Créer une plate-forme de données d'analyse moderne et unifiée avec Google Cloud
Découvrez les points de décision à prendre en compte pour créer une plate-forme de données analytiques moderne et unifiée basée sur Google Cloud.
Auteurs : Firat Tekiner et Susan Pierce

Présentation
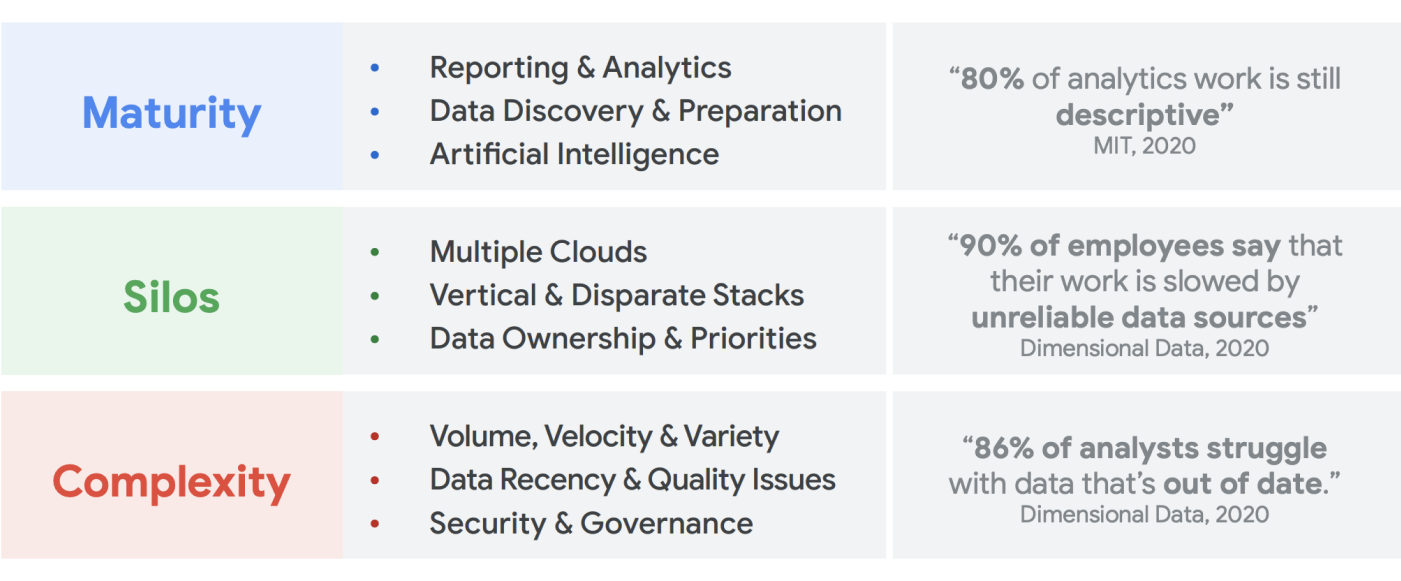
Il n'y a pas de pénurie de données nouvelles. D'après une étude IDC, les données mondiales passeront à 175 zettaoctets d'ici à 20251. Le volume de données générées chaque jour est stupéfiant, et il est de plus en plus difficile pour les entreprises de les collecter, de les stocker et de les organiser de manière accessible et utilisable. En réalité, 90 % des professionnels des données déclarent que leur travail a été ralenti par des sources de données non fiables. Environ 86 % des analystes de données rencontrent des difficultés avec des données obsolètes, et plus de 60 % des travailleurs des données doivent attendre chaque mois des ressources techniques pour nettoyer et préparer leurs données2.
Des structures organisationnelles et des décisions architecturales inefficaces contribuent à l'écart entre l'agrégation des données et leur exploitation utile par les entreprises. Les entreprises souhaitent passer au cloud pour moderniser leurs systèmes d'analyse de données, mais cela ne résout pas les problèmes sous-jacents liés au cloisonnement des sources de données et à la fragilité des pipelines de traitement. Les décisions stratégiques concernant la propriété des données et les décisions techniques concernant les mécanismes de stockage doivent être prises de façon globale afin d'améliorer l'efficacité d'une plate-forme de données pour votre organisation.
Dans cet article, nous abordons les points de décision nécessaires pour créer une plate-forme de données analytiques moderne et unifiée sur Google Cloud.
Au cours des deux dernières décennies, le big data a créé d'incroyables opportunités pour les entreprises. Cependant, il est difficile pour les entreprises de présenter à leurs utilisateurs professionnels des données pertinentes, exploitables et actualisées. Des études montrent que 86 % des analystes rencontrent encore des difficultés avec des données obsolètes3 et que seulement 32 % des entreprises estiment tirer un bénéfice tangible de leurs données4. Le premier problème concerne la fraîcheur des données. Le second problème est dû à la difficulté d'intégrer des systèmes disparates et anciens entre différents silos. Les entreprises migrent vers le cloud, mais cela ne résout pas le véritable problème des anciens systèmes qui ont parfois été structurés verticalement pour ne répondre aux besoins que d'une seule unité commerciale.
Lors de la planification des besoins en données d'une organisation, il est facile de généraliser et d'envisager une structure unique et simplifiée, avec un ensemble de sources de données cohérentes, un entrepôt de données d'entreprise, un ensemble de sémantiques et un outil d'informatique décisionnelle. Cela peut fonctionner pour une très petite organisation hautement centralisée, voire pour une seule unité commerciale disposant de sa propre équipe informatique et d'ingénierie des données. Dans la pratique, cependant, aucune organisation n'est aussi simple et il y a toujours des difficultés surprenantes au niveau de l'ingestion, du traitement et/ou de l'utilisation des données qui compliquent davantage les choses.
En parlant avec des centaines de clients, nous avons constaté qu'il fallait adopter une approche plus holistique des données et de l'analyse en créant une plate-forme capable de répondre aux besoins de plusieurs unités commerciales et types d'utilisateurs, avec le moins d'étapes redondantes possible pour le traitement des données. Cela va au-delà d'une nouvelle architecture ou d'un nouvel ensemble de composants logiciels à acheter. Au contraire, cela implique que les entreprises fassent le point sur la maturité globale de leurs données et mettent en œuvre des modifications systémiques et organisationnelles, en plus des mises à niveau techniques.
D'ici fin 2024, 75 % des entreprises vont passer du pilotage à l'opérationnalisation de l'intelligence artificielle, ce qui entraînera une multiplication par cinq des flux de données et des infrastructures d'analyse5. Il est assez facile de piloter l'IA avec une équipe indépendante de data scientists travaillant dans un environnement cloisonné. Mais le défi fondamental qui empêche ces insights d'être transmis dans les systèmes de production est la friction organisationnelle et architecturale qui permet de segmenter la propriété des données. Par conséquent, la plupart des insights intégrés aux activités commerciales d'une organisation sont de nature descriptive et l'analyse prédictive est reléguée au domaine d'une équipe de recherche.

Une plateforme pour tous les utilisateurs tout au long du cycle de vie des données
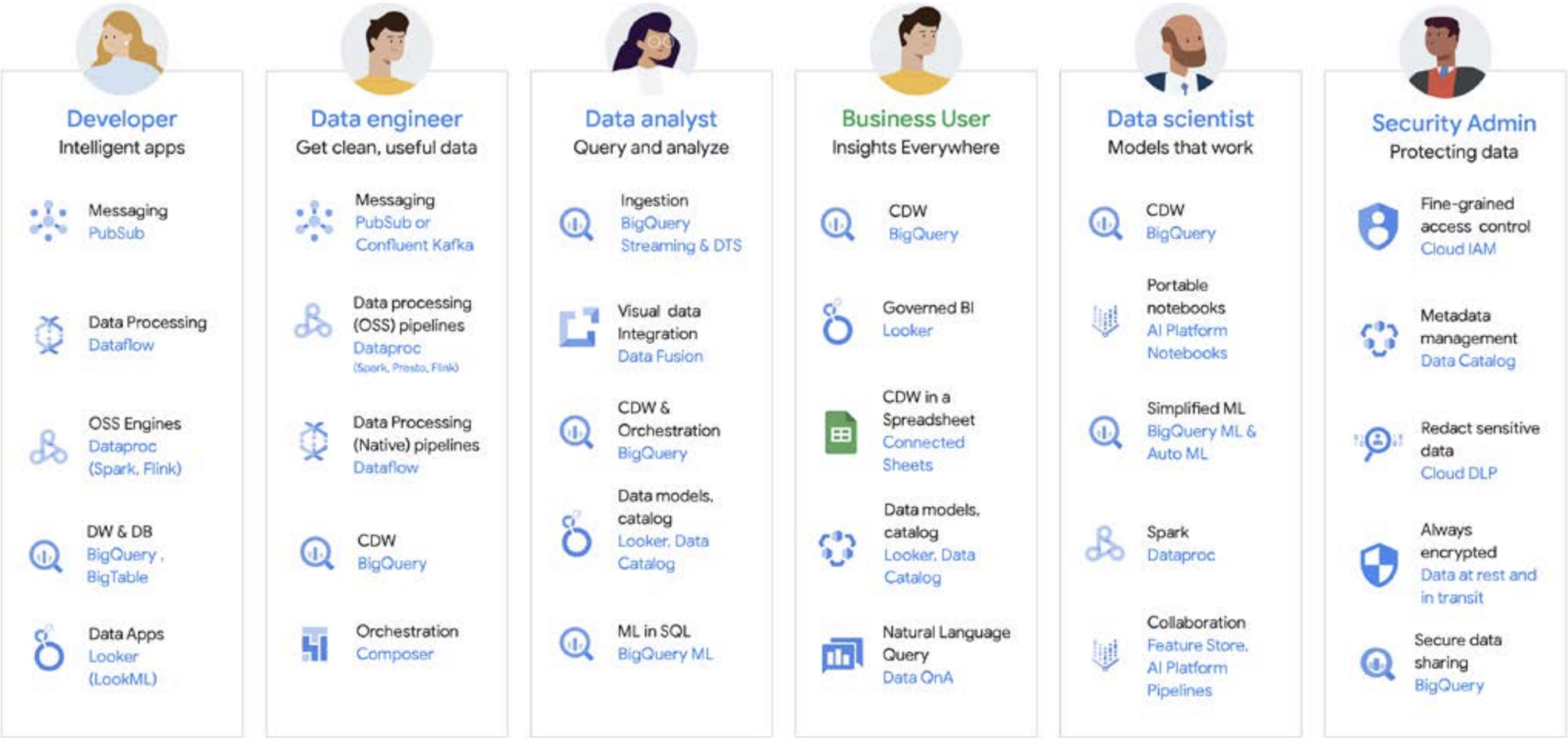
Le travail sur les données est rarement effectué par une seule personne. Une organisation compte de nombreux utilisateurs qui jouent un rôle important dans le cycle de vie des données. Chacun d'eux a un point de vue différent sur la gouvernance des données, la fraîcheur, la visibilité, les métadonnées, les délais de traitement, l'interrogation, et plus encore. Dans la plupart des cas, ils utilisent tous des systèmes et des logiciels différents pour opérer sur les mêmes données, à des étapes différentes du traitement.
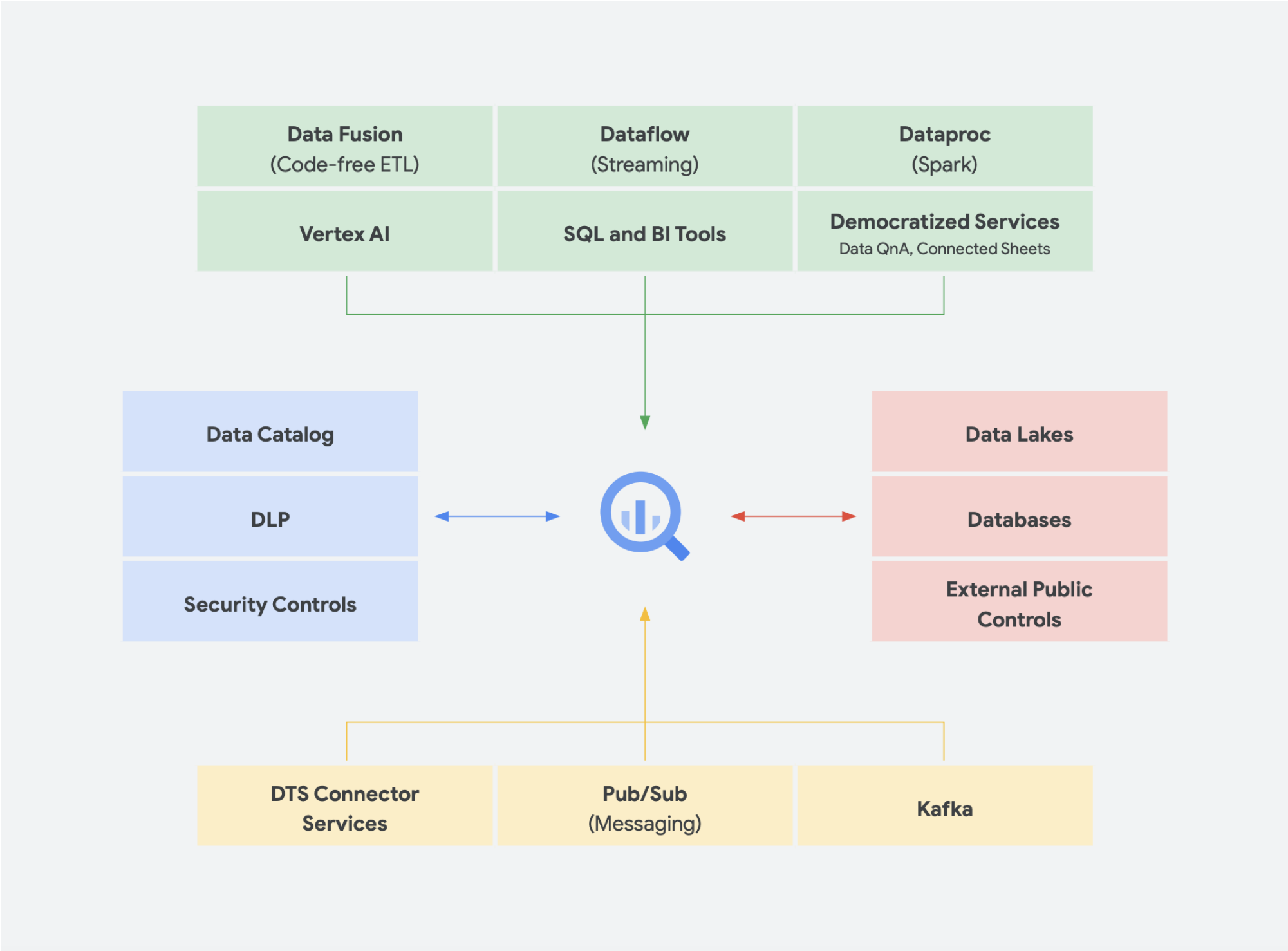
Examinons, par exemple, un cycle de vie de machine learning. Un ingénieur de données peut être chargé de s'assurer que des données récentes sont disponibles pour l'équipe de science des données, en mettant en place des contraintes de sécurité et de confidentialité appropriées. Un data scientist peut créer des ensembles de données d'entraînement et de test basés sur un ensemble fiable de sources de données pré-agrégées par l'ingénieur de données, créer et tester des modèles, et mettre des insights à la disposition d'une autre équipe. Un ingénieur en ML peut être chargé d'empaqueter le modèle en vue de son déploiement dans les systèmes de production, sans perturber les autres pipelines de traitement des données. Un responsable produit ou un analyste commercial peut vérifier les insights dérivés, utiliser Data QnA (une interface en langage naturel pour l'analyse des données BigQuery), un logiciel de visualisation, ou encore interroger l'ensemble de résultats directement via un IDE ou une interface de ligne de commande. Il existe d'innombrables utilisateurs ayant des besoins différents. Nous avons donc créé une plate-forme complète pour répondre à tous ces besoins. Google Cloud sert ses clients en proposant des outils adaptés aux besoins des entreprises.
Que choisir à l'ère du big data : l'entrepôt ou le lac de données ?
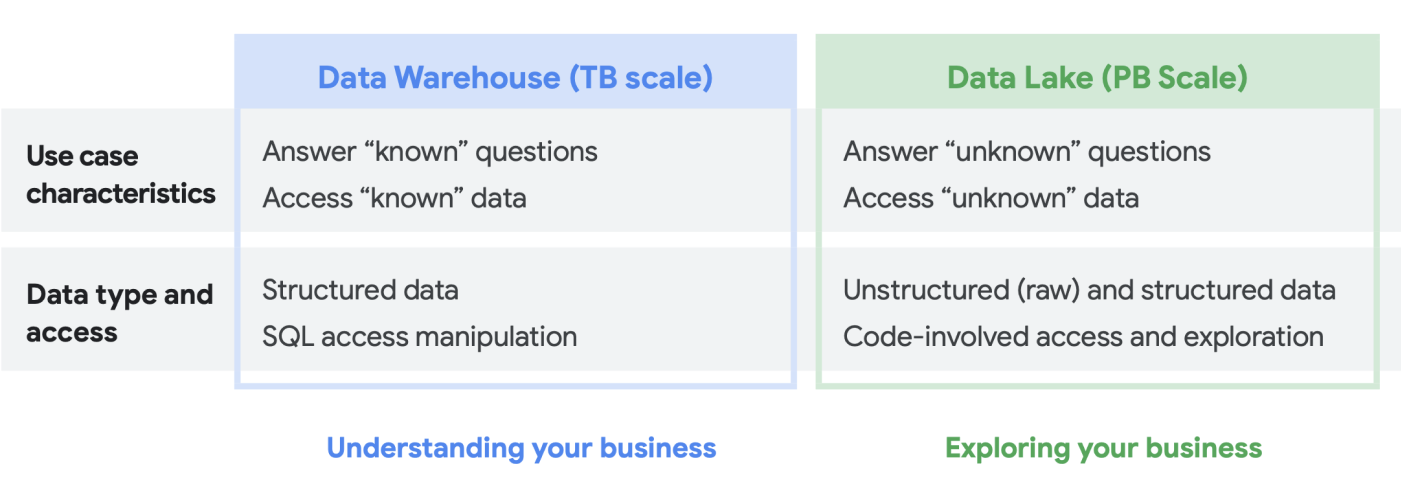
Lorsque nous discutons avec des clients de leurs besoins en analyse de données, nous entendons souvent la question suivante : "De quoi ai-je besoin : un lac de données ou un entrepôt de données ?". Compte tenu de la variété des utilisateurs de données et des besoins en données au sein d'une organisation, il peut s'avérer difficile de répondre à cette question qui dépend de l'utilisation prévue, des types de données et du personnel.
- Si vous savez quels ensembles de données vous devez analyser, si vous avez une compréhension claire de leurs structures et que vous avez une série connue de questions auxquelles vous devez répondre, la solution la plus adaptée est probablement un entrepôt de données.
- En revanche, si vous avez besoin de visibilité sur plusieurs types de données, si vous ne savez pas quels types d'analyses effectuer, si vous recherchez des opportunités à explorer plutôt que des insights, et si vous disposez des ressources nécessaires pour gérer et explorer efficacement cet environnement, un lac de données sera probablement mieux adapté à vos besoins
Cette décision a cependant de nombreuses autres implications… Penchons-nous donc sur quelques-uns des défis organisationnels spécifiques à chaque option. Les entrepôts de données sont souvent difficiles à gérer. Les anciens systèmes qui ont bien fonctionné au cours des 40 dernières années se sont révélés très onéreux et posent de nombreux défis en termes de fraîcheur des données, de mise à l'échelle et de coûts. De plus, ils ne peuvent pas fournir facilement des fonctionnalités d'IA ou en temps réel sans intégration a posteriori. Ces problèmes ne sont pas le seul apanage des anciens entrepôts de données sur site. Effectivement, ils concernent aussi les nouveaux entrepôts de données dans le cloud. Beaucoup d'entre eux n'offrent pas de fonctionnalités d'IA intégrées, malgré leurs affirmations dans ce sens. Ces nouveaux entrepôts de données sont essentiellement identiques aux anciens environnements, mais transférés vers le cloud. Les utilisateurs d'entrepôts de données sont généralement des analystes, souvent intégrés à une unité commerciale spécifique. Il peut avoir des idées d'ensembles de données supplémentaires qui seraient utiles pour enrichir la compréhension de l'entreprise. Ils peuvent avoir des idées d'améliorations pour l'analyse, le traitement des données et les exigences pour les fonctions d'informatique décisionnelle.
Toutefois, dans une organisation traditionnelle, ils n'ont souvent pas d'accès direct aux propriétaires des données et ne peuvent pas non plus facilement influencer les décisionnaires techniques qui décident des ensembles de données et des outils. De plus, comme ils sont isolés des données brutes, ils ne sont pas en mesure de tester des hypothèses ni d'approfondir la compréhension des données sous-jacentes. Les lacs de données ont leurs propres défis. En théorie, ils sont peu coûteux et faciles à faire évoluer. Cependant, nombre de nos clients ont constaté une réalité différente dans leurs lacs de données sur site. Planifier et provisionner un espace de stockage suffisant peut s'avérer coûteux et difficile, en particulier pour les organisations qui produisent des quantités de données très variables. Les lacs de données sur site peuvent être fragiles et la maintenance des systèmes existants prend du temps. Dans de nombreux cas, les ingénieurs qui développeraient autrement de nouvelles fonctionnalités sont relégués à la maintenance et à l'alimentation des clusters de données. En d'autres termes, ils préservent la valeur plutôt que d'en créer. Globalement, le coût total de possession est plus élevé que prévu pour de nombreuses entreprises. De plus, la gouvernance n'est pas facile à résoudre entre les multiples systèmes, en particulier lorsque les différents services de l'organisation utilisent des modèles de sécurité différents. Par conséquent, les lacs de données sont cloisonnés et segmentés, ce qui complique le partage des données et des modèles entre les équipes.
Les utilisateurs des lacs de données sont généralement plus proches des sources de données brutes, et disposent des outils et capacités nécessaires pour explorer les données. Dans les entreprises traditionnelles, ces utilisateurs ont tendance à se concentrer sur les données elles-mêmes et sont souvent éloignés du reste de l'entreprise. En raison de cette dissociation, les unités commerciales passent à côté d'une occasion de trouver des insights qui leur permettraient d'augmenter leurs revenus, de diminuer les coûts, de diminuer les risques et de saisir de nouvelles opportunités. Compte tenu de ces compromis, de nombreuses entreprises finissent par adopter une approche hybride dans laquelle un lac de données est utilisé pour choisir les données spécifiques à intégrer dans un entrepôt de données, ou dans laquelle un entrepôt de données se voit adjoindre un lac de données secondaire à des fins de test et d'analyse supplémentaire. Toutefois, lorsque plusieurs équipes fabriquent leurs propres architectures de données pour répondre à leurs besoins spécifiques, le partage et la fidélité des données se complexifient encore davantage pour l'équipe informatique centrale. Au lieu d'avoir des équipes distinctes avec des objectifs distincts, où l'une explore l'activité commerciale et une autre la comprend, vous pouvez unir ces fonctions et leurs systèmes de données afin de créer un cercle vertueux au sein duquel une compréhension approfondie de l'entreprise permet une exploration dirigée, qui favorise une meilleure compréhension de l'activité commerciale.
Traiter le stockage d'un entrepôt de données comme un lac de données
Vous pouvez créer un entrepôt ou un lac de données séparément sur Google Cloud, mais vous n'avez pas à choisir l'un ou l'autre. Bien souvent, nos clients utilisent les mêmes produits sous-jacents, et la seule différence entre les mises en œuvre du lac de données et de l'entrepôt de données réside dans les règles d'accès aux données utilisées. En fait, ces deux termes commencent à converger vers un ensemble de fonctionnalités plus unifié : une plate-forme de données analytiques moderne. Voyons comment cela fonctionne dans Google Cloud.
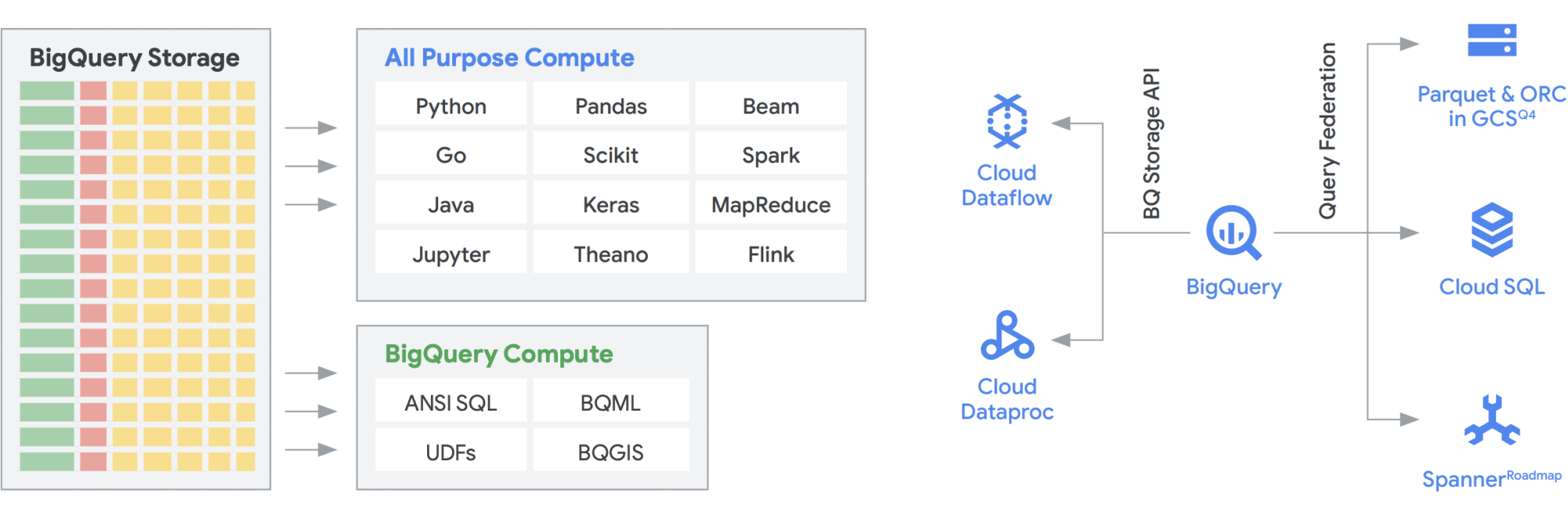
L'API BigQuery Storage permet d'utiliser BigQuery Storage à la manière de Cloud Storage pour un certain nombre d'autres systèmes tels que Dataflow et Managed Service pour Apache Spark. Cela permet de segmenter l'espace de stockage de l'entrepôt de données et d'exécuter des trames de données hautes performances sur BigQuery. En d'autres termes, l'API BigQuery Storage permet à votre entrepôt de données BigQuery de se comporter comme un lac de données. Alors, quelles sont ses utilisations pratiques ? Tout d'abord, nous avons créé une série de connecteurs (MapReduce, Hive et Spark, par exemple) qui vous permettent d'exécuter vos charges de travail Hadoop et Spark directement sur vos données dans BigQuery. Vous n'avez plus besoin d'un lac de données en plus de votre entrepôt de données ! Dataflow est incroyablement puissant pour le traitement par lot et par flux. À l'heure actuelle, vous pouvez exécuter des jobs Dataflow sur des données BigQuery, en les enrichissant avec des données provenant de Pub/Sub, de Spanner ou de n'importe quelle autre source de données.
BigQuery peut faire évoluer le stockage et le calcul indépendamment, le tout sans serveur, ce qui permet un scaling illimité pour répondre à la demande, quelle que soit l'utilisation faite par les différents outils, modèles d'accès et équipes. Toutes les applications ci-dessus peuvent s'exécuter sans affecter les performances de tout autre job accédant à BigQuery au même moment. De plus, l'API BigQuery Storage fournit un réseau à l'échelle du pétaoctet qui déplace les données entre les nœuds pour répondre aux requêtes, ce qui permet d'obtenir des performances similaires à celles d'une opération en mémoire. Elle permet également la fédération directe avec les formats de données Hadoop courants tels que Parquet et ORC, ainsi qu'avec les bases de données NoSQL et OLTP. Vous pouvez aller encore plus loin avec les fonctionnalités fournies par Dataflow SQL, qui est intégré à BigQuery. Cet outil vous permet de joindre les flux avec des tables BigQuery ou avec des données stockées dans des fichiers, en créant efficacement une architecture lambda, ce qui vous permet d'ingérer de grandes quantités de données par lot et par flux, tout en fournissant une couche de diffusion pour répondre aux requêtes. Avec BigQuery BI Engine et les vues matérialisées, vous pouvez encore améliorer l'efficacité et les performances de cette architecture multi-usage.
La plate-forme d'analyse intelligente Google fournie par BigQuery
Les solutions de données sans serveur sont absolument nécessaires pour permettre à votre entreprise d'aller au-delà des silos de données et d'entrer dans le domaine des insights et des actions. Tous nos principaux services d'analyse de données sont sans serveur et étroitement intégrés.

La gestion du changement est souvent l'un des aspects les plus difficiles de l'intégration de nouvelles technologies dans une organisation. Google Cloud cherche à répondre aux besoins de ses clients en leur proposant des outils, des plates-formes et des intégrations qu'ils connaissent déjà, tant pour les développeurs que pour les utilisateurs professionnels. Notre mission est d'accélérer la capacité de votre organisation à transformer et repenser numériquement votre activité grâce à une innovation conjointe basée sur les données. Plutôt que de dépendre d'un fournisseur, Google Cloud offre aux entreprises des options simples et rationalisées pour des intégrations à des environnements sur site, à d'autres offres cloud et même à la périphérie, afin de former un cloud véritablement hybride :
- Avec BigQuery Omni, il n'est plus nécessaire de transférer les données d'un environnement à un autre, et l'analyse est transférée vers les données, quel que soit l'environnement.
- Apache Beam, le SDK exploité dans Dataflow, confère transférabilité et portabilité aux exécuteurs comme Apache Spark et Apache Flink
- Pour les entreprises qui souhaitent exécuter Apache Spark ou Apache Hadoop, Google Cloud propose Managed Service pour Apache Spark.
La plupart des utilisateurs se soucient des données dont ils disposent, mais pas du système dans lequel elles se trouvent. Avoir accès aux données nécessaires au moment opportun est le point le plus important. Ainsi, dans la plupart des cas, le type de plate-forme n'a pas d'importance pour les utilisateurs, tant qu'ils sont en mesure d'accéder à des données actualisées et exploitables à l'aide d'outils familiers, qu'il s'agisse d'explorer des ensembles de données, de gérer des sources dans des datastores, d'exécuter des requêtes ad hoc ou de développer des outils internes d'informatique décisionnelle pour les dirigeants.
Tendances émergentes
Dans la continuité de l'idée de convergence d'un lac de données et d'un entrepôt de données dans une plate-forme de données analytiques unifiée, d'autres solutions de données gagnent du terrain. De nombreux concepts ont fait leur apparition autour du lakehouse et du maillage de données, par exemple. Vous avez peut-être déjà entendu certains de ces termes. Certains ne sont pas nouveaux et existent depuis des années sous des formes et des formats différents. Cependant, ils fonctionnent très bien dans l'environnement Google Cloud. Examinons de plus près ce à quoi ressembleraient un maillage de données et un lakehouse de données dans Google Cloud, et ce que ces systèmes impliquent pour le partage des données au sein d'une organisation. Le lakehouse et le maillage de données ne s'excluent pas mutuellement, mais ils permettent de résoudre différents défis au sein d'une organisation. L'un favorise l'exploitation des données, tandis que l'autre favorise les équipes. Le maillage de données permet aux utilisateurs d'éviter un goulot d'étranglement créé par une équipe, ce qui facilite l'utilisation de l'intégralité de la pile de données. Elle divise les silos en unités organisationnelles plus petites dans une architecture qui fournit un accès aux données fédéré. Le lakehouse rassemble l'entrepôt et le lac de données, permettant ainsi d'utiliser différents types de données et des volumes plus élevés. Cela conduit en effet à un schéma en lecture plutôt qu'à un schéma en écriture, une fonctionnalité des lacs de données qui est censée solutionner certains des problèmes de performances des entrepôts de données d'entreprise. Autre avantage : cette architecture utilise une gouvernance des données plus stricte, ce qui manque généralement aux lacs de données.

Lakehouse
Comme mentionné ci-dessus, l'API Storage de BigQuery vous permet de traiter votre entrepôt de données comme un lac de données. Les jobs Spark exécutés sur Managed Service pour Apache Spark ou dans des environnements Hadoop similaires peuvent utiliser les données stockées sur BigQuery plutôt que de nécessiter un support de stockage distinct en effectuant un stockage à partir de l'entrepôt de données. La puissance de calcul exceptionnelle qui est découplée de l'espace de stockage dans BigQuery permet une transformation basée sur SQL et utilise des vues sur différentes couches de ces transformations. Cela conduit ensuite à une approche de type ELT et permet d'obtenir une plate-forme de traitement des données plus agile. En s'appuyant sur l'ELT plutôt que sur l'ETL, BigQuery permet de stocker des transformations basées sur SQL en tant que vues logiques. Bien que le vidage de toutes les données brutes dans le stockage d'un entrepôt de données puisse être coûteux avec un entrepôt de données traditionnel, il n'y a pas de frais supplémentaires pour le stockage BigQuery. Son coût est relativement comparable à celui du stockage de blobs dans Google Cloud Storage.
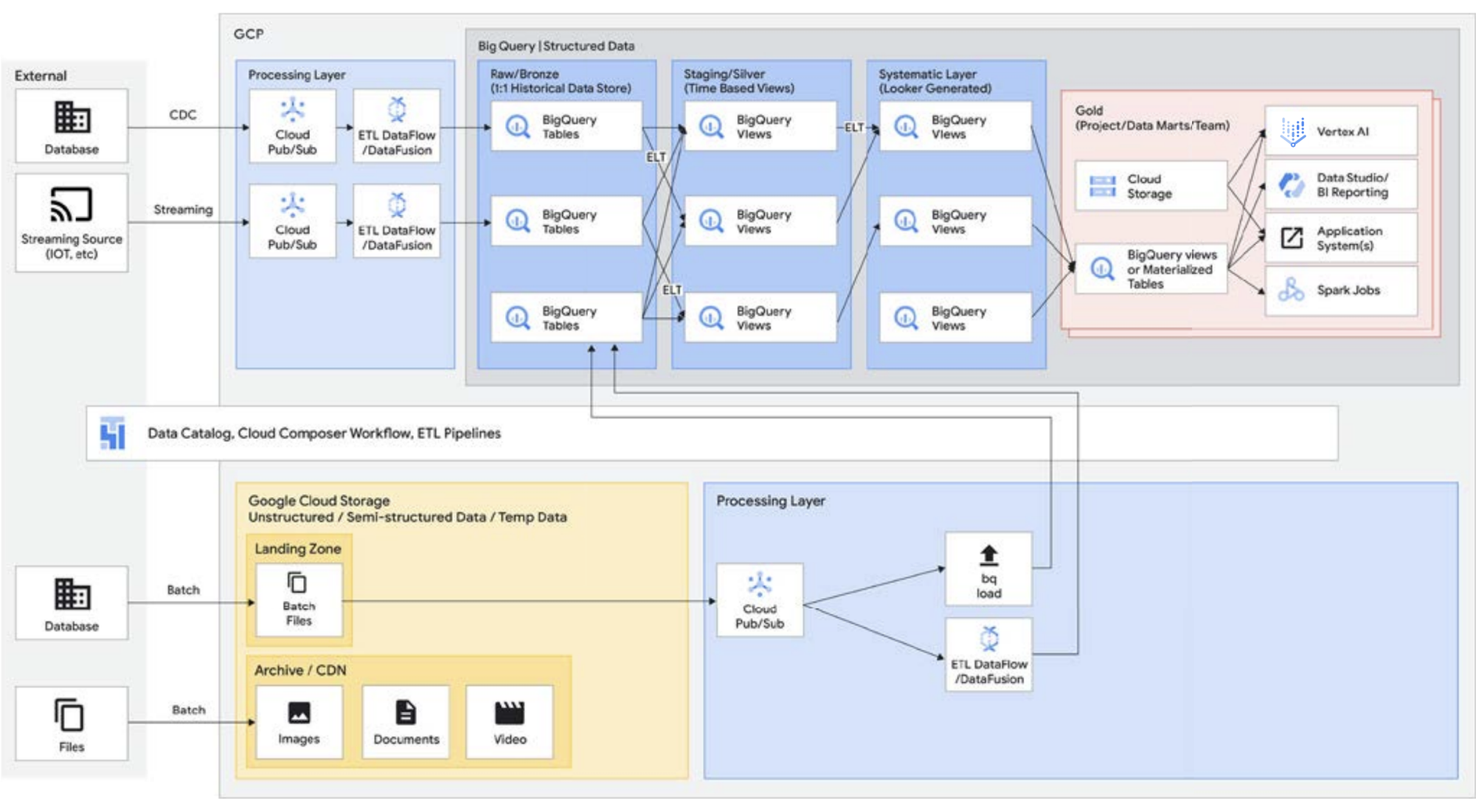
Lors de l'exécution des opérations ETL, les transformations ont lieu en dehors de BigQuery, potentiellement dans un outil qui n'est pas aussi évolutif. Cela peut entraîner la transformation des données ligne par ligne plutôt que d'exécuter les requêtes en parallèle. Dans certains cas, Spark ou d'autres processus ETL sont déjà codifiés, et leur remplacement pour passer à une nouvelle technologie n'est pas justifié. Toutefois, si des transformations peuvent être écrites en SQL, BigQuery est probablement l'endroit idéal pour les réaliser.
De plus, cette architecture est compatible avec tous les composants Google Cloud, tels que Managed Service pour Apache Airflow, Data Catalog ou Data Fusion. Elle fournit une couche de bout en bout pour différents types d'utilisateurs. Un autre aspect important de la réduction des coûts opérationnels peut être mis en œuvre en exploitant les capacités de l'infrastructure sous-jacente. Prenons l'exemple de Dataflow et BigQuery, qui s'exécutent sur des conteneurs et nous permettent de gérer le temps d'activité et les mécanismes en arrière-plan. Une fois ce fonctionnement étendu aux outils tiers et partenaires, et lorsque ces derniers commencent à explorer des fonctionnalités similaires à celles de Kubernetes, la gestion et la portabilité s'en trouvent grandement simplifiés. Cela permet de réduire les coûts opérationnels et de ressources. En outre, cela peut être complété par une meilleure observabilité en exploitant les tableaux de bord de surveillance avec Managed Service pour Apache Airflow pour viser l'excellence opérationnelle. Vous pouvez non seulement créer un lac de données en rassemblant les données stockées dans Cloud Storage et BigQuery, sans les déplacer ni les dupliquer, mais aussi bénéficier de fonctionnalités d'administration supplémentaires pour gérer vos sources de données. Knowledge Catalog (anciennement Dataplex) crée un lakehouse en offrant une couche de gestion centralisée pour coordonner les données dans Cloud Storage et BigQuery. Cela vous permet d'organiser vos données en fonction des besoins de votre entreprise. Ainsi, vous n'êtes plus limité par la manière ou l'endroit où les données sont stockées.
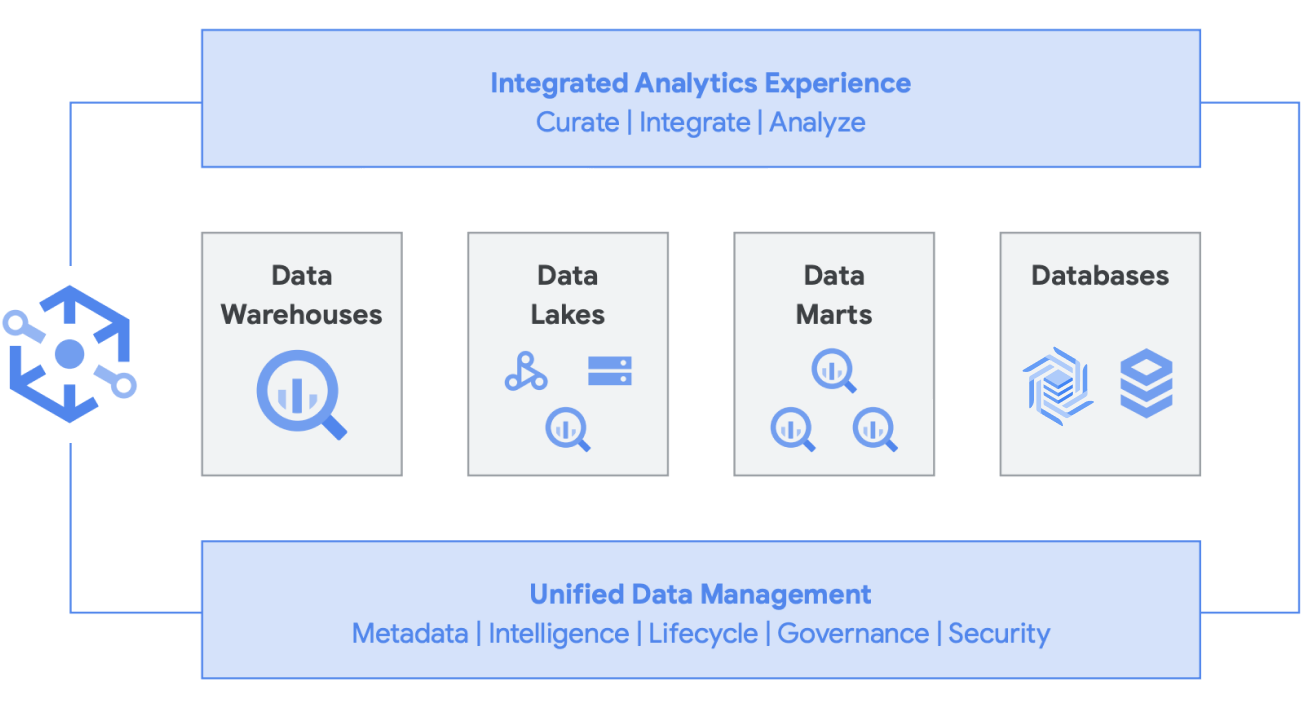
Knowledge Catalog est une data fabric intelligente qui vous permet de conserver vos données distribuées au rapport prix/performances qui vous convient, tout en permettant à l'ensemble de vos outils d'analyse d'y accéder de façon sécurisée. Dataplex permet une gestion des données par les métadonnées, et intègre la qualité et la gouvernance des données. Vous passez donc moins de temps à lutter contre les limites et les inefficacités de l'infrastructure, vous faites confiance aux données en votre possession et vous passez plus de temps à valoriser ces données. De plus, ce produit offre une expérience d'analyse intégrée, car il réunit les meilleurs outils Google Cloud et Open Source, ce qui vous permet d'organiser, de sécuriser, d'intégrer et d'analyser rapidement vos données à grande échelle. Enfin, vous pouvez concevoir une stratégie d'analyse qui élargit l'architecture existante et répond à vos objectifs de gouvernance financière.
Un maillage de données
Le maillage de données s'appuie sur une longue histoire d'innovation pour les entrepôts et les lacs de données, en association à des modèles de paiement basés sur les performances et l'évolutivité, à des API, à des DevOps et à une intégration étroite des produits Google Cloud. Cette approche vous permet de créer efficacement une solution de données à la demande. Un maillage de données décentralise la propriété des données entre les propriétaires de données du domaine, chacun d'entre eux étant tenu de fournir ses données en tant que produit de manière standardisée. Un maillage de données facilite également la communication entre les différentes parties de l'organisation avec des ensembles de données distribués dans différents emplacements. Dans un maillage de données, la responsabilité de générer de la valeur à partir des données est fédérée aux personnes qui les comprennent le mieux. En d'autres termes, les personnes qui ont créé les données ou les ont introduites dans l'organisation doivent également être responsables de la création d'actifs de données consommables en tant que produits, à partir des données qu'elles créent. Dans de nombreuses organisations, il est difficile d'établir une "source unique de vérité" ou une "source de données faisant autorité" en raison de l'extraction et de la transformation répétées des données au sein de l'organisation, sans responsabilité claire de la propriété des données nouvellement créées. Dans le maillage de données, la source de données faisant autorité est le produit de données publié par le domaine source, avec un propriétaire et un responsable des données clairement désignés qui sont responsables de ces données.
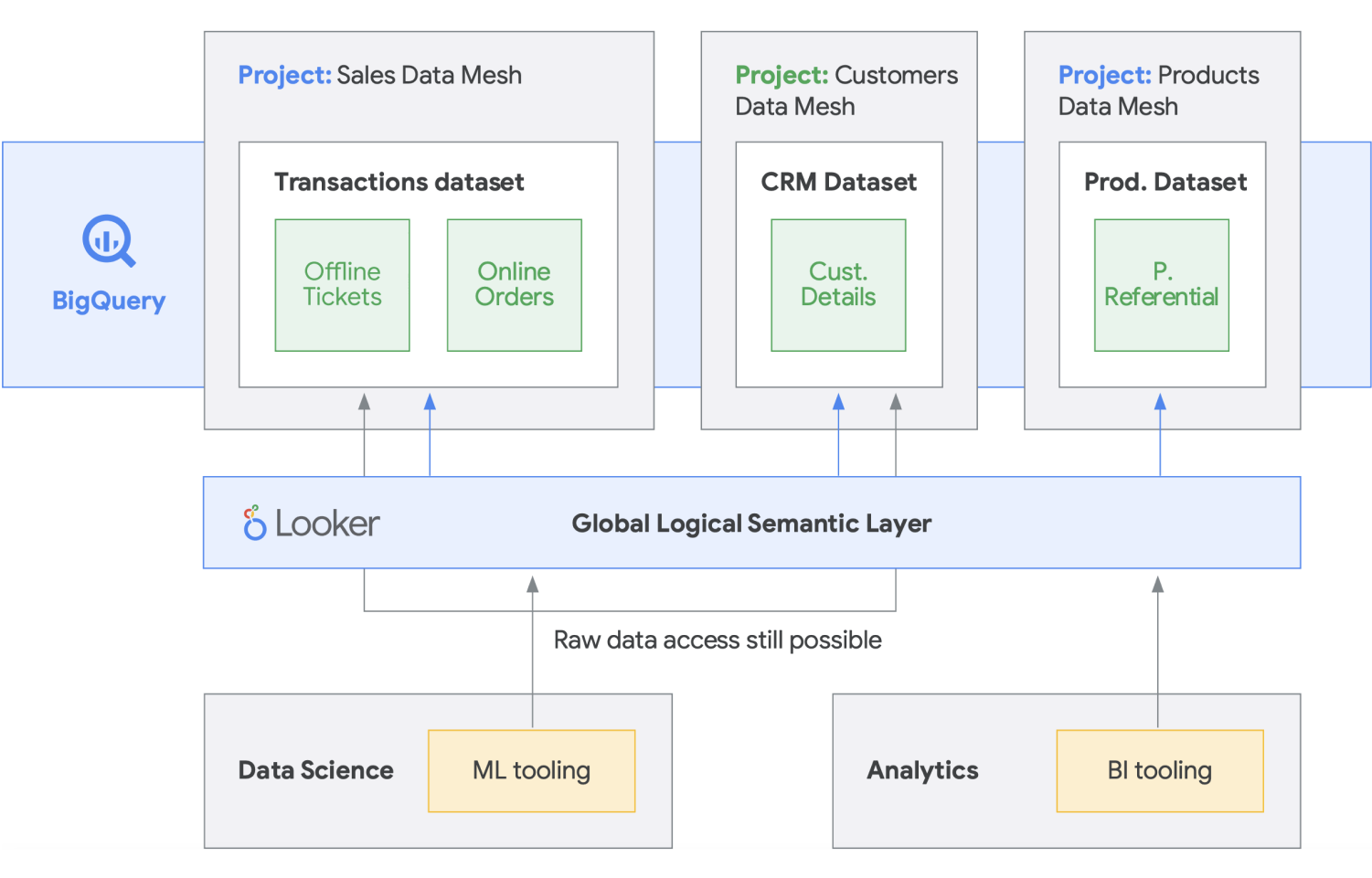
En résumé, le maillage de données promet une architecture et une propriété des données décentralisées et orientées domaine. Cela est possible grâce à des couches de calcul et d'accès fédérées, comme nous le proposons dans Google Cloud. De plus, si votre entreprise souhaite obtenir davantage de fonctionnalités, vous pouvez utiliser Looker, qui peut fournir une couche unifiée pour la modélisation et l'accès aux données. La plateforme Looker offre une interface utilisateur à volet unique permettant d'accéder à la version la plus complète et la plus récente des données et définitions commerciales de votre entreprise. Grâce à cette vue unifiée de l'activité, vous pouvez choisir ou concevoir des expériences de données qui assurent aux personnes et aux systèmes que les données leur sont fournies de la manière la plus logique pour leurs besoins. Il s'intègre parfaitement, car il permet aux data scientists, aux analystes et même aux utilisateurs professionnels d'accéder à leurs données avec un seul modèle sémantique. Les data scientists accèdent toujours aux données brutes, mais sans les déplacer ni les dupliquer.
Nous développons des fonctionnalités supplémentaires pour nos produits phares comme BigQuery, afin de faciliter la création et la gestion des ensembles de données. Analytics Hub offre la possibilité de créer des échanges de données privés. Les administrateurs de l'échange (ou curateurs de données) autorisent la publication de données dans l'échange et leur abonnement à des personnes ou groupes spécifiques, à la fois dans l'entreprise et en externe pour des partenaires commerciaux ou des acheteurs.
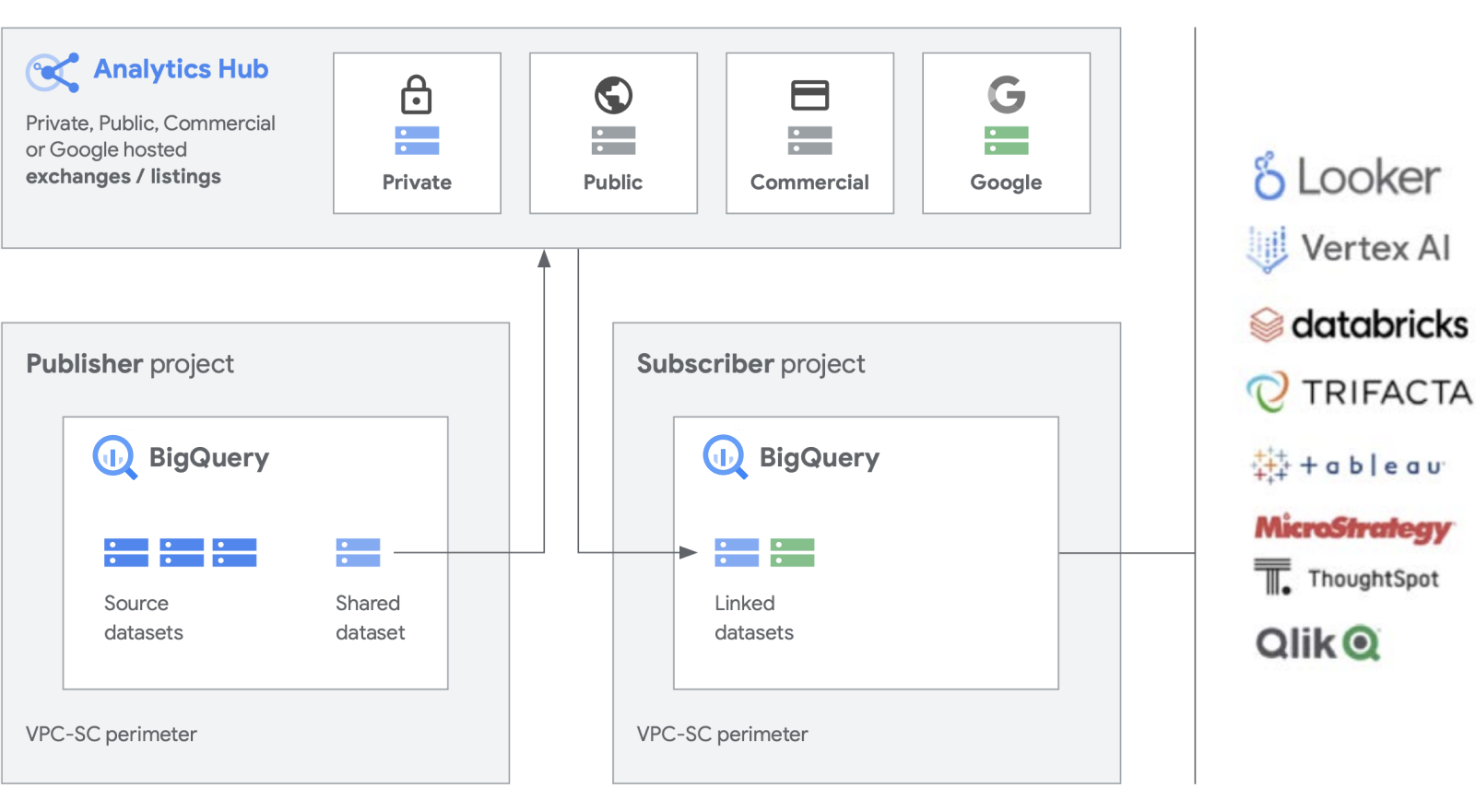
Publiez, découvrez et abonnez-vous à des ressources partagées, y compris dans des formats Open Source, grâce à l'évolutivité de BigQuery. Les éditeurs peuvent consulter des métriques d'utilisation agrégées. Les fournisseurs de données peuvent proposer aux clients BigQuery d'entreprise des données, des insights, des modèles de ML ou des visualisations, et exploiter Cloud Marketplace pour monétiser leurs applications, leurs insights ou leurs modèles. C'est également ainsi que les ensembles de données publics BigQuery sont gérés par le biais d'un échange géré par Google. Stimulez l'innovation en accédant à des ensembles de données uniques de Google, des ensembles de données commerciaux ou industriels, des ensembles de données publics ou des sélections d'échanges de données de votre organisation ou de l'écosystème de partenaires.
Gérer l'héritage
Bien qu'il soit tentant de créer une toute nouvelle plate-forme de données à partir de zéro, nous savons que toutes les entreprises n'en ont pas la possibilité. La plupart d'entre elles doit gérer d'anciens systèmes qu'ils doivent migrer, transférer ou corriger jusqu'à ce qu'ils puissent être remplacés. Nous avons travaillé avec des clients à chaque étape de leur parcours sur la plate-forme de données et nous avons des solutions adaptées à votre situation.
Trois catégories de migration sont généralement observées chez les clients : la migration "Lift and Replatform", la migration "Lift and Rehome" et la modernisation complète. Pour la plupart des entreprises, nous conseillons de commencer par la migration "Lift and Replatform", car elle offre une migration à fort impact avec le moins de perturbations et de risques possible. Avec cette stratégie, vous migrez vos données vers BigQuery ou Managed Service pour Apache Spark depuis vos anciens entrepôts de données et vos clusters Hadoop. Une fois les données déplacées, vous pouvez optimiser vos pipelines de données et vos requêtes pour améliorer les performances. Avec une stratégie de migration "Lift and Replatform", vous pouvez le faire par phases, en fonction de la complexité de vos charges de travail. Nous recommandons cette approche aux grandes entreprises clientes dotées d'un service informatique centralisé et de plusieurs unités commerciales, en raison de leur complexité.
La deuxième stratégie de migration que nous observons le plus souvent consiste à commencer par une modernisation complète. Vous coupez ainsi avec le passé, car vous exploitez une approche cloud native. Il est conçu de manière native sur Google Cloud, mais comme vous pouvez tout modifier d'un seul coup, la migration peut être plus lente si vous disposez de plusieurs environnements anciens et volumineux.

Pour que la transition fonctionne correctement, il est nécessaire de réécrire les jobs et de changer les différentes applications. Cependant, elle offre également plus de rapidité et d'agilité, pour un coût total de possession le plus faible à long terme par rapport aux autres approches. Cela est dû à deux raisons principales : vos applications sont déjà optimisées et n'ont pas besoin d'être mises à jour, et une fois vos sources de données migrées, vous n'avez pas à gérer deux environnements en même temps. Cette approche convient particulièrement aux entreprises de type "digital native" ou basées sur l'ingénierie qui disposent de peu d'environnements anciens.
Enfin, l'approche la plus prudente consiste à effectuer une migration "Lift and Rehome", que nous recommandons comme solution tactique à court terme pour migrer votre infrastructure de données vers le cloud. Vous pouvez migrer vos plates-formes existantes à l'aide d'une migration "Lift and Rehome" et continuer à les utiliser comme avant, mais dans l'environnement Google Cloud. Cela s'applique à des environnements tels que Teradata et Databricks par exemple, afin de réduire le risque initial et de permettre l'exécution des applications. Cependant, l'environnement cloisonné existant est transféré dans le cloud au lieu de le transformer. Vous ne bénéficierez donc pas des performances d'une plate-forme conçue en mode natif sur Google Cloud. Toutefois, nous pouvons vous aider à effectuer une migration complète vers les produits natifs Google Cloud. Vous pourrez ainsi profiter de l'interopérabilité et créer une plate-forme de données analytiques complètement moderne sur Google Cloud.
Tactique ou stratégique ?
Nous pensons que les principaux facteurs de différenciation d'une plate-forme de données analytiques basée sur Google Cloud sont son caractère ouvert, intelligent, flexible et étroitement intégré. Il existe de nombreuses solutions sur le marché qui fournissent des solutions tactiques qui peuvent être pratiques et familières. Toutefois, ces solutions sont généralement à court terme et ne font qu'aggraver les problèmes organisationnels et techniques au fil du temps.
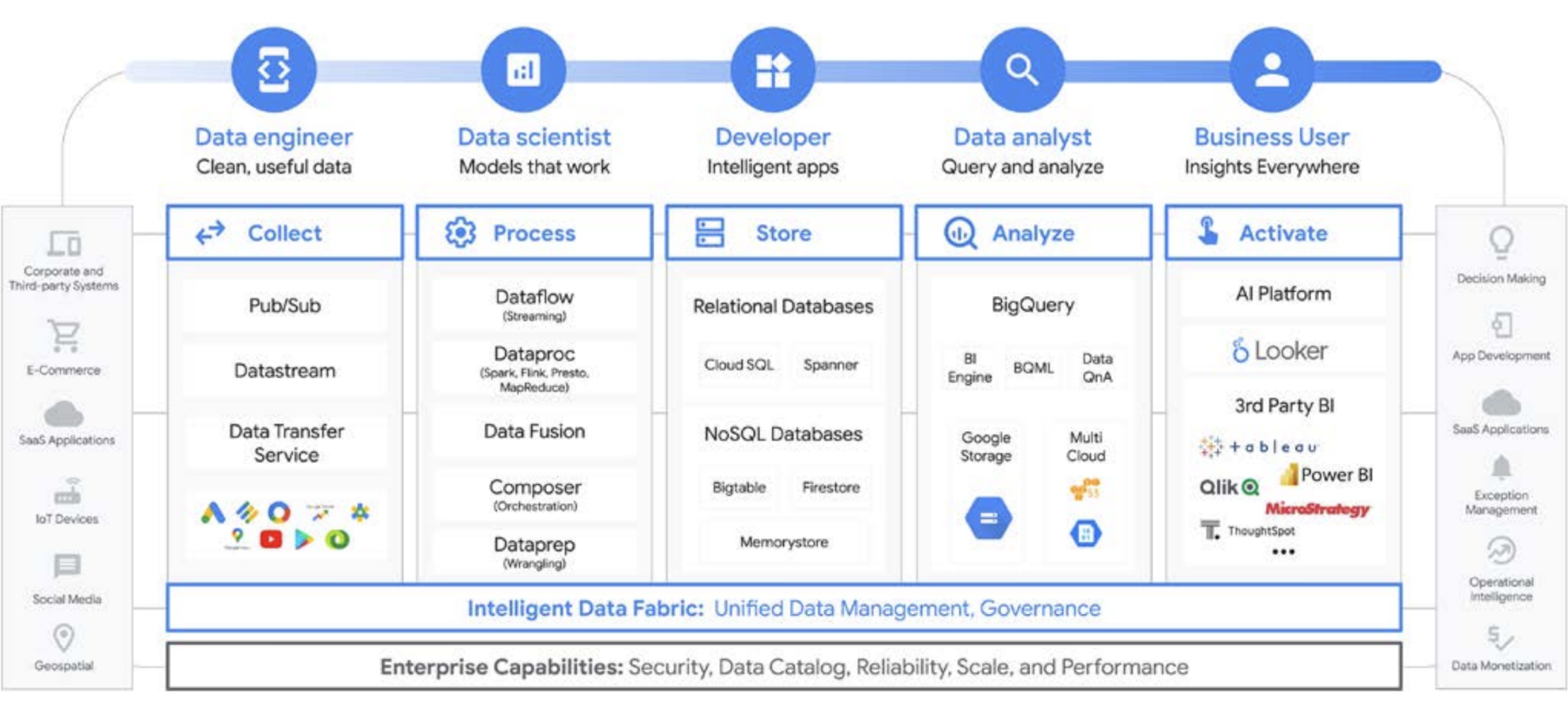
Google Cloud simplifie considérablement l'analyse de données. Vous pouvez exploiter tout le potentiel caché de vos données grâce à une approche cloud native sans serveur qui dissocie le stockage du calcul et vous permet d'analyser des gigaoctets, voire des pétaoctets, de données en quelques minutes. Cela vous permet d'éliminer les contraintes traditionnelles d'évolutivité, de performances et de coût pour poser toute question sur les données et résoudre des problèmes métier. Il devient ainsi plus facile d'opérationnaliser les insights dans toute l'entreprise avec une data fabric unique et fiable.
Quels sont les avantages ?
- Vous pouvez vous concentrer uniquement sur les analyses plutôt que sur l'infrastructure.
- Elle s’applique à chaque étape du cycle de vie de l’analyse de données, de l’ingestion à la transformation et l’analyse, en passant par l’informatique décisionnelle et plus encore.
- Elle crée une infrastructure de données solide pour opérationnaliser le machine learning
- Elle vous permet d'exploiter les meilleures technologies Open Source pour votre organisation.
- Elle évolue pour répondre aux besoins de votre entreprise, en particulier si vous utilisez davantage les données pour développer votre activité et réaliser votre transformation numérique.
Une plate-forme de données analytiques moderne et unifiée basée sur Google Cloud vous offre les meilleures fonctionnalités d'un lac de données et d'un entrepôt de données, mais avec une intégration plus étroite dans AI Platform. Vous pouvez traiter automatiquement les données en temps réel de milliards d'événements en flux continu et fournir des insights en quelques millisecondes pour répondre à l'évolution des besoins des clients. Nos services d'IA de pointe peuvent optimiser la prise de décision et l'expérience client dans votre organisation, et vous aider à combler l'écart entre les analyses descriptives et normatives sans avoir à recruter une nouvelle équipe. Vous pouvez renforcer vos compétences existantes pour faire évoluer l'impact de l'IA grâce à des fonctionnalités intelligentes intégrées et automatisées.
Passez à l'étape suivante
Vous souhaitez en savoir plus sur la façon dont la plate-forme de données Google peut transformer la façon dont votre entreprise traite les données ? Contactez-nous pour commencer.
Vous avez besoin d'aide pour démarrer ?
Contacter le service commercialFaites appel à un partenaire de confiance
Trouver un partenairePoursuivez vos recherches
Voir tous les produits


















