Build a modern, unified analytics data platform with Google Cloud
Hier erfahren Sie mehr über die notwendigen Entscheidungspunkte beim Aufbau einer modernen, einheitlichen Datenanalyseplattform auf der Grundlage von Google Cloud.
Autoren: Firat Tekiner und Susan Pierce

Übersicht
Es gibt keinen Mangel an Daten, die erstellt werden. Laut Untersuchungen der IDC werden die Daten bis 2025 weltweit auf 175 Zettabyte steigen.1 Die täglich erzeugte Datenmenge ist erstaunlich und es wird für Unternehmen zunehmend schwieriger, diese zugänglich und nutzbar zu erfassen, zu speichern und zu organisieren. Tatsächlich geben 90 % der Datenfachleute an, dass ihre Arbeit durch unzuverlässige Datenquellen ausgebremst wurde. Etwa 86% der Datenanalysten haben mit veralteten Daten zu kämpfen und mehr als 60% der Datennutzer sind davon betroffen, jeden Monat auf Engineering-Ressourcen warten zu müssen, während ihre Daten bereinigt und vorbereitet werden2.
Ineffiziente Organisationsstrukturen und Architekturentscheidungen tragen dazu bei, dass Unternehmen Lücken zwischen dem Aggregieren von Daten und ihrer Nutzung haben. Unternehmen möchten in die Cloud wechseln, um ihre Datenanalysesysteme zu modernisieren. Das allein löst jedoch noch nicht die zugrunde liegenden Probleme mit isolierten Datenquellen und anfälligen Verarbeitungspipelines. Strategische Entscheidungen in Bezug auf Dateneigentümerschaft und technische Entscheidungen über Speichermechanismen müssen ganzheitlich getroffen werden, um eine Datenplattform für Ihr Unternehmen erfolgreicher zu machen.
In diesem Artikel werden die Entscheidungspunkte erörtert, die zum Erstellen einer modernen, einheitlichen Datenanalyseplattform auf Google Cloud erforderlich sind.
Big Data haben in den letzten zwei Jahrzehnten unglaubliche Möglichkeiten für Unternehmen geschaffen. Es ist jedoch für Unternehmen kompliziert, ihren geschäftlichen Nutzern relevante, umsetzbare und aktuelle Daten zu präsentieren. Untersuchungen haben ergeben, dass 86 % der Analysten immer noch mit veralteten Daten zu kämpfen haben3 und nur 32 % der Unternehmen glauben, dass sie einen materiellen Wert aus ihren Daten ziehen4. Das erste Problem ist die Datenaktualität. Das zweite Problem besteht darin, dass es schwierig ist, unterschiedliche Systeme und Legacy-Systeme in Silos zu integrieren. Unternehmen migrieren in die Cloud, was jedoch das eigentliche Problem älterer Legacy-Systeme nicht löst, die vertikal so strukturiert waren, dass sie den Anforderungen einer einzelnen Geschäftseinheit gerecht werden.
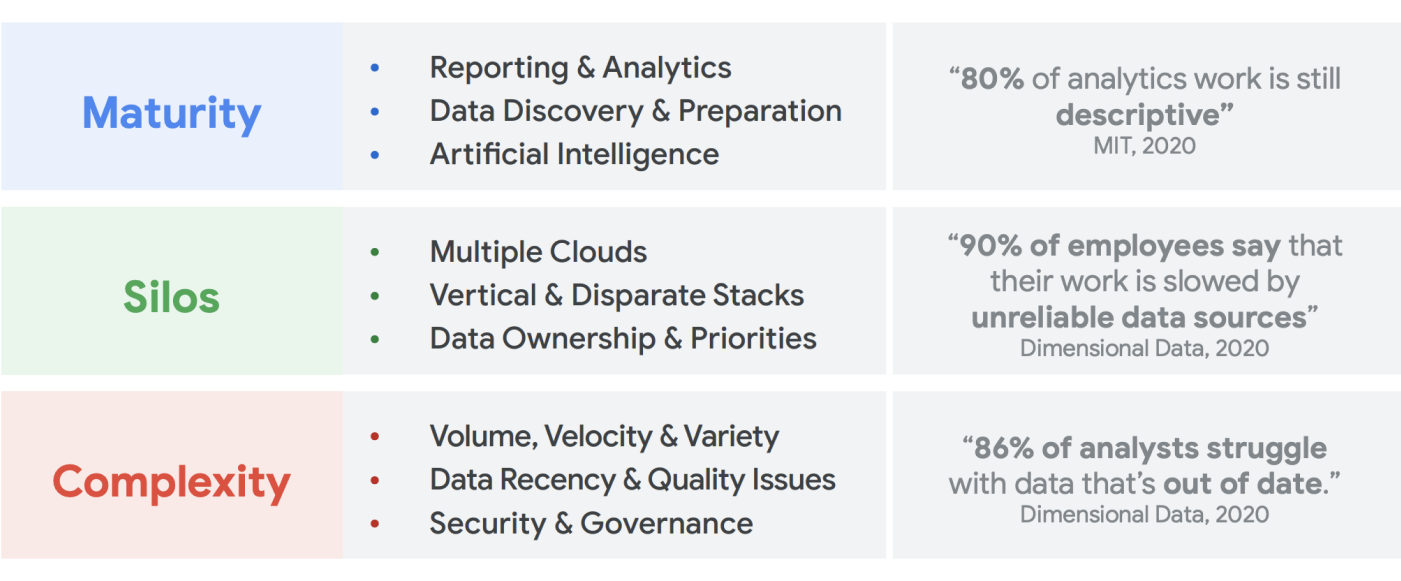
Bei der Planung von Unternehmensdatenanforderungen ist es leicht, zu verallgemeinern und eine einzelne, vereinfachte Struktur in Betracht zu ziehen, in der es eine Gruppe konsistenter Datenquellen, ein Enterprise-Data-Warehouse, ein Satz an Semantiken und ein Tool für Business Intelligence gibt. Das kann für eine sehr kleine, stark zentralisierte Organisation oder sogar für eine einzelne Geschäftseinheit mit eigenem integriertes IT- und Data-Engineering-Team funktionieren. In der Praxis ist jedoch keine Organisation so einfach und es gibt immer überraschende Komplexitäten bei der Datenaufnahme, -verarbeitung und/oder -nutzung, die noch komplizierter werden.
Bei unseren Gesprächen mit Hunderten von Kunden benötigen wir einen ganzheitlichen Ansatz für Daten und Analysen. Diese Plattform erfüllt die Anforderungen mehrerer Geschäftseinheiten und User Personas mit so wenigen redundanten Schritten wie möglich. Dabei geht es um mehr als nur eine neue Architektur oder mehrere neue Softwarekomponenten, die gekauft werden müssen. Es erfordert, dass Unternehmen ihre Datenreife insgesamt im Auge behalten und zusätzlich zu technischen Upgrades systematische, organisatorische Änderungen vornehmen.
Bis Ende 2024 werden 75 % der Unternehmen vom Pilotprojekt auf die Operationalisierung von KI umstellen, was zu einer Verfünffachung der Streaming-Daten- und Analyseinfrastrukturen führt.5 Es ist ganz einfach, KI mit einem Data-Science-Team in einer isolierten Umgebung zu testen. Die grundlegende Herausforderung, die verhindert, dass diese Erkenntnisse in Produktionssysteme übertragen werden, ist jedoch die organisatorische und architektonische Hürde, die dafür sorgt, dass die Dateneigentümerschaft segmentiert bleibt. Infolgedessen sind die meisten Erkenntnisse, die in die Geschäftsabläufe eines Unternehmens einfließen, beschreibender Charakter und prädiktive Analysen sind auf den Bereich eines Forschungsteams beschränkt.

Eine Plattform für alle Nutzenden im gesamten Datenlebenszyklus
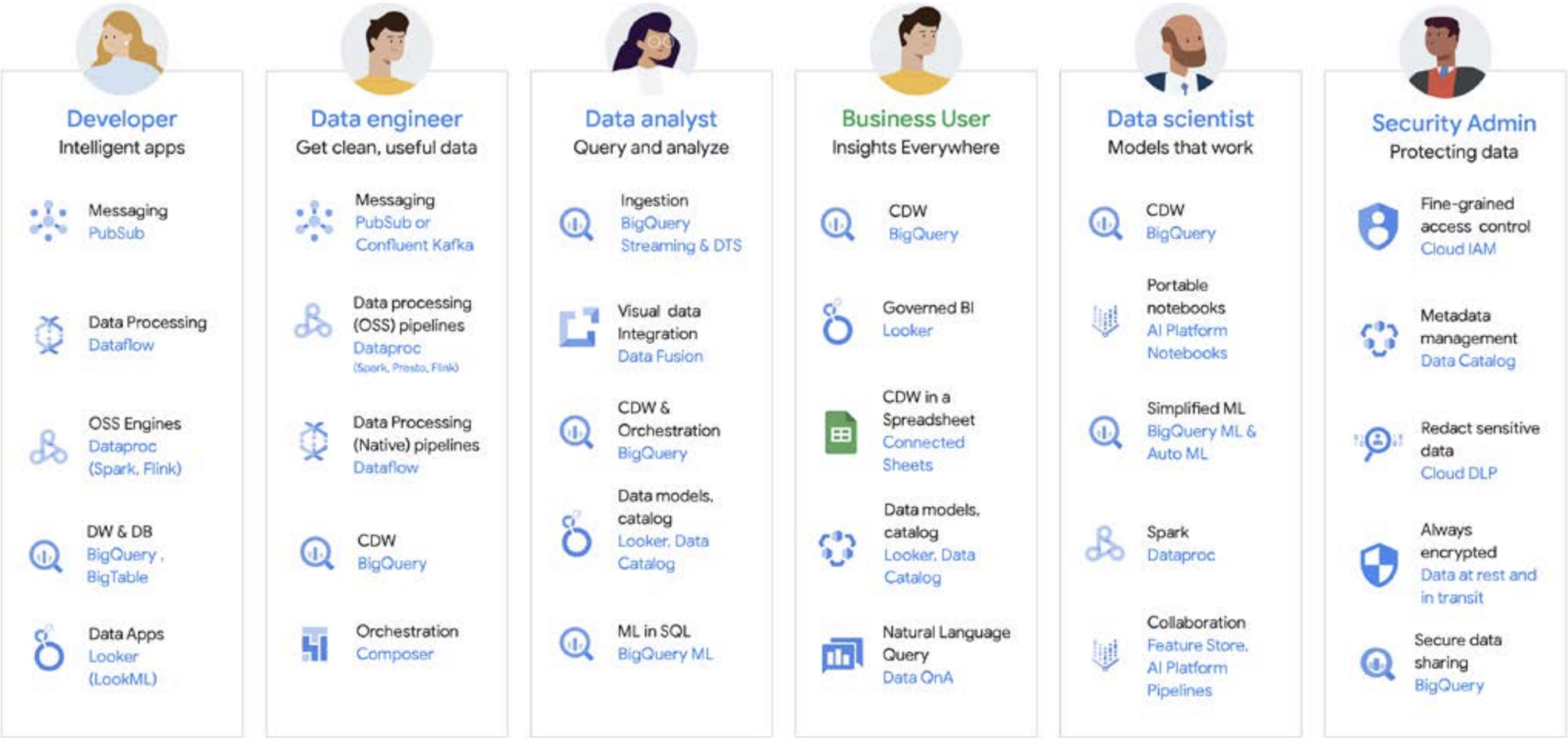
Datenarbeit wird selten von einer einzelnen Person ausgeführt; Es gibt viele datenbezogene Nutzende in einem Unternehmen, die eine wichtige Rolle im Datenlebenszyklus spielen. Jeder hat eine andere Perspektive in Bezug auf Data Governance, Aktualität, Sichtbarkeit, Metadaten, Verarbeitungszeiträume, Abfragebarkeit und mehr. In den meisten Fällen verwenden sie alle unterschiedliche Systeme und Software, um dieselben Daten in verschiedenen Verarbeitungsphasen zu verarbeiten.
Sehen wir uns als Beispiel den Lebenszyklus des maschinellen Lernens an. Ein Data Engineer kann sicherstellen, dass aktuelle Daten für das Data-Science-Team verfügbar sind, wobei angemessene Sicherheits- und Datenschutzbeschränkungen vorhanden sind. Ein Data Scientist kann Trainings- und Test-Datasets basierend auf einer goldenen Reihe von vorab aggregierten Datenquellen des Data Engineer erstellen, Modelle erstellen und testen und Erkenntnisse für ein anderes Team zur Verfügung stellen. Ein ML-Entwickler ist möglicherweise dafür verantwortlich, das Modell für die Bereitstellung in Produktionssystemen so zu packen, sodass andere Datenverarbeitungspipelines nicht störend sind. Produktmanager oder Business-Analysten prüfen abgeleitete Erkenntnisse mithilfe von Data QnA (eine Natural Language Interface für die Analyse von BigQuery-Daten), Visualisierungssoftware oder fragen den Ergebnissatz direkt über eine IDE oder eine Befehlszeile ab. Es gibt unzählige Nutzer mit unterschiedlichen Anforderungen, und wir haben für alle eine Plattform entwickelt, die auf die Anforderungen von Nutzerinnen und Nutzer zugeschnitten ist. Google Cloud unterstützt Kunden dort, wo sie sich gerade befinden, mit Tools, die den Anforderungen ihres Unternehmens gerecht werden.
Die große Big Data-Entscheidung: Data Warehouse oder Data Lake?
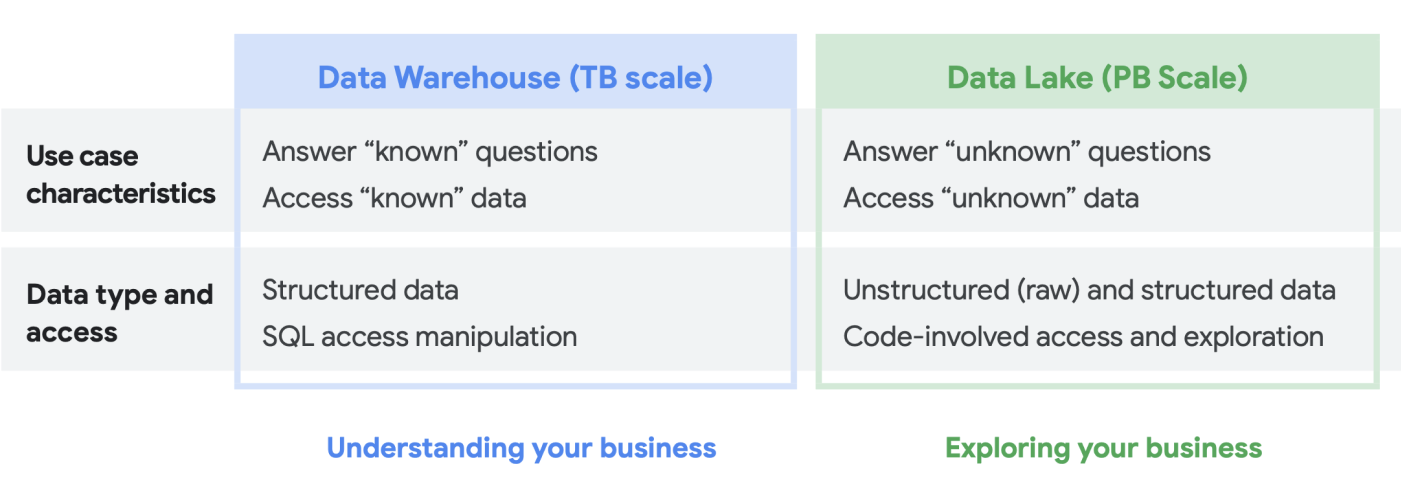
Wenn wir mit Kunden über ihre Data-Analytics-Anforderungen sprechen, wird uns häufig die Frage gestellt: „Was brauche ich: einen Data Lake oder ein Data Warehouse?“ Angesichts der Vielfalt der Datennutzenden und -anforderungen in einem Unternehmen kann dies eine schwierige Frage sein. Sie hängt von der beabsichtigten Nutzung, den Datentypen und dem Personal ab.
- Wenn Sie wissen, welche Datasets Sie analysieren müssen, eine klare Vorstellung von deren Struktur haben und eine Reihe bekannter Fragen haben, die Sie beantworten müssen, ist für Sie wahrscheinlich ein Data Warehouse die bessere Wahl.
- Wenn Sie hingegen die Auffindbarkeit mehrerer Datentypen benötigen, unsicher sind, welche Arten von Analysen Sie durchführen müssen, nach neuen Möglichkeiten suchen, anstatt Statistiken zu präsentieren, und Sie die Ressourcen haben, um diese Umgebung effektiv zu verwalten und zu analysieren, ist ein Data Lake für Ihre Anforderungen wahrscheinlich besser geeignet.
Bei der Entscheidung sind jedoch noch weitere Faktoren zu berücksichtigen. Sehen wir uns daher einige organisatorische Herausforderungen der jeweiligen Option an. Data Warehouses sind oft schwer zu verwalten. Die Legacy-Systeme, die in den letzten 40 Jahren gut funktioniert haben, haben sich als sehr teuer erwiesen und stellen eine Menge Herausforderungen in Bezug auf Datenaktualität, ‐skalierung und hohe Kosten dar. Außerdem ist es nicht einfach, KI- oder Echtzeitfunktionen bereitzustellen, ohne diese Funktion nachträglich zu aktivieren. Diese Probleme treten nicht nur in lokalen Legacy-Data-Warehouses auf. Wir beobachten das auch bei den neu erstellten cloudbasierten Data Warehouses. Viele bieten keine integrierten KI-Funktionen, obwohl dies behauptet wird. Diese neuen Data Warehouses sind im Wesentlichen die gleichen Legacy-Umgebungen, werden aber in die Cloud migriert. Data-Warehouse-Nutzer sind in der Regel Analysten, die oft in eine bestimmte Geschäftseinheit eingebettet sind. Möglicherweise haben sie Ideen zu zusätzlichen Datasets, die hilfreich sein könnten, um ihr Verständnis des Unternehmens zu erweitern. Sie haben möglicherweise Ideen für Verbesserungen in den Bereichen Analyse, Datenverarbeitung und Anforderungen an Business-Intelligence-Funktionen.
In einer traditionellen Organisation haben sie jedoch häufig keinen direkten Zugang zu den Dateninhabern und können auch nicht einfach die technischen Entscheidungsträger beeinflussen, die Datensätze und Tools entscheiden. Außerdem sind sie nicht in der Lage, Hypothesen zu testen oder die zugrunde liegenden Daten besser zu verstehen, da sie von Rohdaten getrennt gehalten werden. Data Lakes haben ihre eigenen Herausforderungen. Theoretisch sind sie kostengünstig und einfach zu skalieren, aber viele unserer Kunden sehen in ihren lokalen Data Lakes eine andere Realität. Die Planung und Bereitstellung eines ausreichenden Speichers kann teuer und schwierig sein, insbesondere für Organisationen mit sehr unterschiedlichen Datenmengen. Lokale Data Lakes können problemanfällig sein und die Wartung vorhandener Systeme braucht Zeit. In vielen Fällen werden die Engineers, die sonst neue Funktionen entwickeln würden, mit der Pflege und Versorgung von Datenclustern betraut. Kurz gesagt: Sie behalten den Wert bei, anstatt einen neuen Mehrwert zu schaffen. Insgesamt sind die Gesamtbetriebskosten für viele Unternehmen höher als erwartet. Nicht nur das: Governance ist systemübergreifend schwierig zu lösen, insbesondere wenn verschiedene Teile des Unternehmens unterschiedliche Sicherheitsmodelle verwenden. Infolgedessen werden die Data Lakes isoliert und segmentiert, was den Austausch von Daten und Modellen zwischen Teams erschwert.
Data-Lake-Nutzer sind in der Regel näher an den Rohdatenquellen und verfügen über Tools und Funktionen, um die Daten zu untersuchen. In traditionellen Unternehmen konzentrieren sich diese Nutzenden tendenziell auf die Daten selbst und werden häufig auf Abstand vom Rest des Unternehmens gehalten. Das bedeutet, dass Geschäftseinheiten keine Informationen mehr erhalten, mit denen sie ihre Geschäftsziele in Richtung höherer Umsätze, geringerer Kosten, geringerer Risiken und neuer Chancen voranbringen können. Angesichts dieser Nachteile haben viele Unternehmen einen hybriden Ansatz gewählt, bei dem ein Data Lake eingerichtet wird, um einige Daten in ein Data Warehouse umzuwandeln, oder ein Data Warehouse einen seitlichen Data Lake für zusätzliche Tests und Analysen hat. Da jedoch mehrere Teams ihre eigenen Datenarchitekturen erstellen, um ihren individuellen Anforderungen gerecht zu werden, werden die Weitergabe und die Genauigkeit der Daten für ein zentrales IT-Team noch komplizierter. Anstatt separate Teams mit separaten Zielen zu haben, bei denen eines der Teams das Unternehmen erkundet und ein anderes das Unternehmen versteht, können Sie diese Funktionen und deren Datensysteme zu einem positiven Kreislauf vereinen, in dem ein tieferes Verständnis des Unternehmens die gezielte Erkundung fördert, und diese Erkundung zu einem besseren Verständnis des Unternehmens führt.
Data-Warehouse-Speicher wie einen Data Lake behandeln
Sie können in Google Cloud ein Data Warehouse oder einen Data Lake separat erstellen, aber Sie müssen sich nicht für das eine oder das andere entscheiden. In vielen Fällen verwenden unsere Kundenunternehmen für beide dieselben zugrunde liegenden Produkte. Der einzige Unterschied zwischen der Data Lake- und der Data Warehouse-Implementierung ist die verwendete Datenzugriffsrichtlinie. Tatsächlich beginnen die beiden Begriffe allmählich, sich zu einem einheitlichen Satz an Funktionen zu verbinden, einer modernen Analysedatenplattform. Sehen wir uns an, wie das in Google Cloud funktioniert.
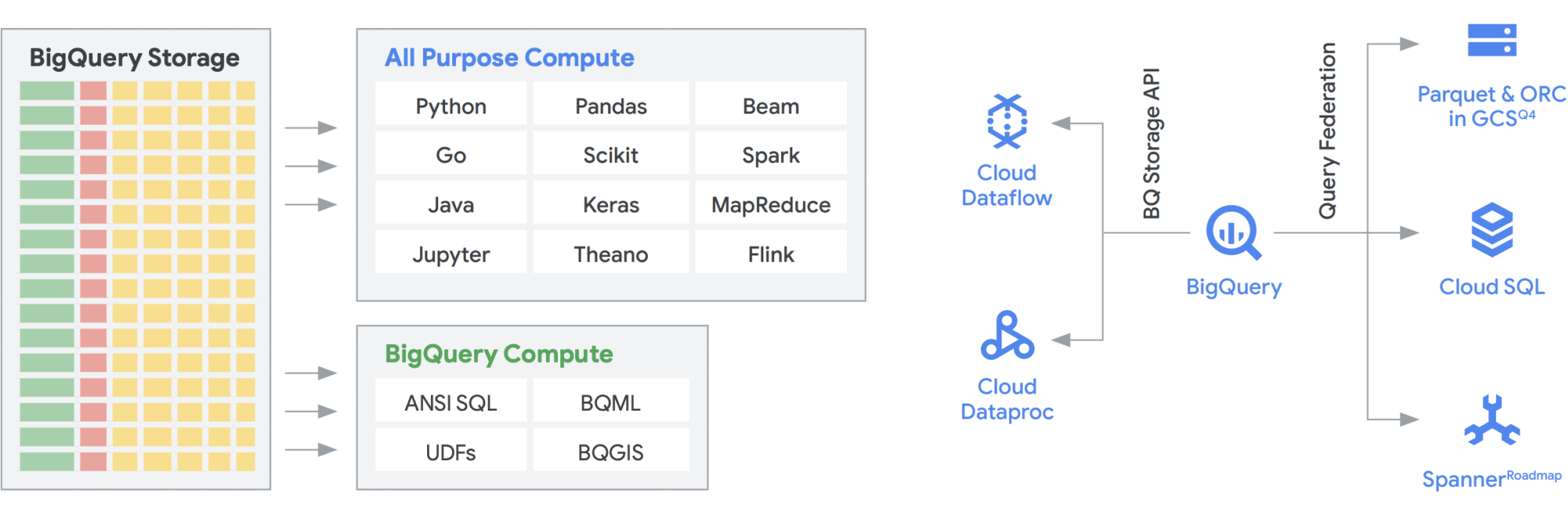
Die BigQuery Storage API bietet die Möglichkeit, BigQuery Storage wie Cloud Storage für eine Reihe anderer Systeme wie Dataflow und Managed Service for Apache Spark zu verwenden. So lassen sich Speicherkapazitäten im Data Warehouse überwinden und leistungsstarke Dataframes in BigQuery ausführen. Mit anderen Worten: Mit der BigQuery Storage API kann Ihr BigQuery Data Warehouse wie ein Data Lake agieren. Wozu dient er also in der Praxis? Zum einen haben wir eine Reihe von Connectors erstellt, z. B. MapReduce, Hive oder Spark, damit Sie Ihre Hadoop- und Spark-Arbeitslasten direkt für Ihre Daten in BigQuery ausführen können. Zusätzlich zu Ihrem Data Warehouse benötigen Sie keinen Data Lake mehr. Dataflow ist für die Batch- und Streamverarbeitung extrem leistungsstark. Derzeit können Sie Dataflow-Jobs auf BigQuery-Daten ausführen und diese mit Daten aus Pub/Sub, Spanner oder einer anderen Datenquelle anreichern.
BigQuery kann sowohl den Speicher als auch die Computing-Ressourcen unabhängig skalieren. Beide Lösungen sind serverlos. Das ermöglicht eine unbegrenzte Skalierung, unabhängig von der Nutzung durch verschiedene Teams, Tools und Zugriffsmuster. Alle oben genannten Anwendungen können ausgeführt werden, ohne die Leistung anderer Jobs zu beeinträchtigen, die gleichzeitig auf BigQuery zugreifen. Darüber hinaus bietet die BigQuery Storage API ein Netzwerk auf Petabit-Ebene, bei dem Daten zwischen Knoten verschoben werden, um eine Abfrageanfrage zu erfüllen. Dies führt effektiv zu einer ähnlichen Leistung wie bei einem In-Memory-Vorgang. Außerdem ermöglicht sie eine direkte Verbindung mit den beliebten Hadoop-Datenformaten wie Parquet und ORC sowie NoSQL- und OLTP-Datenbanken. Mit den Funktionen von Dataflow SQL, die in BigQuery eingebettet sind, können Sie noch einen Schritt weiter gehen. Auf diese Weise können Sie die Streams mit BigQuery-Tabellen oder Daten in Dateien verknüpfen und so eine Lambda-Architektur erstellen, die es Ihnen ermöglicht, große Mengen von Batch- und Streamingdaten aufzunehmen, und gleichzeitig eine Bereitstellungsebene zum Antworten auf Abfragen bereitzustellen. BigQuery BI Engine und materialisierte Ansichten machen es in dieser Mehrzweckarchitektur noch einfacher, Effizienz und Leistung zu steigern.
Intelligente Analysen-Plattform von Google auf Basis von BigQuery
Serverlose Datenlösungen sind absolut notwendig, damit Ihr Unternehmen Datensilos überwinden und in den Bereich der Erkenntnisse und Maßnahmen eintreten kann. Alle unsere zentralen Datenanalysedienste sind serverlos und eng miteinander verknüpft.

Änderungsmanagement ist oft einer der schwierigsten Aspekte bei der Einbindung neuer Technologien in ein Unternehmen. Google Cloud möchte unsere Kunden dort erreichen, wo sie sich gerade befinden, und bietet Entwicklern und geschäftlichen Nutzern vertraute Tools, Plattformen und Integrationen. Unser Ziel ist es, Unternehmen durch datengestützte Innovationen dabei zu helfen, schneller startklar für die digitale Transformation zu werden. Anstatt an einen Anbieter gebunden zu sein, bietet Google Cloud Unternehmen Optionen für einfache, optimierte Integrationen in lokale Umgebungen, andere Cloud-Angebote und sogar in den Edge-Bereich, um eine echte Hybrid-Cloud zu schaffen:
- Mit BigQuery Omni müssen Daten nicht mehr von einer Umgebung in eine andere übertragen werden. Stattdessen werden die Analysen unabhängig von der Umgebung auf die Daten übertragen.
- Apache Beam, das SDK, das in Dataflow genutzt wird, bietet Verwaltbarkeit und Übertragbarkeit für Runner wie Apache Spark und Apache Flink
- Für Organisationen, die Apache Spark oder Apache Hadoop ausführen möchten, bietet Google Cloud Managed Service for Apache Spark
Den meisten Datennutzenden ist wichtig, zu wissen, welche Daten sie haben, nicht, in welchem System sie gespeichert sind. Das Wichtigste ist, jederzeit Zugriff auf die benötigten Daten zu haben. In den meisten Fällen spielt der Plattformtyp also keine Rolle für die Nutzenden, solange sie mit vertrauten Tools auf aktuelle, nutzbare Daten zugreifen können – egal, ob sie Datasets untersuchen, Quellen in Datenspeichern verwalten, Ad-hoc-Abfragen ausführen oder interne Business-Intelligence-Tools für Führungskräfte entwickeln.
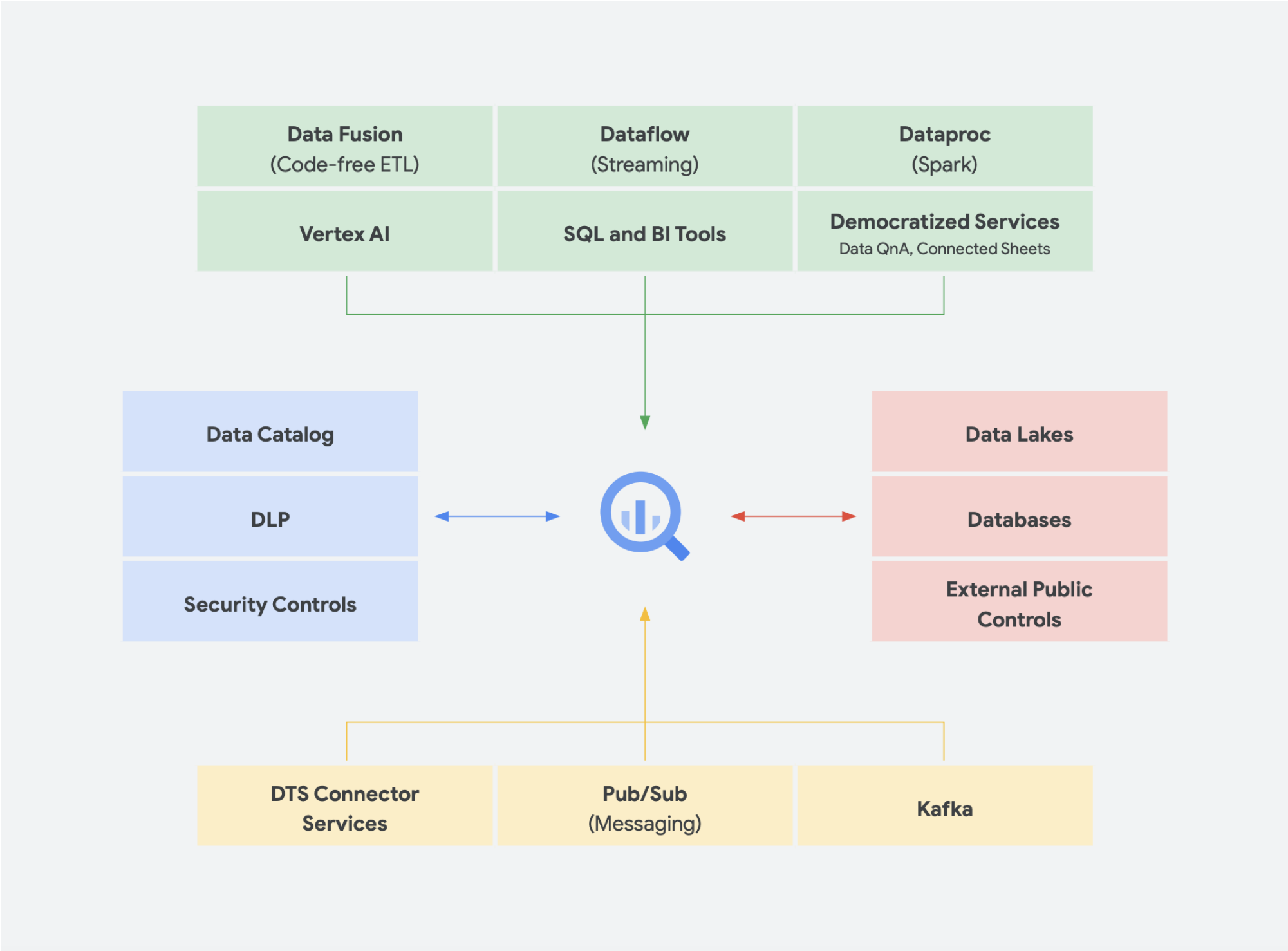
Aufkommende Trends
Neben der Konvergenz von Data Lake und Data Warehouse zu einer einheitlichen Datenplattform für Analysen gibt es noch weitere Datenlösungen, die immer beliebter werden. Es gibt viele neue Konzepte wie Lakehouse und Data Mesh. Einige dieser Begriffe haben Sie vielleicht schon einmal gehört. Einige sind nicht neu und es gibt sie schon seit Jahren in verschiedenen Formen und Formaten. Sie funktionieren jedoch sehr gut in der Google Cloud-Umgebung. Sehen wir uns genauer an, wie ein Data Mesh und ein Lakehouse in Google Cloud aussehen würden und was sie für den Datenaustausch innerhalb einer Organisation bedeuten. Lakehouse und Data Mesh schließen sich nicht gegenseitig aus, sondern helfen bei der Bewältigung unterschiedlicher Herausforderungen in einem Unternehmen. Das eine befürwortet jedoch die Befähigung von Daten, während das andere Teams unterstützt. Mit einem Data Mesh können Teams unabhängig voneinander arbeiten und die gesamte Dateninfrastruktur wird effizienter. Er zerlegt Silos in kleinere Organisationseinheiten in einer Architektur, die föderierten Zugriff auf Daten bietet. Lakehouse vereint Data Warehouse und Data Lake und ermöglicht so die Verarbeitung verschiedener Datentypen und größerer Datenmengen. Dies führt effektiv zu Schema-on-Read statt Schema-on-Write, einem Feature von Data Lakes, das einige der Leistungslücken in Data Warehouses von Unternehmen schließen sollte. Ein weiterer Vorteil dieser Architektur ist die strengere Data Governance, die Data Lakes in der Regel fehlt.

Lakehouse
Wie bereits erwähnt, können Sie Ihr Data Warehouse mit der Storage API von BigQuery wie einen Data Lake behandeln. Spark-Jobs, die in Managed Service for Apache Spark oder ähnlichen Hadoop-Umgebungen ausgeführt werden, können die in BigQuery gespeicherten Daten verwenden, ohne dass ein separates Speichermedium erforderlich ist, da die Speicherung über das Data Warehouse erfolgt. Die schmale Rechenleistung, die vom Speicher in BigQuery entkoppelt ist, ermöglicht die SQL-basierte Transformation und nutzt Ansichten über verschiedene Ebenen dieser Transformationen hinweg. Dies führt dann zu einem ELT-ähnlichen Ansatz und ermöglicht eine agilere Datenverarbeitungsplattform. Durch die Nutzung von ELT über ETL ermöglicht BigQuery das Speichern von SQL-basierten Transformationen als logische Ansichten. Während das Auslesen aller Rohdaten in ein Data Warehouse bei einem traditionellen Data Warehouse teuer sein kann, fallen für den BigQuery-Speicher keine Premiumgebühren an. Die Kosten sind weitgehend mit dem Blob-Speicher in Google Cloud Storage vergleichbar.
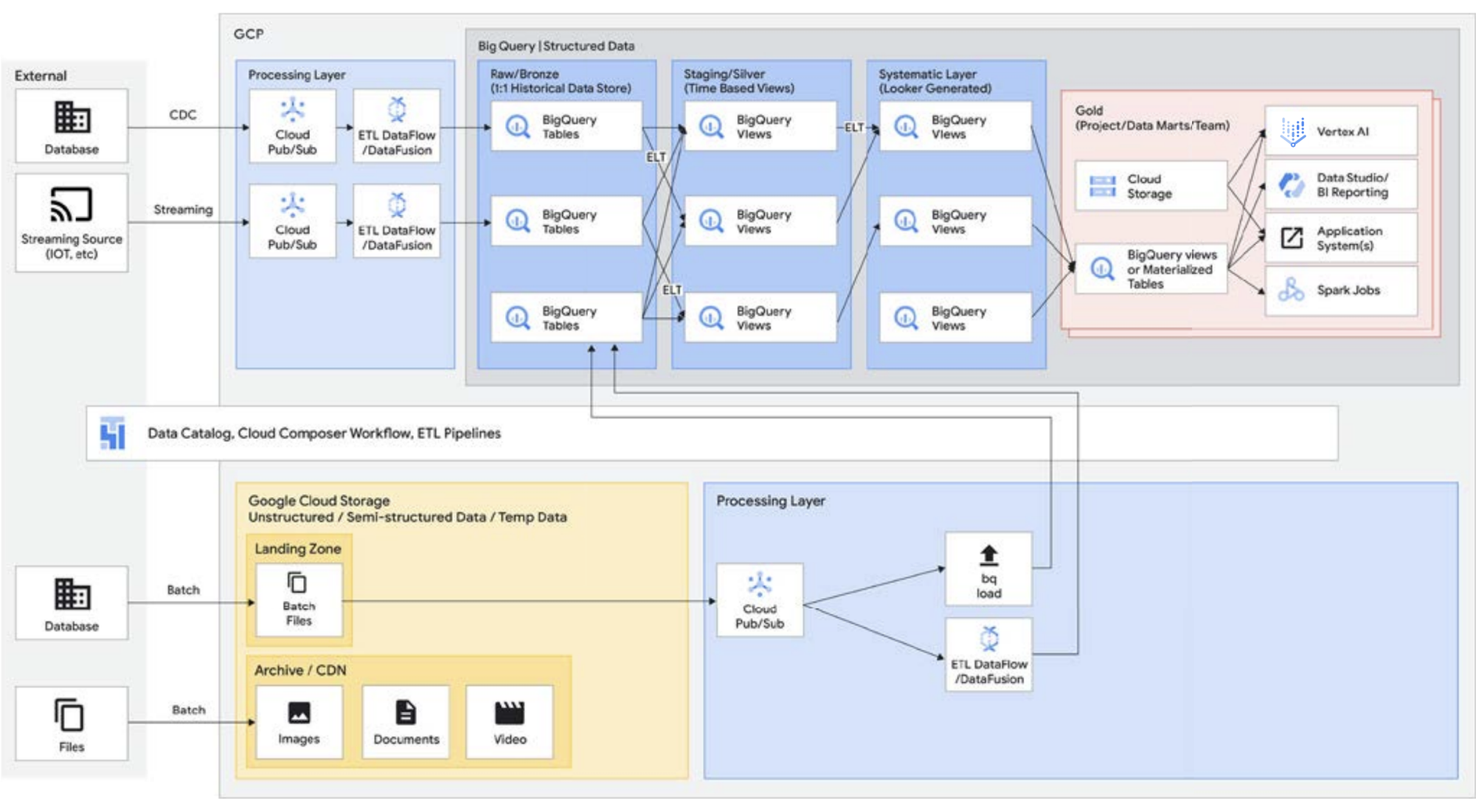
Bei der Durchführung von ETL finden die Transformationen außerhalb von BigQuery statt, möglicherweise in einem Tool, das sich nicht so gut skalieren lässt. Dies könnte dazu führen, dass die Daten Zeile für Zeile transformiert werden, anstatt die Abfragen zu parallelisieren. Es kann Fälle geben, in denen Spark oder andere ETL-Prozesse bereits kodifiziert sind und Änderungen an ihnen zugunsten einer neuen Technologie nicht sinnvoll sind. Wenn es jedoch Transformationen gibt, die in SQL geschrieben werden können, ist BigQuery wahrscheinlich ein guter Ort dafür.
Darüber hinaus wird diese Architektur von allen Google Cloud-Komponenten wie Managed Service for Apache Airflow, Data Catalog oder Data Fusion unterstützt. Sie bietet eine End-to-End-Ebene für verschiedene User Personas. Ein weiterer wichtiger Aspekt zur Reduzierung des operativen Aufwands kann durch die Nutzung der Funktionen der zugrunde liegenden Infrastruktur erreicht werden. Nehmen wir als Beispiel Dataflow und BigQuery, die alle in Containern ausgeführt werden und es uns ermöglichen, die Betriebszeit und die Funktionsweise im Hintergrund zu verwalten. Sobald dies auf Drittanbieter- und Partner-Tools ausgeweitet wird und sie ähnliche Funktionen wie Kubernetes ausprobieren, wird sie viel einfacher zu verwalten und zu übertragen. Dies reduziert wiederum die Ressourcennutzung und den operativen Aufwand. Darüber hinaus wird dies durch eine bessere Beobachtbarkeit ergänzt, indem Monitoring-Dashboards mit Managed Service for Apache Airflow genutzt werden, um für operative Exzellenz zu sorgen. Sie können einen Data Lake erstellen, indem Sie die in Cloud Storage und BigQuery gespeicherten Daten zusammenführen, ohne sie verschieben oder duplizieren zu müssen. Außerdem bieten wir zusätzliche administrative Funktionen zur Verwaltung Ihrer Datenquellen. Knowledge Catalog (ehemals Dataplex) ermöglicht ein Lakehouse, indem es eine zentrale Verwaltungsebene zur Koordinierung von Daten in Cloud Storage und BigQuery bereitstellt. Auf diese Weise können Sie Ihre Daten entsprechend Ihren Geschäftsanforderungen organisieren, sodass keine Einschränkungen mehr dahingehend bestehen, wie oder wo sie gespeichert werden.
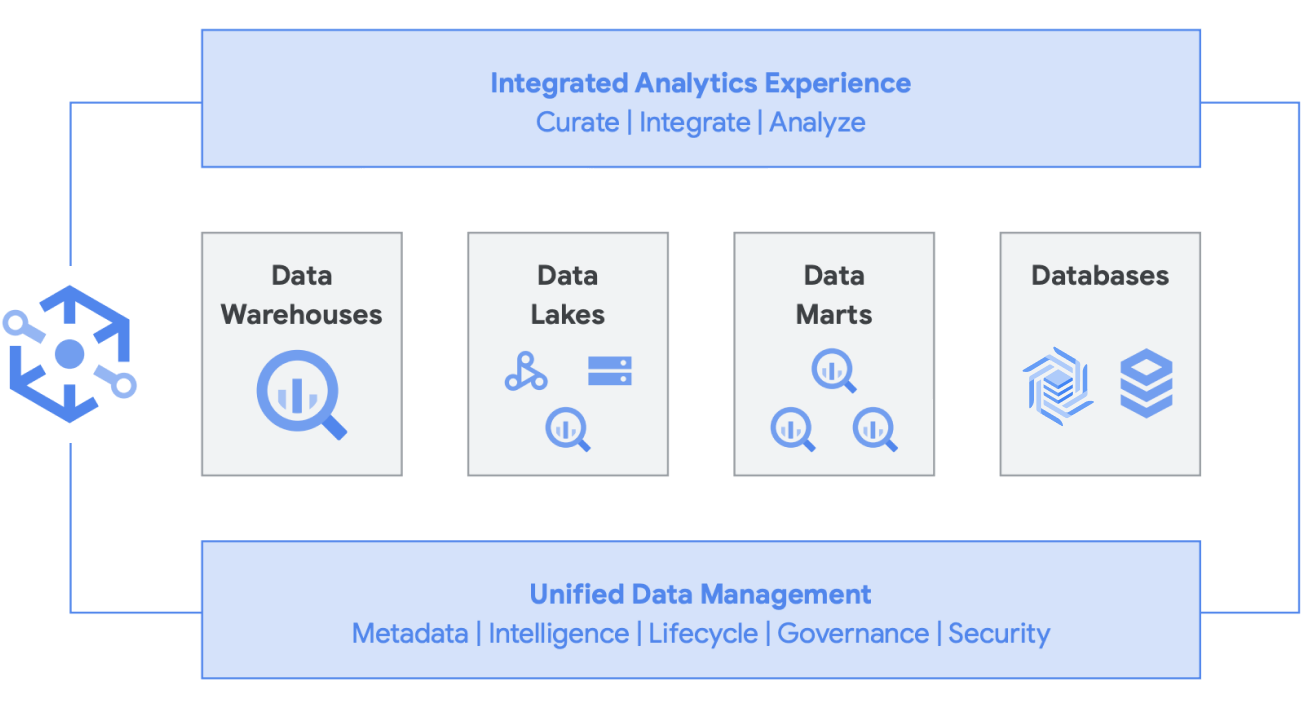
Knowledge Catalog ist eine intelligente Datenstruktur, mit der Sie Daten im richtigen Preis-Leistungs-Verhältnis verteilen können. Gleichzeitig können Sie für alle Ihre Analysetools einen sicheren Zugriff auf diese Daten ermöglichen. Dank der metadatengestützten Datenverwaltung mit integrierter Datenqualität und Governance sparen Sie Zeit im Umgang mit den Grenzen und Ineffizienzen der Infrastruktur. Sie können den Daten, die sie haben, vertrauen und die gesparte Zeit damit verbringen, diese Daten sinnvoll zu nutzen. Dank der integrierten Analyse, die das Beste von Google Cloud und Open Source kombiniert, können Sie Ihre Daten schnell kuratieren, sichern, einbinden und in großem Umfang analysieren. Und nicht zuletzt können Sie eine Analysestrategie als Ergänzung zur bestehenden Architektur erstellen, die auch Ihre Ziele im Bereich finanzieller Governance erfüllt.
Data Mesh
Data Mesh baut auf einer langjährigen Innovationsgeschichte bezüglich Data Warehouses und Data Lakes auf, kombiniert mit Zahlungsmodellen für beispiellose Skalierbarkeit und Leistung, APIs, DevOps und der engen Einbindung von Google Cloud-Produkten. Mit diesem Ansatz können Sie effektiv eine On-Demand-Datenlösung erstellen. Bei einem Data Mesh wird die Eigentümerschaft von Daten zwischen Domaininhabern dezentralisiert, die jeweils für die standardmäßige Bereitstellung ihrer Daten als Produkt verantwortlich sind. Ein Data Mesh erleichtert auch die Kommunikation zwischen verschiedenen Teilen des Unternehmens mit verteilten Datasets über verschiedene Standorte hinweg. In einem Data Mesh liegt die Verantwortung für die Wertschöpfung aus Daten bei den Menschen, die sie am besten verstehen. Mit anderen Worten: Die Personen, die die Daten erstellt oder in das Unternehmen eingebracht haben, müssen auch dafür verantwortlich sein, verwertbare Daten-Assets als Produkte aus den von ihnen erzeugten Daten zu erstellen. In vielen Unternehmen ist es schwierig, eine „Single Source of Truth“ oder „maßgebliche Datenquelle“ einzurichten, da Daten im gesamten Unternehmen wiederholt extrahiert und transformiert werden, da es keine klaren Verantwortlichkeiten für die neu erstellten Daten gibt. Im Data Mesh ist die maßgebliche Datenquelle das von der Quelldomain veröffentlichte Datenprodukt mit einem eindeutig zugewiesenen Dateninhaber und ‐verwalter, der für diese Daten verantwortlich ist.
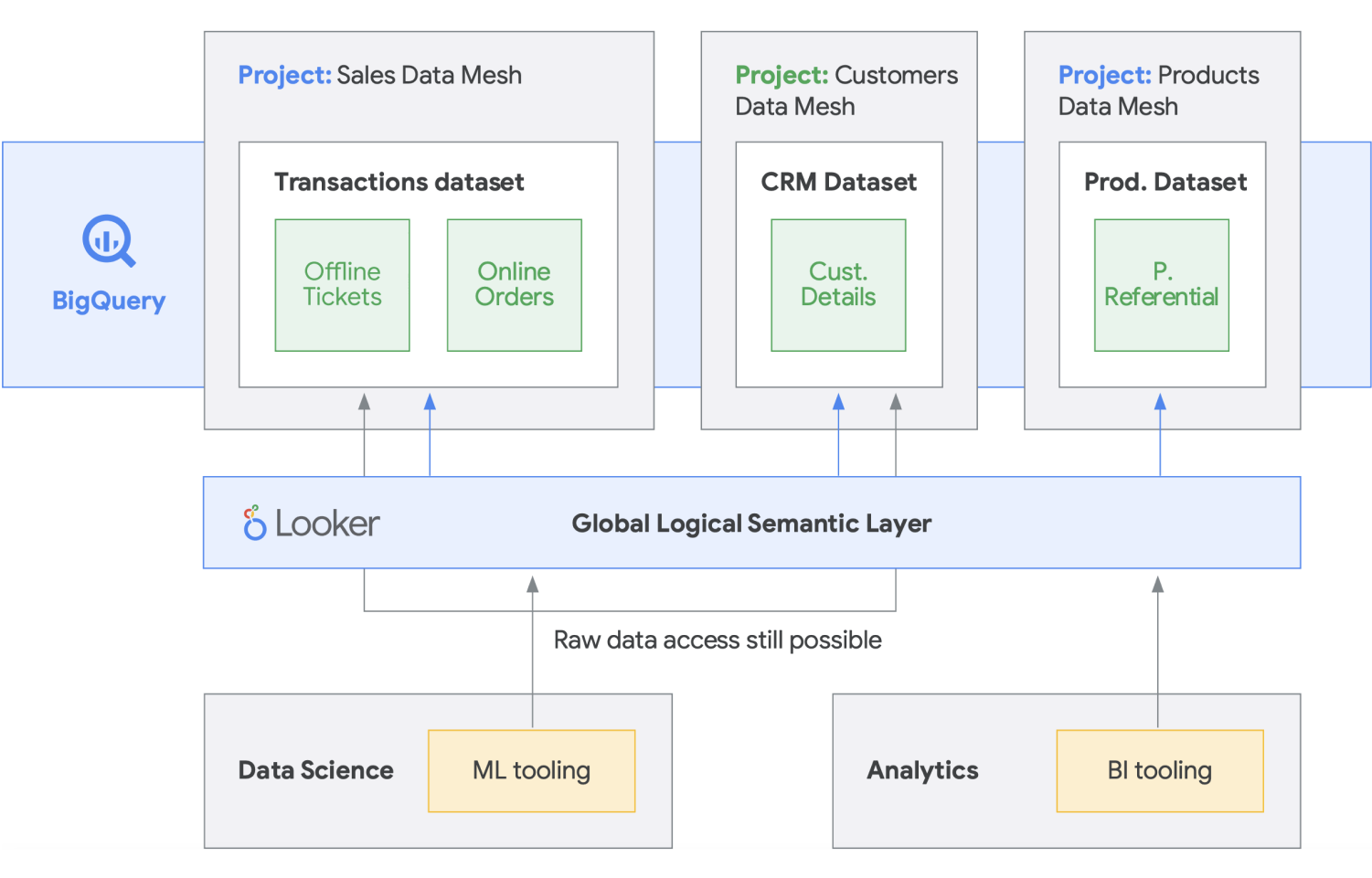
Zusammenfassend lässt sich sagen, dass Data Mesh eine domainorientierte, dezentrale Dateninhaberschaft und -architektur verspricht. Dies wird durch die föderierte Berechnung und die Zugriffsebenen ermöglicht, wie wir es in Google Cloud anbieten. Wenn Ihr Unternehmen darüber hinaus mehr Funktionalität wünscht, können Sie eine Lösung wie Looker verwenden, die eine einheitliche Ebene für die Modellierung und den Zugriff auf die Daten bieten kann. Die Plattform von Looker bietet eine zentrale Benutzeroberfläche für den Zugriff auf die aktuellste und wahrheitsgemäße Version der Daten und Geschäftsdefinitionen Ihres Unternehmens. Mit dieser ganzheitlichen Übersicht über das Unternehmen können Sie Datenerlebnisse auswählen oder gestalten, die dafür sorgen, dass Personen und Systeme Daten auf eine Weise erhalten, die für ihre Anforderungen am sinnvollsten ist. Sie fügt sich perfekt ein, da Data Scientists, Analysten und sogar geschäftliche Nutzer mit einem einzigen semantischen Modell auf ihre Daten zugreifen können. Datenwissenschaftler greifen immer noch auf die Rohdaten zu, jedoch ohne die Datenverschiebung und -duplizierung.
Wir entwickeln zusätzliche Funktionen für unsere wichtigsten Produkte wie BigQuery, um das Erstellen und Verwalten von Datasets zu vereinfachen. Mit Analytics Hub können Sie einen privaten Datenaustausch erstellen, bei dem Exchange-Administratoren (auch Datenkuratoren genannt) Berechtigungen zum Veröffentlichen und Abonnieren von Daten im Austausch für bestimmte Personen oder Gruppen innerhalb und außerhalb des Unternehmens, z. B. Geschäftspartnern oder Käufern, erteilen.
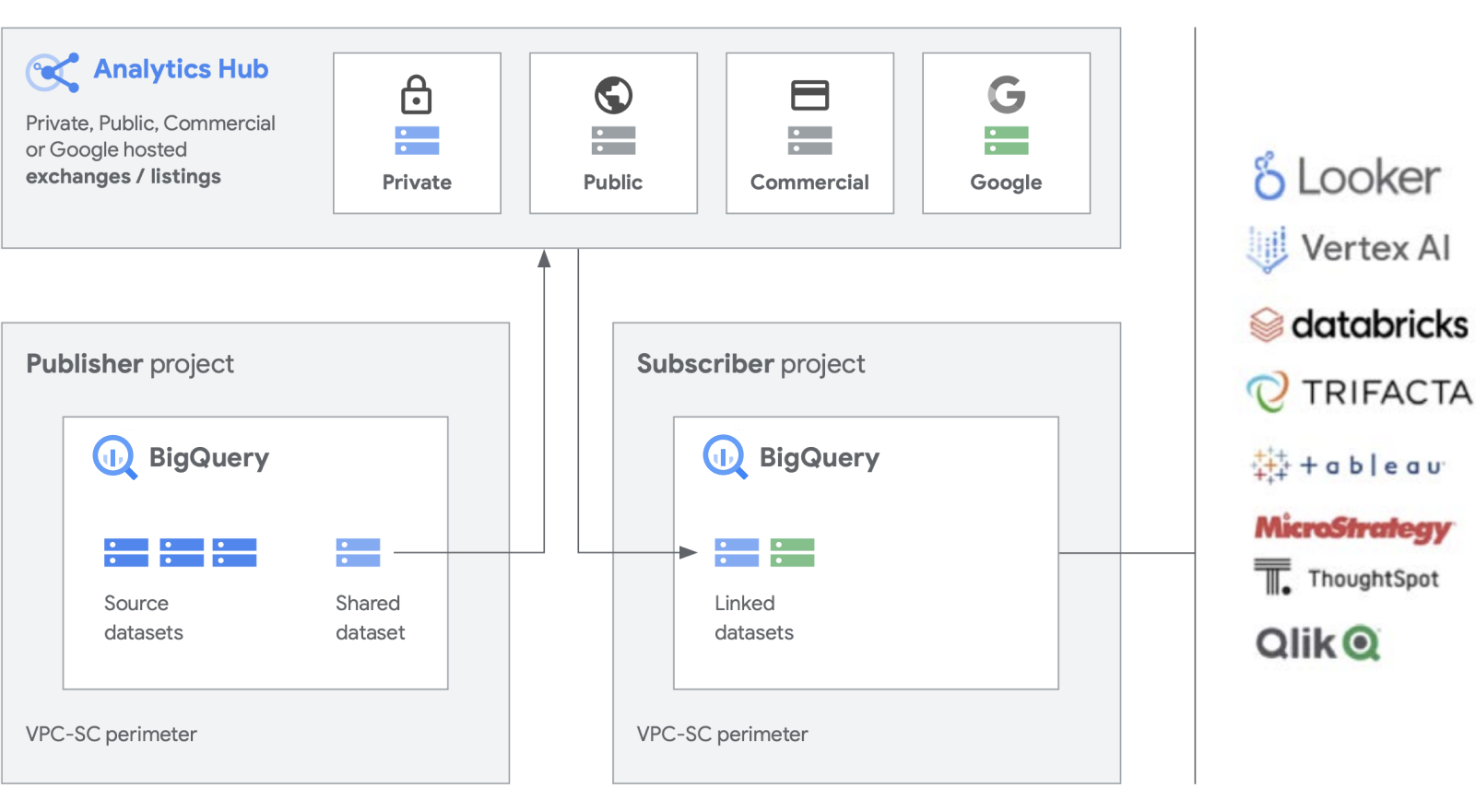
Veröffentlichen, Entdecken oder Abonnieren von freigegebenen Assets, einschließlich Open-Source-Formaten, mit der Skalierbarkeit von BigQuery. Publisher können zusammengefasste Nutzungsdaten anzeigen. Datenanbieter können Unternehmenskunden, die BigQuery nutzen, mit Daten, Statistiken, ML-Modellen oder Visualisierungen erreichen und den Cloud Marketplace zur Monetarisierung ihrer Apps, Statistiken oder Modelle nutzen. Ähnlich werden auch öffentliche BigQuery-Datasets über einen von Google verwalteten Austausch verwaltet. Innovation fördern mit dem Zugriff auf einzigartige Datasets von Google, kommerzielle/branchenspezifische Datasets, öffentliche Datasets oder auf kuratierten Datenaustausch mit Ihren Unternehmens- oder Partnerumgebungen.
Umgang mit Legacy-Systemen
Es klingt zwar toll, eine komplett neue Datenplattform von Grund auf zu entwickeln, aber wir wissen, dass nicht jedes Unternehmen in der Lage sein wird, dies zu tun. Die meisten haben es mit bestehenden Legacy-Systemen zu tun, die sie migrieren, portieren oder patchen müssen, bis sie ersetzt werden können. Wir haben mit unseren Kunden in jeder Phase ihrer Datenplattform gearbeitet und bieten Lösungen für Ihre Situation.
Bei Kunden gibt es in der Regel drei Migrationskategorien: Lift-and-Replatforming (Plattformwechsel), Lift-and-Rehome und vollständige Modernisierung. Für die meisten Unternehmen empfehlen wir, mit der Lift-and-Replatforming-Strategie zu beginnen, da dies eine effektive Migration mit so wenig Unterbrechungen und Risiken wie möglich ermöglicht. Mit dieser Strategie migrieren Sie Ihre Daten von Ihren Legacy-Data-Warehouses und Hadoop-Clustern zu BigQuery oder Managed Service for Apache Spark. Nachdem die Daten verschoben wurden, können Sie die Leistung Ihrer Datenpipelines und Abfragen optimieren. Mit einer Lift-and-Replatforming-Migrationsstrategie können Sie dies je nach Komplexität Ihrer Arbeitslasten in Phasen vornehmen. Aufgrund der Komplexität empfehlen wir diesen Ansatz für große Unternehmenskunden mit zentralisierter IT und mehreren Geschäftseinheiten.
Die zweite Migrationsstrategie, die wir am häufigsten sehen, ist die vollständige Modernisierung als erster Schritt. So schaffen Sie Klarheit und bereinigen die Vergangenheit, da Sie voll und ganz auf einen cloudnativen Ansatz setzen. Die Migration ist nativ in Google Cloud erstellt, aber da Sie alles auf einmal ändern, kann dies länger dauern, wenn Sie mehrere große Legacy-Umgebungen haben.

Für eine saubere Legacy-Pause müssen Jobs umgeschrieben und verschiedene Anwendungen geändert werden. Im Vergleich zu den anderen Ansätzen sorgt dies jedoch auch für höhere Geschwindigkeit und Agilität sowie langfristig die niedrigsten Gesamtbetriebskosten. Das hat zwei Hauptgründe: Ihre Anwendungen sind bereits optimiert und müssen nicht nachgerüstet werden. Nach der Migration Ihrer Datenquellen müssen Sie nicht zwei Umgebungen gleichzeitig verwalten. Dieser Ansatz eignet sich am besten für Digital Natives oder entwicklungsorientierte Unternehmen mit wenigen Legacy-Umgebungen.
Der konservativste Ansatz ist ein Lift-and-Rehome-Ansatz, den wir als kurzfristige taktische Lösung zum Verschieben Ihres Datenbestands in die Cloud empfehlen. Sie können Ihre bestehenden Plattformen per Lift-and-Shift umgestalten und sie wie gewohnt in der Google Cloud-Umgebung verwenden. Dies gilt für Umgebungen wie Teradata und Databricks, um das anfängliche Risiko zu reduzieren und die Ausführung von Anwendungen zu ermöglichen. Dadurch wird jedoch die vorhandene isolierte Umgebung in die Cloud verschoben, anstatt sie zu transformieren. Daher profitieren Sie nicht von der Leistung einer Plattform, die nativ auf Google Cloud basiert. Wir können Sie jedoch bei einer vollständigen Migration in native Google Cloud-Produkte unterstützen, damit Sie von der Interoperabilität profitieren und eine vollständig moderne Analysedatenplattform in Google Cloud erstellen können.
Taktisch oder strategisch?
Die Hauptunterschiede einer auf Google Cloud basierenden Analysedatenplattform bestehen unserer Meinung nach darin, dass sie offen, intelligent, flexibel und eng eingebunden ist. Auf dem Markt gibt es viele Lösungen mit taktischen Ansätzen, die sich vertraut und angenehm anfühlen. Diese sind in der Regel jedoch nur eine kurzfristige Lösung, die eine Organisation erschweren und im Laufe der Zeit zu technischen Problemen führen können.
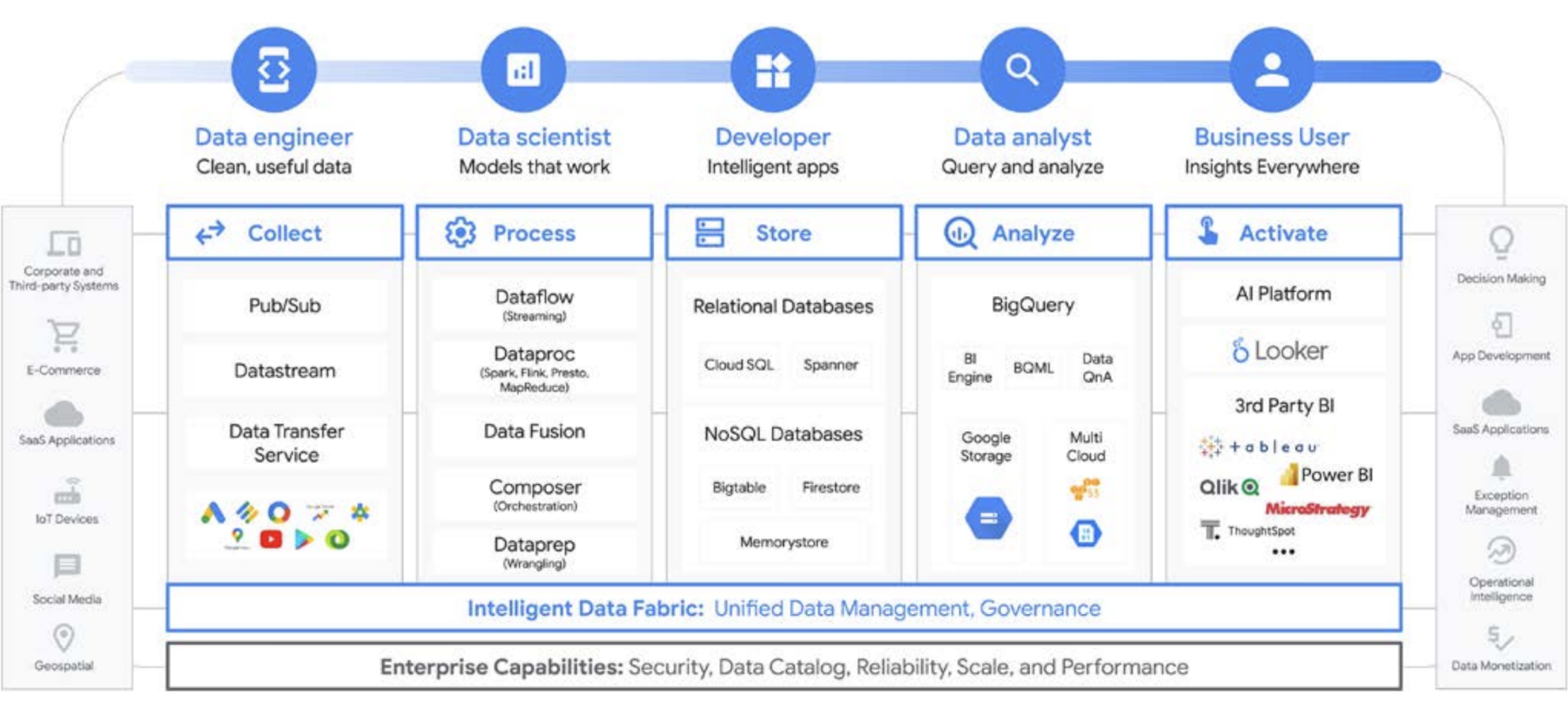
Google Cloud vereinfacht Datenanalysen erheblich. Mit einem cloudnativen, serverlosen Ansatz können Sie das in Ihren Daten versteckte Potenzial nutzen. Speicher und Rechenleistung werden getrennt und Sie können Gigabyte bis Petabyte an Daten innerhalb weniger Minuten analysieren. Auf diese Weise können Sie die traditionellen Einschränkungen in Bezug auf Umfang, Leistung und Kosten beseitigen, um Fragen zu Daten zu stellen und Geschäftsprobleme zu lösen. Dadurch wird es einfacher, Informationen im gesamten Unternehmen mit einer einzigen, vertrauenswürdigen Datenstruktur zu operationalisieren.
Vorteile
- Sie können sich auf die Analyse statt auf die Infrastruktur konzentrieren
- Löst alle Phasen des Data-Analytics-Lebenszyklus, von der Aufnahme über die Transformation und Analyse bis hin zu Business Intelligence und mehr
- Schafft eine solide Datengrundlage für die Operationalisierung von maschinellem Lernen
- Ermöglicht die Nutzung der besten Open-Source-Technologien für Ihr Unternehmen
- Die Skalierung erfolgt entsprechend den Anforderungen Ihres Unternehmens, insbesondere bei zunehmender Nutzung von Daten für die Geschäftsförderung und durch die digitale Transformation.
Eine moderne, einheitliche Datenanalyseplattform, die auf Google Cloud aufbaut, bietet Ihnen die besten Funktionen eines Data Lake und eines Data Warehouse, aber mit enger Einbindung in die KI-Plattform. Sie können Daten aus Milliarden von Streamingereignissen automatisch in Echtzeit verarbeiten und quasi innerhalb von Millisekunden Informationen bereitstellen, um auf sich ändernde Kundenbedürfnisse zu reagieren. Mit unseren branchenführenden KI-Diensten können Sie die Entscheidungsfindung in Ihrem Unternehmen und die Kundenzufriedenheit optimieren und die Lücke zwischen beschreibenden und präskriptiven Analysen schließen, ohne ein neues Team einstellen zu müssen. Sie können Ihre vorhandenen Fähigkeiten erweitern, um die Auswirkungen von KI mit automatisierter, integrierter Intelligenz zu skalieren.
Gleich loslegen
Möchten Sie mehr darüber erfahren, wie die Datenplattform von Google die Art und Weise verändern kann, wie Ihr Unternehmen mit Daten umgeht? Nehmen Sie Kontakt mit uns auf.
Benötigen Sie Hilfe beim Einstieg?
Vertrieb kontaktierenMit einem zertifizierten Partnerunternehmen arbeiten
Partner findenMehr ansehen
Alle Produkte ansehen


















