Linear optimizes data and scalability with vector search support on Google Cloud SQL
Tom Moor
Head of US Engineering, Linear
Editor’s note: Since its founding in 2019, Linear has been enhancing global product development workflows for businesses through its project and issue-tracking system. Leveraging the power of Cloud SQL for PostgreSQL, Linear was able to keep pace with its expanding customer base–improving the efficiency, scalability, and reliability of data management, scaling up into the tens of terabytes without increasing engineering effort.
Linear’s mission is to empower product teams to ship great software. We’ve spent the last few years building a comprehensive project and issue tracking system to help users streamline workflows throughout the product development process. While we started as an issue tracker, we’ve grown our application into a powerful project management platform for cross-functional teams and users around the world.
For instance, Linear Asks allows organizations to manage request workflows like bug and feature requests via Slack, streamlining collaboration for individuals without Linear accounts who regularly work with our platform. Additionally, we introduced Similar Issues, a feature that prevents duplicate or overlapping tickets and ensures cleaner and more accurate data representation for growing organizations.
As our customers grow their businesses, they have more users on the platform and issues to track, which means more need for workflow and product management software. We’re focused on supporting this growth while continuing to deliver on stability, quality, performance, and the features that support complex technical configurations alongside a great user experience.
Seeking a scalable database with vector search
In our initial development phase, we had a PostgreSQL database with pgvector extension hosted on a PaaS that wasn’t indexed or used for production workloads. For production workloads we needed to upgrade our databases and find a solution with strong vector search support, since it’s the best way to identify and group similar issues based on shared characteristics or patterns. By representing issues as vectors and finding similarities, we can quickly identify duplicate or related issues. This functionality streamlines bug tracking and helps our customers address issues more effectively, saving them time and resources while improving their overall workflows.
We explored several new entrants in the database market that focus on storing vectors and ended up trialing several. However, we faced challenges with speed of indexing and unacceptable downtime while scaling, not to mention the relatively high cost for a feature that wasn’t the core of the product. Given Linear’s existing data volume and our goals for finding a cost-efficient solution, we opted for Cloud SQL for PostgreSQL once support for pgvector was added. We were impressed by its scalability and reliability. This choice was also compatible with our existing database usage, models, ORM, etc. and this meant the learning curve was non-existent for our team.
Our migration process from development to production was challenging at first due to the sheer size and volume of vectors we had to work with for the production dataset. However, after partitioning the issues table into 300 segments, we were able to successfully index each partition. The migration process followed a standard approach of creating a follower from the existing PostgreSQL database and proceeded smoothly.
Google Cloud powers Linear's real-time sync
Today, our primary operational database uses Cloud SQL for PostgreSQL. Since Cloud SQL for PostgreSQL includes the pgvector extension, we were able to set up an additional database to store vectors for our similarity-search features. This is achieved by encoding the semantic meaning of issues into a vector using OpenAI ada embeddings, then combining it with other filters to help us identify similar relevant entities.
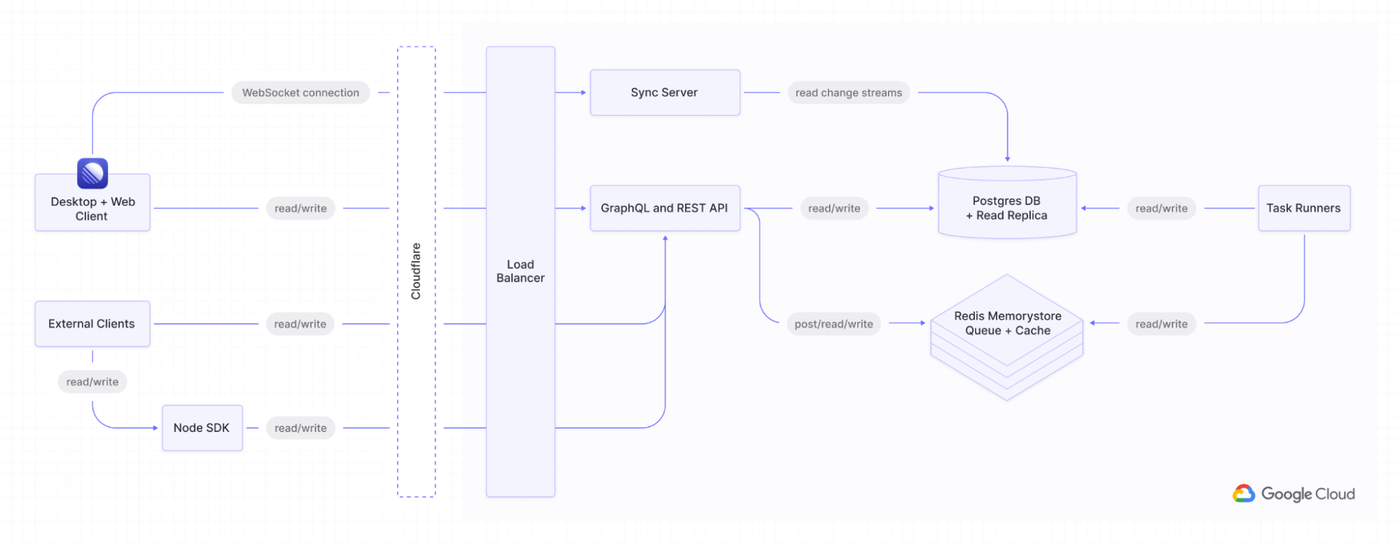
A simplified diagram of Linear's architecture
In terms of our architecture design, Linear’s web and desktop clients seamlessly sync with our backend through real-time connections. On Google Cloud, we operate synchronized WebSocket servers, both public and private GraphQL APIs, and task runners for background jobs.
Each of these functions as a Kubernetes workload that can scale independently. Our technology stack is fully built with NodeJS and Typescript, and our primary database solution is Cloud SQL for PostgreSQL, a choice we’re confident with. Additionally, we use Google’s managed Memorystore for Redis as an event bus and cache.
Seamless scaling and future innovation with Cloud SQL for PostgreSQL
Cloud SQL for PostgreSQL has proven invaluable for Linear. Because we do not have a dedicated operations team, relying on managed services is crucial. It allows us to scale our database smoothly into tens of terabytes of data without requiring extensive engineering efforts, which is fantastic for our operations and enables engineering to spend more time building user-facing features.
Furthermore, our customers have provided us with great feedback, specifically regarding Linear’s ability to identify duplicate issues when they report a bug. Now, when a user creates a new issue, the application first suggests potential duplicates. Additionally, when handling customer tickets through customer support application integrations like Zendesk, Linear displays possible related bugs that have already been logged.
Looking ahead, we envision integrating machine learning (ML) into Linear to enhance the user experience, automate tasks, and offer intelligent suggestions within the product. We're also committed to further developing our similarity search features, expanding beyond vector similarity to incorporate additional signals into our calculations. We firmly believe that Google Cloud will be instrumental in helping us realize this vision.
Get started:
- Discover how Cloud SQL for PostgreSQL can help you run your business. Learn more about Memorystore for Redis.
- Start a free trial today! New Google Cloud customers get $300 in free credits.

