Après avoir déployé Google Cloud Managed Service pour Prometheus, vous pouvez interroger les données envoyées au service géré et afficher les résultats dans des graphiques et des tableaux de bord.
Ce document décrit les champs d'application de métriques, qui déterminent les données que vous pouvez interroger et comment utiliser Grafana pour récupérer et utiliser les données que vous avez collectées.
Toutes les interfaces de requête de Managed Service pour Prometheus sont configurées pour récupérer les données de Monarch à l'aide de l'API Cloud Monitoring. En interrogeant Monarch au lieu d'interroger les données des serveurs Prometheus locaux, vous obtenez une surveillance globale à grande échelle.
Avant de commencer
Si vous n'avez pas encore déployé le service géré, configurez la collecte gérée ou la collecte auto-déployée. Vous pouvez ignorer cette étape si vous souhaitez uniquement interroger des métriques Cloud Monitoring à l'aide de PromQL.
Configurer votre environnement
Pour éviter de saisir à plusieurs reprises l'ID de votre projet ou le nom de votre cluster, effectuez la configuration suivante :
Configurez les outils de ligne de commande comme suit :
Configurez la gcloud CLI pour faire référence à l'ID de votre projetGoogle Cloud :
gcloud config set project PROJECT_ID
Configurez la CLI
kubectlpour utiliser votre cluster :kubectl config set-cluster CLUSTER_NAME
Pour en savoir plus sur ces outils, consultez les articles suivants :
Configurer un espace de noms
Créez l'espace de noms Kubernetes NAMESPACE_NAME pour les ressources que vous créez dans le cadre de l'exemple d'application :
kubectl create ns NAMESPACE_NAME
Vérifier les identifiants du compte de service
Si Workload Identity Federation for GKE est activé sur votre cluster Kubernetes, vous pouvez ignorer cette section.
Lors de l'exécution sur GKE, Managed Service pour Prometheus récupère automatiquement les identifiants de l'environnement en fonction du compte de service Compute Engine par défaut. Le compte de service par défaut dispose des autorisations nécessaires, monitoring.metricWriter et monitoring.viewer, par défaut. Si vous n'utilisez pas Workload Identity Federation for GKE et que vous avez précédemment supprimé l'un de ces rôles du compte de service de nœud par défaut, vous devrez rajouter ces autorisations manquantes avant de continuer.
Configurer un compte de service pour Workload Identity Federation for GKE
Si Workload Identity Federation for GKE n'est pas activé sur votre cluster Kubernetes, vous pouvez ignorer cette section.
Managed Service pour Prometheus capture les données de métriques à l'aide de l'API Cloud Monitoring. Si votre cluster utilise Workload Identity Federation for GKE, vous devez autoriser votre compte de service Kubernetes à accéder à l'API Monitoring. Cette section décrit les opérations suivantes :
- Créer un compte de serviceGoogle Cloud dédié,
gmp-test-sa. - Associer le compte de service Google Cloud au compte de service Kubernetes par défaut dans un espace de noms de test,
NAMESPACE_NAME. - Accorder l'autorisation nécessaire au compte de service Google Cloud .
Créer et associer le compte de service
Cette étape apparaît à plusieurs endroits de la documentation de Managed Service pour Prometheus. Si vous avez déjà effectué cette étape dans le cadre d'une tâche précédente, vous n'avez pas besoin de la répéter. Passez directement à la section Autoriser le compte de service.
La séquence de commandes suivante crée le compte de service gmp-test-sa et l'associe au compte de service Kubernetes par défaut dans l'espace de noms NAMESPACE_NAME :
gcloud config set project PROJECT_ID \ && gcloud iam service-accounts create gmp-test-sa \ && gcloud iam service-accounts add-iam-policy-binding \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:PROJECT_ID.svc.id.goog[NAMESPACE_NAME/default]" \ gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ && kubectl annotate serviceaccount \ --namespace NAMESPACE_NAME \ default \ iam.gke.io/gcp-service-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
Si vous utilisez un autre espace de noms ou compte de service GKE, ajustez les commandes en conséquence.
Autoriser le compte de service
Les groupes d'autorisations associées sont collectés dans des rôles que vous attribuez à un compte principal, dans cet exemple, le compte de service Google Cloud. Pour en savoir plus sur les rôles Monitoring, consultez Contrôle des accès.
La commande suivante accorde au compte de service Google Cloud ,gmp-test-sa, les rôles de l'API Monitoring dont il a besoin pour lire les données de métriques.
Si vous avez déjà attribué un rôle spécifique au compte de service Google Cloud dans le cadre de la tâche précédente, vous n'avez pas besoin de le faire à nouveau.
Pour autoriser votre compte de service à lire les données de métriques d'un champ d'application de métriques multiprojets, suivez ces instructions, puis consultez la section Modifier le projet interrogé.gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.viewer \ && \ gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/iam.serviceAccountTokenCreator
Déboguer votre configuration de Workload Identity Federation for GKE
Si vous rencontrez des difficultés pour utiliser Workload Identity Federation for GKE, consultez la documentation sur la vérification de la configuration de Workload Identity Federation for GKE et le guide de dépannage de Workload Identity Federation for GKE.
Les fautes de frappe et les copier-coller partiels sont les sources d'erreurs les plus courantes lors de la configuration de Workload Identity Federation for GKE. Nous vous recommandons vivement d'utiliser les variables modifiables et les icônes de copier-coller cliquables intégrées dans les exemples de code figurant dans ces instructions.
Workload Identity Federation for GKE dans les environnements de production
L'exemple décrit dans ce document associe le compte de service Google Cloud au compte de service Kubernetes par défaut et accorde au compte de service Google Cloudtoutes les autorisations nécessaires pour utiliser l'API Monitoring.
Dans un environnement de production, vous pouvez utiliser une approche plus précise, avec un compte de service pour chaque composant, chacun disposant d'autorisations minimales. Pour en savoir plus sur la configuration des comptes de service pour la gestion des identités de charge de travail, consultez la section Utiliser Workload Identity Federation for GKE.
Champs d'application des requêtes et des métriques
Les données que vous pouvez interroger sont déterminées par le champ d'application des métriques Cloud Monitoring, quelle que soit la méthode que vous utilisez pour interroger les données. Par exemple, si vous utilisez Grafana pour interroger les données de Managed Service pour Prometheus, chaque champ d'application des métriques doit être configuré en tant que source de données distincte.
Un champ d'application des métriques Monitoring est une structure en lecture seule qui vous permet d'interroger les données de métriques appartenant à plusieurs projets Google Cloud . Chaque champ d'application des métriques est hébergé par un projet Google Cloud désigné, appelé projet de champ d'application.
Par défaut, un projet est le projet de champ d'application pour son propre champ d'application des métriques. Le champ d'application des métriques contient les métriques et la configuration de ce projet. Un projet de champ d'application peut avoir plusieurs projets surveillés dans son champ d'application des métriques, et les métriques et les configurations de tous les projets surveillés dans le champ d'application des métriques sont visibles dans le projet de champ d'application. Un projet surveillé peut également appartenir à plusieurs champs d'application des métriques.
Lorsque vous interrogez les métriques d'un projet effectuant une surveillance et si ce projet héberge un champ d'application des métriques multiprojets, vous pouvez extraire les données de plusieurs projets. Si le champ d'application des métriques contient tous vos projets, vos requêtes et règles sont évaluées globalement.
Pour en savoir plus sur les projets de champ d'application et les champs d'application des métriques, consultez la section Champs d'application des métriques. Pour en savoir plus sur la configuration d'un champ d'application de métriques multiprojets, consultez la section Afficher les métriques de plusieurs projets.
Données Managed Service pour Prometheus dans Cloud Monitoring
Le moyen le plus simple de vérifier que vos données Prometheus sont exportées consiste à utiliser la page de l'explorateur de métriques Cloud Monitoring dans la console Google Cloud , qui est compatible avec PromQL. Pour obtenir des instructions, consultez Interroger des données à l'aide de PromQL dans Cloud Monitoring.
Vous pouvez également importer vos tableaux de bord Grafana dans Cloud Monitoring. Vous pouvez ainsi continuer à utiliser les tableaux de bord Grafana créés par la communauté ou sans avoir à configurer ni déployer une instance Grafana.
Grafana
Managed Service pour Prometheus utilise la source de données Prometheus intégrée pour Grafana, ce qui signifie que vous pouvez continuer à utiliser n'importe quel tableau de bord Grafana créé par la communauté ou personnel sans aucune modification.
Déployez Grafana, si nécessaire
Si vous n'avez pas de déploiement Grafana en cours d'exécution sur votre cluster, vous pouvez créer un déploiement test éphémère.
Pour créer un déploiement Grafana éphémère, appliquez le fichier manifeste de Managed Service pour Prometheus grafana.yaml à votre cluster et transférez le service grafana vers votre ordinateur local. En raison des restrictions CORS, vous ne pouvez pas accéder à un déploiement Grafana à l'aide de Cloud Shell.
Appliquez le fichier manifeste
grafana.yaml:kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/grafana.yaml
Transférez le service
grafanavers votre ordinateur local. Cet exemple transfère le service vers le port 3000 :kubectl -n NAMESPACE_NAME port-forward svc/grafana 3000
Cette commande ne renvoie pas de résultat et signale les accès à l'URL pendant son exécution.
Vous pouvez accéder à Grafana dans votre navigateur à l'adresse
http://localhost:3000avec le nom d'utilisateur et le mode de passeadmin:admin.
Ensuite, ajoutez une nouvelle source de données Prometheus à Grafana en procédant comme suit :
Accédez à votre déploiement Grafana, par exemple en recherchant l'URL
http://localhost:3000pour accéder à la page d'accueil de Grafana.Dans le menu principal de Grafana, sélectionnez Connections, puis Data Sources (Sources de données).
Sélectionnez Add data source (Ajouter une source de données), puis sélectionnez Prometheus comme base de données de séries temporelles.
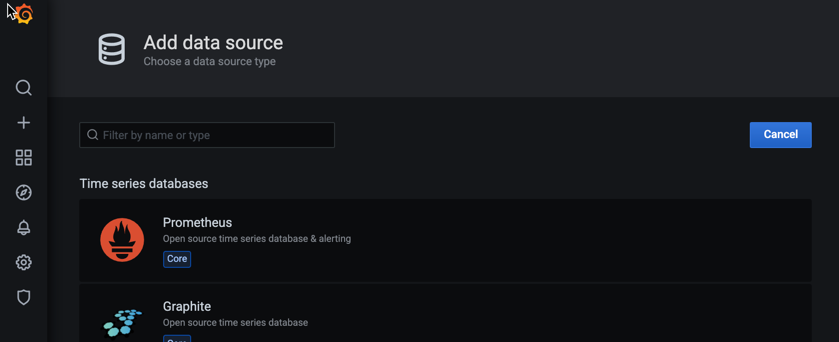
Donnez un nom à la source de données. Définissez le champ
URLsurhttp://localhost:9090, puis sélectionnez Enregistrer et tester. Vous pouvez ignorer les erreurs indiquant que la source de données n'est pas configurée correctement.Copiez l'URL du service local pour votre déploiement, qui se présentera comme suit :
http://grafana.NAMESPACE_NAME.svc:3000
Configurer et authentifier la source de données Grafana
Les APIGoogle Cloud nécessitent toutes une authentification via OAuth2. Toutefois, Grafana n'est pas compatible avec l'authentification OAuth2 pour les comptes de service utilisés avec des sources de données Prometheus. Pour utiliser Grafana avec Managed Service pour Prometheus, vous devez utiliser le synchronisateur de sources de données pour générer des identifiants OAuth2 pour votre compte de service et les synchroniser avec Grafana via l'API de source de données Grafana.
Vous devez utiliser le synchronisateur de sources de données pour configurer et autoriser Grafana à interroger des données à l'échelle mondiale. Si vous ne suivez pas ces étapes, Grafana n'exécute des requêtes que sur les données du serveur Prometheus local.
Le synchronisateur de sources de données est un outil d'interface de ligne de commande qui envoie à distance les valeurs de configuration à une source de données Grafana Prometheus spécifiée. Cela garantit que les éléments suivants sont correctement configurés pour votre source de données Grafana :
- Authentification, effectuée en actualisant périodiquement un jeton d'accès OAuth2
- API Cloud Monitoring définie comme URL du serveur Prometheus
- Méthode HTTP définie sur GET
- Type et version de Prometheus définis sur 2.40.x comme version minimale
- Les valeurs du délai d'expiration HTTP et de la requête sont définies sur 2 minutes
Le synchronisateur de sources de données doit s'exécuter à plusieurs reprises. Comme les jetons d'accès aux comptes de service ont une durée de vie par défaut d'une heure, l'exécution du synchronisateur de sources de données toutes les 10 minutes vous assure une connexion authentifiée ininterrompue entre Grafana et l'API Cloud Monitoring.
Vous pouvez choisir d'exécuter le synchronisateur de sources de données à l'aide d'un CronJob Kubernetes ou à l'aide de Cloud Run et de Cloud Scheduler pour une expérience entièrement sans serveur. Si vous déployez Grafana en local, par exemple avec la version Open Source de Grafana ou Grafana Enterprise, nous vous recommandons d'exécuter le synchroniseur de sources de données dans le même cluster que Grafana. Si vous utilisez Grafana Cloud, nous vous recommandons de choisir l'option entièrement sans serveur.
Utiliser le mode sans serveur
Pour déployer et exécuter un synchronisateur de sources de données sans serveur à l'aide de Cloud Run et Cloud Scheduler, procédez comme suit :
Choisissez un projet dans lequel déployer le synchronisateur de sources de données. Nous vous recommandons de choisir le projet de champ d'application d'un champ d'application des métriques multiprojets. Le synchronisateur de sources de données utilise le projet Google Cloud configuré comme projet de champ d'application.
Ensuite, configurez et autorisez un compte de service pour le synchroniseur de sources de données. La séquence de commandes suivante crée un compte de service et lui attribue plusieurs rôles IAM. Les deux premiers rôles permettent au compte de service de lire les données de l'API Cloud Monitoring et de générer des jetons de compte de service. Les deux derniers rôles permettent au compte de service de lire le jeton du compte de service Grafana à partir de Secret Manager et d'appeler Cloud Run :
gcloud config set project PROJECT_ID \ && gcloud iam service-accounts create gmp-ds-syncer-sa \ && gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:gmp-ds-syncer-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.viewer \ && \ gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:gmp-ds-syncer-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/iam.serviceAccountTokenCreator \ && \ gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:gmp-ds-syncer-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/secretmanager.secretAccessor && \ gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:gmp-ds-syncer-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/run.invoker
Déterminez l'URL de votre instance Grafana, par exemple
https://yourcompanyname.grafana.netpour un déploiement Grafana Cloud. Votre instance Grafana doit être accessible depuis Cloud Run, c'est-à-dire depuis l'ensemble d'Internet.Si votre instance Grafana n'est pas accessible depuis Internet, nous vous recommandons de déployer le synchronisateur de sources de données sur Kubernetes.
Choisissez la source de données Prometheus Grafana à utiliser pour Managed Service pour Prometheus (il peut s'agir d'une nouvelle source de données Prometheus ou d'une source de données Prometheus préexistante), puis recherchez et notez l'UID de la source de données. Vous pouvez trouver l'UID de la source de données dans la dernière partie de l'URL lors de l'exploration ou de la configuration d'une source de données, par exemple
https://yourcompanyname.grafana.net/connections/datasources/edit/GRAFANA_DATASOURCE_UID. Ne copiez pas l'URL complète de la source de données. Ne copiez que l'identifiant unique dans l'URL.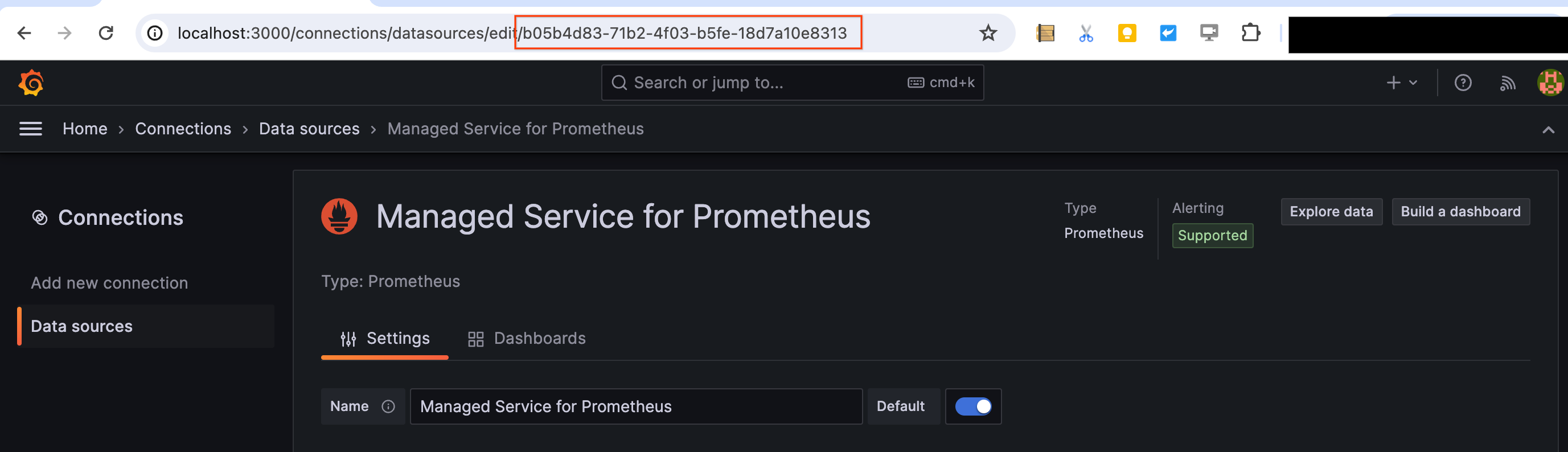
Configurez un compte de service Grafana en créant le compte de service et en générant un jeton que le compte utilisera:
Dans la barre latérale de navigation Grafana, cliquez sur Administration > Utilisateurs et accès > Comptes de service.
Créez le compte de service dans Grafana en cliquant sur Ajouter un compte de service, en lui attribuant un nom et en lui accordant le rôle "Sources de données > Rédacteur". Veillez à cliquer sur le bouton Appliquer pour attribuer le rôle. Dans les anciennes versions de Grafana, vous pouvez utiliser le rôle "Admin" à la place.
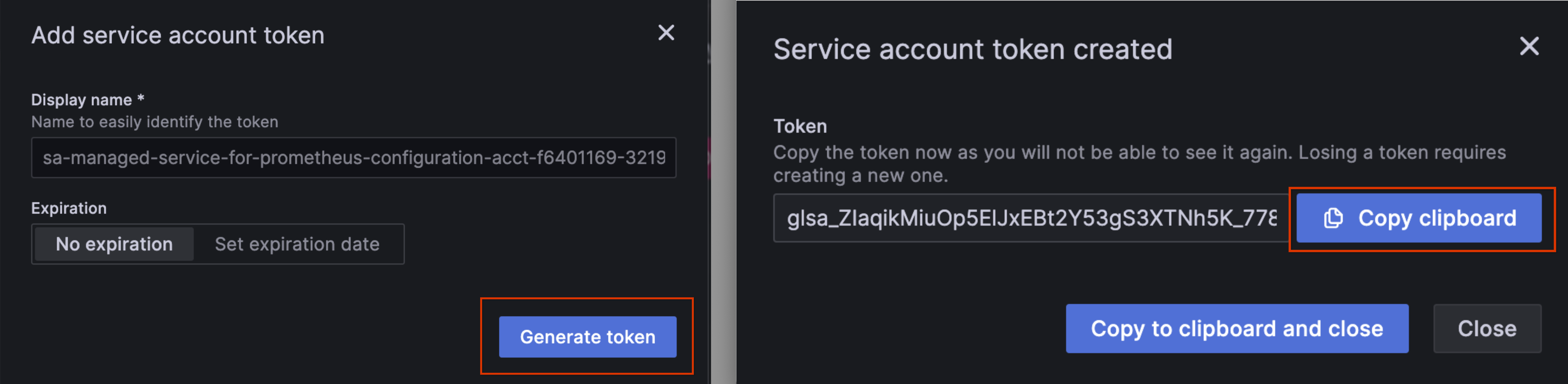
Cliquez sur Ajouter un jeton de compte de service.
Définissez le délai d'expiration du jeton sur "Aucun délai d'expiration", cliquez sur Générer un jeton, puis copiez le jeton généré dans le presse-papiers pour l'utiliser en tant que GRAFANA_SERVICE_ACCOUNT_TOKEN à l'étape suivante :
Définissez les variables de documentation suivantes à l'aide des résultats des étapes précédentes. Vous n'avez pas besoin de les coller dans un terminal :
# These values are required. REGION # The Google Cloud region where you want to run your Cloud Run job, such as us-central1. PROJECT_ID # The Project ID from Step 1. GRAFANA_INSTANCE_URL # The Grafana instance URL from step 2. This is a URL. Include "http://" or "https://". GRAFANA_DATASOURCE_UID # The Grafana data source UID from step 3. This is not a URL. GRAFANA_SERVICE_ACCOUNT_TOKEN # The Grafana service account token from step 4.
Créez un secret dans Secret Manager :
gcloud secrets create datasource-syncer --replication-policy="automatic" && \ echo -n GRAFANA_SERVICE_ACCOUNT_TOKEN | gcloud secrets versions add datasource-syncer --data-file=-
Créez le fichier YAML suivant et nommez-le
cloud-run-datasource-syncer.yaml:apiVersion: run.googleapis.com/v1 kind: Job metadata: name: datasource-syncer-job spec: template: spec: taskCount: 1 template: spec: containers: - name: datasource-syncer image: gke.gcr.io/prometheus-engine/datasource-syncer:v0.15.3-gke.0 args: - "--datasource-uids=GRAFANA_DATASOURCE_UID" - "--grafana-api-endpoint=GRAFANA_INSTANCE_URL" - "--project-id=PROJECT_ID" env: - name: GRAFANA_SERVICE_ACCOUNT_TOKEN valueFrom: secretKeyRef: key: latest name: datasource-syncer serviceAccountName: gmp-ds-syncer-sa@PROJECT_ID.iam.gserviceaccount.comExécutez ensuite la commande suivante pour créer un job Cloud Run à l'aide du fichier YAML :
gcloud run jobs replace cloud-run-datasource-syncer.yaml --region REGION
Créez une planification dans Cloud Scheduler pour exécuter le job Cloud Run toutes les 10 minutes :
gcloud scheduler jobs create http datasource-syncer \ --location REGION \ --schedule="*/10 * * * *" \ --uri="https://REGION-run.googleapis.com/apis/run.googleapis.com/v1/namespaces/PROJECT_ID/jobs/datasource-syncer-job:run" \ --http-method POST \ --oauth-service-account-email=gmp-ds-syncer-sa@PROJECT_ID.iam.gserviceaccount.com
Ensuite, forcez l'exécution du programmeur que vous venez de créer :
gcloud scheduler jobs run datasource-syncer --location REGION
La mise à jour de la source de données peut prendre jusqu'à 15 secondes.
Accédez à la source de données Grafana que vous venez de configurer, puis vérifiez que la valeur de l'URL du serveur Prometheus commence par
https://monitoring.googleapis.com. Vous devrez peut-être actualiser la page. Une fois la validation effectuée, accédez au bas de la page, sélectionnez Enregistrer et tester, puis vérifiez qu'une coche verte s'affiche pour indiquer que la source de données est correctement configurée. Vous devez sélectionner au moins une option Save & test (Enregistrer et tester) pour vous assurer que la saisie semi-automatique des étiquettes dans Grafana fonctionne.
Utiliser Kubernetes
Pour déployer et exécuter le synchronisateur de sources de données dans un cluster Kubernetes, procédez comme suit :
Choisissez un projet, un cluster et un espace de noms dans lesquels déployer le synchronisateur de sources de données. Nous vous recommandons de déployer le synchroniseur de sources de données dans un cluster appartenant au projet de champ d'application d'un champ d'application des métriques multiprojets. Le synchronisateur de sources de données utilise le projet Google Cloud configuré comme projet de champ d'application.
Ensuite, assurez-vous de bien configurer et autoriser le synchroniseur de sources de données :
- Si vous utilisez Workload Identity Federation for GKE, suivez les instructions pour créer et autoriser un compte de service. Veillez à le lier à l'espace de noms Kubernetes dans lequel vous souhaitez exécuter le synchronisateur de sources de données.
- Si vous n'utilisez pas Workload Identity Federation for GKE, vérifiez que vous n'avez pas modifié le compte de service Compute Engine par défaut.
- Si vous n'exécutez pas sur GKE, consultez Exécuter le synchroniseur de sources de données en dehors de GKE.
Déterminez ensuite si vous devez accorder davantage d'autorisations au synchroniseur de sources de données pour les requêtes multiprojets :
- Si votre projet local est votre projet de surveillance et que vous avez suivi les instructions pour vérifier ou configurer un compte de service pour le projet local, les requêtes multiprojets devraient fonctionner sans autre configuration.
- Si votre projet local n'est pas votre projet de surveillance, vous devez autoriser le synchroniseur de sources de données à exécuter des requêtes sur le projet de surveillance. Pour obtenir des instructions, consultez Autoriser le synchroniseur de sources de données à surveiller plusieurs projets.
Déterminez l'URL de votre instance Grafana, par exemple
https://yourcompanyname.grafana.netpour un déploiement Grafana Cloud ouhttp://grafana.NAMESPACE_NAME.svc:3000pour une instance locale configurée à l'aide du fichier YAML de déploiement de test.Si vous déployez Grafana localement et que votre cluster est configuré pour sécuriser tout le trafic dans le cluster à l'aide de TLS, vous devez utiliser
https://dans votre URL et vous authentifier à l'aide de l'une des options d'authentification TLS compatibles.Choisissez la source de données Prometheus Grafana que vous souhaitez utiliser pour Managed Service pour Prometheus, qui peut être une nouvelle source ou une source de données préexistante, puis recherchez et notez l'UID de la source de données. L'UID de la source de données se trouve dans la dernière partie de l'URL lorsque vous explorez ou configurez une source de données. Exemple :
https://yourcompanyname.grafana.net/connections/datasources/edit/GRAFANA_DATASOURCE_UID.Ne pas copier l'intégralité de l'URL de la source de données.. Ne copiez que l'identifiant unique dans l'URL.Configurez un compte de service Grafana en créant le compte de service et en générant un jeton que le compte utilisera:
- Dans la barre latérale de navigation Grafana, cliquez sur Administration > Utilisateurs et accès > Comptes de service.
Créez le compte de service en cliquant sur Ajouter un compte de service, en lui attribuant un nom et en lui attribuant le rôle "Administrateur" dans Grafana. Si votre version de Grafana autorise des autorisations plus précises, vous pouvez utiliser le rôle Sources de données > Écrivain.
Cliquez sur Ajouter un jeton de compte de service.
Définissez le délai d'expiration du jeton sur "Aucun délai d'expiration", cliquez sur Générer un jeton, puis copiez le jeton généré dans le presse-papiers pour l'utiliser en tant que GRAFANA_SERVICE_ACCOUNT_TOKEN à l'étape suivante.
Configurez les variables d'environnement suivantes à l'aide des résultats des étapes précédentes :
# These values are required. PROJECT_ID=SCOPING_PROJECT_ID # The value from Step 1. GRAFANA_API_ENDPOINT=GRAFANA_INSTANCE_URL # The value from step 2. This is a URL. DATASOURCE_UIDS=GRAFANA_DATASOURCE_UID # The value from step 3. This is not a URL. GRAFANA_API_TOKEN=GRAFANA_SERVICE_ACCOUNT_TOKEN # The value from step 4.
Exécutez la commande suivante pour créer un contrôleur CronJob qui actualise la source de données lors de l'initialisation, puis toutes les 10 minutes : Si vous utilisez Workload Identity Federation for GKE, la valeur de NAMESPACE_NAME doit correspondre au même espace de noms que celui que vous avez précédemment associé au compte de service.
curl https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/cmd/datasource-syncer/datasource-syncer.yaml \ | sed 's|$DATASOURCE_UIDS|'"$DATASOURCE_UIDS"'|; s|$GRAFANA_API_ENDPOINT|'"$GRAFANA_API_ENDPOINT"'|; s|$GRAFANA_API_TOKEN|'"$GRAFANA_API_TOKEN"'|; s|$PROJECT_ID|'"$PROJECT_ID"'|;' \ | kubectl -n NAMESPACE_NAME apply -f -
Accédez à la source de données Grafana que vous venez de configurer, puis vérifiez que la valeur de l'URL du serveur Prometheus commence par
https://monitoring.googleapis.com. Vous devrez peut-être actualiser la page. Une fois la validation effectuée, accédez au bas de la page et sélectionnez Enregistrer et tester. Vous devez sélectionner ce bouton au moins une fois pour vous assurer que la saisie semi-automatique des étiquettes dans Grafana fonctionne.
Exécuter des requêtes à l'aide de Grafana
Vous pouvez maintenant créer des tableaux de bord Grafana et exécuter des requêtes à l'aide de la source de données configurée. La capture d'écran suivante montre un graphique Grafana qui affiche la métrique up :
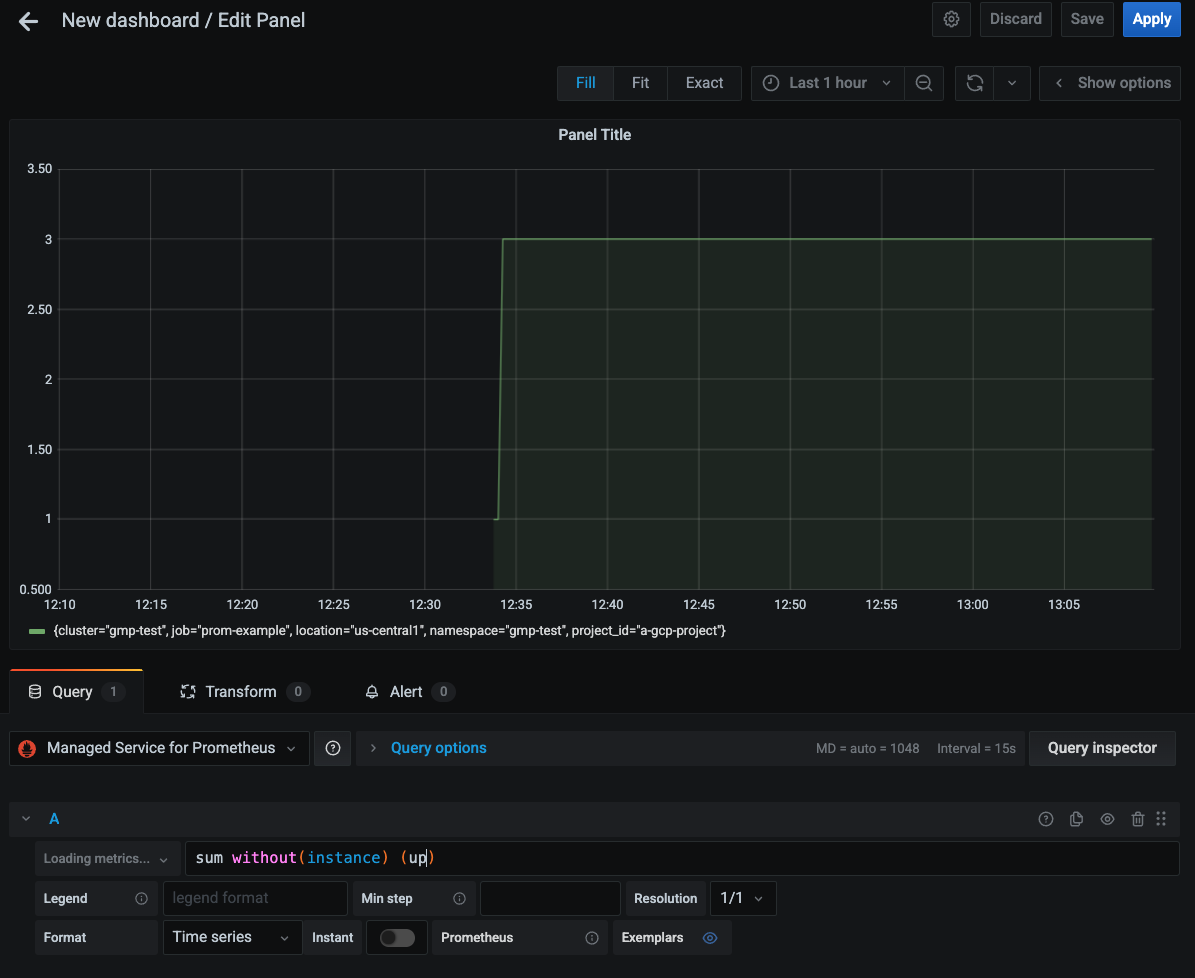
Pour en savoir plus sur l'interrogation des métriques systèmeGoogle Cloud à l'aide de PromQL, consultez la page PromQL pour les métriques Cloud Monitoring.
Exécuter le synchronisateur de sources de données en dehors de GKE
Si vous exécutez le synchronisateur de sources de données dans un cluster Google Kubernetes Engine ou si vous utilisez l'option sans serveur, vous pouvez ignorer cette section. Si vous rencontrez des problèmes d'authentification sur GKE, consultez la page Vérifier les identifiants du compte de service.
Lors de l'exécution sur GKE, le synchronisateur de sources de données récupère automatiquement les identifiants de l'environnement en fonction du compte de service du nœud ou de la configuration de Workload Identity Federation for GKE.
Dans les clusters Kubernetes non GKE, les identifiants doivent être explicitement fournis au synchronisateur de source de données à l'aide de la variable d'environnement GOOGLE_APPLICATION_CREDENTIALS.
Définissez le contexte de votre projet cible :
gcloud config set project PROJECT_ID
Créez un compte de service :
gcloud iam service-accounts create gmp-test-sa
Cette étape crée le compte de service que vous avez peut-être déjà créé dans les instructions de Workload Identity Federation for GKE.
Accordez les autorisations requises au compte de service :
gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.viewer \ && \ gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/iam.serviceAccountTokenCreator
Créez et téléchargez une clé pour le compte de service :
gcloud iam service-accounts keys create gmp-test-sa-key.json \ --iam-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
Définissez le chemin d'accès du fichier de clé à l'aide de la variable d'environnement
GOOGLE_APPLICATION_CREDENTIALS.
Autoriser le synchroniseur de sources de données à surveiller plusieurs projets
Managed Service pour Prometheus est compatible avec la surveillance multi-projets à l'aide de champs d'application de métriques.
Pour ceux qui utilisent l'option sans serveur, vous obtenez des requêtes multiprojets si le projet choisi est le projet de surveillance d'un champ d'application de métriques multiprojets.
Pour ceux qui déploient le synchronisateur de sources de données sur Kubernetes, si votre projet local est votre projet de surveillance et que vous avez suivi les instructions pour vérifier ou configurer un compte de service les requêtes multiprojets devraient fonctionner sans autre configuration.
Si votre projet local n'est pas votre projet de champ d'application, vous devez autoriser le compte de service Compute par défaut du projet local ou votre compte de service Workload Identity Federation for GKE pour disposer de l'accès monitoring.viewer au projet de champ d'application. Transmettez ensuite l'ID du projet de champ d'application en tant que valeur de la variable d'environnement PROJECT_ID.
Si vous utilisez le compte de service Compute Engine default, vous pouvez effectuer l'une des opérations suivantes :
Déployez le synchroniseur de sources de données dans un cluster appartenant à votre projet de champ d'application.
Activez Workload Identity Federation for GKE pour votre cluster et suivez les étapes de configuration.
Indiquez une clé de compte de service explicite.
Pour accorder à un compte de service les autorisations nécessaires pour accéder à un autre projet Google Cloud , procédez comme suit :
Accordez au compte de service l'autorisation de lire à partir du projet cible que vous souhaitez interroger :
gcloud projects add-iam-policy-binding SCOPING_PROJECT_ID \ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.viewer
Lors de la configuration du synchronisateur de sources de données, transmettez l'ID du projet de champ d'application en tant que valeur de la variable d'environnement
PROJECT_ID.
Inspecter le CronJob Kubernetes
Si vous déployez le synchronisateur de sources de données sur Kubernetes, vous pouvez inspecter la tâche Cron et vous assurer que toutes les variables sont correctement définies en exécutant la commande suivante :
kubectl describe cronjob datasource-syncer
Pour afficher les journaux de la tâche qui configure initialement Grafana, exécutez la commande suivante immédiatement après l'application du fichier datasource-syncer.yaml :
kubectl logs job.batch/datasource-syncer-init
Suppression
Pour désactiver la tâche Cron du synchronisateur de sources de données sur Kubernetes, exécutez la commande suivante :
kubectl delete -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/cmd/datasource-syncer/datasource-syncer.yaml
La désactivation du synchronisateur de sources de données cesse de mettre à jour le fichier Grafana associé avec de nouveaux identifiants d'authentification et, par conséquent, l'interrogation du service géré pour Prometheus ne fonctionne plus.
Compatibilité avec les API
Les points de terminaison de l'API HTTP Prometheus suivants sont compatibles avec Managed Service pour Prometheus sous l'URL précédée du préfixe https://monitoring.googleapis.com/v1/projects/PROJECT_ID/location/global/prometheus/api/v1/.
Pour obtenir la documentation complète, consultez la documentation de référence de l'API Cloud Monitoring. Les points de terminaison HTTP Prometheus ne sont pas disponibles dans les bibliothèques clientes Cloud Monitoring spécifiques à chaque langage.
Pour plus d'informations sur la compatibilité PromQL, consultez la page Compatibilité de PromQL.
Les points de terminaison suivants sont entièrement compatibles :
Le point de terminaison
/api/v1/label/<label_name>/valuesne fonctionne que si le libellé__name__est fourni en l'utilisant en tant que valeur<label_name>ou comme correspondance exacte dans le sélecteur de séries. Par exemple, les appels suivants sont entièrement compatibles :/api/v1/label/__name__/values/api/v1/label/__name__/values?match[]={__name__=~".*metricname.*"}/api/v1/label/labelname/values?match[]={__name__="metricname"}
Cette limitation entraîne l'échec des requêtes de variables
label_values($label)dans Grafana. Vous pouvez utiliserlabel_values($metric, $label)à la place. Ce type de requête est recommandé, car il évite de récupérer des valeurs d'étiquettes sur les métriques qui ne sont pas pertinentes pour le tableau de bord donné.Le point de terminaison
/api/v1/seriesest compatible avec les requêtesGET, mais pasPOST. Lorsque vous utilisez le synchronisateur de sources de données ou le proxy d'interface, cette restriction est gérée automatiquement. Vous pouvez également configurer vos sources de données Prometheus dans Grafana pour n'émettre que des requêtesGET. Le paramètrematch[]n'est pas compatible avec la correspondance des expressions régulières sur le libellé__name__.
Étape suivante
- Utilisez les alertes PromQL dans Cloud Monitoring.
- Configurez l'évaluation des règles gérées.
- Configurez des exportateurs couramment utilisés.