リアルタイム分析データベースとは
リアルタイム分析データベースは、データが作成された瞬間にデータを処理することで、即座に分析情報とアクションを提供します。このタイプのデータベースは、企業の知識と運用ワークフローを組み合わせて、時間を考慮する必要がある機能や日々のビジネス運営に AI を組み込む必要がある機能を実現できます。
リアルタイム分析は、パーソナライズされたおすすめ情報、スマート デバイスからのリアクション、予測メンテナンス、データメッシュ、プロセス自動化、サイバーセキュリティ、不正行為の防止などのアプリケーションで使用されます。リアルタイムの分析データベースは、多くの場合、最新の情報にアクセスする生成 AI ワークフローにとって不可欠です。
以前はこのようなタイプのアプリケーションの構築は複雑で、リソースを大量に消費しましたが、Bigtable と BigQuery の新しい進化により、プロセスが簡素化されました。
利点
シームレスなインテグレーション
シームレスなインテグレーション
Bigtable と BigQuery は、セルフマネージド ETL ジョブを必要とせずに、リアルタイムの分析情報と過去のデータを組み合わせます。また、両者の間で SQL 言語が統一されているため、単一の開発エクスペリエンスを実現できます。
組み込みのリアルタイム機能
組み込みのリアルタイム機能
連携するように設計された専用のリアルタイム機能により、テラバイトやペタバイト規模のデータや非常に高い秒間クエリ数(QPS)でも、包括的なリアルタイム分析データベースを提供します。
運用を削減し、より多くの成果を達成
運用を削減し、より多くの成果を達成
フルマネージド型のエンタープライズ グレードのリアルタイム分析ソリューションは、業界をリードする SLA により運用上のオーバーヘッドを最小限に抑え、信頼できる信頼性とパフォーマンスを実現します。
主な機能
ストリーミング データへの応答
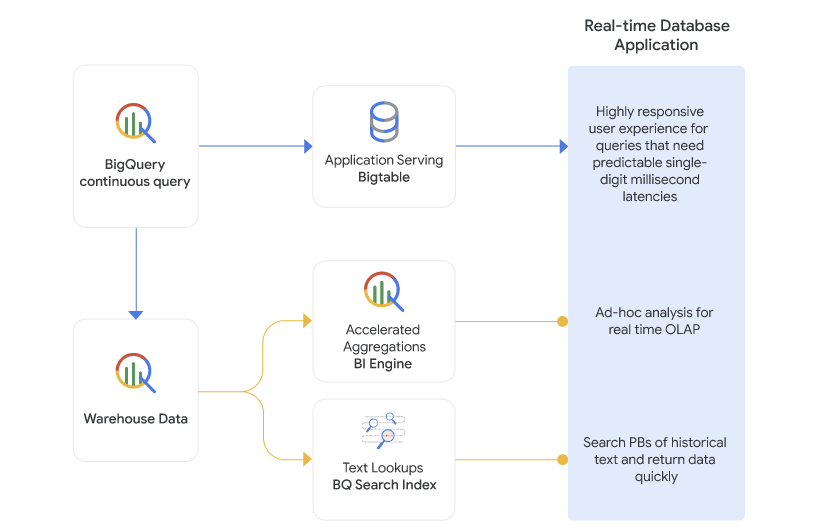
Google Cloud は、さまざまなソースからの継続的なデータ ストリームを処理するための堅牢なストリーミング分析エコシステムを提供します。BigQuery は、既知のスキーマのデータの取り込みソースとして最適です。BigQuery のストレージ書き込み API と継続的クエリにより、直接データを取り込むことができ、データウェアハウス内のデータの更新速度を最大限に高めるため、他のソースへの接続が可能になります。一方、Bigtable は、グローバルな線形のスケーラビリティと組み込みのデータ同期を提供し、書き込み後の即時的な整合性が必要とされる柔軟で動的なスキーマに優れています。Bigtable は、すぐに使えるタイムスタンプ ベースのバージョニングと自動化された有効期間(TTL)保持ポリシーも提供しているため、ストリーミング イベントの保存と分析に最適な選択肢となります。また、ストリーミングに必要なデータの量も考慮する必要があります。BigQuery は、米国と EU のマルチリージョンでは 1 秒あたり数ギガビット/秒(Gbps)で、他のリージョンでは 1 秒あたり数百メガビット/秒(Mbps)でデータをストリーミングできます。Bigtable は、Bigtable がサポートするすべてのリージョンで、1 秒あたり 14,000 回の書き込みという線形のスケーラビリティを備え、ストリーミング データのキャプチャに柔軟性を提供します。
BigQuery と Bigtable を組み合わせることで、トレードオフを行う必要がなく、ユースケースに適した取り込み手法を選択できます。
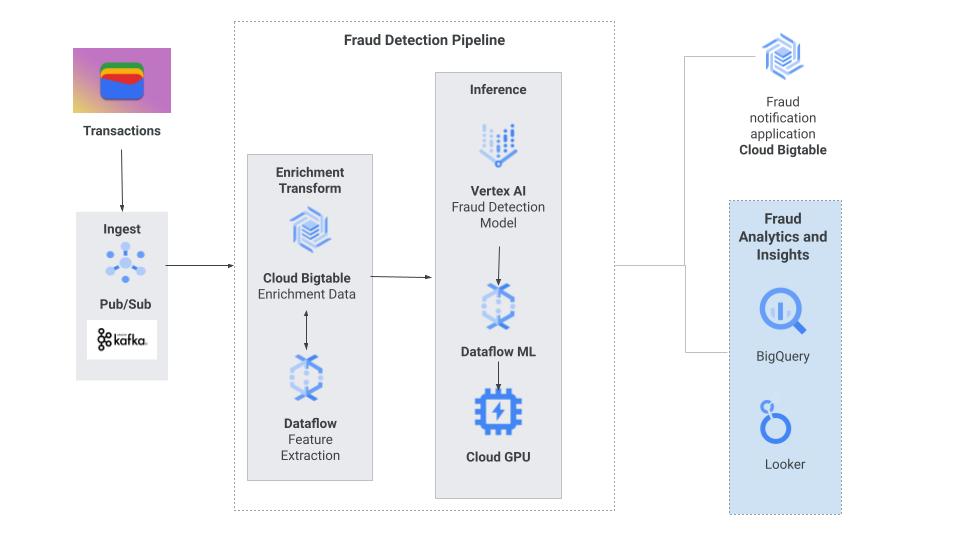
分析と迅速な取得を実現するスケーラブルで柔軟なストレージ
ほとんどのデータベースでは、高速な行の取得と大規模な分析処理のどちらかを選択する必要があります。Bigtable と BigQuery のそれぞれの目的を組み合わせることで、クエリの種類に関係なく使用できる、完全なリアルタイム分析データベースとなります。
Bigtable は、単一の行またはデータ範囲の超高速な取得に最適化されたストレージ エンジンとして優れており、アプリケーション内のグラフ、プロファイル検索、時系列分析、クリック数などのストリーミング データの指標、予測可能で大量かつ低レイテンシで処理する必要があるその他のクエリなど、ユーザー向けアプリケーションでリアルタイムの応答性が求められる場面で理想的です。Bigtable は、ログ構造化エンジン(LSM ツリー)に基づいており、インメモリと分割ディスク ストレージの組み合わせと、同期アクセスと非同期アクセスの両方に対応する特殊なクライアント ライブラリを使用して、高パフォーマンスを実現するように最適化されています。Bigtable の柔軟なスキーマと自己管理機能により、要求の厳しいアプリケーションへの適合性がさらに高まります。一方、BigQuery は分析ワークロードに優れており、複雑な集計、Gemini Enterprise Agent Platform との統合、変換を伴う大規模なデータセットのクエリや分析のための強力なツールとなります。
Bigtable と BigQuery を組み合わせることで、個々の行の検索と大規模なデータセットに対する包括的な分析処理のどちらかを選択する必要がなくなります。シームレスな統合により、どちらのストレージ モデルでもリアルタイム アプリケーションを簡単に強化できます。Bigtable は、BigQuery サイズのデータセットに適した費用対効果の高いキャッシュ ソリューションとしてよく使用されます。たとえば、BigQuery を使用してエンベディングをバッチで生成し、Bigtable でそれらのエンベディングを提供して、検索拡張生成(RAG)アプリケーションをサポートできます。
すぐに利用できる指標
Bigtable は、書き込まれたデータを前処理して、即座に結果と分析情報を提供する特殊なデータ型を提供します。データの書き込み時に合計、最小値、最大値、個別の概算数を計算できます。また、組み込みのグローバル レプリケーションにより、アプリケーション全体で一貫した結果を取得できます。これらのデータ型は、BigQuery から読み込めるウェアハウス データとも完全に相互運用できます。
リアルタイムのデータ集約は、包括的な ML 機能の作成を強化し、その瞬間にユーザーを引きつける正確な予測につながります。
継続的なデータの分析
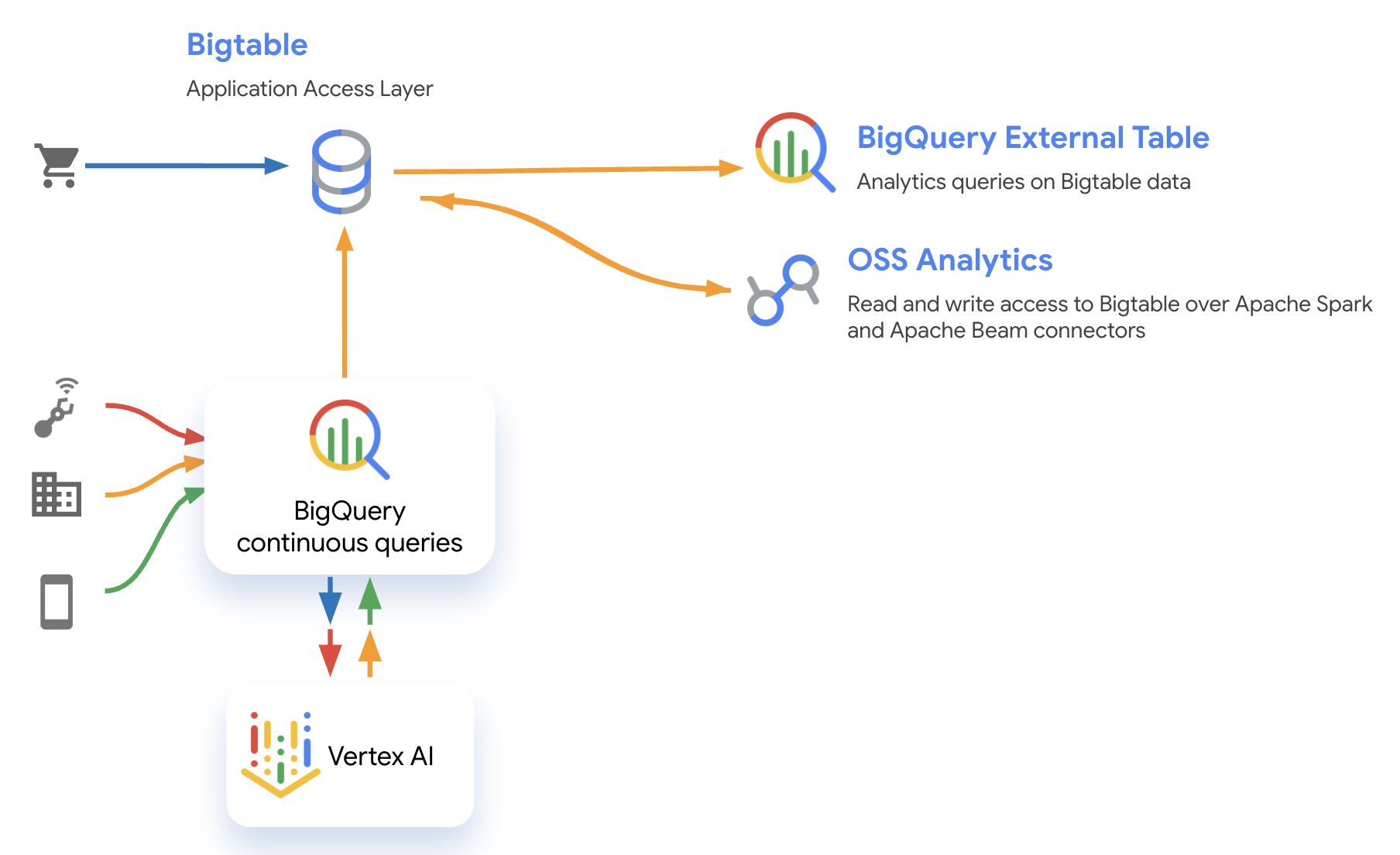
Bigtable は BigQuery 分析エコシステムに統合されているため、リアルタイム データに簡単にアクセスして追加のストリーム分析を行うことができます。外部テーブルを使用して BigQuery の他のデータセットで Bigtable データのクエリ実行と結合を行い、オープンソースの Spark 分析または Apache Beam パイプラインを使用して、Bigtable データに直接結果を書き戻すことができます。また、この分析アクセスでは、Bigtable の Data Boost を使用して、リアルタイムのアプリケーション パフォーマンスに影響を与えることなく、高パフォーマンスの分析を取得することもできます。さらに、変更データ キャプチャ(CDC)と Knowledge Catalog(旧称 Dataplex)により、Bigtable データのエクスポートと検出が簡単になります。複雑なデータ同期タスクやカスタマイズされたタスクは必要ありません。
リアルタイムのユースケース
Bigtable と BigQuery を使用したリアルタイム分析で成功しているお客様の事例。
 PLAIDPLAID は BigQuery と Bigtable を使用して、1 秒あたり 10 万件を超えるイベントが発生する書き込みトラフィックの多い状況で真のリアルタイム分析を実現しています。
PLAIDPLAID は BigQuery と Bigtable を使用して、1 秒あたり 10 万件を超えるイベントが発生する書き込みトラフィックの多い状況で真のリアルタイム分析を実現しています。 ビジネス インテリジェンス アナリスト、Stephanie Chau 氏Bigtable と BigQuery を使用することで、Credit Karma は 10 倍以上の機能を毎日デプロイし、1 日あたり 600 億件のモデル予測を実行しています。
ビジネス インテリジェンス アナリスト、Stephanie Chau 氏Bigtable と BigQuery を使用することで、Credit Karma は 10 倍以上の機能を毎日デプロイし、1 日あたり 600 億件のモデル予測を実行しています。 Major League BaseballMLB は、通常シーズンの 2,430 試合から 2,500 万のデータポイントにわたる選手のモーション トラッキングを Bigtable に取り込み、BigQuery で分析します。
Major League BaseballMLB は、通常シーズンの 2,430 試合から 2,500 万のデータポイントにわたる選手のモーション トラッキングを Bigtable に取り込み、BigQuery で分析します。


















