Google Cloud データベース
Google Cloud は、AI を中核としたグローバル規模のインフラストラクチャ上に構築された、業界トップクラスのデータベースを提供しています。あらゆる AI エージェントやアプリケーションにおいて、比類のない信頼性、コスト パフォーマンス、セキュリティ、グローバル スケールを体験できます。
さらに、Google の Agentic Data Cloud により、モデル、分析、オペレーショナル データベースを単一の AI ネイティブ システムに統合した統一プラットフォームが実現しました。

リレーショナル データベースは、定義された関係を持つテーブルにデータを保存して整理するため、データ構造の相互関連性の理解が容易に
- Cloud SQL: MySQL、PostgreSQL、SQL Server のワークロード向けの柔軟性が高いフルマネージド データベース サービスで、優れたパフォーマンス、可用性、管理性を実現します。
- AlloyDB for PostgreSQL: PostgreSQL との 100% の互換性を備え、あらゆる環境で動作するよう設計されたデータベースで、最も要求の厳しいワークロードに対して、優れたパフォーマンス、可用性、スケーラビリティを提供します。
- Spanner: 常時稼働でグローバルな整合性を備え、実質的に無制限にスケール可能なマルチモデル データベース。Google 検索、Gmail、YouTube などの 10 億ユーザーを擁する Google プロダクトの基盤となっています。最大 99.999% の可用性 SLA を提供します。
非リレーショナル データベース(NoSQL データベースとも呼ばれる)は、柔軟な表形式以外の形式でデータを保存
- Bigtable: 大規模な高スループット、低レイテンシ アプリケーションに対応する柔軟性の高い NoSQL データベース。Google 検索、広告、YouTube など、10 億人規模のユーザーが使用する Google プロダクトを支えています。最大 99.999% の可用性 SLA を提供します。
- Memorystore: Valkey、Redis*、Memcached 向けのフルマネージド インメモリ データベース サービス。ミリ秒未満のデータアクセス、スケーラビリティ、高可用性を実現します。
- Firestore: 多機能アプリケーション開発に適した、非常にスケーラブルなサーバーレスのドキュメント データベース。最大 99.999% の可用性 SLA を提供します。
- MongoDB 互換の Firestore: MongoDB に関して備わっている専門知識を、Firestore のサーバーレスのスケーラビリティ、パフォーマンス、高可用性と組み合わせて活用できます。
ベクトル データベースでは、ベクトル エンベディング(テキスト、画像、音声などの非構造化データの数値表現)の保存、インデックス登録、クエリを行うことが可能
- AlloyDB AI: 使い慣れた PostgreSQL インターフェースでエンタープライズ生成 AI アプリを構築できます。モデル推論のための Vertex AI などの AI ツールや、pgvector や LangChain などのオープンで標準的なテクノロジーと統合します。また、新しい ScaNN インデックスにより、Google の 12 年にわたる研究成果が PostgreSQL にもたらされ、ベクトル検索のパフォーマンスと精度が向上します。
- Spanner: リレーショナル、グラフ、キー値、全文検索、ベクトル検索を統合した単一のデータベースを使用してインテリジェントなアプリを構築できるため、専用のデータベース ソリューションを別途用意する必要がありません。ベクトルの保存と、厳密最近傍(KNN)検索または近似最近傍(ANN)検索を使用したベクトルの検索をサポートしています。
- Cloud SQL: すでに使用しているのと同じ Cloud SQL for MySQL および Cloud SQL for PostgreSQL インスタンスにベクトルを保存し、厳密最近傍(KNN)検索または近似最近傍(ANN)検索を使用してベクトルストアに対して検索を行います。Cloud SQL は、Vertex AI と統合してモデル推論を実現します。また、オープンソースの pgvector をサポートしているため、生成 AI アプリを迅速に構築できます。
データベースとアプリケーションをクラウドベースのサービスに移行してモダナイズし、パフォーマンス、スケーラビリティ、費用対効果の向上を実現
- Database Migration Service: MySQL、PostgreSQL、SQL Server、Oracle データベースから Cloud SQL や AlloyDB への移行を簡素化します。Gemini アシストによる統合型の変換と移行のエクスペリエンスを利用し、数回のクリックで移行を開始できます。
- Datastream: MySQL、PostgreSQL、SQL Server、Oracle データベースのデータに対する、サーバーレスで使いやすい変更データ キャプチャとレプリケーション サービス。Datastream for BigQuery を使用すると、リレーショナル データベースから BigQuery に直接シームレスに複製できるため、運用データに関する準リアルタイムの分析情報を得ることができます。
- Oracle Database@Google Cloud: Oracle データベースとアプリケーションを Google Cloud に移行し、機能を強化します。Oracle Cloud Infrastructure(OCI)ハードウェア上で動作する Google Cloud データセンターに最新のデータベース サービスをデプロイします。
- Oracle 向け Bare Metal Solution: コンピューティング、ストレージ、ネットワークを含むエンドツーエンドのフルマネージド インフラストラクチャ上で、オンプレミスと同じ方法で Oracle データベースを運用します。
データベース フリート全体の包括的な把握と管理の強化を AI で実現します。問題をプロアクティブに検出して根本原因を特定します。
- データベース センター: データベース フリート全体で、可用性、費用、保護設定、パフォーマンス、セキュリティ、コンプライアンスを管理します。一元化されたダッシュボードで、Cloud SQL、AlloyDB、Spanner、Bigtable、Memorystore 、Firestore のインスタンスの統合ビューを提供します。また、Google Compute Engine 上のセルフマネージド データベース(MySQL、PostgreSQL、SQL Server)のサポートも(プレビュー版で)提供するようになりました。
- AI を活用したトラブルシューティング: Database Center に組み込まれた AI を使用して、データベースのパフォーマンスを分析してトラブルシューティングし、クエリの実行中の異常を検出します。Cloud SQL または AlloyDB がクエリのパフォーマンスの異常を検出するとき、またはシステムへの高付加を検知したときに、AI を活用したトラブルシューティングの手順により証拠に基づいて状況を分析し、推奨事項を確認することができます。
リレーショナル データベース
リレーショナル データベースは、定義された関係を持つテーブルにデータを保存して整理するため、データ構造の相互関連性の理解が容易に
- Cloud SQL: MySQL、PostgreSQL、SQL Server のワークロード向けの柔軟性が高いフルマネージド データベース サービスで、優れたパフォーマンス、可用性、管理性を実現します。
- AlloyDB for PostgreSQL: PostgreSQL との 100% の互換性を備え、あらゆる環境で動作するよう設計されたデータベースで、最も要求の厳しいワークロードに対して、優れたパフォーマンス、可用性、スケーラビリティを提供します。
- Spanner: 常時稼働でグローバルな整合性を備え、実質的に無制限にスケール可能なマルチモデル データベース。Google 検索、Gmail、YouTube などの 10 億ユーザーを擁する Google プロダクトの基盤となっています。最大 99.999% の可用性 SLA を提供します。
非リレーショナル データベース
非リレーショナル データベース(NoSQL データベースとも呼ばれる)は、柔軟な表形式以外の形式でデータを保存
- Bigtable: 大規模な高スループット、低レイテンシ アプリケーションに対応する柔軟性の高い NoSQL データベース。Google 検索、広告、YouTube など、10 億人規模のユーザーが使用する Google プロダクトを支えています。最大 99.999% の可用性 SLA を提供します。
- Memorystore: Valkey、Redis*、Memcached 向けのフルマネージド インメモリ データベース サービス。ミリ秒未満のデータアクセス、スケーラビリティ、高可用性を実現します。
- Firestore: 多機能アプリケーション開発に適した、非常にスケーラブルなサーバーレスのドキュメント データベース。最大 99.999% の可用性 SLA を提供します。
- MongoDB 互換の Firestore: MongoDB に関して備わっている専門知識を、Firestore のサーバーレスのスケーラビリティ、パフォーマンス、高可用性と組み合わせて活用できます。
ベクトル データベース
ベクトル データベースでは、ベクトル エンベディング(テキスト、画像、音声などの非構造化データの数値表現)の保存、インデックス登録、クエリを行うことが可能
- AlloyDB AI: 使い慣れた PostgreSQL インターフェースでエンタープライズ生成 AI アプリを構築できます。モデル推論のための Vertex AI などの AI ツールや、pgvector や LangChain などのオープンで標準的なテクノロジーと統合します。また、新しい ScaNN インデックスにより、Google の 12 年にわたる研究成果が PostgreSQL にもたらされ、ベクトル検索のパフォーマンスと精度が向上します。
- Spanner: リレーショナル、グラフ、キー値、全文検索、ベクトル検索を統合した単一のデータベースを使用してインテリジェントなアプリを構築できるため、専用のデータベース ソリューションを別途用意する必要がありません。ベクトルの保存と、厳密最近傍(KNN)検索または近似最近傍(ANN)検索を使用したベクトルの検索をサポートしています。
- Cloud SQL: すでに使用しているのと同じ Cloud SQL for MySQL および Cloud SQL for PostgreSQL インスタンスにベクトルを保存し、厳密最近傍(KNN)検索または近似最近傍(ANN)検索を使用してベクトルストアに対して検索を行います。Cloud SQL は、Vertex AI と統合してモデル推論を実現します。また、オープンソースの pgvector をサポートしているため、生成 AI アプリを迅速に構築できます。
移行とモダナイゼーション
データベースとアプリケーションをクラウドベースのサービスに移行してモダナイズし、パフォーマンス、スケーラビリティ、費用対効果の向上を実現
- Database Migration Service: MySQL、PostgreSQL、SQL Server、Oracle データベースから Cloud SQL や AlloyDB への移行を簡素化します。Gemini アシストによる統合型の変換と移行のエクスペリエンスを利用し、数回のクリックで移行を開始できます。
- Datastream: MySQL、PostgreSQL、SQL Server、Oracle データベースのデータに対する、サーバーレスで使いやすい変更データ キャプチャとレプリケーション サービス。Datastream for BigQuery を使用すると、リレーショナル データベースから BigQuery に直接シームレスに複製できるため、運用データに関する準リアルタイムの分析情報を得ることができます。
- Oracle Database@Google Cloud: Oracle データベースとアプリケーションを Google Cloud に移行し、機能を強化します。Oracle Cloud Infrastructure(OCI)ハードウェア上で動作する Google Cloud データセンターに最新のデータベース サービスをデプロイします。
- Oracle 向け Bare Metal Solution: コンピューティング、ストレージ、ネットワークを含むエンドツーエンドのフルマネージド インフラストラクチャ上で、オンプレミスと同じ方法で Oracle データベースを運用します。
フリート管理
データベース フリート全体の包括的な把握と管理の強化を AI で実現します。問題をプロアクティブに検出して根本原因を特定します。
- データベース センター: データベース フリート全体で、可用性、費用、保護設定、パフォーマンス、セキュリティ、コンプライアンスを管理します。一元化されたダッシュボードで、Cloud SQL、AlloyDB、Spanner、Bigtable、Memorystore 、Firestore のインスタンスの統合ビューを提供します。また、Google Compute Engine 上のセルフマネージド データベース(MySQL、PostgreSQL、SQL Server)のサポートも(プレビュー版で)提供するようになりました。
- AI を活用したトラブルシューティング: Database Center に組み込まれた AI を使用して、データベースのパフォーマンスを分析してトラブルシューティングし、クエリの実行中の異常を検出します。Cloud SQL または AlloyDB がクエリのパフォーマンスの異常を検出するとき、またはシステムへの高付加を検知したときに、AI を活用したトラブルシューティングの手順により証拠に基づいて状況を分析し、推奨事項を確認することができます。

お客様の成功事例








Google Cloud のデータベースを選ぶ理由
信頼できるエンタープライズ データを使用して生成 AI アプリとエージェントを構築
信頼できる独自のエンタープライズ データを使用して、生成 AI アプリケーションとエージェントを迅速に構築できます。すべてのデータベースに組み込まれたベクトル サポートにより、データを移動することなく、ベクトル エンベディングを迅速かつ簡単に保存、検索できます。ナレッジグラフやグラフベースの検索拡張生成(RAG)を活用して、AI アプリを簡単に強化し、高い価値を持つユースケースを実現できます。Gemini Enterprise Agent Platform や LangChain などの主要な AI ツールとのシームレスなインテグレーションにより、正確で関連性が高く、企業の実体に基づいたアプリを迅速に構築できます。

95%
Google Cloud を利用する上位 100 社のうち、95% を超えるお客様が Cloud SQL を使用
4 倍
AlloyDB はトランザクションのワークロードにおいて標準的な PostgreSQL よりも 4 倍以上高速
2 倍
AlloyDB の費用対効果は、セルフマネージド PostgreSQL の最大 2 倍。
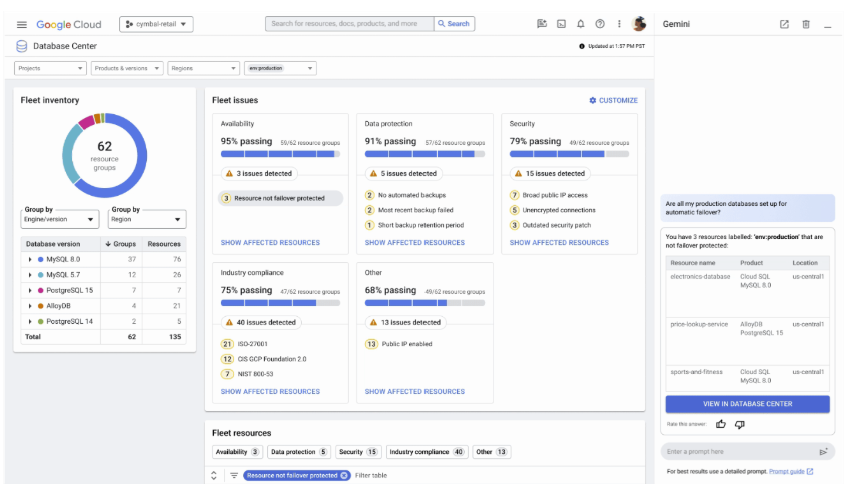
Gemini in Databases のおかげで、フリートの健全性に関する情報を数秒で取得でき、アプリケーションに潜むリスクをこれまで以上に迅速に、先を見越して軽減できます。
Ford Motor Company データベース テクノロジー担当テクニカル エキスパート、Bogdan Capatina 氏



















