Google Cloud Managed Service for Prometheus mengenakan biaya untuk jumlah sampel yang di-ingest ke Cloud Monitoring dan untuk permintaan baca ke Monitoring API. Jumlah sampel yang diserap adalah kontributor utama biaya Anda.
Dokumen ini menjelaskan cara mengontrol biaya yang terkait dengan penyerapan metrik dan cara mengidentifikasi sumber penyerapan bervolume tinggi.
Untuk mengetahui informasi selengkapnya tentang harga Managed Service for Prometheus, lihat bagian Cloud Monitoring di halaman Harga Google Cloud Observability.
Melihat tagihan Anda
Untuk melihat Google Cloud tagihan, lakukan langkah berikut:
Di konsol Google Cloud , buka halaman Billing.
Jika Anda memiliki lebih dari satu akun penagihan, pilih Buka akun penagihan tertaut untuk melihat akun penagihan project saat ini. Untuk menemukan akun penagihan lain, pilih Kelola akun penagihan dan pilih akun yang ingin Anda dapatkan laporan penggunaannya.
Di bagian Pengelolaan biaya pada menu navigasi Penagihan, pilih Laporan.
Dari menu Services, pilih opsi Cloud Monitoring.
Dari menu SKU, pilih opsi berikut:
- Contoh Prometheus yang Di-Ingest
- Memantau Permintaan API
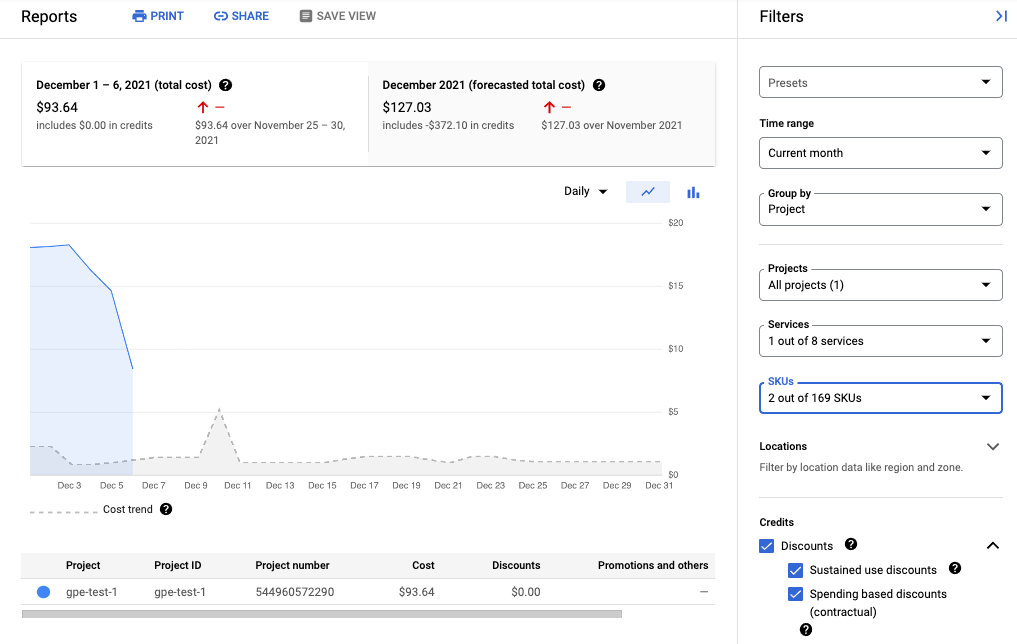
Screenshot berikut menunjukkan laporan penagihan untuk Managed Service for Prometheus dari satu project:
Mengurangi biaya
Untuk mengurangi biaya yang terkait dengan penggunaan Managed Service for Prometheus, Anda dapat melakukan hal berikut:
- Kurangi jumlah deret waktu yang Anda kirim ke layanan terkelola dengan memfilter data metrik yang Anda buat.
- Kurangi jumlah sampel yang Anda kumpulkan dengan mengubah interval scraping.
- Batasi jumlah sampel dari metrik berkardinalitas tinggi yang berpotensi salah dikonfigurasi.
Mengurangi jumlah deret waktu
Dokumentasi Prometheus open source jarang merekomendasikan pemfilteran volume metrik, yang wajar jika biaya dibatasi oleh biaya mesin. Namun, saat membayar penyedia layanan terkelola berdasarkan unit, pengiriman data tanpa batas dapat menyebabkan tagihan yang terlalu tinggi.
Exporter yang disertakan dalam project kube-prometheus—khususnya layanan kube-state-metrics—dapat memancarkan banyak data metrik.
Misalnya, layanan kube-state-metrics memancarkan ratusan metrik, yang sebagian besar mungkin tidak bernilai sama sekali bagi Anda sebagai konsumen. Cluster tiga node baru yang menggunakan project kube-prometheus mengirimkan sekitar 900 sampel per detik ke Managed Service for Prometheus.
Memfilter metrik yang tidak relevan ini mungkin cukup untuk menurunkan tagihan Anda ke tingkat yang dapat diterima.
Untuk mengurangi jumlah metrik, Anda dapat melakukan hal berikut:
- Ubah konfigurasi pengambilan data Anda untuk mengambil data lebih sedikit target.
- Filter metrik yang dikumpulkan seperti yang dijelaskan di bawah ini:
- Memfilter metrik yang diekspor saat menggunakan pengumpulan terkelola.
- Memfilter metrik yang diekspor saat menggunakan pengumpulan yang di-deploy sendiri.
Jika menggunakan layanan kube-state-metrics, Anda dapat menambahkan
aturan pelabelan ulang Prometheus dengan tindakan keep. Untuk koleksi terkelola, aturan ini masuk dalam definisi PodMonitoring atau
ClusterPodMonitoring Anda. Untuk pengumpulan yang di-deploy sendiri, aturan ini masuk ke scrape config Prometheus atau definisi ServiceMonitor (untuk prometheus-operator).
Misalnya, menggunakan filter berikut pada cluster tiga node baru akan mengurangi volume sampel Anda sekitar 125 sampel per detik:
metricRelabeling:
- action: keep
regex: kube_(daemonset|deployment|pod|namespace|node|statefulset|persistentvolume|horizontalpodautoscaler)_.+
sourceLabels: [__name__]
Filter sebelumnya menggunakan ekspresi reguler untuk menentukan metrik mana yang akan dipertahankan berdasarkan nama metrik. Misalnya, metrik yang namanya diawali dengan
kube_daemonset_ akan dipertahankan.
Anda juga dapat menentukan tindakan drop, yang memfilter metrik
yang cocok dengan ekspresi reguler.
Terkadang, Anda mungkin menganggap seluruh pengekspor tidak penting. Misalnya, paket kube-prometheus menginstal monitor layanan berikut secara default, yang sebagian besar tidak diperlukan dalam lingkungan terkelola:
alertmanagercorednsgrafanakube-apiserverkube-controller-managerkube-schedulerkube-state-metricskubeletnode-exporterprometheusprometheus-adapterprometheus-operator
Untuk mengurangi jumlah metrik yang Anda ekspor, Anda dapat menghapus, menonaktifkan, atau
berhenti meng-scraping monitor layanan yang tidak Anda perlukan. Misalnya, menonaktifkan
monitor layanan kube-apiserver pada cluster tiga node baru akan mengurangi
volume sampel Anda sekitar 200 sampel per detik.
Mengurangi jumlah sampel yang dikumpulkan
Managed Service for Prometheus mengenakan biaya per sampel. Anda dapat mengurangi jumlah sampel yang diserap dengan meningkatkan durasi periode pengambilan sampel. Contoh:
- Mengubah periode pengambilan sampel 10 detik menjadi 30 detik dapat mengurangi volume sampel Anda sebesar 66%, tanpa banyak kehilangan informasi.
- Mengubah periode pengambilan sampel 10 detik menjadi periode pengambilan sampel 60 detik dapat mengurangi volume sampel Anda sebesar 83%.
Untuk mengetahui informasi tentang cara penghitungan sampel dan pengaruh periode pengambilan sampel terhadap jumlah sampel, lihat Data metrik yang ditagih berdasarkan sampel yang diserap.
Anda biasanya dapat menyetel interval scraping per tugas atau per target.
Untuk koleksi terkelola, Anda menetapkan interval pengambilan data di
resource PodMonitoring menggunakan kolom interval.
Untuk pengumpulan yang di-deploy sendiri, Anda menetapkan interval pengambilan sampel di scrape
configs, biasanya
dengan menetapkan kolom interval atau scrape_interval.
Mengonfigurasi agregasi lokal (hanya pengumpulan yang di-deploy sendiri)
Jika Anda mengonfigurasi layanan menggunakan pengumpulan yang di-deploy sendiri, misalnya dengan kube-prometheus, prometheus-operator, atau dengan men-deploy image secara manual, Anda dapat mengurangi sampel yang dikirim ke Managed Service for Prometheus dengan menggabungkan metrik kardinalitas tinggi secara lokal. Anda dapat
menggunakan aturan perekaman untuk menggabungkan label seperti instance dan menggunakan
flag --export.match atau variabel lingkungan EXTRA_ARGS untuk hanya mengirim data gabungan ke
Monarch.
Misalnya, Anda memiliki tiga metrik, high_cardinality_metric_1, high_cardinality_metric_2,
dan low_cardinality_metric. Anda ingin mengurangi sampel yang dikirim untuk
high_cardinality_metric_1 dan menghapus semua sampel yang dikirim untuk
high_cardinality_metric_2, sambil menyimpan semua data mentah yang disimpan secara lokal (mungkin
untuk tujuan pemberitahuan). Penyiapan Anda mungkin terlihat seperti ini:
- Deploy image Managed Service for Prometheus.
- Konfigurasi konfigurasi scraping Anda untuk meng-scrape semua data mentah ke server lokal (menggunakan sesedikit mungkin filter yang diinginkan).
Konfigurasi aturan perekaman Anda untuk menjalankan agregasi lokal pada
high_cardinality_metric_1danhigh_cardinality_metric_2, mungkin dengan mengagregasi labelinstanceatau sejumlah label metrik, bergantung pada apa yang memberikan pengurangan terbaik dalam jumlah deret waktu yang tidak diperlukan. Anda dapat menjalankan aturan yang terlihat seperti berikut, yang menghilangkan labelinstancedan menjumlahkan deret waktu yang dihasilkan di seluruh label yang tersisa:record: job:high_cardinality_metric_1:sum expr: sum without (instance) (high_cardinality_metric_1)
Lihat operator agregasi dalam dokumentasi Prometheus untuk opsi agregasi lainnya.
Deploy image Managed Service for Prometheus dengan flag filter berikut, yang mencegah data mentah dari metrik yang tercantum dikirim ke Monarch:
--export.match='{__name__!="high_cardinality_metric_1",__name__!="high_cardinality_metric_2"}'Contoh tanda
export.matchini menggunakan pemilih yang dipisahkan koma dengan operator!=untuk memfilter data mentah yang tidak diinginkan. Jika Anda menambahkan aturan perekaman tambahan untuk menggabungkan metrik kardinalitas tinggi lainnya, Anda juga harus menambahkan pemilih__name__baru ke filter agar data mentah dihapus. Dengan menggunakan satu tanda yang berisi beberapa pemilih dengan operator!=untuk memfilter data yang tidak diinginkan, Anda hanya perlu mengubah filter saat membuat agregasi baru, bukan setiap kali Anda mengubah atau menambahkan konfigurasi pengambilan data.Metode deployment tertentu, seperti prometheus-operator, mungkin mengharuskan Anda menghilangkan tanda kutip tunggal yang mengapit tanda kurung.
Alur kerja ini mungkin menimbulkan beberapa overhead operasional dalam membuat dan mengelola aturan perekaman dan tanda export.match, tetapi kemungkinan Anda dapat mengurangi banyak volume dengan hanya berfokus pada metrik dengan kardinalitas yang sangat tinggi. Untuk
mengetahui informasi tentang cara mengidentifikasi metrik mana yang paling diuntungkan dari pra-agregasi lokal, lihat Mengidentifikasi metrik bervolume tinggi.
Jangan menerapkan federasi saat menggunakan Managed Service for Prometheus. Alur kerja ini membuat penggunaan server federasi menjadi tidak relevan, karena satu server Prometheus yang di-deploy sendiri dapat melakukan agregasi tingkat cluster yang mungkin Anda perlukan. Federasi dapat menyebabkan efek yang tidak terduga seperti metrik yang diketik "tidak diketahui" dan volume penyerapan ganda.
Membatasi sampel dari metrik berkardinalitas tinggi (hanya pengumpulan yang di-deploy sendiri)
Anda dapat membuat metrik dengan kardinalitas sangat tinggi dengan menambahkan label yang memiliki
sejumlah besar kemungkinan nilai, seperti ID pengguna atau alamat IP. Metrik
tersebut dapat menghasilkan sampel dalam jumlah yang sangat besar. Menggunakan label
dengan sejumlah besar nilai biasanya merupakan kesalahan konfigurasi. Anda dapat
melindungi diri dari metrik kardinalitas tinggi di pengumpul yang di-deploy sendiri
dengan menetapkan nilai sample_limit
di konfigurasi pengambilan data.
Jika Anda menggunakan batas ini, sebaiknya tetapkan ke nilai yang sangat tinggi, sehingga hanya menangkap metrik yang jelas salah konfigurasinya. Contoh yang melebihi batas akan dihapus, dan akan sangat sulit untuk mendiagnosis masalah yang disebabkan oleh melebihi batas.
Penggunaan batas sampel bukanlah cara yang baik untuk mengelola penyerapan sampel, tetapi batas tersebut dapat melindungi Anda dari kesalahan konfigurasi yang tidak disengaja. Untuk mengetahui informasi selengkapnya, lihat Menggunakan sample_limit untuk menghindari kelebihan beban.
Mengidentifikasi dan mengatribusikan biaya
Anda dapat menggunakan Cloud Monitoring untuk mengidentifikasi metrik Prometheus yang menulis jumlah sampel terbesar. Metrik ini paling berkontribusi terhadap biaya Anda. Setelah mengidentifikasi metrik yang paling mahal, Anda dapat mengubah konfigurasi pengambilan data untuk memfilter metrik ini dengan tepat.
Halaman Pengelolaan Metrik Cloud Monitoring memberikan informasi yang dapat membantu Anda mengontrol jumlah yang Anda belanjakan untuk metrik yang dapat ditagih tanpa memengaruhi kemampuan pengamatan. Halaman Pengelolaan Metrik melaporkan informasi berikut:
- Volume penyerapan untuk penagihan berbasis byte dan sampel, di seluruh domain metrik dan untuk setiap metrik.
- Data tentang label dan kardinalitas metrik.
- Jumlah pembacaan untuk setiap metrik.
- Penggunaan metrik dalam kebijakan pemberitahuan dan dasbor kustom.
- Rasio error penulisan metrik.
Anda juga dapat menggunakan halaman Pengelolaan Metrik untuk mengecualikan metrik yang tidak diperlukan, sehingga menghilangkan biaya penyerapan metrik tersebut.
Untuk melihat halaman Pengelolaan Metrik, lakukan hal berikut:
-
Di konsol Google Cloud , buka halaman Pengelolaan metrik:
Jika Anda menggunakan kotak penelusuran untuk menemukan halaman ini, pilih hasil yang subjudulnya adalah Monitoring.
- Di toolbar, pilih rentang waktu Anda. Secara default, halaman Pengelolaan Metrik menampilkan informasi tentang metrik yang dikumpulkan dalam satu hari sebelumnya.
Untuk mengetahui informasi selengkapnya tentang halaman Pengelolaan Metrik, lihat Melihat dan mengelola penggunaan metrik.
Bagian berikut menjelaskan cara menganalisis jumlah sampel yang Anda kirim ke Managed Service for Prometheus dan mengatribusikan volume tinggi ke metrik, namespace Kubernetes, dan Google Cloud region tertentu.
Mengidentifikasi metrik volume tinggi
Untuk mengidentifikasi metrik Prometheus dengan volume penyerapan terbesar, lakukan hal berikut:
-
Di konsol Google Cloud , buka halaman Pengelolaan metrik:
Jika Anda menggunakan kotak penelusuran untuk menemukan halaman ini, pilih hasil yang subjudulnya adalah Monitoring.
- Pada kartu skor Contoh yang dapat ditagih yang di-ingest, klik Lihat diagram.
- Cari diagram Penyerapan Volume Namespace, lalu klik more_vert Opsi diagram lainnya.
- Pilih opsi diagram Lihat di Metrics Explorer.
- Di panel Builder pada Metrics Explorer, ubah kolom
sebagai berikut:
- Di kolom Metrik, pastikan resource dan
dan metrik berikut dipilih:
Metric Ingestion AttributiondanSamples written by attribution id. - Untuk kolom Agregasi, pilih
sum. - Untuk kolom oleh, pilih
label berikut:
attribution_dimensionmetric_type
- Untuk kolom Filter, gunakan
attribution_dimension = namespace. Anda harus melakukannya setelah menggabungkan menurut labelattribution_dimension.
Diagram yang dihasilkan menunjukkan volume penyerapan untuk setiap jenis metrik.
- Di kolom Metrik, pastikan resource dan
dan metrik berikut dipilih:
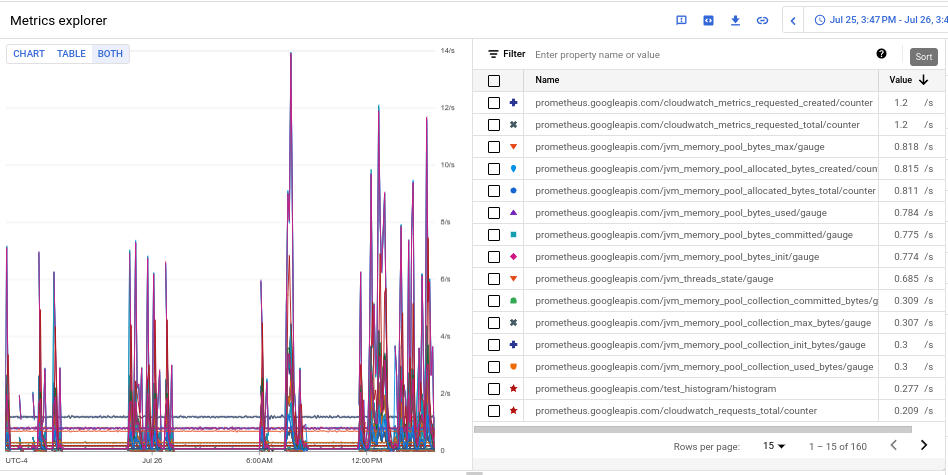
- Untuk melihat volume penyerapan setiap metrik, di tombol berlabel Chart Table Both, pilih Both. Tabel ini menampilkan volume yang di-ingest untuk setiap metrik di kolom Nilai.
- Klik header kolom Nilai dua kali untuk mengurutkan metrik berdasarkan volume penyerapan menurun.
Diagram yang dihasilkan, yang menampilkan metrik teratas Anda menurut volume yang diurutkan berdasarkan rata-rata, akan terlihat seperti screenshot berikut:
Mengidentifikasi namespace dengan volume tinggi
Untuk mengatribusikan volume penyerapan ke namespace Kubernetes tertentu, lakukan hal berikut:
-
Di konsol Google Cloud , buka halaman Pengelolaan metrik:
Jika Anda menggunakan kotak penelusuran untuk menemukan halaman ini, pilih hasil yang subjudulnya adalah Monitoring.
- Pada kartu skor Contoh yang dapat ditagih yang di-ingest, klik Lihat diagram.
- Cari diagram Penyerapan Volume Namespace, lalu klik more_vert Opsi diagram lainnya.
- Pilih opsi diagram Lihat di Metrics Explorer.
- Di panel Builder di Metrics Explorer, ubah kolom
sebagai berikut:
- Di kolom Metrik, pastikan resource dan
metrik berikut dipilih:
Metric Ingestion AttributiondanSamples written by attribution id. - Konfigurasi parameter kueri lainnya sebagaimana mestinya:
- Untuk mengorelasikan volume penyerapan keseluruhan dengan namespace:
- Untuk kolom Agregasi, pilih
sum. - Untuk kolom oleh, pilih
label berikut:
attribution_dimensionattribution_id
- Untuk kolom Filter, gunakan
attribution_dimension = namespace.
- Untuk kolom Agregasi, pilih
- Untuk mengorelasikan volume penyerapan setiap metrik dengan
namespace:
- Untuk kolom Agregasi, pilih
sum. - Untuk kolom oleh, pilih
label berikut:
attribution_dimensionattribution_idmetric_type
- Untuk kolom Filter, gunakan
attribution_dimension = namespace.
- Untuk kolom Agregasi, pilih
- Untuk mengidentifikasi namespace yang bertanggung jawab atas metrik
volume tinggi tertentu:
- Identifikasi jenis metrik untuk metrik volume tinggi dengan
menggunakan salah satu contoh lainnya untuk mengidentifikasi jenis
metrik volume tinggi. Jenis metrik adalah string dalam tampilan
tabel yang dimulai dengan
prometheus.googleapis.com/. Untuk mengetahui informasi selengkapnya, lihat Mengidentifikasi metrik bervolume tinggi. - Batasi data diagram ke jenis metrik yang diidentifikasi dengan
menambahkan filter untuk jenis metrik di kolom
Filter. Misalnya:
metric_type= prometheus.googleapis.com/container_tasks_state/gauge. - Untuk kolom Agregasi, pilih
sum. - Untuk kolom oleh, pilih
label berikut:
attribution_dimensionattribution_id
- Untuk kolom Filter, gunakan
attribution_dimension = namespace.
- Identifikasi jenis metrik untuk metrik volume tinggi dengan
menggunakan salah satu contoh lainnya untuk mengidentifikasi jenis
metrik volume tinggi. Jenis metrik adalah string dalam tampilan
tabel yang dimulai dengan
- Untuk melihat penyerapan menurut Google Cloud wilayah, tambahkan
label
locationke kolom menurut. - Untuk melihat penyerapan menurut Google Cloud project, tambahkan
label
resource_containerke kolom menurut.
- Untuk mengorelasikan volume penyerapan keseluruhan dengan namespace:
- Di kolom Metrik, pastikan resource dan
metrik berikut dipilih: