이 문서에서는 자체 배포 컬렉션을 사용하는 Managed Service for Prometheus 배포의 규칙과 알림 평가의 구성을 설명합니다.
다음 다이어그램은 두 Google Cloud 프로젝트에서 클러스터를 여러 개 사용하고 규칙과 알림 평가를 모두 사용하는 배포를 보여줍니다.
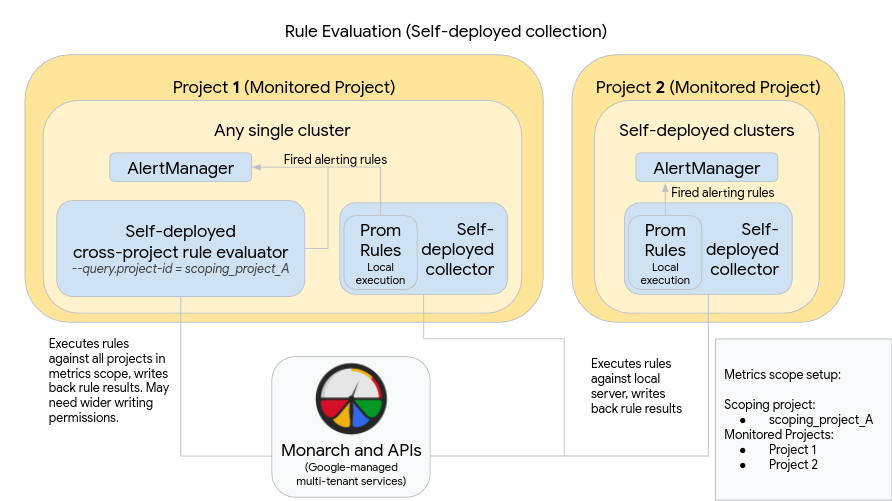
다이어그램과 같이 배포를 설정하고 사용하려면 다음 사항에 유의하세요.
규칙은 표준 Prometheus를 사용할 때와 마찬가지로 각 Managed Service for Prometheus 컬렉션 서버 내에 설치됩니다. 규칙 평가는 각 서버에 로컬로 저장된 데이터에 대해 실행됩니다. 서버는 모든 규칙의 대상 기간(일반적으로 1시간 이하)을 포함할 수 있는 충분히 긴 데이터를 보관하도록 구성됩니다. 규칙 결과는 평가 후 Monarch에 기록됩니다.
Prometheus AlertManager 인스턴스는 모든 단일 클러스터에 수동으로 배포됩니다. Prometheus 서버는 실행된 알림 규칙을 로컬 AlertManager 인스턴스로 전송하도록 구성 파일의
alertmanager_config필드를 수정함으로써 구성됩니다. 음소거, 확인, 사고 관리 워크플로는 일반적으로 PagerDuty와 같은 타사 도구에서 처리됩니다.Kubernetes 엔드포인트 리소스를 사용하여 여러 클러스터의 알림 관리를 단일 AlertManager 한 곳에서 제어할 수 있습니다.
Google Cloud 내에서 실행되는 단일 클러스터 하나가 측정항목 범위의 전역 규칙 평가 클러스터로 지정됩니다. 독립형 규칙 평가자는 클러스터에 배포되며 규칙은 표준 Prometheus 규칙 파일 형식으로 설치됩니다.
독립형 규칙 평가자는 프로젝트 1과 2가 포함된 scoping_project_A를 사용하도록 구성됩니다. scoping_project_A에 대해 실행된 규칙은 자동으로 프로젝트 1과 2로 팬아웃됩니다. 기본 서비스 계정에는 scoping_project_A에 대한 Monitoring 뷰어 권한이 부여되어야 합니다.
규칙 평가자는 구성 파일의
alertmanager_config필드를 사용하여 알림을 로컬 Prometheus Alertmanager로 전송하도록 구성됩니다.
자체 배포된 전역 규칙 평가자를 사용하면 규칙에서 project_id, location, cluster, namespace 라벨을 보존하거나 집계하는지에 따라 예상치 못한 결과가 발생할 수 있습니다.
규칙에서
by(project_id)절을 사용하여project_id라벨을 보존하는 경우 규칙 결과는 기본 시계열의 원래project_id값을 통해 Monarch에 다시 기록됩니다이 시나리오에서는 기본 서비스 계정에 scoping_project_A의 각 모니터링 프로젝트에 대한 Monitoring 측정항목 작성자 권한이 있는지 확인해야 합니다. 새 모니터링 프로젝트를 scoping_project_A에 추가하는 경우 수동으로 서비스 계정에 새 권한도 추가해야 합니다.
규칙에서
by(project_id)절을 사용하지 않고project_id라벨을 사용하는 경우 규칙 결과는 전역 규칙 평가자가 실행되는 클러스터의project_id값을 통해 Monarch에 다시 기록됩니다.이 시나리오에서는 기본 서비스 계정을 추가로 수정할 필요가 없습니다.
규칙에서
by(location)절을 사용하여location라벨을 보존하는 경우 규칙 결과는 기본 시계열이 시작하는 각 원본 Google Cloud 리전을 통해 Monarch에 다시 기록됩니다.규칙에서
location라벨을 보존하지 않는 경우 데이터는 전역 규칙 평가자가 실행 중인 클러스터의 위치에 다시 기록됩니다.
가능하면 규칙 평가 결과에 cluster 라벨과 namespace 라벨을 보존하는 것이 좋습니다. 그렇지 않으면 쿼리 성능이 저하되고 카디널리티 제한이 발생할 수 있습니다. 두 라벨 모두 제거하지 않는 것이 좋습니다.