Ce document décrit une configuration pour l'évaluation des règles et des alertes dans un déploiement de service géré pour Prometheus qui utilise une collection auto-déployée.
Le schéma suivant illustre un déploiement qui utilise plusieurs clusters dans deux Google Cloud projets et utilise à la fois l'évaluation des règles et des alertes:
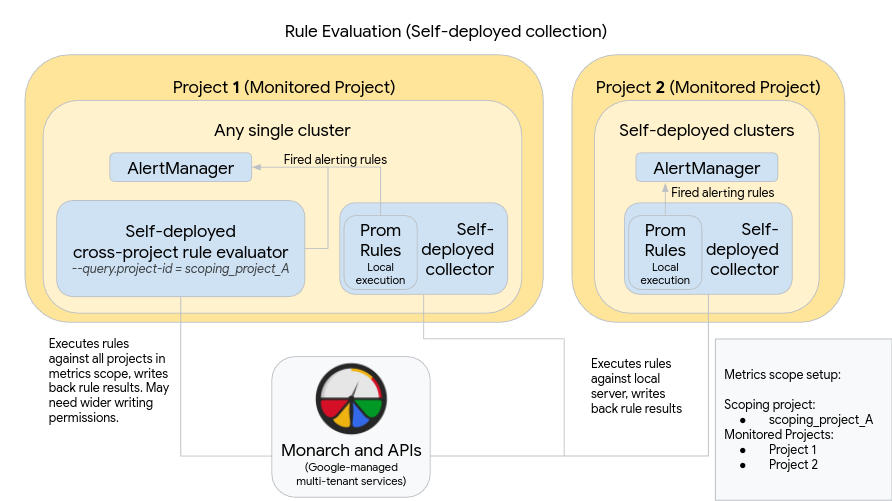
Pour configurer et utiliser un déploiement comme celui du diagramme, notez les points suivants :
Les règles sont installées dans chaque serveur de collection du service géré pour Prometheus, comme c'est le cas lorsque vous utilisez Prometheus standard. L'évaluation des règles s'exécute sur les données stockées localement sur chaque serveur. Les serveurs sont configurés pour conserver les données suffisamment longtemps pour couvrir la période d'analyse de toutes les règles, qui ne dépasse généralement pas une heure. Les résultats de la règle sont écrits dans Monarch après l'évaluation.
Une instance Prometheus AlertManager est déployée manuellement dans chaque cluster. Les serveurs Prometheus sont configurés en modifiant le champ
alertmanager_configdu fichier de configuration pour envoyer des règles d'alerte déclenchées à leur instance AlertManager locale. Les workflows de silence, d'accusé de réception et de gestion des incidents sont généralement gérés dans un outil tiers tel que PagerDuty.Vous pouvez centraliser la gestion des alertes sur plusieurs clusters en un seul gestionnaire d'alertes à l'aide d'une ressource Endpoints Kubernetes.
Un cluster unique exécuté dans Google Cloud est désigné comme cluster d'évaluation de la règle globale pour un champ d'application des métriques. L'évaluateur de règle autonome est déployé dans ce cluster et les règles sont installées à l'aide du format de fichier de règles Prometheus standard.
L'évaluateur de règle autonome est configuré pour utiliser scoping_project_A, qui contient les projets 1 et 2. Les règles exécutées sur scoping_project_A font automatiquement l'objet d'une distribution ramifiée vers les projets 1 et 2. Le compte de service sous-jacent doit disposer des autorisations du lecteur Monitoring pour scoping_project_A.
L'évaluateur de règle est configuré pour envoyer des alertes au gestionnaire d'alertes local Prometheus à l'aide du champ
alertmanager_configdu fichier de configuration.
L'utilisation d'un évaluateur de règle global auto-déployé peut avoir des effets inattendus, selon que vous conservez ou agrégez les libellés project_id, location, cluster et namespace dans vos règles :
Si vos règles conservent le libellé
project_id(à l'aide d'une clauseby(project_id)), les résultats de la règle sont réécrits dans Monarch à l'aide de la valeurproject_idd'origine de la série temporelle sous-jacente.Dans ce scénario, vous devez vous assurer que le compte de service sous-jacent dispose des autorisations Rédacteur de métriques Monitoring pour chaque projet surveillé dans scoping_project_A. Si vous ajoutez un nouveau projet surveillé à scoping_project_A, vous devez également ajouter manuellement une nouvelle autorisation au compte de service.
Si vos règles ne conservent pas le libellé
project_id(en n'utilisant pas de clauseby(project_id)), les résultats de la règle sont réécrits dans Monarch à l'aide de la valeurproject_iddu cluster où l'évaluateur de règle global est en cours d'exécution.Dans ce scénario, vous n'avez pas besoin de modifier davantage le compte de service sous-jacent.
Si vos règles conservent le libellé
location(à l'aide d'une clauseby(location)), les résultats de la règle sont réécrits dans Monarch à l'aide de chaque région Google Cloud d'origine à partir de laquelle la série temporelle sous-jacente est créée.Si vos règles ne conservent pas le libellé
location, les données sont réécrites à l'emplacement du cluster dans lequel l'évaluateur de règle global est exécuté.
Dans la mesure du possible, nous vous recommandons vivement de conserver les libellés cluster et namespace dans les résultats de l'évaluation des règles. Sinon, les performances de requête risquent de diminuer, et vous risquez de rencontrer des limites de cardinalité. Il est fortement déconseillé de supprimer les deux libellés.