Google Cloud Managed Service for Prometheus berechnet die Anzahl der in Cloud Monitoring aufgenommenen Beispiele sowie die Leseanfragen an die Monitoring API. Die Anzahl der aufgenommenen Stichproben ist der Hauptfaktor für Ihre Kosten.
In diesem Dokument wird beschrieben, wie Sie die mit der Messwertaufnahme verbundenen Kosten steuern und Quellen für die Aufnahme großer Datenmengen identifizieren können.
Weitere Informationen zu den Preisen für Managed Service for Prometheus finden Sie auf der Seite Google Cloud Observability-Preise im Abschnitt zu Cloud Monitoring.
Rechnung ansehen
So rufen Sie Ihre Google Cloud Rechnung auf:
Rufen Sie in der Google Cloud Console die Seite Abrechnung auf.
Wenn Sie mehrere Rechnungskonten haben und das Rechnungskonto des aktuellen Projekts aufrufen möchten, wählen Sie Zum verknüpften Rechnungskonto aus. Wenn Sie lieber ein anderes Rechnungskonto aufrufen möchten, wählen Sie Rechnungskonten verwalten und anschließend das Konto aus, für das Sie Nutzungsberichte abrufen möchten.
Wählen Sie im Navigationsmenü „Abrechnung” im Abschnitt Kostenverwaltung die Option Berichte aus.
Wählen Sie im Menü Dienste die Option Cloud Monitoring aus.
Wählen Sie im Menü SKUs die folgenden Optionen aus:
- Aufgenommene Prometheus-Stichproben
- Monitoring API-Anfragen
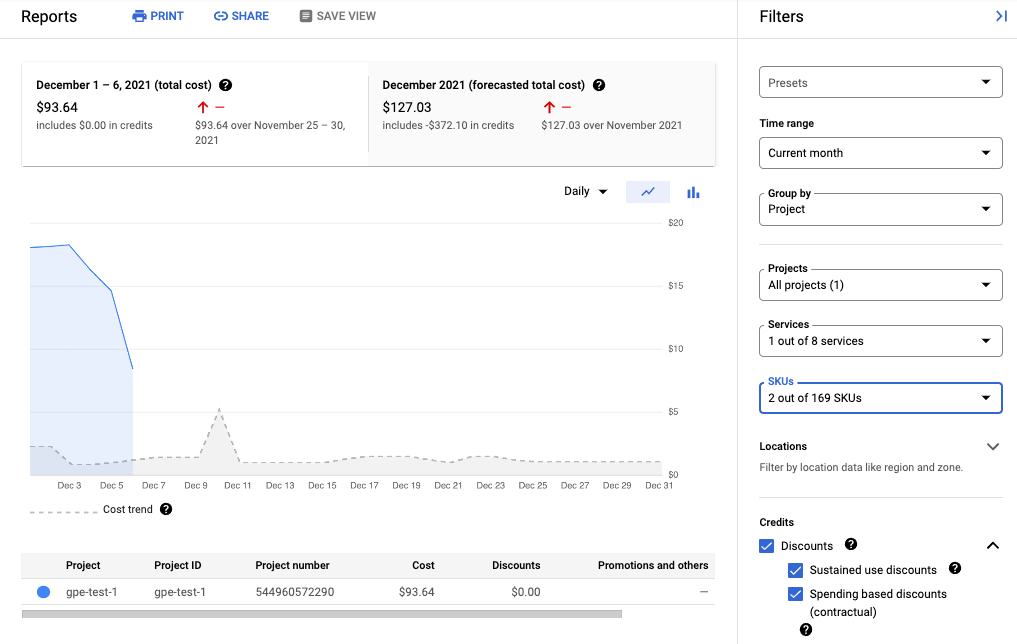
Der folgende Screenshot zeigt den Abrechnungsbericht für Managed Service for Prometheus aus einem Projekt:
Kosten senken
So können Sie die Kosten für die Verwendung von Managed Service for Prometheus reduzieren:
- Reduzieren Sie die Anzahl der Zeitachsen, die Sie an den verwalteten Dienst senden, indem Sie die generierten Messwertdaten filtern.
- Reduzieren Sie die Anzahl der Stichproben, die Sie erfassen, indem Sie das Extraktionsintervall ändern.
- Begrenzen Sie die Anzahl der Stichproben von potenziell falsch konfigurierten Messwerten mit hoher Kardinalität.
Anzahl der Zeitachsen reduzieren
Die Open-Source-Prometheus-Dokumentation empfiehlt selten das Filtern des Messwertvolumens, was sinnvoll ist, wenn die Kosten durch Maschinenkosten begrenzt sind. Wenn Sie jedoch einen Anbieter für verwaltete Dienste auf Basis einzelner Einheiten bezahlen, kann das Senden unbegrenzter Daten zu unnötig hohen Kosten führen.
Die im Projekt kube-prometheus enthaltenen Exporter, insbesondere der Dienst kube-state-metrics, können viele Messwertdaten ausgeben.
Der Dienst kube-state-metrics gibt beispielsweise Hunderte von Messwerten aus, von denen viele für Sie als Nutzer möglicherweise völlig wertlos sind. Ein neuer Cluster mit drei Knoten, der das Projekt kube-prometheus verwendet, sendet ungefähr 900 Stichproben pro Sekunde an den verwalteten Dienst für Prometheus.
Das Filtern dieser zusätzlichen Messwerte kann schon ausreichen, um Ihre Rechnung auf ein akzeptables Niveau zu reduzieren.
So reduzieren Sie die Anzahl der Messwerte:
- Ändern Sie die Extraktionskonfiguration für die Extraktion von weniger Zielen.
- Filtern Sie die erfassten Messwerte so:
- Exportieren Sie Messwerte, wenn Sie eine verwaltete Sammlung verwenden.
- Filtern Sie exportierte Messwerte, wenn Sie die selbst bereitgestellte Sammlung verwenden.
Wenn Sie den Dienst kube-state-metrics verwenden, können Sie eine Prometheus-Relabeling-Regel mit der Aktion keep hinzufügen. Bei der verwalteten Sammlung wird diese Regel in die Definition des PodMonitoring oder ClusterPodMonitoring aufgenommen. Bei der selbst bereitgestellten Sammlung wird diese Regel in die Prometheus-Scraping-Konfiguration oder die ServiceMonitor-Definition (für den Prometheus-Operator) aufgenommen.
Wenn Sie beispielsweise den folgenden Filter für einen neuen Cluster mit drei Knoten verwenden, wird das Stichprobenvolumen um etwa 125 Beispiele pro Sekunde reduziert:
metricRelabeling:
- action: keep
regex: kube_(daemonset|deployment|pod|namespace|node|statefulset|persistentvolume|horizontalpodautoscaler)_.+
sourceLabels: [__name__]
Der vorherige Filter verwendet einen regulären Ausdruck, um anzugeben, welche Messwerte basierend auf dem Namen des Messwerts beibehalten werden sollen. Beispielsweise werden Messwerte beibehalten, deren Name mit kube_daemonset_ beginnt.
Sie können auch die Aktion drop angeben, wodurch die Messwerte herausgefiltert werden, die dem regulären Ausdruck entsprechen.
Manchmal ist ein Exporter als unwichtig eingestuft. Das Paket kube-prometheus installiert beispielsweise standardmäßig die folgenden Dienstmonitore, von denen viele in einer verwalteten Umgebung nicht benötigt werden:
alertmanagercorednsgrafanakube-apiserverkube-controller-managerkube-schedulerkube-state-metricskubeletnode-exporterprometheusprometheus-adapterprometheus-operator
Damit die Anzahl der zu exportierenden Messwerte reduziert wird, können Sie die nicht mehr benötigten Dienstmonitore löschen, deaktivieren oder beenden. Wenn Sie beispielsweise den Dienst-Monitoring kube-apiserver in einem neuen Cluster mit drei Knoten deaktivieren, verringert sich das Stichprobenvolumen um etwa 200 Beispiele pro Sekunde.
Anzahl der erfassten Stichproben reduzieren
Managed Service for Prometheus wird pro Stichprobe abgerechnet. Sie können die Anzahl der aufgenommenen Stichproben reduzieren, indem Sie die Länge des Stichprobenzeitraums erhöhen. Beispiel:
- Wenn Sie einen Stichprobenzeitraum von 10 Sekunden in einen Stichprobenzeitraum von 30 Sekunden ändern, kann das Stichprobenvolumen um 66 % reduziert werden, ohne dass dadurch zu viele Informationen verloren gehen.
- Durch das Ändern eines Stichprobenzeitraums von 10 Sekunden auf 60 Sekunden kann das Stichprobenvolumen um 83 % reduziert werden.
Informationen dazu, wie Stichproben gezählt werden und wie sich der Stichprobenzeitraum auf die Anzahl der Stichproben auswirkt, finden Sie unter Nach aufgenommenen Stichproben berechnete Messwertdaten.
Normalerweise ist das Extraktionsintervall pro Job oder Ziel festgelegt.
Für die verwaltete Sammlung legen Sie das Extraktionsintervall in der Ressource PodMonitoring mithilfe des Felds interval fest.
Für die selbst bereitgestellte Sammlung legen Sie das Stichprobenintervall in Ihren Extraktionskonfigurationen fest, normalerweise durch Festlegen des Felds interval oder scrape_interval.
Lokale Aggregation konfigurieren (nur selbst bereitgestellte Sammlung)
Wenn Sie den Dienst mithilfe einer selbst bereitgestellten Sammlung konfigurieren, z. B. mit kube-prometheus, prometheus-operator, oder das Image manuell bereitstellen, können Sie die an den Managed Service for Prometheus gesendeten Stichproben reduzieren. Fassen Sie dazu Messwerte mit hoher Kardinalität lokal zusammen. Sie können Aufnahmeregeln verwenden, um Labels wie instance zusammenzufassen, und das Flag --export.match oder die Umgebungsvariable EXTRA_ARGS verwenden, um nur aggregierte Daten an Montreal zu senden.
Angenommen, Sie haben drei Messwerte: high_cardinality_metric_1, high_cardinality_metric_2 und low_cardinality_metric. Sie möchten die für high_cardinality_metric_1 gesendeten Stichproben reduzieren und alle für high_cardinality_metric_2 gesendeten Stichproben entfernen, während alle Rohdaten lokal gespeichert werden (z. B. für Benachrichtigungen). Ihre Einrichtung könnte beispielsweise so aussehen:
- Stellen Sie das Image für Managed Service for Prometheus bereit.
- Konfigurieren Sie die Extraktionskonfigurationen, um alle Rohdaten auf dem lokalen Server zu extrahieren (mit nur wenigen Filtern nach Bedarf).
Konfigurieren Sie Ihre Aufzeichnungsregeln so, dass sie lokale Zusammenfassungen über
high_cardinality_metric_1undhigh_cardinality_metric_2durchführen, vielleicht durch Wegaggregieren des Labelsinstanceoder einer beliebigen Anzahl von Messwertlabels, je nachdem, was die Anzahl nicht benötigter Zeitachsen am besten reduziert. Sie können eine Regel wie die folgende ausführen, die das Labelinstancelöscht und die resultierenden Zeitachsen über die verbleibenden Labels summiert:record: job:high_cardinality_metric_1:sum expr: sum without (instance) (high_cardinality_metric_1)
Siehe Aggregationsoperatoren in der Prometheus-Dokumentation für weitere Aggregationsoptionen.
Stellen Sie das Managed Service for Prometheus-Image mit dem folgenden Filter-Flag bereit. Damit wird verhindert, dass Rohdaten aus den aufgeführten Messwerten an Monarch gesendet werden:
--export.match='{__name__!="high_cardinality_metric_1",__name__!="high_cardinality_metric_2"}'In diesem Beispiel für das Flag
export.matchwerden durch Kommas getrennte Selektoren mit dem Operator!=verwendet, um unerwünschte Rohdaten herauszufiltern. Wenn Sie zusätzliche Aufnahmeregeln hinzufügen, um andere Messwerte mit hoher Kardinalität zu aggregieren, müssen Sie dem Filter auch einen neuen Selektor vom Typ__name__hinzufügen, damit die Rohdaten verworfen werden. Durch die Verwendung eines einzigen Flags, das mehrere Selektoren mit dem Operator!=enthält, um unerwünschte Daten herauszufiltern, müssen Sie den Filter nur ändern, wenn Sie eine neue Zusammenfassung erstellen und nicht jedes Mal, wenn Sie eine Scrape-Konfiguration ändern oder hinzufügen.Bei bestimmten Bereitstellungsmethoden wie dem "prometheus-operator" müssen Sie möglicherweise die einfachen Anführungszeichen um die Klammern weglassen.
Dieser Workflow kann einen gewissen operativen Aufwand beim Erstellen und Verwalten von Aufnahmeregeln und Flags vom Typ export.match verursachen, aber Sie können sehr viel Volumen reduzieren, wenn Sie sich nur auf Messwerte mit außergewöhnlich hoher Kardinalität konzentrieren. Informationen dazu, welche Messwerte von der lokalen Vorabaggregation am meisten profitieren können, finden Sie unter Messwerte mit hohem Volumen identifizieren.
Implementieren Sie die Föderation nicht, wenn Sie Managed Service for Prometheus verwenden. Bei diesem Workflow sind keine Föderationsserver mehr erforderlich, da ein einzelner selbst bereitgestellter Prometheus-Server alle erforderlichen Zusammenfassungen auf Clusterebene ausführen kann. Föderation kann unerwartete Auswirkungen haben, z. B. Messwerte unbekannten Typs und ein doppeltes Aufnahmevolumen.
Stichproben aus Messwerten mit hoher Kardinalität beschränken (nur selbst bereitgestellte Sammlung)
Sie können Messwerte mit sehr hoher Kardinalität erstellen, indem Sie Labels mit einer großen Anzahl potenzieller Werte hinzufügen, z. B. eine Nutzer-ID oder IP-Adresse. Solche Messwerte können eine sehr große Anzahl von Stichproben generieren. Die Verwendung von Labels mit einer großen Anzahl von Werten ist in der Regel eine fehlerhafte Konfiguration. Sie können sich vor Messwerten mit hoher Kardinalität in Ihren selbst bereitgestellten Collectors schützen, indem Sie in Ihren Extraktionskonfigurationen einen sample_limit-Wert festlegen.
Wenn Sie dieses Limit verwenden, sollten Sie es auf einen sehr hohen Wert setzen, damit nur offensichtlich falsch konfigurierte Messwerte abgefangen werden. Alle Stichproben, die das Limit überschreiten, werden verworfen und es kann sehr schwierig sein, Probleme zu diagnostizieren, die durch das Überschreiten des Limits verursacht wurden.
Die Verwendung eines Beispiellimits ist keine gute Möglichkeit, die Beispielaufnahme zu verwalten. Dieses Limit kann Sie jedoch vor versehentlichen Fehlkonfigurationen schützen. Weitere Informationen finden Sie unter sample_limit zur Vermeidung von Überlastungen.
Kosten identifizieren und zuordnen
Mit Cloud Monitoring können Sie die Prometheus-Messwerte ermitteln, die die größte Anzahl von Stichproben schreiben. Diese Messwerte tragen am meisten zu Ihren Kosten bei. Nachdem Sie die teuersten Messwerte ermittelt haben, können Sie die Extraktionskonfigurationen ändern, um diese Messwerte entsprechend zu filtern.
Auf der Cloud Monitoring-Seite Messwertverwaltung können Sie den Betrag steuern, den Sie für abrechenbare Messwerte ausgeben, ohne die Beobachtbarkeit zu beeinträchtigen. Die Seite Messwertverwaltung enthält die folgenden Informationen:
- Aufnahmevolumen für byte- und probenbasierte Abrechnung für Messwertdomains und einzelne Messwerte
- Daten zu Labels und zur Kardinalität von Messwerten
- Anzahl der Lesevorgänge für jeden Messwert
- Nutzung von Messwerten in Benachrichtigungsrichtlinien und benutzerdefinierten Dashboards
- Fehlerrate beim Schreiben von Messwerten
Auf der Seite Messwertverwaltung können Sie auch nicht benötigte Messwerte ausschließen, um unnötige Kosten bei der Datenaufnahme zu vermeiden.
So rufen Sie die Seite Messwertverwaltung auf:
-
Rufen Sie in der Google Cloud Console die Seite Messwertverwaltung auf:
Wenn Sie diese Seite über die Suchleiste suchen, wählen Sie das Ergebnis aus, dessen Zwischenüberschrift Monitoring ist.
- Wählen Sie in der Symbolleiste das Zeitfenster aus. Standardmäßig werden auf der Seite Messwertverwaltung Informationen zu den Messwerten angezeigt, die am Vortag erfasst wurden.
Weitere Informationen zur Seite Messwertverwaltung finden Sie unter Messwertnutzung ansehen und verwalten.
In den folgenden Abschnitten wird beschrieben, wie Sie die Anzahl der Beispiele analysieren können, die Sie an Managed Service for Prometheus senden, und bestimmten Messwerten, Kubernetes-Namespaces und Google Cloud Regionen ein hohes Volumen zuordnen.
Messwerte mit hohem Volumen identifizieren
So ermitteln Sie die Prometheus-Messwerte mit den größten Datenaufnahme-Volumes:
-
Rufen Sie in der Google Cloud Console die Seite Messwertverwaltung auf:
Wenn Sie diese Seite über die Suchleiste suchen, wählen Sie das Ergebnis aus, dessen Zwischenüberschrift Monitoring ist.
- Klicken Sie in der Kurzübersicht Aufgenommene kostenpflichtige Stichproben auf Diagramme ansehen.
- Suchen Sie das Diagramm Volume-Aufnahme nach Namespace und klicken Sie dann auf more_vert Weitere Diagrammoptionen.
- Wählen Sie die Diagrammoption In Metrics Explorer ansehen aus.
- Ändern Sie im Bereich Builder des Metrics Explorer die Felder so:
- Prüfen Sie im Feld Messwert, ob die folgende Ressource und der folgende Messwert ausgewählt sind:
Metric Ingestion AttributionundSamples written by attribution id. - Wählen Sie für das Feld Aggregation die Option
sumaus. - Wählen Sie für das Feld nach die folgenden Labels aus:
attribution_dimensionmetric_type
- Verwenden Sie für das Feld Filter den Wert
attribution_dimension = namespace. Dies ist nach der Zusammenfassung nach dem Labelattribution_dimensionerforderlich.
Das resultierende Diagramm zeigt das Aufnahmevolumen für die einzelnen Messwerttypen an.
- Prüfen Sie im Feld Messwert, ob die folgende Ressource und der folgende Messwert ausgewählt sind:
- Um das Aufnahmevolumen für jeden der Messwerte anzuzeigen, wählen Sie auf der Schaltfläche Diagramm Tabelle Beides Beides aus. In der Tabelle sehen Sie in der Spalte Wert das aufgenommene Volumen für jeden Messwert.
- Klicken Sie zweimal auf die Spaltenüberschrift Wert, um die Messwerte nach absteigendem Aufnahmevolumen zu sortieren.
Das daraus resultierende Diagramm, in dem Ihre Top-Messwerte nach Volumen und Mittelwert sortiert werden, sieht so aus: 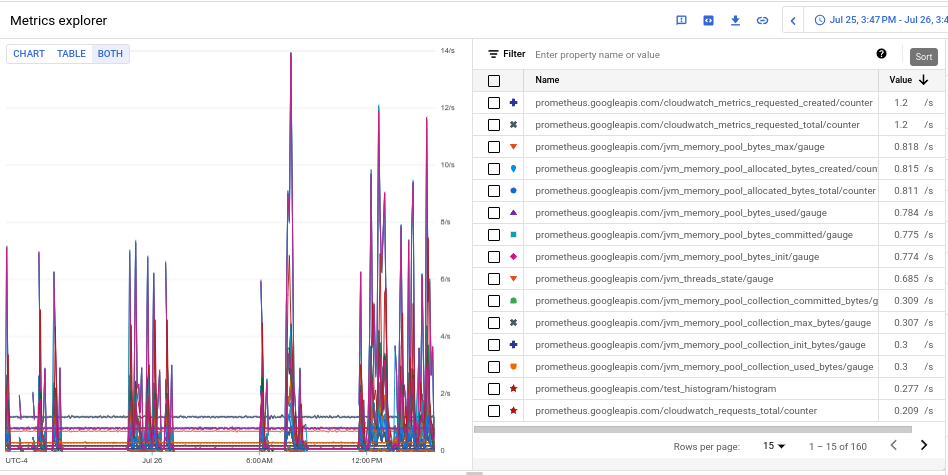
Namespaces mit hohem Volumen identifizieren
So ordnen Sie das Aufnahmevolumen bestimmten Kubernetes-Namespaces zu:
-
Rufen Sie in der Google Cloud Console die Seite Messwertverwaltung auf:
Wenn Sie diese Seite über die Suchleiste suchen, wählen Sie das Ergebnis aus, dessen Zwischenüberschrift Monitoring ist.
- Klicken Sie in der Kurzübersicht Aufgenommene kostenpflichtige Stichproben auf Diagramme ansehen.
- Suchen Sie das Diagramm Volume-Aufnahme nach Namespace und klicken Sie dann auf more_vert Weitere Diagrammoptionen.
- Wählen Sie die Diagrammoption In Metrics Explorer ansehen aus.
- Ändern Sie im Bereich Builder des Metrics Explorers die Felder so:
- Prüfen Sie im Feld Messwert, ob die folgende Ressource und der folgende Messwert ausgewählt sind:
Metric Ingestion AttributionundSamples written by attribution id. - Konfigurieren Sie die restlichen Abfrageparameter nach Bedarf:
- So korrelieren Sie das Gesamtaufnahmevolumen mit Namespaces:
- Wählen Sie für das Feld Aggregation die Option
sumaus. - Wählen Sie für das Feld nach die folgenden Labels aus:
attribution_dimensionattribution_id
- Verwenden Sie für das Feld Filter den Wert
attribution_dimension = namespace.
- Wählen Sie für das Feld Aggregation die Option
- So korrelieren Sie das Aufnahmevolumen einzelner Messwerte mit Namespaces:
- Wählen Sie für das Feld Aggregation die Option
sumaus. - Wählen Sie für das Feld nach die folgenden Labels aus:
attribution_dimensionattribution_idmetric_type
- Verwenden Sie für das Feld Filter den Wert
attribution_dimension = namespace.
- Wählen Sie für das Feld Aggregation die Option
- So identifizieren Sie die Namespaces, die für einen bestimmten Messwert mit hohem Volumen verantwortlich sind:
- Ermitteln Sie den Messwerttyp für den Messwert mit hohem Volumen. Verwenden Sie dazu eines der anderen Beispiele, um die Messwerttypen mit hohem Volumen zu identifizieren. Der Messwerttyp ist der String in der Tabellenansicht, der mit
prometheus.googleapis.com/beginnt. Weitere Informationen finden Sie unter Messwerte mit hohem Volumen identifizieren. - Beschränken Sie die Diagrammdaten auf den identifizierten Messwerttyp. Fügen Sie dazu im Feld Filter einen Filter für den Messwerttyp hinzu. Beispiel:
metric_type= prometheus.googleapis.com/container_tasks_state/gauge. - Wählen Sie für das Feld Aggregation die Option
sumaus. - Wählen Sie für das Feld nach die folgenden Labels aus:
attribution_dimensionattribution_id
- Verwenden Sie für das Feld Filter den Wert
attribution_dimension = namespace.
- Ermitteln Sie den Messwerttyp für den Messwert mit hohem Volumen. Verwenden Sie dazu eines der anderen Beispiele, um die Messwerttypen mit hohem Volumen zu identifizieren. Der Messwerttyp ist der String in der Tabellenansicht, der mit
- Wenn Sie die Aufnahme nach Google Cloud -Region sehen möchten, fügen Sie dem Feld nach das Label
locationhinzu. - Wenn Sie die Aufnahme nach Google Cloud Projekt sehen möchten, fügen Sie dem Feld nach das Label
resource_containerhinzu.
- So korrelieren Sie das Gesamtaufnahmevolumen mit Namespaces:
- Prüfen Sie im Feld Messwert, ob die folgende Ressource und der folgende Messwert ausgewählt sind: