Google Cloud Managed Service per Prometheus addebita un costo per il numero di campioni importati in Cloud Monitoring e per le richieste di lettura all'API Monitoring. Il numero di campioni importati è il principale fattore che contribuisce al costo.
Questo documento descrive come controllare i costi associati all'importazione delle metriche e come identificare le origini dell'importazione di volumi elevati.
Per ulteriori informazioni sui prezzi di Managed Service for Prometheus, consulta le sezioni di Cloud Monitoring della pagina Prezzi di Google Cloud Observability.
Visualizzare la fattura
Per visualizzare la tua Google Cloud fattura:
Nella console Google Cloud , vai alla pagina Fatturazione.
Se disponi di più di un account di fatturazione, seleziona Vai all'account di fatturazione collegato per visualizzare l'account di fatturazione del progetto attuale. Per trovare un altro account di fatturazione, seleziona Gestisci account di fatturazione e scegli l'account per cui vuoi ottenere i report sull'utilizzo.
Nella sezione Gestione dei costi del menu di navigazione Fatturazione, seleziona Report.
Dal menu Servizi, seleziona l'opzione Cloud Monitoring.
Dal menu SKU, seleziona le seguenti opzioni:
- Campioni Prometheus importati
- Monitoraggio delle richieste API
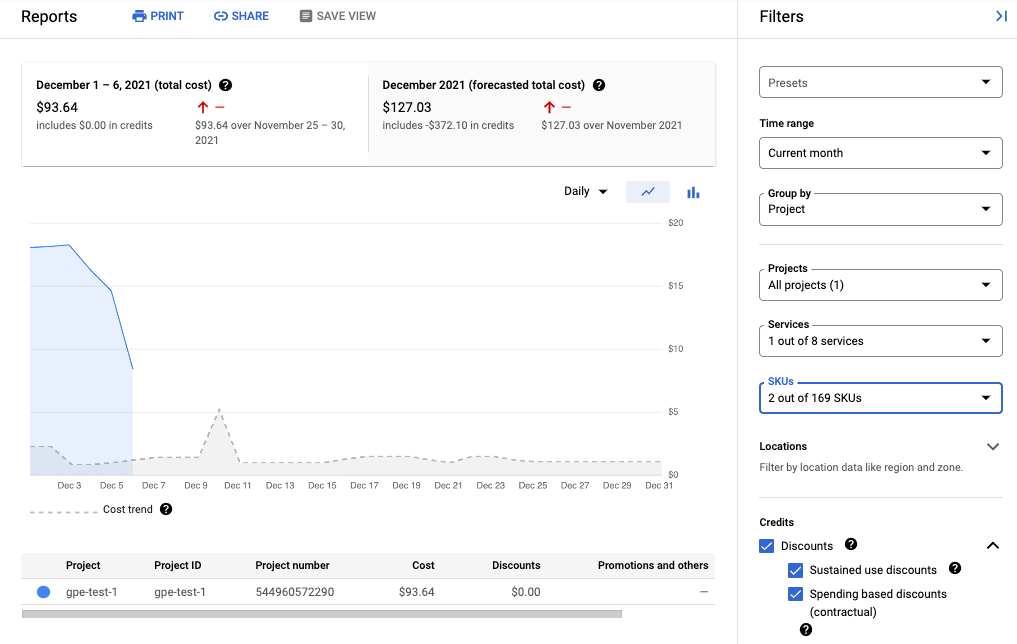
Lo screenshot seguente mostra il report di fatturazione per Managed Service per Prometheus di un progetto:
Ridurre i costi
Per ridurre i costi associati all'utilizzo di Managed Service per Prometheus, puoi:
- Riduci il numero di serie temporali inviate al servizio gestito filtrando i dati delle metriche che generi.
- Riduci il numero di campioni raccolti modificando l'intervallo di scraping.
- Limita il numero di campioni provenienti da metriche ad alta cardinalità potenzialmente configurate in modo errato.
Ridurre il numero di serie temporali
La documentazione open source di Prometheus raramente consiglia di filtrare il volume delle metriche, il che è ragionevole quando i costi sono limitati dai costi della macchina. Tuttavia, quando paghi un fornitore di servizi gestiti in base all'unità, l'invio di dati illimitati può causare fatture inutilmente elevate.
Gli esportatori inclusi nel progetto kube-prometheus, in particolare il servizio kube-state-metrics, possono generare molti dati delle metriche.
Ad esempio, il servizio kube-state-metrics genera centinaia di metriche,
molte delle quali potrebbero essere completamente inutili per te in qualità di consumatore. Un
cluster di tre nodi nuovo che utilizza il progetto kube-prometheus invia
circa 900 campioni al secondo a Managed Service for Prometheus.
Il filtraggio di queste metriche estranee potrebbe essere sufficiente per ridurre la fattura
a un livello accettabile.
Per ridurre il numero di metriche, puoi:
- Modifica le configurazioni di scraping per eseguire lo scraping di un numero inferiore di target.
- Filtra le metriche raccolte come descritto di seguito:
- Filtra le metriche esportate quando utilizzi la raccolta gestita.
- Filtra le metriche esportate quando utilizzi la raccolta autogestita.
Se utilizzi il servizio kube-state-metrics, puoi aggiungere una
regola di rietichettatura di Prometheus con un'azione keep. Per la raccolta gestita, questa regola viene inserita nella definizione di PodMonitoring o
ClusterPodMonitoring. Per la raccolta con deployment autonomo, questa regola viene inserita nella configurazione di scraping di Prometheus o nella definizione di ServiceMonitor (per prometheus-operator).
Ad esempio, l'utilizzo del seguente filtro su un nuovo cluster di tre nodi riduce il volume del campione di circa 125 campioni al secondo:
metricRelabeling:
- action: keep
regex: kube_(daemonset|deployment|pod|namespace|node|statefulset|persistentvolume|horizontalpodautoscaler)_.+
sourceLabels: [__name__]
Il filtro precedente utilizza un'espressione regolare per specificare quali metriche conservare
in base al nome della metrica. Ad esempio, vengono conservate le metriche il cui nome inizia con
kube_daemonset_.
Puoi anche specificare un'azione di drop, che filtra le metriche
che corrispondono all'espressione regolare.
A volte, potresti ritenere che un intero esportatore non sia importante. Ad esempio,
il pacchetto kube-prometheus installa i seguenti monitor di servizio per
impostazione predefinita, molti dei quali sono inutili in un ambiente gestito:
alertmanagercorednsgrafanakube-apiserverkube-controller-managerkube-schedulerkube-state-metricskubeletnode-exporterprometheusprometheus-adapterprometheus-operator
Per ridurre il numero di metriche esportate, puoi eliminare, disattivare o
interrompere lo scraping dei monitor dei servizi che non ti servono. Ad esempio, la disattivazione
del monitoraggio del servizio kube-apiserver su un nuovo cluster di tre nodi riduce
il volume di campioni di circa 200 campioni al secondo.
Riduci il numero di campioni raccolti
Managed Service per Prometheus prevede addebiti per campione. Puoi ridurre il numero di campioni importati aumentando la durata del periodo di campionamento. Ad esempio:
- La modifica di un periodo di campionamento di 10 secondi in un periodo di campionamento di 30 secondi può ridurre il volume del campione del 66%, senza una grande perdita di informazioni.
- La modifica di un periodo di campionamento di 10 secondi in un periodo di campionamento di 60 secondi può ridurre il volume del campione dell'83%.
Per informazioni su come vengono conteggiati i campioni e su come il periodo di campionamento influisce sul numero di campioni, consulta Dati delle metriche addebitati in base ai campioni importati.
In genere puoi impostare l'intervallo di scraping in base al job o al target.
Per la raccolta gestita, imposta l'intervallo di scraping nella
risorsa PodMonitoring utilizzando il campo interval.
Per la raccolta autodeploy, imposta l'intervallo di campionamento nelle configurazioni
di scraping, in genere
impostando un campo interval o scrape_interval.
Configurare l'aggregazione locale (solo raccolta con deployment autonomo)
Se configuri il servizio utilizzando la raccolta autodeployata,
ad esempio con kube-prometheus, prometheus-operator o eseguendo manualmente
il deployment dell'immagine, puoi ridurre i campioni inviati a Managed Service per Prometheus
aggregando localmente le metriche con cardinalità elevata. Puoi
utilizzare le regole di registrazione per aggregare le etichette come instance e utilizzare il
flag --export.match o la variabile di ambiente EXTRA_ARGS per inviare solo i dati aggregati a
Monarch.
Ad esempio, supponiamo di avere tre metriche: high_cardinality_metric_1, high_cardinality_metric_2 e low_cardinality_metric. Vuoi ridurre i campioni inviati per high_cardinality_metric_1 ed eliminare tutti i campioni inviati per high_cardinality_metric_2, mantenendo tutti i dati non elaborati archiviati localmente (magari per scopi di avviso). La configurazione potrebbe avere un aspetto simile al seguente:
- Esegui il deployment dell'immagine di Managed Service per Prometheus.
- Configura le configurazioni di scraping in modo da eseguire lo scraping di tutti i dati non elaborati nel server locale (utilizzando il minor numero possibile di filtri).
Configura le regole di registrazione per eseguire aggregazioni locali su
high_cardinality_metric_1ehigh_cardinality_metric_2, ad esempio aggregando l'etichettainstanceo un numero qualsiasi di etichette delle metriche, a seconda di ciò che offre la migliore riduzione del numero di serie temporali non necessarie. Potresti eseguire una regola simile alla seguente, che elimina l'etichettainstancee somma le serie temporali risultanti sulle etichette rimanenti:record: job:high_cardinality_metric_1:sum expr: sum without (instance) (high_cardinality_metric_1)
Per altre opzioni di aggregazione, consulta gli operatori di aggregazione nella documentazione di Prometheus.
Esegui il deployment dell'immagine di Managed Service per Prometheus con il seguente flag di filtro, che impedisce l'invio a Monarch dei dati non elaborati delle metriche elencate:
--export.match='{__name__!="high_cardinality_metric_1",__name__!="high_cardinality_metric_2"}'Questo esempio di flag
export.matchutilizza selettori separati da virgole con l'operatore!=per filtrare i dati non elaborati indesiderati. Se aggiungi regole di registrazione aggiuntive per aggregare altre metriche con cardinalità elevata, devi anche aggiungere un nuovo selettore__name__al filtro in modo che i dati non elaborati vengano eliminati. Se utilizzi un singolo flag contenente più selettori con l'operatore!=per filtrare i dati indesiderati, devi modificare il filtro solo quando crei una nuova aggregazione, anziché ogni volta che modifichi o aggiungi una configurazione di scraping.Alcuni metodi di deployment, come prometheus-operator, potrebbero richiedere di omettere gli apici singoli che racchiudono le parentesi.
Questo flusso di lavoro potrebbe comportare alcuni costi operativi per la creazione e la gestione
di regole di registrazione e flag export.match, ma è probabile che tu possa ridurre notevolmente
il volume concentrandoti solo sulle metriche con cardinalità eccezionalmente elevata. Per
informazioni su come identificare le metriche che potrebbero trarre il massimo vantaggio dalla preaggregazione
locale, consulta Identificare le metriche di volumi elevati.
Non implementare la federazione quando utilizzi Managed Service per Prometheus. Questo flusso di lavoro rende obsoleti i server di federazione, in quanto un singolo server Prometheus autodeployato può eseguire qualsiasi aggregazione a livello di cluster di cui potresti aver bisogno. La federazione può causare effetti imprevisti, ad esempio metriche di tipo "sconosciuto" e volume di importazione raddoppiato.
Limita i campioni delle metriche ad alta cardinalità (solo raccolta autogestita)
Puoi creare metriche con cardinalità estremamente elevata aggiungendo etichette con
un numero elevato di valori potenziali, ad esempio un ID utente o un indirizzo IP. Queste
metriche possono generare un numero molto elevato di campioni. L'utilizzo di etichette
con un numero elevato di valori è in genere un errore di configurazione. Puoi
proteggerti dalle metriche con cardinalità elevata nei raccoglitori autogestiti
impostando un valore sample_limit
nelle configurazioni di scraping.
Se utilizzi questo limite, ti consigliamo di impostarlo su un valore molto alto, in modo che rilevi solo le metriche ovviamente configurate in modo errato. Tutti i campioni che superano il limite vengono eliminati ed è molto difficile diagnosticare i problemi causati dal superamento del limite.
L'utilizzo di un limite di campionamento non è un buon modo per gestire l'importazione dei campioni, ma il limite può proteggerti da errori di configurazione accidentali. Per ulteriori informazioni, consulta la sezione Utilizzare sample_limit per evitare il sovraccarico.
Identificare e attribuire i costi
Puoi utilizzare Cloud Monitoring per identificare le metriche Prometheus che scrivono il maggior numero di campioni. Queste metriche contribuiscono maggiormente ai tuoi costi. Dopo aver identificato le metriche più costose, puoi modificare le configurazioni di scraping per filtrare queste metriche in modo appropriato.
La pagina Gestione delle metriche di Cloud Monitoring fornisce informazioni che possono aiutarti a controllare l'importo che spendi per le metriche fatturabili senza influire sull'osservabilità. La pagina Gestione delle metriche riporta le seguenti informazioni:
- Volumi di importazione per la fatturazione basata su byte e campioni, in tutti i domini delle metriche e per le singole metriche.
- Dati su etichette e cardinalità delle metriche.
- Numero di letture per ogni metrica.
- Utilizzo delle metriche nelle policy di avviso e nelle dashboard personalizzate.
- Tasso di errori di scrittura delle metriche.
Puoi anche utilizzare la pagina Gestione metriche per escludere le metriche non necessarie, eliminando il costo della loro importazione.
Per visualizzare la pagina Gestione metriche:
-
Nella console Google Cloud , vai alla pagina Gestione metriche:
Se utilizzi la barra di ricerca per trovare questa pagina, seleziona il risultato con il sottotitolo Monitoring.
- Nella barra degli strumenti, seleziona la finestra temporale. Per impostazione predefinita, nella pagina Gestione metriche vengono visualizzate le informazioni sulle metriche raccolte nel giorno precedente.
Per saperne di più sulla pagina Gestione metriche, consulta Visualizzare e gestire l'utilizzo delle metriche.
Le sezioni seguenti descrivono i modi per analizzare il numero di campioni che invii a Managed Service for Prometheus e attribuire un volume elevato a metriche, spazi dei nomi Kubernetes e regioni specifici. Google Cloud
Identificare le metriche con volumi elevati
Per identificare le metriche Prometheus con i volumi di importazione più grandi, procedi nel seguente modo:
-
Nella console Google Cloud , vai alla pagina Gestione metriche:
Se utilizzi la barra di ricerca per trovare questa pagina, seleziona il risultato con il sottotitolo Monitoring.
- Nella scorecard Campioni fatturabili importati, fai clic su Visualizza grafici.
- Individua il grafico Inserimento volume spazio dei nomi, quindi fai clic su more_vert Altre opzioni per il grafico.
- Seleziona l'opzione del grafico Visualizza in Esplora metriche.
- Nel riquadro Generatore di Metrics Explorer, modifica i campi
come segue:
- Nel campo Metrica, verifica che siano selezionate le seguenti risorse e metriche:
Metric Ingestion AttributioneSamples written by attribution id. - Per il campo Aggregazione, seleziona
sum. - Per il campo by, seleziona
le seguenti etichette:
attribution_dimensionmetric_type
- Per il campo Filtro, utilizza
attribution_dimension = namespace. Devi farlo dopo l'aggregazione in base all'etichettaattribution_dimension.
Il grafico risultante mostra i volumi di importazione per ogni tipo di metrica.
- Nel campo Metrica, verifica che siano selezionate le seguenti risorse e metriche:
- Per visualizzare il volume di importazione per ciascuna metrica, seleziona Entrambi nell'opzione di attivazione/disattivazione con l'etichetta Grafico Tabella Entrambi. La tabella mostra il volume importato per ogni metrica nella colonna Valore.
- Fai clic due volte sull'intestazione della colonna Valore per ordinare le metriche in base al volume di importazione decrescente.
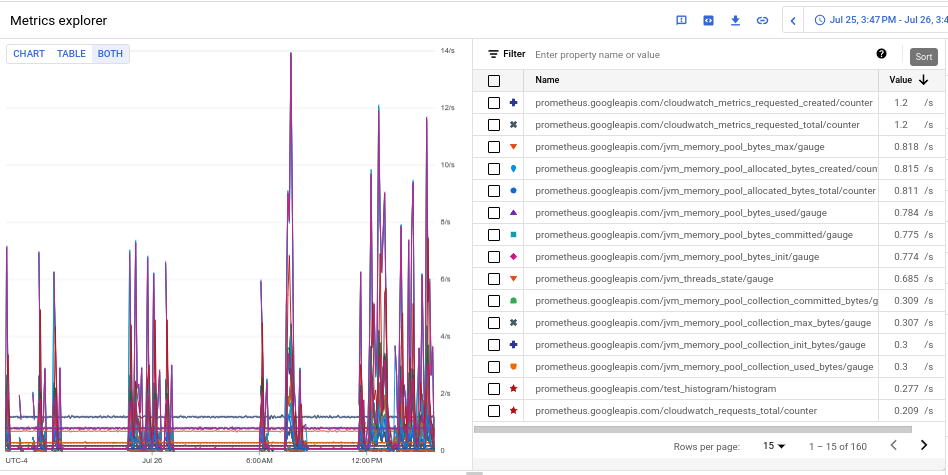
Il grafico risultante, che mostra le principali metriche per volume classificate in base alla media, è simile allo screenshot seguente:
Identificare gli spazi dei nomi con volumi elevati
Per attribuire il volume di importazione a spazi dei nomi Kubernetes specifici, segui questi passaggi:
-
Nella console Google Cloud , vai alla pagina Gestione metriche:
Se utilizzi la barra di ricerca per trovare questa pagina, seleziona il risultato con il sottotitolo Monitoring.
- Nella scorecard Campioni fatturabili importati, fai clic su Visualizza grafici.
- Individua il grafico Inserimento volume spazio dei nomi, quindi fai clic su more_vert Altre opzioni per il grafico.
- Seleziona l'opzione del grafico Visualizza in Esplora metriche.
- Nel riquadro Generatore di Metrics Explorer, modifica i campi
come segue:
- Nel campo Metrica, verifica che siano selezionate le seguenti risorsa e metrica:
Metric Ingestion AttributioneSamples written by attribution id. - Configura gli altri parametri di ricerca in modo appropriato:
- Per correlare il volume di importazione complessivo con gli spazi dei nomi:
- Per il campo Aggregazione, seleziona
sum. - Per il campo by, seleziona le seguenti etichette:
attribution_dimensionattribution_id
- Per il campo Filtro, utilizza
attribution_dimension = namespace.
- Per il campo Aggregazione, seleziona
- Per correlare il volume di importazione delle singole metriche con
gli spazi dei nomi:
- Per il campo Aggregazione, seleziona
sum. - Per il campo by, seleziona
le seguenti etichette:
attribution_dimensionattribution_idmetric_type
- Per il campo Filtro, utilizza
attribution_dimension = namespace.
- Per il campo Aggregazione, seleziona
- Per identificare gli spazi dei nomi responsabili di una metrica specifica
con volume elevato:
- Identifica il tipo di metrica per la metrica di volume elevato
utilizzando uno degli altri esempi per identificare i tipi di metriche
di volume elevato. Il tipo di metrica è la stringa nella visualizzazione
della tabella che inizia con
prometheus.googleapis.com/. Per ulteriori informazioni, consulta Identificare le metriche ad alto volume. - Limita i dati del grafico al tipo di metrica identificato
aggiungendo un filtro per il tipo di metrica nel campo
Filtro. Ad esempio:
metric_type= prometheus.googleapis.com/container_tasks_state/gauge. - Per il campo Aggregazione, seleziona
sum. - Per il campo by, seleziona
le seguenti etichette:
attribution_dimensionattribution_id
- Per il campo Filtro, utilizza
attribution_dimension = namespace.
- Identifica il tipo di metrica per la metrica di volume elevato
utilizzando uno degli altri esempi per identificare i tipi di metriche
di volume elevato. Il tipo di metrica è la stringa nella visualizzazione
della tabella che inizia con
- Per visualizzare l'importazione per regione Google Cloud , aggiungi l'etichetta
locational campo Per. - Per visualizzare l'importazione per progetto Google Cloud , aggiungi l'etichetta
resource_containeral campo Per.
- Per correlare il volume di importazione complessivo con gli spazi dei nomi:
- Nel campo Metrica, verifica che siano selezionate le seguenti risorsa e metrica: