Membangun platform data analisis modern yang terpadu dengan Google Cloud
Pelajari poin-poin keputusan yang diperlukan dalam membuat platform data analisis modern yang terpadu dan dibangun di Google Cloud.
Penulis: Firat Tekiner dan Susan Pierce

Ringkasan
Tidak ada kekurangan data yang dibuat. Riset IDC menunjukkan bahwa data di seluruh dunia akan bertambah menjadi 175 zettabyte pada tahun 20251. Volume data yang dihasilkan setiap hari sungguh mengejutkan, dan semakin sulit bagi perusahaan untuk mengumpulkan, menyimpan, dan mengaturnya dengan cara yang dapat diakses dan digunakan. Faktanya, 90% profesional data mengatakan bahwa pekerjaan mereka terhambat oleh sumber data yang tidak dapat diandalkan. Sekitar 86% analis data kesulitan dengan data yang sudah tidak berlaku, dan lebih dari 60% pekerja data terdampak karena harus menunggu resource engineering setiap bulan selagi data mereka dibersihkan dan disiapkan2.
Struktur organisasi dan keputusan arsitektur yang tidak efisien berkontribusi pada kesenjangan yang dimiliki perusahaan antara menggabungkan data dan menjadikannya bermanfaat bagi mereka. Banyak perusahaan ingin beralih ke cloud untuk memodernisasi sistem analisis data mereka, tetapi hal tersebut tidak menyelesaikan masalah mendasar seputar sumber data yang terpisah-pisah dan pipeline pemrosesan yang rapuh. Keputusan strategis seputar kepemilikan data dan keputusan teknis tentang mekanisme penyimpanan harus dibuat secara holistik untuk membuat platform data lebih sukses bagi organisasi Anda.
Dalam artikel ini, kita akan membahas poin-poin keputusan yang diperlukan dalam membuat platform data analisis modern yang terpadu dan dibangun di Google Cloud.
Big data telah menciptakan peluang luar biasa bagi bisnis selama dua dekade terakhir. Namun, sulit bagi organisasi untuk menyajikan data yang relevan, dapat ditindaklanjuti, dan tepat waktu kepada pengguna bisnis mereka. Riset menunjukkan bahwa 86% analis masih kesulitan dengan data usang3 dan hanya 32% perusahaan yang merasa telah mewujudkan nilai nyata dari data mereka4. Masalah pertama adalah keaktualan data. Masalah kedua berasal dari kesulitan dalam mengintegrasikan sistem yang berbeda dan sistem lama di silo. Organisasi bermigrasi ke cloud, tetapi hal tersebut tidak menyelesaikan masalah sebenarnya dari sistem lama yang mungkin disusun secara vertikal untuk memenuhi kebutuhan satu unit bisnis.
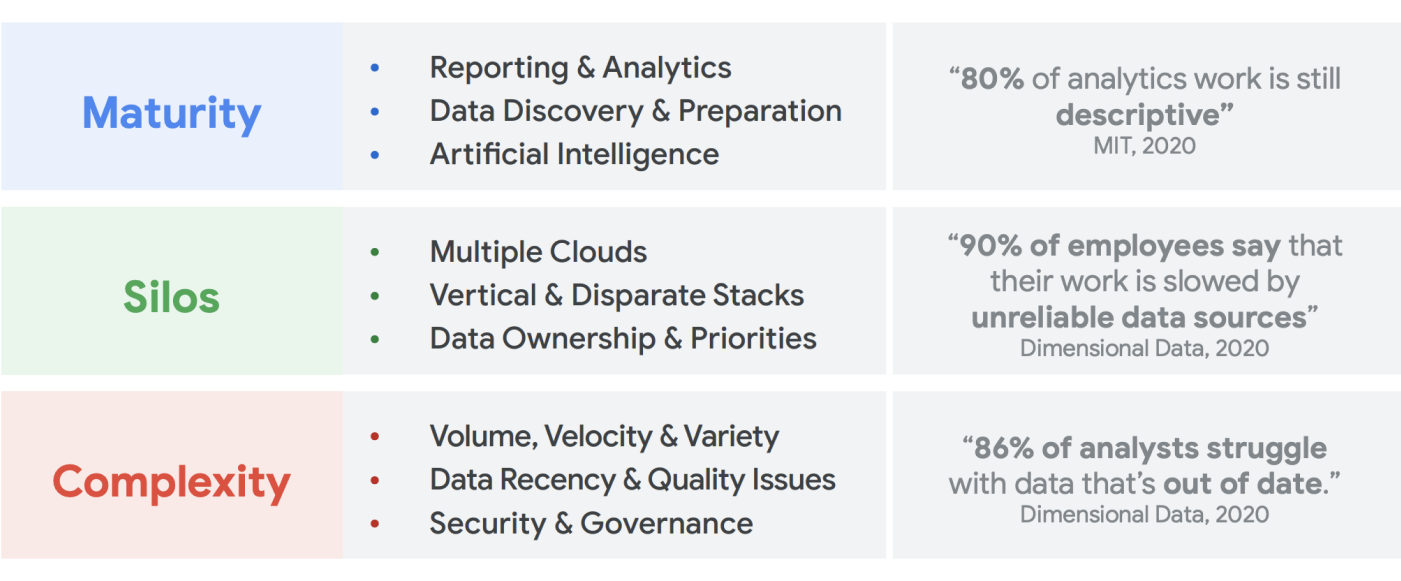
Dalam merencanakan kebutuhan data organisasi, mudah untuk menggeneralisasi secara berlebihan dan mempertimbangkan struktur tunggal yang disederhanakan di mana terdapat satu set sumber data yang konsisten, satu data warehouse perusahaan, satu set semantik, dan satu alat untuk business intelligence. Hal itu mungkin dapat digunakan untuk organisasi yang sangat kecil dan sangat terpusat, bahkan dapat berfungsi untuk satu unit bisnis dengan tim IT dan data engineering-nya sendiri yang terintegrasi. Namun dalam praktiknya, tidak ada organisasi yang sederhana dan selalu ada kompleksitas yang tidak terduga terkait penyerapan, pemrosesan, dan/atau penggunaan data yang semakin mempersulit masalah.
Apa yang telah kami lihat setelah berbicara dengan ratusan pelanggan adalah kebutuhan akan pendekatan yang lebih holistik terhadap data dan analisis, sebuah platform yang dapat memenuhi kebutuhan beberapa unit bisnis dan persona pengguna, dengan langkah redundan sesedikit mungkin untuk memproses data. Hal ini bukan hanya sekadar arsitektur atau serangkaian komponen software baru yang perlu dibeli; perusahaan harus mengevaluasi kematangan data secara keseluruhan dan membuat perubahan yang sistematis dan organisatoris selain peningkatan teknis.
Pada akhir 2024, 75% perusahaan akan beralih dari menguji coba ke mengoperasionalkan AI, sehingga mendorong peningkatan 5 kali lipat dalam infrastruktur data dan analisis streaming5. Cukup mudah untuk menguji coba AI dengan tim data science yang lengkap, yang bekerja di lingkungan terpisah. Namun, tantangan mendasar yang mencegah insight tersebut dirilis ke dalam sistem produksi adalah friksi organisasi dan arsitektur yang membuat kepemilikan data tetap tersegmentasi. Akibatnya, sebagian besar insight yang dimasukkan ke dalam operasi bisnis organisasi bersifat deskriptif, dan analisis prediktif diturunkan ke ranah tim riset.

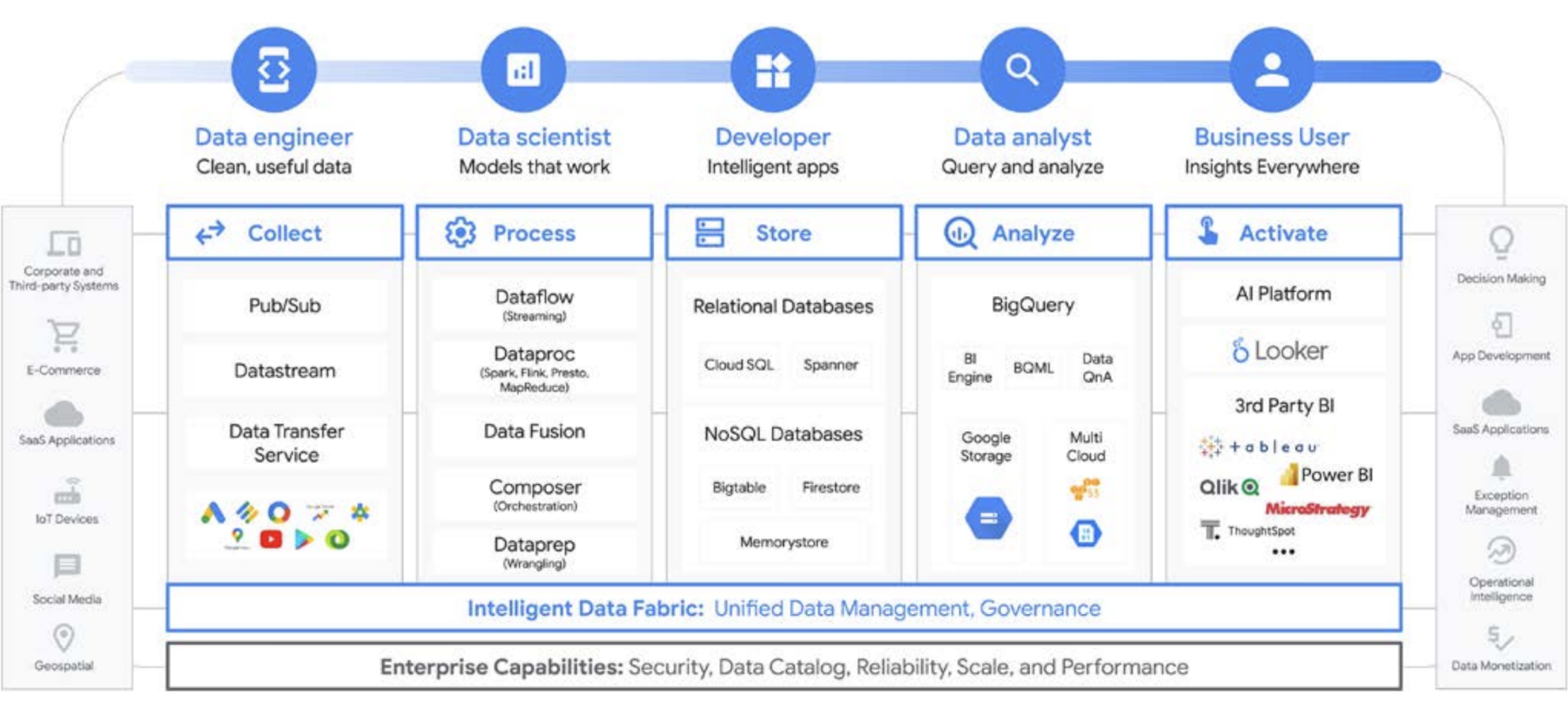
Platform untuk semua pengguna di sepanjang siklus proses data
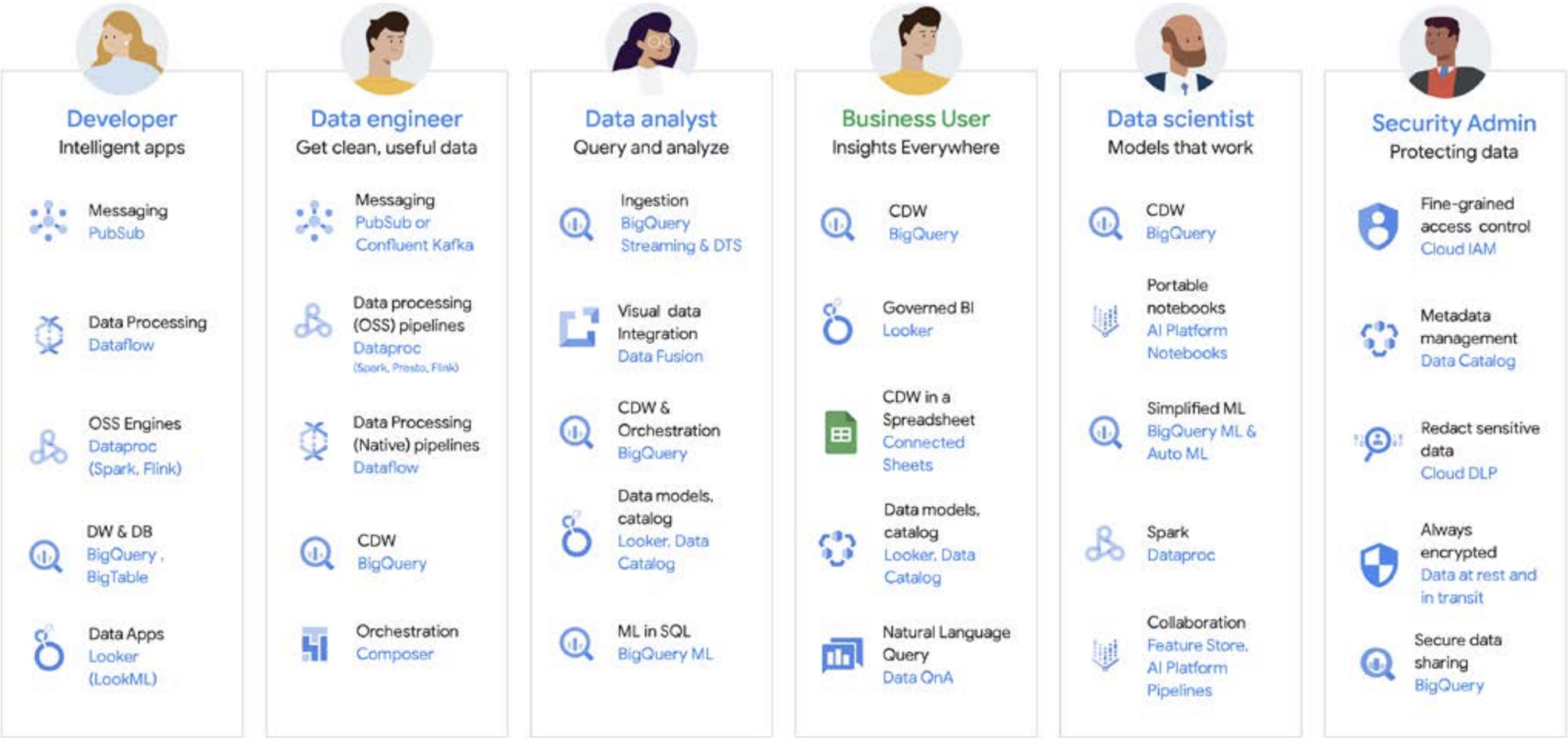
Pekerjaan data jarang dilakukan oleh seorang individu; ada banyak pengguna terkait data dalam sebuah organisasi yang memainkan peran penting dalam siklus proses data. Masing-masing memiliki perspektif yang berbeda terkait tata kelola data, keaktualan, visibilitas, metadata, linimasa pemrosesan, kemampuan kueri, dan lain-lain. Pada umumnya, mereka semua menggunakan sistem dan software yang berbeda untuk beroperasi pada data yang sama, pada tahap pemrosesan yang berbeda.
Sebagai contoh, mari kita lihat siklus proses machine learning. Seorang data engineer mungkin bertanggung jawab untuk memastikan data baru tersedia untuk tim data science, dengan batasan keamanan dan privasi yang sesuai. Seorang data scientist dapat membuat set data pelatihan dan pengujian berdasarkan sekumpulan sumber data terpilih yang telah digabungkan sebelumnya dari data engineer, membangun dan menguji model, serta menyediakan insight untuk tim lain. Seorang engineer ML mungkin bertanggung jawab mengemas model untuk deployment ke dalam sistem produksi dengan cara yang tidak mengganggu pipeline pemrosesan data lainnya. Seorang product manager atau analis bisnis mungkin memeriksa insight yang diperoleh, menggunakan Data QnA (antarmuka bahasa alami untuk analisis pada data BigQuery), software visualisasi, atau mungkin mengkueri hasil yang ditetapkan langsung melalui IDE atau antarmuka command line. Ada banyak sekali pengguna dengan kebutuhan yang berbeda-beda, dan kami telah membangun platform yang terkompresi untuk melayani mereka semua. Google Cloud melayani pelanggan di mana pun mereka berada dengan alat untuk memenuhi kebutuhan bisnis.
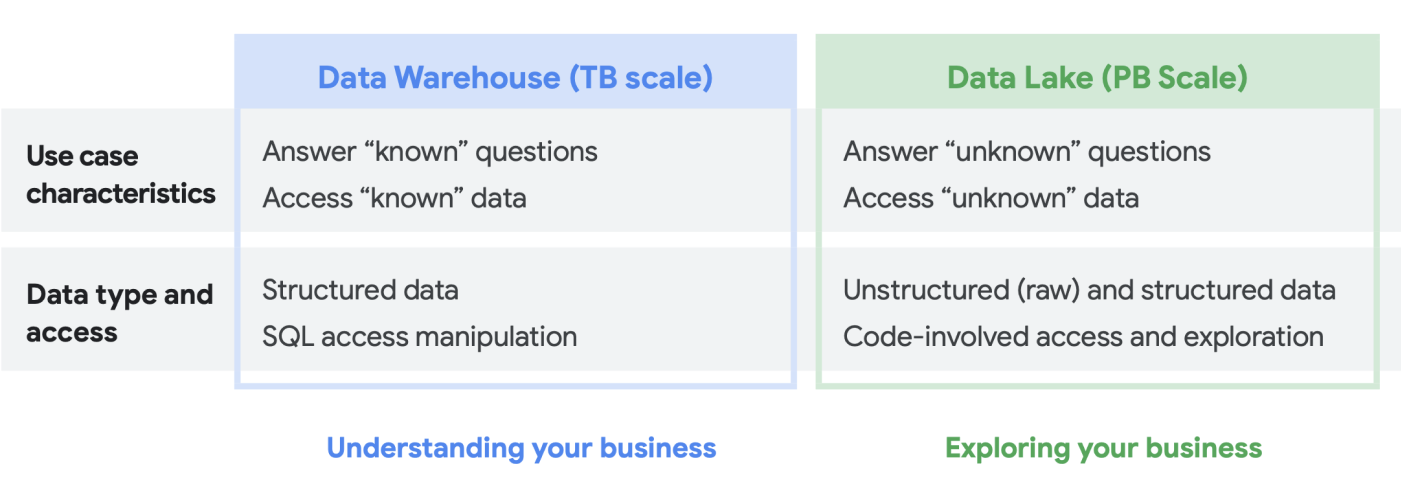
Keputusan big data: data warehouse atau data lake?
Saat berbicara dengan pelanggan tentang kebutuhan analisis data mereka, sering kali kami mendengar pertanyaan, “Mana yang saya perlukan: data lake atau data warehouse?” Mengingat beragam pengguna data dan kebutuhan dalam suatu organisasi, pertanyaan tersebut bisa sulit untuk dijawab karena bergantung pada tujuan penggunaan, jenis data, dan personel.
- Jika Anda tahu set data apa yang perlu dianalisis, memiliki pemahaman yang jelas tentang strukturnya, dan telah mempunyai jawaban atas serangkaian pertanyaan yang diperlukan, maka yang Anda butuhkan adalah data warehouse
- Di sisi lain, jika Anda memerlukan visibilitas di berbagai jenis data, tidak yakin dengan jenis analisis yang perlu dijalankan, mencari peluang untuk mengeksplorasi daripada menyajikan insight, dan memiliki sumber daya untuk mengelola dan mempelajari lingkungan ini secara efektif, maka data lake mungkin akan lebih sesuai dengan kebutuhan Anda
Namun, ada lebih banyak hal terkait keputusan tersebut, jadi mari kita bahas beberapa tantangan organisatoris dari data lake dan data warehouse. Data warehouse sering kali sulit dikelola. Sistem lama yang telah berfungsi dengan baik dalam 40 tahun terakhir terbukti sangat mahal dan menimbulkan banyak tantangan seputar keaktualan data, penskalaan, dan biaya yang tinggi. Selain itu, sistem lama tidak dapat dengan mudah memberikan kemampuan AI atau real-time tanpa mengaktifkan fungsi tersebut setelahnya. Masalah ini tidak hanya ada di data warehouse lama lokal; kami bahkan melihat masalah ini juga terjadi pada data warehouse berbasis cloud yang baru dibuat. Banyak yang tidak menawarkan kemampuan AI terintegrasi, apa pun klaim mereka. Data warehouse baru tersebut pada dasarnya adalah lingkungan lama yang sama, tetapi ditransfer ke cloud. Pengguna data warehouse biasanya adalah analis, yang sering bergabung ke dalam unit bisnis tertentu. Mereka mungkin memiliki ide tentang set data tambahan yang akan berguna untuk memperkaya pemahaman mereka tentang bisnis. Mereka mungkin memiliki ide untuk peningkatan analisis, pemrosesan data, dan persyaratan untuk fungsi business intelligence.
Namun, dalam organisasi tradisional, mereka sering kali tidak memiliki akses langsung ke pemilik data, serta tidak dapat dengan mudah memengaruhi pengambil keputusan teknis yang memutuskan set data dan alat. Selain itu, karena tidak memiliki akses ke data mentah, mereka tidak dapat menguji hipotesis atau mendorong pemahaman yang lebih mendalam tentang data yang mendasarinya. Data lake memiliki tantangannya sendiri. Secara teoretis, data lake murah dan mudah diskalakan, tetapi banyak pelanggan kami melihat fakta yang berbeda pada data lake lokal mereka. Merencanakan dan menyediakan penyimpanan yang cukup bisa memakan biaya tinggi dan sulit dilakukan, terutama bagi organisasi yang menghasilkan data dalam jumlah yang sangat bervariasi. Data lake lokal bisa bersifat rapuh, dan pemeliharaan sistem yang ada memerlukan waktu. Dalam banyak kasus, para engineer yang seharusnya mengembangkan fitur baru pada akhirnya diturunkan ke perawatan dan pengumpanan cluster data. Lebih jelas lagi, mereka mempertahankan nilai, bukan menciptakan nilai baru. Secara keseluruhan, total biaya kepemilikan lebih tinggi daripada yang diharapkan untuk banyak perusahaan. Tidak hanya itu, tata kelola tidak mudah diselesaikan di seluruh sistem, terutama ketika berbagai bagian organisasi menggunakan model keamanan yang berbeda. Akibatnya, data lake menjadi terpisah dan tersegmentasi, sehingga sulit untuk berbagi data dan model antartim.
Pengguna data lake biasanya lebih dekat dengan sumber data mentah serta dilengkapi dengan alat dan kemampuan untuk mengeksplorasi data. Dalam organisasi tradisional, pengguna data lake cenderung berfokus pada data itu sendiri dan sering kali tidak terlibat dalam bagian lain di dalam organisasi tersebut. Terputusnya hubungan ini berarti bahwa unit bisnis kehilangan peluang untuk menemukan insight yang akan memajukan tujuan bisnis mereka dalam mencapai pendapatan yang lebih tinggi, biaya yang lebih rendah, risiko yang lebih kecil, serta peluang-peluang baru. Mengingat konsekuensi ini, banyak perusahaan akhirnya memilih pendekatan hybrid, di mana data lake disiapkan untuk meneruskan beberapa data ke data warehouse atau data warehouse memiliki data lake sampingan untuk pengujian dan analisis tambahan. Namun, dengan banyaknya tim yang membuat arsitektur data mereka sendiri agar sesuai dengan kebutuhan masing-masing, pembagian data dan fidelitas menjadi lebih rumit bagi tim IT pusat. Alih-alih memiliki tim terpisah dengan sasaran terpisah—di mana satu tim mengeksplorasi bisnis, dan tim yang lainnya memahami bisnis—Anda dapat menyatukan fungsi-fungsi tersebut dengan sistem data mereka untuk menciptakan siklus yang menguntungkan di mana pemahaman yang lebih mendalam tentang bisnis mendorong eksplorasi yang terarah, dan eksplorasi itu mendorong pemahaman bisnis yang lebih baik.
Memperlakukan penyimpanan data warehouse seperti data lake
Anda dapat membangun data warehouse atau data lake secara terpisah di Google Cloud, tetapi Anda tidak harus memilih salah satunya. Dalam banyak kasus, produk pokok yang digunakan pelanggan kami sama untuk keduanya, dan satu-satunya perbedaan antara penerapan data lake dan data warehouse mereka adalah kebijakan akses data yang diterapkan. Faktanya, kedua istilah tersebut mulai menyatu menjadi satu set fungsi yang lebih terpadu, sebuah platform data analisis modern. Mari kita lihat cara kerjanya di Google Cloud.
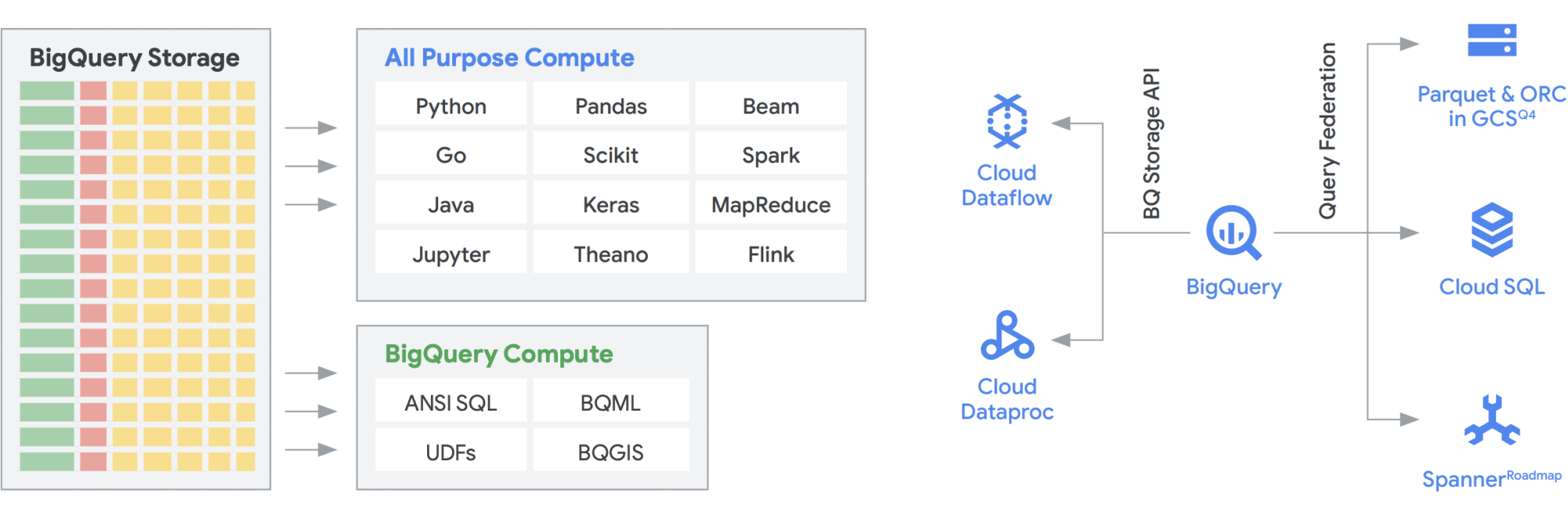
BigQuery Storage API memberikan kemampuan menggunakan BigQuery Storage, seperti Cloud Storage, untuk sejumlah sistem lain seperti Dataflow dan Managed Service untuk Apache Spark. BigQuery Storage API memungkinkan peniadaan dinding penyimpanan data warehouse dan menjalankan frame data berperforma tinggi di BigQuery. Dengan kata lain, BigQuery Storage API memungkinkan data warehouse BigQuery Anda berfungsi seperti data lake. Jadi, apa saja kegunaan praktisnya? Salah satunya, kami membuat serangkaian konektor, misalnya MapReduce, Hive, Spark, sehingga Anda dapat menjalankan workload Hadoop dan Spark langsung pada data Anda di BigQuery. Anda tidak lagi memerlukan data lake selain data warehouse Anda. Dataflow sangat canggih untuk batch dan stream processing. Saat ini, Anda dapat menjalankan tugas Dataflow di atas data BigQuery, memperkayanya dengan data dari Pub/Sub, Spanner, atau sumber data lainnya.
BigQuery dapat menskalakan penyimpanan maupun komputasi secara independen, dan masing-masing bersifat serverless, sehingga memungkinkan penskalaan tanpa batas untuk memenuhi permintaan, terlepas dari penggunaan oleh tim, alat, dan pola akses yang berbeda. Semua aplikasi di atas dapat berjalan tanpa memengaruhi performa tugas lain yang mengakses BigQuery pada saat bersamaan. Selain itu, BigQuery Storage API menyediakan jaringan level petabit, yang memindahkan data antar-node untuk memenuhi permintaan kueri secara efektif sehingga menghasilkan performa yang serupa dengan operasi dalam memori. BigQuery Storage API juga memungkinkan federasi dengan format data Hadoop populer, seperti Parquet dan ORC, secara langsung serta database NoSQL dan OLTP. Anda dapat melangkah lebih jauh dengan kemampuan yang disediakan oleh Dataflow SQL, yang disematkan dalam BigQuery. Hal ini membuat Anda dapat menggabungkan streaming dengan tabel BigQuery atau data yang berada dalam file, sehingga menciptakan arsitektur lambda secara efektif yang memungkinkan Anda dapat menyerap data batch dan streaming dalam jumlah besar, sekaligus menyediakan lapisan layanan untuk merespons kueri. BigQuery BI Engine dan tampilan terwujud mempermudah peningkatan efisiensi dan performa dalam arsitektur multiguna ini.
Platform analisis smart Google yang didukung oleh BigQuery
Solusi data serverless benar-benar diperlukan agar organisasi Anda dapat bergerak melampaui data silo dan masuk ke ranah insight serta tindakan. Semua layanan analisis data inti kami serverless dan terintegrasi erat.

Manajemen perubahan sering kali menjadi salah satu aspek tersulit dalam memasukkan teknologi baru ke dalam organisasi. Google Cloud berupaya menjangkau pelanggan kami di mana pun mereka berada dengan menyediakan alat, platform, dan integrasi yang familier bagi developer dan pengguna bisnis. Misi kami adalah mempercepat kemampuan organisasi Anda dalam mentransformasi dan menata ulang bisnis secara digital melalui inovasi yang didukung data, bersama-sama. Alih-alih membatasi vendor, Google Cloud memberikan opsi bagi perusahaan untuk melakukan integrasi yang sederhana dan efisien dengan lingkungan lokal, penawaran cloud lainnya, dan bahkan Edge untuk membentuk hybrid cloud yang sesungguhnya:
- BigQuery Omni tidak memerlukan pemindahan data dari satu lingkungan ke lingkungan lainnya dan melakukan analisis terhadap data, apa pun lingkungannya
- Apache Beam, SDK yang dimanfaatkan pada Dataflow, memberikan kemampuan transfer dan portabilitas bagi runner seperti Apache Spark dan Apache Flink
- Untuk organisasi yang ingin menjalankan Apache Spark atau Apache Hadoop, Google Cloud menyediakan Managed Service untuk Apache Spark
Sebagian besar pengguna data memikirkan data yang mereka miliki, bukan sistem tempat data berada. Hal yang paling penting adalah memiliki akses ke data yang dibutuhkan saat data tersebut dibutuhkan. Jadi, secara umum, jenis platform tidak menjadi masalah bagi pengguna, selama mereka dapat mengakses data baru yang dapat digunakan dengan alat yang familier, baik menjelajahi set data, mengelola sumber di seluruh penyimpanan data, menjalankan kueri ad hoc, atau mengembangkan alat business intelligence internal untuk pemangku kepentingan eksekutif.
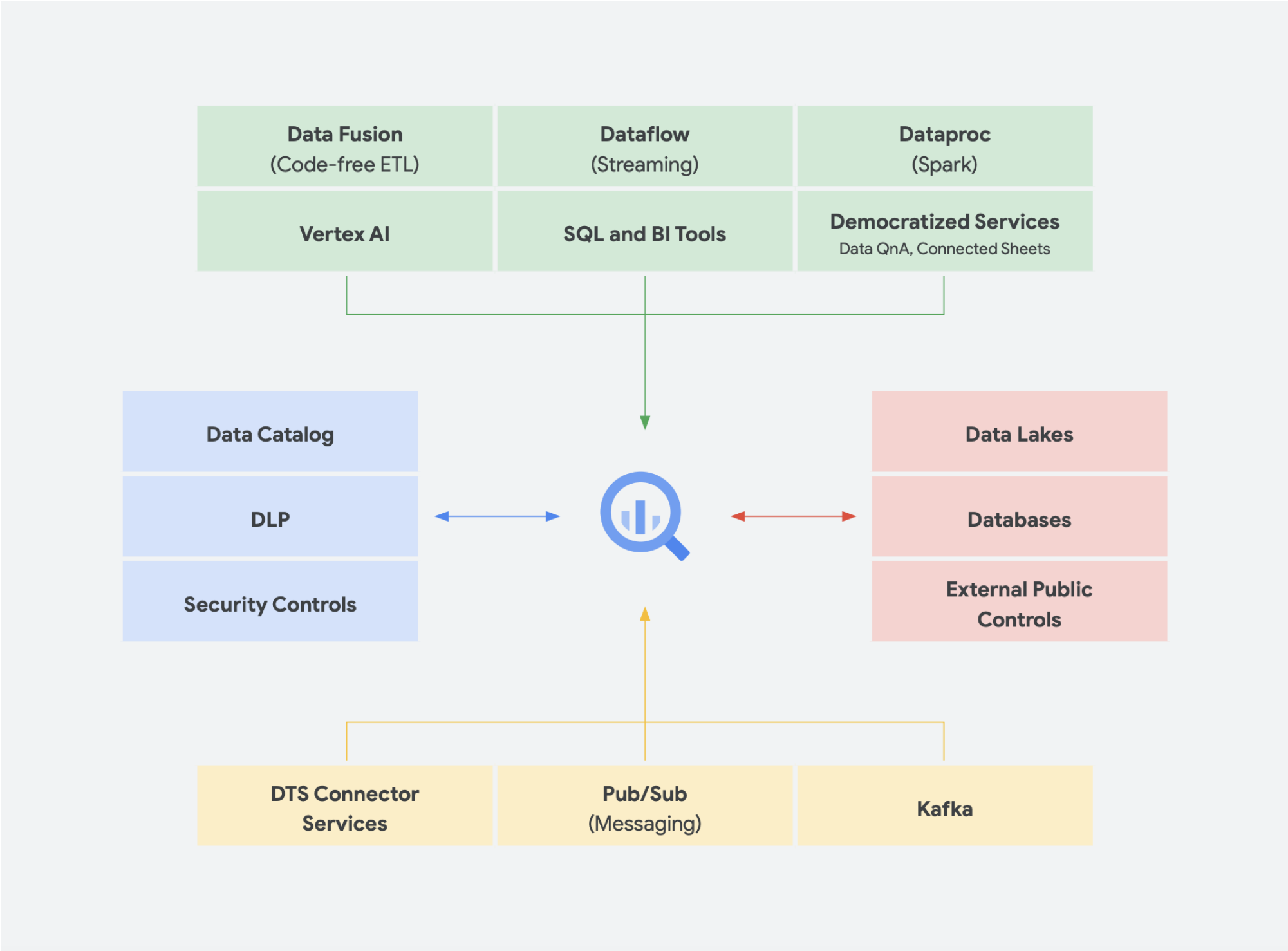
Tren baru
Melanjutkan soal gagasan tentang konvergensi data lake dan data warehouse menjadi platform data analisis terpadu, ada beberapa solusi data tambahan yang semakin diterima luas. Kami telah melihat banyak konsep yang muncul, misalnya seputar lakehouse dan mesh data. Anda mungkin pernah mendengar beberapa istilah ini sebelumnya. Beberapa di antaranya bukanlah hal baru dan telah ada dalam berbagai bentuk dan format selama bertahun-tahun. Namun, keduanya berfungsi dengan sangat baik dalam lingkungan Google Cloud. Mari kita lihat lebih dekat bagaimana mesh data dan lakehouse terlihat di Google Cloud serta apa arti keduanya dalam berbagi data dalam suatu organisasi. Lakehouse dan mesh data tidak saling eksklusif, tetapi membantu memecahkan berbagai tantangan dalam suatu organisasi. Tetapi yang satu mendukung pengaktifan data, sementara yang lainnya mengaktifkan tim. Dengan mesh data, pengguna dapat menghindari hambatan oleh satu tim, sehingga memungkinkan keseluruhan stack data. Mesh data memecah silo menjadi unit-unit organisasi yang lebih kecil dalam arsitektur yang mampu memberikan akses ke data secara terfederasi. Lakehouse menyatukan data warehouse dan data lake, sehingga memungkinkan berbagai jenis data dan volume data yang lebih tinggi. Hal ini secara efektif menghasilkan schema-on-read, bukan schema-on-write, sebuah fitur data lake yang dianggap dapat mengatasi beberapa kesenjangan performa di data warehouse perusahaan. Sebagai manfaat tambahan, arsitektur ini juga menggunakan tata kelola data yang lebih ketat, yang biasanya tidak dimiliki oleh data lake.

Lakehouse
Seperti disebutkan di atas, Storage API BigQuery memungkinkan Anda memperlakukan data warehouse seperti data lake. Tugas Spark yang berjalan di Managed Service untuk Apache Spark atau lingkungan Hadoop serupa dapat menggunakan data yang disimpan di BigQuery, daripada memerlukan media penyimpanan terpisah dengan membuat penyimpanan dari data warehouse. Keunggulan komputasi yang terpisah dari penyimpanan dalam BigQuery memungkinkan transformasi berbasis SQL dan memanfaatkan tampilan di berbagai lapisan transformasi ini. Hal ini kemudian menghasilkan pendekatan jenis ELT dan memungkinkan platform pemrosesan data yang lebih tangkas. Dengan memanfaatkan ELT daripada ETL, BigQuery memungkinkan transformasi berbasis SQL disimpan sebagai tampilan logis. Meskipun membuang semua data mentah ke penyimpanan data warehouse mungkin mahal dengan data warehouse tradisional, tidak ada biaya premi untuk penyimpanan BigQuery. Biayanya cukup sebanding dengan penyimpanan blob di Google Cloud Storage.
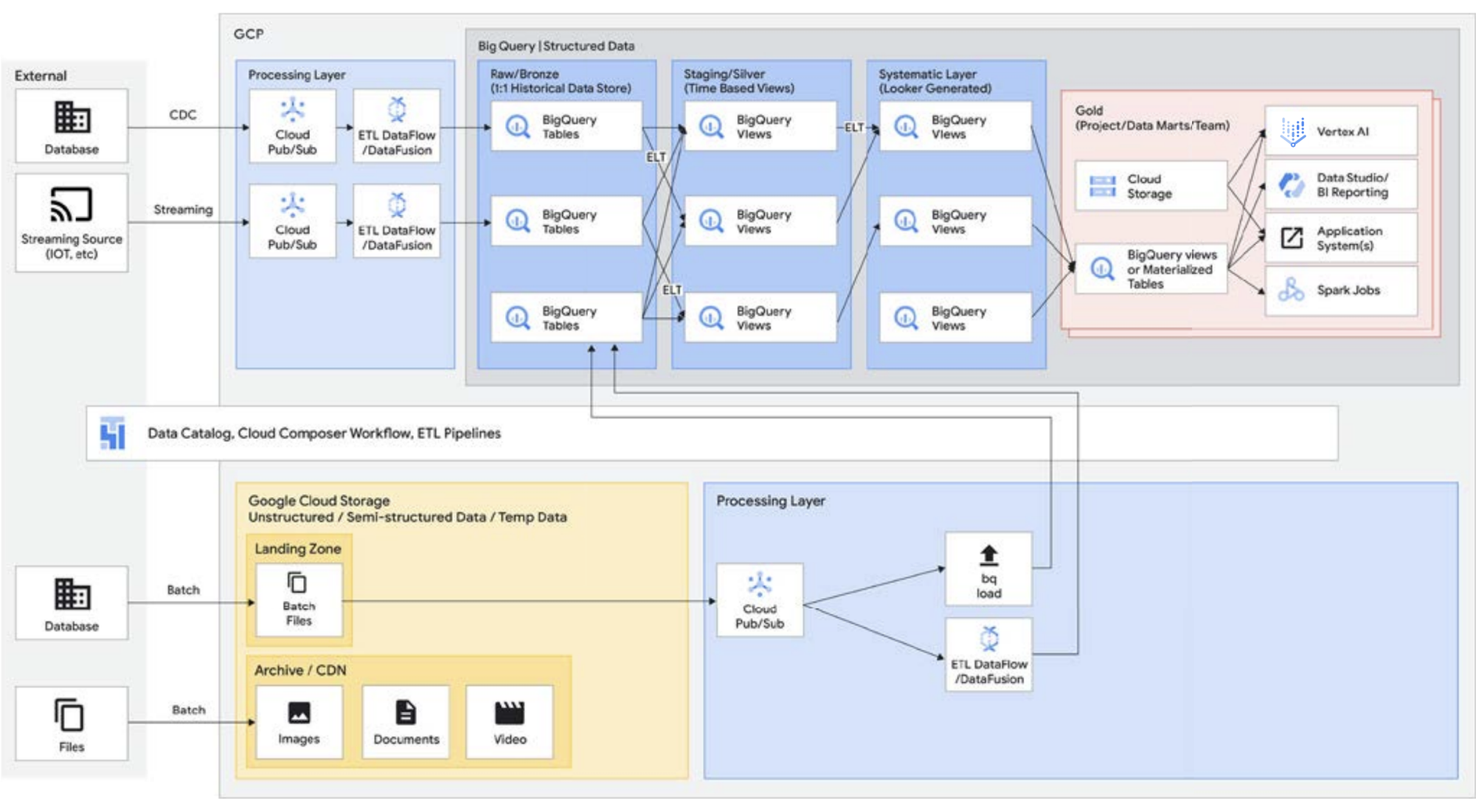
Saat melakukan ETL, transformasi terjadi di luar BigQuery, kemungkinan di alat yang tidak diskalakan juga. Hal ini pada akhirnya mungkin akan mengubah data baris demi baris, bukan memparalelkan kueri. Ada kalanya Spark atau proses ETL lainnya sudah dikodifikasi, dan mengubahnya demi teknologi baru mungkin tidak masuk akal. Namun, jika ada transformasi yang dapat ditulis dalam SQL, BigQuery kemungkinan besar merupakan tempat yang tepat untuk melakukannya.
Selain itu, arsitektur ini didukung oleh semua komponen Google Cloud, seperti Managed Service untuk Apache Airflow, Data Catalog, atau Data Fusion. Arsitektur ini menyediakan lapisan end-to-end untuk persona pengguna yang berbeda. Aspek penting lainnya untuk mengurangi overhead operasional dapat dilakukan dengan memanfaatkan kemampuan infrastruktur yang mendasari. Pertimbangkan Dataflow dan BigQuery, semuanya dijalankan di container dan memungkinkan kami mengelola waktu beroperasi dan mekanisme di balik layar. Setelah diluncurkan ke alat pihak ketiga dan partner, dan saat mereka mulai mempelajari kemampuan serupa seperti Kubernetes, arsitektur ini akan menjadi jauh lebih mudah untuk dikelola dan portabel. Pada akhirnya, arsitektur ini mengurangi overhead operasional dan resource. Selain itu, arsitektur ini dapat dilengkapi dengan kemampuan observasi yang lebih baik dengan memanfaatkan dasbor pemantauan dengan Managed Service untuk Apache Airflow untuk menghasilkan keunggulan operasional. Anda tidak hanya dapat membangun data lake dengan menyatukan data yang disimpan di Cloud Storage dan BigQuery, tanpa duplikasi atau pemindahan data, tetapi kami juga menawarkan fungsi administratif tambahan untuk mengelola sumber data Anda. Knowledge Catalog (sebelumnya Dataplex) memungkinkan lakehouse dengan menawarkan lapisan pengelolaan terpusat untuk mengoordinasikan data di Cloud Storage dan BigQuery. Dengan melakukannya, Anda dapat mengatur data berdasarkan kebutuhan bisnis, sehingga Anda tidak lagi dibatasi oleh bagaimana atau di mana data tersebut disimpan.
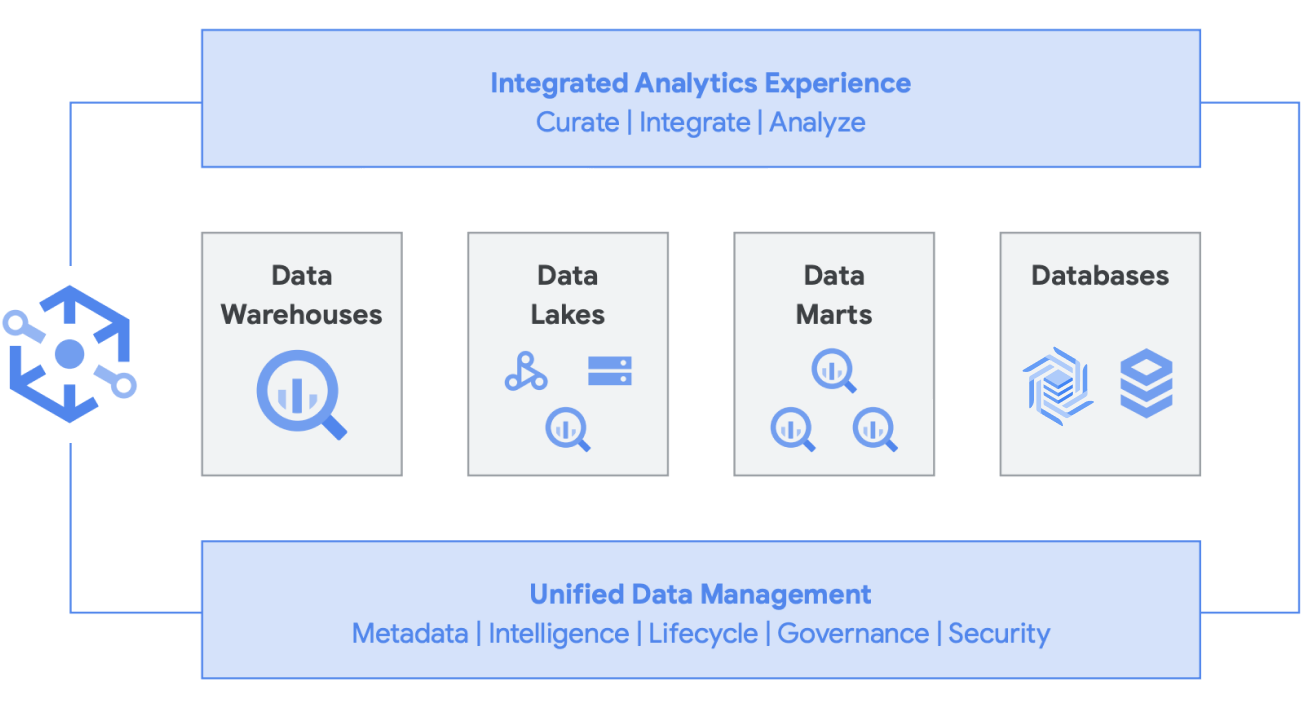
Knowledge Catalog adalah data fabric cerdas yang memungkinkan Anda menyimpan data Anda dengan harga/performa yang tepat sekaligus membuat data ini dapat diakses dengan aman oleh semua alat analisis Anda. Dataplex menyediakan pengelolaan data berbasis metadata dengan kualitas data dan tata kelola bawaan sehingga Anda dapat mengurangi waktu yang dihabiskan untuk mengatasi batasan dan inefisiensi infrastruktur, memercayai data yang Anda miliki, dan menghabiskan lebih banyak waktu untuk mendapatkan nilai dari data ini. Selain itu, Dataplex memberikan pengalaman analisis terintegrasi, yang menyatukan hal-hal terbaik dari Google Cloud dan open source, sehingga Anda dapat dengan cepat menyeleksi, mengamankan, mengintegrasikan, dan menganalisis data dalam skala besar. Terakhir, Anda dapat membangun strategi analisis yang mendukung arsitektur yang ada dan memenuhi sasaran tata kelola keuangan Anda.
Mesh data
Mesh data dibangun berdasarkan sejarah inovasi yang panjang dari berbagai data warehouse dan data lake, yang dikombinasikan dengan model pembayaran berbasis performa skalabilitas yang tak tertandingi, API, DevOps, dan integrasi erat produk-produk Google Cloud. Dengan pendekatan ini, Anda dapat membuat solusi data on demand secara efektif. Mesh data mendesentralisasi kepemilikan data di antara pemilik data domain, yang masing-masing bertanggung jawab untuk menyediakan data mereka sebagai produk dengan cara standar. Mesh data juga memfasilitasi komunikasi antara berbagai bagian organisasi untuk mendistribusikan set data yang terdistribusi di berbagai lokasi. Dalam mesh data, tanggung jawab untuk menghasilkan nilai dari data disematkan kepada orang-orang yang paling memahaminya; dengan kata lain, orang yang membuat data atau membawanya ke dalam organisasi juga harus bertanggung jawab untuk membuat aset data dapat dipakai sebagai produk dari data yang mereka buat. Di banyak organisasi, menetapkan “satu sumber tepercaya” atau “sumber data yang kredibel” sulit dilakukan karena ekstraksi dan transformasi data berulang di seluruh organisasi tanpa tanggung jawab kepemilikan yang jelas atas data yang baru dibuat. Dalam mesh data, sumber data yang kredibel adalah produk data yang dipublikasikan oleh domain sumber, dengan pemilik dan penjaga data yang jelas dan bertanggung jawab atas data tersebut.
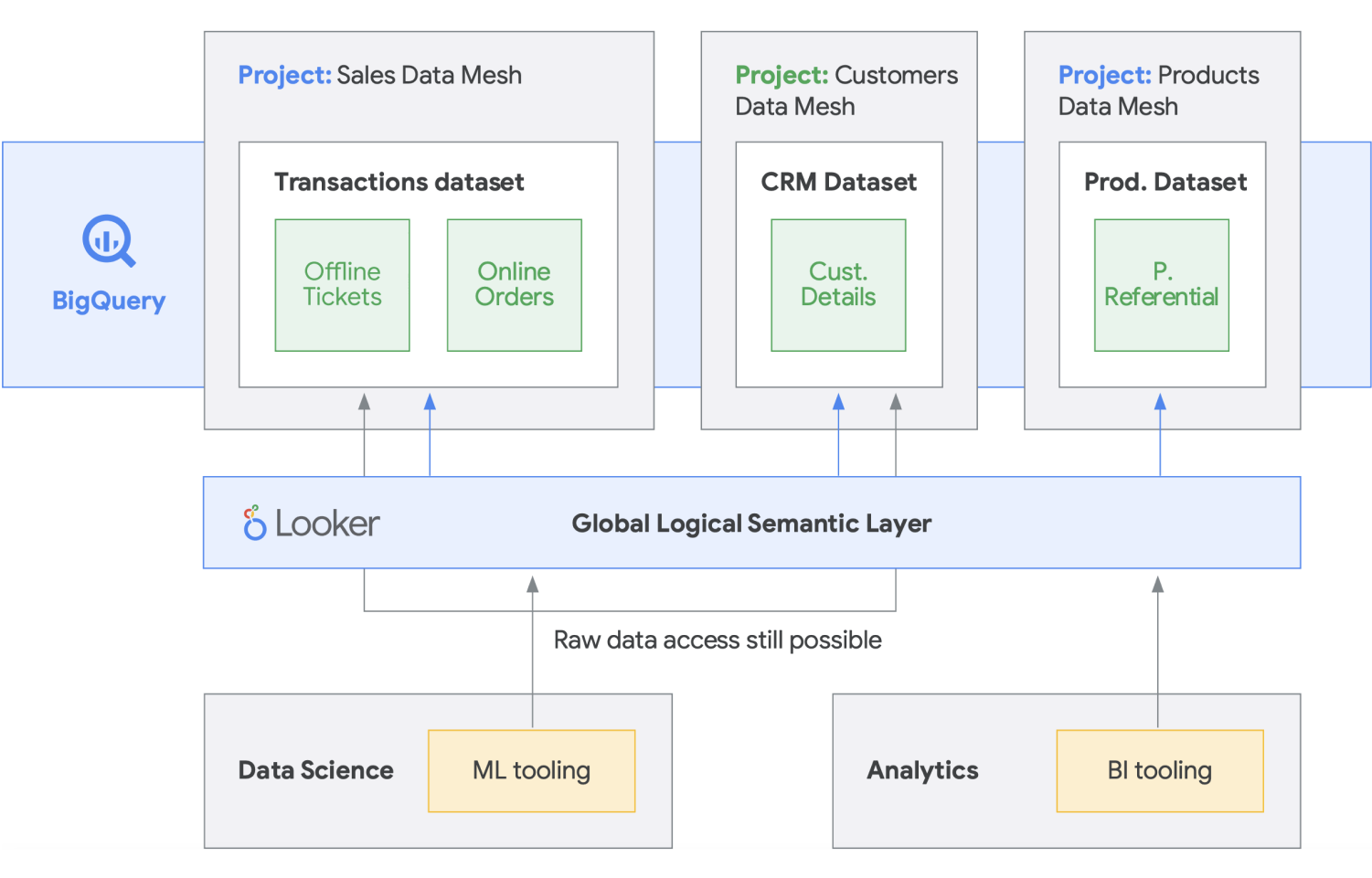
Singkatnya, mesh data menjanjikan kepemilikan dan arsitektur data yang terdesentralisasi dan berorientasi domain. Hal ini dimungkinkan dengan memiliki lapisan komputasi dan akses gabungan seperti yang kami sediakan di Google Cloud. Selain itu, jika organisasi Anda ingin mendapatkan lebih banyak fungsi, Anda dapat menggunakan sesuatu seperti Looker, yang dapat menyediakan lapisan terpadu untuk membuat model dan mengakses data. Platform Looker menawarkan UI panel tunggal untuk mengakses versi yang paling benar dan terkini dari data dan definisi bisnis perusahaan Anda. Dengan tampilan terpadu atas bisnis ini, Anda dapat memilih atau mendesain pengalaman data yang meyakinkan karyawan dan sistem bahwa data dikirimkan kepada mereka dengan cara yang paling sesuai dengan kebutuhan mereka. Ini sangat cocok karena memungkinkan ilmuwan data, analis, dan bahkan pengguna bisnis untuk mengakses data mereka dengan satu model semantik. Data scientist masih mengakses data mentah, tetapi tanpa pemindahan dan duplikasi data.
Kami sedang membangun fungsi tambahan pada produk kerja keras kami seperti BigQuery, untuk mempermudah pembuatan dan pengelolaan set data. Analytics Hub menyediakan kemampuan untuk membuat pertukaran data pribadi, di mana administrator bursa (kurator data alias) memberikan izin untuk memublikasikan dan berlangganan data dalam pertukaran untuk individu atau grup tertentu baik di dalam perusahaan maupun secara eksternal untuk partner bisnis atau pembeli.
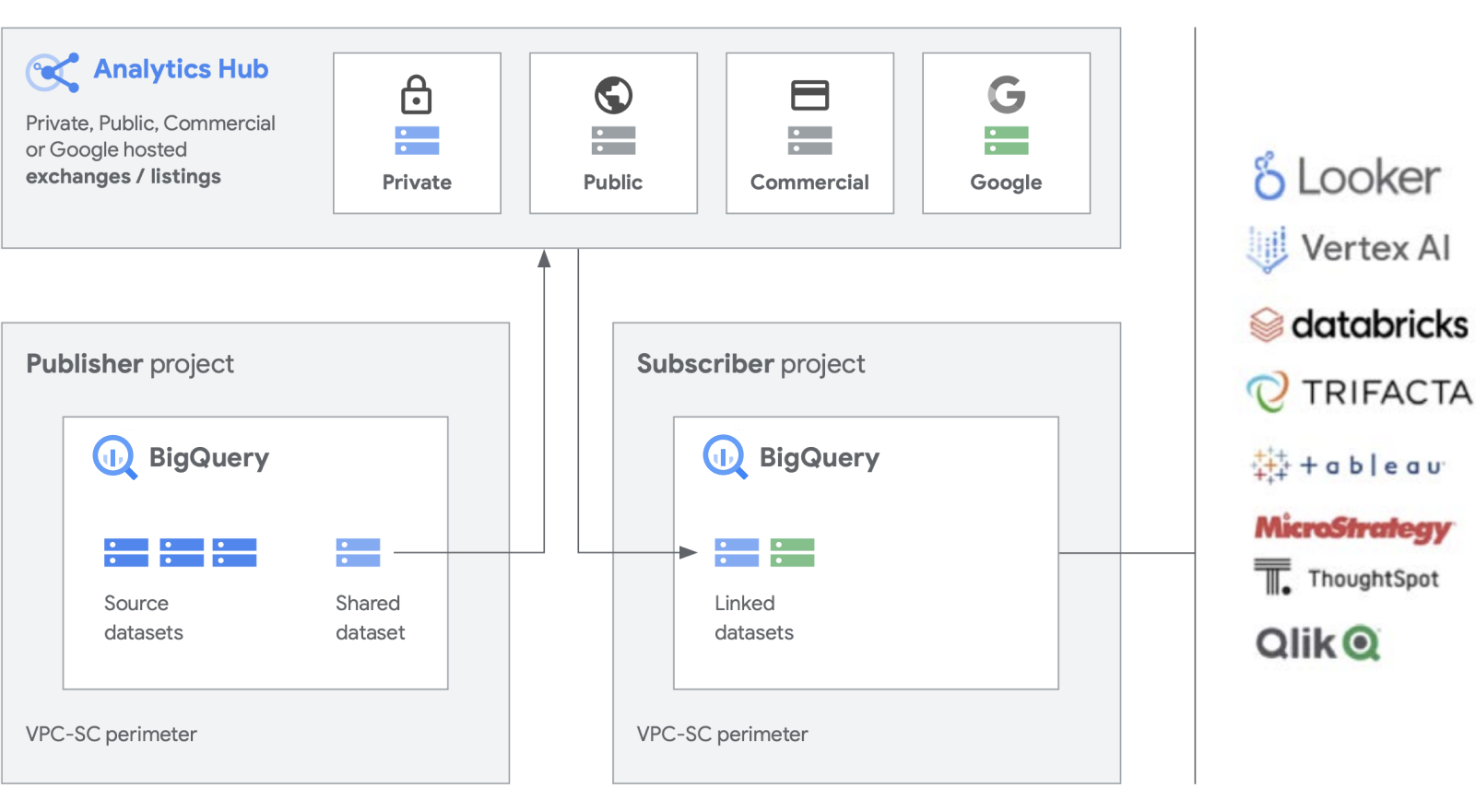
Memublikasikan, menemukan, dan berlangganan aset bersama, termasuk format open source, yang didukung oleh skalabilitas BigQuery. Penayang dapat melihat metrik penggunaan gabungan. Penyedia data dapat menjangkau pelanggan BigQuery perusahaan dengan data, insight, model ML, atau visualisasi, serta memanfaatkan Cloud Marketplace untuk memonetisasi aplikasi, insight, atau model mereka. Hal ini juga mirip dengan cara set data publik BigQuery dikelola melalui bursa yang dikelola Google. Dorong inovasi dengan akses ke set data Google yang unik, set data komersial/industri, set data publik, atau pertukaran data pilihan dari organisasi atau ekosistem partner Anda.
Menangani sistem lama
Meskipun membangun platform data baru dari awal adalah hal yang bagus, kami memahami bahwa tidak semua perusahaan dapat melakukannya. Sebagian besar kasus tersebut berurusan dengan sistem lama yang sudah ada dan perlu dimigrasikan, ditransfer, atau di-patch hingga sistem tersebut dapat diganti. Kami telah bekerja sama dengan pelanggan di setiap tahap perjalanan platform data mereka dan kami memiliki solusi untuk memenuhi situasi Anda.
Biasanya ada tiga kategori migrasi yang kami lihat di kalangan pelanggan: lift-and-replatform, lift-and-rehome, dan modernisasi penuh. Untuk sebagian besar bisnis, sebaiknya mulai dengan lift-and-replatform, karena menawarkan migrasi berdampak tinggi dengan gangguan dan risiko seminimal mungkin. Dengan strategi ini, Anda akan memigrasikan data ke BigQuery atau Managed Service untuk Apache Spark dari data warehouse dan cluster Hadoop lama. Setelah data dipindahkan, Anda dapat mengoptimalkan pipeline data dan kueri untuk performa. Dengan strategi migrasi lift-and-replatform, Anda dapat melakukannya secara bertahap, berdasarkan kompleksitas workload Anda. Kami merekomendasikan pendekatan ini untuk pelanggan perusahaan besar dengan IT terpusat dan beberapa unit bisnis, mengingat kompleksitasnya.
Strategi migrasi kedua yang paling sering kita lihat adalah modernisasi penuh sebagai langkah pertama. Hal ini memberikan jeda bersih dari masa lalu karena Anda akan sepenuhnya menggunakan pendekatan berbasis cloud. Modernisasi penuh ini dibangun secara native di Google Cloud, tetapi karena Anda mengubah semuanya sekaligus, migrasi dapat menjadi lebih lambat jika Anda memiliki beberapa lingkungan lama yang besar.

Kerusakan lama yang bersih memerlukan penulisan ulang pekerjaan dan perubahan aplikasi yang berbeda. Namun, hal ini juga memberikan kecepatan dan ketangkasan yang lebih tinggi serta total biaya kepemilikan yang paling rendah dalam jangka panjang dibandingkan dengan pendekatan lainnya. Ini karena dua alasan utama: aplikasi Anda sudah dioptimalkan dan tidak perlu diperbaiki, dan setelah memigrasikan sumber data, Anda tidak perlu mengelola dua lingkungan secara bersamaan. Pendekatan ini paling cocok untuk organisasi berbasis digital atau organisasi berbasis engineering yang memiliki sedikit lingkungan lama.
Terakhir, pendekatan yang paling konservatif adalah lift-and-rehome, yang kami rekomendasikan sebagai solusi taktis jangka pendek untuk memindahkan estate data Anda ke cloud. Anda dapat melakukan lift-and-rehome platform yang sudah ada dan terus menggunakannya seperti sebelumnya, tetapi di lingkungan Google Cloud. Hal ini berlaku untuk lingkungan seperti Teradata dan Databricks, misalnya, untuk mengurangi risiko awal dan memungkinkan aplikasi berjalan. Namun, tindakan ini akan menghadirkan lingkungan terpisah yang sudah ada ke cloud, bukan mentransformasinya, sehingga Anda tidak akan mendapatkan keuntungan dari performa platform yang dibangun secara native di Google Cloud. Namun, kami dapat membantu Anda melakukan migrasi penuh ke produk berbasis Google Cloud, sehingga Anda dapat memanfaatkan interoperabilitas dan membuat platform data analisis yang sepenuhnya modern di Google Cloud.
Taktis atau strategis?
Menurut kami, pembeda utama dari platform data analisis yang dibangun di Google Cloud adalah platform ini terbuka, cerdas, fleksibel, dan terintegrasi erat. Ada banyak solusi di pasar yang menyediakan solusi taktis yang mungkin terasa nyaman dan familier. Namun, hal ini umumnya memberikan solusi jangka pendek dan hanya menambah masalah organisasi dan teknis dari waktu ke waktu.
Google Cloud menyederhanakan analisis data secara signifikan. Anda dapat membuka potensi yang tersembunyi dalam data dengan pendekatan serverless berbasis cloud yang memisahkan penyimpanan dari komputasi dan memungkinkan Anda menganalisis data berukuran gigabyte hingga petabyte dalam hitungan menit. Hal ini memungkinkan Anda untuk menghilangkan batasan tradisional skala, performa, dan biaya untuk mengajukan pertanyaan apa pun tentang data dan memecahkan masalah bisnis. Hasilnya, mengoperasionalkan insight di seluruh perusahaan menjadi lebih mudah dengan satu data fabric tepercaya.
Apa keuntungannya?
- Menjaga fokus Anda sepenuhnya pada analisis, bukan infrastruktur
- Memecahkan setiap tahap siklus proses analisis data, mulai dari penyerapan, transformasi dan analisis, hingga business intelligence dan banyak lagi
- Menciptakan fondasi data yang solid untuk mengoperasionalkan machine learning
- Memungkinkan kemampuan untuk memanfaatkan teknologi open source terbaik bagi organisasi Anda
- Melakukan penskalaan untuk memenuhi kebutuhan perusahaan Anda, terutama saat meningkatkan penggunaan data dalam mendorong bisnis dan melalui transformasi digital Anda
Platform data analisis modern dan terpadu yang dibangun di Google Cloud memberi Anda kemampuan terbaik dari data lake dan data warehouse, tetapi dengan integrasi yang lebih dekat dengan platform AI. Anda dapat otomatis memproses data real-time dari miliaran peristiwa streaming dan menyajikan insight dalam hitungan milidetik untuk merespons kebutuhan pelanggan yang terus berubah. Layanan AI kami yang terdepan di industri dapat mengoptimalkan pengambilan keputusan organisasi dan pengalaman pelanggan, membantu Anda menutup kesenjangan antara analisis deskriptif dan preskriptif tanpa harus merekrut tim baru. Anda dapat meningkatkan keterampilan yang ada untuk menskalakan dampak AI dengan kecerdasan bawaan otomatis.
Langkah selanjutnya
Tertarik untuk mempelajari lebih lanjut tentang cara platform data Google dapat mentransformasi cara bisnis Anda menangani data? Hubungi kami untuk memulai.
Perlu bantuan untuk memulai?
Hubungi bagian penjualanBekerja sama dengan partner tepercaya
Temukan partnerLanjutkan menjelajah
Lihat semua produk


















