Este documento descreve como configurar um ambiente que combina coletores autoimplantados com coletores gerenciados em diferentes projetos e clusters doGoogle Cloud .
É altamente recomendável usar a coleta gerenciada em todos os ambientes do Kubernetes. Assim, você praticamente elimina a sobrecarga de executar coletores Prometheus no cluster. Vale lembrar que é possível executar coletores gerenciados e autoimplantados no mesmo cluster. É aconselhável seguir uma abordagem consistente de monitoramento, mas você pode optar por combinar os métodos de implantação em alguns casos de uso específicos (por exemplo, para hospedar um gateway push, conforme ilustrado neste documento).
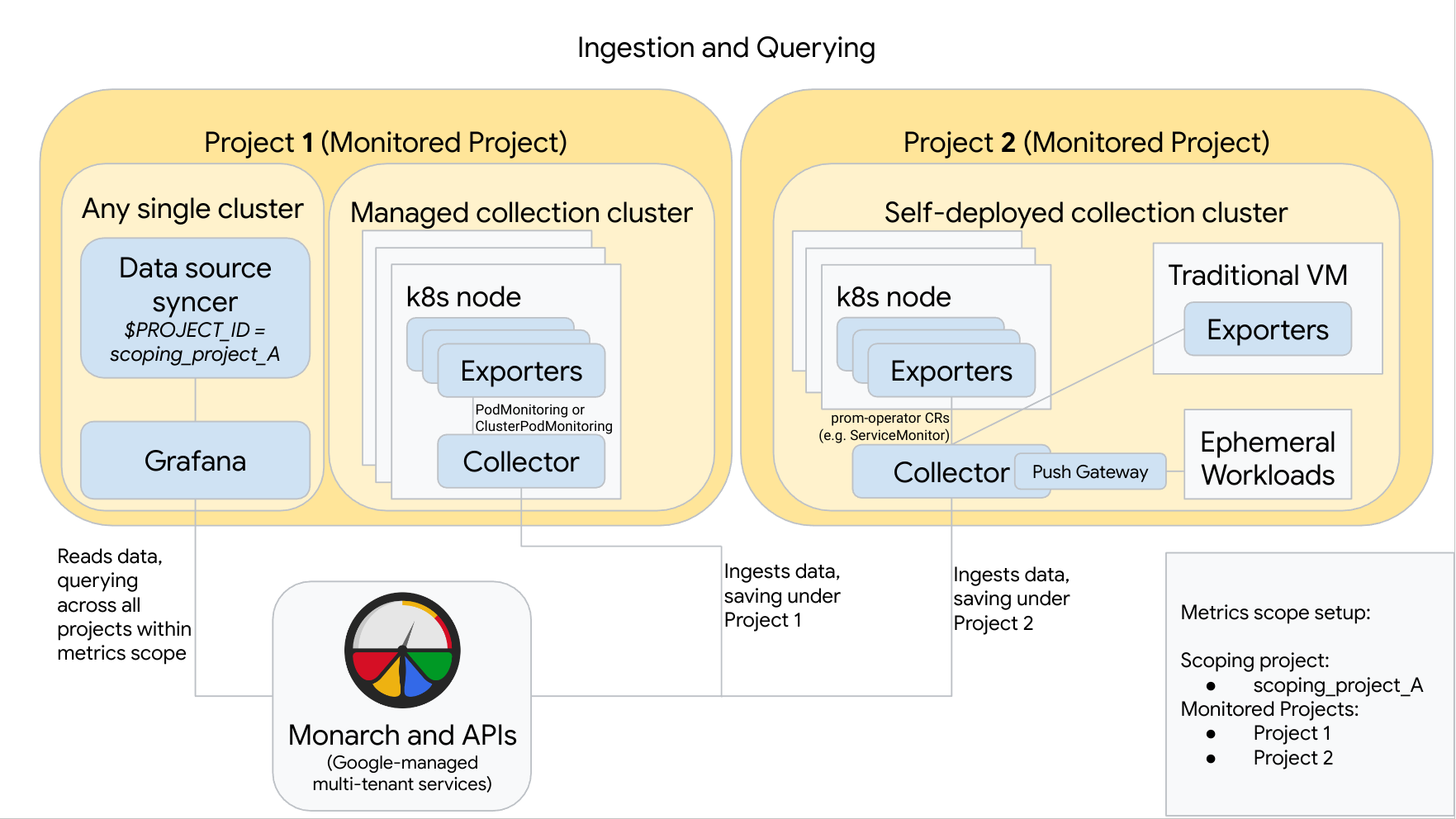
O diagrama a seguir ilustra uma configuração que usa dois projetosGoogle Cloud , três clusters e combina coleta gerenciada e autoimplantada. O diagrama também é válido para quem usa somente a coleta gerenciada ou autoimplantada, basta ignorar os estilos de coleta que não são usados:
Para definir e usar uma configuração como a do diagrama:
É necessário instalar todos os exportadores necessários nos clusters. já que o Google Cloud Managed Service para Prometheus faz isso em seu nome.
O Projeto 1 tem um cluster que faz a coleta gerenciada, executado como um agente de nó. Os coletores são configurados com recursos PodMonitoring para fazer a raspagem de dados dos destinos em um namespace; e com recursos ClusterPodMonitoring para fazer a raspagem de dados dos destinos em um cluster. Os PodMonitorings precisam ser aplicados em todos os namespaces em que você quer coletar métricas. Já ps ClusterPodMonitorings são aplicados uma vez por cluster.
Todos os dados coletados no Projeto 1 são salvos no Monarch em "Projeto 1". Esses dados são armazenados por padrão na região do Google Cloud de onde foram emitidos.
O Projeto 2 tem um cluster que faz a coleta autoimplantada com prometheus-operator, executado como um serviço independente. Esse cluster é configurado para usar PodMonitors ou ServiceMonitors de prometheus-operator para fazer a raspagem de dados de exportadores de pods ou VMs.
O Projeto 2 também hospeda um arquivo secundário de gateway push para coletar métricas de cargas de trabalho temporárias.
Todos os dados coletados no Projeto 2 são salvos no Monarch em "Projeto 2". Esses dados são armazenados por padrão na região do Google Cloud de onde foram emitidos.
O projeto 1 também tem um cluster que executa o Grafana e o sincronizador de fonte de dados. No exemplo, esses componentes ficam hospedados em um cluster independente, mas podem ser hospedados em qualquer cluster único.
O sincronizador de fonte de dados está configurado para que use scoping_project_A, e a conta de serviço subjacente tem permissões de Leitor do Monitoring para scoping_project_A.
Quando um usuário emite consultas do Grafana, o Monarch expande scoping_project_A para os projetos monitorados constituintes e retorna resultados para o Projeto 1 e o Projeto 2 em todas as Google Cloud regiões. Todas as métricas mantêm os identificadores originais
project_idelocation(regiãoGoogle Cloud ) para agrupamento e filtragem.
Se o cluster não estiver em execução no Google Cloud, configure manualmente
os identificadores project_id e location. Para saber mais sobre como definir
esses valores, consulte Executar o Managed Service para Prometheus fora do
Google Cloud.
Não faça a federação ao usar o Managed Service para Prometheus. Para reduzir a cardinalidade e o custo na "visualização completa" de dados antes de enviá-los ao Monarch, use a agregação local. Para saber mais, consulte Configurar a agregação local.