Crea una plataforma de datos de análisis moderna y unificada con Google Cloud
Obtén información sobre los puntos de decisión necesarios para crear una plataforma de datos de estadísticas unificada y moderna compilada en Google Cloud.
Autores: Firat Tekiner y Susan Pierce

Descripción general
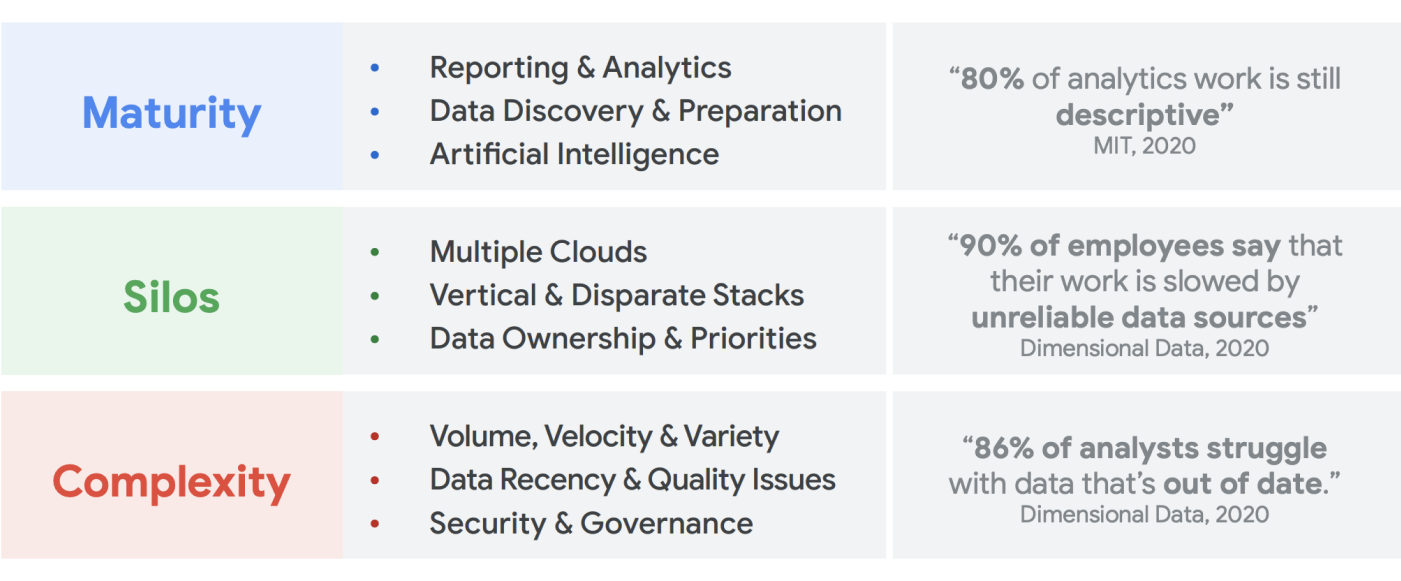
Hay una gran cantidad de datos que se están creando. La investigación de IDC indica que los datos mundiales alcanzarán los 175 zettabytes en 20251. El volumen de datos que se generan a diario es asombroso, y cada vez es más difícil para las empresas recopilarlos, almacenarlos y organizarlos de forma accesible y utilizable. De hecho, el 90% de los profesionales de datos dice que su trabajo se ve ralentizado por fuentes de datos poco confiables. Alrededor del 86% de los analistas de datos tiene dificultades con datos desactualizados, y más del 60% de los trabajadores de datos se ven afectados por tener que esperar en recursos de ingeniería todos los meses mientras se limpian y preparan sus datos2.
Las estructuras organizativas ineficientes y las decisiones arquitectónicas contribuyen a la brecha que las empresas tienen entre la agregación de datos y el hecho de que les sirva. Las empresas quieren migrar a la nube para modernizar sus sistemas de análisis de datos, pero eso por sí solo no resuelve los problemas subyacentes de fuentes de datos aisladas y canalizaciones de procesamiento frágiles. Las decisiones estratégicas en torno a la propiedad de los datos y las decisiones técnicas sobre los mecanismos de almacenamiento deben tomarse de manera holística para que una plataforma de datos sea más exitosa para su organización.
En este artículo, analizaremos los puntos de decisión necesarios para crear una plataforma de datos de estadísticas unificada y moderna compilada en Google Cloud.
Los macrodatos crearon oportunidades increíbles para las empresas en las últimas dos décadas. Sin embargo, es complicado para las organizaciones presentar a sus usuarios empresariales datos relevantes, prácticos y oportunos. Las investigaciones demuestran que el 86% de los analistas todavía tienen problemas con los datos desactualizados3 y solo el 32% de las empresas creen que obtienen un valor tangible de sus datos4. El primer problema es la actualización de los datos. El segundo problema surge de la dificultad de integrar sistemas heredados y distintos en silos. Las organizaciones están migrando a la nube, pero eso no resuelve el problema real de los sistemas heredados más antiguos que podrían haberse estructurado verticalmente para satisfacer las necesidades de una sola unidad de negocios.
Cuando planificas las necesidades de datos organizacionales, es fácil generalizar demasiado y considerar una estructura única y simplificada en la que hay un conjunto de fuentes de datos coherentes, un almacén de datos empresarial, un conjunto de semántica y una herramienta para la inteligencia empresarial. Podría funcionar para una organización muy pequeña y altamente centralizada, y hasta para una sola unidad de negocios que tenga su propio equipo integrado de ingeniería de datos y TI. Sin embargo, en la práctica, ninguna organización es tan simple y siempre existen complejidades sorpresa en la transferencia, el procesamiento o el uso de datos que complican aún más el asunto.
Lo que observamos al hablar con cientos de clientes es la necesidad de un enfoque más integral de los datos y los análisis, una plataforma que pueda satisfacer las necesidades de múltiples unidades de negocios y arquetipos de usuarios, con la menor cantidad de pasos redundantes para procesar los datos. Esto se convierte en algo más que una nueva arquitectura o un conjunto de componentes de software para comprar, requiere que las empresas analicen su madurez general de datos y realicen cambios organizativos y sistémicos, además de actualizaciones técnicas.
Para finales de 2024, el 75% de las empresas pasarán de la prueba piloto a la puesta en funcionamiento de la IA, lo que generará un aumento 5 veces mayor en las infraestructuras de estadísticas y datos de transmisión5. Es lo suficientemente fácil como para poner a prueba la IA con un equipo de ciencia de datos de cuerpo entero que trabaje en un entorno aislado. Sin embargo, el desafío fundamental que impide que esas estadísticas se publiquen en los sistemas de producción es la fricción organizacional y de la arquitectura que mantiene segmentada la propiedad de los datos. Como resultado, la mayoría de los conocimientos que se incorporan a las operaciones comerciales de una organización son de naturaleza descriptiva, y el análisis predictivo se delega al dominio de un equipo de investigación.

Una plataforma para todos los usuarios a lo largo del ciclo de vida de los datos
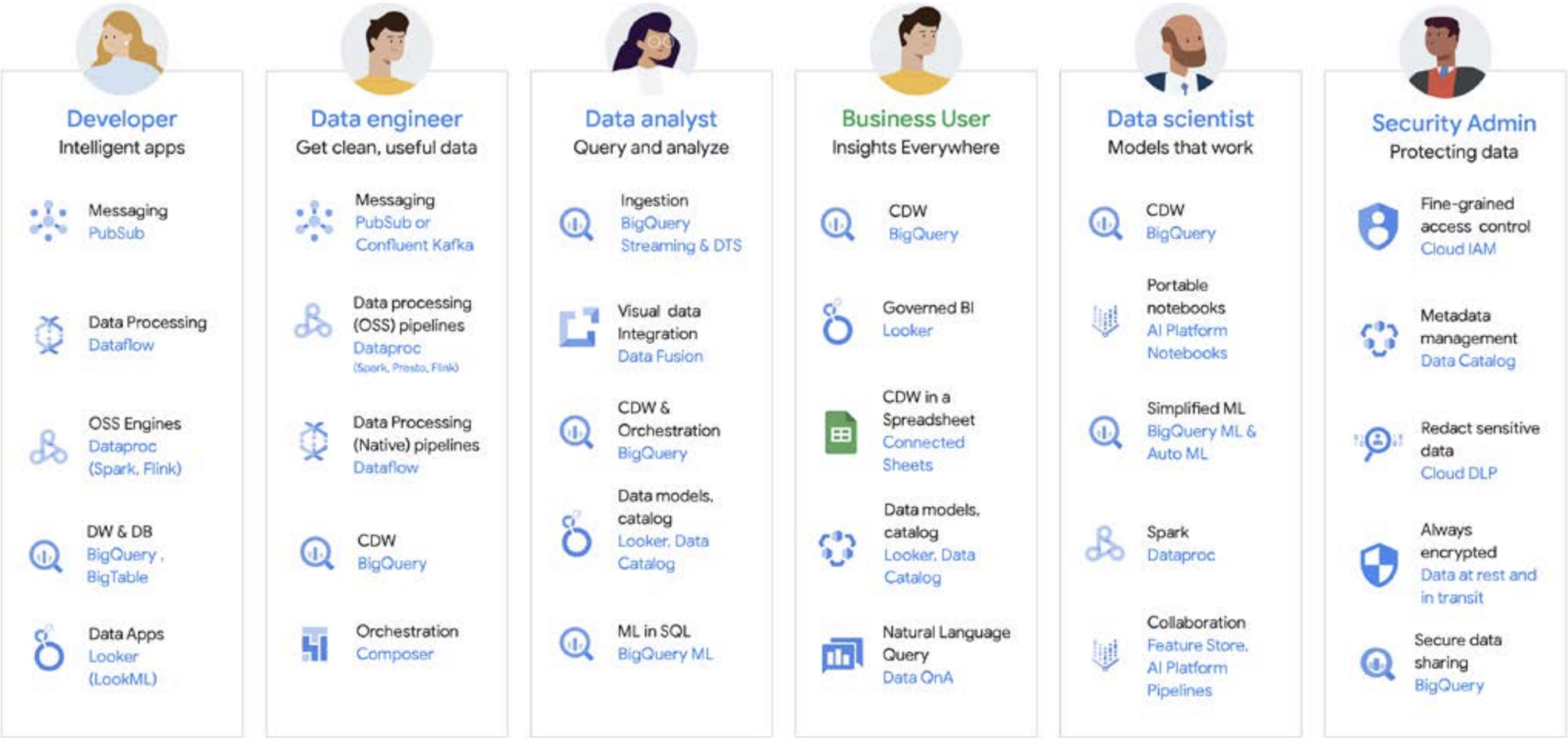
El trabajo con los datos pocas veces lo realiza una sola persona; en una organización hay muchos usuarios relacionados con los datos que desempeñan roles importantes en el ciclo de vida de los datos. Cada uno tiene una perspectiva diferente en cuanto a la administración de datos, la actualidad, la visibilidad, los metadatos, los cronogramas de procesamiento, la capacidad de consulta y mucho más. En la mayoría de los casos, todos usan sistemas y software diferentes para operar con los mismos datos, en diferentes etapas del procesamiento.
Veamos, por ejemplo, el ciclo de vida del aprendizaje automático. Un ingeniero de datos puede ser responsable de garantizar que los datos actualizados estén disponibles para el equipo de ciencia de datos, con las restricciones de seguridad y privacidad adecuadas. Un científico de datos puede crear conjuntos de datos de entrenamiento y prueba basados en un conjunto dorado de fuentes de datos agregados previamente del ingeniero de datos, compilar y probar modelos y poner las estadísticas a disposición de otro equipo. Es posible que un ingeniero del AA sea responsable de empaquetar el modelo para implementarlo en los sistemas de producción, de una manera que no afecte otras canalizaciones de procesamiento de datos. Es posible que un gerente de producto o un analista de negocios esté consultando estadísticas derivadas con Data QnA (una interfaz de lenguaje natural para el análisis de datos de BigQuery), software de visualización o podría consultar el conjunto de resultados directamente a través de un IDE o una interfaz de línea de comandos. Existen innumerables usuarios con diferentes necesidades, y creamos una plataforma de compresión para satisfacerlos a todos. Google Cloud se adapta a las necesidades de los clientes conforme a su situación actual, con herramientas para satisfacer las necesidades de la empresa.
La gran decisión de macrodatos: ¿almacén de datos o data lake?
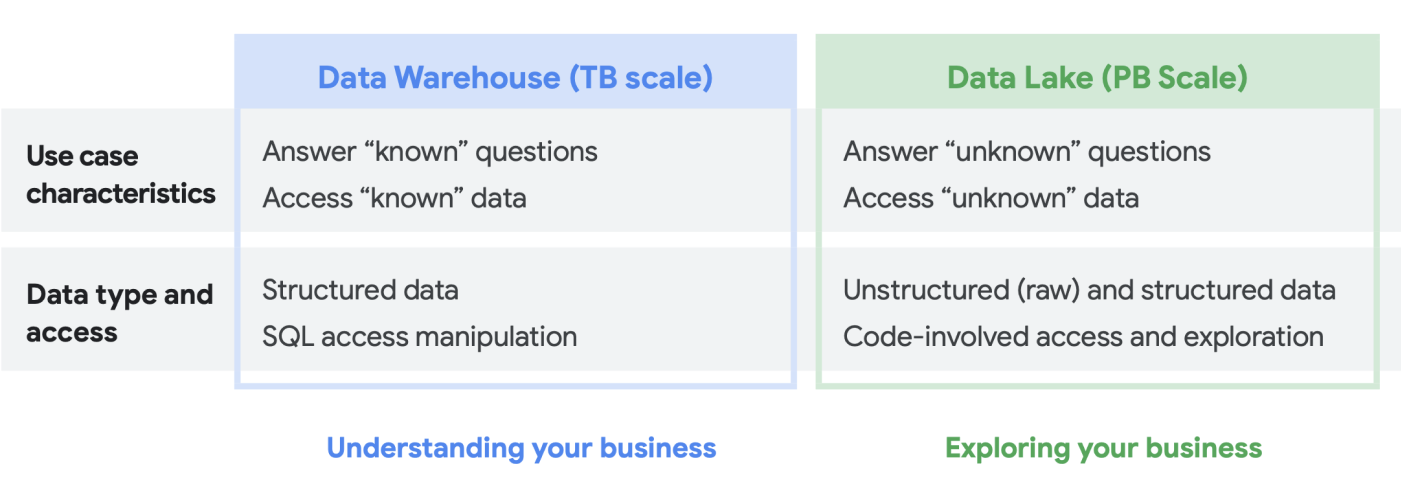
Cuando hablamos con los clientes sobre sus necesidades de análisis de datos, con frecuencia escuchamos la pregunta “¿Qué necesito: un data lake o un almacén de datos?”. Dada la variedad de usuarios de datos y las necesidades dentro de una organización, esta puede ser una pregunta difícil de responder que depende del uso previsto, los tipos de datos y el personal.
- Si sabes qué conjuntos de datos necesitas analizar, tienes una comprensión clara de su estructura y tienes un conjunto conocido de preguntas que necesitas que se respondan, es probable que estés consultando un almacén de datos
- Por otro lado, si necesita visibilidad en varios tipos de datos, no estás seguro de qué tipos de análisis deberás ejecutar, buscas oportunidades para explorar en lugar de presentar estadísticas y tiene los recursos para administrar y explorar esto de manera eficaz. Es probable que un data lake se adapte mejor a tus necesidades.
Pero la decisión tiene mucho más que ver, así que hablemos sobre algunos de los desafíos organizacionales de cada uno. Los almacenes de datos suelen ser difíciles de administrar. Los sistemas heredados que funcionaron bien en los últimos 40 años demostraron ser muy costosos y plantean muchos desafíos en relación con la actualidad de los datos, el escalamiento y los altos costos. Además, no pueden proporcionar IA o capacidades en tiempo real con facilidad sin incorporar esa funcionalidad con posterioridad. Estos problemas no solo están presentes en los almacenes de datos heredados locales; con los almacenes de datos basados en la nube recientemente creados. A pesar de sus afirmaciones, muchos no ofrecen capacidades de IA integradas. Estos almacenes de datos nuevos son, en esencia, los mismos entornos heredados, pero se trasladaron a la nube. Los usuarios de almacenes de datos tienden a ser analistas y, con frecuencia, están incorporados dentro de una unidad de negocios específica. Pueden tener ideas sobre conjuntos de datos adicionales que serían útiles para profundizar su comprensión del negocio. Pueden tener ideas para mejorar el análisis, el procesamiento de datos y los requisitos de la funcionalidad de inteligencia empresarial.
Sin embargo, en una organización tradicional, a menudo no tienen acceso directo a los propietarios de los datos ni pueden influir con facilidad en los encargados de tomar decisiones técnicas que deciden los conjuntos de datos y las herramientas. Además, debido a que se mantienen separados de los datos sin procesar, no pueden probar hipótesis o impulsar una comprensión más profunda de los datos subyacentes. Los data lakes tienen sus propios desafíos. En teoría, son de bajo costo y fáciles de escalar, pero muchos de nuestros clientes han visto una realidad diferente en sus data lakes locales. Planificar y aprovisionar suficiente almacenamiento puede ser costoso y difícil, especialmente para las organizaciones que producen cantidades de datos muy variables. Los data lakes locales pueden ser frágiles y el mantenimiento de los sistemas existentes lleva tiempo. En muchos casos, los ingenieros, que de otro modo estarían desarrollando nuevas funciones, deben dedicarse al cuidado y la alimentación de los clústeres de datos. Dicho de manera más directa, mantienen el valor en lugar de crear uno nuevo. En general, el costo total de propiedad es más alto de lo esperado para muchas empresas. No solo eso, la gobernanza no se resuelve fácilmente en todos los sistemas, en especial cuando diferentes partes de la organización usan modelos de seguridad distintos. Como resultado, los data lakes se separan y segmentan, lo que dificulta compartir datos y modelos entre equipos.
Los usuarios de data lakes suelen estar más cerca de las fuentes de datos sin procesar y cuentan con herramientas y capacidades para explorar los datos. En las organizaciones tradicionales, estos usuarios tienden a centrarse en los datos en sí y, con frecuencia, se mantienen a poca distancia del resto de la empresa. Esta desconexión significa que las unidades de negocios pierden la oportunidad de encontrar estadísticas que impulsarían sus objetivos comerciales hacia mayores ingresos, costos más bajos, menos riesgo y nuevas oportunidades. Debido a estas compensaciones, muchas empresas terminan con un enfoque híbrido, en el que un data lake se configura para convertir algunos datos en un almacén de datos o un almacén de datos tiene un data lake lateral para pruebas y análisis adicionales. Sin embargo, con varios equipos que fabrican sus propias arquitecturas de datos para satisfacer sus necesidades individuales, el uso compartido de datos y la fidelidad se vuelven aún más complicados para un equipo central de TI. En lugar de tener equipos separados con objetivos distintos, donde uno explora el negocio y otro lo comprende, puedes unir estas funciones con sus sistemas de datos para crear un círculo virtuoso en el que una comprensión más profunda del negocio impulse la exploración directa y esa exploración una mejor comprensión del negocio.
Trata el almacenamiento del almacén de datos como un data lake
Puedes compilar un almacén de datos o un data lake por separado en Google Cloud, pero no es necesario que elijas uno o el otro. En muchos casos, los productos subyacentes que usan nuestros clientes son los mismos para ambos, y la única diferencia entre la implementación del data lake y el almacén de datos es la política de acceso a los datos que se emplea. De hecho, los dos términos están empezando a converger en un conjunto de funciones más unificado: una plataforma de datos analítica moderna. Veamos cómo funciona esto en Google Cloud.
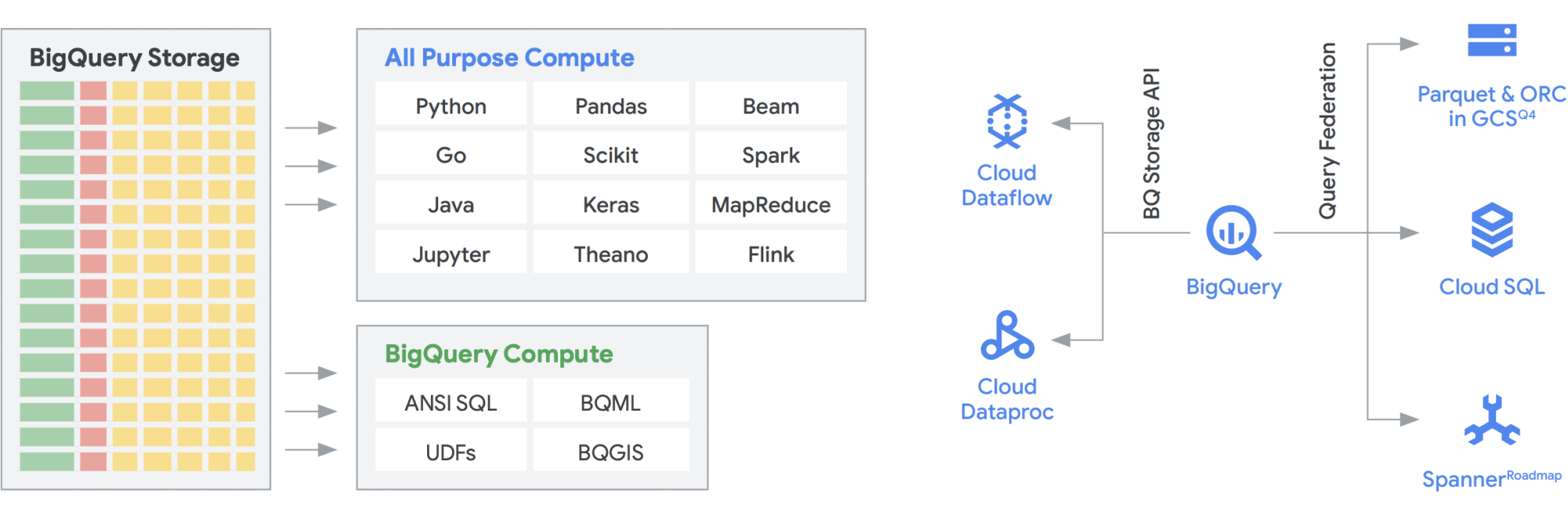
La API de BigQuery Storage proporciona la capacidad de usar BigQuery Storage para otros sistemas, como Dataflow y Managed Service para Apache Spark. Esto permite desglosar el muro de almacenamiento del almacén de datos y ejecutar marcos de datos de alto rendimiento en BigQuery. En otras palabras, la API de BigQuery Storage permite que tu almacén de datos de BigQuery actúe como un data lake. ¿Cuáles son algunos de sus usos prácticos? Por un lado, creamos una serie de conectores, por ejemplo, MapReduce, Hive, Spark, para que puedas ejecutar tus cargas de trabajo de Hadoop y Spark directamente en tus datos en BigQuery. Ya no necesitas un data lake además de tu almacén de datos. Dataflow es increíblemente potente para el procesamiento de transmisión y por lotes. En la actualidad, puedes ejecutar trabajos de Dataflow sobre los datos de BigQuery y enriquecerlos con datos de Pub/Sub, Spanner o cualquier otra fuente de datos.
BigQuery puede escalar de forma independiente el almacenamiento y el procesamiento, y cada uno funciona sin servidores, lo que permite un escalamiento ilimitado para satisfacer la demanda sin importar el uso de diferentes equipos, herramientas y patrones de acceso. Todas las aplicaciones anteriores pueden ejecutarse sin afectar el rendimiento de cualquier otro trabajo que acceda a BigQuery al mismo tiempo. Además, la API de BigQuery Storage proporciona una red a nivel de petabytes que traslada datos entre nodos para entregar una solicitud de consulta de manera eficaz, lo que genera un rendimiento similar al de una operación en la memoria. También permite federar directamente con los formatos de datos populares de Hadoop, como Parquet y ORC, así como bases de datos NoSQL y OLTP. Puedes ir un paso más allá con las funciones que proporciona Dataflow SQL, que está incorporada en BigQuery. Esto te permite unir las transmisiones con tablas o datos de BigQuery alojados en archivos, lo que crea una arquitectura lambda de forma eficaz, lo que te permite transferir grandes cantidades de datos por lotes y de transmisión, a la vez que proporciona una capa de servicio para responder a las consultas. BigQuery BI Engine y las vistas materializadas facilitan aún más el aumento de la eficiencia y el rendimiento en esta arquitectura de varios uso.
La plataforma de analítica inteligente de Google con la tecnología de BigQuery
Las soluciones de datos sin servidores son absolutamente necesarias para permitir que tu organización avance más allá de los silos de datos y vaya al dominio de las estadísticas y la acción. Todos nuestros servicios principales de análisis de datos son sin servidores y están estrechamente integrados.

La gestión de cambios suele ser uno de los aspectos más difíciles de incorporar tecnología nueva en una organización. Google Cloud busca satisfacer a nuestros clientes dondequiera que proporcionen herramientas, integraciones y plataformas conocidas tanto para desarrolladores como para usuarios empresariales. Nuestra misión es acelerar la capacidad de tu organización para reimaginar y transformar digitalmente tu negocio mediante la innovación impulsada por los datos, en conjunto. En lugar de depender de proveedores, Google Cloud ofrece a las empresas opciones para realizar integraciones sencillas y optimizadas con entornos on‐premise, otras soluciones en la nube e incluso el perímetro para formar una nube híbrida:
- BigQuery Omni elimina la necesidad de transferir datos de un entorno a otro y, en cambio, lleva las estadísticas a los datos sin importar el entorno.
- Apache Beam, el SDK que se aprovecha en Dataflow, proporciona transferibilidad y portabilidad a ejecutores como Apache Spark y Apache Flink
- Para las organizaciones que buscan ejecutar Apache Spark o Apache Hadoop, Google Cloud ofrece Managed Service para Apache Spark
A la mayoría de los usuarios de datos les importa qué datos tienen, no en qué sistema se encuentran. Tener acceso a los datos que necesitan cuando los necesitan es lo más importante. Así que, en general, el tipo de plataforma no importa para los usuarios, siempre y cuando puedan acceder a datos actualizados y utilizables con herramientas conocidas, ya estén explorando conjuntos de datos, gestionando fuentes entre almacenes de datos, ejecutando consultas ad hoc o desarrollando herramientas internas de inteligencia empresarial para partes interesadas ejecutivas.
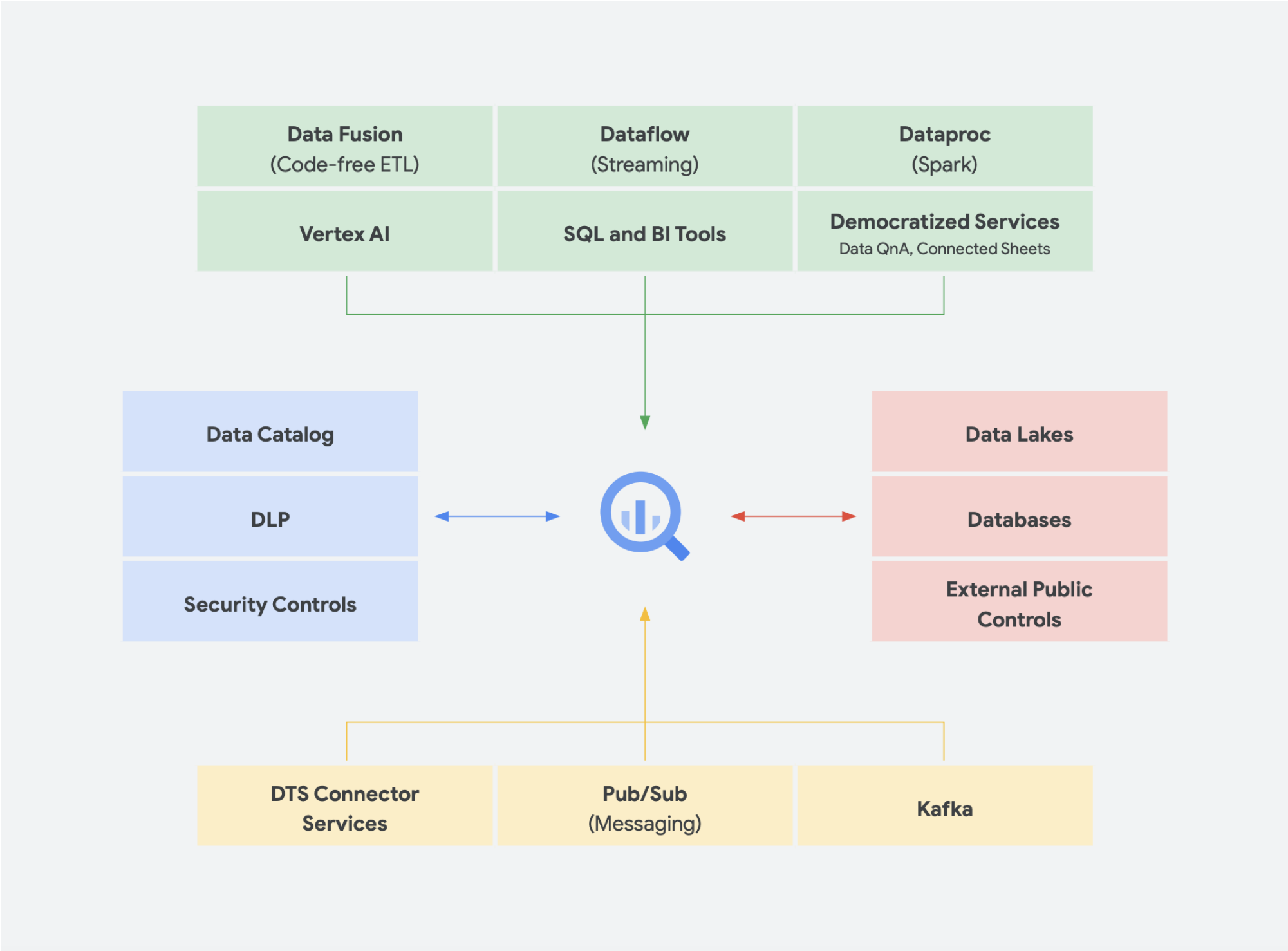
Tendencias emergentes
Para continuar con esta idea de la convergencia de data lake y almacén de datos en una plataforma unificada de datos analíticos, existen algunas soluciones de datos adicionales que cada vez ganan más terreno. Por ejemplo, hemos visto que surgen muchos conceptos en torno a lakehouse y malla de datos. Es posible que ya hayas escuchado algunos de estos términos. Algunos no son nuevos y han estado presente en diferentes formas y formatos durante años. Sin embargo, funcionan muy bien en el entorno de Google Cloud. Veamos con más detalle cómo se verían una malla de datos y una lakehouse en Google Cloud y lo que significan para el uso compartido de datos dentro de una organización. Lakehouse y la malla de datos no son mutuamente excluyentes, pero ayudan a resolver diferentes desafíos dentro de una organización. Pero uno favorece la habilitación de datos, mientras que el otro habilita a los equipos. La malla de datos ayuda a las personas a evitar los cuellos de botella que genera un equipo y, por lo tanto, habilita toda la pila de datos. Divide los silos en unidades organizativas más pequeñas en una arquitectura que proporciona acceso a los datos de manera federada. Lakehouse combina el almacén de datos y el data lake, lo que permite diferentes tipos y mayores volúmenes de datos. Esto conduce de forma eficaz al esquema en lectura en lugar del esquema en escritura, una característica de los data lakes que se pensó que cierra algunas de las brechas de rendimiento en los almacenes de datos empresariales. Como beneficio adicional, esta arquitectura también emplea una administración de datos más rigurosa, algo que los data lakes suelen carecer.

Lakehouse
Como se mencionó antes, la API de Storage de BigQuery te permite tratar tu almacén de datos como un data lake. Los trabajos de Spark que se ejecutan en Managed Service para Apache Spark o entornos similares de Hadoop pueden usar los datos almacenados en BigQuery en lugar de requerir un medio de almacenamiento independiente mediante la extracción del almacenamiento del almacén de datos. La pura potencia de procesamiento que está separada del almacenamiento dentro de BigQuery permite la transformación basada en SQL y usa vistas en las diferentes capas de estas transformaciones. Esto conduce a un enfoque de tipo ELT y permite una plataforma de procesamiento de datos más ágil. BigQuery aprovecha ELT en vez de ETL para permitir que las transformaciones basadas en SQL se almacenen como vistas lógicas. Si bien volcar todos los datos sin procesar en el almacenamiento del almacén de datos puede ser costoso con un almacén de datos tradicional, no hay cargos premium por el almacenamiento en BigQuery. Su costo es bastante similar al del almacenamiento de BLOB en Google Cloud Storage.
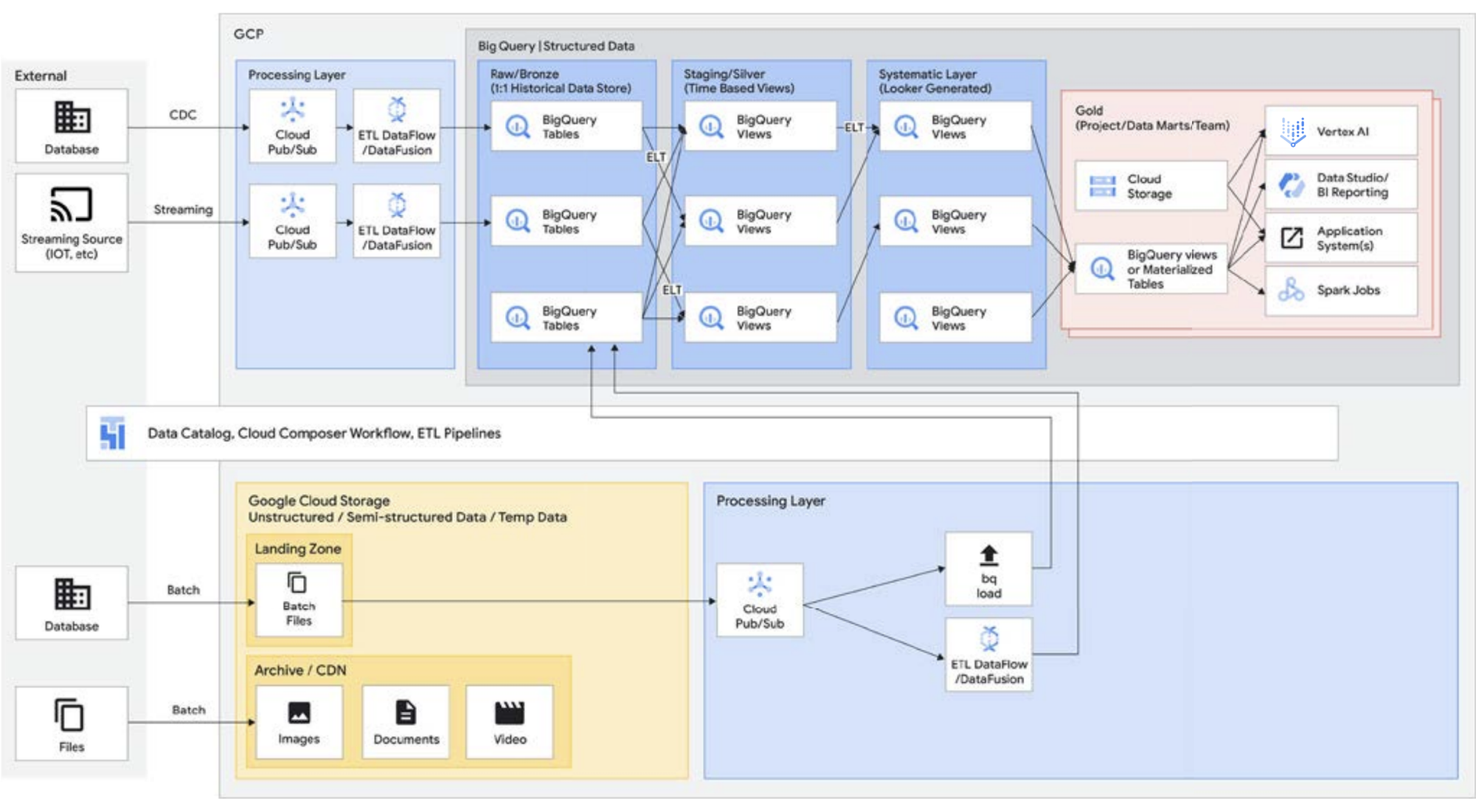
Cuando se realiza el proceso de ETL, las transformaciones se realizan fuera de BigQuery, posiblemente en una herramienta que no escala bien. Podría terminar transformando los datos línea por línea en lugar de paralelizar las consultas. Puede haber casos en los que Spark y otros procesos de ETL ya estén codificados y cambiarlos por el uso de tecnología nueva podría no tener sentido. Sin embargo, si hay transformaciones que se pueden escribir en SQL, es probable que BigQuery sea un excelente lugar para realizarlas.
Además, esta arquitectura es compatible con todos los componentes de Google Cloud, como Managed Service para Apache Airflow, Data Catalog o Data Fusion. Proporciona una capa de extremo a extremo para diferentes arquetipos de usuario. Otro aspecto importante de reducir la sobrecarga operativa se puede hacer aprovechando las capacidades de la infraestructura subyacente. Considera Dataflow y BigQuery, ya que se ejecutan en contenedores y nos permiten administrar el tiempo de actividad y la mecánica detrás de escena. Una vez que esto se extiende a las herramientas de terceros y de socios, y cuando comienzan a explorar capacidades similares, como Kubernetes, se vuelve mucho más fácil de administrar y portátil. A su vez, esto reduce las sobrecargas operativas y de recursos. Además, esto se puede complementar con una mejor observabilidad con el aprovechamiento de los paneles de supervisión con Managed Service para Apache Airflow para liderar la excelencia operativa. No solo puedes crear un data lake combinando datos almacenados en Cloud Storage y BigQuery, sin mover ni duplicar datos, sino que también ofrecemos funcionalidades administrativas adicionales para administrar tus fuentes de datos. Knowledge Catalog (anteriormente, Dataplex) habilita un lakehouse, ya que ofrece una capa de administración centralizada para coordinar datos en Cloud Storage y BigQuery. Esto te permite organizar tus datos según las necesidades de tu empresa, para que ya no tengas que limitarte a cómo o dónde se almacenan los datos.
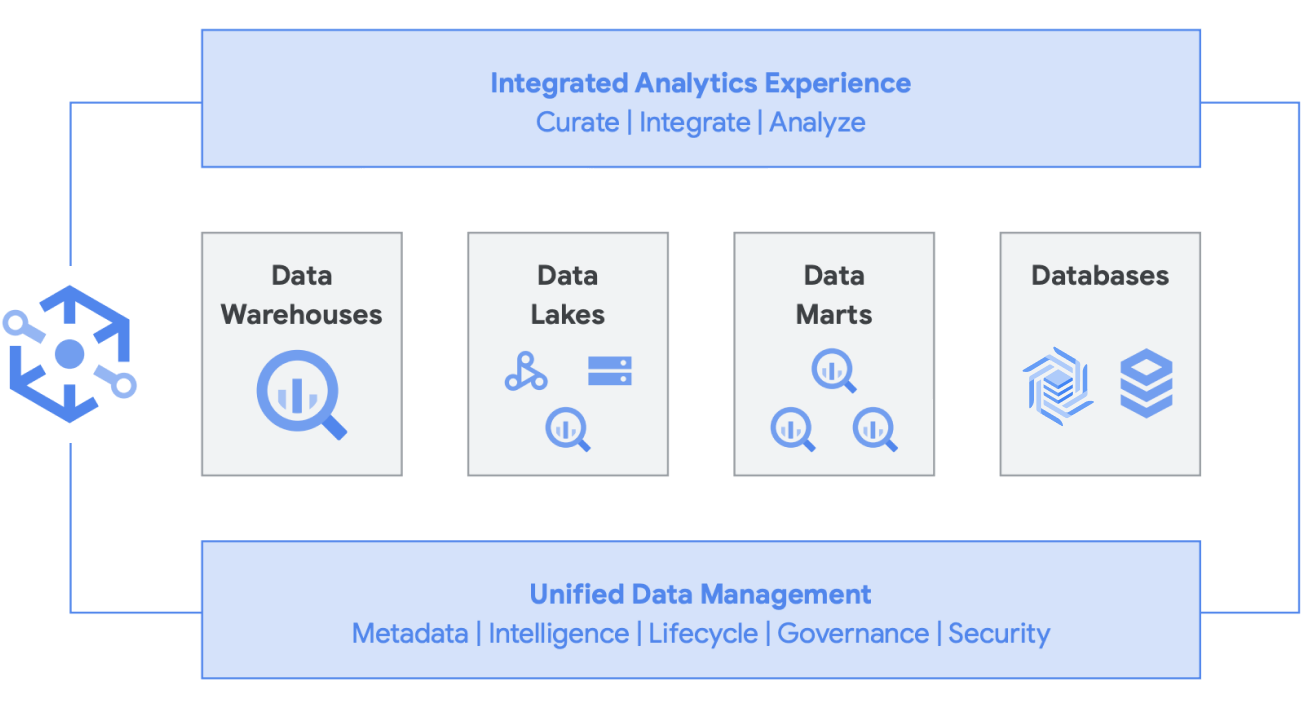
Knowledge Catalog es un tejido de datos inteligente que te permite mantener tus datos distribuidos por la relación precio y rendimiento adecuada, a la vez que haces que todas tus herramientas de estadísticas puedan acceder de forma segura a estos datos. Proporciona una gestión de datos basada en metadatos con calidad y administración de datos integradas, para que dediques menos tiempo a superar los límites y las ineficiencias de la infraestructura, confíes en los datos que tienes y dediques más tiempo a obtener valor de estos datos. Además, proporciona una experiencia de estadísticas integrada que reúne lo mejor de Google Cloud y el código abierto para que puedas seleccionar, proteger, integrar y analizar datos con rapidez a gran escala. Por último, puedes crear una estrategia de análisis que mejore la arquitectura existente y cumpla con tus objetivos de administración financiera.
Malla de datos
La malla de datos se basa en una larga historia de innovación de diversos almacenes de datos y data lakes, en combinación con los modelos de rendimiento de escalabilidad inigualables, las APIs, las DevOps y la integración cercana de los productos de Google Cloud. Con este enfoque, puedes crear con eficacia una solución de datos a pedido. Una malla de datos descentraliza la propiedad de los datos entre los propietarios de datos del dominio, cada uno de los cuales es responsable de proporcionar sus datos como un producto de forma estándar. Una malla de datos también facilita la comunicación entre diferentes partes de la organización con conjuntos de datos distribuidos en distintas ubicaciones. En una malla de datos, la responsabilidad de generar valor a partir de los datos está federada para las personas que mejor lo comprenden. En otras palabras, las personas que crearon los datos o los incorporaron a la organización también deben ser responsables de crear recursos de datos consumibles como productos a partir de los datos que crean. En muchas organizaciones, establecer una “única fuente de información” o una “fuente de datos autorizada” es un desafío debido a la extracción y transformación repetidas de datos en toda la organización sin responsabilidades de propiedad claras sobre los datos recién creados. En la malla de datos, la fuente de datos autorizada es el producto de datos que publica el dominio de origen, con un propietario y administrador de datos asignado claramente que es responsable de esos datos.
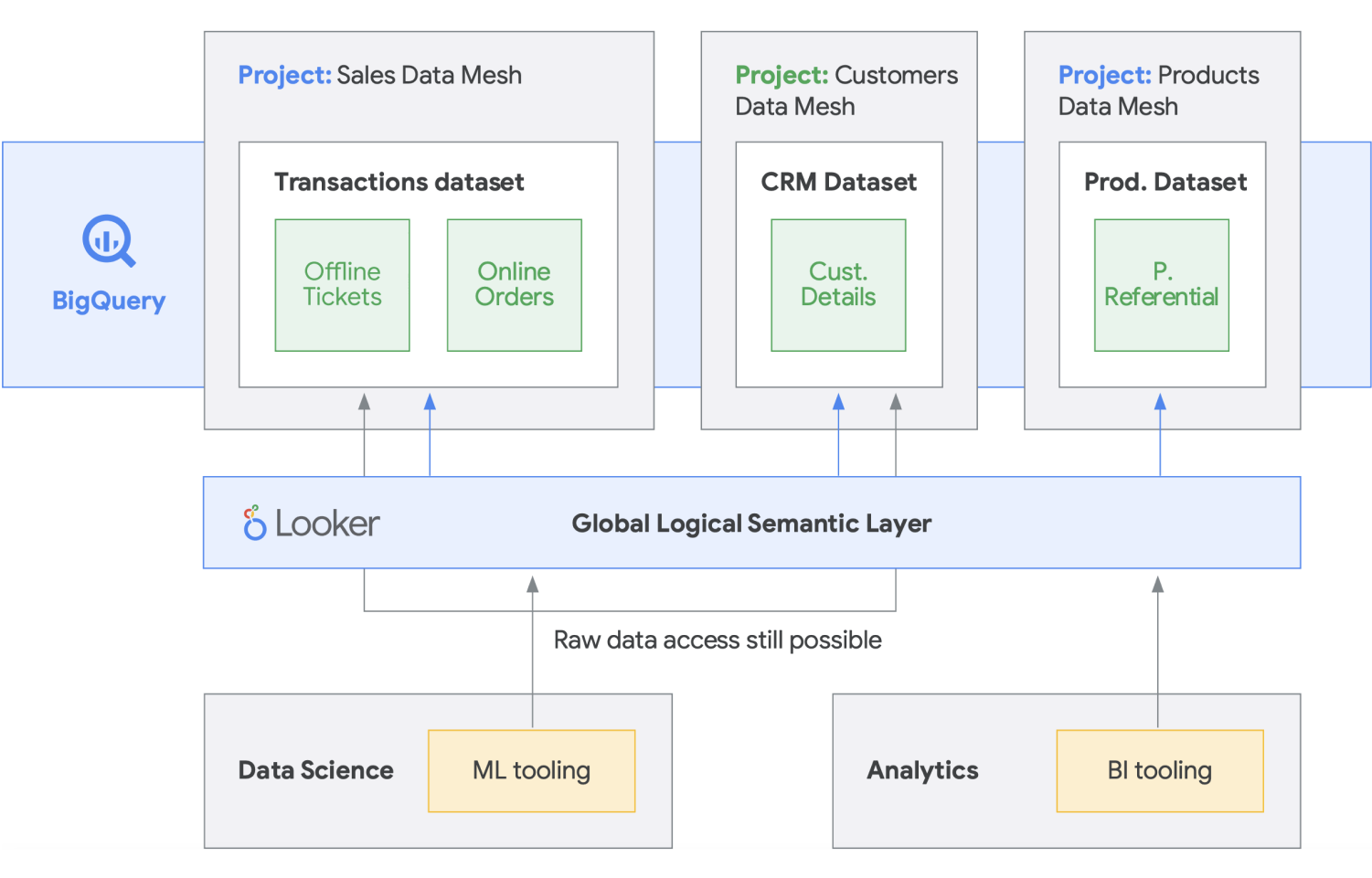
En resumen, la malla de datos promete una propiedad y una arquitectura de datos orientadas al dominio y descentralizadas. Esto es posible gracias a las capas de procesamiento y acceso federadas, como las que proporcionamos en Google Cloud. Además, si tu organización busca obtener más funciones, puedes usar algo como Looker, que puede proporcionar una capa unificada para modelar y acceder a los datos. La plataforma de Looker ofrece una IU de panel único para acceder a la versión más verdadera y actualizada de los datos y las definiciones de tu empresa. Con esta vista unificada de la empresa, puedes elegir o diseñar experiencias de datos que garanticen que las personas y los sistemas reciben los datos de la manera más conveniente para sus necesidades. Encaja perfectamente, ya que permite que científicos de datos, analistas y hasta usuarios empresariales accedan a sus datos con un solo modelo semántico. Los científicos de datos siguen accediendo a los datos sin procesar, pero sin el movimiento y la duplicación de los datos.
Estamos creando funciones adicionales sobre nuestros productos de trabajo, como BigQuery, para facilitar la creación y administración de conjuntos de datos. Analytics Hub permite crear intercambios de datos privados, en los que los administradores de intercambios (también conocidos como selectores de datos) otorgan permisos para publicar datos y suscribirse a ellos en el intercambio a personas o grupos específicos, tanto dentro de la empresa como externamente. socios comerciales o compradores.
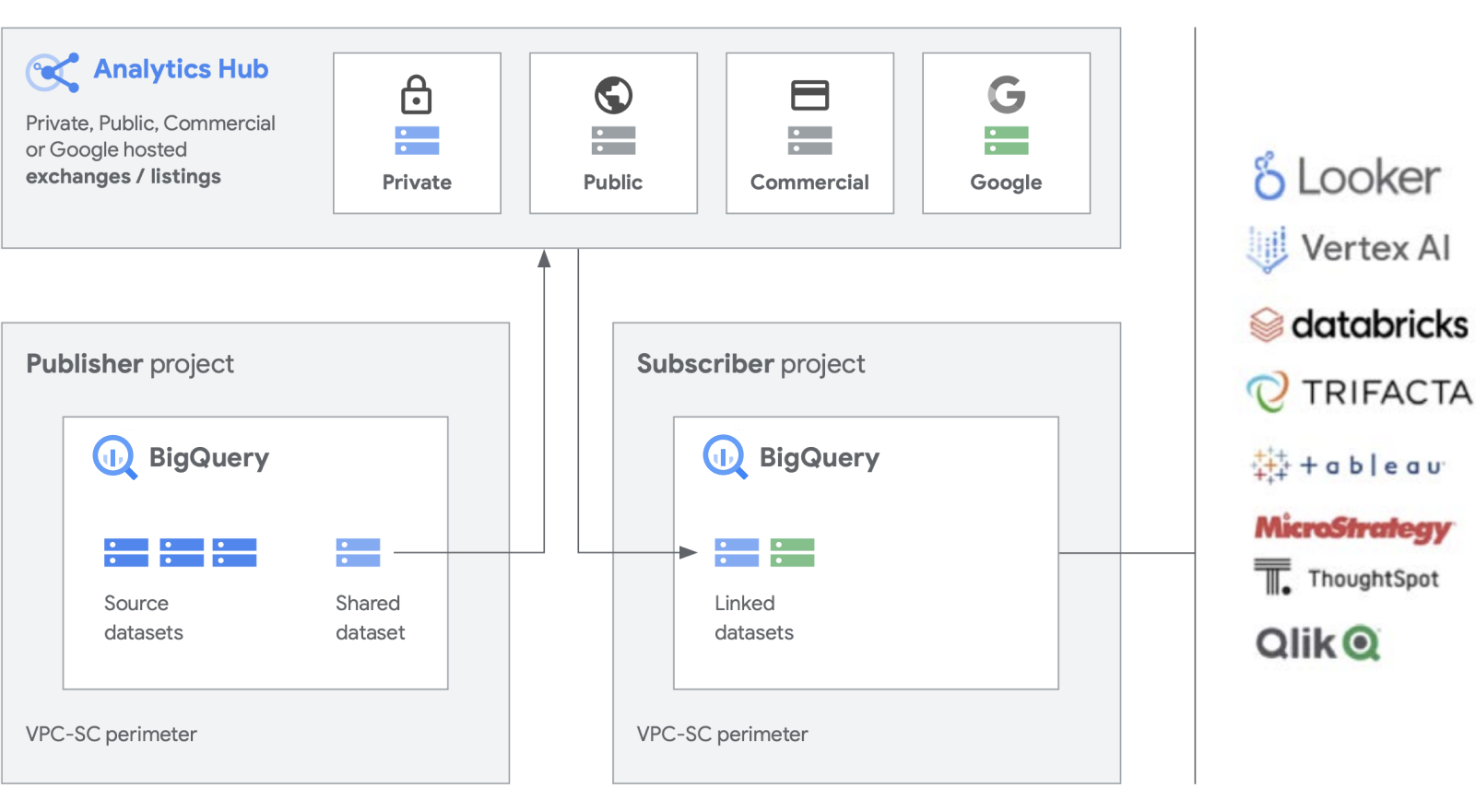
Publica y descubre elementos compartidos, y suscríbete a ellos, incluidos los formatos de código abierto, con la tecnología de escalabilidad de BigQuery. Los publicadores pueden ver las métricas de uso agregadas. Los proveedores de datos pueden llegar a los clientes empresariales de BigQuery con datos, estadísticas, modelos de AA o visualizaciones y aprovechar Cloud Marketplace para monetizar sus aplicaciones, estadísticas o modelos. Esto también es similar a la forma en que los conjuntos de datos públicos de BigQuery se administran a través de un intercambio administrado por Google. Impulsa la innovación con acceso a conjuntos de datos únicos de Google, conjuntos de datos comerciales o de la industria, conjuntos de datos públicos o intercambios de datos seleccionados de tu organización o ecosistema de socios.
Cómo abordar los problemas heredados
Si bien suena genial crear una plataforma de datos completamente nueva, entendemos que no todas las empresas estarán en posición de hacerlo. La mayoría se ocupa de sistemas heredados existentes que se deben migrar, portar o aplicar parches hasta que se puedan reemplazar. Trabajamos con los clientes en todas las etapas de su recorrido en la plataforma de datos y tenemos soluciones para satisfacer tu situación.
Por lo general, los clientes presentan tres categorías de migración: lift-and-shift, lift-and-shift y modernización total. Para la mayoría de las empresas, sugerimos comenzar con la efectividad y el cambio de plataforma, ya que ofrece una migración de alto impacto con la menor cantidad posible de interrupciones y riesgo. Con esta estrategia, migras tus datos a BigQuery o Managed Service para Apache Spark desde tus almacenes de datos heredados y clústeres de Hadoop. Una vez que se transfieren los datos, puedes optimizar las canalizaciones de datos y las consultas para mejorar el rendimiento. Con una estrategia de migración lift-and-shift, puedes hacerlo en fases, según la complejidad de tus cargas de trabajo. Dada su complejidad, recomendamos este enfoque para clientes empresariales grandes que tengan una TI centralizada y varias unidades de negocios.
La segunda estrategia de migración que vemos con mayor frecuencia es una modernización completa como primer paso. Esto proporciona un descanso limpio del pasado porque se está ampliando con un enfoque nativo de la nube. Se compila de forma nativa en Google Cloud, pero, como cambias todo de una sola vez, la migración puede ser más lenta si tienes varios entornos heredados grandes.

Una interrupción heredada limpia requiere volver a escribir los trabajos y cambiar aplicaciones diferentes. Sin embargo, también proporciona una mayor velocidad y agilidad, además del menor costo total de propiedad a largo plazo en comparación con otros enfoques. Esto se debe a dos motivos principales: tus aplicaciones ya están optimizadas y no necesitan ser actualizadas. Además, una vez que migres las fuentes de datos, no será necesario que administres dos entornos al mismo tiempo. Este enfoque es más adecuado para organizaciones centradas en ingeniería o nativas digitales con pocos entornos heredados.
Por último, el enfoque más conservador es usar lift-and-shift, que recomendamos como una solución táctica a corto plazo para trasladar tu patrimonio de datos a la nube. Puedes migrar tus plataformas existentes con la modalidad lift-and-shift y seguir usándolas como antes, pero en el entorno de Google Cloud. Esto se aplica a entornos como Teradata y Databricks, por ejemplo, para reducir el riesgo inicial y permitir que se ejecuten las aplicaciones. Sin embargo, esto trae el entorno aislado existente a la nube en lugar de transformarlo, por lo que no te beneficiarás del rendimiento de una plataforma compilada de forma nativa en Google Cloud. Sin embargo, podemos ayudarte con una migración completa a los productos nativos de Google Cloud para que puedas aprovechar la interoperabilidad y crear una plataforma de datos de estadísticas completamente moderna en Google Cloud.
¿Táctica o estratégica?
Creemos que los diferenciadores clave de una plataforma de datos de estadísticas compilada en Google Cloud son que es abierta, inteligente, flexible y está estrechamente integrada. Hay muchas soluciones en el mercado que ofrecen soluciones tácticas que pueden resultar cómodas y familiares. Sin embargo, estos suelen proporcionar una solución a corto plazo y solo acumulan problemas técnicos y de organización con el tiempo.
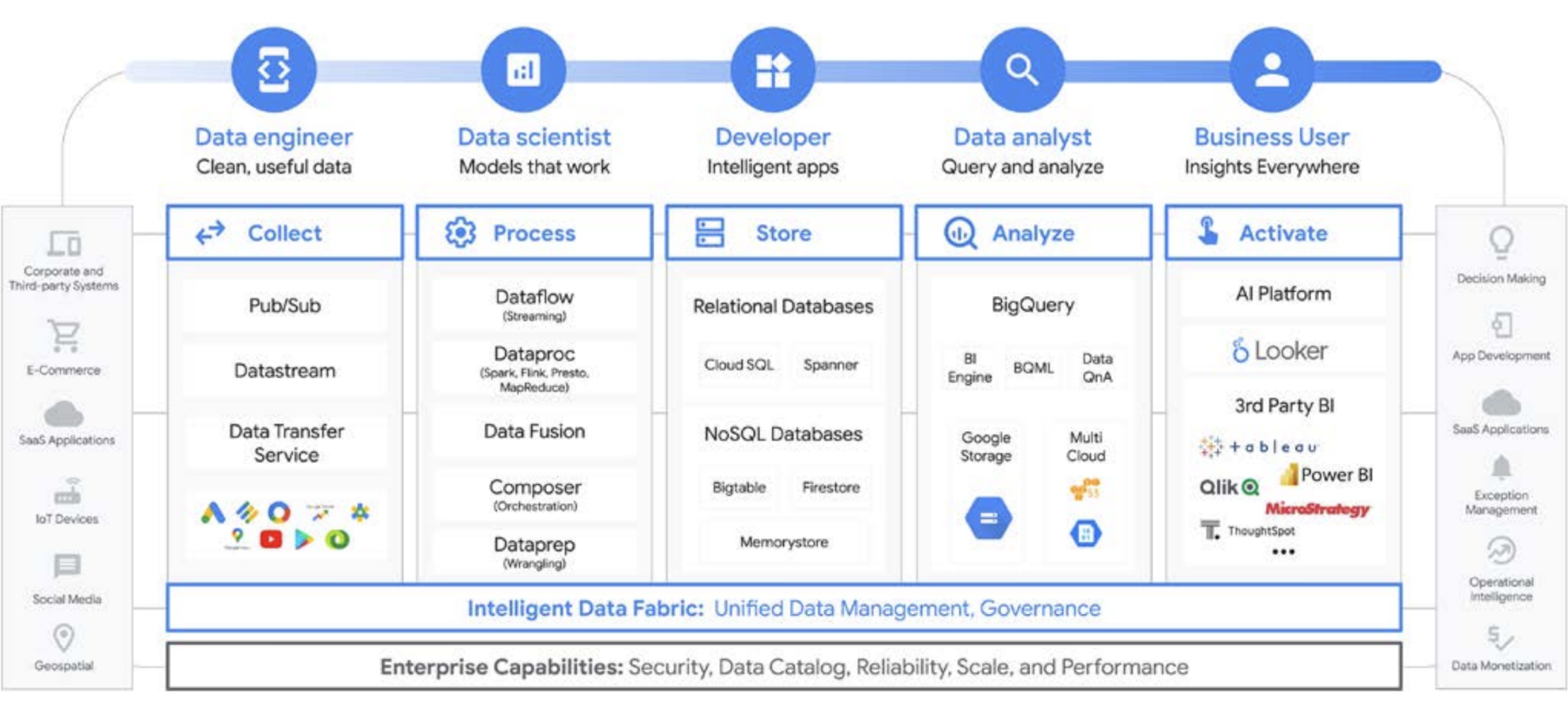
Google Cloud simplifica en gran medida el análisis de datos. Puedes liberar el potencial oculto en tus datos con un enfoque sin servidores y nativo de la nube que separa el almacenamiento del procesamiento y te permite analizar gigabytes y petabytes de datos en minutos. Esto te permite quitar las restricciones tradicionales de escala, rendimiento y costo para formular preguntas sobre los datos y resolver problemas empresariales. Como resultado, es más fácil poner en funcionamiento estadísticas en toda la empresa con un tejido de datos único y confiable.
¿Cuáles son los beneficios?
- Mantiene tu enfoque exclusivamente en el análisis en lugar de la infraestructura.
- Resuelve cada etapa del ciclo de vida del análisis de datos, desde la transferencia hasta la transformación y el análisis, la inteligencia empresarial y mucho más
- Crea una base de datos sólida para poner en funcionamiento el aprendizaje automático.
- Permite aprovechar las mejores tecnologías de código abierto para tu organización.
- Escala para satisfacer las necesidades de tu empresa, en especial a medida que aumentas el uso de los datos para impulsar tu negocio y la transformación digital
Una plataforma de datos de estadísticas unificada y moderna compilada en Google Cloud te brinda las mejores capacidades de un data lake y un almacén de datos, pero con una integración más estrecha en la plataforma de IA. Puedes procesar automáticamente datos en tiempo real de miles de millones de eventos de transmisión y entregar estadísticas en hasta milisegundos para responder a las necesidades cambiantes de los clientes. Nuestros servicios de IA líderes en la industria pueden optimizar la toma de decisiones de tu organización y las experiencias de los clientes, lo que te ayuda a cerrar la brecha entre las estadísticas descriptivas y prescriptivas sin tener que contratar un nuevo equipo. Puedes mejorar tus habilidades existentes para escalar el impacto de la IA con inteligencia integrada y automatizada.
Da el siguiente paso
¿Te interesa obtener más información sobre cómo la plataforma de datos de Google puede transformar la forma en que tu empresa maneja los datos? Comunícate con nosotros para comenzar.
¿Necesitas ayuda para comenzar?
Comunicarse con VentasTrabaja con un socio confiable
Buscar un socioSigue explorando
Ver todos los productos


















