Questo documento descrive una configurazione per la valutazione delle regole e degli avvisi in un deployment di Managed Service per Prometheus che utilizza la raccolta di cui è stato eseguito il deployment autonomo.
Il seguente diagramma illustra un deployment che utilizza più cluster in due Google Cloud progetti e utilizza sia la valutazione delle regole sia quella degli avvisi:
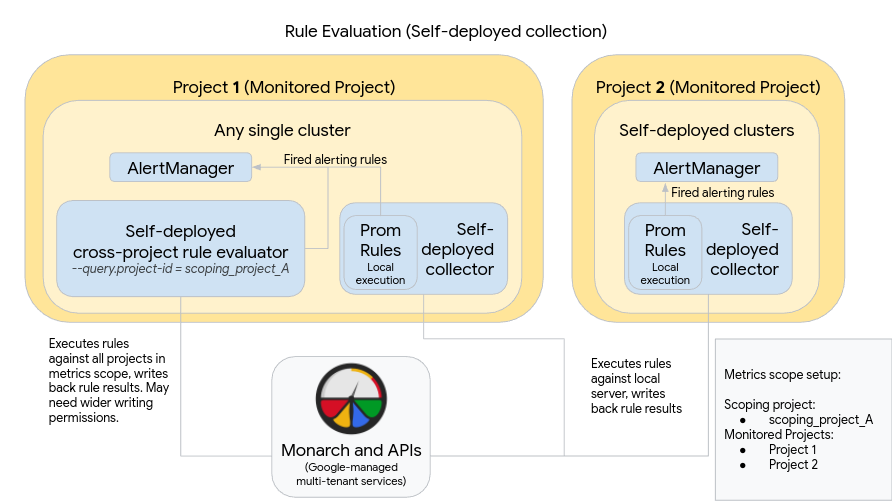
Per configurare e utilizzare un'implementazione come quella nel diagramma, tieni presente quanto segue:
Le regole vengono installate in ogni server di raccolta di Managed Service per Prometheus, come quando si utilizza Prometheus standard. La valutazione delle regole viene eseguita sui dati memorizzati localmente su ogni server. I server sono configurati per conservare i dati per un periodo di tempo sufficiente a coprire il periodo di riferimento di tutte le regole, che in genere non supera 1 ora. I risultati delle regole vengono scritti in Monarch dopo la valutazione.
Un'istanza Prometheus AlertManager viene dispiegamento manualmente in ogni singolo cluster. I server Prometheus vengono configurati modificando il campo
alertmanager_configdel file di configurazione per inviare le regole di avviso attivate all'istanza AlertManager locale. I silenzi, gli acknowledgement e i flussi di lavoro per la gestione degli incidenti vengono in genere gestiti in uno strumento di terze parti come PagerDuty.Puoi centralizzare la gestione degli avvisi su più cluster in un singolo AlertManager utilizzando una risorsa Endpoints di Kubernetes.
Un singolo cluster in esecuzione in Google Cloud è designato come cluster di valutazione delle regole globali per un ambito delle metriche. L'valutatore di regole autonomo viene dispiegato in questo cluster e le regole vengono installate utilizzando il formato del file di regole Prometheus standard.
Il valutatore delle regole autonomo è configurato per utilizzare scoping_project_A, che contiene i progetti 1 e 2. Le regole eseguite in base a scoping_project_A vengono distribuite automaticamente ai progetti 1 e 2. All'account di servizio sottostante devono essere assegnate le autorizzazioni Visualizzatore Monitoring per scoping_project_A.
Il valutatore delle regole è configurato per inviare avvisi al Prometheus Alertmanager locale utilizzando il campo
alertmanager_configdel file di configurazione.
L'utilizzo di un valutatore delle regole globali di cui è stato eseguito il deployment autonomo può avere effetti inaspettati, a seconda che tu conservi o aggreghi le etichette project_id, location, cluster e namespace nelle regole:
Se le regole mantengono l'etichetta
project_id(utilizzando una clausolaby(project_id)), i risultati delle regole vengono scritti nuovamente in Monarch utilizzando il valoreproject_idoriginale della serie temporale sottostante.In questo scenario, devi assicurarti che l'account di servizio di base abbia le autorizzazioni Monitoring Metric Writer per ogni progetto monitorato in scoping_project_A. Se aggiungi un nuovo progetto monitorato a scoping_project_A, devi anche aggiungere manualmente una nuova autorizzazione all'account di servizio.
Se le regole non mantengono l'etichetta
project_id(non utilizzando una clausolaproject_id), i risultati delle regole vengono scritti nuovamente in Monarch utilizzando il valoreproject_iddel cluster in cui è in esecuzione il valutatore delle regole globali.by(project_id)In questo caso, non è necessario modificare ulteriormente l'account di servizio di base.
Se le regole mantengono l'etichetta
location(utilizzando una clausolaby(location)), i risultati delle regole vengono riscritti in Monarch utilizzando ogni regione Google Cloud originale da cui ha avuto origine la serie temporale sottostante.Se le regole non mantengono l'etichetta
location, i dati vengono scritti nuovamente nella posizione del cluster in cui viene eseguito il valutatore delle regole globali.
Ti consigliamo vivamente di conservare le etichette cluster e namespace
nei risultati di valutazione delle regole, se possibile. In caso contrario, il rendimento delle query potrebbe diminuire e potresti riscontrare limiti di cardinalità. La rimozione di entrambe le etichette è vivamente sconsigliata.