Crie uma plataforma de dados de análise unificada e moderna com o Google Cloud
Saiba mais sobre os pontos de decisão necessários para criar uma plataforma de dados de análise unificada e moderna no Google Cloud.
Autores: Firat Tekiner e Susan Pierce

Visão geral
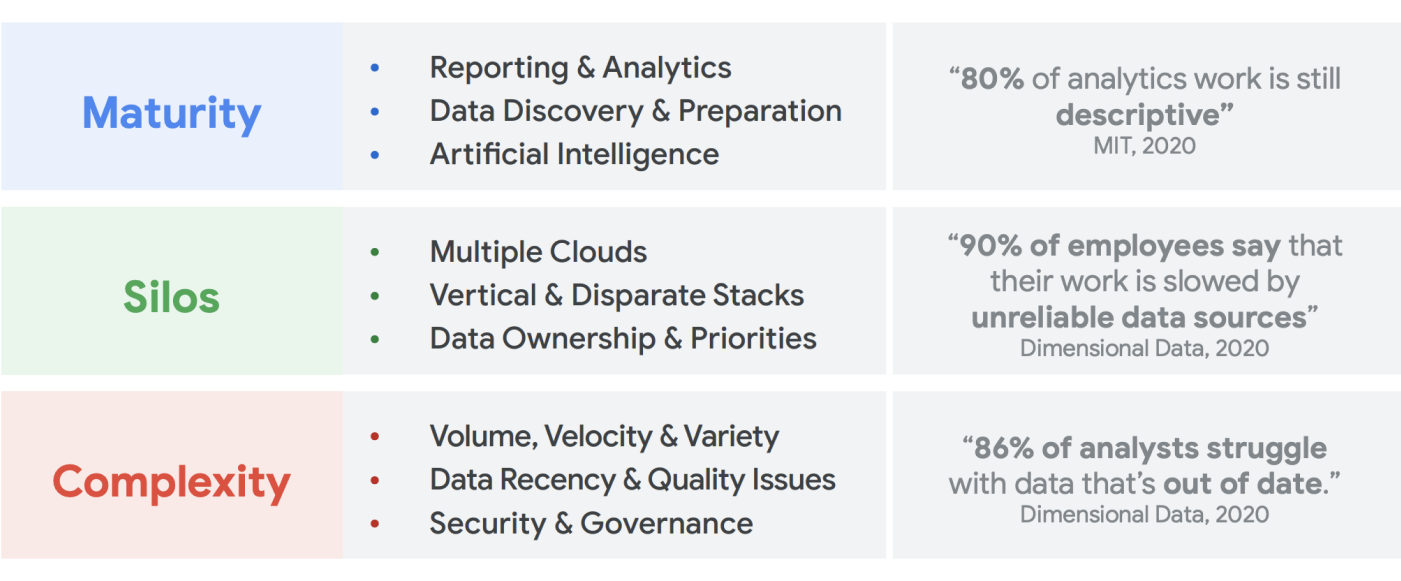
Não faltam dados sendo criados. A pesquisa da IDC indica que os dados mundiais crescerão para 175 zettabytes até 20251. O volume de dados gerados todos os dias é impressionante, e é cada vez mais difícil para as empresas coletar, armazenar e organizar esses dados de uma maneira acessível e utilizável. Na verdade, 90% dos profissionais de dados dizem que seu trabalho foi retardado por fontes de dados não confiáveis. Cerca de 86% dos analistas de dados têm dificuldades com dados desatualizados, e mais de 60% dos profissionais de dados são afetados por esperar os recursos de engenharia todos os meses enquanto os dados são limpos e preparados2.
Estruturas organizacionais e decisões arquitetônicas ineficientes contribuem para a lacuna que as empresas têm entre agregar dados e fazê-los funcionar para elas. As empresas querem migrar para a nuvem para modernizar os sistemas de análise de dados, mas isso por si só não resolve os problemas das fontes de dados em silos e dos pipelines de processamento frágeis. As decisões estratégicas sobre propriedade de dados e decisões técnicas sobre mecanismos de armazenamento precisam ser tomadas de forma holística para que uma plataforma de dados tenha mais sucesso em sua organização.
Neste artigo, vamos discutir os pontos de decisão necessários para criar uma plataforma de dados de análise unificada e moderna no Google Cloud.
O Big Data criou oportunidades incríveis para as empresas nas últimas duas décadas. No entanto, é complicado para as organizações apresentar aos seus usuários de negócios dados relevantes, acionáveis e oportunos. A pesquisa mostra que 86% dos analistas ainda têm dificuldade com dados desatualizados3, e apenas 32% das empresas acham que estão conseguindo valor tangível com os dados4. O primeiro problema é a atualização de dados. O segundo problema é decorrente da dificuldade em integrar sistemas díspares e legados em silos. As organizações estão migrando para a nuvem, mas isso não resolve o problema real de sistemas legados mais antigos, que poderiam ter sido estruturados verticalmente para atender às necessidades de uma única unidade de negócios.
Ao planejar as necessidades de dados organizacionais, é fácil generalizar demais e considerar uma estrutura única e simplificada em que há um conjunto de fontes de dados consistentes, um data warehouse corporativo, um conjunto de semânticas e uma ferramenta de Business Intelligence. Isso pode funcionar para uma organização muito pequena e altamente centralizada, e pode até funcionar para uma única unidade de negócios com sua própria equipe integrada de TI e engenharia de dados. Na prática, no entanto, nenhuma organização é tão simples e há sempre complexidades surpresa com a ingestão, o processamento e/ou o uso de dados que complicam ainda mais.
Conversamos com centenas de clientes sobre a necessidade de uma abordagem mais holística para os dados e a análise, uma plataforma que possa atender às necessidades de várias unidades de negócios e perfis de usuários, com o mínimo de etapas redundantes possível para processar os dados. Isso se torna mais do que uma nova arquitetura ou um conjunto de componentes de software para compra. Isso exige que as empresas avaliem a maturidade geral de dados e façam mudanças organizacionais e sistêmicas, além de atualizações técnicas.
Até o final de 2024, 75% das empresas vão migrar dos pilotos para a operacionalização da IA, gerando um aumento de 5 vezes no streaming de dados e nas infraestruturas de análise5. É fácil testar a IA com uma equipe ampla de ciência de dados, trabalhando em um ambiente isolado. Mas o principal desafio que impede que esses insights sejam lançados nos sistemas de produção é o atrito organizacional e arquitetônico que mantém a propriedade dos dados segmentada. Como resultado, a maioria dos insights incorporados nas operações de negócios de uma organização é de natureza descritiva, e a análise preditiva é relegada ao âmbito de uma equipe de pesquisa.

Uma plataforma para todos os usuários ao longo do ciclo de vida dos dados
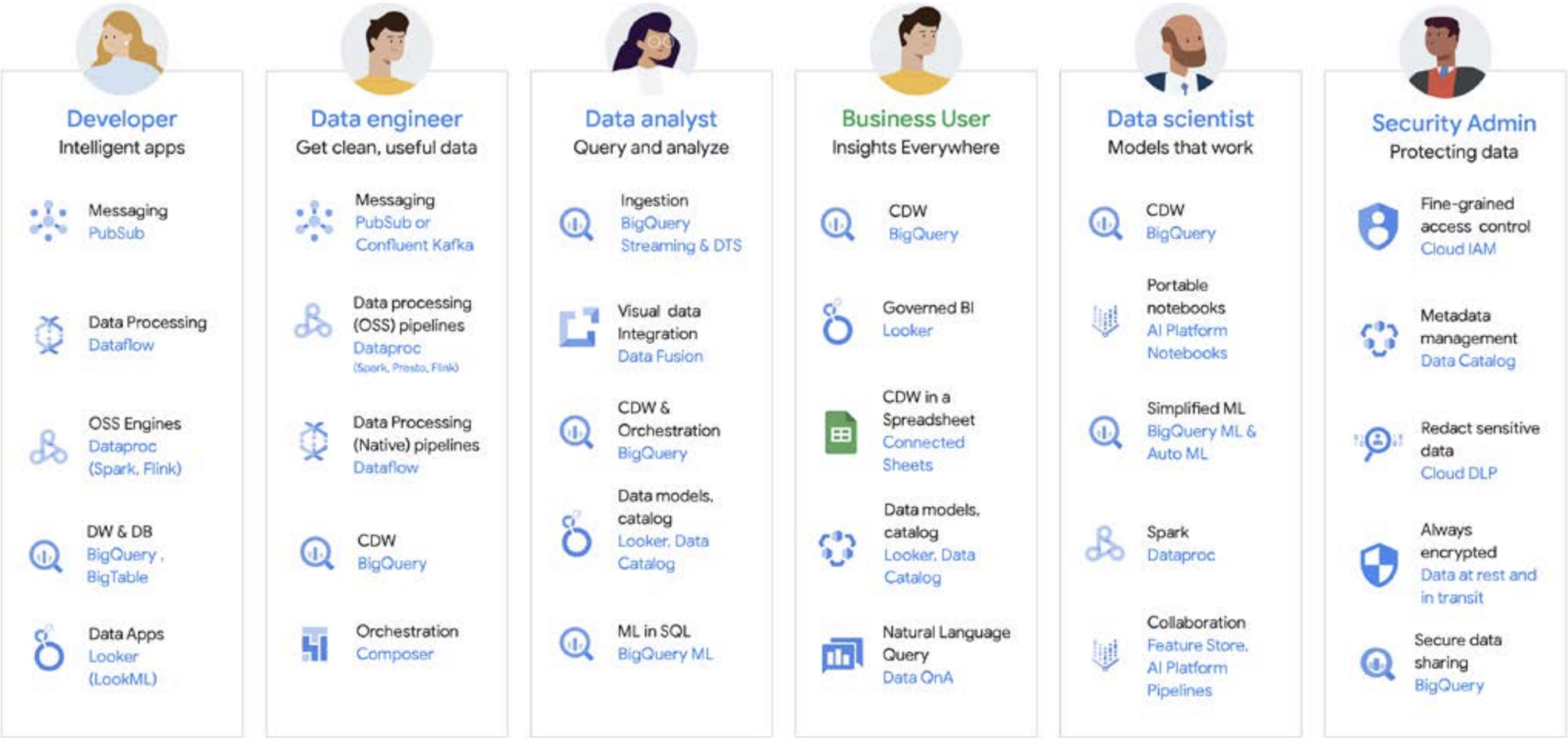
O trabalho de dados raramente é feito por um único indivíduo; há muitos usuários relacionados a dados em uma organização que desempenham papéis importantes no ciclo de vida dos dados. Cada uma tem uma perspectiva diferente sobre governança de dados, atualização, descoberta, metadados, cronogramas de processamento, capacidade de consulta e muito mais. Na maioria dos casos, todas usam sistemas e softwares diferentes para operar nos mesmos dados, em diferentes estágios de processamento.
Vamos observar, por exemplo, um ciclo de vida de machine learning. Um engenheiro de dados pode ser responsável por garantir que dados novos estejam disponíveis para a equipe de ciência de dados, com as restrições de segurança e privacidade apropriadas em vigor. Um cientista de dados pode criar conjuntos de dados de treinamento e teste com base em um conjunto de ouro de fontes de dados pré-agregadas do engenheiro de dados, criar e testar modelos e disponibilizar insights para outra equipe. Um engenheiro de ML pode ser responsável por empacotar o modelo para implantação em sistemas de produção de maneira que não cause interrupções para outros pipelines de processamento de dados. Um gerente de produto ou analista de negócios pode conferir insights derivados usando o Data QnA (uma interface de linguagem natural para análise de dados do BigQuery), um software de visualização ou pode consultar o conjunto de resultados diretamente por um ambiente de desenvolvimento integrado ou interface de linha de comando. Há inúmeros usuários com diferentes necessidades e nós criamos uma plataforma compacta para atender a todos. O Google Cloud atende aos clientes onde quer que eles estejam com ferramentas que atendem às necessidades da empresa.
A decisão de Big Data: data warehouse ou data lake?
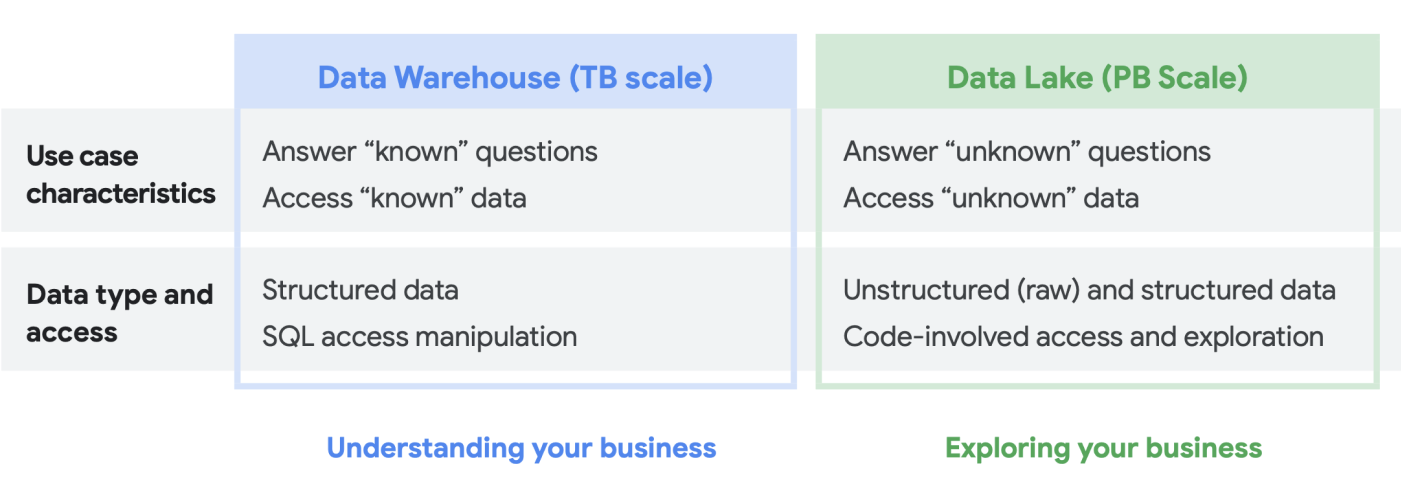
Quando conversamos com os clientes sobre suas necessidades de análise de dados, frequentemente ouvimos a pergunta: “O que eu preciso: um data lake ou um data warehouse?” Dada a variedade de usuários e necessidades de dados dentro de uma organização, isso pode ser uma pergunta difícil de responder que depende do uso pretendido, tipos de dados e pessoal.
- Se você sabe quais conjuntos de dados precisa analisar, tem uma compreensão clara da estrutura deles e tem um conjunto conhecido de perguntas que precisa responder, provavelmente está usando um data warehouse.
- Por outro lado, se você precisa de visibilidade em vários tipos de dados, não tem certeza sobre os tipos de análises que precisa executar, está em busca de oportunidades para explorar em vez de apresentar insights e tem os recursos para gerenciar e explorar isso de maneira eficaz um data lake provavelmente será mais adequado às suas necessidades,
mas há mais na decisão, então vamos falar sobre alguns dos desafios organizacionais de cada uma. Os data warehouses costumam ser difíceis de gerenciar. Os sistemas legados que funcionaram bem nos últimos 40 anos provaram ser muito caros e apresentam muitos desafios em relação à atualização de dados, escalonamento e custos elevados. Além disso, eles não podem oferecer recursos de IA ou em tempo real facilmente sem implementar essa funcionalidade após o fato. Esses problemas não estão presentes apenas em data warehouses legados e locais. Vemos isso também nos data warehouses baseados em nuvem recém-criados. Muitos não oferecem recursos de IA integrados, apesar das afirmações. Esses novos data warehouses são essencialmente os mesmos ambientes legados, mas transferidos para a nuvem. Os usuários do data warehouse tendem a ser analistas, geralmente incorporados a uma unidade de negócios específica. Eles podem ter ideias sobre conjuntos de dados adicionais que seriam úteis para enriquecer sua compreensão dos negócios. Eles podem ter ideias para melhorias na análise, processamento de dados e requisitos da funcionalidade de Business Intelligence.
No entanto, em uma organização tradicional, eles geralmente não têm acesso direto aos proprietários dos dados, nem podem influenciar facilmente os tomadores de decisão técnicos que decidem conjuntos de dados e ferramentas. Além disso, como são mantidos separados dos dados brutos, eles são incapazes de testar hipóteses ou conduzir uma compreensão mais profunda dos dados subjacentes. Os data lakes têm seus próprios desafios. Em teoria, eles são de baixo custo e fáceis de escalonar, mas muitos dos nossos clientes perceberam uma realidade diferente nos data lakes no local. Planejar e provisionar armazenamento suficiente pode ser caro e difícil, principalmente para organizações que produzem quantidades de dados altamente variáveis. Os data lakes no local podem ser frágeis, e a manutenção dos sistemas atuais leva tempo. Em muitos casos, os engenheiros que, de outra forma, estariam desenvolvendo novos atributos, são atribuídos ao cuidado e à alimentação dos clusters de dados. Em poucas palavras, eles mantêm valor em vez de criar valor. De modo geral, o custo total de propriedade é maior do que o esperado para muitas empresas. Não apenas isso, a governança não é facilmente resolvida entre sistemas, especialmente quando partes diferentes da organização usam modelos de segurança distintos. Como resultado, os data lakes ficam isolados e segmentados, dificultando o compartilhamento de dados e modelos entre as equipes.
Os usuários do data lake normalmente estão mais próximos das fontes de dados brutos e têm ferramentas e recursos para explorar os dados. Em organizações tradicionais, esses usuários tendem a se concentrar nos próprios dados e costumam ser mantidos à distância do restante do negócio. Essa desconexão significa que as unidades de negócios perdem a oportunidade de encontrar insights que levariam seus objetivos de negócios adiante para receitas mais altas, custos mais baixos, menor risco e novas oportunidades. Devido a essas desvantagens, muitas empresas acabam com uma abordagem híbrida, em que um data lake é configurado para graduar alguns dados em um data warehouse, ou esse data warehouse tem um data lake lateral para testes e análises adicionais. No entanto, com várias equipes fabricando as próprias arquiteturas de dados para atender às necessidades individuais, a fidelidade e o compartilhamento de dados se tornam ainda mais complicados para uma equipe central de TI. Em vez de ter equipes separadas com metas separadas, em que uma explora o negócio e outra o entende, é possível unir essas funções e os sistemas de dados delas para criar um ciclo virtuoso em que uma compreensão mais profunda dos negócios impulsiona a exploração direcionada, e essa exploração impulsiona a exploração um melhor entendimento do negócio.
Tratar o armazenamento de data warehouse como um data lake
É possível criar um data warehouse ou um data lake separadamente no Google Cloud, mas não é preciso escolher apenas um deles. Em muitos casos, os produtos subjacentes que nossos clientes usam são os mesmos em ambos, e a única diferença entre a implementação de data lake e data warehouse é a política de acesso aos dados empregada. Na verdade, os dois termos estão começando a convergir em um conjunto mais unificado de funcionalidades, uma moderna plataforma de dados de análise. Vamos conferir como isso funciona no Google Cloud.
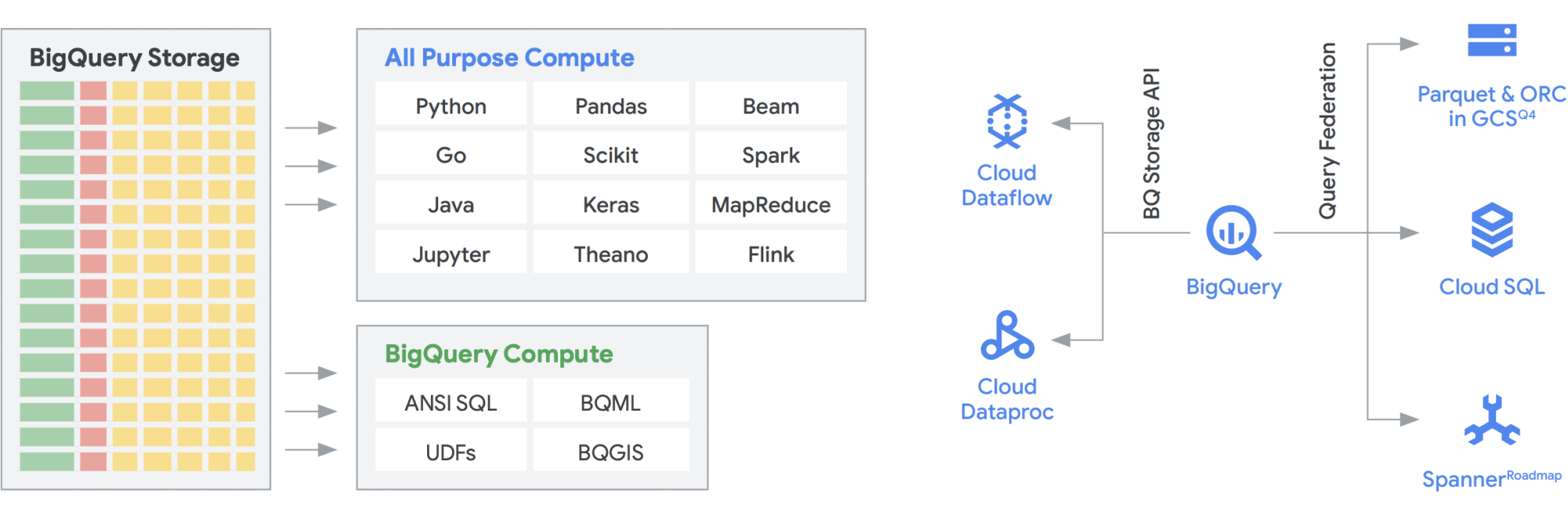
Com a API BigQuery Storage, é possível usar o BigQuery Storage, como o Cloud Storage, em vários outros sistemas, como o Dataflow e o serviço gerenciado para Apache Spark. Dessa forma, é possível quebrar o limite de armazenamento de data warehouses e executar data frames de alto desempenho no BigQuery. Em outras palavras, a API BigQuery Storage permite que seu data warehouse do BigQuery atue como um data lake. Quais são alguns dos usos práticos dele? Por um lado, criamos uma série de conectores, como o MapReduce, o Hive e o Spark, para que as cargas de trabalho do Hadoop e do Spark possam ser executadas diretamente nos dados do BigQuery. Você não precisa mais de um data lake além do seu data warehouse. O Dataflow é incrivelmente eficiente para processamento de stream e em lote. Atualmente, é possível executar jobs do Dataflow nos dados do BigQuery, enriquecendo-os com dados do Pub/Sub, do Spanner ou de qualquer outra fonte de dados.
O BigQuery pode escalonar de maneira independente o armazenamento e a computação, e cada um é sem servidor, o que permite um escalonamento ilimitado para atender à demanda, independentemente do uso de diferentes equipes, ferramentas e padrões de acesso. Todos os aplicativos acima podem ser executados sem afetar o desempenho de outros jobs que acessam o BigQuery ao mesmo tempo. Além disso, a API BigQuery Storage fornece uma rede em nível de petabit, movendo dados entre nós para atender a uma solicitação de consulta, levando a um desempenho semelhante ao de uma operação na memória. Ela também permite a federação com os formatos de dados conhecidos do Hadoop, como Parquet e ORC, diretamente, bem como bancos de dados NoSQL e OLTP. Você pode ir além com os recursos oferecidos pelo Dataflow SQL, que está incorporado ao BigQuery. Isso permite mesclar os streams com tabelas do BigQuery ou dados que estão em arquivos, criando efetivamente uma arquitetura lambda, permitindo a ingestão de grandes quantidades de dados em lote e de streaming, além de fornecer uma camada de disponibilização para responder a consultas. O BigQuery BI Engine e as visualizações materializadas facilitam ainda mais o aumento da eficiência e do desempenho nessa arquitetura multiuso.
Plataforma de análise inteligente do Google com tecnologia BigQuery
As soluções de dados sem servidor são absolutamente necessárias para permitir que sua organização vá além dos silos de dados e para o campo de insights e ação. Todos os nossos serviços principais de análise de dados são totalmente integrados e sem servidor.

A gestão de mudanças é muitas vezes um dos aspectos mais difíceis de incorporar qualquer nova tecnologia em uma organização. O Google Cloud procura atender nossos clientes onde eles estão, fornecendo ferramentas, plataformas e integrações conhecidas para desenvolvedores e usuários corporativos. Nossa missão é acelerar a capacidade da sua organização de reimaginar e transformar digitalmente seus negócios por meio da inovação impulsionada por dados. Em vez de depender de apenas um fornecedor, o Google Cloud oferece às empresas opções para integrações simples e simplificadas com ambientes locais, outras ofertas de nuvem e até mesmo o Edge para formar uma nuvem verdadeiramente híbrida:
- O BigQuery Omni elimina a necessidade de transferir dados de um ambiente para outro. Em vez disso, ele leva as análises para os dados em qualquer ambiente.
- O Apache Beam, o SDK usado no Dataflow, oferece portabilidade e portabilidade a executores como Apache Spark e Apache Flink
- Para organizações que querem executar o Apache Spark ou o Apache Hadoop, o Google Cloud oferece o Serviço gerenciado para Apache Spark
A maioria dos usuários de dados se preocupa com os dados que eles têm, não com o sistema em que estão. Ter acesso aos dados de que precisam quando precisam é o mais importante. Na maioria das vezes, o tipo de plataforma não importa para os usuários, desde que eles possam acessar dados novos e utilizáveis com ferramentas conhecidas, seja explorando conjuntos de dados, gerenciando fontes em armazenamentos de dados, executando consultas ad hoc ou desenvolvimento de ferramentas internas de Business Intelligence para executivos.
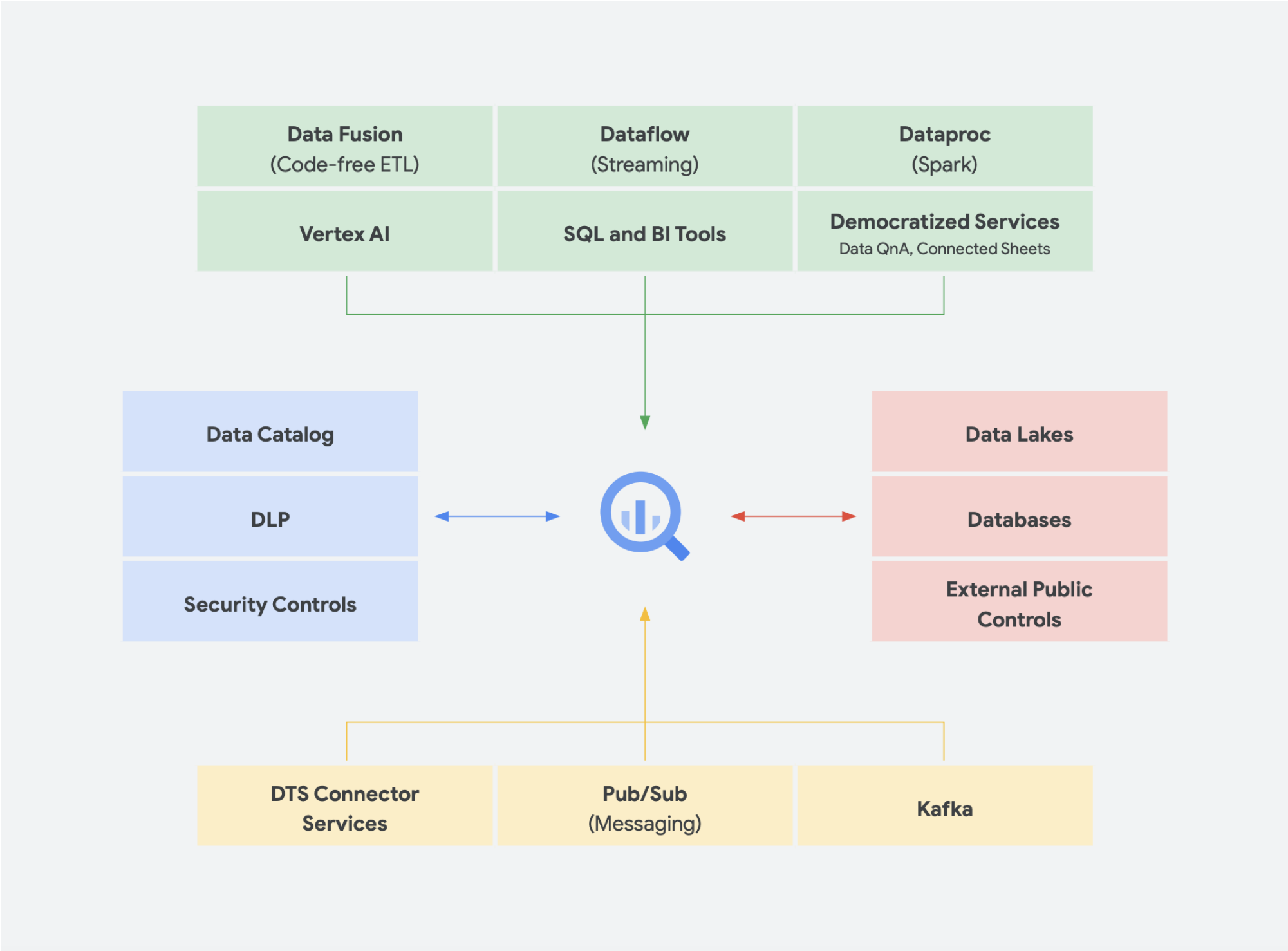
Tendências emergentes
Continuando com essa ideia de convergência de um data lake e um data warehouse em uma plataforma de dados de análise unificada, outras soluções de dados estão ganhando força. Temos visto muitos conceitos surgindo em torno de lakehouse e malha de dados, por exemplo. Você já deve ter ouvido alguns desses termos antes. Alguns não são novos e existem em diferentes formas e formatos há anos. No entanto, eles funcionam muito bem no ambiente do Google Cloud. Vamos entender melhor como seriam uma malha de dados e um lakehouse no Google Cloud e o que eles significam para o compartilhamento de dados em uma organização. Lakehouse e malha de dados não são mutuamente exclusivos, mas ajudam a resolver diferentes desafios dentro de uma organização. Mas um favorece a ativação dos dados, enquanto o outro capacita as equipes. A malha de dados permite que as pessoas evitem gargalos de uma equipe, possibilitando toda a pilha de dados. Ela divide os silos em unidades organizacionais menores em uma arquitetura que dá acesso aos dados de maneira federada. O lakehouse reúne o data warehouse e o data lake, permitindo tipos diferentes e volumes de dados maiores. Isso resulta na prática de esquemas na leitura em vez de esquemas na gravação, um recurso de data lakes que se pensou em preencher algumas das lacunas de desempenho nos data warehouses corporativos. Outra vantagem dessa arquitetura é usar uma governança de dados mais rigorosa, algo que os data lakes não costumam ter.

Lakehouse
Como mencionado acima, a API Storage do BigQuery permite tratar seu data warehouse como um data lake. Os jobs do Spark em execução no Serviço Gerenciado para Apache Spark ou em ambientes Hadoop semelhantes podem usar os dados armazenados no BigQuery, em vez de exigir um meio de armazenamento separado, usando o armazenamento do data warehouse. O poder de computação separado do armazenamento no BigQuery permite a transformação baseada em SQL e usa visualizações em diferentes camadas dessas transformações. Isso leva a uma abordagem do tipo ELT e permite uma plataforma de processamento de dados mais ágil. Usando ELT sobre ETL, o BigQuery permite que transformações baseadas em SQL sejam armazenadas como visualizações lógicas. Despejar todos os dados brutos no armazenamento do data warehouse pode ser caro com um data warehouse tradicional, mas não há cobrança extra pelo armazenamento do BigQuery. Seu custo é bastante comparável ao armazenamento de blobs no Google Cloud Storage.
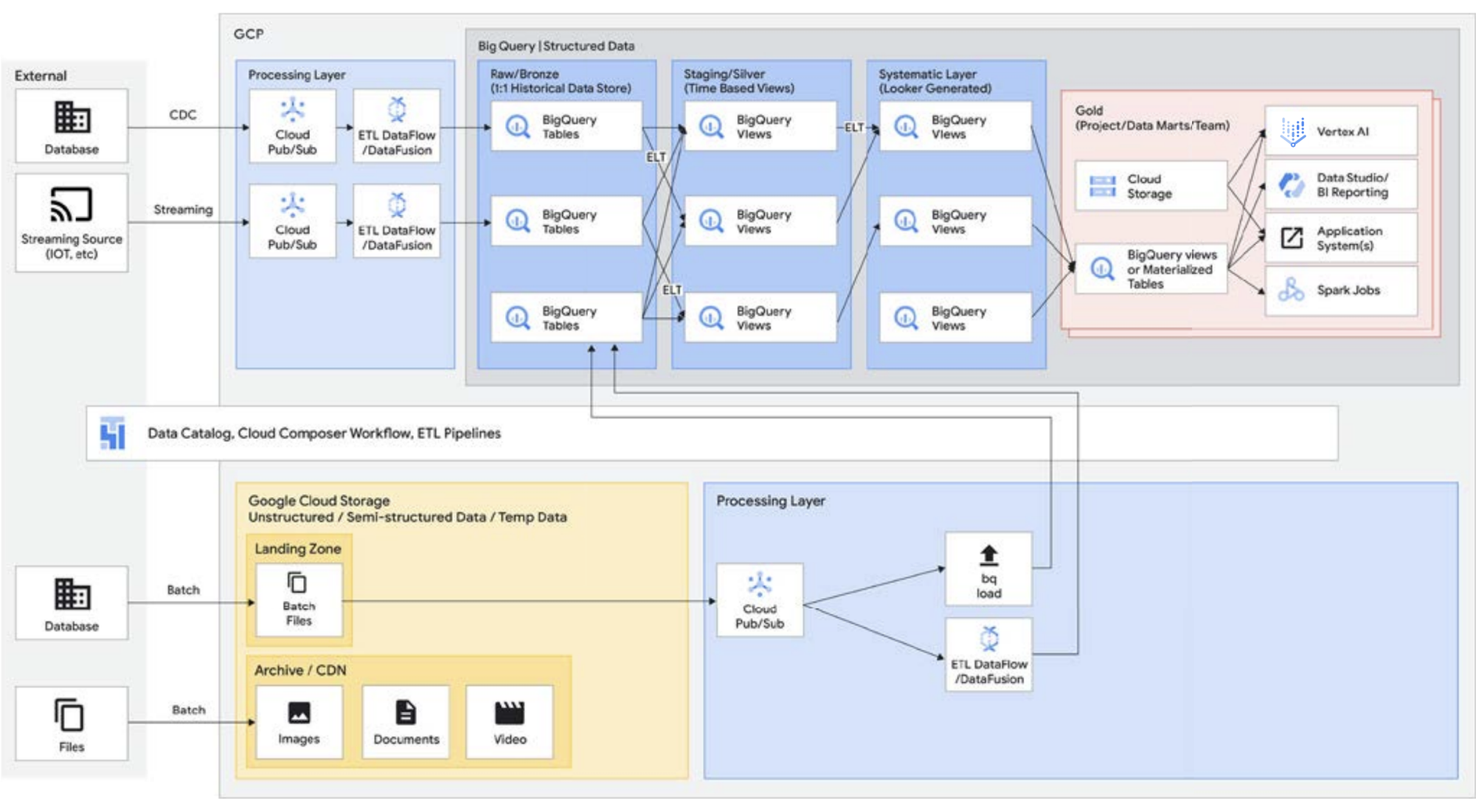
Ao executar ETL, as transformações estão ocorrendo fora do BigQuery, possivelmente em uma ferramenta que não tem capacidade de escalonamento. Ela pode acabar transformando os dados linha por linha em vez de paralelizar as consultas. Pode haver casos em que o Spark ou outros processos de ETL já estejam codificados, e mudá-los para uma nova tecnologia pode não fazer sentido. No entanto, se houver transformações que possam ser escritas em SQL, o BigQuery provavelmente é um ótimo lugar para fazê-las.
Além disso, essa arquitetura é compatível com todos os componentes do Google Cloud, como o Serviço gerenciado para Apache Airflow, o Data Catalog ou o Data Fusion. Ela fornece uma camada de ponta a ponta para diferentes perfis de usuários. Outro aspecto importante da redução do overhead operacional é o aproveitamento dos recursos da infraestrutura subjacente. Considere o Dataflow e o BigQuery. Todos são executados em contêineres e permitem gerenciar o tempo de atividade e a mecânica em segundo plano. Depois que ela for estendida a ferramentas de terceiros e parceiros, e quando eles começarem a usar recursos semelhantes, como o Kubernetes, vai ficar muito mais simples de gerenciar e transferir. Por sua vez, isso reduz as despesas operacionais e de recursos. Além disso, é possível complementar isso com melhor observabilidade com o uso dos painéis de monitoramento do Serviço Gerenciado para Apache Airflow para alcançar a excelência operacional. Além de reunir os dados armazenados no Cloud Storage e no BigQuery para criar um data lake, sem movimentação ou duplicação de dados, também oferecemos funcionalidades administrativas adicionais para gerenciar suas origens de dados. O Knowledge Catalog (antigo Dataplex) permite criar um lakehouse com uma camada de gerenciamento centralizada para coordenar os dados no Cloud Storage e no BigQuery. Isso permite que você organize seus dados com base nas necessidades do seu negócio, assim você não fica mais restrito por como ou onde eles são armazenados.
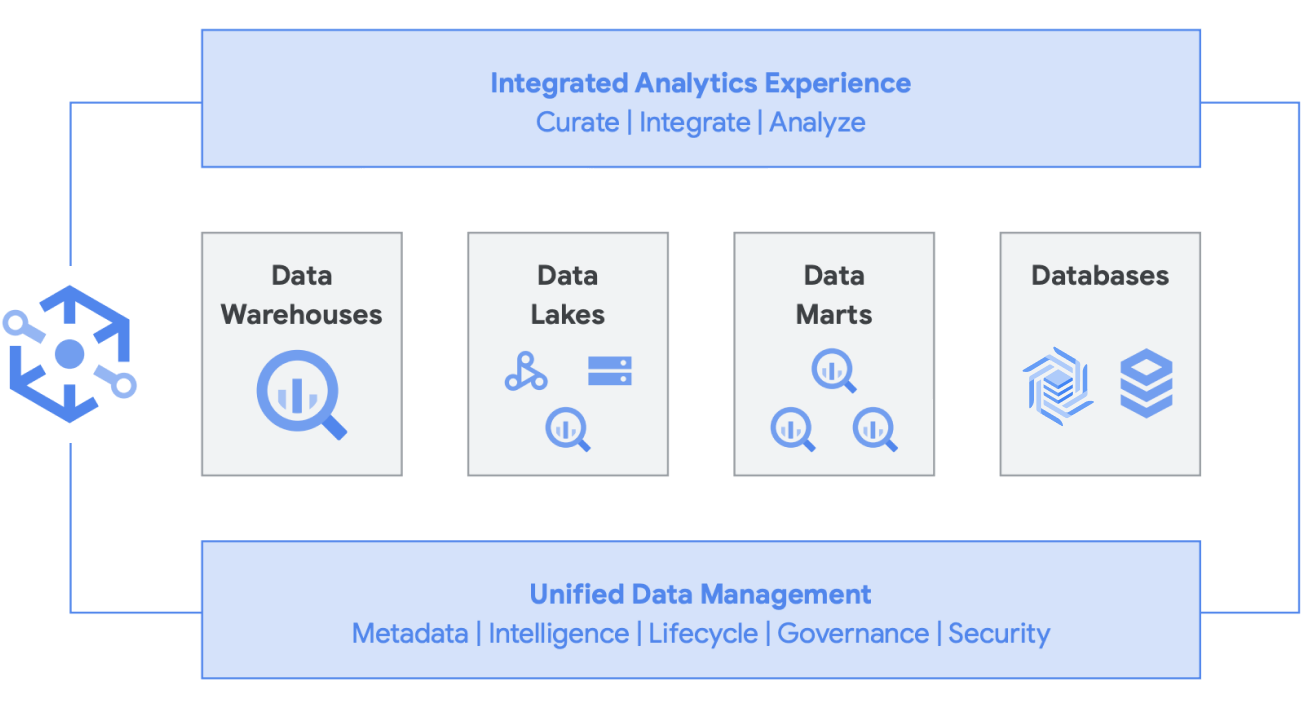
O Dataplex é uma malha de dados inteligente que permite que você mantenha seus dados distribuídos pelo preço/desempenho certo, além de tornar esses dados acessíveis com segurança para todas as ferramentas de análise. Ele fornece gerenciamento de dados liderado por metadados com qualidade e governança de dados integradas, para que você passe menos tempo lidando com limites e ineficiências de infraestrutura, confie nos dados que tem e passe mais tempo extraindo valor deles. Além disso, ele oferece uma experiência de análise integrada, reunindo o melhor do Google Cloud e do código aberto para selecionar, proteger, integrar e analisar dados em grande escala com rapidez. Por fim, é possível criar uma estratégia de análise que amplie a arquitetura atual e atenda às suas metas de governança financeira.
Malha de dados
A malha de dados foi criada com base em um longo histórico de inovações em data warehouses e data lakes, além de modelos de pagamento por desempenho e escalonabilidade incomparáveis, APIs, DevOps e integração total dos produtos do Google Cloud. Com essa abordagem, você pode criar uma solução de dados sob demanda de maneira eficaz. Uma malha de dados descentraliza a propriedade dos dados entre os proprietários de dados do domínio, cada um deles responsável por fornecer os dados como um produto de maneira padrão. Uma malha de dados também facilita a comunicação entre diferentes partes da organização com conjuntos de dados distribuídos em diferentes locais. Em uma malha de dados, a responsabilidade de gerar valor dos dados é federada para as pessoas que os entendem melhor; em outras palavras, as pessoas que criaram os dados ou os trouxeram para a organização também devem ser responsáveis por criar ativos de dados consumíveis como produtos a partir dos dados que elas criam. Em muitas organizações, estabelecer uma "única fonte de verdade" ou "fonte de dados autoritativa" é um desafio devido à extração e transformação repetidas de dados em toda a organização sem responsabilidades claras de propriedade sobre os dados recém-criados. Na malha de dados, a fonte autoritativa é o produto de dados publicado pelo domínio de origem, com um proprietário de dados claramente atribuído e um administrador responsável por esses dados.
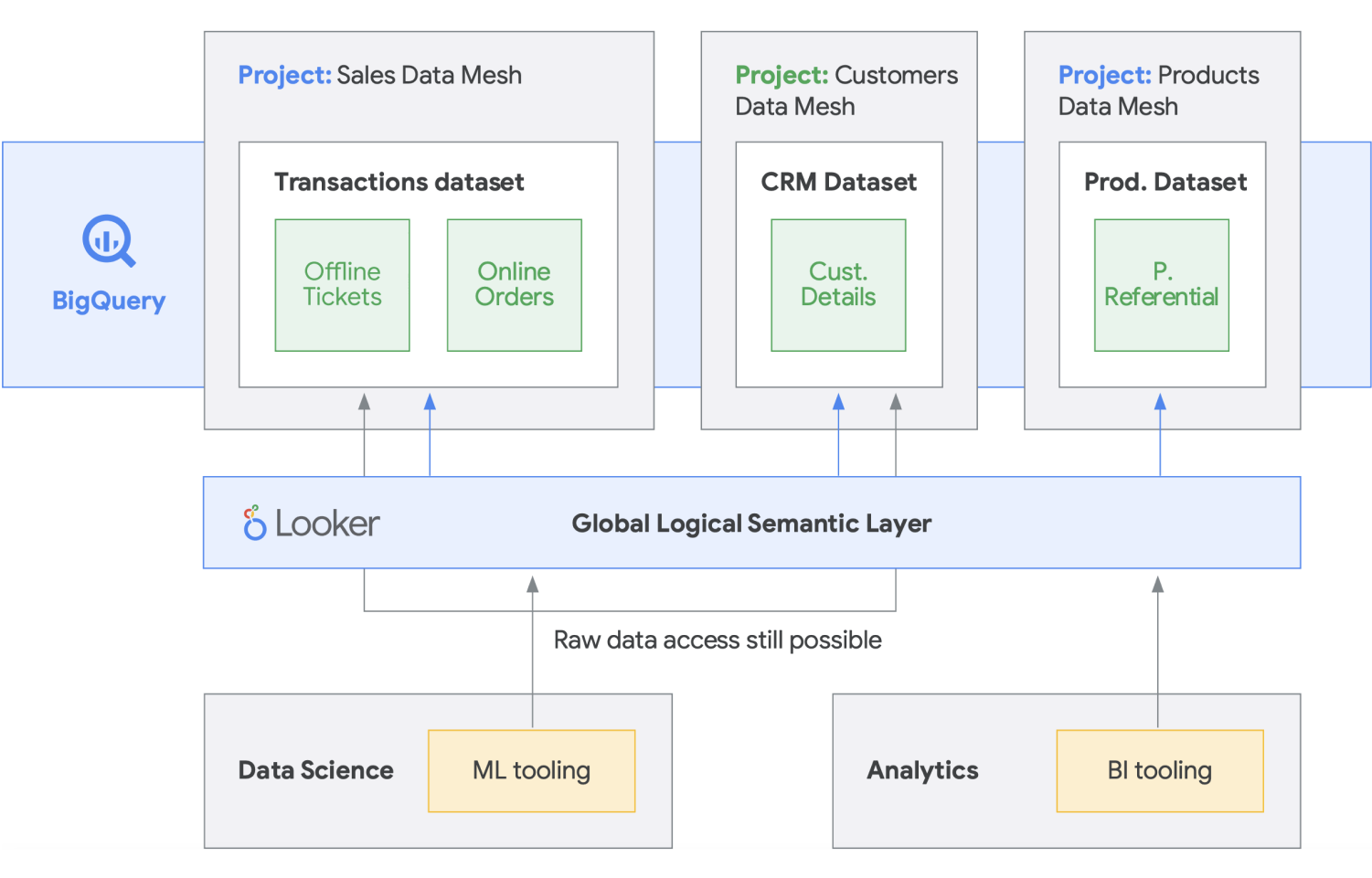
Em resumo, a malha de dados promete uma propriedade e arquitetura de dados descentralizadas e orientadas ao domínio. Isso é possível graças à computação federada e às camadas de acesso, como oferecemos no Google Cloud. Além disso, se a sua organização quer mais funcionalidades, é possível usar algo como o Looker, que pode fornecer uma camada unificada para modelar e acessar os dados. A plataforma do Looker oferece uma interface de painel único para acessar a versão mais verdadeira e atualizada dos dados e definições de negócios da sua empresa. Com essa visão unificada dos negócios, você pode escolher ou projetar experiências de dados que garantam que as pessoas e os sistemas recebam os dados da maneira que faz mais sentido para suas necessidades. Ela se encaixa perfeitamente porque permite que cientistas de dados, analistas e até usuários comerciais acessem os dados com um único modelo semântico. Os cientistas de dados ainda acessam os dados brutos, mas sem a movimentação e duplicação de dados.
Estamos desenvolvendo mais funcionalidades com nossos produtos para cargas de trabalho, como o BigQuery, para facilitar a criação e o gerenciamento de conjuntos de dados. O Analytics Hub permite criar trocas de dados particulares, nas quais os administradores da troca (também conhecidos como curadores de dados) dão permissões para publicar e assinar dados em troca de indivíduos ou grupos específicos dentro e fora da empresa para parceiros de negócios ou compradores.
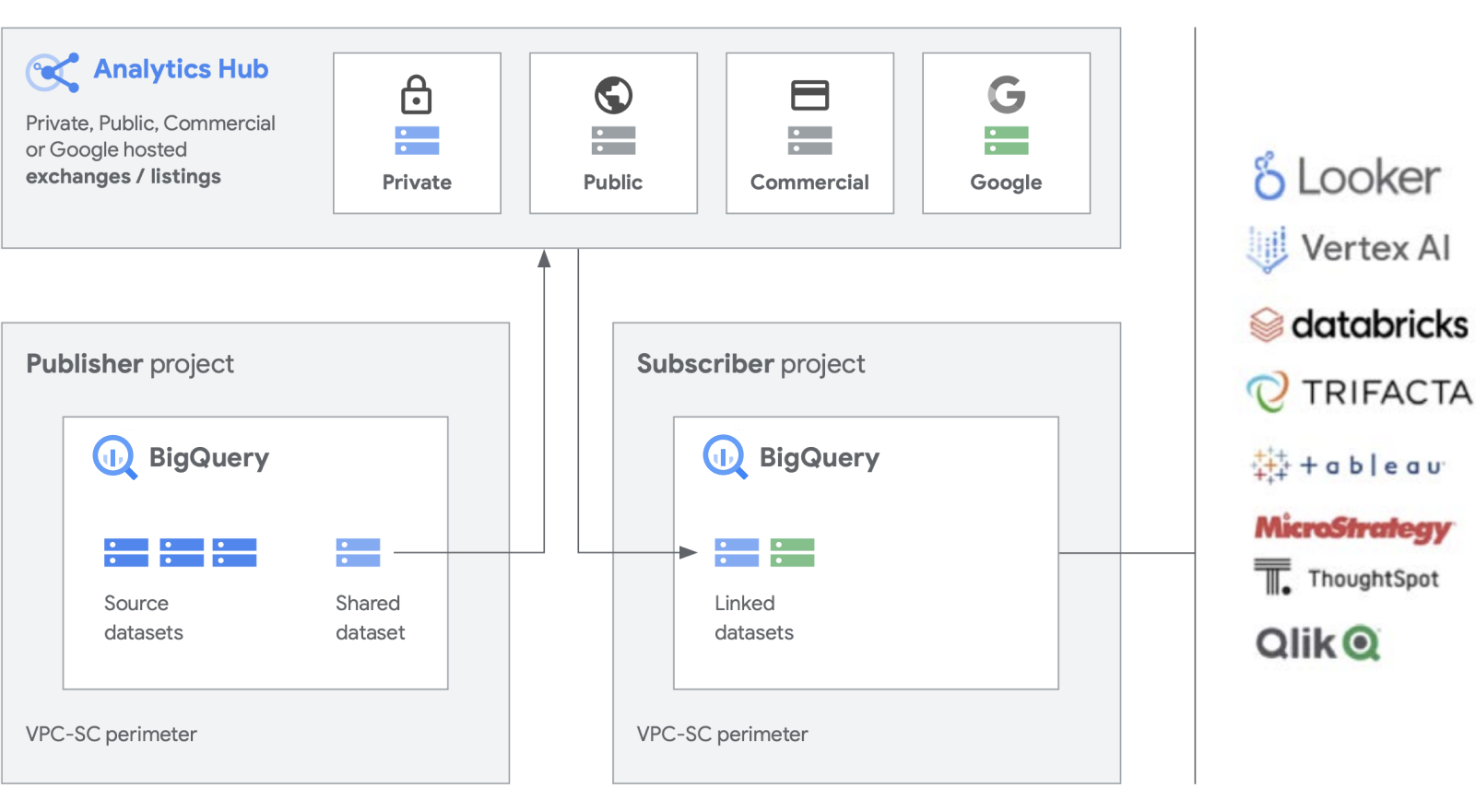
Publique, descubra e assine recursos compartilhados, incluindo formatos de código aberto, com a escalonabilidade do BigQuery. Os editores podem visualizar métricas de uso agregadas. Os provedores de dados podem alcançar clientes corporativos do BigQuery com dados, insights, modelos de ML ou visualizações e aproveitar o Cloud Marketplace para monetizar apps, insights ou modelos. Isso também é parecido com a forma como os conjuntos de dados públicos do BigQuery são gerenciados em uma troca gerenciada pelo Google. Promova a inovação com acesso a conjuntos de dados exclusivos do Google, conjuntos de dados comerciais/do setor, conjuntos de dados públicos ou trocas de dados selecionadas da sua organização ou ecossistema de parceiros.
Como lidar com o legado
Embora pareça ótimo criar uma plataforma de dados totalmente nova do zero, entendemos que nem toda empresa vai conseguir fazer isso. A maioria lida com sistemas legados que precisam migrar, fazer a portabilidade ou aplicar patches até que possam ser substituídos. Trabalhamos com os clientes em todas as etapas da jornada deles na plataforma de dados e temos soluções para atender à sua situação.
Geralmente, há três categorias de migração que observamos entre os clientes: migração lift-and-re-platform, lift-and-rehome e modernização completa. Para a maioria das empresas, sugerimos começar com a migração lift-and-re-platform, porque esse tipo de migração proporciona uma migração de alto impacto com o mínimo de interrupções e riscos possível. Com essa estratégia, você migra seus dados de data warehouses legados e clusters do Hadoop para o BigQuery ou o Serviço Gerenciado para Apache Spark. Depois que os dados são movidos, é possível otimizar os pipelines e as consultas de dados para melhorar o desempenho. Com uma estratégia de migração lift-and-shift, é possível fazer isso em fases, com base na complexidade das suas cargas de trabalho. Recomendamos essa abordagem para clientes corporativos de grande porte com TI centralizada e várias unidades de negócios, dada a complexidade.
A segunda estratégia de migração que vemos com mais frequência é a modernização completa da primeira etapa. Isso proporciona uma pausa no passado, porque você está aproveitando tudo ao máximo com uma abordagem nativa da nuvem. Ele é criado de maneira nativa no Google Cloud, mas como você muda tudo de uma só vez, a migração poderá ser mais lenta se você tiver vários ambientes legados grandes.

Uma quebra de legado limpa requer a reescrita de jobs e a alteração de diferentes aplicativos. No entanto, ele oferece maior velocidade e agilidade e o menor custo total de propriedade a longo prazo em comparação com outras abordagens. Isso se deve a dois motivos principais: seus aplicativos já estão otimizados e não precisam ser adaptados e, depois de migrar suas fontes de dados, você não precisa gerenciar dois ambientes ao mesmo tempo. Essa abordagem é mais adequada para nativos digitais ou organizações orientadas por engenharia com poucos ambientes legados.
Por último, a abordagem mais conservadora é a migração lift-and-rehome, que é uma solução tática de curto prazo para mover seus dados para a nuvem. É possível migrar as plataformas atuais e continuar usando-as como antes, mas no ambiente do Google Cloud. Isso se aplica a ambientes como Teradata e Databricks, por exemplo, para reduzir o risco inicial e permitir a execução de aplicativos. No entanto, isso traz o ambiente isolado atual para a nuvem em vez de transformá-lo. Assim, você não se beneficiará do desempenho de uma plataforma criada de forma nativa no Google Cloud. No entanto, podemos ajudar você com a migração completa para os produtos nativos do Google Cloud, para que aproveite a interoperabilidade e crie uma plataforma de dados de análise totalmente moderna no Google Cloud.
Tática ou estratégico?
Acreditamos que os principais diferenciais de uma plataforma de dados analítico criada no Google Cloud são que ela é aberta, inteligente, flexível e totalmente integrada. Existem muitas soluções no mercado que oferecem soluções táticas confortáveis e conhecidas. No entanto, eles geralmente fornecem uma solução de curto prazo e apenas a combinação de problemas técnicos e organizacionais com o tempo.
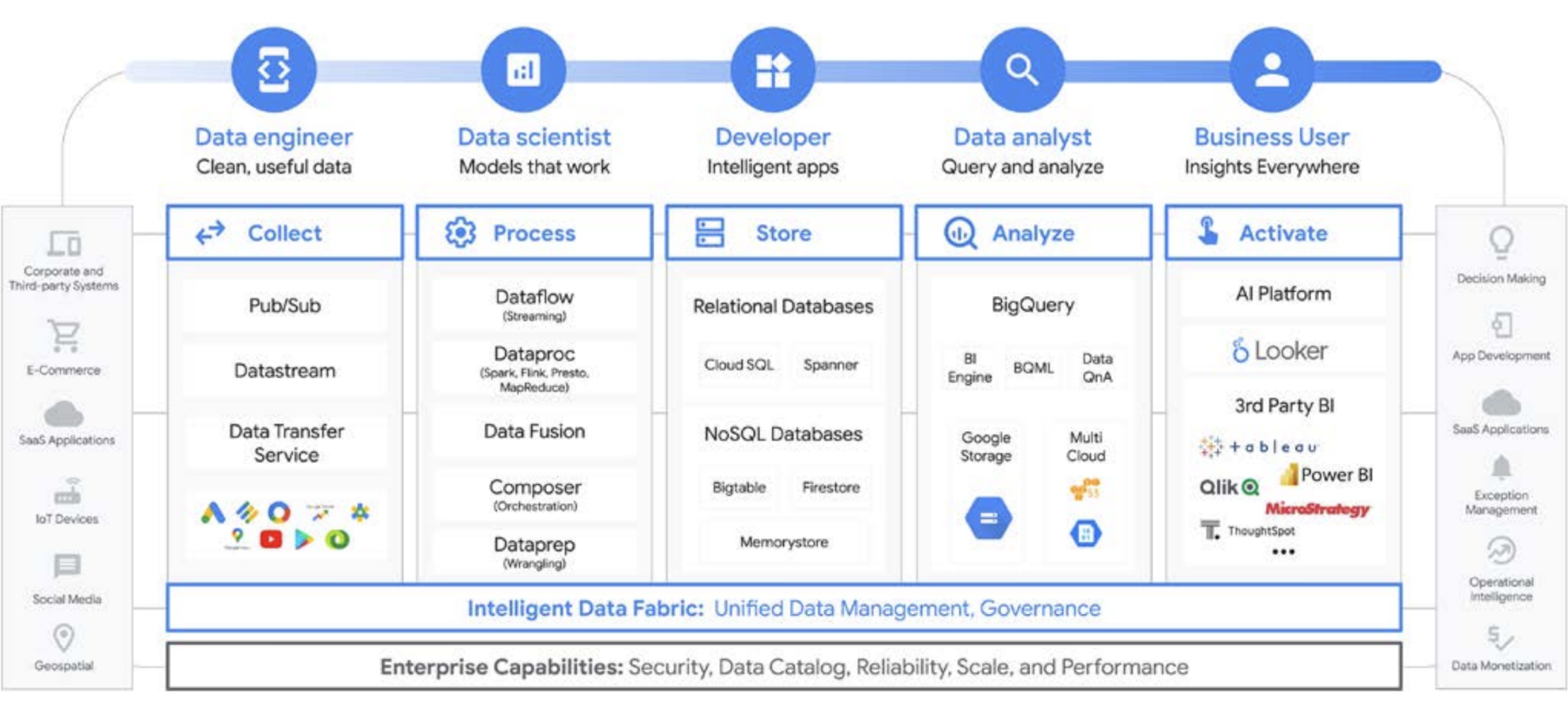
O Google Cloud simplifica significativamente a análise de dados. Desbloqueie o potencial oculto dos seus dados com uma abordagem nativa da nuvem e sem servidor que separa o armazenamento da computação e permite analisar de gigabytes a petabytes de dados em minutos. Isso permite que você remova as restrições tradicionais de escala, desempenho e custo para fazer qualquer pergunta sobre dados e resolver problemas de negócios. Como resultado, é mais fácil operacionalizar insights em toda a empresa com uma malha de dados única e confiável.
Quais são as vantagens?
- Foco puramente na análise, não na infraestrutura
- Soluções para todas as etapas do ciclo de vida da análise de dados, desde a ingestão até a transformação e análise, até o Business Intelligence e muito mais
- Cria uma base de dados sólida para operacionalizar o machine learning.
- Permite que a organização aproveite as melhores tecnologias de código aberto
- Escalonamento para atender às necessidades da sua empresa, especialmente à medida que você aumenta o uso de dados para conduzir seus negócios e a transformação digital
Uma plataforma de dados de análise unificada e moderna criada no Google Cloud oferece os melhores recursos de um data lake e um data warehouse, mas com maior integração à AI Platform. É possível processar automaticamente dados em tempo real de bilhões de eventos de streaming e exibir insights em até milissegundos para responder às mudanças nas necessidades dos clientes. Nossos serviços de IA líderes do setor podem otimizar a tomada de decisões organizacionais e as experiências do cliente, ajudando você a preencher a lacuna entre a análise descritiva e a prescritiva sem precisar formar uma nova equipe. É possível aprimorar suas habilidades atuais para escalonar o impacto da IA com inteligência automatizada e integrada.
Vá além
Quer saber mais sobre como a plataforma de dados do Google pode transformar a maneira como sua empresa lida com dados? Entre em contato conosco para começar.
Precisa de ajuda para começar?
Entre em contato com a equipe de vendasTrabalhe com um parceiro confiável
Encontre um parceiroContinue navegando
Ver todos os produtos











