
Google Kubernetes Engine (GKE)
Kubernetes 的演变:平台构建者的基础
为您的容器启用 Autopilot 模式并大规模安全运行企业工作负载,全程几乎无需 Kubernetes 运维专业知识。
每月免费获取一个可用区级或 Autopilot 集群。此外,新客户可获享 $300 赠金,用于试用 GKE。

功能
简化集群管理并提高资源效率
GKE Autopilot 是一种运维模式,在此模式中,Google 会管理您的节点基础设施、扩缩、安全性和预配置功能。借助自动容量合理调整和按 Pod 定价,您可以避免过度预配、过度付费和利用率过低。借助 Autopilot 的容器优化计算平台,您可以获得近乎实时的纵向和横向可扩缩计算资源,以最优性价比,按需提供所需容量。
可用于生产用途的平台,支持智能体 AI 工作负载和生成式 AI 模型
GKE 支持多达 65,000 个节点的集群,集成了 AI Hypercomputer,并支持 GPU 和 TPU,因此可以轻松运行机器学习、HPC 和其他能受益于专业化硬件加速器的工作负载。
GKE 推理功能采用了生成式 AI 感知型扩缩和负载均衡技术,与其他托管式和开源 Kubernetes 产品相比,有助于将服务费用降低 30% 以上、尾部延迟降低 60%,并将吞吐量提高多达 40%。
原生安全
GKE 提供大规模安全保障,内置最佳实践、合规的基础设施和实时提醒,让您能够以统一的视图快速、迅速地缓解安全威胁和合规性问题。
GKE 由超过 750 位专家组成的 Google 安全团队提供支持,其内置的安全状况包括修补和安全加固、隔离和分段、机密 GKE 节点、身份和访问权限管理,以及与 Cloud Logging 和 Cloud Monitoring 的集成。
此外,借助 GKE Sandbox,您可以在 GKE 上的容器化工作负载之间再增加一层防御,实现更高的工作负载安全性。
支持多云的工作负载可移植性
GKE 运行经过认证的 Kubernetes,并采用开放标准,让客户能够在现有的本地硬件投资或公有云上运行应用,而无需进行修改。
GKE 关联集群可让您将自己创建的任何符合要求的 Kubernetes 集群注册或关联到 GKE 管理环境。通过关联集群,您可以管理 GKE 并对其进行控制,还可以使用 Config Sync、Cloud Service Mesh 和舰队等其他功能。
常见用途
为所有工作负载构建平台
构建企业开发者平台,实现快速可靠的应用交付
构建企业开发者平台,实现快速可靠的应用交付
Google Cloud 提供一整套托管式服务和运行时,可作为平台的基础组件,因此您可以针对自己的应用场景找到合适的服务组合。GKE 与 Google Cloud 生态系统深度集成,具有出色的可伸缩性和内置的安全状况,是构建平台的理想基础。
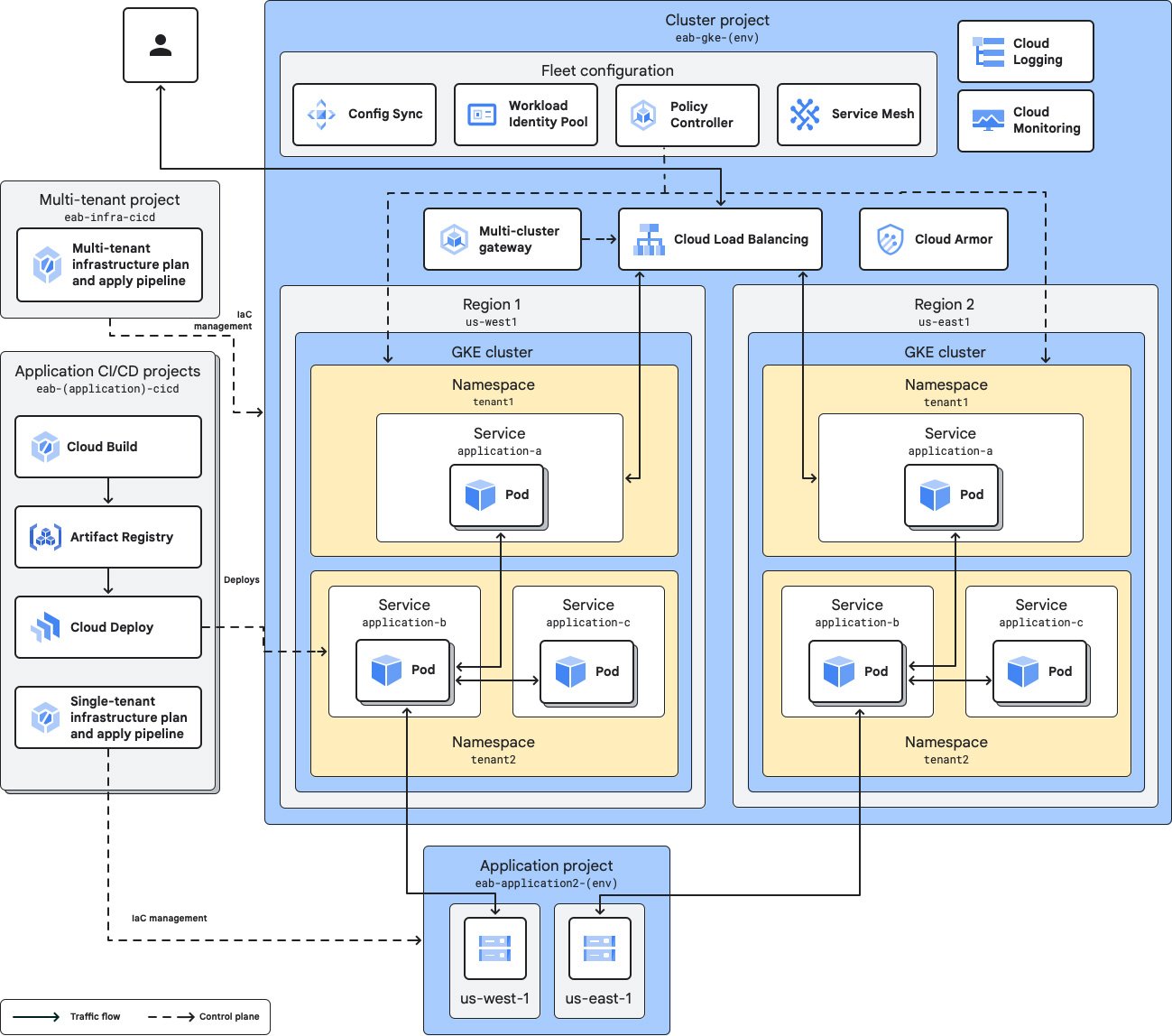
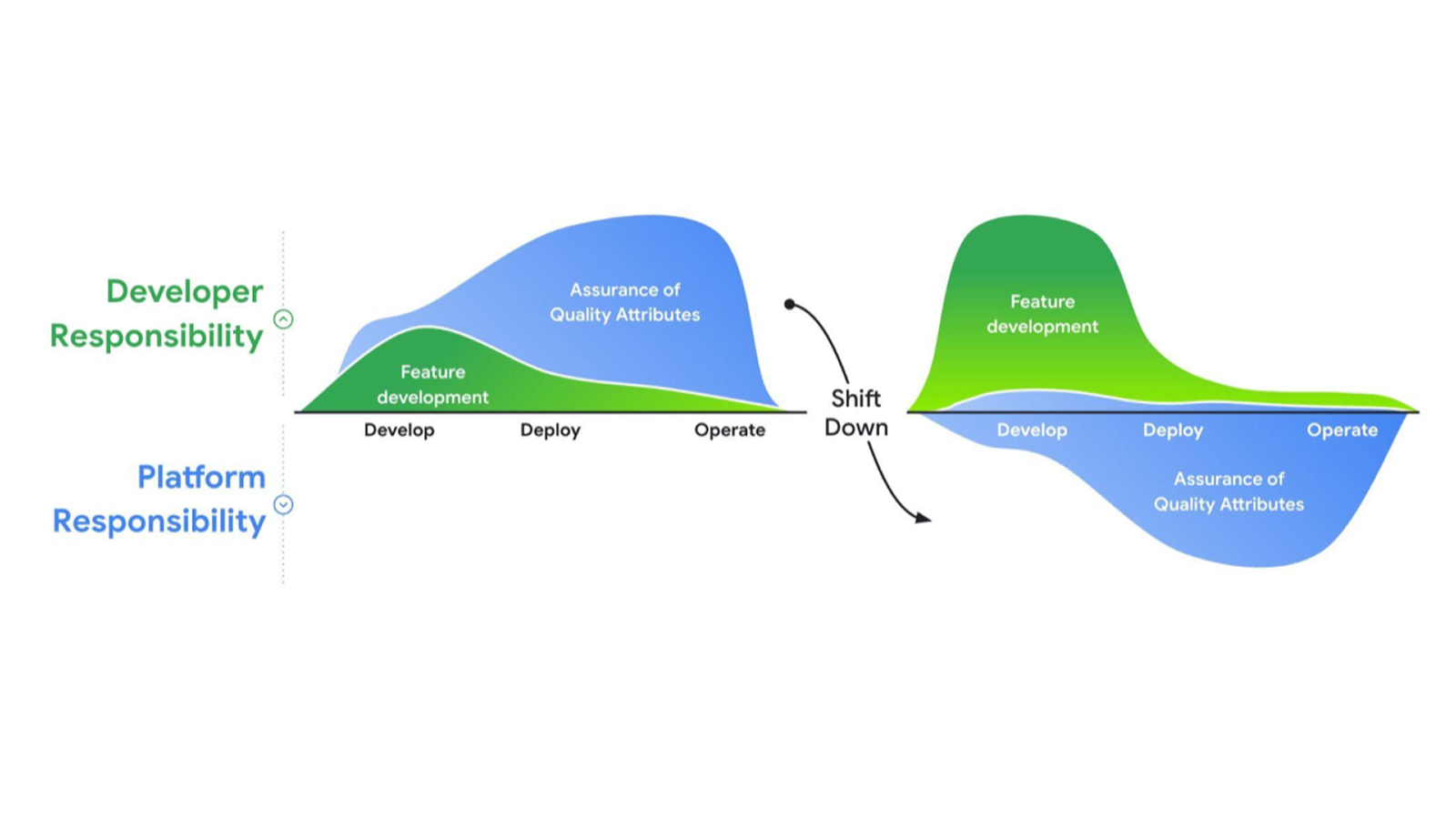
教程、快速入门和实验
构建企业开发者平台,实现快速可靠的应用交付
构建企业开发者平台,实现快速可靠的应用交付
Google Cloud 提供一整套托管式服务和运行时,可作为平台的基础组件,因此您可以针对自己的应用场景找到合适的服务组合。GKE 与 Google Cloud 生态系统深度集成,具有出色的可伸缩性和内置的安全状况,是构建平台的理想基础。
学习资源
训练、部署和扩缩生成式 AI 模型
使用 GKE 部署生成式 AI 推理
使用 GKE 部署生成式 AI 推理
GKE 不仅为 AI 提供平台,还利用 AI 简化和自动化 Kubernetes 操作。GKE 支持多达 65,000 个节点,并与 AI Hypercomputer 集成,因此您可以在 GKE 上训练和扩缩最大的生成式 AI 模型。
此外,与 OSS K8s 相比,GKE 的生成式 AI 感知型推理功能可将服务费用降低多达 30%,将尾部延迟降低 60%,并将吞吐量提高 40%。
教程、快速入门和实验
使用 GKE 部署生成式 AI 推理
使用 GKE 部署生成式 AI 推理
GKE 不仅为 AI 提供平台,还利用 AI 简化和自动化 Kubernetes 操作。GKE 支持多达 65,000 个节点,并与 AI Hypercomputer 集成,因此您可以在 GKE 上训练和扩缩最大的生成式 AI 模型。
此外,与 OSS K8s 相比,GKE 的生成式 AI 感知型推理功能可将服务费用降低多达 30%,将尾部延迟降低 60%,并将吞吐量提高 40%。
多代理编排
教程、快速入门和实验
价格
| GKE 定价方式 | 用完赠金后,总费用将取决于集群操作模式、集群管理费用和适用的入站数据传输费用。 | |
|---|---|---|
| 服务 | 说明 | 价格 (USD) |
免费层级 | GKE 免费层级每月为每个计费账号提供 $74.40 的赠金,该赠金适用于可用区级集群和 Autopilot 集群。 | 免费 |
集群管理费用 | 包括完全自动化的集群生命周期管理、Pod 和集群自动扩缩、费用可见性、基础设施费用自动优化以及多集群管理功能,无需额外费用。 | $0.10 每个集群每小时 |
计算 | 使用 Autopilot 时,您只需为 Pod 预配的 CPU、内存和计算资源付费。 对于不使用 Autopilot 的节点池和计算类别,您需要为节点的底层 Compute Engine 实例付费,直到节点被删除。 | |
详细了解 GKE 价格。 查看所有价格详情。
GKE 定价方式
用完赠金后,总费用将取决于集群操作模式、集群管理费用和适用的入站数据传输费用。
集群管理费用
包括完全自动化的集群生命周期管理、Pod 和集群自动扩缩、费用可见性、基础设施费用自动优化以及多集群管理功能,无需额外费用。
$0.10
每个集群每小时
使用 Autopilot 时,您只需为 Pod 预配的 CPU、内存和计算资源付费。
对于不使用 Autopilot 的节点池和计算类别,您需要为节点的底层 Compute Engine 实例付费,直到节点被删除。
详细了解 GKE 价格。 查看所有价格详情。
业务用例















