Client
Spanner unterstützt SQL-Abfragen. Hier eine Beispielabfrage:
SELECT s.SingerId, s.FirstName, s.LastName, s.SingerInfo
FROM Singers AS s
WHERE s.FirstName = @firstName;
Die Formulierung @firstName ist ein Verweis auf einen Abfrageparameter. Sie können einen Abfrageparameter überall verwenden, wo ein Literalwert verwendet werden kann. Es wird dringend empfohlen, Parameter in programmatischen APIs zu verwenden. Die Verwendung von Abfrageparametern hilft, SQL-Injection-Angriffe zu vermeiden. Die daraus resultierenden Abfragen werden eher von verschiedenen serverseitigen Caches profitieren. Siehe Caching unten.
Abfrageparameter müssen auf einen Wert begrenzt werden, wenn die Abfrage ausgeführt wird. Beispiel:
Statement statement =
Statement.newBuilder("SELECT s.SingerId...").bind("firstName").to("Jimi").build();
try (ResultSet resultSet = dbClient.singleUse().executeQuery(statement)) {
while (resultSet.next()) {
...
}
}
Sobald Spanner einen API-Aufruf erhält, analysiert es die Abfrage und Grenzparameter, um festzustellen, welcher Spanner-Serverknoten die Abfrage bearbeiten soll. Der Server sendet einen Stream von Ergebniszeilen zurück, die von den Aufrufen an ResultSet.next() genutzt werden.
Ausführung von Abfragen
Die Abfrageausführung beginnt mit dem Eintreffen der Anfrage „Abfrage ausführen“ auf einem beliebigen Spanner-Server. Der Server führt die folgenden Schritte aus:
- Die Anfrage validieren
- Den Text der Suchanfrage parsen
- Eine erste Abfragealgebra generieren
- Eine optimierte Abfragealgebra generieren
- Einen ausführbaren Abfrageplan generieren
- Den Plan ausführen (Berechtigungen überprüfen, Daten lesen, Ergebnisse codieren usw.)
Parsen
Der SQL-Parser analysiert den Abfragetext und wandelt ihn in eine abstrakte Syntaxstruktur um. Es extrahiert die grundlegende Abfragestruktur (SELECT …
FROM … WHERE …) und führt syntaktische Prüfungen durch.
Algebra
Das Typsystem von Spanner kann Skalare, Arrays, Strukturen usw. darstellen. Die Abfragealgebra definiert Vorgänge für Tabellenscans, das Filtern, Sortieren/Gruppieren, verschiedene Verknüpfungen, Aggregation und vieles mehr. Die ursprüngliche Abfragealgebra besteht aus der Ausgabe des Parsers. Feldnamenreferenzen in der Strukturansicht werden mit dem Datenbankschema gelöst. Dieser Code überprüft auch auf semantische Fehler (z. B. falsche Anzahl von Parametern, nicht übereinstimmende Typen usw.).
Der nächste Schritt ("Abfrageoptimierung") geht von der ersten Algebra aus und erzeugt eine optimalere Algebra. Diese kann einfacher, effizienter oder einfach besser an die Fähigkeiten der Ausführungsengine angepasst sein. Beispielsweise könnte die erste Algebra nur "Join" angeben, wobei die optimierte Algebra "Hash Join" angibt.
Ausführung
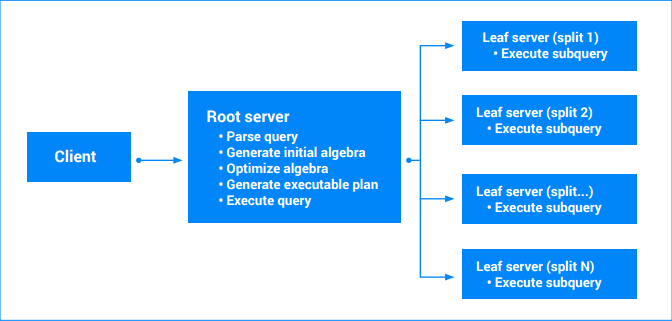
Der endgültige ausführbare Abfrageplan wird aus der neu geschriebenen Algebra erstellt. Im Grunde ist der ausführbare Plan eine gerichtete azyklische Grafik von "Iteratoren". Jeder Iterator enthält eine Wertesequenz. Iteratoren verbrauchen eventuell Eingaben, um Ausgaben zu generieren (z. B. Iterator sortieren). Abfragen mit einem einzelnen Split können von einem einzelnen Server ausgeführt werden (von dem, der die Daten enthält). Der Server scannt Bereiche verschiedener Tabellen und führt Joins, Aggregationen und alle anderen von der Abfragealgebra definierten Vorgänge aus.
Abfragen mit mehreren Splits werden in mehrere Teile einbezogen. Ein Teil der Abfrage wird weiterhin auf dem Hauptserver (Stammserver) ausgeführt. Andere partielle Unterabfragen werden an Blattknoten übergeben (die Inhaber der Splits, die gelesen werden). Diese Übergabe kann für komplexe Abfragen rekursiv angewendet werden, was zu einer Baumstruktur von Serverausführungen führt. Alle Server vereinbaren einen Zeitstempel, damit die Abfrageergebnisse ein konsistenter Snapshot der Daten sind. Jeder Blattserver gibt einen Stream von Teilergebnissen zurück. Bei Abfragen mit Aggregation können dies partiell aggregierte Ergebnisse sein. Der Abfrage-Stammserver verarbeitet die Ergebnisse von den Blatt-Servern und führt den Rest des Abfrageplans aus. Weitere Informationen finden Sie unter Abfrage-Ausführungspläne.
Wenn eine Abfrage mehrere Splits umfasst, kann Spanner die Abfrage parallel über die Splits hinweg ausführen. Der Grad der Parallelität hängt vom Datenbereich ab, der von der Abfrage gescannt wird, vom Abfrageausführungsplan und von der Verteilung der Daten auf die Teilungen. Spanner legt den maximalen Parallelisierungsgrad für eine Abfrage automatisch anhand der Instanzgröße und der Instanzkonfiguration (regional oder mehrregional) fest, um eine optimale Abfrageleistung zu erzielen und eine Überlastung der CPU zu vermeiden.
Caching
Viele Artefakte der Abfrageverarbeitung werden automatisch im Cache gespeichert und noch einmal für alle nachfolgenden Abfragen verwendet. Dazu gehören Abfragealgebren, ausführbare Abfragepläne usw. Das Caching basiert auf dem Abfragetext, den Namen und Typen der gebundenen Parameter und so weiter. Aus diesem Grund ist die Verwendung von gebundenen Parametern wie @firstName im obigen Beispiel besser als die Verwendung von Literalwerten im Abfragetext. Erstere können einmal im Cache gespeichert werden und unabhängig vom tatsächlichen Grenzwert wiederverwendet werden. Weitere Informationen finden Sie unter Optimieren der Spanner-Abfrageleistung.
Fehlerbehandlung
Der Stream der Ergebniszeilen von der Methode executeQuery kann aus verschiedenen Gründen unterbrochen werden: vorübergehende Netzwerkfehler, Übergabe eines Splits von einem Server an einen anderen (z.B. Load Balancing), Serverneustarts (z.B. Upgrade auf eine neue Version). Zur Behebung dieser Fehler sendet Spanner intransparente „Fortfahren-Tokens“ und Batches partieller Ergebnisdaten. Diese Fortfahren-Tokens können bei der Wiederholung der Abfrage verwendet werden, um an der Stelle fortzufahren, an der die unterbrochene Abfrage abgebrochen wurde. Wenn Sie die Spanner-Clientbibliotheken verwenden, geschieht dies automatisch. Nutzer der Clientbibliothek müssen sich daher nicht mit solchen vorübergehenden Fehlern befassen.