
Spanner
実質的に無制限のスケーリング機能を備えた、常時稼働のデータベース
リレーショナル、グラフ、Key-Value、検索を統合した単一のデータベースを使用して、インテリジェントでミッション クリティカルなアプリを構築できます。Spanner Omni を使用してどこでも実行できます。
今すぐ 90 日間無料トライアル インスタンスをお試しください。
機能
マルチモデル: 1 つのデータベースで多くの可能性を実現
Spanner のマルチモデル機能により、Gemini Enterprise エージェント プラットフォームとのネイティブなインテグレーション、複雑な関係をクエリするための Spanner Graph、セマンティック検索のためのベクトル検索、組み込みの全文検索を活用して、インテリジェントで AI 対応のアプリケーションを運用リレーショナル データと NoSQL データの上に構築できます。これらはすべて「真の ZeroETL」の相互運用性によって実現されます。この統合アプローチにより、データサイロの解消、費用の節約、運用とセキュリティのタッチポイントの削減が実現し、すべてのモデルでデータの整合性が確保されます。

エージェント型 AI アプリケーションの基盤
Gemini Enterprise Agent Platform とシームレスに統合して、最新の Gemini モデルを活用できます。Agent Development Kit(ADK)を使用して、リアルタイムの運用状態に基づいて推論する自律エージェントを構築し、AI デベロッパーの生産性を最大化します。リモート MCP サーバーを使用して、Gemini CLI などのバイブ コーディング プラットフォームで Spanner のデータと自然言語で対話できます。Spanner の AI 関数を活用することで、複雑なセマンティック オペレーションを SQL で直接実行でき、インテリジェンスをデータに近づけることが可能です。 Spanner の会話型分析では、自然言語を使用してデータベース データについてエージェントとチャットできます。Data Agent Kit は、セキュアな Model Context Protocol(MCP)ツール、ネイティブ IDE プラグイン、事前にコード化されたデータ エンジニアリング、データ サイエンス、データアプリ デベロッパーのスキルを 1 つのオープンソース パッケージにバンドルすることで、ワークフローを合理化します。

場所を選ばず実行
Spanner Omni は、Google Cloud のグローバルに分散されたマルチモデル データベースである Spanner のダウンロード可能なバージョンです。Spanner の業界トップクラスのスケール、高可用性、強グローバル整合性を、インフラストラクチャ(オンプレミス、クラウド間、ノートパソコン)に拡張します。Spanner Omni は、クロス クラウド レジリエンスが必要な場合や、エージェント型 AI アプリケーションを強化するために Google Cloud の外部で動作するスケールアウト データベースが必要な場合に理想的なソリューションです。

ビジネスのスピードに合わせてリアルタイムの分析情報を取得

高速なネットワーク環境にも支障なく対応
大きな夢を抱き、小さく始めて、ニーズが拡大するにつれて簡単にスケーリングできます。Spanner は、水平方向の読み取りと「書き込み」のスケーラビリティにより、増大するデータセットと要求の厳しいワークロードをシームレスに処理します。自動データベース シャーディングにより最適なデータ分散を実現します。また、地域パーティショニングにより、データをユーザーのいる場所に近づけることでレイテンシを低減します。 Spanner Data Boost を使用すると、ワークロードから分離されたクエリ処理により、需要のピーク時でも一貫して高いパフォーマンスを得られます。

常時利用が可能
アプリケーションを常時オンにして、ユーザーにサービスを提供する準備ができた状態にします。Spanner は、自動メンテナンスと柔軟なデプロイ オプションにより、最大 99.999% の可用性を実現します。 単一リージョン、デュアルリージョン、マルチリージョンの構成から選択して、お客様固有の可用性とフォールト トレランスの要件を満たします。

一貫性のあるトランザクションを保証
データの不整合や、それを管理する複雑さとは、もうお別れです。Spanner は、強力なトランザクション整合性を保証します。つまり、データのサイズや分布に関係なく、すべての読み取りに最新の更新が反映されます。アプリケーションが常にデータの一貫したビューを備えていることを確信して、自信を持って構築できます。
信頼できるセキュリティとコンプライアンス
Spanner により安全でコンプライアンス準拠のプラットフォームにデータを預けることができます。データベース センター で一元的な管理と制御を実現し、クラウド データベースの管理を簡素化します。Spanner は、保存データと転送データの暗号化、Identity and Access Management(IAM)によるきめ細かいアクセス管理、業界標準への準拠など、エンタープライズ グレードのセキュリティと制御を提供します。ポイントインタイム リカバリをはじめとする堅牢なバックアップと復元の機能でデータの保護を強化し、運用の安心感を実現します。
データベースの比較
| データベース属性 | 他のリレーショナル DB | 他の非リレーショナル DB | Spanner |
|---|---|---|---|
スキーマ | 静的 | 動的 | 動的 |
SQL | ○ | × | ○ (PostgreSQL、Google SQL) |
履歴 | ACID (原子性、整合性、独立性、耐久性) | 結果 | 強力な ACID TrueTime による順序付けで実現 |
スケーラビリティ | 垂直型 (より大型なマシンを使用) | 水平型 (マシンを追加します) | 水平型 |
サービス提供状況 | フェイルオーバー(ダウンタイム) | 高 | 99.999% の高 SLA |
レプリケーション | 構成可能 | 構成可能 | 自動 |
Gartner® は、軽量トランザクション ユースケースで Spanner を第 1 位にランク付けしました。レポート全文をダウンロード
スキーマ
静的
動的
動的
履歴
ACID
(原子性、整合性、独立性、耐久性)
結果
強力な ACID
TrueTime による順序付けで実現
スケーラビリティ
垂直型
(より大型なマシンを使用)
水平型
(マシンを追加します)
水平型
サービス提供状況
フェイルオーバー(ダウンタイム)
高
99.999% の高 SLA
レプリケーション
構成可能
構成可能
自動
Gartner® は、軽量トランザクション ユースケースで Spanner を第 1 位にランク付けしました。レポート全文をダウンロード
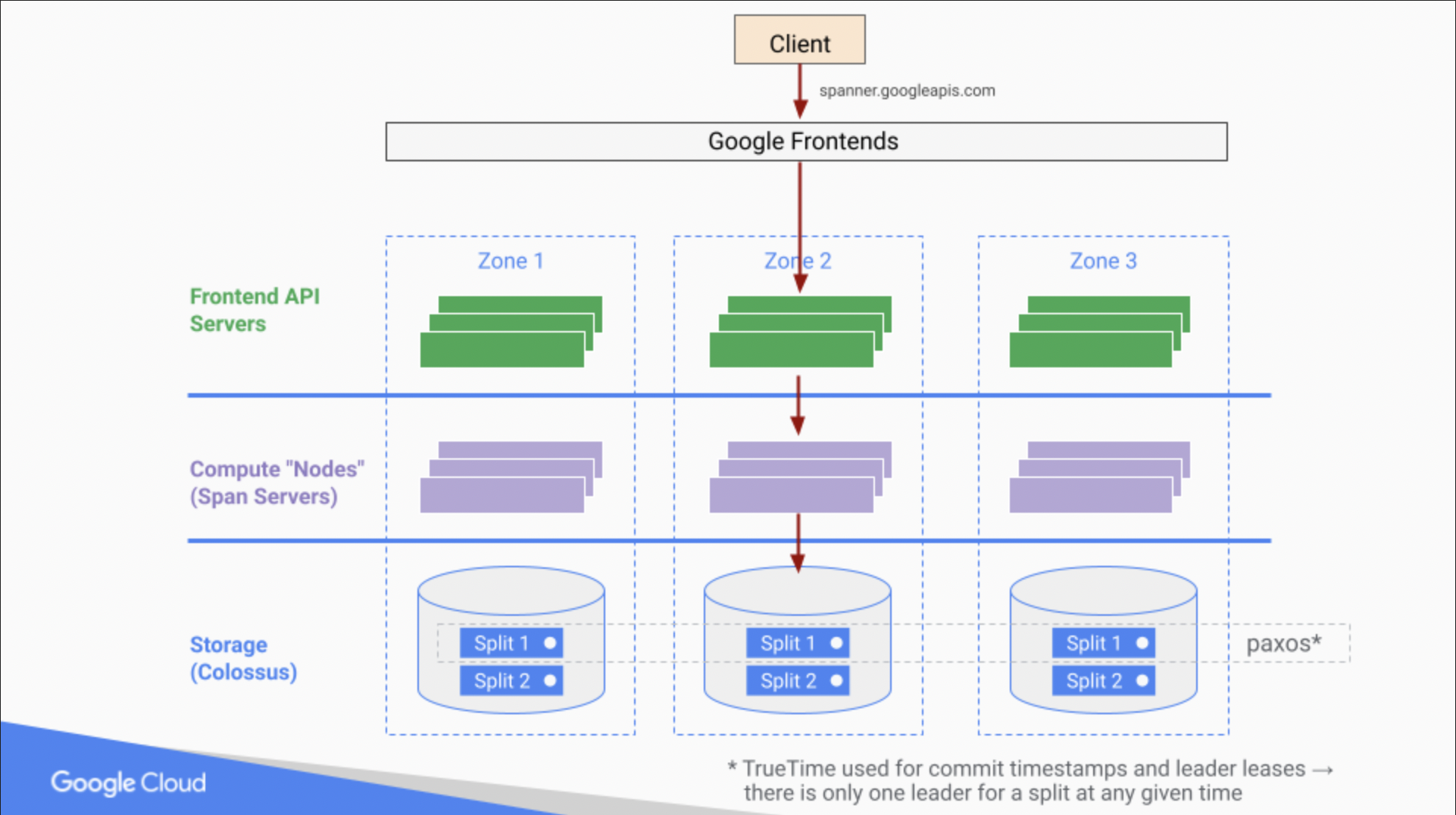
移行とモダナイゼーション
MySQL と Cassandra のモダナイゼーションを効率化
MySQL と Cassandra のモダナイゼーションを効率化
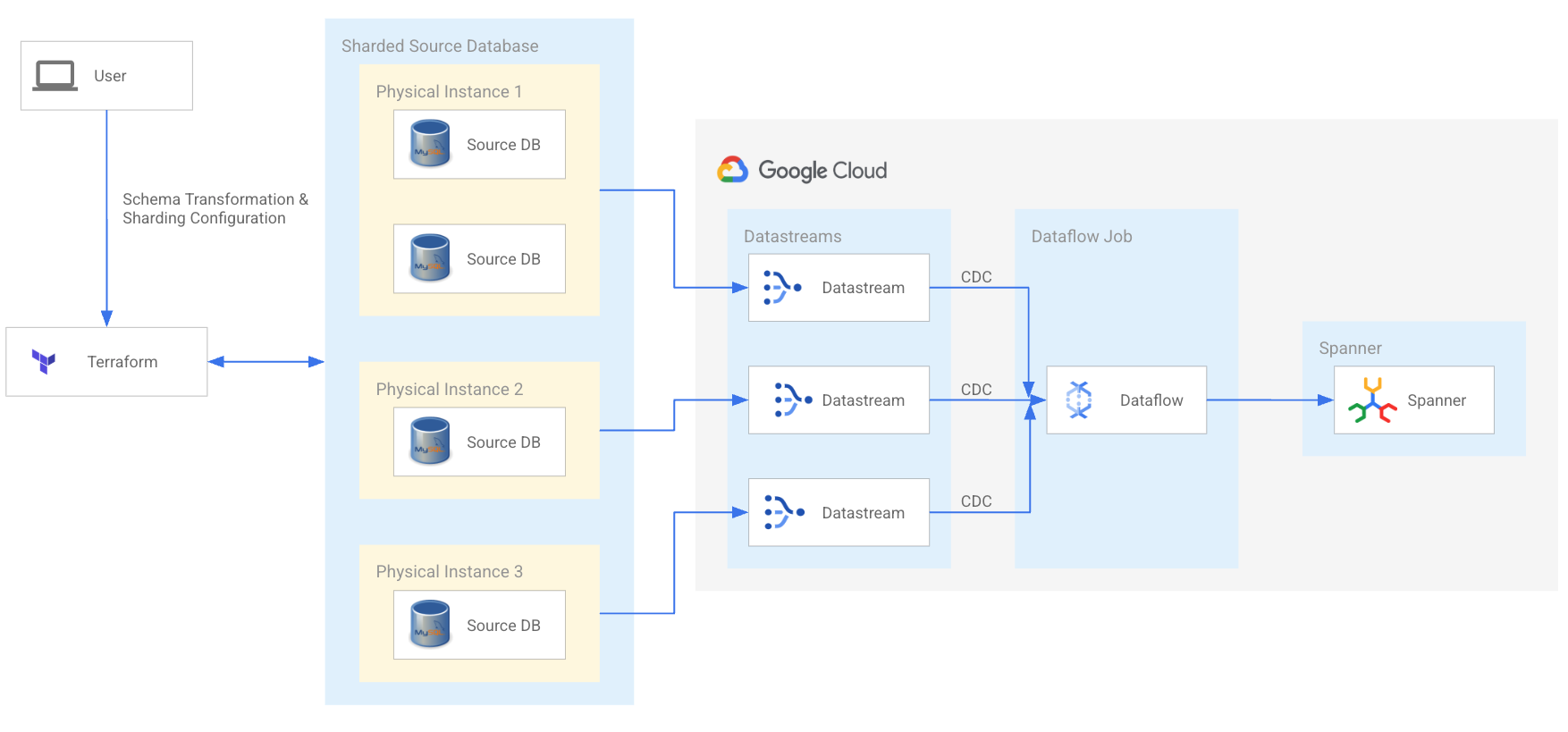
シャーディングされた MySQL と Cassandra のワークロードをモダナイズして、開発チームを強化し、次の成長フェーズに向けてスケーリングします。オープンソースの Spanner 移行ツールと、移行を効率化できる認定サービス パートナーとテクノロジー パートナーのネットワークを活用できます。
チュートリアル、クイックスタート、ラボ
MySQL と Cassandra のモダナイゼーションを効率化
MySQL と Cassandra のモダナイゼーションを効率化
シャーディングされた MySQL と Cassandra のワークロードをモダナイズして、開発チームを強化し、次の成長フェーズに向けてスケーリングします。オープンソースの Spanner 移行ツールと、移行を効率化できる認定サービス パートナーとテクノロジー パートナーのネットワークを活用できます。
ハイブリッド クラウドとマルチクラウドのレジリエンス
多様な環境でビジネスの継続性を確保
多様な環境でビジネスの継続性を確保
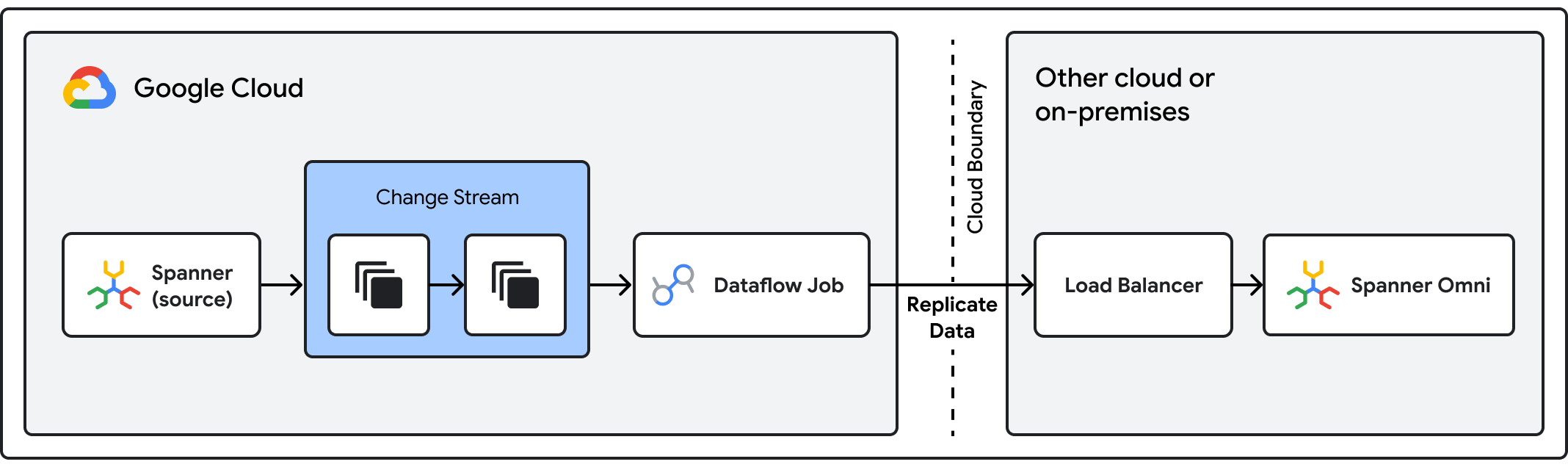
単一のクラウド プロバイダの境界を超えた、真に復元力のある高可用性アーキテクチャを構築できます。セカンダリ クラウドまたはオンプレミスのデータセンターに Spanner Omni をデプロイし、Google Cloud のプライマリ Spanner マネージド サービスの「ホット/コールド」フェイルオーバー サイトとして使用することで、重要なセーフティ ネットを構築できます。この「プライマリ/セカンダリ」アーキテクチャにより、サービス停止に対する脆弱性が軽減され、金融サービス業界の厳格な「ストレス下での離脱」規制要件を満たすことが可能です。
チュートリアル、クイックスタート、ラボ
多様な環境でビジネスの継続性を確保
多様な環境でビジネスの継続性を確保
単一のクラウド プロバイダの境界を超えた、真に復元力のある高可用性アーキテクチャを構築できます。セカンダリ クラウドまたはオンプレミスのデータセンターに Spanner Omni をデプロイし、Google Cloud のプライマリ Spanner マネージド サービスの「ホット/コールド」フェイルオーバー サイトとして使用することで、重要なセーフティ ネットを構築できます。この「プライマリ/セカンダリ」アーキテクチャにより、サービス停止に対する脆弱性が軽減され、金融サービス業界の厳格な「ストレス下での離脱」規制要件を満たすことが可能です。
ユーザー プロフィールと利用資格
重要なユーザーデータをあらゆる規模に応じて安全に管理
重要なユーザーデータをあらゆる規模に応じて安全に管理
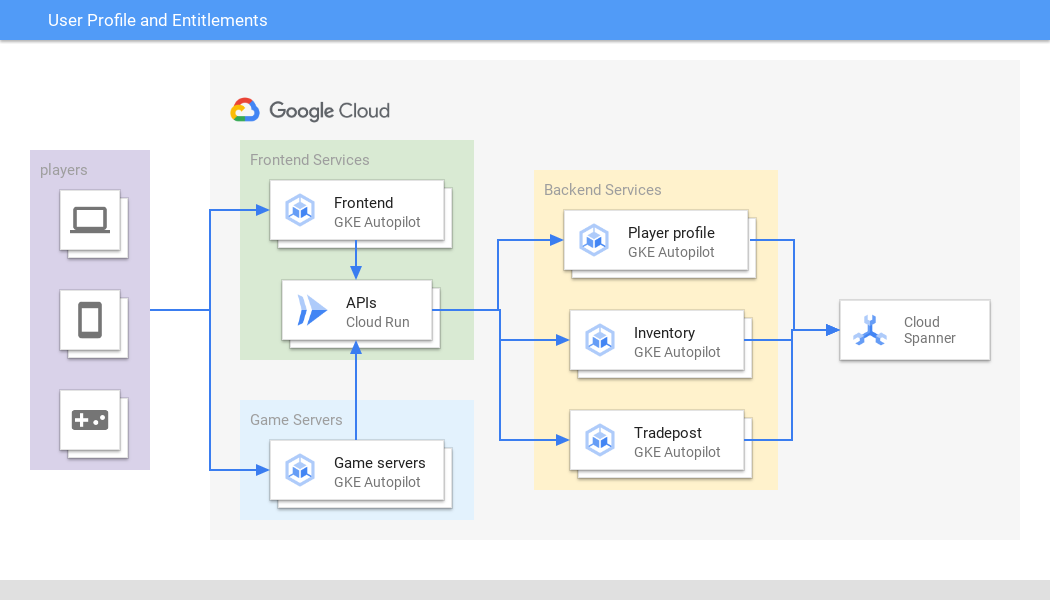
ユーザー プロファイルの管理は重要な機能であり、Spanner のスケーラビリティ、可用性、グローバルな整合性を必要とします。あらゆるゲーム、プラットフォーム、地域のプレーヤーのエントリー ポイントを管理できます。同様に、金融サービス企業は、Spanner を使用して顧客情報と製品サービスを管理できます。
チュートリアル、クイックスタート、ラボ
重要なユーザーデータをあらゆる規模に応じて安全に管理
重要なユーザーデータをあらゆる規模に応じて安全に管理
ユーザー プロファイルの管理は重要な機能であり、Spanner のスケーラビリティ、可用性、グローバルな整合性を必要とします。あらゆるゲーム、プラットフォーム、地域のプレーヤーのエントリー ポイントを管理できます。同様に、金融サービス企業は、Spanner を使用して顧客情報と製品サービスを管理できます。
会計台帳
最新で整合性のあるグローバル トランザクションのビューを取得
最新で整合性のあるグローバル トランザクションのビューを取得
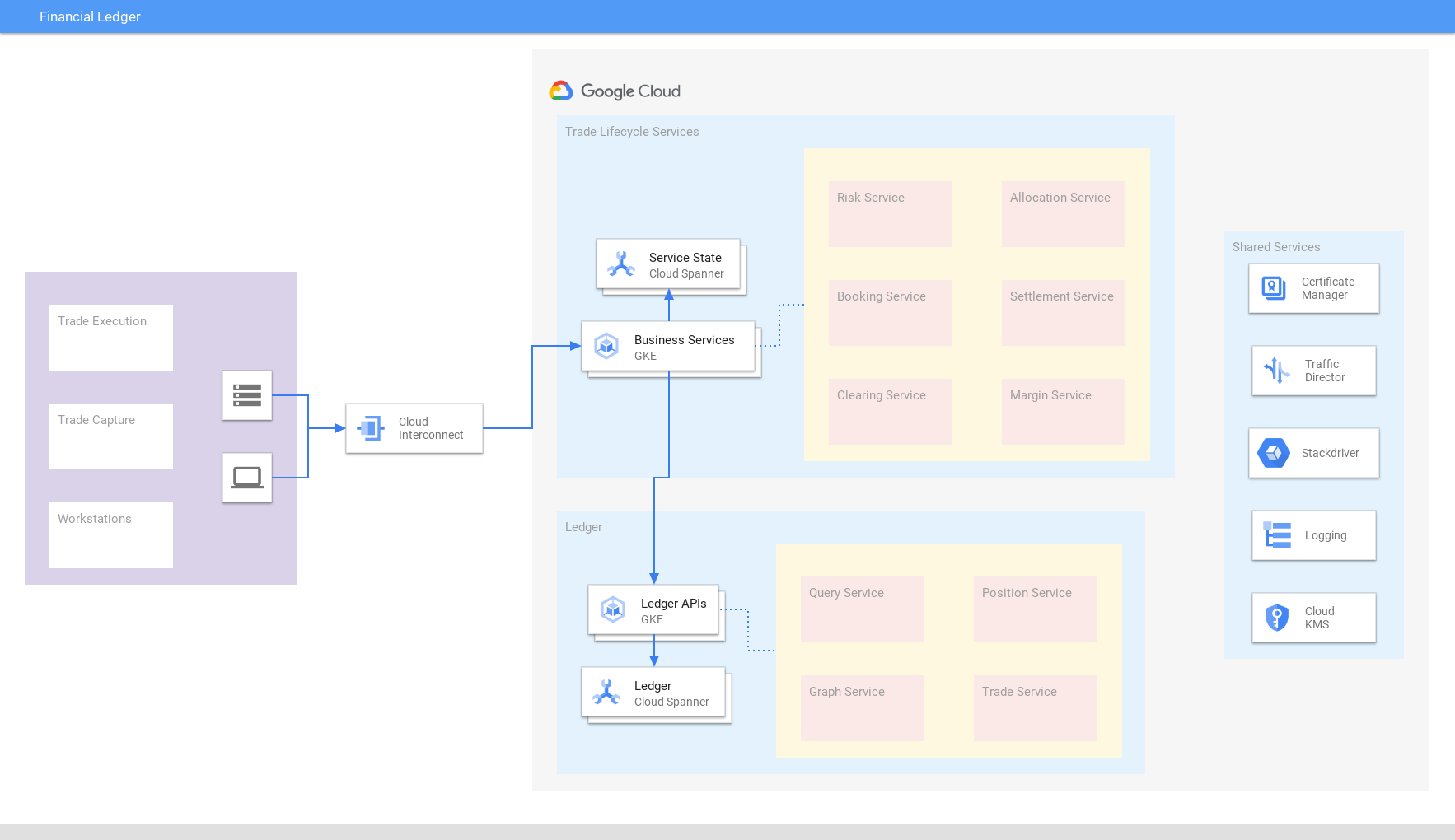
Spanner 上に構築された、統合された取引台帳に世界各地の金融トランザクション、取引、決済、ポジションを一元化することで、外部の整合性とスケーラビリティを保証します。データを統合することで、市場状況や規制要件の変化に迅速に対応できます。同様に、小売業や e コマースの企業も、在庫台帳に Spanner を使用しています。
チュートリアル、クイックスタート、ラボ
最新で整合性のあるグローバル トランザクションのビューを取得
最新で整合性のあるグローバル トランザクションのビューを取得
Spanner 上に構築された、統合された取引台帳に世界各地の金融トランザクション、取引、決済、ポジションを一元化することで、外部の整合性とスケーラビリティを保証します。データを統合することで、市場状況や規制要件の変化に迅速に対応できます。同様に、小売業や e コマースの企業も、在庫台帳に Spanner を使用しています。
オンライン バンキング
デジタル エクスペリエンスのインタラクティビティを常時提供
デジタル エクスペリエンスのインタラクティビティを常時提供
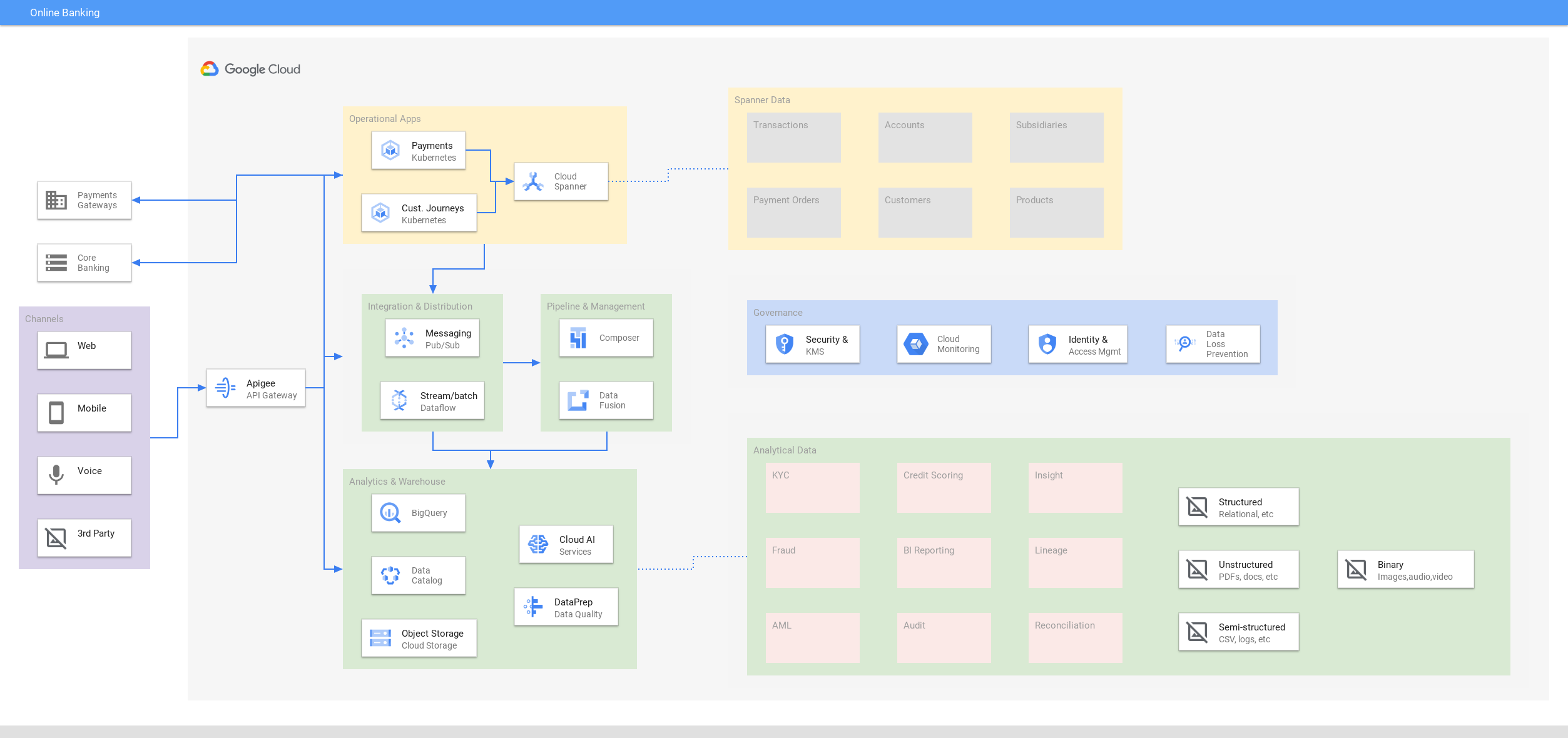
消費者は、通常の銀行業務時間外に、重要な金融データにデバイス上でアクセスできることを期待しています。デベロッパーは、手動シャーディングや結果整合性などの運用上のオーバーヘッドにとらわれず、新しいエクスペリエンスの開発に集中できます。99.999% の可用性と、メンテナンス不要により、リスクとダウンタイムが削減されます。
チュートリアル、クイックスタート、ラボ
デジタル エクスペリエンスのインタラクティビティを常時提供
デジタル エクスペリエンスのインタラクティビティを常時提供
消費者は、通常の銀行業務時間外に、重要な金融データにデバイス上でアクセスできることを期待しています。デベロッパーは、手動シャーディングや結果整合性などの運用上のオーバーヘッドにとらわれず、新しいエクスペリエンスの開発に集中できます。99.999% の可用性と、メンテナンス不要により、リスクとダウンタイムが削減されます。
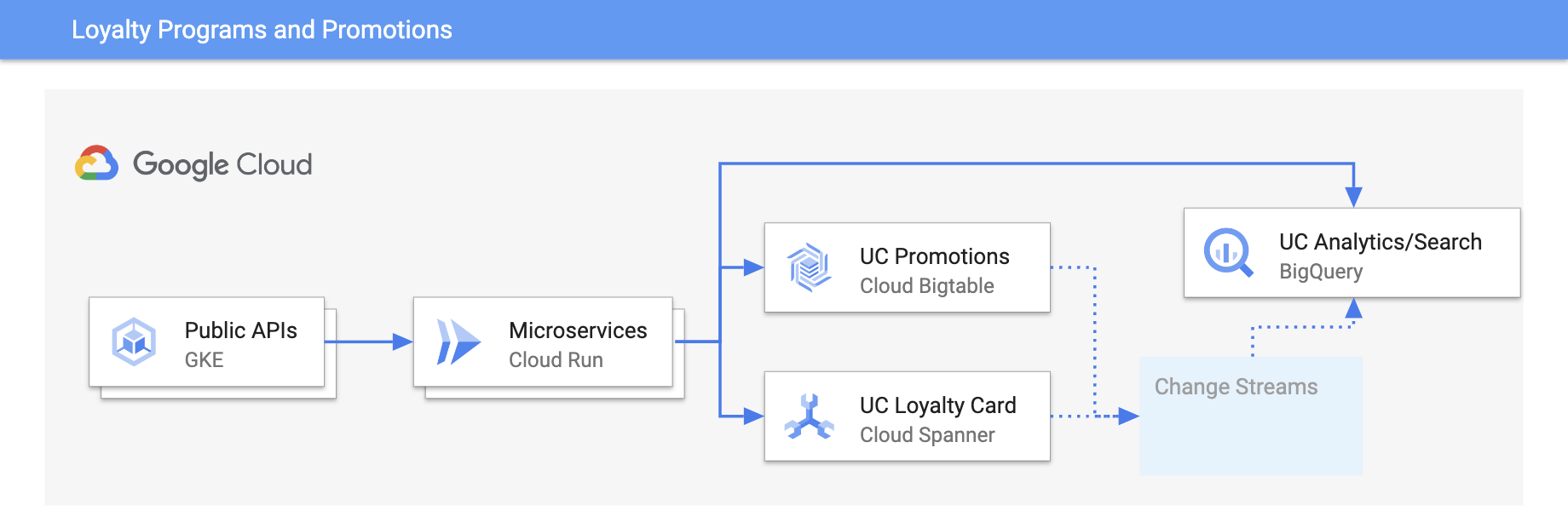
ポイント プログラムとプロモーション
リアルタイム アップデートでエクスペリエンスをカスタマイズする
リアルタイム アップデートでエクスペリエンスをカスタマイズする
ポイント プログラムの顧客参加と嗜好を追跡して傾向を分析し、顧客満足度を改善します。同様に、ゲーム会社も Spanner を使用して、パーソナライズされたリーダーボードをゲームに組み込んでいます。
チュートリアル、クイックスタート、ラボ
リアルタイム アップデートでエクスペリエンスをカスタマイズする
リアルタイム アップデートでエクスペリエンスをカスタマイズする
ポイント プログラムの顧客参加と嗜好を追跡して傾向を分析し、顧客満足度を改善します。同様に、ゲーム会社も Spanner を使用して、パーソナライズされたリーダーボードをゲームに組み込んでいます。
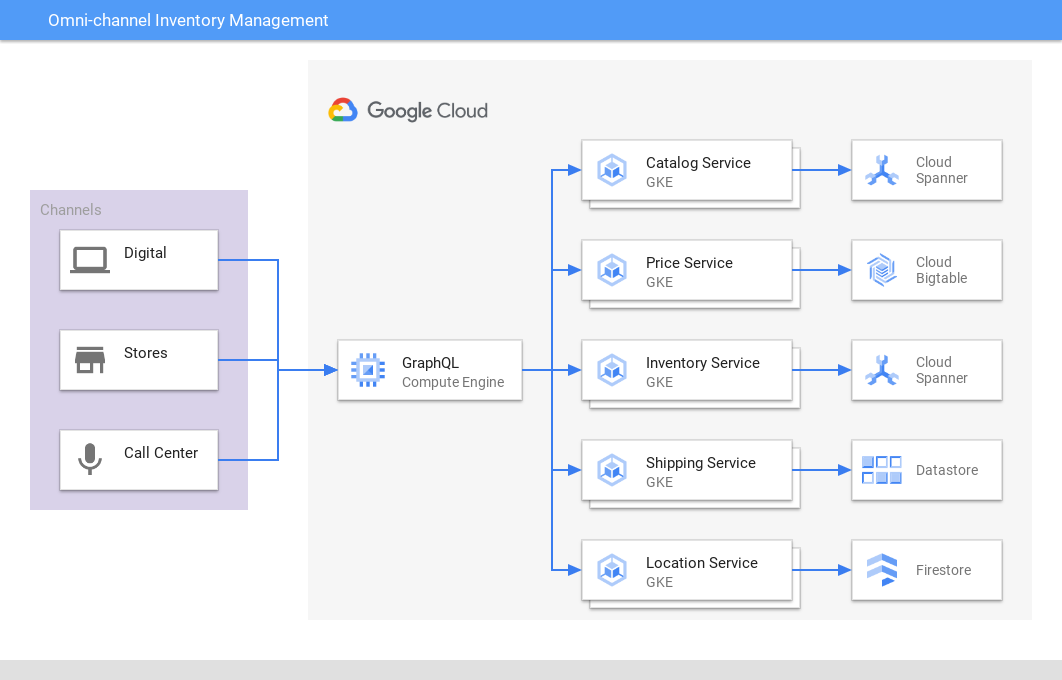
オムニチャネル在庫管理
複数のチャネルとアプリで一貫性のあるビューを提供する
複数のチャネルとアプリで一貫性のあるビューを提供する
Spanner は、小売業の在庫と注文に関して、高パフォーマンスで信頼できる唯一の情報源を提供します。オンライン、店舗、配送センター、配送全体で在庫と需要を照合し、カスタマー エクスペリエンスと収益性を向上させます。ゲーム会社も同様に、Spanner を使用してゲーム内のインベントリ データを保存しています。
チュートリアル、クイックスタート、ラボ
複数のチャネルとアプリで一貫性のあるビューを提供する
複数のチャネルとアプリで一貫性のあるビューを提供する
Spanner は、小売業の在庫と注文に関して、高パフォーマンスで信頼できる唯一の情報源を提供します。オンライン、店舗、配送センター、配送全体で在庫と需要を照合し、カスタマー エクスペリエンスと収益性を向上させます。ゲーム会社も同様に、Spanner を使用してゲーム内のインベントリ データを保存しています。
ナレッジグラフ
データに隠された関係とつながりを明らかにする
データに隠された関係とつながりを明らかにする
Spanner Graph を使用すると、エンティティ(ノードとして表現)とエンティティ間の関係(エッジとして表現)の複雑なつながりを捉えたナレッジグラフを開発できます。これらのつながりによって豊富なコンテキストが提供されるため、ナレッジグラフはナレッジベース システムやレコメンデーション エンジンの開発にとってかけがえのないものとなります。統合された検索機能により、セマンティック理解、キーワード ベースの取得、グラフをシームレスにブレンドして包括的な結果を得ることができます。
チュートリアル、クイックスタート、ラボ
データに隠された関係とつながりを明らかにする
データに隠された関係とつながりを明らかにする
Spanner Graph を使用すると、エンティティ(ノードとして表現)とエンティティ間の関係(エッジとして表現)の複雑なつながりを捉えたナレッジグラフを開発できます。これらのつながりによって豊富なコンテキストが提供されるため、ナレッジグラフはナレッジベース システムやレコメンデーション エンジンの開発にとってかけがえのないものとなります。統合された検索機能により、セマンティック理解、キーワード ベースの取得、グラフをシームレスにブレンドして包括的な結果を得ることができます。
料金
| Spanner の料金の仕組み | Spanner の料金は、コンピューティング容量、Spanner Data Boost、データベース ストレージ、バックアップ ストレージ、レプリケーション、ネットワーク使用量に基づいて決まります。コンピューティングの料金は、選択したエディションと構成によって異なります。確約利用割引により、コンピューティング料金をさらに削減できます。 | |
|---|---|---|
| サービス | 説明 | 料金(米ドル) |
コンピューティング | Standard エディション リージョン(シングル リージョン)構成向けの包括的な既存機能スイートが備わっている コンピューティング容量は、処理ユニットまたはノード(1 ノード = 1,000 処理ユニット)単位でプロビジョニングされます。 | 目安 $0.030 / 100 処理ユニット(レプリカごとに 1 時間あたり) |
Enterprise エディション 運用の簡素化と効率性を高めた、追加のマルチモデル検索機能と検索オプション機能を備えています コンピューティング容量は、処理ユニットまたはノード(1 ノード = 1,000 処理ユニット)単位でプロビジョニングされます。 | 目安 $0.041 / 100 処理ユニット(レプリカごとに 1 時間あたり) | |
Enterprise Plus エディション 最高レベルの可用性、パフォーマンス、コンプライアンス、ガバナンスを備え、特に要求の厳しいワークロードをサポート コンピューティング容量は、処理ユニットまたはノード(1 ノード = 1,000 処理ユニット)単位でプロビジョニングされます。 | 目安 $0.057 / 100 処理ユニット(レプリカごとに 1 時間あたり) | |
Data Boost | CPU、メモリ、ローカルデータ転送などのオンデマンドの分離されたコンピューティング リソース | 目安 $0.00117 サーバーレス処理ユニットごと、1 時間あたり |
データベース ストレージ | 料金は、データベースに保存されているデータの量に基づいており、読み取り / 書き込みレプリカと読み取り専用レプリカのストレージ費用が含まれます。ただし、ウィットネス レプリカは無料です。 SSD ストレージ 運用データに低レイテンシと高スループットが必要な場合は、SSD ストレージを使用します。 | 目安 $0.10 GB /月(レプリカあたり、SSD の場合) |
HDD ストレージ アクセス頻度が低く、高い読み取りレイテンシと低スループットを許容できるデータには、HDD ストレージを使用します。また、指定した時間枠が経過した後に SSD から HDD にデータを移動するように階層化ポリシーを構成することもできます。 | 目安 $0.02 GB /月(レプリカあたり、HDD の場合) | |
バックアップ ストレージ | リージョン構成 料金はバックアップ ストレージの量に基づいて計算され、すべてのレプリカのストレージ費用が含まれます。 | 目安 $0.10 /GB/月(すべてのレプリカを含む) |
デュアルリージョンとマルチリージョンの構成 料金はバックアップ ストレージの量に基づいて計算され、すべてのレプリカのストレージ費用が含まれます。 | 目安 $0.30 /GB/月(すべてのレプリカを含む) | |
レプリケーション | リージョン内のレプリケーション | 無料 |
リージョン間レプリケーション | 目安 $0.04 GB 単位 | |
ネットワーク | Ingress | 無料 |
リージョン内の外向き | 無料 | |
リージョン間の下り(外向き) | 目安 $0.01 GB 単位 | |
Spanner の料金の仕組み
Spanner の料金は、コンピューティング容量、Spanner Data Boost、データベース ストレージ、バックアップ ストレージ、レプリケーション、ネットワーク使用量に基づいて決まります。コンピューティングの料金は、選択したエディションと構成によって異なります。確約利用割引により、コンピューティング料金をさらに削減できます。
コンピューティング
Standard エディション
リージョン(シングル リージョン)構成向けの包括的な既存機能スイートが備わっている
コンピューティング容量は、処理ユニットまたはノード(1 ノード = 1,000 処理ユニット)単位でプロビジョニングされます。
Starting at
$0.030
/ 100 処理ユニット(レプリカごとに 1 時間あたり)
Enterprise エディション
運用の簡素化と効率性を高めた、追加のマルチモデル検索機能と検索オプション機能を備えています
コンピューティング容量は、処理ユニットまたはノード(1 ノード = 1,000 処理ユニット)単位でプロビジョニングされます。
Starting at
$0.041
/ 100 処理ユニット(レプリカごとに 1 時間あたり)
Enterprise Plus エディション
最高レベルの可用性、パフォーマンス、コンプライアンス、ガバナンスを備え、特に要求の厳しいワークロードをサポート
コンピューティング容量は、処理ユニットまたはノード(1 ノード = 1,000 処理ユニット)単位でプロビジョニングされます。
Starting at
$0.057
/ 100 処理ユニット(レプリカごとに 1 時間あたり)
Data Boost
CPU、メモリ、ローカルデータ転送などのオンデマンドの分離されたコンピューティング リソース
Starting at
$0.00117
サーバーレス処理ユニットごと、1 時間あたり
データベース ストレージ
料金は、データベースに保存されているデータの量に基づいており、読み取り / 書き込みレプリカと読み取り専用レプリカのストレージ費用が含まれます。ただし、ウィットネス レプリカは無料です。
SSD ストレージ
運用データに低レイテンシと高スループットが必要な場合は、SSD ストレージを使用します。
Starting at
$0.10
GB /月(レプリカあたり、SSD の場合)
HDD ストレージ
アクセス頻度が低く、高い読み取りレイテンシと低スループットを許容できるデータには、HDD ストレージを使用します。また、指定した時間枠が経過した後に SSD から HDD にデータを移動するように階層化ポリシーを構成することもできます。
Starting at
$0.02
GB /月(レプリカあたり、HDD の場合)
バックアップ ストレージ
リージョン構成
料金はバックアップ ストレージの量に基づいて計算され、すべてのレプリカのストレージ費用が含まれます。
Starting at
$0.10
/GB/月(すべてのレプリカを含む)
デュアルリージョンとマルチリージョンの構成
料金はバックアップ ストレージの量に基づいて計算され、すべてのレプリカのストレージ費用が含まれます。
Starting at
$0.30
/GB/月(すべてのレプリカを含む)
レプリケーション
リージョン内のレプリケーション
無料
リージョン間レプリケーション
Starting at
$0.04
GB 単位
ネットワーク
Ingress
無料
リージョン内の外向き
無料
リージョン間の下り(外向き)
Starting at
$0.01
GB 単位
ビジネスケース
他の企業が Spanner を利用して革新的なアプリをビルドして、優れたカスタマー エクスペリエンスを実現し、コストを削減し、費用対効果を向上させた方法をご確認ください。
- Forrester の Total Economic Impact™ 調査によると、Spanner は代表的なモデル組織に対して 132% の費用対効果、9 か月の投資回収期間、数百万ドルの利益をもたらします。詳しくは、調査の全文をダウンロードしてご確認ください。
- Gartner® は、運用データベースの 13 の重要機能を評価し、Spanner を軽量トランザクション ユースケースで第 1 位に選びました。レポート全文をダウンロード




注目の利点とお客様
あらゆるニーズに応じて無制限にスケーリングできる革新的なアプリケーションで、ビジネスを拡大しましょう。
TCO を削減し、デベロッパーを煩雑な作業から解放できます。目標を高く持ち、開発を迅速化しましょう。
月額 $40 からの従量制で、優れたコスト パフォーマンスを獲得できます。















パートナーとインテグレーション
評価からビジネスケース、移行、Spanner での新しいアプリのビルドまで、お客様のあらゆる段階で、Spanner の専門知識を持つパートナーをご活用ください。












システム インテグレータ
Spanner パートナーは、アプリケーションのモダナイズとクラウドへのシームレスな移行を支援します。Google Cloud のディレクトリで、理想的なパートナーやサードパーティ統合を見つけましょう。
その他のリソースとサポート
よくある質問
Spanner はリレーショナル データベースですか、それとも非リレーショナル データベースですか?
Spanner は、リレーショナル、Key-Value、グラフ、ベクトル検索のワークロードすべてを同じデータベースに統合することで、データ アーキテクチャを簡素化します。Spanner は、セカンダリ インデックス、強整合性、スキーマ、SQL などのリレーショナル セマンティクスを組み合わせ、単一の簡単なソリューションで 99.999% の可用性を提供する、スケーラビリティの高いデータベースです。そのため、リレーショナル ワークロードと非リレーショナル ワークロードの両方に適しています。
Spanner Omni とは
Spanner Omni は、Spanner のダウンロード可能なバージョンで、同じコア機能を備え、お客様がどこにでもデプロイできる柔軟性が追加されています。詳しくは、https://cloud.google.com/products/spanner/omni をご覧ください。
Spanner では SQL を使用しますか?
データベースを Spanner に移行するにはどうすればよいですか?
既存のワークロードを Spanner に移行すると、信頼性や価格性能比に妥協することなく、将来の成長のための基盤を確保できます。Spanner のマルチモデル インターフェースは、MySQL や SQL Server などのリレーショナル データベース、Cassandra や DynamoDB などの Key-Value ストア、グラフ、検索、ドキュメント ツールから運用ワークロードを処理する、さまざまな業界の革新的な組織で現在使用されています。移行の具体的なアプローチは、データ量、パフォーマンス SLO、可用性などの要件によって異なります。Spanner 移行ツールを使用すると、シャーディングされた MySQL データベースと Cassandra データベースのエンドツーエンドの評価、スキーマとデータの移行、ダウンタイムの少ないカットオーバー、さらに PostgreSQL の評価と移行が実現します。認定された技術パートナーとサービス パートナーのネットワークにより、ほぼすべてのソースからの移行を加速できます。
Spanner を運用するうえで考慮すべき重要事項は何ですか?
Spanner はフルマネージドのデータベースなので、インフラストラクチャの包括的な管理機能が自動的に提供されますが、ワークロードによっては、アプリケーション固有の管理アクションが必要になる場合があります。本番環境を常にスムーズに稼働させるには、適切なアラートとモニタリングをセットアップし、注意深く監視する必要があります。時間の経過とともにトラフィックが有機的に増加した場合やピーク トラフィックが想定される場合に、どう対処すべきかや、アプリケーションのバグに起因するデータの破損を処理する方法を理解する必要があります。さらに、パフォーマンスの問題をトラブルシューティングする方法と、レイテンシ増加の原因となるコンポーネントを把握する方法を理解することも重要です。


















