Este documento descreve como configurar o Google Cloud Managed Service for Prometheus com a recolha gerida. A configuração é um exemplo mínimo de carregamento funcional, que usa uma implementação do Prometheus que monitoriza uma aplicação de exemplo e armazena as métricas recolhidas no Monarch.
Este documento mostra como fazer o seguinte:
- Configure o seu ambiente e ferramentas de linha de comandos.
- Configure a recolha gerida para o seu cluster.
- Configure um recurso para a extração de alvos e a carregamento de métricas.
- Migre recursos personalizados do prometheus-operator existentes.
Recomendamos que use a recolha gerida, pois reduz a complexidade da implementação, do dimensionamento, da divisão, da configuração e da manutenção dos coletores. A recolha gerida é suportada para o GKE e todos os outros ambientes do Kubernetes.
A recolha gerida executa coletores baseados no Prometheus como um Daemonset e garante a escalabilidade apenas ao extrair dados de alvos em nós colocados. Configura os coletores com recursos personalizados simples para extrair exportadores através da recolha por obtenção. Em seguida, os coletores enviam os dados extraídos para o repositório de dados central Monarch. O Google Cloud nunca acede diretamente ao seu cluster para obter ou extrair dados de métricas. Os seus coletores enviam dados para Google Cloud. Para mais informações sobre a recolha de dados gerida e implementada automaticamente, consulte os artigos Recolha de dados com o Managed Service for Prometheus e Carregamento e consulta com a recolha gerida e implementada automaticamente.
Antes de começar
Esta secção descreve a configuração necessária para as tarefas descritas neste documento.
Configure projetos e ferramentas
Para usar o serviço gerido do Google Cloud para Prometheus, precisa dos seguintes recursos:
Um Google Cloud projeto com a API Cloud Monitoring ativada.
Se não tiver um Google Cloud projeto, faça o seguinte:
Na Google Cloud consola, aceda a Novo projeto:
No campo Nome do projeto, introduza um nome para o projeto e, de seguida, clique em Criar.
Aceda a Faturação:
Selecione o projeto que acabou de criar, se ainda não estiver selecionado na parte superior da página.
É-lhe pedido que escolha um perfil de pagamentos existente ou que crie um novo.
A API Monitoring está ativada por predefinição para novos projetos.
Se já tiver um Google Cloud projeto, certifique-se de que a API Monitoring está ativada:
Aceda a APIs e serviços:
Selecione o seu projeto.
Clique em Ativar APIs e serviços.
Pesquise "Monitorização".
Nos resultados da pesquisa, clique em "API Cloud Monitoring".
Se não for apresentado "API ativada", clique no botão Ativar.
Um cluster do Kubernetes. Se não tiver um cluster do Kubernetes, siga as instruções no guia de início rápido do GKE.
Também precisa das seguintes ferramentas de linha de comandos:
gcloudkubectl
As ferramentas gcloud e kubectl fazem parte da
CLI gcloud do Google Cloud. Para obter informações sobre a instalação
destes componentes, consulte o artigo Faça a gestão dos componentes da CLI gcloud. Para ver os componentes da CLI gcloud que instalou, execute o seguinte comando:
gcloud components list
Configure o seu ambiente
Para evitar introduzir repetidamente o ID do projeto ou o nome do cluster, faça a seguinte configuração:
Configure as ferramentas de linha de comandos da seguinte forma:
Configure a CLI gcloud para fazer referência ao ID do seu Google Cloud projeto:
gcloud config set project PROJECT_ID
Configure a CLI
kubectlpara usar o seu cluster:kubectl config set-cluster CLUSTER_NAME
Para mais informações sobre estas ferramentas, consulte o seguinte:
Configure um espaço de nomes
Crie o espaço de nomes do Kubernetes NAMESPACE_NAME para os recursos que criar
como parte da aplicação de exemplo:
kubectl create ns NAMESPACE_NAME
Configure a recolha gerida
Pode usar a recolha gerida em clusters do Kubernetes do GKE e não pertencentes ao GKE.
Depois de a recolha gerida ser ativada, os componentes no cluster são executados, mas ainda não são geradas métricas. Os recursos PodMonitoring ou ClusterPodMonitoring são necessários por estes componentes para extrair corretamente os pontos finais de métricas. Tem de implementar estes recursos com pontos finais de métricas válidos ou ativar um dos pacotes de métricas geridas, por exemplo, as métricas de estado do Kube, incorporadas no GKE. Para informações de resolução de problemas, consulte a secção Problemas do lado do carregamento.
A ativação da recolha gerida instala os seguintes componentes no cluster:
- A implementação
gmp-operator, que implementa o operador do Kubernetes para o Managed Service for Prometheus. - A implementação
rule-evaluator, que é usada para configurar e executar regras de alerta e gravação. - O
collectorDaemonSet, que dimensiona horizontalmente a recolha através da extração de métricas apenas de pods em execução no mesmo nó que cada coletor. - O
alertmanagerStatefulSet, que está configurado para enviar alertas acionados para os seus canais de notificação preferidos.
Para consultar a documentação de referência sobre o operador do Managed Service for Prometheus, consulte a página de manifestos.
Ative a recolha gerida: GKE
A recolha gerida está ativada por predefinição para o seguinte:
Clusters do GKE Autopilot com a versão 1.25 ou superior do GKE.
Clusters GKE Standard com a versão 1.27 ou superior do GKE. Pode substituir esta predefinição quando criar o cluster. Consulte o artigo Desative a recolha gerida.
Se estiver a executar num ambiente do GKE que não ative a recolha gerida por predefinição, consulte o artigo Ative a recolha gerida manualmente.
A recolha gerida no GKE é atualizada automaticamente quando são lançadas novas versões de componentes no cluster.
A recolha gerida no GKE usa as autorizações concedidas à conta de serviço do Compute Engine predefinida. Se tiver uma política que modifique as autorizações padrão na conta de serviço do nó predefinida, pode ter de adicionar a função Monitoring Metric Writer para continuar.
Ative a recolha gerida manualmente
Se estiver a executar num ambiente do GKE que não ative a recolha gerida por predefinição, pode ativar a recolha gerida através do seguinte:
- O painel de controlo Managed Prometheus Bulk Cluster Enablement no Cloud Monitoring.
- A página Kubernetes Engine na Google Cloud consola.
- A CLI do Google Cloud. Para usar a CLI gcloud, tem de estar a executar a versão 1.21.4-gke.300 ou mais recente do GKE.
Terraform para o Google Kubernetes Engine. Para usar o Terraform para ativar o Managed Service for Prometheus, tem de estar a executar a versão 1.21.4-gke.300 ou mais recente do GKE.
Painel de controlo de ativação de clusters em massa do Managed Prometheus
Pode fazer o seguinte através do painel de controlo Ativação em massa do Prometheus gerido no Cloud Monitoring.
- Determine se o Managed Service for Prometheus está ativado nos seus clusters e se está a usar a recolha gerida ou implementada automaticamente.
- Ative a recolha gerida em clusters no seu projeto.
- Veja outras informações sobre os seus clusters.
Para ver o painel de controlo Ativação em massa de clusters do Prometheus gerido, faça o seguinte:
-
Na Google Cloud consola, aceda à página
 Painéis de controlo:
Painéis de controlo:
Se usar a barra de pesquisa para encontrar esta página, selecione o resultado cujo subtítulo é Monitorização.
Use a barra de filtros para pesquisar a entrada Managed Prometheus Bulk Cluster Enablement e, de seguida, selecione-a.
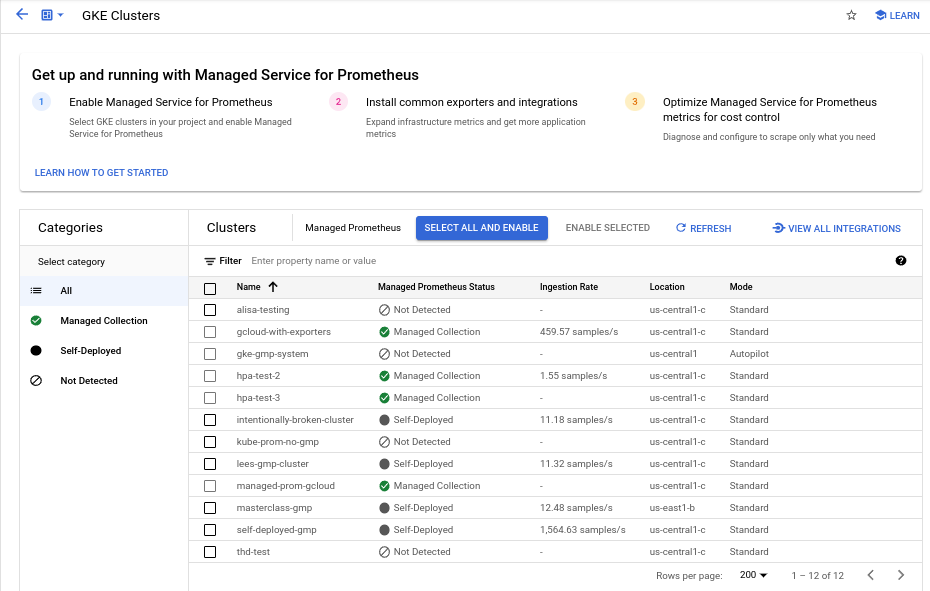
Para ativar a recolha gerida num ou mais clusters do GKE através do painel de controlo Ativação em massa de clusters do Prometheus gerido, faça o seguinte:
Selecione a caixa de verificação de cada cluster do GKE no qual quer ativar a recolha gerida.
Selecione Ativar selecionado.
IU do Kubernetes Engine
Pode fazer o seguinte através da Google Cloud consola:
- Ative a recolha gerida num cluster do GKE existente.
- Crie um novo cluster do GKE com a recolha gerida ativada.
Para atualizar um cluster existente, faça o seguinte:
-
Na Google Cloud consola, aceda à página Clusters do Kubernetes:
Aceda a Clusters do Kubernetes
Se usar a barra de pesquisa para encontrar esta página, selecione o resultado cujo subtítulo é Kubernetes Engine.
Clique no nome do cluster.
Na lista Funcionalidades, localize a opção Serviço gerido para Prometheus. Se estiver listado como desativado, clique em edit Editar, e, de seguida, selecione Ativar serviço gerido para Prometheus.
Clique em Guardar alterações.
Para criar um cluster com a recolha gerida ativada, faça o seguinte:
-
Na Google Cloud consola, aceda à página Clusters do Kubernetes:
Aceda a Clusters do Kubernetes
Se usar a barra de pesquisa para encontrar esta página, selecione o resultado cujo subtítulo é Kubernetes Engine.
Clique em Criar.
Clique em Configurar para a opção Padrão.
No painel de navegação, clique em Funcionalidades.
Na secção Operações, selecione Ativar serviço gerido para o Prometheus.
Clique em Guardar.
CLI gcloud
Pode fazer o seguinte através da gcloud CLI:
- Ative a recolha gerida num cluster do GKE existente.
- Crie um novo cluster do GKE com a recolha gerida ativada.
Estes comandos podem demorar até 5 minutos a serem concluídos.
Primeiro, defina o projeto:
gcloud config set project PROJECT_ID
Para atualizar um cluster existente, execute um dos seguintes comandos update com base no facto de o cluster ser zonal ou regional:
gcloud container clusters update CLUSTER_NAME --enable-managed-prometheus --zone ZONE
gcloud container clusters update CLUSTER_NAME --enable-managed-prometheus --region REGION
Para criar um cluster com a recolha gerida ativada, execute o seguinte comando:
gcloud container clusters create CLUSTER_NAME --zone ZONE --enable-managed-prometheus
GKE Autopilot
A recolha gerida está ativada por predefinição em clusters do GKE Autopilot com a versão 1.25 ou superior do GKE. Não pode desativar a recolha gerida.
Se o cluster não conseguir ativar a recolha gerida automaticamente quando fizer a atualização para a versão 1.25, pode ativá-la manualmente executando o comando de atualização na secção da CLI gcloud.
Terraform
Para obter instruções sobre como configurar a recolha gerida através do Terraform, consulte o
registo do Terraform para o google_container_cluster.
Para informações gerais sobre a utilização do Google Cloud com o Terraform, consulte Terraform com o Google Cloud.
Desative a recolha gerida
Se quiser desativar a recolha gerida nos seus clusters, pode usar um dos seguintes métodos:
IU do Kubernetes Engine
Pode fazer o seguinte através da Google Cloud consola:
- Desative a recolha gerida num cluster do GKE existente.
- Substitua a ativação automática da recolha gerida quando criar um novo cluster padrão do GKE com a versão 1.27 ou superior do GKE.
Para atualizar um cluster existente, faça o seguinte:
-
Na Google Cloud consola, aceda à página Clusters do Kubernetes:
Aceda a Clusters do Kubernetes
Se usar a barra de pesquisa para encontrar esta página, selecione o resultado cujo subtítulo é Kubernetes Engine.
Clique no nome do cluster.
Na secção Funcionalidades, localize a opção Serviço gerido para Prometheus. Clique em edit Editar e desmarque a opção Ativar o serviço gerido para o Prometheus.
Clique em Guardar alterações.
Para substituir a ativação automática da recolha gerida ao criar um novo cluster padrão do GKE (versão 1.27 ou superior), faça o seguinte:
-
Na Google Cloud consola, aceda à página Clusters do Kubernetes:
Aceda a Clusters do Kubernetes
Se usar a barra de pesquisa para encontrar esta página, selecione o resultado cujo subtítulo é Kubernetes Engine.
Clique em Criar.
Clique em Configurar para a opção Padrão.
No painel de navegação, clique em Funcionalidades.
Na secção Operações, desmarque a opção Ativar serviço gerido para o Prometheus.
Clique em Guardar.
CLI gcloud
Pode fazer o seguinte através da gcloud CLI:
- Desative a recolha gerida num cluster do GKE existente.
- Substitua a ativação automática da recolha gerida quando criar um novo cluster padrão do GKE com a versão 1.27 ou superior do GKE.
Estes comandos podem demorar até 5 minutos a serem concluídos.
Primeiro, defina o projeto:
gcloud config set project PROJECT_ID
Para desativar a recolha gerida num cluster existente, execute um dos seguintes comandos update com base no facto de o cluster ser zonal ou regional:
gcloud container clusters update CLUSTER_NAME --disable-managed-prometheus --zone ZONE
gcloud container clusters update CLUSTER_NAME --disable-managed-prometheus --region REGION
Para substituir a ativação automática da recolha gerida quando cria um novo cluster padrão do GKE (versão 1.27 ou superior), execute o seguinte comando:
gcloud container clusters create CLUSTER_NAME --zone ZONE --no-enable-managed-prometheus
GKE Autopilot
Não pode desativar a recolha gerida em clusters do GKE Autopilot com a versão 1.25 ou superior do GKE.
Terraform
Para desativar a recolha gerida, defina o atributo enabled no bloco de configuração managed_prometheus como false. Para mais informações
acerca deste bloco de configuração, consulte o
registo do Terraform para google_container_cluster.
Para informações gerais sobre a utilização do Google Cloud com o Terraform, consulte Terraform com o Google Cloud.
Ative a recolha gerida: Kubernetes não GKE
Se estiver a executar num ambiente não GKE, pode ativar a recolha gerida através do seguinte:
- A CLI
kubectl. Implementações no local do VMware ou bare metal com a versão 1.12 ou mais recente.
kubectl CLI
Para instalar coletores geridos quando estiver a usar um cluster Kubernetes não GKE, execute os seguintes comandos para instalar os manifestos de configuração e do operador:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/manifests/setup.yaml kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/manifests/operator.yaml
Nas instalações
Para obter informações sobre a configuração da recolha gerida para clusters no local, consulte a documentação da sua distribuição:
Implemente a aplicação de exemplo
A aplicação de exemplo emite a métrica de contador example_requests_total e a métrica de histograma example_random_numbers (entre outras) na porta metrics. O manifesto para a aplicação define três réplicas.
Para implementar a aplicação de exemplo, execute o seguinte comando:
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/example-app.yaml
Configure um recurso PodMonitoring
Para carregar os dados de métricas emitidos pela aplicação de exemplo, o Managed Service for Prometheus usa a extração de destinos. A extração de dados e a ingestão de métricas de destino são configuradas através de recursos personalizados do Kubernetes. O serviço gerido usa recursos personalizados (CRs) do PodMonitoring.
Um CR PodMonitoring extrai alvos apenas no espaço de nomes em que o CR está implementado.
Para extrair alvos em vários espaços de nomes, implemente o mesmo CR PodMonitoring em cada espaço de nomes. Pode verificar se o recurso PodMonitoring está instalado no espaço de nomes pretendido executando kubectl get podmonitoring -A.
Para ver a documentação de referência sobre todos os CRs do Managed Service for Prometheus, consulte a referência da API prometheus-engine/doc/api.
O seguinte manifesto define um recurso PodMonitoring,
prom-example, no espaço de nomes NAMESPACE_NAME. O recurso usa um seletor de etiquetas do Kubernetes para encontrar todos os pods no espaço de nomes que têm a etiqueta app.kubernetes.io/name com o valor prom-example.
Os pods correspondentes são extraídos numa porta denominada metrics, a cada 30 segundos, no caminho HTTP /metrics.
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: prom-example
spec:
selector:
matchLabels:
app.kubernetes.io/name: prom-example
endpoints:
- port: metrics
interval: 30s
Para aplicar este recurso, execute o seguinte comando:
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/pod-monitoring.yaml
O seu coletor gerido está agora a extrair os pods correspondentes. Pode ver o estado do seu alvo de extração de dados ativando a funcionalidade de estado do alvo.
Para configurar a recolha horizontal que se aplica a um intervalo de pods em todos os espaços de nomes, use o recurso ClusterPodMonitoring. O recurso ClusterPodMonitoring fornece a mesma interface que o recurso PodMonitoring, mas não limita os pods descobertos a um determinado espaço de nomes.
Se estiver a usar o GKE, pode fazer o seguinte:
- Para consultar as métricas carregadas pela aplicação de exemplo através do PromQL no Cloud Monitoring, consulte o artigo Consultar através do Cloud Monitoring.
- Para consultar as métricas carregadas pela aplicação de exemplo através do Grafana, consulte o artigo Consultar através do Grafana ou de qualquer consumidor da API Prometheus.
- Para saber como filtrar métricas exportadas e adaptar os recursos do operador prom, consulte Tópicos adicionais para a recolha gerida.
Se estiver a executar fora do GKE, tem de criar uma conta de serviço e autorizá-la a escrever os dados das métricas, conforme descrito na secção seguinte.
Forneça credenciais explicitamente
Quando executado no GKE, o servidor Prometheus de recolha obtém automaticamente as credenciais do ambiente com base na conta de serviço do nó. Em clusters Kubernetes não GKE, as credenciais têm de ser fornecidas explicitamente através do recurso OperatorConfig no espaço de nomes gmp-public.
Defina o contexto para o projeto de destino:
gcloud config set project PROJECT_ID
Crie uma conta de serviço:
gcloud iam service-accounts create gmp-test-sa
Conceda as autorizações necessárias à conta de serviço:
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
Crie e transfira uma chave para a conta de serviço:
gcloud iam service-accounts keys create gmp-test-sa-key.json \ --iam-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
Adicione o ficheiro de chave como um segredo ao seu cluster não GKE:
kubectl -n gmp-public create secret generic gmp-test-sa \ --from-file=key.json=gmp-test-sa-key.json
Abra o recurso OperatorConfig para edição:
kubectl -n gmp-public edit operatorconfig config
Adicione o texto apresentado em negrito ao recurso:
apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config collection: credentials: name: gmp-test-sa key: key.jsonrulessecção para que a avaliação de regras geridas funcione.Guarde o ficheiro e feche o editor. Após a aplicação da alteração, os pods são recriados e começam a autenticar-se no back-end de métricas com a conta de serviço fornecida.
Tópicos adicionais para a coleção gerida
Esta secção descreve como fazer o seguinte:
- Ative a funcionalidade de estado do alvo para facilitar a depuração.
- Configure a extração de alvos através do Terraform.
- Filtre os dados que exporta para o serviço gerido.
- Extraia métricas do Kubelet e do cAdvisor.
- Converta os seus recursos prom-operator existentes para utilização com o serviço gerido.
- Execute a recolha gerida fora do GKE.
Ativar a funcionalidade de estado do objetivo
O Managed Service for Prometheus oferece uma forma de verificar se os seus alvos estão a ser descobertos e extraídos corretamente pelos coletores. Este relatório do estado do destino destina-se a ser uma ferramenta para depurar problemas graves. Recomendamos vivamente que ative esta funcionalidade apenas para investigar problemas imediatos. Deixar os relatórios do estado do destino ativados em grandes clusters pode fazer com que o operador fique sem memória e entre num ciclo de falhas.
Pode verificar o estado dos seus destinos nos recursos PodMonitoring ou ClusterPodMonitoring definindo o valor
features.targetStatus.enabledno recurso OperatorConfig comotrue, conforme mostrado no seguinte:apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config features: targetStatus: enabled: trueApós alguns segundos, o campo
Status.Endpoint Statusesaparece em todos os recursos PodMonitoring ou ClusterPodMonitoring válidos, quando configurados.Se tiver um recurso PodMonitoring com o nome
prom-exampleno espaço de nomesNAMESPACE_NAME, pode verificar o estado executando o seguinte comando:kubectl -n NAMESPACE_NAME describe podmonitorings/prom-example
O resultado tem o seguinte aspeto:
API Version: monitoring.googleapis.com/v1 Kind: PodMonitoring ... Status: Conditions: ... Status: True Type: ConfigurationCreateSuccess Endpoint Statuses: Active Targets: 3 Collectors Fraction: 1 Last Update Time: 2023-08-02T12:24:26Z Name: PodMonitoring/custom/prom-example/metrics Sample Groups: Count: 3 Sample Targets: Health: up Labels: Cluster: CLUSTER_NAME Container: prom-example Instance: prom-example-589ddf7f7f-hcnpt:metrics Job: prom-example Location: REGION Namespace: NAMESPACE_NAME Pod: prom-example-589ddf7f7f-hcnpt project_id: PROJECT_ID Last Scrape Duration Seconds: 0.020206416 Health: up Labels: ... Last Scrape Duration Seconds: 0.054189485 Health: up Labels: ... Last Scrape Duration Seconds: 0.006224887A saída inclui os seguintes campos de estado:
Status.Conditions.Statusé verdadeiro quando o Managed Service for Prometheus reconhece e processa o PodMonitoring ou o ClusterPodMonitoring.Status.Endpoint Statuses.Active Targetsmostra o número de alvos de recolha de dados que o Managed Service for Prometheus contabiliza em todos os coletores para este recurso PodMonitoring. Na aplicação de exemplo, aprom-exampleimplementação tem três réplicas com um único objetivo de métrica, pelo que o valor é3. Se existirem objetivos não saudáveis, é apresentado o campoStatus.Endpoint Statuses.Unhealthy Targets.Status.Endpoint Statuses.Collectors Fractionmostra um valor de1(ou seja, 100%) se todos os coletores geridos forem acessíveis pelo Managed Service for Prometheus.Status.Endpoint Statuses.Last Update Timemostra a hora da última atualização. Quando o tempo da última atualização é significativamente superior ao tempo do intervalo de extração desejado, a diferença pode indicar problemas com o alvo ou o cluster.- O campo
Status.Endpoint Statuses.Sample Groupsmostra exemplos de destinos agrupados por etiquetas de destino comuns injetadas pelo coletor. Este valor é útil para depurar situações em que os seus alvos não são descobertos. Se todos os alvos estiverem em bom estado e a serem recolhidos, o valor esperado para o campoHealthéupe o valor do campoLast Scrape Duration Secondsé a duração habitual de um alvo típico.
Para mais informações sobre estes campos, consulte o documento da API Managed Service for Prometheus.
Qualquer uma das seguintes situações pode indicar um problema com a configuração:
- Não existe um campo
Status.Endpoint Statusesno seu recurso PodMonitoring. - O valor do campo
Last Scrape Duration Secondsé demasiado antigo. - Vê poucos alvos.
- O valor do campo
Healthindica que o destino édown.
Para mais informações sobre a depuração de problemas de deteção de alvos, consulte Problemas do lado da carregamento na documentação de resolução de problemas.
Configurar um ponto final de extração autorizado
Se o seu destino de recolha exigir autorização, pode configurar o coletor para usar o tipo de autorização correto e fornecer todos os segredos relevantes.
O serviço gerido do Google Cloud para Prometheus suporta os seguintes tipos de autorização:
mTLS
Normalmente, o mTLS é configurado em ambientes de confiança zero, como a malha de serviços do Istio ou a malha de serviços do Google Cloud.
Para ativar os pontos finais de extração protegidos através do mTLS, defina o campo
Spec.Endpoints[].Schemeno seu recurso PodMonitoring comohttps. Embora não seja recomendado, pode definir o campoSpec.Endpoints[].tls.insecureSkipVerifyno recurso PodMonitoring comotruepara ignorar a validação da autoridade de certificação. Em alternativa, pode configurar o Managed Service for Prometheus para carregar certificados e chaves a partir de recursos secretos.Por exemplo, o seguinte recurso Secret contém chaves para os certificados de cliente (
cert), chave privada (key) e autoridade de certificação (ca):kind: Secret metadata: name: secret-example stringData: cert: ******** key: ******** ca: ********
Conceda autorização ao coletor do Managed Service for Prometheus para aceder a esse recurso secreto:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
Nos clusters do GKE Autopilot, o aspeto é o seguinte:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
Para configurar um recurso PodMonitoring que usa o recurso Secret anterior, modifique o recurso para adicionar uma secção
schemeetls:apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s scheme: https tls: ca: secret: name: secret-example key: ca cert: secret: name: secret-example key: cert key: secret: name: secret-example key: keyPara consultar a documentação de referência sobre todas as opções de mTLS do Managed Service for Prometheus, consulte a documentação de referência da API.
BasicAuth
Para ativar os pontos finais de extração protegidos através da autenticação básica, defina o campo
Spec.Endpoints[].BasicAuthno seu recurso PodMonitoring com o seu nome de utilizador e palavra-passe. Para outros tipos de cabeçalhos de autorização HTTP, consulte o artigo Cabeçalho de autorização HTTP.Por exemplo, o recurso Secret seguinte contém uma chave para armazenar a palavra-passe:
kind: Secret metadata: name: secret-example stringData: password: ********
Conceda autorização ao coletor do Managed Service for Prometheus para aceder a esse recurso secreto:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
Nos clusters do GKE Autopilot, o aspeto é o seguinte:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
Para configurar um recurso PodMonitoring que usa o recurso Secret anterior e um nome de utilizador de
foo, modifique o recurso para adicionar uma secçãobasicAuth:apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s basicAuth: username: foo password: secret: name: secret-example key: passwordPara consultar a documentação de referência sobre todas as opções de BasicAuth do Managed Service for Prometheus, consulte a documentação de referência da API.
Cabeçalho de autorização HTTP
Para ativar a extração de pontos finais protegidos através de cabeçalhos de autorização HTTP, defina o campo
Spec.Endpoints[].Authorizationno recurso PodMonitoring com o tipo e as credenciais. Para pontos finais BasicAuth, use a configuração BasicAuth.Por exemplo, o recurso Secret seguinte contém uma chave para armazenar as credenciais:
kind: Secret metadata: name: secret-example stringData: credentials: ********
Conceda autorização ao coletor do Managed Service for Prometheus para aceder a esse recurso secreto:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
Nos clusters do GKE Autopilot, o aspeto é o seguinte:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
Para configurar um recurso PodMonitoring que usa o recurso Secret anterior e um tipo de
Bearer, modifique o recurso para adicionar uma secçãoauthorization:apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s authorization: type: Bearer credentials: secret: name: secret-example key: credentialsPara consultar a documentação de referência sobre todas as opções do cabeçalho de autorização HTTP do Managed Service for Prometheus, consulte a documentação de referência da API.
OAuth 2
Para ativar os pontos finais de extração protegidos através do OAuth 2, tem de definir o campo
Spec.Endpoints[].OAuth2no recurso PodMonitoring.Por exemplo, o recurso Secret seguinte contém uma chave para armazenar o segredo do cliente:
kind: Secret metadata: name: secret-example stringData: clientSecret: ********
Conceda autorização ao coletor do Managed Service for Prometheus para aceder a esse recurso secreto:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
Nos clusters do GKE Autopilot, o aspeto é o seguinte:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
Para configurar um recurso PodMonitoring que usa o recurso Secret anterior com um ID de cliente de
fooe um URL do token deexample.com/token, modifique o recurso para adicionar uma secçãooauth2:apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s oauth2: clientID: foo clientSecret: secret: name: secret-example key: password tokenURL: example.com/tokenPara ver documentação de referência sobre todas as opções de OAuth 2 do Managed Service for Prometheus, consulte a documentação de referência da API.
Configurar a extração de alvos com o Terraform
Pode automatizar a criação e a gestão de recursos PodMonitoring e ClusterPodMonitoring através do
kubernetes_manifesttipo de recurso do Terraform ou dokubectl_manifesttipo de recurso do Terraform. Qualquer um deles permite especificar recursos personalizados arbitrários.Para informações gerais sobre a utilização do Google Cloud com o Terraform, consulte Terraform com o Google Cloud.
Filtre métricas exportadas
Se recolher muitos dados, pode querer impedir que algumas séries cronológicas sejam enviadas para o serviço gerido para Prometheus para manter os custos baixos. Pode fazê-lo usando regras de reetiquetagem do Prometheus com uma ação
keeppara uma lista de autorizações ou uma açãodroppara uma lista de recusas. Para uma coleção gerida, esta regra é colocada na secçãometricRelabelingdo recurso PodMonitoring ou ClusterPodMonitoring.Por exemplo, a seguinte regra de reetiquetagem de métricas filtra qualquer métrica que comece por
foo_bar_,foo_baz_oufoo_qux_:metricRelabeling: - action: drop regex: foo_(bar|baz|qux)_.+ sourceLabels: [__name__]A página Gestão de métricas do Cloud Monitoring fornece informações que podem ajudar a controlar o valor gasto em métricas faturáveis sem afetar a observabilidade. A página Gestão de métricas apresenta as seguintes informações:
- Volumes de carregamento para a faturação baseada em bytes e em amostras, em domínios de métricas e para métricas individuais.
- Dados sobre as etiquetas e a cardinalidade das métricas.
- Número de leituras para cada métrica.
- Utilização de métricas em políticas de alerta e painéis de controlo personalizados.
- Taxa de erros de escrita de métricas.
Também pode usar a página Gestão de métricas para excluir métricas desnecessárias, eliminando o custo da respetiva ingestão. Para mais informações sobre a página Gestão de métricas, consulte o artigo Veja e faça a gestão da utilização de métricas.
Para ver sugestões adicionais sobre como reduzir os custos, consulte o artigo Controlos de custos e atribuição.
Extrair métricas do Kubelet e do cAdvisor
O Kubelet expõe métricas sobre si próprio, bem como métricas do cAdvisor sobre contentores em execução no respetivo nó. Pode configurar a recolha gerida para extrair métricas do Kubelet e do cAdvisor editando o recurso OperatorConfig. Para ver instruções, consulte a documentação do exportador para o Kubelet e o cAdvisor.
Converta recursos prometheus-operator existentes
Normalmente, pode converter os seus recursos do prometheus-operator existentes em recursos do Managed Service for Prometheus de recolha gerida PodMonitoring e ClusterPodMonitoring.
Por exemplo, o recurso ServiceMonitor define a monitorização de um conjunto de serviços. O recurso PodMonitoring publica um subconjunto dos campos publicados pelo recurso ServiceMonitor. Pode converter um CR ServiceMonitor num CR PodMonitoring mapeando os campos conforme descrito na tabela seguinte:
monitoring.coreos.com/v1
ServiceMonitorCompatibilidade
monitoring.googleapis.com/v1
PodMonitoring.ServiceMonitorSpec.SelectorIdêntico .PodMonitoringSpec.Selector.ServiceMonitorSpec.Endpoints[].TargetPorté mapeado para.Port
.Path: compatível
.Interval: compatível
.Timeout: compatível.PodMonitoringSpec.Endpoints[].ServiceMonitorSpec.TargetLabelsO PodMonitor tem de especificar:
.FromPod[].Frometiqueta do agrupamento
.FromPod[].Toetiqueta de destino.PodMonitoringSpec.TargetLabelsSegue-se um exemplo de um CR ServiceMonitor; o conteúdo em negrito é substituído na conversão, e o conteúdo em itálico é mapeado diretamente:
apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: example-app spec: selector: matchLabels: app: example-app endpoints: - targetPort: web path: /stats interval: 30s targetLabels: - fooSegue-se o CR PodMonitoring análogo, partindo do princípio de que o seu serviço e os respetivos pods estão etiquetados com
app=example-app. Se esta suposição não se aplicar, tem de usar os seletores de etiquetas do recurso de serviço subjacente.O conteúdo a negrito foi substituído na conversão:
apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: example-app spec: selector: matchLabels: app: example-app endpoints: - port: web path: /stats interval: 30s targetLabels: fromPod: - from: foo # pod label from example-app Service pods. to: fooPode sempre continuar a usar os seus recursos prometheus-operator e configurações de implementação existentes usando coletores implementados automaticamente em vez de coletores geridos. Pode consultar as métricas enviadas a partir de ambos os tipos de coletores, pelo que pode querer usar coletores implementados automaticamente para as suas implementações existentes do Prometheus, enquanto usa coletores geridos para novas implementações do Prometheus.
Etiquetas reservadas
O Managed Service for Prometheus adiciona automaticamente as seguintes etiquetas a todas as métricas recolhidas. Estas etiquetas são usadas para identificar de forma exclusiva um recurso no Monarch:
project_id: o identificador do projeto Google Cloud associado à sua métrica.location: a localização física (Google Cloud região) onde os dados são armazenados. Este valor é normalmente a região do seu cluster do GKE. Se os dados forem recolhidos a partir de uma implementação local ou da AWS, o valor pode ser a região Google Cloud mais próxima.cluster: o nome do cluster do Kubernetes associado à sua métrica.namespace: o nome do espaço de nomes do Kubernetes associado à sua métrica.job: a etiqueta de tarefa do destino do Prometheus, se for conhecida; pode estar vazia para resultados de avaliação de regras.instance: a etiqueta de instância do destino do Prometheus, se for conhecida; pode estar vazia para resultados de avaliação de regras.
Embora não seja recomendado quando executado no Google Kubernetes Engine, pode substituir as etiquetas
project_id,locationeclusteradicionando-as comoargsao recurso de implementação nooperator.yaml. Se usar etiquetas reservadas como etiquetas de métricas, o Managed Service for Prometheus reetiqueta-as automaticamente adicionando o prefixoexported_. Este comportamento corresponde à forma como o Prometheus a montante processa os conflitos com etiquetas reservadas.Configurações de compressão
Se tiver muitos recursos PodMonitoring, pode ficar sem espaço no ConfigMap. Para corrigir esta situação, ative a compressão
gzipno seu recurso OperatorConfig:apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config features: config: compression: gzipAtive a escala automática vertical de pods (VPA) para a recolha gerida
Se estiver a deparar-se com erros de falta de memória (OOM) para os pods de recolha no seu cluster ou se os pedidos e os limites de recursos predefinidos para os coletores não satisfizerem as suas necessidades, pode usar o redimensionamento automático vertical de pods para alocar recursos dinamicamente.
Quando define o campo
scaling.vpa.enabled: trueno recursoOperatorConfig, o operador implementa um manifestoVerticalPodAutoscalerno cluster que permite que os pedidos e os limites de recursos dos pods do coletor sejam definidos automaticamente com base na utilização.Para ativar o VPA para pods de recolha no Managed Service for Prometheus, execute o seguinte comando:
kubectl -n gmp-public patch operatorconfig/config -p '{"scaling":{"vpa":{"enabled":true}}}' --type=mergeSe o comando for concluído com êxito, o operador configura a escala automática vertical de pods para os pods do coletor. Os erros de falta de memória resultam num aumento imediato dos limites de recursos. Se não existirem erros de OOM, o primeiro ajuste aos pedidos e limites de recursos dos pods do coletor ocorre normalmente no prazo de 24 horas.
Pode receber este erro quando tenta ativar a VPA:
vertical pod autoscaling is not available - install vpa support and restart the operatorPara resolver este erro, primeiro, tem de ativar a escala automática vertical de pods ao nível do cluster:
Aceda à página Kubernetes Engine – Clusters na Google Cloud consola.
Na Google Cloud consola, aceda à página Clusters do Kubernetes:
Aceda a Clusters do Kubernetes
Se usar a barra de pesquisa para encontrar esta página, selecione o resultado cujo subtítulo é Kubernetes Engine.
Selecione o cluster que quer modificar.
Na secção Automação, edite o valor da opção Vertical Pod Autoscaling.
Selecione a caixa de verificação Ativar o ajuste automático vertical de pods e, de seguida, clique em Guardar alterações. Esta alteração reinicia o cluster. O operador é reiniciado como parte deste processo.
Volte a tentar o seguinte comando:
kubectl -n gmp-public patch operatorconfig/config -p '{"scaling":{"vpa":{"enabled":true}}}' --type=mergepara ativar o VPA para o Managed Service for Prometheus.
Para confirmar que o recurso
OperatorConfigfoi editado com êxito, abra-o usando o comandokubectl -n gmp-public edit operatorconfig config. Se for bem-sucedida, a suaOperatorConfiginclui a seguinte secção em negrito:apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config scaling: vpa: enabled: trueSe já ativou a escala automática vertical de pods ao nível do cluster e continuar a ver o erro
vertical pod autoscaling is not available - install vpa support and restart the operator, o podgmp-operatorpode ter de reavaliar a configuração do cluster. Se estiver a executar um cluster padrão, execute o seguinte comando para recriar o pod:kubectl -n gmp-system rollout restart deployment/gmp-operator
Depois de o pod
gmp-operatorser reiniciado, siga os passos acima para aplicar novamente a correção aoOperatorConfig.Se estiver a executar um cluster do Autopilot, contacte o apoio técnico para receber ajuda no reinício do cluster.
A escala automática vertical de pods funciona melhor quando ingere números estáveis de amostras, divididos igualmente entre os nós. Se o carregamento de métricas for irregular ou instável, ou se o carregamento de métricas variar muito entre os nós, o VPA pode não ser uma solução eficiente.
Para mais informações, consulte o artigo Escala automática vertical de pods no GKE.
Configure o statsd_exporter e outros exportadores que comunicam métricas de forma centralizada
Se usar o statsd_exporter para o Prometheus, o Envoy para o Istio, o SNMP exporter, o Prometheus Pushgateway, o kube-state-metrics ou tiver um exportador semelhante que intermedeia e comunica métricas em nome de outros recursos em execução no seu ambiente, tem de fazer algumas pequenas alterações para que o exportador funcione com o Managed Service for Prometheus.
Para ver instruções sobre como configurar estes exportadores, consulte esta nota na secção Resolução de problemas.
Desmontagem
Para desativar a recolha gerida implementada através da
gcloudou da IU do GKE, pode fazer uma das seguintes ações:Execute o seguinte comando:
gcloud container clusters update CLUSTER_NAME --disable-managed-prometheus
Use a IU do GKE:
Selecione Kubernetes Engine na Google Cloud consola e, de seguida, selecione Clusters.
Localize o cluster para o qual quer desativar a recolha gerida e clique no respetivo nome.
No separador Detalhes, desloque a página para baixo até Funcionalidades e altere o estado para Desativado através do botão de edição.
Para desativar a recolha gerida implementada através do Terraform, especifique
enabled = falsena secçãomanaged_prometheusdo recursogoogle_container_cluster.Para desativar a recolha gerida implementada através de
kubectl, execute o seguinte comando:kubectl delete -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/manifests/operator.yaml
A desativação da recolha gerida faz com que o cluster deixe de enviar novos dados para o Managed Service for Prometheus. Esta ação não elimina os dados de métricas existentes já armazenados no sistema.
A desativação da recolha gerida também elimina o espaço de nomes
gmp-publice todos os recursos no mesmo, incluindo quaisquer exportadores instalados nesse espaço de nomes.Execute a recolha gerida fora do GKE
Em ambientes do GKE, pode executar a recolha gerida sem configuração adicional. Noutros ambientes do Kubernetes, tem de fornecer explicitamente credenciais, um valor
project-idpara conter as suas métricas, um valorlocation(Google Cloud região) onde as suas métricas vão ser armazenadas e um valorclusterpara guardar o nome do cluster no qual o coletor está a ser executado.Como
gcloudnão funciona fora dos ambientes Google Cloud , tem de fazer a implementação com o kubectl. Ao contrário do que acontece com ogcloud, a implementação da recolha gerida através dokubectlnão atualiza automaticamente o cluster quando está disponível uma nova versão. Não se esqueça de consultar a página de lançamentos para ver novas versões e atualizar manualmente executando novamente os comandoskubectlcom a nova versão.Pode fornecer uma chave de conta de serviço modificando o recurso OperatorConfig em
operator.yaml, conforme descrito em Forneça credenciais explicitamente. Pode fornecer valores deproject-id,locationeclusteradicionando-os comoargsao recurso de implementação emoperator.yaml.Recomendamos que escolha
project-idcom base no modelo de arrendamento planeado para leituras. Escolha um projeto para armazenar métricas com base na forma como planeia organizar as leituras mais tarde com âmbitos de métricas. Se não se importar, pode colocar tudo num único projeto.Para
location, recomendamos que escolha a região mais próxima da sua implementação Google Cloud . Quanto mais distante estiver a Google Cloud região escolhida da sua implementação,0x0A>maior será a latência de escrita e mais será afetado por potenciais problemas de rede. Recomendamos que consulte esta lista de regiões em várias nuvens. Se não tiver interesse, pode colocar tudo numa única Google Cloud região. Não pode usarglobalcomo a sua localização.Para
cluster, recomendamos que escolha o nome do cluster no qual o operador está implementado.Quando configurado corretamente, o OperatorConfig deve ter o seguinte aspeto:
apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config collection: credentials: name: gmp-test-sa key: key.json rules: credentials: name: gmp-test-sa key: key.jsonO recurso de implementação deve ter o seguinte aspeto:
apiVersion: apps/v1 kind: Deployment ... spec: ... template: ... spec: ... containers: - name: operator ... args: - ... - "--project-id=PROJECT_ID" - "--cluster=CLUSTER_NAME" - "--location=REGION"Este exemplo pressupõe que definiu a variável
REGIONpara um valor comous-central1, por exemplo.A execução do Managed Service for Prometheus fora do Google Cloud incorre em taxas de transferência de dados. Existem taxas para transferir dados para o Google Cloude pode incorrer em taxas para transferir dados de outra nuvem. Pode minimizar estes custos ativando a compressão gzip através da rede através do OperatorConfig. Adicione o texto apresentado em negrito ao recurso:
apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config collection: compression: gzip ...Leitura adicional sobre recursos personalizados de recolha gerida
Para ver a documentação de referência sobre todos os recursos personalizados do Managed Service for Prometheus, consulte a referência da API prometheus-engine/doc/api.
O que se segue?