Google Cloud Managed Service para Prometheus cobra por el número de muestras ingeridas en Cloud Monitoring y por las solicitudes de lectura a la API de Monitoring. El número de muestras ingeridas es el factor que más influye en el coste.
En este documento se describe cómo puede controlar los costes asociados a la ingestión de métricas y cómo identificar las fuentes de ingestión de gran volumen.
Para obtener más información sobre los precios de Managed Service for Prometheus, consulta las secciones de Cloud Monitoring de la página Precios de Google Cloud Observability.
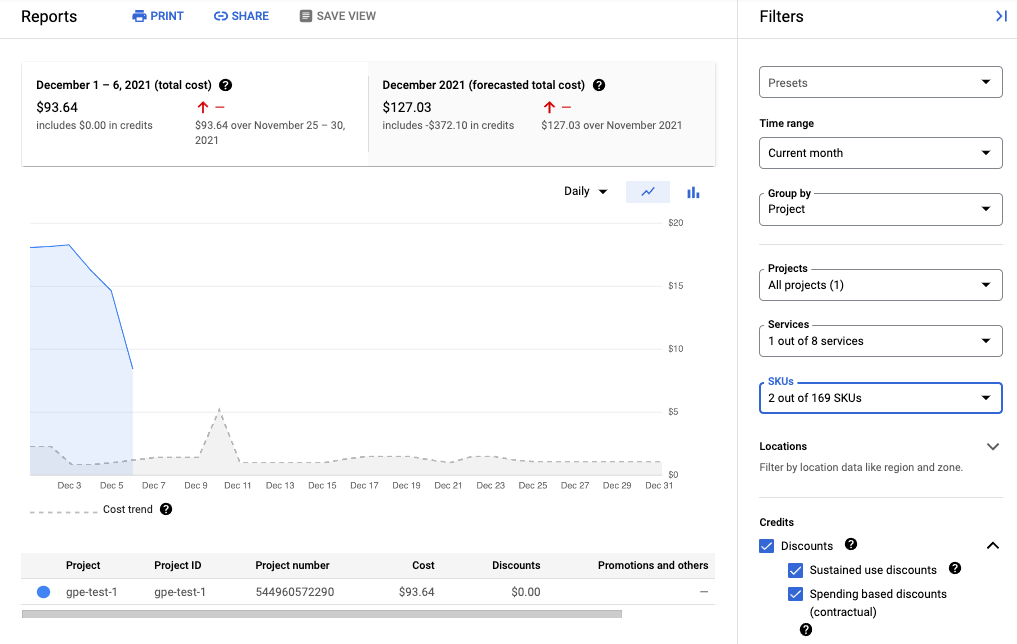
Ver tu factura
Para ver tu Google Cloud factura, sigue estos pasos:
En la Google Cloud consola, ve a la página Facturación.
Si tienes más de una cuenta de facturación, selecciona Ir a la cuenta de facturación vinculada para ver la cuenta de facturación del proyecto actual. Si quieres acceder a otra cuenta de facturación, haz clic en Gestionar cuentas de facturación y elige la cuenta de la que quieras obtener informes de uso.
En la sección Gestión de costes del menú de navegación Facturación, selecciona Informes.
En el menú Servicios, selecciona la opción Cloud Monitoring.
En el menú SKUs (SKUs), selecciona las siguientes opciones:
- Muestras de Prometheus ingeridas
- Monitorizar solicitudes de API
En la siguiente captura de pantalla se muestra el informe de facturación de Managed Service para Prometheus de un proyecto:
Reduce tus costes
Para reducir los costes asociados al uso de Managed Service para Prometheus, puedes hacer lo siguiente:
- Reduzca el número de series temporales que envía al servicio gestionado filtrando los datos de métricas que genera.
- Reduzca el número de muestras que recoge cambiando el intervalo de raspado.
- Limita el número de muestras de métricas de alta cardinalidad que puedan estar mal configuradas.
Reducir el número de series temporales
En la documentación de Prometheus de código abierto, rara vez se recomienda filtrar el volumen de métricas, lo cual es razonable cuando los costes están limitados por los costes de las máquinas. Sin embargo, si pagas a un proveedor de servicios gestionados por unidad, enviar datos ilimitados puede generar facturas innecesariamente altas.
Los exportadores incluidos en el proyecto kube-prometheus
(en concreto, el servicio kube-state-metrics
) pueden emitir una gran cantidad de datos de métricas.
Por ejemplo, el servicio kube-state-metrics emite cientos de métricas, muchas de las cuales pueden no tener ningún valor para ti como consumidor. Un clúster nuevo de tres nodos que usa el proyecto kube-prometheus envía aproximadamente 900 muestras por segundo a Managed Service para Prometheus.
Filtrar estas métricas superfluas puede ser suficiente para que tu factura alcance un nivel aceptable.
Para reducir el número de métricas, puede hacer lo siguiente:
- Modifica tus configuraciones de raspado para raspar menos destinos.
- Filtre las métricas recogidas tal como se describe a continuación:
- Filtra las métricas exportadas cuando uses la colección gestionada.
- Filtra las métricas exportadas cuando utilices la recogida autodesplegada.
Si usas el servicio kube-state-metrics, puedes añadir una regla de reetiquetado de Prometheus con una keep
acción. En el caso de la recogida gestionada, esta regla se incluye en la definición de PodMonitoring o ClusterPodMonitoring. En el caso de la recogida autodesplegada, esta regla se incluye en tu scrape_config de Prometheus o en tu definición de ServiceMonitor (en el caso de prometheus-operator).
Por ejemplo, si usa el siguiente filtro en un clúster nuevo de tres nodos, el volumen de muestra se reducirá en aproximadamente 125 muestras por segundo:
metricRelabeling:
- action: keep
regex: kube_(daemonset|deployment|pod|namespace|node|statefulset|persistentvolume|horizontalpodautoscaler)_.+
sourceLabels: [__name__]
El filtro anterior usa una expresión regular para especificar qué métricas se deben conservar en función del nombre de la métrica. Por ejemplo, se conservan las métricas cuyo nombre empieza por
kube_daemonset_.
También puede especificar la acción drop, que excluye las métricas que coinciden con la expresión regular.
En ocasiones, puede que un exportador completo no te parezca importante. Por ejemplo, el paquete kube-prometheus instala los siguientes monitores de servicio de forma predeterminada, muchos de los cuales no son necesarios en un entorno gestionado:
alertmanagercorednsgrafanakube-apiserverkube-controller-managerkube-schedulerkube-state-metricskubeletnode-exporterprometheusprometheus-adapterprometheus-operator
Para reducir el número de métricas que exporta, puede eliminar, inhabilitar o dejar de monitorizar los servicios que no necesite. Por ejemplo, si inhabilita el monitor de servicios kube-apiserver en un clúster de tres nodos nuevo, el volumen de muestras se reducirá en aproximadamente 200 muestras por segundo.
Reducir el número de muestras recogidas
Managed Service para Prometheus se factura por muestra. Puede reducir el número de muestras ingeridas aumentando la duración del periodo de muestreo. Por ejemplo:
- Si cambias un periodo de muestreo de 10 segundos a 30 segundos, puedes reducir el volumen de muestras en un 66 % sin perder mucha información.
- Si cambias el periodo de muestreo de 10 a 60 segundos, puedes reducir el volumen de la muestra en un 83%.
Para obtener información sobre cómo se contabilizan las muestras y cómo afecta el periodo de muestreo al número de muestras, consulta Datos de métricas facturados por muestras ingeridas.
Por lo general, puedes definir el intervalo de raspado por tarea o por objetivo.
En el caso de la recogida gestionada, el intervalo de raspado se define en el recurso PodMonitoring mediante el campo interval.
En el caso de la recogida autodesplegada, debes definir el intervalo de muestreo en scrape
configs, normalmente
definiendo un campo interval o scrape_interval.
Configurar la agregación local (solo para la recogida con despliegue automático)
Si configuras el servicio mediante la recogida autodesplegada, por ejemplo, con kube-prometheus, prometheus-operator o desplegando la imagen manualmente, puedes reducir las muestras enviadas a Managed Service para Prometheus agregando métricas de alta cardinalidad de forma local. Puedes usar reglas de registro para agregar etiquetas como instance y usar la marca --export.match o la variable de entorno EXTRA_ARGS para enviar solo datos agregados a Monarch.
Por ejemplo, supongamos que tienes tres métricas: high_cardinality_metric_1, high_cardinality_metric_2 y low_cardinality_metric. Quieres reducir las muestras enviadas para high_cardinality_metric_1 y eliminar todas las muestras enviadas para high_cardinality_metric_2, pero conservar todos los datos sin procesar almacenados localmente (quizá para enviar alertas). Tu configuración podría tener un aspecto similar a este:
- Despliega la imagen de Managed Service para Prometheus.
- Configura tus configs de raspado para que raspen todos los datos sin procesar en el servidor local (con los filtros que quieras).
Configura tus reglas de registro para que ejecuten agregaciones locales en
high_cardinality_metric_1yhigh_cardinality_metric_2. Por ejemplo, puedes agregar la etiquetainstanceo cualquier número de etiquetas de métricas, en función de lo que te permita reducir al máximo el número de series temporales innecesarias. Puede ejecutar una regla como la siguiente, que elimina la etiquetainstancey suma la serie temporal resultante en las etiquetas restantes:record: job:high_cardinality_metric_1:sum expr: sum without (instance) (high_cardinality_metric_1)
Consulta más opciones de agregación en la documentación de Prometheus sobre operadores de agregación.
Implementa la imagen de Managed Service para Prometheus con la siguiente marca de filtro, que impide que los datos sin procesar de las métricas indicadas se envíen a Monarch:
--export.match='{__name__!="high_cardinality_metric_1",__name__!="high_cardinality_metric_2"}'En este ejemplo, la marca
export.matchusa selectores separados por comas con el operador!=para excluir los datos sin procesar no deseados. Si añade reglas de registro adicionales para agregar otras métricas de alta cardinalidad, también debe añadir un nuevo selector__name__al filtro para que se descarten los datos sin procesar. Si usas una sola marca que contenga varios selectores con el operador!=para excluir datos no deseados, solo tendrás que modificar el filtro cuando crees una agregación en lugar de cada vez que modifiques o añadas una configuración de raspado.Es posible que algunos métodos de implementación, como el operador de Prometheus, requieran que omitas las comillas simples que rodean los corchetes.
Este flujo de trabajo puede conllevar algunos costes operativos al crear y gestionar reglas de registro y marcas export.match, pero es probable que puedas reducir mucho el volumen centrándote solo en las métricas con una cardinalidad excepcionalmente alta. Para obtener información sobre cómo identificar las métricas que pueden beneficiarse más de la preagregación local, consulta Identificar métricas de gran volumen.
No implementes la federación cuando uses Managed Service para Prometheus. Este flujo de trabajo hace que los servidores de federación sean obsoletos, ya que un único servidor de Prometheus autodesplegado puede realizar cualquier agregación a nivel de clúster que necesites. La federación puede provocar efectos inesperados, como métricas de tipo "desconocido" y duplicar el volumen de ingesta.
Limitar las muestras de métricas de alta cardinalidad (solo para la recogida autodesplegada)
Puede crear métricas de cardinalidad extremadamente alta añadiendo etiquetas que tengan un gran número de valores posibles, como un ID de usuario o una dirección IP. Estas métricas pueden generar un número muy elevado de muestras. Usar etiquetas con un gran número de valores suele ser un error de configuración. Puedes protegerte frente a las métricas de alta cardinalidad en tus colectores autodesplegados
definiendo un valor sample_limit
en tus configuraciones de raspado.
Si usas este límite, te recomendamos que lo definas con un valor muy alto para que solo detecte las métricas que estén claramente mal configuradas. Se descartarán las muestras que superen el límite y será muy difícil diagnosticar los problemas causados por excederlo.
Usar un límite de muestra no es una buena forma de gestionar la ingesta de muestras, pero el límite puede protegerte frente a errores de configuración accidentales. Para obtener más información, consulta el artículo sobre cómo usar sample_limit para evitar la sobrecarga.
Identificar y atribuir costes
Puedes usar Cloud Monitoring para identificar las métricas de Prometheus que escriben el mayor número de muestras. Estas métricas son las que más contribuyen a tus costes. Una vez que haya identificado las métricas más caras, puede modificar sus configuraciones de raspado para filtrar estas métricas de forma adecuada.
La página Gestión de métricas de Cloud Monitoring proporciona información que puede ayudarte a controlar el importe que gastas en métricas facturables sin que esto afecte a la observabilidad. En la página Gestión de métricas se muestra la siguiente información:
- Volúmenes de ingesta para la facturación basada en bytes y en muestras, en todos los dominios de métricas y para métricas concretas.
- Datos sobre las etiquetas y la cardinalidad de las métricas.
- Número de lecturas de cada métrica.
- Uso de métricas en políticas de alertas y paneles de control personalizados.
- Tasa de errores de escritura de métricas.
También puede usar la página Gestión de métricas para excluir las métricas que no necesite y, de esta forma, no incurrir en los costes de ingesta.
Para ver la página Gestión de métricas, haz lo siguiente:
-
En la Google Cloud consola, ve a la página Gestión de métricas:
Si usas la barra de búsqueda para encontrar esta página, selecciona el resultado cuya sección sea Monitorización.
- En la barra de herramientas, selecciona el periodo que quieras. De forma predeterminada, la página Gestión de métricas muestra información sobre las métricas recogidas en el día anterior.
Para obtener más información sobre la página Gestión de métricas, consulta el artículo Ver y gestionar el uso de métricas.
En las siguientes secciones se describen formas de analizar el número de muestras que envías a Managed Service para Prometheus y de atribuir un volumen alto a métricas, espacios de nombres de Kubernetes y Google Cloud regiones específicos.
Identificar métricas de gran volumen
Para identificar las métricas de Prometheus con los volúmenes de ingestión más grandes, haz lo siguiente:
-
En la Google Cloud consola, ve a la página Gestión de métricas:
Si usas la barra de búsqueda para encontrar esta página, selecciona el resultado cuya sección sea Monitorización.
- En la tarjeta de resultados Muestras facturables ingeridas, haga clic en Ver gráficos.
- Busca el gráfico Ingestión de volumen de espacio de nombres y haz clic en more_vert Más opciones de gráfico.
- Seleccione la opción de gráfico Ver en Explorador de métricas.
- En el panel Creador del explorador de métricas, modifica los campos de la siguiente manera:
- En el campo Métrica, comprueba que estén seleccionados los siguientes recursos y métricas:
Metric Ingestion AttributionySamples written by attribution id. - En el campo Agregación, selecciona
sum. - En el campo por, selecciona las siguientes etiquetas:
attribution_dimensionmetric_type
- En el campo Filtro, usa
attribution_dimension = namespace. Debes hacerlo después de agregar los datos por la etiquetaattribution_dimension.
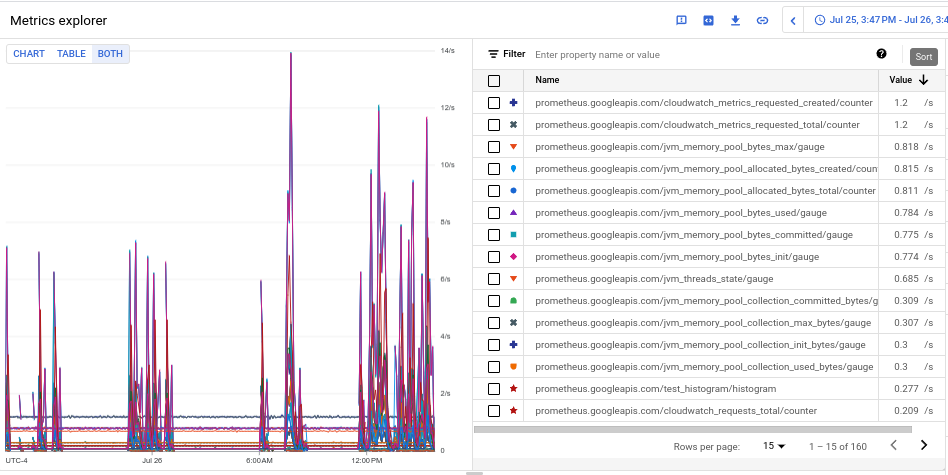
En el gráfico resultante se muestran los volúmenes de ingestión de cada tipo de métrica.
- En el campo Métrica, comprueba que estén seleccionados los siguientes recursos y métricas:
- Para ver el volumen de ingesta de cada métrica, en el activa el interruptor Gráfico, tabla o ambos y selecciona Ambos. En la tabla se muestra el volumen ingerido de cada métrica en la columna Valor.
- Haga clic dos veces en el encabezado de la columna Valor para ordenar las métricas por volumen de ingestión descendente.
El gráfico resultante, que muestra las métricas principales por volumen ordenadas por media, tiene el siguiente aspecto:
Identificar espacios de nombres con mucho volumen
Para atribuir el volumen de ingestión a espacios de nombres de Kubernetes específicos, haz lo siguiente:
-
En la Google Cloud consola, ve a la página Gestión de métricas:
Si usas la barra de búsqueda para encontrar esta página, selecciona el resultado cuya sección sea Monitorización.
- En la tarjeta de resultados Muestras facturables ingeridas, haga clic en Ver gráficos.
- Busca el gráfico Ingestión de volumen de espacio de nombres y haz clic en more_vert Más opciones de gráfico.
- Seleccione la opción de gráfico Ver en Explorador de métricas.
- En el panel Creador de Explorador de métricas, modifique los campos de la siguiente manera:
- En el campo Métrica, comprueba que se hayan seleccionado los siguientes recursos y métricas:
Metric Ingestion AttributionySamples written by attribution id. - Configure el resto de los parámetros de consulta según corresponda:
- Para correlacionar el volumen de ingestión general con los espacios de nombres, sigue estos pasos:
- En el campo Agregación, selecciona
sum. - En el campo por, selecciona las siguientes etiquetas:
attribution_dimensionattribution_id
- En el campo Filtro, usa
attribution_dimension = namespace.
- En el campo Agregación, selecciona
- Para correlacionar el volumen de ingestión de métricas individuales con espacios de nombres, sigue estos pasos:
- En el campo Agregación, selecciona
sum. - En el campo por, selecciona las siguientes etiquetas:
attribution_dimensionattribution_idmetric_type
- En el campo Filtro, usa
attribution_dimension = namespace.
- En el campo Agregación, selecciona
- Para identificar los espacios de nombres responsables de una métrica de gran volumen específica, haz lo siguiente:
- Identifica el tipo de métrica de gran volumen siguiendo uno de los otros ejemplos. El tipo de métrica es la cadena de la tabla
que empieza por
prometheus.googleapis.com/. Para obtener más información, consulta el artículo Identificar métricas de gran volumen. - Restringe los datos del gráfico al tipo de métrica identificado añadiendo un filtro para el tipo de métrica en el campo Filtro. Por ejemplo:
metric_type= prometheus.googleapis.com/container_tasks_state/gauge. - En el campo Agregación, selecciona
sum. - En el campo por, selecciona las siguientes etiquetas:
attribution_dimensionattribution_id
- En el campo Filtro, usa
attribution_dimension = namespace.
- Identifica el tipo de métrica de gran volumen siguiendo uno de los otros ejemplos. El tipo de métrica es la cadena de la tabla
que empieza por
- Para ver la ingestión por Google Cloud región, añade la etiqueta
locational campo por. - Para ver la ingesta por Google Cloud proyecto, añade la etiqueta
resource_containeral campo Por.
- Para correlacionar el volumen de ingestión general con los espacios de nombres, sigue estos pasos:
- En el campo Métrica, comprueba que se hayan seleccionado los siguientes recursos y métricas: