Crea una plataforma de datos de analíticas moderna y unificada con Google Cloud
Descubre los puntos de decisión necesarios a la hora de crear una plataforma de datos de analíticas moderna y unificada basada en Google Cloud.
Autores: Firat Tekiner y Susan Pierce

Información general
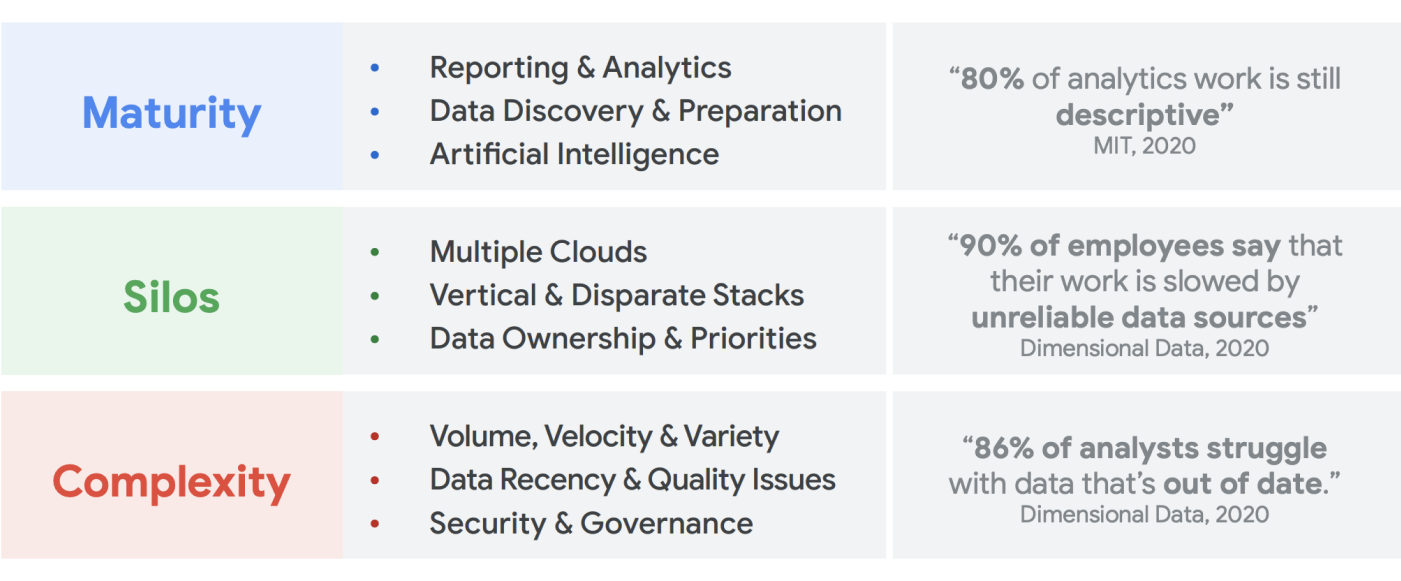
No nos faltan datos que se puedan generar. Estudio de IDC que indica que los datos mundiales aumentarán a 175 zettabytes de aquí al 20251. El volumen de datos que se generan cada día es asombroso y cada vez es más difícil para las empresas recogerlos, almacenarlos y organizarlos de una forma que sea accesible y utilizable. De hecho, el 90 % de los profesionales de datos afirman que fuentes de datos poco fiables han ralentizado su trabajo. Aproximadamente el 86 % de los analistas de datos se enfrentan a datos obsoletos, y más del 60 % de los trabajadores de datos se ven afectados por la necesidad de esperar a los recursos de ingeniería cada mes mientras se limpian y preparan sus datos.2.
Las estructuras organizativas y las decisiones sobre arquitectura ineficientes contribuyen a la brecha que las empresas tienen entre agregar datos y hacer que les funcionen. Las empresas quieren pasarse a la nube para modernizar sus sistemas de analíticas de datos, pero eso por sí solo no soluciona los problemas subyacentes relacionados con las fuentes de datos en silos y los flujos de procesamiento de procesamiento frágiles. Las decisiones estratégicas sobre propiedad de los datos y las decisiones técnicas sobre los mecanismos de almacenamiento deben tomarse de forma integral para que la plataforma de datos tenga más éxito en tu organización.
En este artículo, veremos los puntos de decisión necesarios para crear una plataforma de datos de analíticas moderna y unificada basada en Google Cloud.
En las dos últimas décadas, el Big Data ha generado oportunidades increíbles para las empresas. Sin embargo, para las organizaciones es difícil ofrecer datos relevantes, útiles y oportunos a los usuarios empresariales. Los estudios demuestran que el 86 % de los analistas sigue teniendo dificultades con datos obsoletos3 y solo el 32 % de las empresas creen que están obteniendo un valor tangible a partir de sus datos4. El primero es la actualización de los datos. El segundo problema radica en la dificultad de integrar sistemas distintos y antiguos en varios silos. Las empresas están migrando a la nube, pero eso no resuelve el problema real de los sistemas antiguos que podrían haberse estructurado verticalmente para satisfacer las necesidades de una sola unidad de negocio.
Al planificar las necesidades de datos de la organización, es fácil generalizar en exceso y considerar una estructura única y simplificada en la que hay un conjunto de fuentes de datos coherentes, un almacén de datos empresariales, un conjunto de semánticas y una herramienta para la inteligencia empresarial. Eso podría funcionar para una organización muy pequeña y muy centralizada, e incluso podría funcionar para una sola unidad de negocio con su propio equipo integrado de TI e ingeniería de datos. Sin embargo, en la práctica, ninguna organización es tan sencilla y siempre surgen complejidades sorprendentes relacionadas con la ingestión, el procesamiento o el uso de datos que complican aún más la tarea.
Lo que hemos observado al hablar con cientos de clientes es la necesidad de adoptar un enfoque más integral en lo que respecta a los datos y las analíticas, una plataforma que pueda satisfacer las necesidades de varias unidades de negocio y perfiles ficticios con el menor número de pasos redundantes posible para procesar los datos. Es algo más que una nueva arquitectura o un nuevo conjunto de componentes de software que deben comprarse; esto requiere que las empresas tengan en cuenta su madurez de datos general y hagan cambios sistémicos y organizativos, además de actualizaciones técnicas.
Para cuando termine el 2024, el 75 % de las empresas habrán pasado de hacer pruebas piloto de inteligencia artificial a implementarla en sus operaciones, lo que supondrá multiplicar por cinco los datos de streaming y las infraestructuras de análisis". Probar la IA es muy fácil con un equipo de científicos de datos que trabaja en un entorno aislado. Sin embargo, el principal reto que impide que esa información se incluya en los sistemas de producción es la fricción organizativa y de arquitectura que mantiene segmentada la propiedad de los datos. En consecuencia, la mayoría de los datos que se incorporan a las operaciones comerciales de una organización son de naturaleza descriptiva, y los análisis predictivos se relegan al ámbito de un equipo de investigación.

Una plataforma para todos los usuarios a lo largo del ciclo de vida de los datos
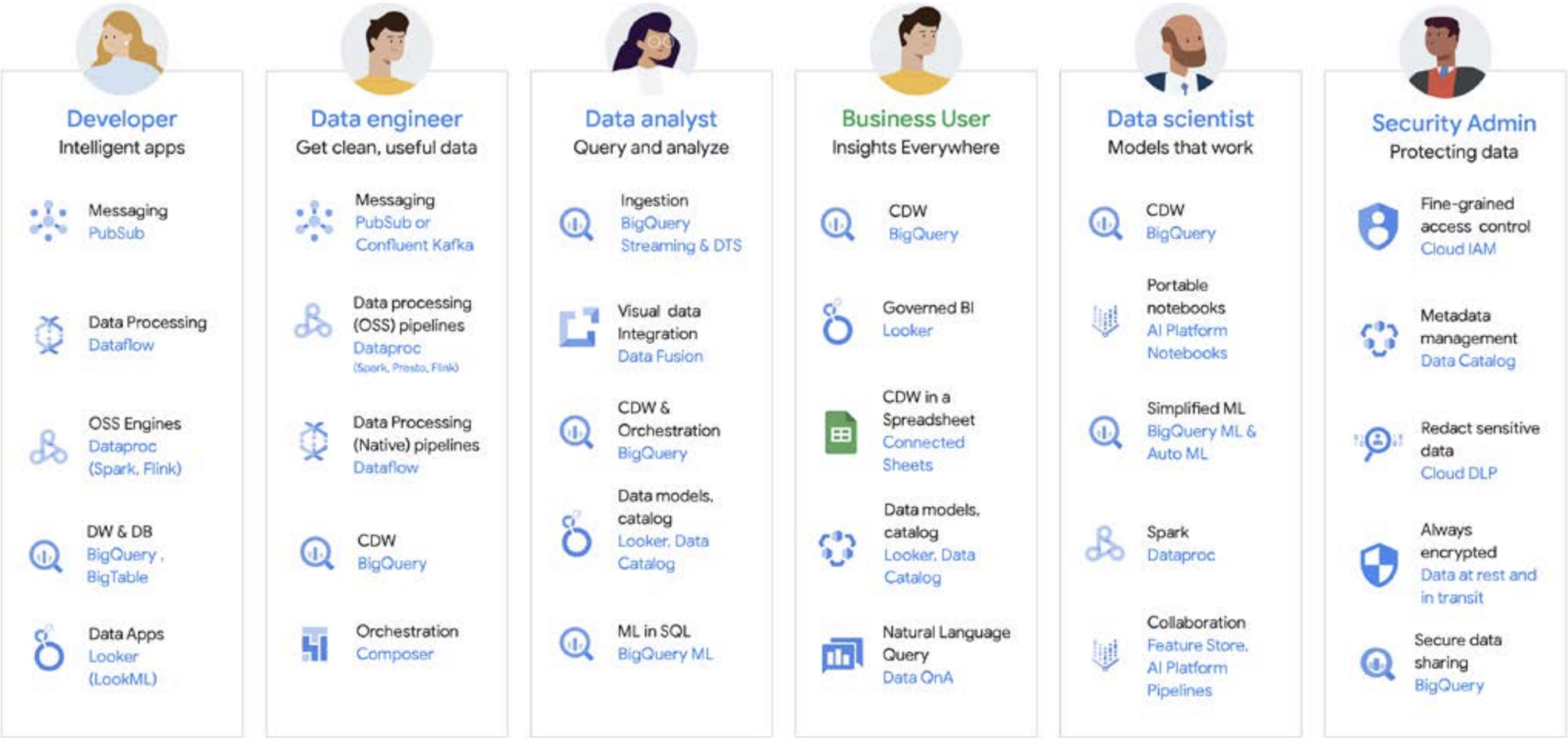
El trabajo de datos rara vez lo hace una sola persona. hay muchos usuarios relacionados con los datos en una organización que desempeñan un papel importante en el ciclo de vida de los datos. Cada uno de ellos tiene su propia perspectiva sobre la gobernanza de datos, la actualización, la descubribilidad, los metadatos, los plazos de procesamiento y la posibilidad de consultar datos, entre otros aspectos. En la mayoría de los casos, utilizan sistemas y software diferentes para operar con los mismos datos en diferentes fases de procesamiento.
Veamos, por ejemplo, el ciclo de vida del aprendizaje automático. Un ingeniero de datos puede ser responsable de que el equipo de científicos de datos disponga de datos actualizados, con las restricciones de seguridad y privacidad adecuadas. Los científicos de datos pueden crear conjuntos de datos de entrenamiento y prueba basados en un conjunto dorado de fuentes de datos previamente agregadas del ingeniero de datos, crear y probar modelos y poner la información a disposición de otro equipo. Es posible que un ingeniero de aprendizaje automático sea el responsable de empaquetar el modelo para el despliegue en los sistemas de producción, de una forma que no interfiera en otros flujos de procesamiento de datos. Es posible que un gestor de productos o un analista empresarial consulten estadísticas derivadas usando Data QnA (una interfaz de lenguaje natural para hacer análisis de datos de BigQuery), software de visualización o puede estar consultando el conjunto de resultados directamente a través de un IDE o una interfaz de línea de comandos. Existen infinidad de usuarios con necesidades distintas, por lo que hemos creado una plataforma compacta para ofrecer sus servicios a todos. Google Cloud satisface las necesidades de cada negocio de los clientes gracias a las herramientas que necesitan.
La decisión sobre el Big Data: ¿almacén de datos o data lake?
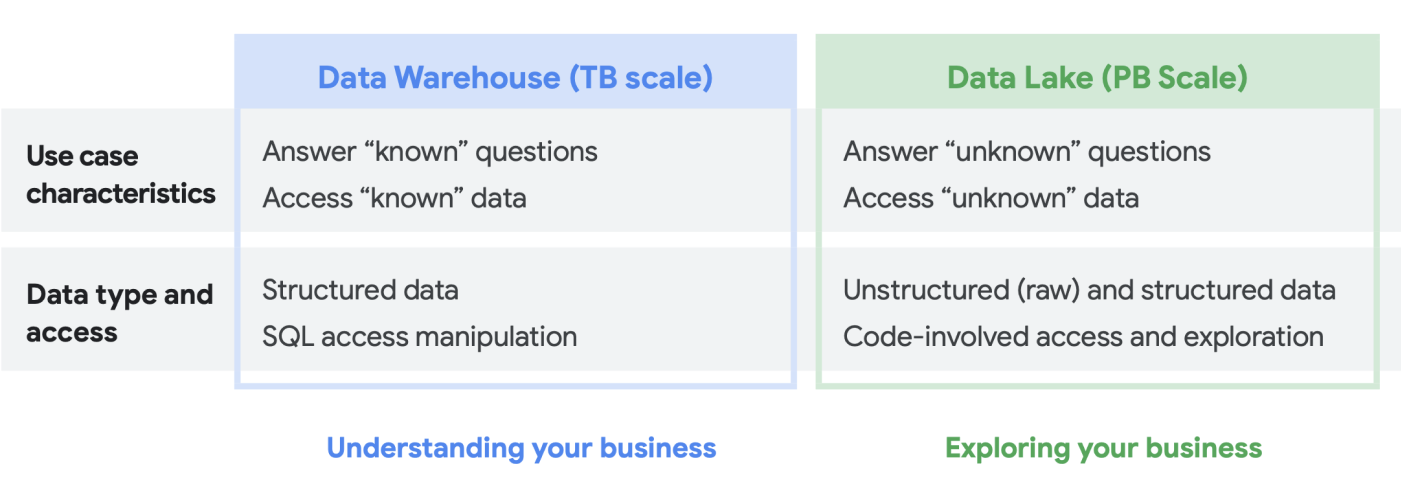
Cuando hablamos con los clientes sobre sus necesidades de analíticas de datos, a menudo oímos la pregunta qué necesito: un data lake o un almacén de datos. Dada la variedad de usuarios de datos y necesidades dentro de una organización, esta puede ser una pregunta difícil de responder que depende del uso previsto, los tipos de datos y el personal.
- Si sabes qué conjuntos de datos debes analizar, conoces bien su estructura y tienes un conjunto de preguntas que debes responder, lo más probable es que estés buscando un almacén de datos.
- Por otro lado, si necesitas visibilidad en varios tipos de datos, no estás seguro de los tipos de análisis que tendrás que ejecutar, buscas oportunidades que descubrir en lugar de presentar estadísticas, y tienes los recursos para gestionar y examinar eficazmente entorno, es probable que un data lake se adapte mejor a tus necesidades
Pero hay más aspectos que influyen en la decisión, así que vamos a ver algunos de los retos organizativos de cada uno. Los almacenes de datos suelen ser difíciles de gestionar. Los sistemas antiguos que han funcionado bien en los últimos 40 años han demostrado ser muy caros y suponer muchos retos en cuanto a la actualización de los datos, el escalado y los elevados costes. Además, no pueden proporcionar fácilmente funciones de IA o en tiempo real sin añadirlas como complementos después. Estos problemas no solo se producen en los almacenes de datos antiguos on‐premise. incluso lo vemos con los nuevos almacenes de datos basados en la nube. Muchos no ofrecen funciones de IA integradas, a pesar de sus afirmaciones. Estos nuevos almacenes de datos son básicamente los mismos entornos antiguos, pero que se han trasladado a la nube. Los usuarios de los almacenes de datos suelen ser analistas, que a menudo están integrados en una unidad de negocio específica. Puede que se les ocurran ideas sobre conjuntos de datos adicionales que podrían serles útiles para ampliar sus conocimientos sobre la empresa. También pueden sugerir mejoras en el análisis, el tratamiento de datos y los requisitos de las funciones de inteligencia empresarial.
Sin embargo, en una organización tradicional, a menudo no tienen acceso directo a los propietarios de los datos ni pueden influir fácilmente en los responsables de la toma de decisiones técnicas que deciden los conjuntos de datos y las herramientas. Además, como se mantienen separados de los datos en bruto, no pueden probar hipótesis ni comprender mejor los datos subyacentes. Los data lakes tienen sus propios retos. En teoría, son de bajo coste y fáciles de escalar, pero muchos de nuestros clientes han visto una realidad diferente en sus lagos de datos on-premise. Planificar y aprovisionar el almacenamiento suficiente puede ser caro y difícil, especialmente para las organizaciones que producen cantidades muy variables de datos. Los lagos de datos on‐premise pueden ser débiles y el mantenimiento de los sistemas requiere tiempo. En muchos casos, los ingenieros que, de otra forma, desarrollarían nuevas funciones, se ven relegados a cuidar y alimentar los clústeres de datos. Dicho de manera más contundente, es que están manteniendo el valor en lugar de crear uno nuevo. En general, el coste total de propiedad es mayor de lo esperado para muchas empresas. Además, el gobierno de datos no se puede resolver fácilmente en distintos sistemas, sobre todo cuando hay distintas partes de la organización que utilizan modelos de seguridad diferentes. Como consecuencia, los data lakes se aíslan y segmentan, lo que dificulta compartir datos y modelos entre equipos.
Los usuarios de data lakes suelen estar más cerca de las fuentes de datos en bruto y cuentan con herramientas y capacidades para consultar los datos. En las organizaciones tradicionales, estos usuarios tienden a centrarse en los datos en sí y, con frecuencia, están a una distancia del resto de la empresa. Esta desconexión implica que las unidades de negocio pierden la oportunidad de encontrar estadísticas que les ayuden a avanzar en sus objetivos de negocio y conseguir más ingresos, menores costes, menos riesgos y nuevas oportunidades. Teniendo en cuenta estas repercusiones, muchas empresas acaban con un enfoque híbrido, en el que se configura un data lake para convertir algunos datos en un almacén de datos, o bien un almacén de datos tiene un data lake adicional para hacer pruebas y análisis adicionales. Sin embargo, dado que hay varios equipos que diseñan sus propias arquitecturas de datos para adaptarse a sus necesidades particulares, compartir datos y establecer la fidelidad son aún más complicados para un equipo de TI centralizado. En lugar de tener equipos independientes con objetivos independientes (en el que uno explora los datos de la empresa y el otro la comprende), puede combinar estas funciones y sus sistemas de datos para crear un círculo virtuoso en el que conocer mejor el negocio impulsa la exploración dirigida, y esa exploración impulsa un mejor conocimiento del negocio.
Utiliza el espacio de un almacén de datos como un data lake
Puedes crear un almacén o un data lake por separado en Google Cloud, pero no tienes que elegir uno u otro. En muchos casos, los productos subyacentes que utilizan nuestros clientes son los mismos en ambos casos, y la única diferencia entre la implementación de data lake y el de su almacén de datos es la política de acceso a datos que se emplea. De hecho, ambos términos están empezando a converger en un conjunto de funciones más unificado: una moderna plataforma de datos de analíticas. Veamos cómo funciona en Google Cloud.
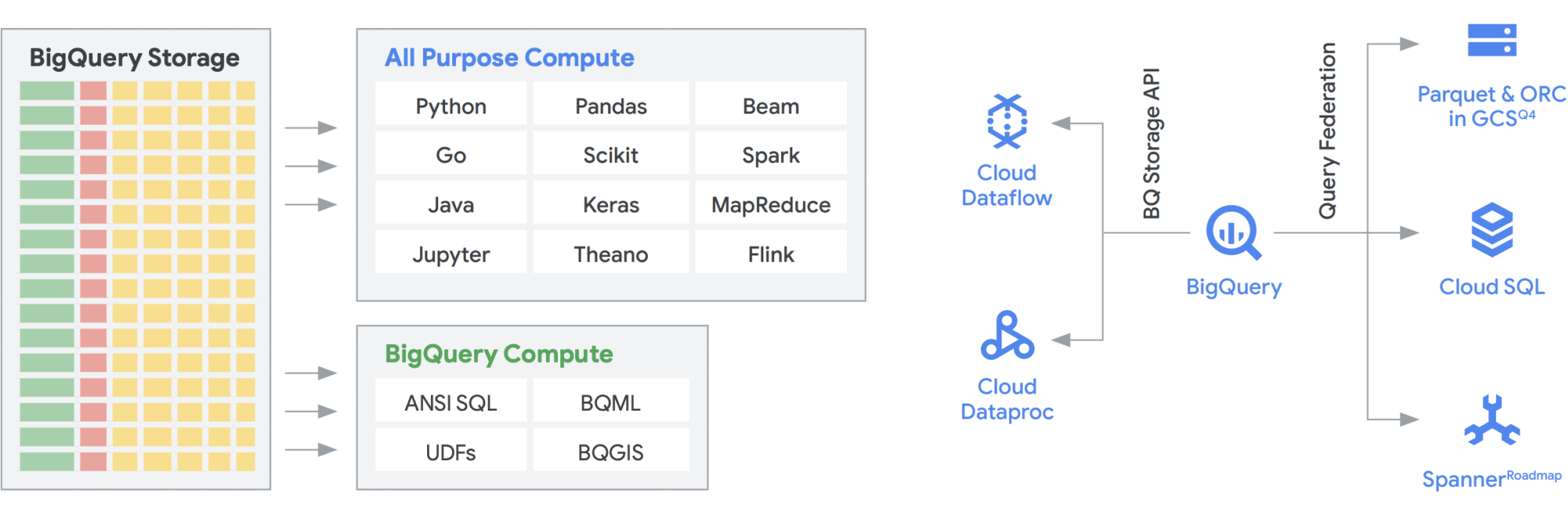
La API Storage de BigQuery permite utilizar el almacenamiento de BigQuery (por ejemplo, Cloud Storage) en otros sistemas, como Dataflow y Managed Service for Apache Spark. Esto permite romper las barreras del almacenamiento de datos y permite ejecutar marcos de datos de alto rendimiento en BigQuery. En otras palabras, la API Storage de BigQuery permite que tu almacén de datos de BigQuery actúe como un data lake. ¿Qué usos prácticos tiene? Para empezar, hemos creado una serie de conectores (por ejemplo, MapReduce, Hive o Spark) para que puedas ejecutar tus cargas de trabajo de Hadoop y Spark directamente en tus datos en BigQuery. Ya no necesitas un data lake además de tu almacén de datos. Dataflow es una herramienta increíblemente potente para el procesamiento de streaming y por lotes. Actualmente, puedes ejecutar tareas de Dataflow sobre datos de BigQuery y enriquecerlos con datos de Pub/Sub, Spanner o cualquier otra fuente de datos.
BigQuery puede escalar de forma independiente tanto el almacenamiento como los recursos de computación, y cada uno de ellos funciona sin servidor, lo que permite un escalado ilimitado para satisfacer la demanda con independencia del uso que hagan los diferentes equipos, herramientas y patrones de acceso. Todas las aplicaciones anteriores se pueden ejecutar sin afectar al rendimiento de ninguna otra tarea que acceda a BigQuery al mismo tiempo. Además, la API Storage de BigQuery proporciona una red a nivel de petabit, que mueve los datos entre los nodos para satisfacer una solicitud de consulta, lo que lleva a un rendimiento similar a una operación en memoria. Además, permite la federación con formatos de datos populares de Hadoop, como Parquet y ORC directamente, así como con bases de datos NoSQL y OLTP. Puedes ir un paso más allá con las funciones que ofrece Dataflow SQL, que está insertado en BigQuery. De esta forma, podrás combinar los flujos con las tablas de BigQuery o con los datos ubicados en archivos, lo que te permitirá crear de forma eficaz una arquitectura lambda que te permitirá ingerir grandes cantidades de datos por lotes y de streaming, así como proporcionar una capa de servicio para responder a las consultas. El motor de BI de BigQueryy las vistas materializadas facilitan aún más la eficiencia y el rendimiento en esta arquitectura multiusos.
Plataforma de analíticas inteligentes de Google con la tecnología de BigQuery
Las soluciones de datos sin servidor son absolutamente necesarias para que tu empresa pueda ir más allá de los silos de datos y adentrarse en el ámbito de la información valiosa y las acciones. Todos nuestros servicios principales de analíticas de datos no tienen servidor y se integran a la perfección.

La gestión del cambio suele ser uno de los aspectos más difíciles de incorporar una tecnología nueva en una organización. En Google Cloud, queremos llegar a nuestros clientes allá donde estén proporcionándoles herramientas, plataformas e integraciones conocidas tanto para desarrolladores como para usuarios empresariales. Nuestra misión es ayudar a tu organización a transformar y rediseñar su negocio digitalmente más rápidamente mediante la innovación basada en datos. En lugar de depender de proveedores, Google Cloud ofrece a las empresas opciones para realizar integraciones sencillas y optimizadas con entornos on‐premise, otras soluciones en la nube e incluso el perímetro para formar una nube híbrida:
- BigQuery Omni elimina la necesidad de transferir los datos de un entorno a otro y, en su lugar, lleva las analíticas a los datos independientemente del entorno.
- Apache Beam, el SDK que se utiliza en Dataflow, ofrece transferencia y portabilidad a los ejecutores como Apache Spark y Apache Flink.
- Para las organizaciones que quieren ejecutar Apache Spark o Apache Hadoop, Google Cloud proporciona Managed Service for Apache Spark
A la mayoría de los usuarios les preocupan los datos que tienen, no el sistema en el que se encuentran. Lo más importante es poder acceder a los datos que necesitan en el momento oportuno. Así que, en general, el tipo de plataforma no importa para los usuarios, siempre y cuando puedan acceder a datos actualizados y utilizables con herramientas conocidas, ya estén explorando conjuntos de datos, gestionando fuentes entre almacenes de datos, ejecutando consultas ad hoc o desarrollando herramientas internas de inteligencia empresarial para colaboradores executivos.
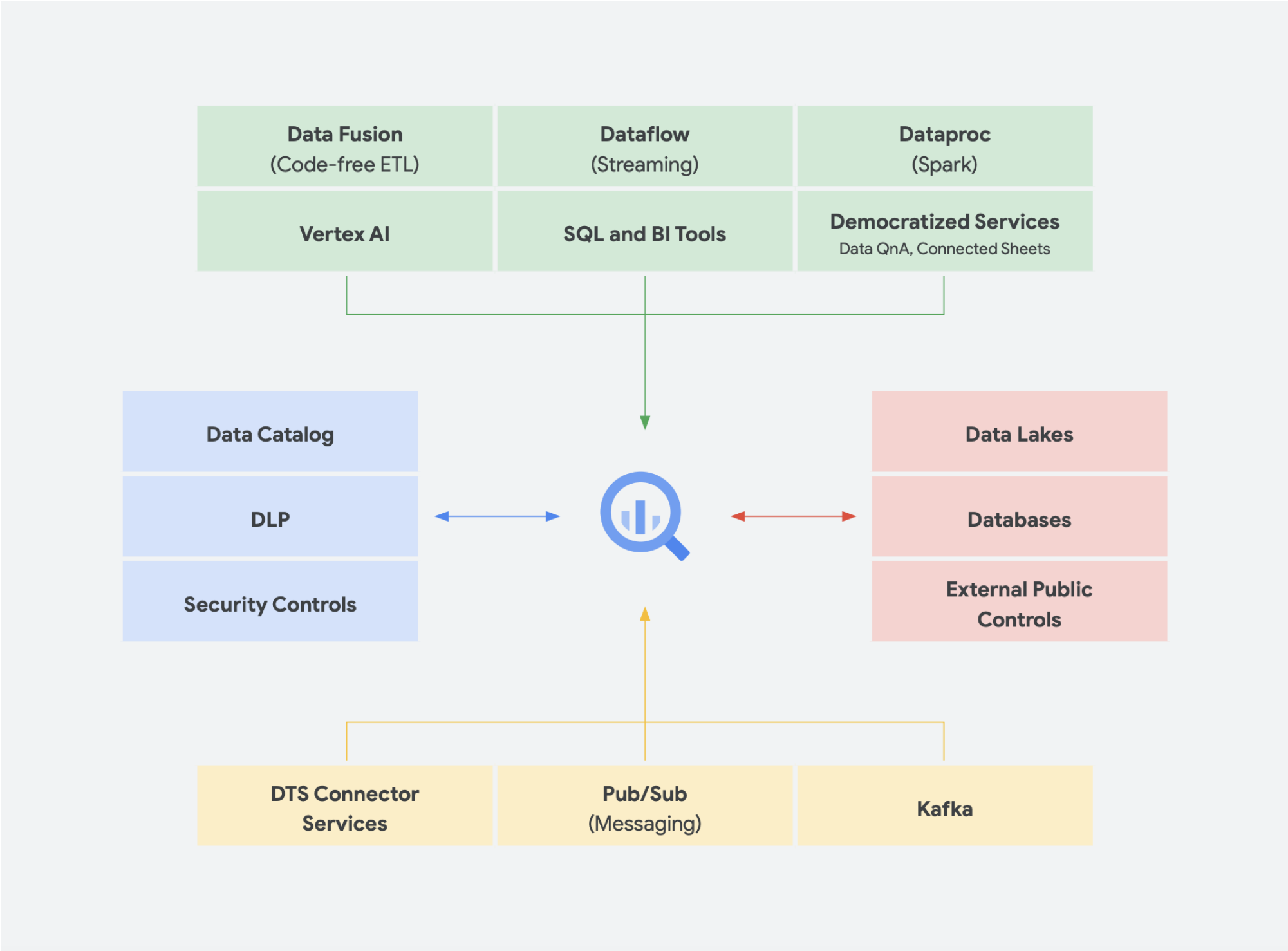
Tendencias emergentes
Continuando con la convergencia de un data lake y un almacén de datos en una plataforma de datos de analíticas unificada, hay otras soluciones de datos que están ganando terreno. Por ejemplo, hemos visto cómo surgieron muchos conceptos relacionados con los lagos y las mallas de datos. Puede que hayas oído alguna vez estos términos. Algunas no son nuevas y llevan años utilizando diferentes formas y formatos. Sin embargo, funcionan muy bien en el entorno de Google Cloud. Veamos en detalle cómo serían las mallas de datos y un lakehouse en Google Cloud y cómo influyen en el uso compartido de datos dentro de una organización. Los lakehouses y las mallas de datos no se excluyen mutuamente, pero ayudan a resolver distintos retos dentro de una organización. Sin embargo, una favorece a los datos, mientras que la otra favorece a los equipos. Las mallas de datos permiten que los usuarios no se fijen en los cuellos de botella de un equipo y, por lo tanto, permiten toda la pila de datos. Además, descompone los silos en unidades organizativas más pequeñas en una arquitectura que proporciona acceso a los datos de forma federada. Lakehouse aúna el almacén de datos y el data lake, lo que permite usar distintos tipos de datos y aumentar el volumen de datos. De este modo, resulta más fácil el uso de esquemas sobre lecturas en lugar de de esquemas sobre escritura, una función de los data lakes que se creía que ayudaba a eliminar algunas de las brechas de rendimiento de los almacenes de datos empresariales. Además, esta arquitectura adopta una gobernanza de datos más rigurosa, algo que los data lakes no suelen tener.

Lakehouse
Como se ha mencionado anteriormente, la API de Storage de BigQuery te permite tratar tu almacén de datos como un data lake. Las tareas de Spark que se ejecutan en Managed Service for Apache Spark o en entornos de Hadoop similares pueden utilizar los datos almacenados en BigQuery, en lugar de necesitar un medio de almacenamiento independiente, ya que el almacenamiento se hace fuera del almacén de datos. La pura potencia de computación que se desacopla del almacenamiento en BigQuery permite la transformación basada en SQL y utiliza vistas en diferentes capas de estas transformaciones. Esto nos lleva a una estrategia del tipo ELT y permite una plataforma de procesamiento de datos más ágil. Al utilizar ELT en lugar de ETL, BigQuery permite que las transformaciones basadas en SQL se almacenen como vistas lógicas. Aunque volcar todos los datos en bruto en un almacén de datos puede ser caro con un almacén de datos tradicional, el almacenamiento en BigQuery no conlleva ningún coste adicional. Su precio es bastante similar al del almacenamiento de blob de Google Cloud Storage.
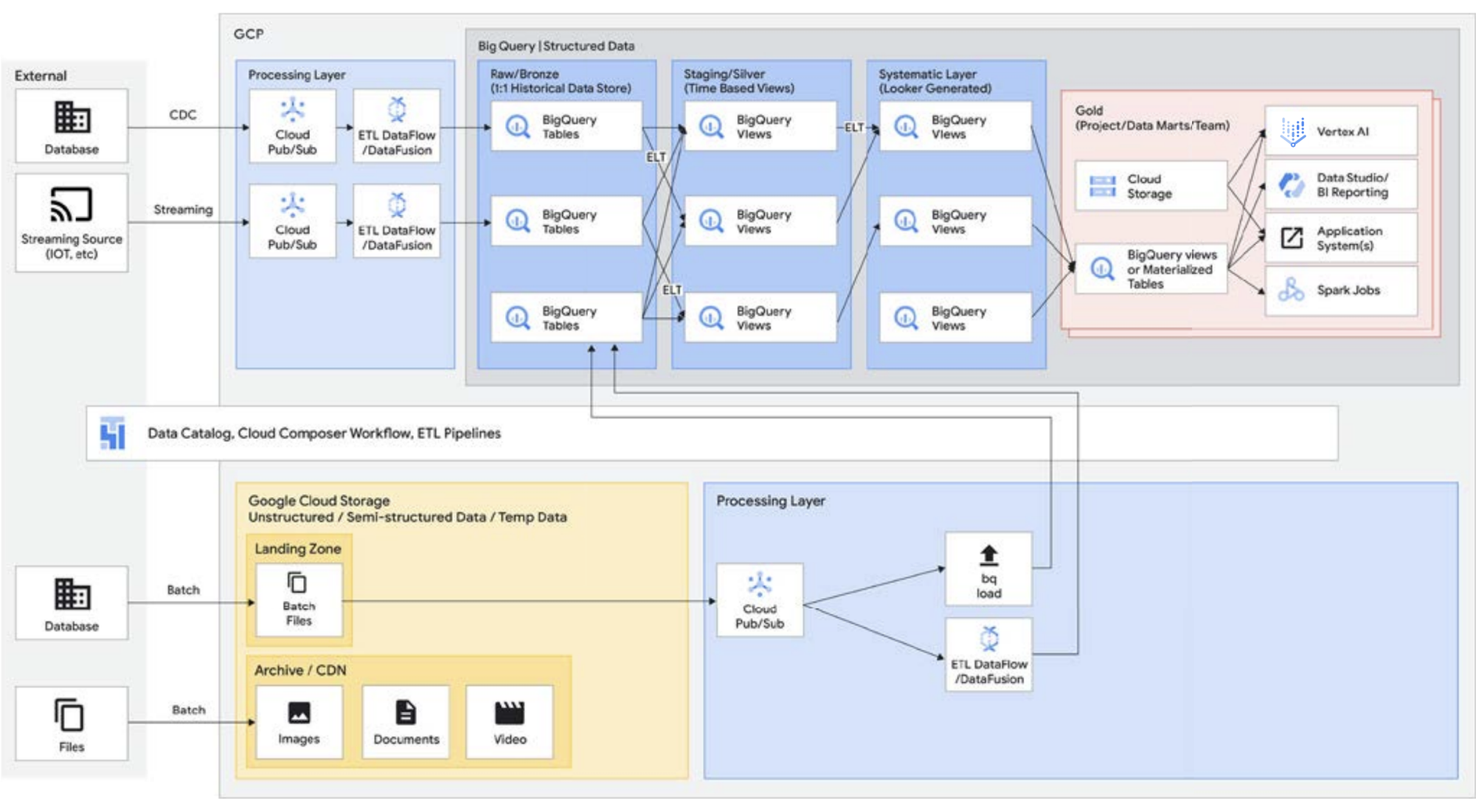
Cuando se realiza el proceso de extracción, transformación y carga (ETL), las transformaciones se producen fuera de BigQuery, posiblemente en una herramienta que no se escala tan bien. Podría acabar transformando los datos línea por línea en lugar de cargar en paralelo las consultas. En algunos casos, puede que Spark u otros procesos de extracción, transformación y carga (ETL) ya estén codificados y que no tenga sentido cambiarlos para incorporar nuevas tecnologías. Sin embargo, si hay transformaciones que se pueden escribir en SQL, es probable que BigQuery sea el lugar ideal para hacerlo.
Además, esta arquitectura es compatible con todos los componentes de Google Cloud, como Managed Service for Apache Airflow, Data Catalog o Data Fusion. Proporciona una capa completa para distintos perfiles ficticios de usuario. Otro aspecto importante de reducir la sobrecarga operativa se puede conseguir aprovechando las funciones de la infraestructura subyacente. Piensa en Dataflow y BigQuery, que se ejecutan en contenedores y nos permite gestionar el tiempo de funcionamiento y los mecanismos subyacentes. Una vez ampliado el uso a herramientas de terceros y partners, y cuando empiecen a explorar funciones similares, como Kubernetes, resulta mucho más sencillo gestionarlo y transferirlo. A su vez, se reduce la sobrecarga operativa y de recursos. Además, esto se puede complementar con una mejor observabilidad, ya que se aprovechan los paneles de monitorización con Managed Service for Apache Airflow para lograr la excelencia operativa. No solo puedes crear lagos de datos combinando los datos almacenados en Cloud Storage y BigQuery sin que se transfieran datos ni se dupliquen, sino que también ofrecemos funciones administrativas adicionales para gestionar tus fuentes de datos. Knowledge Catalog (antes Dataplex) permite crear lakehouses con una capa de gestión centralizada para coordinar los datos de Cloud Storage y BigQuery. De este modo, podrás organizar los datos según las necesidades de tu empresa, de forma que no tendrás que restringir cómo ni dónde se almacenan.
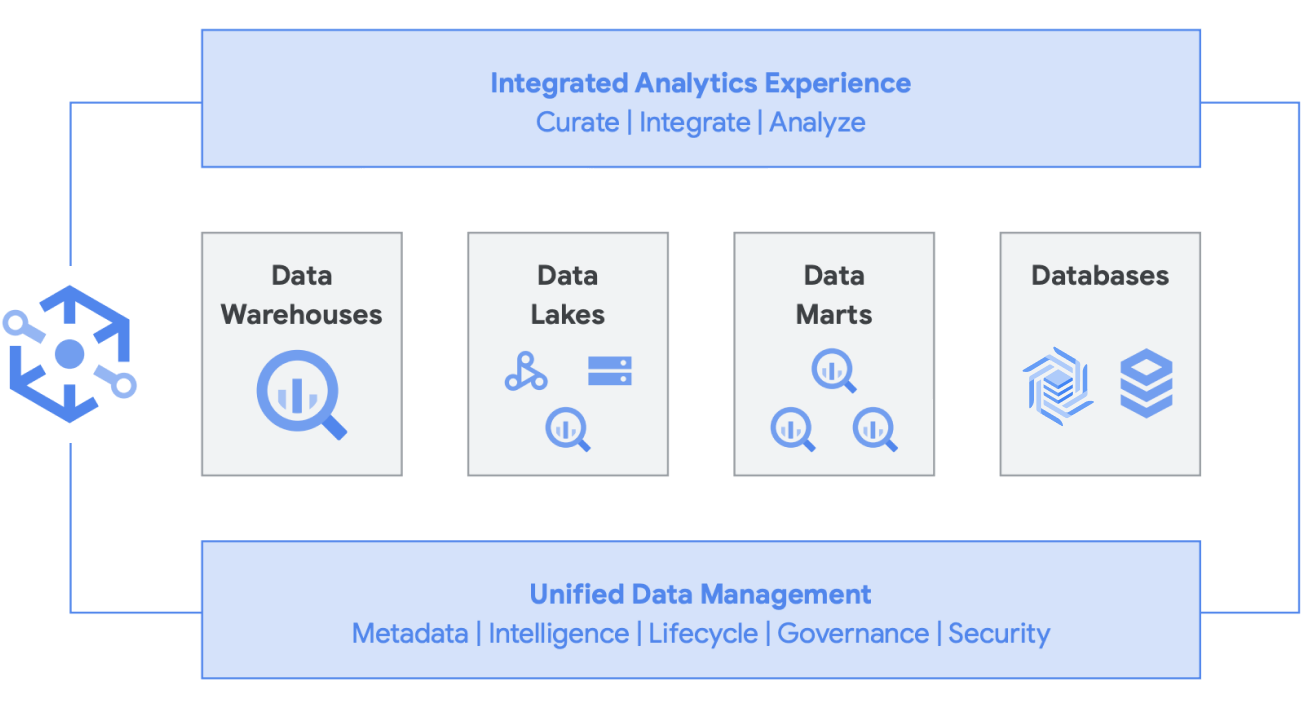
Knowledge Catalog es un tejido de datos inteligente que te permite distribuir tus datos por un precio y rendimiento adecuados y, al mismo tiempo, acceder a ellos de forma segura en todas tus herramientas de analíticas. Este servicio proporciona una gestión de datos basada en metadatos con control y calidad de datos integrados. Así, puedes dedicar menos tiempo a lidiar con los límites y las deficiencias de la infraestructura, confiar en los datos que tienes y dedicar más tiempo a extraer información valiosa de ellos. Además, proporciona una experiencia de analíticas integrada que aúna lo mejor de Google Cloud y del software libre para que puedas seleccionar, proteger, integrar y analizar datos a escala rápidamente. Por último, puedes crear una estrategia de analíticas que mejore la arquitectura actual y cumpla tus objetivos de gobierno financiero.
Mallas de datos
Las mallas de datos se basan en una larga tradición de innovación en almacenes de datos y data lakes. Se suman a los inigualables modelos de pago por rendimiento de escalabilidad, las APIs, los procesos de DevOps y la estrecha integración de los productos de Google Cloud. Con este enfoque, podrás crear eficazmente una solución de datos bajo demanda. Las mallas de datos descentralizan la propiedad de los datos entre los propietarios de los datos del dominio y cada uno de ellos es responsable de proporcionar sus datos como producto de forma estándar. Las mallas de datos también facilitan la comunicación entre las distintas partes de la organización mediante conjuntos de datos distribuidos en distintas ubicaciones. En una malla de datos, la responsabilidad de generar valor a partir de los datos depende de quienes mejor los entiendan. En otras palabras, las personas que hayan creado los datos o los hayan introducido en la organización también deben ser responsables de crear recursos de datos consumibles como productos a partir de los datos que crean. En muchas organizaciones, establecer una "fuente única de información veraz" o una "fuente de datos fiable" supone todo un reto, ya que la extracción y la transformación repetida de los datos no dejan clara responsabilidades de titularidad de los datos recién creados. En las mallas de datos, la fuente de datos autorizada es el producto de datos publicado por el dominio de origen, con un propietario y custodia de los datos claramente asignado, que es responsable de ellos.
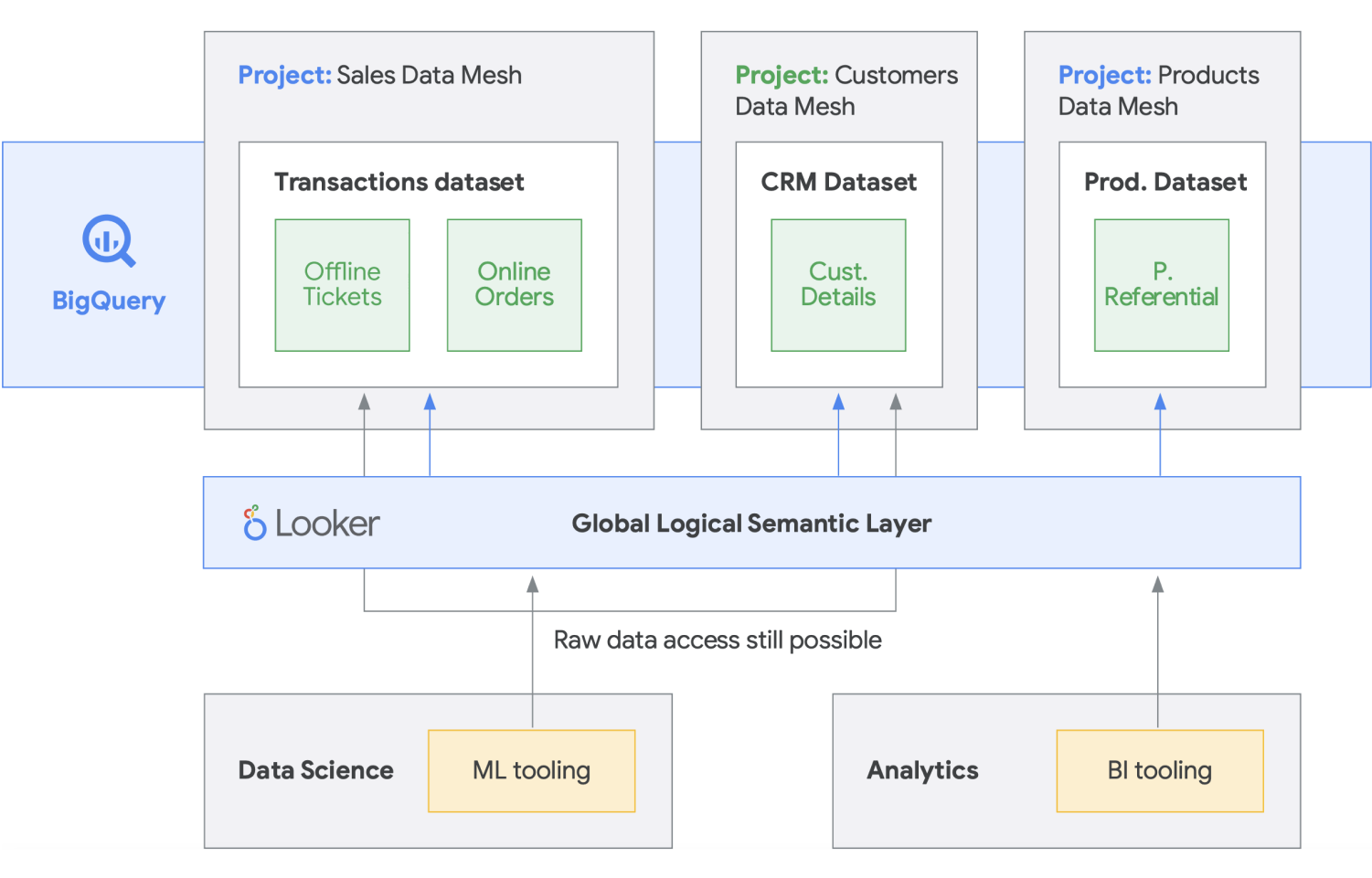
En resumen, las mallas de datos prometen una arquitectura y una propiedad de datos descentralizadas y orientadas a los dominios. Esto es posible porque tienen capas de acceso y computación federadas, iguales que las que proporcionamos en Google Cloud. Además, si tu organización quiere añadir más funciones, puedes usar Looker, por ejemplo, que ofrece una capa unificada para modelizar y acceder a los datos. La plataforma de Looker ofrece una interfaz de usuario en un único panel para acceder a la versión más precisa y actualizada de los datos y las definiciones empresariales de tu empresa. Con esta vista unificada de la empresa, puede elegir o diseñar experiencias de datos que garanticen que los usuarios y los sistemas reciben los datos de la forma que mejor se adapte a sus necesidades. Encaja perfectamente, ya que permite a los científicos de datos, analistas e incluso usuarios empresariales acceder a sus datos con un único modelo semántico. Los científicos de datos siguen teniendo acceso a los datos en bruto, pero sin que se transfieran ni se dupliquen.
Estamos desarrollando funciones adicionales, además de nuestros productos estrella, como BigQuery, para facilitar la creación y la gestión de conjuntos de datos. Analytics Hub ofrece la posibilidad de crear intercambios de datos privados, en los que los administradores de intercambios (también denominados seleccionadores de datos) conceden permisos para publicar y suscribirse a datos en el intercambio a personas o grupos concretos, tanto dentro de la empresa como externamente, y a partners empresariales o compradores.
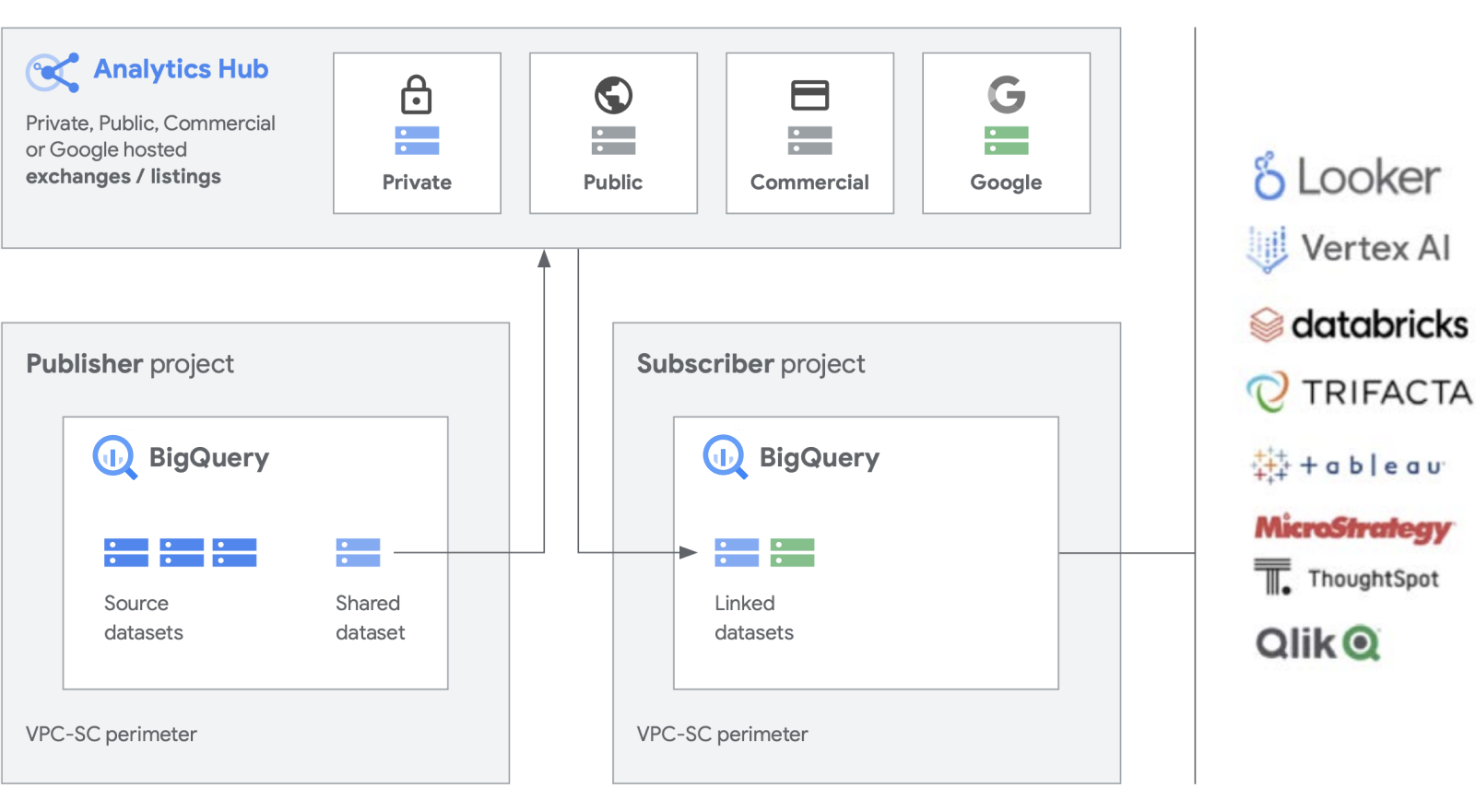
Publica, descubre y suscríbete a recursos compartidos, incluidos formatos de código abierto, gracias a la escalabilidad de BigQuery. Los editores pueden ver métricas de uso agregadas. Los proveedores de datos pueden llegar a los clientes empresariales de BigQuery proporcionándoles datos, estadísticas, modelos de aprendizaje automático o visualizaciones, y aprovechar Cloud Marketplace para monetizar sus aplicaciones, estadísticas o modelos. Este método es similar al modo en que se gestionan los conjuntos de datos públicos de BigQuery a través de un exchange gestionado por Google. Fomenta la innovación accediendo a conjuntos de datos únicos de Google, comerciales o del sector, conjuntos de datos públicos o intercambios de datos seleccionados de tu organización o ecosistema de partners.
Gestionar la versión antigua
Aunque suene muy bien crear una plataforma de datos totalmente nueva desde cero, somos conscientes de que no todas las empresas estarán en condiciones de hacerlo. La mayoría se enfrentan a sistemas antiguos que deben migrar, portar o aplicarle un parche hasta poder sustituirlos. Hemos trabajado con clientes en todas las fases de su recorrido por la plataforma de datos y tenemos soluciones para satisfacer su situación.
Normalmente, los clientes tienen tres categorías de migración: lift y cambio de plataforma, lift y rehome, y modernización completa. En el caso de la mayoría de las empresas, recomendamos empezar por lift y cambio de plataforma, ya que ofrece una migración de gran impacto con el mínimo de interrupciones y riesgos posibles. Con esta estrategia, puedes migrar los datos de tus antiguos almacenes de datos y clústeres de Hadoop a BigQuery o Managed Service for Apache Spark. Una vez que se hayan transferido los datos, podrás optimizar tus flujos de procesamiento y consultas de datos para mejorar el rendimiento. Puedes hacerlo por fases mediante una estrategia de migración mediante lift y cambio de plataforma, en función de la complejidad de tus cargas de trabajo. Recomendamos este enfoque a los clientes de grandes empresas con TI centralizada y varias unidades de negocio, debido a su complejidad.
La segunda estrategia de migración que más a menudo vemos es una modernización completa como primer paso. Esto supone acabar por completo con las soluciones del pasado, ya que optas de forma integral por una estrategia nativa de la nube. Se ha desarrollado de forma nativa en Google Cloud, pero como vas a cambiarlo todo de una sola vez, la migración puede ser más lenta si tienes varios entornos antiguos de gran tamaño.

Para acabar por completo con una versión antigua, es necesario reescribir tareas y cambiar diferentes aplicaciones. No obstante, proporciona mayor velocidad y agilidad, y el coste total de propiedad es más bajo a largo plazo en comparación con otros enfoques. Esto se debe a dos motivos principales: tus aplicaciones ya están optimizadas y no es necesario actualizarlas, y una vez que hayas migrado tus fuentes de datos, no tendrás que gestionar dos entornos al mismo tiempo. Esta opción es la más adecuada para organizaciones nativas digitales o orientadas a la ingeniería con pocos entornos antiguos.
Por último, el enfoque más conservador es lift and rehome, que recomendamos como solución táctica a corto plazo para trasladar tu patrimonio de datos a la nube. Puedes migrar y volver a instalar tus plataformas actuales y seguir usándolas como antes, pero en el entorno de Google Cloud. Esto se aplica a entornos como Teradata y Databricks, por ejemplo, para reducir el riesgo inicial y permitir que las aplicaciones se ejecuten. Sin embargo, esto traslada el entorno aislado a la nube en lugar de transformarlo, por lo que no te beneficias del rendimiento de una plataforma creada de forma nativa en Google Cloud. No obstante, podemos ayudarte con una migración completa a los productos nativos de Google Cloud para que aproveches la interoperabilidad y crees una plataforma de datos de analíticas totalmente moderna en Google Cloud.
¿Táctica o estratégica?
Creemos que las principales diferencias de una plataforma de datos de analíticas creada en Google Cloud son que es abierta, inteligente y flexible y está perfectamente integrada. En el mercado hay muchas soluciones que incluyen tácticas que te pueden resultar cómodas y familiares. Sin embargo, estas soluciones suelen ofrecer una solución a corto plazo y solo presentan una organización y problemas técnicos complejos a lo largo del tiempo.
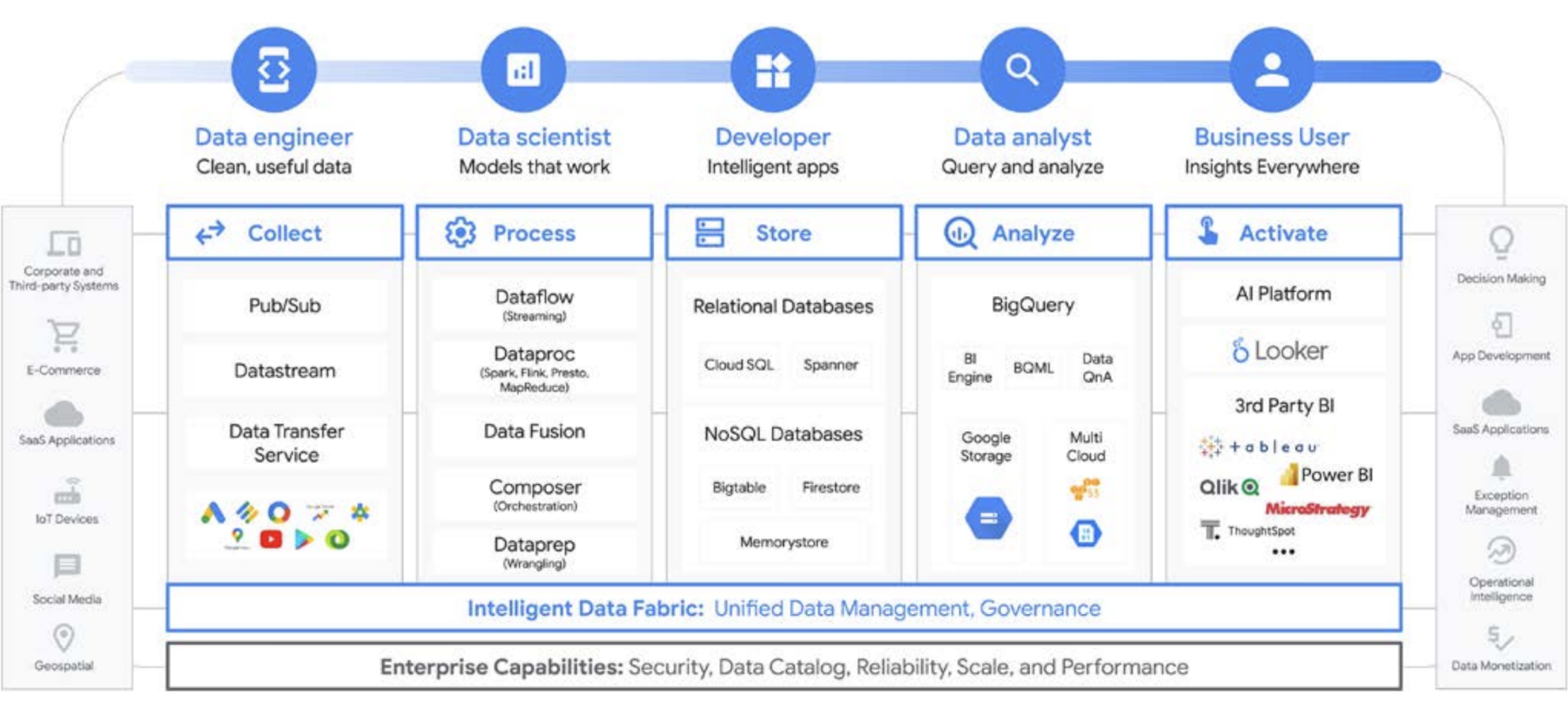
Google Cloud simplifica considerablemente las analíticas de datos. Aprovecha todo el potencial que albergan tus datos con una estrategia sin servidor y nativa de la nube que desvincula el almacenamiento de los recursos de computación y te permite analizar grandes cantidades de datos (desde gigabytes hasta petabytes) en cuestión de minutos. De esta forma, podrás eliminar las restricciones tradicionales de escala, rendimiento y costes para plantear cualquier pregunta sobre los datos y resolver problemas empresariales. Como resultado, es más sencillo utilizar información valiosa en toda la empresa con un único tejido de datos fiable.
¿Cuáles son los beneficios?
- Se centra exclusivamente en las analíticas y no en la infraestructura
- Ofrece soluciones para todas las fases del ciclo de vida de las analíticas de datos, desde la ingestión hasta la transformación y el análisis, pasando por la inteligencia empresarial, entre otros
- Crea una base de datos sólida sobre la que poner en práctica el aprendizaje automático
- Te permite aprovechar las mejores tecnologías de software libre para tu organización
- Es escalable para satisfacer las necesidades de tu empresa, especialmente cuando aumentas el uso de los datos para llevar el negocio y la transformación digital
La plataforma de datos de analíticas moderna y unificada que tiene integrada Google Cloud te ofrece las mejores funciones de los data lakes y los almacenes de datos, pero con una mayor integración en la AI Platform. Puedes procesar automáticamente datos en tiempo real de miles de millones de eventos de streaming y proporcionar información valiosa en cuestión de milisegundos para dar respuesta a las necesidades cambiantes de los clientes. Nuestros servicios de IA líderes en el sector pueden optimizar la toma de decisiones de tu organización y la experiencia de los clientes, lo que te ayuda a cerrar la brecha entre las analíticas descriptivas y prescriptivas sin tener que formar un nuevo equipo. Puedes ampliar tus conocimientos para aumentar el impacto de la IA con una inteligencia automática integrada.
Notas a pie de página
Agosto del 2021
Ve un paso más allá
¿Quieres saber más sobre cómo puede transformar la plataforma de datos de Google la forma en que tu empresa gestiona los datos? Ponte en contacto con nosotros para empezar
¿Necesitas ayuda para empezar?
Contactar con VentasColabora con un partner de confianza
Buscar un partnerSigue explorando
Ver todos los productos


















