항을 참조하세요.
해체
gcloud또는 GKE를 사용하여 배포된 관리형 수집 사용 중지하려면 다음 중 하나를 수행하면 됩니다.다음 명령어를 실행합니다.
gcloud container clusters update CLUSTER_NAME --disable-managed-prometheus
GKE UI를 사용합니다.
Google Cloud 콘솔에서 Kubernetes Engine을 선택한 후 클러스터를 선택합니다.
관리형 컬렉션을 사용 중지하려는 클러스터를 찾아 이름을 클릭합니다.
세부정보 탭에서 기능까지 아래로 스크롤하고 수정 버튼을 사용하여 상태를 사용 중지됨으로 상태를 변경합니다.
Terraform을 사용하여 배포된 관리형 컬렉션을 사용 중지하려면
google_container_cluster리소스의managed_prometheus섹션에서enabled = false를 지정합니다.kubectl를 사용하여 배포된 관리형 컬렉션을 사용 중지하려면 다음 명령어를 실행합니다.kubectl delete -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/manifests/operator.yaml
관리형 컬렉션을 중지하면 클러스터가 Managed Service for Prometheus로 새 데이터를 전송하지 않습니다. 이 작업을 수행해도 시스템에 이미 저장된 기존 측정항목 데이터는 삭제되지 않습니다.
관리형 컬렉션을 중지하면
gmp-public네임스페이스와 이 네임스페이스에 설치된 내보내기 도구를 포함한 내부의 모든 리소스도 삭제됩니다.GKE 외부에서 관리형 컬렉션 실행
GKE 환경에서는 추가 구성 없이 관리형 컬렉션을 실행할 수 있습니다. 다른 Kubernetes 환경에서는 사용자 인증 정보, 측정항목을 포함할
project-id값, 측정항목을 저장할location값(Google Cloud 리전), 수집기가 실행 중인 클러스터의 이름을 저장할cluster값을 명시적으로 제공해야 합니다.gcloud는 Google Cloud 환경 외부에서 작동하지 않으므로 대신 kubectl을 사용하여 배포해야 합니다.gcloud와 달리kubectl을 사용하여 관리형 컬렉션을 배포하면 새 버전을 사용할 수 있을 때 클러스터가 자동으로 업그레이드되지 않습니다. 출시 페이지에서 새 버전을 확인하고kubectl명령어를 새 버전으로 다시 실행하여 수동으로 업그레이드하세요.명시적으로 사용자 인증 정보 제공에 설명된 대로
operator.yaml내에서 OperatorConfig 리소스를 수정하여 서비스 계정 키를 제공할 수 있습니다.project-id,location,cluster값을operator.yaml내의 배포 리소스에args로 추가하여 제공할 수 있습니다.읽기의 경우 계획된 테넌시 모델을 기준으로
project-id를 선택하는 것이 좋습니다. 측정항목 범위를 통해 나중에 읽기를 구성할 방법에 따라 측정항목을 저장할 프로젝트를 선택합니다. 문제되지 않으면 모든 것을 한 프로젝트에 넣을 수 있습니다.location의 경우 배포와 가장 가까운 Google Cloud 리전을 선택하는 것이 좋습니다. 선택한 Google Cloud 리전이 배포에서 멀수록 쓰기 지연 시간이 늘어나고 잠재적으로 네트워킹 문제가 발생할 가능성이 높아집니다. 자세한 내용은 여러 클라우드 간 리전 목록을 참조하세요. 중요하지 않으면 모든 것을 한 Google Cloud 리전에 넣을 수 있습니다.global을 위치로 사용할 수 없습니다.cluster에는 연산자가 배포된 클러스터의 이름을 선택하는 것이 좋습니다.제대로 구성되면 OperatorConfig는 다음과 같은 형태입니다.
apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config collection: credentials: name: gmp-test-sa key: key.json rules: credentials: name: gmp-test-sa key: key.json배포 리소스는 다음과 같은 형태입니다.
apiVersion: apps/v1 kind: Deployment ... spec: ... template: ... spec: ... containers: - name: operator ... args: - ... - "--project-id=PROJECT_ID" - "--cluster=CLUSTER_NAME" - "--location=REGION"이 예시에서는
us-central1와 같은 값으로REGION변수를 설정했다고 가정합니다.Google Cloud 외부에서 Managed Service for Prometheus를 실행하면 데이터 전송 요금이 발생합니다. Google Cloud에 데이터를 전송하기 위한 요금이 있고, 다른 클라우드 외부로 데이터를 전송하는 데 요금이 발생할 수 있습니다. OperatorConfig를 통해 전송 중 gzip 압축을 사용 설정하면 이러한 비용을 최소화할 수 있습니다. 굵게 표시된 텍스트를 리소스에 추가합니다.
apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config collection: compression: gzip ...관리형 수집 커스텀 리소스 추가 읽기
모든 Managed Service for Prometheus 커스텀 리소스에 대한 참고 문서는 prometheus-engine/doc/api 참조를 확인하세요.
다음 단계