모든 긍정적인 영화 평점(평점 >= 4)을 제품 페이지 조회 이벤트로 취급합니다. 사용자 또는 데이터 세트에 있는 시드 영화를 기반으로 영화를 추천하는 내가 좋아할 만한 기타 항목 유형의 추천 모델을 학습시킵니다.
예상 수령 시간
- 모델 학습을 시작하는 초기 단계: 1.5시간 이내
- 모델 학습 대기: 2일 이내
- 모델 예측 평가 및 삭제: 30분 이내
목표
- BigQuery에서 Vertex AI Search for Retail로 제품 및 사용자 이벤트 데이터를 가져오는 방법을 알아봅니다.
- 추천 모델을 학습하고 평가합니다.
비용
이 튜토리얼에서는 비용이 청구될 수 있는 다음과 같은 Google Cloud 구성요소를 사용합니다.- Cloud Storage
- BigQuery
- Vertex AI Search for Retail
Cloud Storage 비용에 대한 자세한 내용은 Cloud Storage 가격 책정 페이지를 참조하세요.
BigQuery 비용에 대한 자세한 내용은 BigQuery 가격 책정 페이지를 참조하세요.
Vertex AI Search for Retail 비용에 대한 자세한 내용은 Vertex AI Search for Retail 가격 책정 페이지를 참조하세요.
시작하기 전에
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
데이터세트 준비
Google Cloud 콘솔을 열고 Google Cloud 프로젝트를 선택합니다. 대시보드 페이지의 프로젝트 정보 카드에서 프로젝트 ID를 기록해 둡니다. 다음 단계를 수행하려면 프로젝트 ID가 필요합니다. 그런 다음 Console 상단에서 Cloud Shell 활성화 버튼을 클릭합니다.

Google Cloud Console 하단의 새로운 프레임에서 Cloud Shell 세션이 열리고 명령줄 프롬프트가 표시됩니다.
데이터 세트 가져오기
Cloud Shell을 사용하여 소스 데이터 세트를 다운로드하고 압축을 해제합니다.
wget https://files.grouplens.org/datasets/movielens/ml-latest.zip unzip ml-latest.zipCloud Storage 버킷을 만들고 데이터를 업로드합니다.
gcloud storage buckets create gs://PROJECT_ID-movielens-data gcloud storage cp ml-latest/movies.csv ml-latest/ratings.csv \ gs://PROJECT_ID-movielens-dataBigQuery 데이터 세트를 만듭니다.
bq mk movielens새 영화 BigQuery 테이블에
movies.csv를 로드합니다.bq load --skip_leading_rows=1 movielens.movies \ gs://PROJECT_ID-movielens-data/movies.csv \ movieId:integer,title,genres새 평점 BigQuery 테이블에
ratings.csv를 로드합니다.bq load --skip_leading_rows=1 movielens.ratings \ gs://PROJECT_ID-movielens-data/ratings.csv \ userId:integer,movieId:integer,rating:float,time:timestamp
BigQuery 뷰 만들기
영화 테이블을 소매 제품 카탈로그 스키마로 변환하는 뷰를 만듭니다.
bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' SELECT CAST(movieId AS string) AS id, SUBSTR(title, 0, 128) AS title, SPLIT(genres, "|") AS categories FROM `PROJECT_ID.movielens.movies`' \ movielens.products이제 새 뷰에 Vertex AI Search for Retail에 필요한 스키마가 포함됩니다. 그런 다음 왼쪽 사이드바에서
BIG DATA -> BigQuery를 선택합니다. 그런 다음 왼쪽의 탐색기 막대에서 프로젝트 이름을 확장하고movielens -> products를 선택하여 이 뷰의 쿼리 페이지를 엽니다.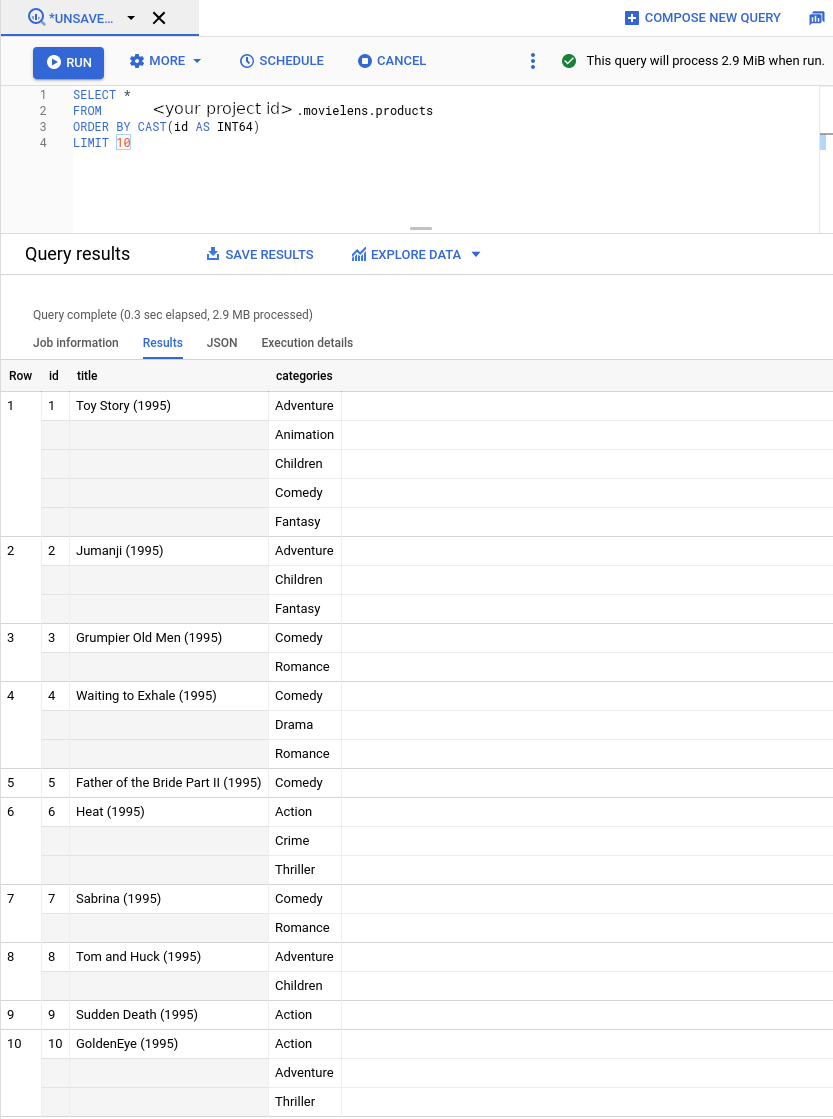
이제 영화 평점을 사용자 이벤트로 변환합니다. 그러면 다음이 수행됩니다.
- 부정적인 영화 평점 무시(4 미만)
- 모든 양수 평점을 제품 페이지 조회 이벤트로 취급(
detail-page-view) - Movielens 타임라인을 이전 90일로 다시 설정합니다. 이렇게 하는 이유는 두 가지입니다.
- Vertex AI Search for Retail에서는 사용자 이벤트가 2015년보다 오래되지 않아야 합니다. Movielens 평가는 1995년에 만들어졌습니다.
- Vertex AI Search for Retail은 사용자에게 예측 요청을 제공할 때 이전 90일 간의 사용자 데이터를 사용합니다. 이후 사용자에 대한 예측을 실행하면 모든 사용자에게 최근 이벤트가 있는 것으로 나타납니다.
BigQuery 뷰를 만듭니다. 다음 명령어는 위에 나열된 변환 요구사항을 충족하는 SQL 쿼리를 사용합니다.
bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' WITH t AS ( SELECT MIN(UNIX_SECONDS(time)) AS old_start, MAX(UNIX_SECONDS(time)) AS old_end, UNIX_SECONDS(TIMESTAMP_SUB( CURRENT_TIMESTAMP(), INTERVAL 90 DAY)) AS new_start, UNIX_SECONDS(CURRENT_TIMESTAMP()) AS new_end FROM `PROJECT_ID.movielens.ratings`) SELECT CAST(userId AS STRING) AS visitorId, "detail-page-view" AS eventType, FORMAT_TIMESTAMP( "%Y-%m-%dT%X%Ez", TIMESTAMP_SECONDS(CAST( (t.new_start + (UNIX_SECONDS(time) - t.old_start) * (t.new_end - t.new_start) / (t.old_end - t.old_start)) AS int64))) AS eventTime, [STRUCT(STRUCT(movieId AS id) AS product)] AS productDetails, FROM `PROJECT_ID.movielens.ratings`, t WHERE rating >= 4' \ movielens.user_events
제품 카탈로그 및 사용자 이벤트 가져오기
이제 제품 카탈로그 및 사용자 이벤트 데이터를 Vertex AI Search for Retail로 가져올 준비가 되었습니다.
Google Cloud 프로젝트에 대해 Vertex AI Search for Retail API를 사용 설정합니다.
시작하기를 클릭합니다.
Search for Retail 콘솔에서 데이터> 페이지로 이동합니다.
데이터 페이지로 이동가져오기를 클릭합니다.
제품 카탈로그 가져오기
위에서 만든 BigQuery 뷰에서 제품을 가져오기 위해 양식을 작성합니다.
- 가져오기 유형으로 제품 카탈로그를 선택합니다.
- 기본 브랜치 이름을 선택합니다.
- 데이터 소스로 BigQuery를 선택합니다.
- 데이터 스키마로 소매 제품 스키마를 선택합니다.
위에서 만든 제품 BigQuery 뷰의 이름을 입력합니다(
PROJECT_ID.movielens.products).
가져오기를 클릭합니다.
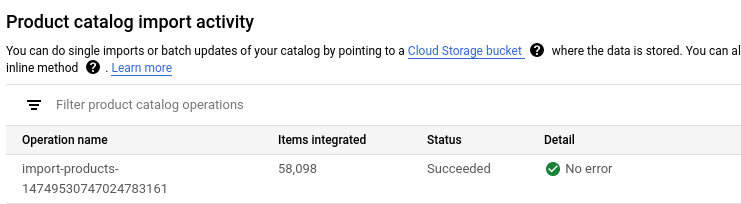
모든 제품을 가져올 때까지 기다립니다. 5~10분 정도 걸립니다.
가져오기 활동에서 가져오기 작업 상태를 확인할 수 있습니다. 가져오기가 완료되면 가져오기 작업 상태가 성공함으로 변경됩니다.
사용자 이벤트 가져오기
user_events BigQuery 뷰를 가져옵니다.
- 가져오기 유형으로 사용자 이벤트를 선택합니다.
- 데이터 소스로 BigQuery를 선택합니다.
- 데이터 스키마로 소매 사용자 이벤트 스키마를 선택합니다.
- 위에서 만든
user_eventsBigQuery 뷰의 이름을 입력합니다.
가져오기를 클릭합니다.
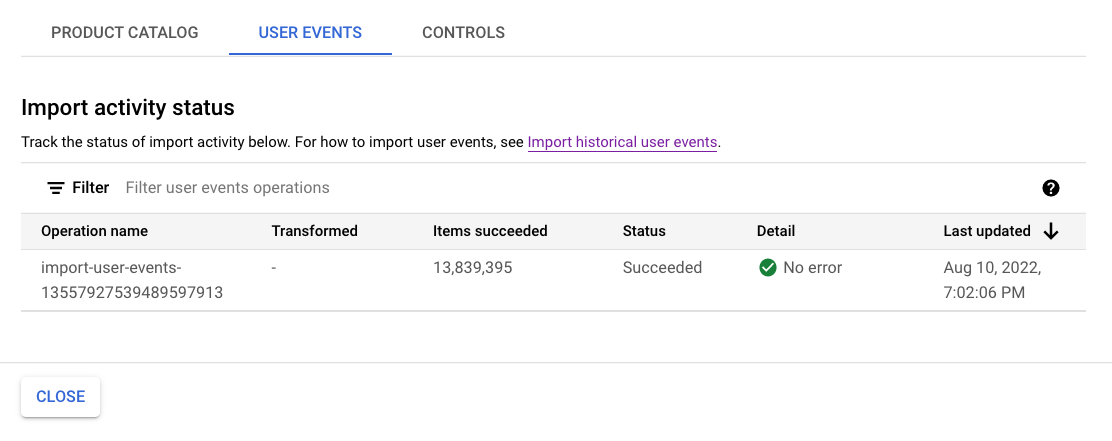
새 모델 학습에 필요한 데이터 요구사항을 충족하려면 다음 단계를 진행하기 전에 최소 1백만 개의 이벤트를 가져올 때까지 기다립니다.
가져오기 활동에서 작업 상태를 확인할 수 있습니다. 이 프로세스는 완료되는 데 1시간 정도 걸립니다.
추천 모델 학습 및 평가
추천 모델 만들기
Search for Retail 콘솔의 모델 페이지로 이동합니다.
모델 페이지로 이동모델 만들기를 클릭합니다.
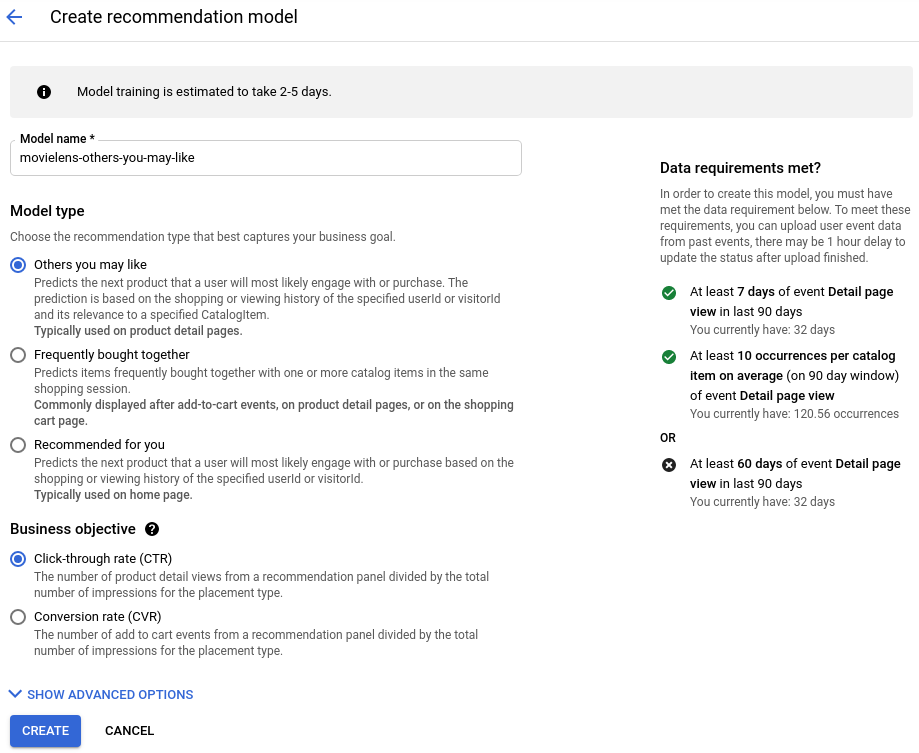
- 모델 이름을 입력합니다.
- 모델 유형으로 내가 좋아할 만한 기타 항목을 선택합니다.
- 비즈니스 목표로 클릭률(CTR)을 선택합니다.
만들기를 클릭합니다.
새 모델이 학습을 시작합니다.
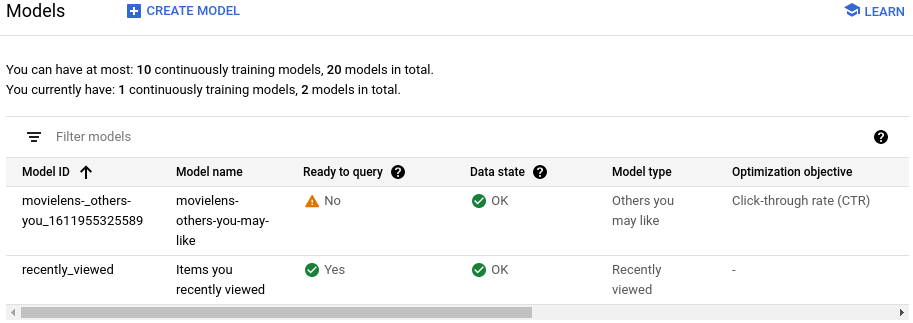
서빙 구성 만들기
Search for Retail 콘솔에서 서빙 구성 페이지로 이동합니다.
서빙 구성 페이지로 이동서빙 구성 만들기를 클릭합니다.
- 추천을 선택합니다.
- 서빙 구성 이름을 지정합니다.
- 만든 모델을 선택합니다.
만들기를 클릭합니다.
모델이 '쿼리 준비 완료' 상태가 될 때까지 기다리기
모델이 학습되고 쿼리를 수행할 준비가 될 때까지 2일 정도 걸립니다.
상태를 보려면 서빙 구성 페이지에서 생성된 서빙 구성을 클릭합니다.
프로세스가 완료되면 쿼리할 모델 준비 완료 필드에 예가 표시됩니다.
추천 미리보기
모델이 쿼리할 준비가 되면 다음 안내를 따르세요.
-
Search for Retail 콘솔에서 서빙 구성 페이지로 이동합니다.
서빙 구성 페이지로 이동 - 서빙 구성 이름을 클릭하여 세부정보 페이지로 이동합니다.
- 평가 탭을 클릭합니다.
시드 영화 ID를 입력합니다. '반지의 제왕: 반지 원정대(2001)'의 경우
4993입니다.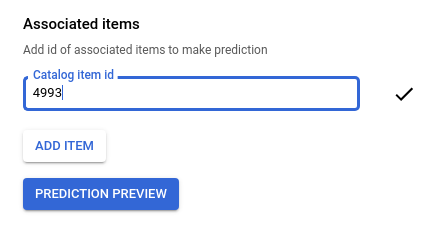
예측 미리보기를 클릭하여 페이지 오른쪽에서 추천 항목 목록을 확인합니다.
삭제
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트를 유지하고 개별 리소스를 삭제하세요.
프로젝트 삭제
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
개별 리소스 삭제
서빙 구성 페이지로 이동하여 만든 서빙 구성을 삭제합니다.
모델 페이지로 이동하여 모델을 삭제합니다.
Cloud Shell에서 BigQuery 데이터 세트를 삭제합니다.
bq rm --recursive --dataset movielensCloud Storage 버킷 및 콘텐츠를 삭제합니다.
gcloud storage rm gs://PROJECT_ID-movielens-data --recursive