Sichere Bereitstellung von Software
Unternehmen konzentrieren sich heute, was Software und Anwendungen angeht, auf Geschwindigkeit und Zeit bis zur Markteinführung. Bestehende Sicherheitspraktiken können jedoch nicht mit dieser Geschwindigkeit Schritt halten, was zu Verzögerungen bei der Entwicklung, riskanten Kompromissen und Sicherheitslücken führt.
In diesem Bericht erfahren Sie, wie Sie das Problem der Sicherheit der Softwarelieferkette lösen können. Dazu müssen Sie:
– Branchenweite Standards und Frameworks nutzen
– Diese Standards in verwalteten Diensten implementieren, bei denen die Prinzipien der geringsten Berechtigung in einer Zero-Trust-Architektur verwendet werden
Erfahren Sie, wie Sie auf sichere Weise vom Programmieren bis zum Erstellen, Verpacken, Bereitstellen und Ausführen von Software kommen.
Informationen zur Softwarelieferkette
Aktuelle Sicherheitslandschaft
Geschwindigkeit und Produkteinführungszeit stellen international für Unternehmen, die Kundenbedürfnisse mit Software und Anwendungen ansprechen, die oberste Priorität dar. Diese strategischen Imperative sind die treibende Kraft hinter dem enormen Wachstum von Containern als Plattform der Wahl. Im letzten Jahr haben viele Unternehmen von den Vorteilen von Containern profitiert, darunter schnellere Produkteinführungen, höhere Verfügbarkeit, mehr Sicherheit, bessere Skalierbarkeit und geringere Kosten. Viele dieser Unternehmen haben auch begonnen, über den serverlosen Ansatz nachzudenken.
Softwarelösungen haben zwar den Zeitaufwand für die Bereitstellung eines neuen Features oder sogar für die Entwicklung eines neuen Produkts reduziert, aber viele bestehende Sicherheitspraktiken kommen bei diesem Tempo nicht mit, was zu einem von drei Problemen führt:
- Entwickler werden durch bestehende Prozesse behindert, was zu Verzögerungen führt
- Sicherheits- und Betriebsteams machen Kompromisse, was das Unternehmen Bedrohungen aussetzt
- Entwicklerteams umgehen bestehende Sicherheitsprozessen um Fristen einzuhalten, was zu Anfälligkeiten führt
In den letzten Jahren gab es eine Reihe von Sicherheitsverletzungen, die als Angriffe auf die Software-Lieferkette eingestuft wurden.
Log4Shell war eine gefährliche Sicherheitslücke in der Apache Log4j-Software, die im Dezember 2021 identifiziert wurde. Diese Sicherheitslücke wurde mit der maximalen CVSS-Bewertung von 10 gekennzeichnet und war besonders verheerend, da Log4j, ein Java-basiertes Logging-Framework, so beliebt ist. Zwei Faktoren haben zum Schweregrad beigetragen: Erstens war es sehr einfach, sie auszunutzen, und sie ermöglichte die vollständige Codeausführung per Fernzugriff. Zweitens lag sie oft viele Ebenen tief in der Abhängigkeitsstruktur und wurde somit leicht übersehen.
Solarwinds, ein IT-Verwaltungssoftware-Unternehmen, wurde von nationalen Akteuren angegriffen, die bösartigen Code in offizielle Open-Source-Software-Builds einschleusten. Dieses schädliche Update wurde an 18.000 Kunden geliefert, darunter die US-Schatzkammer und das US-Handelsministerium.
Kaseya, ein anderer IT-Verwaltungssoftware-Anbieter, wurde über eine Zero-Day-Sicherheitslücke angegriffen, die den Kaseya-VSA-Server manipulierte und ein schädliches Skript sendete, um Ransomware einzuschleusen, die alle Dateien auf den betroffenen Systemen verschlüsselte.
Der dringende Bedarf, auf diese und ähnliche Vorfälle zu reagieren, führte im Weißen Haus im Mai 2021 zu einer Anordnung des Präsidenten, laut der Organisationen, die mit der Bundesregierung zusammenarbeiten, bestimmte Softwarestandards aufrechterhalten müssen.
Die Softwarelieferkette
In vielerlei Hinsicht ist der Begriff „Softwarelieferkette“ sehr treffend: Die Prozesse zur Erstellung einer Softwarelieferkette sind denen in der Automobilproduktion sehr ähnlich.
Ein Autohersteller bezieht verschiedene Standardteile, stellt eigene proprietäre Komponenten her und baut diese in einem stark automatisierten Prozess zusammen. Der Hersteller sorgt für die Sicherheit seiner Vorgänge, indem er dafür sorgt, dass jede Drittanbieterkomponente aus einer vertrauenswürdigen Quelle stammt. Eigene Komponenten werden umfassend getestet, um sicherzustellen, dass es keine Sicherheitsprobleme gibt. Schließlich wird die Montage durch einen vertrauenswürdigen Prozess durchgeführt, der zu fertigen Autos führt.
Die Softwarelieferkette ist in vielerlei Hinsicht ähnlich. Ein Softwarehersteller erhält Komponenten von Drittanbietern, die oft Open Source sind und bestimmte Funktionen erfüllen. Außerdem entwickelt er seine eigene Software, die sein geistiges Eigentum ist. Der Code wird dann durch einen Build-Prozess ausgeführt, bei dem diese Komponenten zu bereitstellbaren Artefakten kombiniert werden, die dann in die Produktion übernommen werden.
Das schwache Glied in der Kette
Es genügt ein einziges ungesichertes Glied in der Kette, um die Software-Lieferkette zu durchbrechen.
Wie bei den bekannten Angriffen im letzten Jahr kann jeder Schritt im Prozess zu einer Sicherheitslücke führen, die Angreifer ausnutzen können.
Das durchschnittliche npm-Paket hat beispielsweise 12 direkte Abhängigkeiten und ungefähr 300 indirekte Abhängigkeiten. Außerdem wissen wir, dass fast 40 % aller veröffentlichten npm-Pakete von Code mit bekannten Sicherheitslücken abhängen.
Diese Sicherheitslücken machen den Code nicht notwendigerweise unsicher. Eine Sicherheitslücke kann beispielsweise ein Teil einer Bibliothek sein, der niemals verwendet wird. Diese Sicherheitslücken müssen aber geprüft werden.
Die Größenordnung dieses Problems ist monumental. Wenn auch nur eine dieser Sicherheitslücken nicht gepatcht werden sollte, könnten böswillige Akteure Zugang zu Ihrer Softwarelieferkette erhalten.
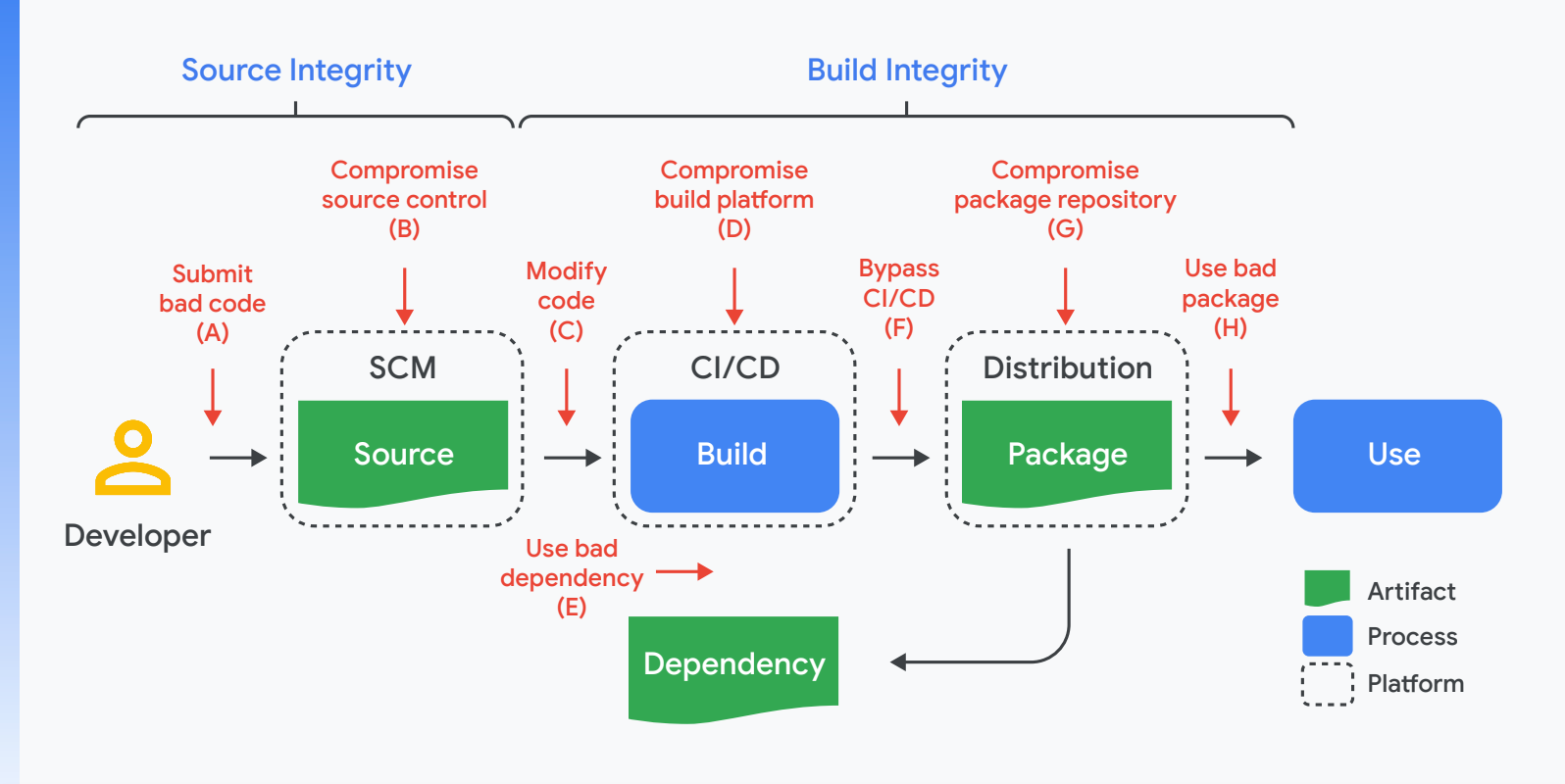
Im Folgenden finden Sie einige Beispiele für Angriffe, bei denen Sicherheitslücken in den verschiedenen im Diagramm oben dargestellten Phasen genutzt wurden.
Bedrohung | Bekanntes Beispiel | |
A | Ungültiger Code wird an das Quell-Repository gesendet | Linux-Hypocrite-Commits: Ein Forscher versuchte bewusst, über Patches auf der Mailingliste Sicherheitslücken in den Linux-Kernel einzuführen. |
B | Manipulierte Versionsverwaltungsplattform | PHP: Der Angreifer hat den selbst gehosteten Git-Server von PHP manipuliert und zwei schädliche Commits eingeschleust. |
K | Build wird gemäß dem offiziellem Prozess erstellt, aber aus Code, der nicht mit der Quellensteuerung übereinstimmt | Webmin: Der Angreifer hat die Build-Infrastruktur so geändert, dass Quelldateien verwendet werden, die nicht mit der Quellenkontrolle übereinstimmen. |
D | Manipulierte Build-Plattform | SolarWinds: Der Angreifer hat die Build-Plattform manipuliert und ein Implantat installiert, um böswilliges Verhalten in jeden Build einzuschleusen. |
O | Schlechte Abhängigkeit (z. B. A-H, rekursiv) | Event-Stream: Der Angreifer hat eine harmlose Abhängigkeit hinzugefügt und dann die Abhängigkeit aktualisiert, um schädliches Verhalten hinzuzufügen. Die Aktualisierung stimmte nicht mit dem an GitHub gesendeten Code überein (siehe Angriff F). |
F | Es wurde ein Artefakt hochgeladen, das nicht vom CI/CD-System erstellt wurde | Codecov: Der Angreifer nutzte gehackte Anmeldedaten, um ein schädliches Artefakt in einen Google Cloud Storage-Bucket hochzuladen, von dem Nutzer direkt Elemente herunterladen. |
G | Kompromittiertes Package Repository | Angriffe auf Paketspiegel: Ein Forscher hat Spiegel für mehrere beliebte Package Repositories ausgeführt, die für die Bereitstellung schädlicher Pakete verwendet werden könnten. |
H | Nutzer wurden zur Verwendung eines falschen Pakets gebracht | Browser-Typosquatting: Der Angreifer hat ein schädliches Paket mit einem ähnlichen Namen hochgeladen. |
Bedrohung
Bekanntes Beispiel
A
Ungültiger Code wird an das Quell-Repository gesendet
Linux-Hypocrite-Commits: Ein Forscher versuchte bewusst, über Patches auf der Mailingliste Sicherheitslücken in den Linux-Kernel einzuführen.
B
Manipulierte Versionsverwaltungsplattform
PHP: Der Angreifer hat den selbst gehosteten Git-Server von PHP manipuliert und zwei schädliche Commits eingeschleust.
K
Build wird gemäß dem offiziellem Prozess erstellt, aber aus Code, der nicht mit der Quellensteuerung übereinstimmt
Webmin: Der Angreifer hat die Build-Infrastruktur so geändert, dass Quelldateien verwendet werden, die nicht mit der Quellenkontrolle übereinstimmen.
D
Manipulierte Build-Plattform
SolarWinds: Der Angreifer hat die Build-Plattform manipuliert und ein Implantat installiert, um böswilliges Verhalten in jeden Build einzuschleusen.
O
Schlechte Abhängigkeit (z. B. A-H, rekursiv)
Event-Stream: Der Angreifer hat eine harmlose Abhängigkeit hinzugefügt und dann die Abhängigkeit aktualisiert, um schädliches Verhalten hinzuzufügen. Die Aktualisierung stimmte nicht mit dem an GitHub gesendeten Code überein (siehe Angriff F).
F
Es wurde ein Artefakt hochgeladen, das nicht vom CI/CD-System erstellt wurde
Codecov: Der Angreifer nutzte gehackte Anmeldedaten, um ein schädliches Artefakt in einen Google Cloud Storage-Bucket hochzuladen, von dem Nutzer direkt Elemente herunterladen.
G
Kompromittiertes Package Repository
Angriffe auf Paketspiegel: Ein Forscher hat Spiegel für mehrere beliebte Package Repositories ausgeführt, die für die Bereitstellung schädlicher Pakete verwendet werden könnten.
H
Nutzer wurden zur Verwendung eines falschen Pakets gebracht
Browser-Typosquatting: Der Angreifer hat ein schädliches Paket mit einem ähnlichen Namen hochgeladen.
Stärkung der Kette: Google Cloud ist Open-Source-Vordenker
Google entwickelt seit Jahrzehnten globale Anwendungen. Im Laufe der Zeit haben wir viele unserer internen Projekte als Open Source veröffentlicht, um die Entwicklungsgeschwindigkeit zu erhöhen. Gleichzeitig haben wir verschiedene interne Prozesse entwickelt, um das Software-Erlebnis zu sichern.
Hier erläutern wir einige der Anstrengungen, die wir ergreifen, um die Softwarelieferkette grundsätzlich zu stärken.
- Höhere Investition: Im August 2020 haben wir angekündigt, dass wir in den nächsten fünf Jahren 10 Milliarden $ investieren werden, um die Internetsicherheit zu verbessern. Unter anderem wollen wir die Verbreitung von Zero-Trust-Programmen stärken, um so zum Schutz der Softwarelieferkette beizutragen und die Open-Source-Sicherheit zu verbessern.
- Lieferkettenebenen für Software-Artefakte (SLSA, Supply-chain Levels for Software Artifacts): SLSA ist ein End-to-End-Framework, das die Integrität der Lieferkette stärkt. Es ist eine Open-Source-Entsprechung der vielen Prozesse, die wir intern bei Google implementiert haben. SLSA bietet eine prüfbare Herkunft dessen, was in einen Built eingeht, und wie.
- DORA (DevOps Research and Assessment): Unser DORA-Team führte ein siebenjähriges Forschungsprogramm durch, das verschiedene technische, prozess-, mess- und kulturrelevante Fähigkeiten prüfte, die zu einer gesteigerten Softwarebereitstellung und Unternehmensleistung beitragen.
- Open Source Security Foundation: 2019 wurden wir Mitgründer der Open Source Security Foundation, einem branchenübergreifenden Forum zur Sicherung der Lieferkette.
- Allstar: Allstar ist eine GitHub-Anwendung, die in Unternehmen oder Repositories installiert wird, um Sicherheitsrichtlinien festzulegen und durchzusetzen. Dies ermöglicht die kontinuierliche Durchsetzung von Best Practices für die Sicherheit von GitHub-Projekten.
- Open Source Scorecards: Scorecards (Bewertungskarten) nutzen Messwerte wie definierte Sicherheitsrichtlinien, Codeprüfungsprozesse und kontinuierliche Testungen mit Fuzzing- und Statistiktools zur Codeanalyse, um eine Risikobewertung für Open-Source-Projekte zu erstellen.
Wir glauben, dass zwei Dinge notwendig sind, um das Sicherheitsproblem der Softwarelieferkette zu überwinden:
- Branchenweite Standards und Frameworks.
- Verwaltete Dienste, die diese Standards anhand der Prinzipien der geringsten Berechtigung implementieren. Diese ist auch als Zero-Trust-Architektur bekannt. In einer Zero-Trust-Architektur wird keiner Person, keinem Gerät und keinem Netzwerk einfach so vertraut. Stattdessen muss das Vertrauen, das zu Zugriff auf Informationen führt, erst gewonnen werden.
Sehen wir uns das einmal an:
Branchenweite Standards und Frameworks
Beginnen wir mit SLSA, um die Prinzipien der Sicherheit der Softwarelieferkette zu verstehen.
In seinem aktuellen Zustand besteht das SLSA aus einer Reihe übernehmbarer Sicherheitsrichtlinien, die im Branchenkonsens etabliert werden. In seiner endgültigen Form wird sich das SLSA von einer Liste mit Best Practices in Bezug auf seine Durchsetzbarkeit unterscheiden, da es die automatische Erstellung prüfbarer Metadaten unterstützen wird, die in Richtlinien-Engines eingespeist werden können, um einem bestimmten Paket oder einer bestimmten Plattform eine „SLSA-Zertifizierung“ hinzuzufügen.
SLSA wurde als stufenweise und umsetzbar entwickelt und bietet in jedem Schritt Sicherheitsvorteile. Sobald ein Artefakt die höchste Ebene erreicht, können Nutzer darauf vertrauen, dass es nicht manipuliert wurde und sicher bis zu seiner Quelle zurückverfolgt werden kann. Das ist heute für die meiste Software schwierig, wenn nicht unmöglich.
SLSA besteht aus vier Ebenen, wobei SLSA 4 den idealen Endzustand darstellt. Die niedrigeren Ebenen stellen inkrementelle Meilensteine mit entsprechenden inkrementellen Integritätsgarantien dar. Die Anforderungen sind derzeit so definiert:
Für SLSA 1 muss der Build-Prozess vollständig skriptbasiert/automatisiert sein und einen Herkunftsbeleg erzeugen. Dieser Herkunftsbeleg besteht aus Metadaten zur Erstellung eines Artefakts, darunter Build-Prozess, Quelle der obersten Ebene und Abhängigkeiten. Über den Herkunftsbeleg können Softwarenutzer risikoabhängige Sicherheitsentscheidungen treffen. Ein Herkunftsbeleg der Stufe SLSA 1 bietet zwar keinen Schutz vor Manipulationen, aber die grundlegende Möglichkeit zur Identifizierung von Codequellen. Dies kann das Management von Sicherheitslücken unterstützen.
SLSA 2 erfordert die Verwendung der Versionsverwaltung und einen gehosteten Build-Dienst, der die authentifizierte Herkunft verwendet. Diese zusätzlichen Anforderungen sorgen für mehr Vertrauen der Nutzer in die Herkunft der Software. Auf dieser Ebene verhindert die Herkunft, dass der Build-Dienst vertrauenswürdig ist. SLSA 2 bietet auch einen einfachen Upgradepfad zu SLSA 3.
SLSA 3 verlangt zusätzlich, dass Quell- und Build-Plattformen bestimmte Standards erfüllen, um die Prüfbarkeit der Quelle und die Integrität des Herkunftsbelegs zu garantieren. SLSA 3 bietet einen viel stärkeren Schutz vor Manipulationen als die vorhergehenden Ebenen, da bestimmte Bedrohungsarten, darunter Cross-Build-Kontaminationen, verhindert werden.
SLSA 4 ist derzeit die höchste Ebene. Sie erfordert eine Prüfung aller Änderungen durch zwei Personen und einen hermetischen, reproduzierbaren Build-Prozess. Die Prüfung durch zwei Personen ist eine branchenübliche Best Practice, die dabei hilft, Fehler zu erkennen und negatives Verhalten zu verhindern. Hermetische Builds stellen sicher, dass die Abhängigkeitsliste des Herkunftsbelegs vollständig ist. Reproduzierbare Builds sind zwar nicht unbedingt erforderlich, bieten aber viele Vorteile in Sachen Prüfbarkeit und Zuverlässigkeit. SLSA 4 sorgt insgesamt dafür, dass Kunden sicher sein können, dass die Software nicht manipuliert wurde. Weitere Informationen zu diesen vorgeschlagenen Ebenen finden Sie im GitHub-Repository, einschließlich der entsprechenden Quell- und Build-/Provenance-Anforderungen.
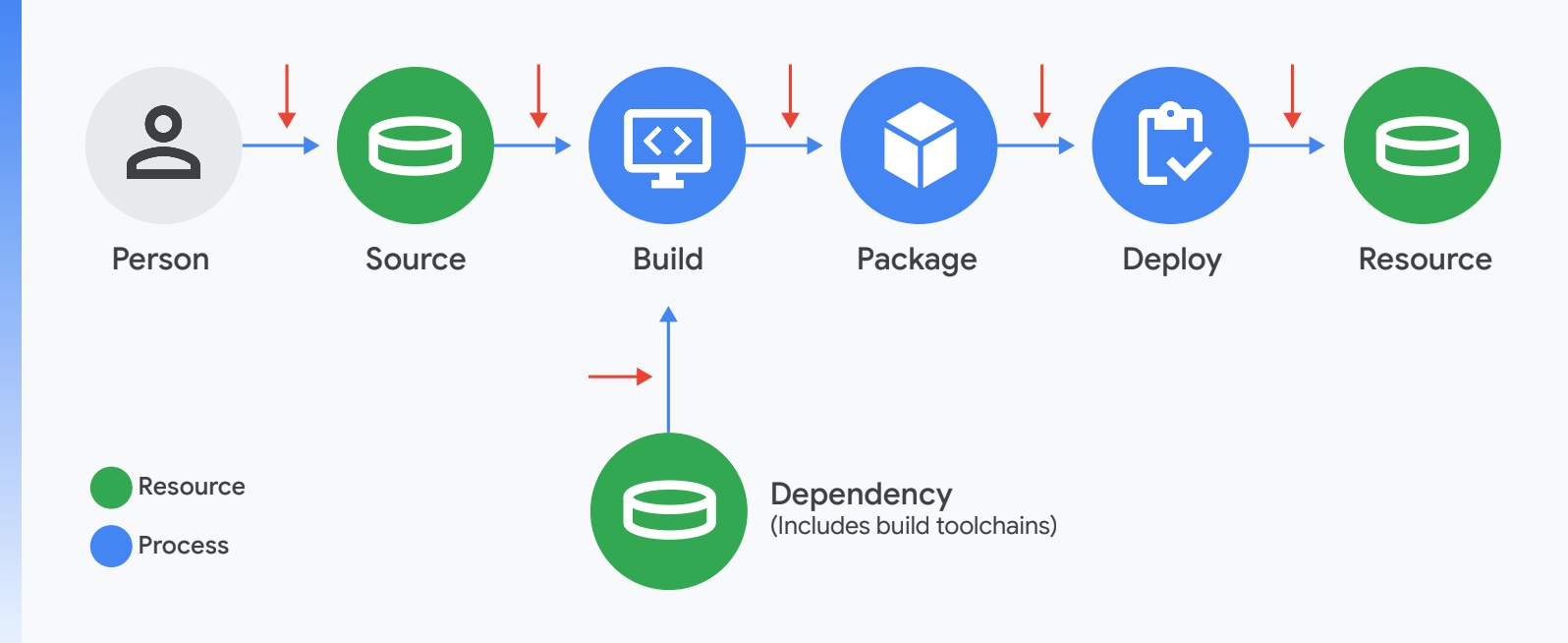
Die Softwarelieferkette kann in fünf verschiedene Phasen unterteilt werden: Programmierung, Build, Verpackung, Bereitstellung und Ausführung. Wir werden uns die einzelnen Phasen in Bezug auf unseren Sicherheitsansatz ansehen.
Verwaltete Dienste für jede Phase
Google Cloud bietet vollständig verwaltete Tools – vom Programmieren und Erstellen bis zum Bereitstellen und Ausführen –, wobei die oben genannten Standards und Best Practices standardmäßig implementiert werden.
Für den Schutz Ihrer Softwarelieferkette ist es erforderlich, eine Vertrauenskette aufzubauen, zu verifizieren und zu pflegen, die die Herkunft Ihres Codes zeigt und dafür sorgt, dass das, was in der Produktionsumgebung ausgeführt ist, Ihren Absichten entspricht. Bei Google erreichen wir dies durch Attestierungen, die während des gesamten Softwareentwicklungs- und Bereitstellungsprozesses generiert und geprüft werden. Dies ermöglicht eine gewisse allgemeine Sicherheit durch Elemente wie Codeprüfung, verifizierte Codeherkunft und Richtlinienerzwingung. Mit diesen Prozessen können wir die Risiken der Softwarelieferkette minimieren und die Produktivität der Entwickler steigern.
Als Basis dienen gängige sichere Infrastrukturdienste wie Identitäts- und Zugriffsverwaltung sowie Audit-Logging. Weiter schützen wir Ihre Softwarelieferkette mit einer Option, Attestierungen für Ihren gesamten Softwarelebenszyklus zu definieren, zu prüfen und durchzusetzen.
Sehen wir uns genauer an, wie Sie die Umgebungssicherheit in Ihrem Entwicklungsprozess in Google Cloud über Richtlinien und Herkunftsbelege erreichen können.
Phase 1: Programmierung
Die Sicherung Ihrer Softwarelieferkette beginnt, wenn Ihre Entwickler mit dem Entwerfen und Schreiben von Code beginnen. Dies umfasst sowohl eigene Software als auch Open-Source-Komponenten, die jeweils eigene Herausforderungen mit sich bringen.
Open-Source-Software und Abhängigkeiten
Open Source ermöglicht es Entwicklern, Inhalte schneller zu erstellen, sodass Unternehmen flexibler und produktiver sein können. Open-Source-Software ist jedoch nicht perfekt. Und obwohl unsere Branche darauf angewiesen ist, haben wir oft nur sehr wenig Einblick in ihre Abhängigkeiten und die unterschiedlichen Risiken, die mit ihr verbunden sind. In den meisten Unternehmen wird das Risiko hauptsächlich durch Sicherheitslücken oder Lizenzfragen bedingt.
Die Open-Source-Software, Pakete, Basis-Images und andere Artefakte, die Sie benötigen, bilden die Grundlage Ihrer "Vertrauenskette".
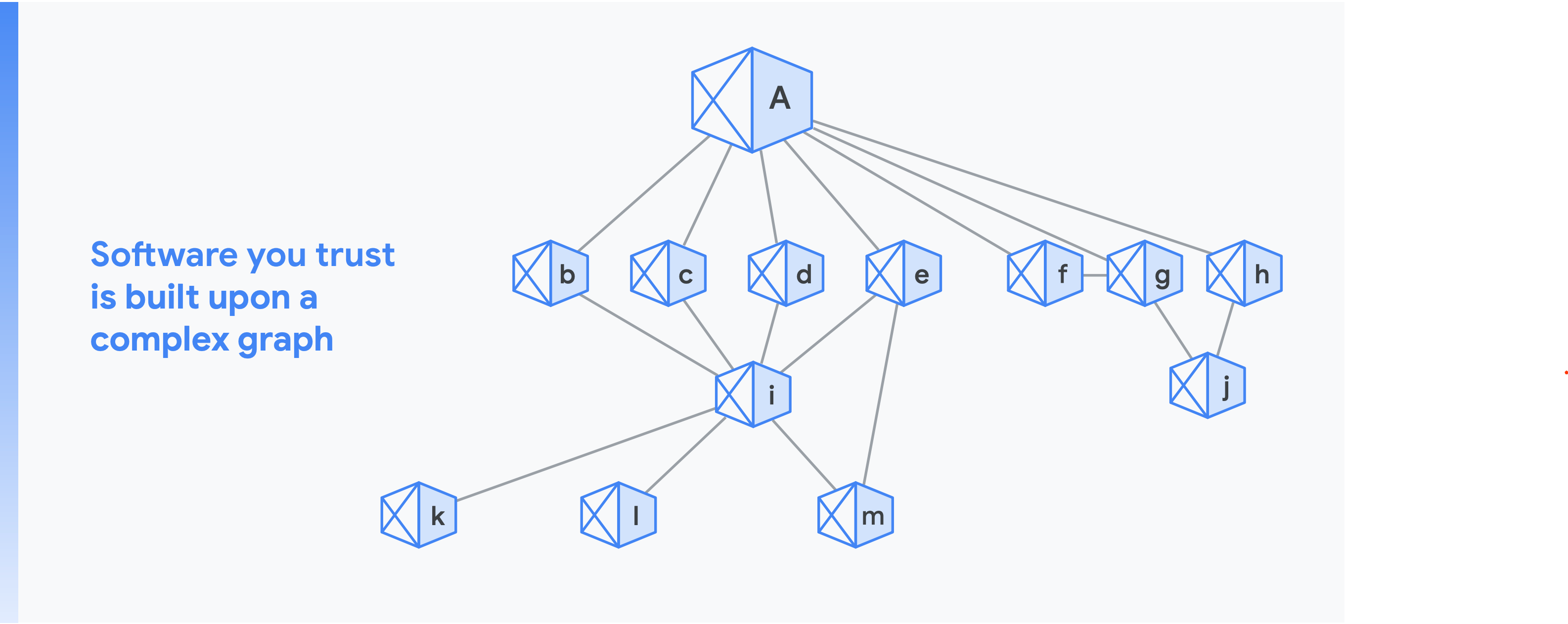
Stellen Sie sich vor, dass Ihre Organisation Software „a“ erstellt. Dieses Diagramm zeigt die Vertrauenskette, also die Anzahl der impliziten Abhängigkeiten in Ihrem Projekt. Im Diagramm sind "b" bis "h" direkte Abhängigkeiten und "i" bis "m" indirekte Abhängigkeiten.
Nehmen wir nun an, dass eine Sicherheitslücke tief in der Abhängigkeitsstruktur enthalten ist. Dieses Problem kann sehr schnell bei vielen Komponenten auftreten. Darüber hinaus ändern sich Abhängigkeiten häufig: An einem durchschnittlichen Tag ändern sich die Abhängigkeiten von 40.000 npm-Paketen.
Open Source Insights ist ein von Google Cloud erstelltes Tool, das eine vorübergehende Abhängigkeitsgrafik liefert, sodass Sie Ihre Abhängigkeiten und deren Abhängigkeiten in der gesamten Baumstruktur anzeigen können. Open Source Insights wird laufend mit Sicherheitshinweisen, Lizenzinformationen und anderen Sicherheitsdaten für mehrere Sprachen an einem Ort aktualisiert. Wenn Open Source Insights in Verbindung mit Open-Source-Kurzübersichten verwendet wird, die eine Risikobewertung für Open-Source-Projekte darstellen, können Ihre Entwickler aus den Millionen verfügbaren Open-Source-Paketen bessere Entscheidungen treffen.
Um dieses Problem zu lösen, ist es wichtig, sich auf die Abhängigkeiten als Code zu konzentrieren. Da sich diese Abhängigkeiten dem Ende der Lieferkette nähern, ist es schwieriger, sie zu prüfen. Zum Schutz Ihrer Abhängigkeiten empfehlen wir, mit der Bereitstellung zu beginnen:
- Verwenden Sie Tools wie Open-Source-Statistiken und OSS-Scorecards, um Abhängigkeiten besser zu verstehen.
- Scannen und verifizieren Sie den gesamten Code, alle Pakete und Basis-Images mit einem automatisierten Prozesses, der ein wichtiger Teil Ihres Workflows sein sollte.
- Steuern Sie, wie Nutzer auf diese Abhängigkeiten zugreifen Es ist sehr wichtig, die Repositories für eigenen und Open-Source-Code streng zu kontrollieren. Dabei gelten Einschränkungen hinsichtlich der gründlichen Codeüberprüfung und der Audit-Anforderungen.
Die Build- und Bereitstellungsprozesse werden später ausführlicher beschrieben. Wichtig ist es aber auch, die Herkunft des Builds zu prüfen, eine sichere Build-Umgebung zu nutzen und darauf zu achten, dass die Images signiert und anschließend bei der Bereitstellung geprüft werden.
Es gibt auch eine Reihe sicherer Codierungspraktiken, die Entwickler anwenden können:
- Tests automatisieren
- Speichersichere Softwaresprachen verwenden
- Code-Prüfungen erforderlich machen
- Commit-Authentizität sichern
- Schadcode frühzeitig erkennen
- Offenlegung vertraulicher Informationen vermeiden
- Logging und Build-Ausgabe erforderlich machen
- Lizenzverwaltung nutzen
Phase 2: Build
Der nächste Schritt beim Sichern Ihrer Softwarelieferkette ist das Einrichten einer sicheren Build-Umgebung im großen Maßstab. Der Build-Prozess beginnt im Wesentlichen damit, dass Sie Ihren Quellcode in einer von vielen Sprachen aus einem Repository importieren und Builds dann ausführen, um die Spezifikationen zu erfüllen, die in Ihren Konfigurationsdateien angegeben sind.
Cloud-Anbieter wie Google bieten Ihnen Zugriff auf eine aktuelle verwaltete Build-Umgebung, mit der Sie Images jeder Größenordnung erstellen können.
Bei der Erstellung des Builds müssen Sie einige Dinge berücksichtigen:
- Sind Ihre Secrets während des Build-Prozesses und darüber hinaus sicher?
- Wer hat Zugriff auf Ihre Build-Umgebungen?
- Was ist mit relativ neuen Angriffsvektoren oder Exfiltrationsrisiken?
Für die Entwicklung einer sicheren Build-Umgebung beginnen Sie mit Secrets. Sie sind kritisch und relativ einfach zu sichern. Achten Sie darauf, dass Ihre Secrets nie im Nur-Text-Format vorliegen und so weit wie möglich nicht Teil Ihres Builds sind. Sorgen Sie stattdessen dafür, dass sie verschlüsselt sind und Ihre Builds so parametrisiert sind, dass sie auf externe Secrets verweisen, die bei Bedarf verwendet werden können. Dies vereinfacht außerdem die regelmäßige Rotation von Secrets und minimiert die Auswirkungen von Datenlecks.
Im nächsten Schritt richten Sie die Berechtigungen für den Build ein. An Ihrem Build-Prozess sind verschiedene Nutzer und Dienstkonten beteiligt. Einige Nutzer müssen möglicherweise in der Lage sein, Secrets zu verwalten, während andere den Build-Prozess verwalten müssen, um Schritte hinzuzufügen oder zu ändern. Und andere müssen vielleicht nur Logs ansehen.
Es ist wichtig, dass Sie die folgenden Best Practices berücksichtigen:
- Am Wichtigsten ist das Prinzip der geringsten Berechtigung. Sie können detaillierte Berechtigungen implementieren, um Nutzern und Dienstkonten genau die Berechtigungen zu erteilen, die sie für ihre Arbeit benötigen.
- Sie müssen wissen, wie Nutzer und Dienstkonten interagieren, und die Vertrauenskette, von der Erstellung eines Builds zu dessen Ausführung und den nachfolgenden Auswirkungen, genau kennen.
Als Nächstes müssen Sie beim Hochskalieren so weit wie möglich Grenzen für den Build festlegen und dann die Automatisierung nutzen, um die Konfiguration als Code und Parametrisierung zu skalieren. So können Sie Änderungen an Ihrem Build-Prozess effektiv prüfen. Außerdem müssen Sie Compliance-Anforderungen erfüllen, indem Sie Genehmigungsmechanismen für sensible Builds und Bereitstellungen, Pull-Anfragen für Infrastrukturänderungen und regelmäßige, von Menschen gesteuerte Audit-Log-Prüfungen einführen.
Prüfen Sie schließlich noch, ob das Netzwerk Ihren Anforderungen entspricht. In den meisten Fällen empfiehlt es sich, eigenen Quellcode in privaten Netzwerken hinter Firewalls zu hosten. Google Cloud bietet Ihnen Zugriff auf Features wie private Cloud Build-Pools, eine gesperrte serverlose Build-Umgebung in Ihrem eigenen privaten Netzwerkperimeter und Features wie VPC Service Controls, um die Exfiltration ihres geistigen Eigentums zu verhindern.
Binärautorisierung
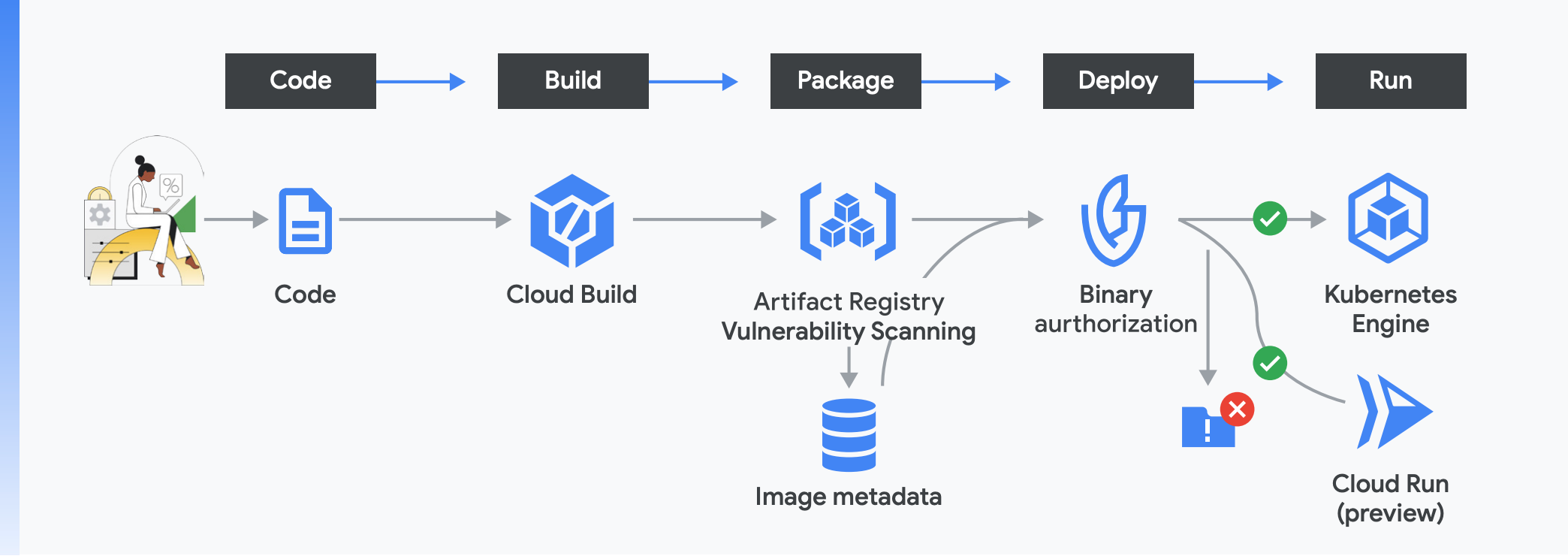
IAM ist ein absolutes Muss und ein logischer Ausgangspunkt, es ist aber nicht hundertprozentig sicher. Fehlerhafte Anmeldedaten stellen ein ernsthaftes Sicherheitsrisiko dar. Um Ihre Abhängigkeit von IAM zu reduzieren, können Sie zu einem attestierungsbasierten System wechseln, das weniger fehleranfällig ist. Google verwendet ein System namens Binärautorisierung, das ausschließlich die Bereitstellung vertrauenswürdiger Arbeitslasten erlaubt.
Der Binärautorisierungsdienst richtet über Attestierungen und Richtlinienprüfungen während des gesamten Vorgangs eine Vertrauenskette ein, die er prüft und pflegt. Im Grunde werden bei der Binärautorisierung kryptografische Signaturen – Attestierungen – generiert, während Code und andere Artefakte in die Produktion überführt werden. Vor der Bereitstellung werden diese Attestierungen anhand von Richtlinien geprüft.
Wenn Sie Google Cloud Build verwenden, wird ein Satz an Attestierungen erfasst und Ihrer gesamten Vertrauenskette hinzugefügt. Zum Beispiel werden Attestierungen für ausgeführte Aufgaben, für verwendete Build-Tools und Prozesse und andere Elemente generiert. Cloud Build hilft Ihnen insbesondere dabei, SLSA Level 1 zu erreichen. Dafür wird die Quelle der Build-Konfiguration erfasst, die dazu verwendet werden kann, zu prüfen, ob der Build geskriptet wurde. Skriptbasierte Builds sind sicherer als manuelle Builds und sind eine SLSA-Level 1-Vorgabe. Außerdem können Sie die Herkunft und die anderen Attestierungen Ihres Builds mit dem Container-Image-Digest nachsehen. Dadurch wird eine eindeutige Signatur für jedes Image erstellt. Auch dies ist eine SLSA Level 1-Vorgabe.
Phase 3: Verpackung
Sobald der Build abgeschlossen ist, haben Sie ein Container-Image, das fast produktionsbereit ist. Es ist wichtig, dass Sie einen sicheren Speicherort für Ihre Bilder haben. So lässt sich verhindern, dass bestehende Bilder und hochgeladene nicht autorisierte Bilder manipuliert werden. Ihr Paketmanager benötigt wahrscheinlich Images für eigene und Open-Source-Builds sowie für Sprachpakete, die Ihre Anwendungen verwenden.
Über die Artifact Registry von Google Cloud erhalten Sie ein solches Repository. Artifact Registry ist ein zentraler Ort, an dem Ihre Organisation sowohl Container-Images als auch Sprachpakete wie Maven und npm verwalten kann. Das Produkt ist vollständig in die Tools und Laufzeiten von Google Cloud eingebunden und unterstützt native Artefaktprotokolle. Dies erleichtert die Einbindung in Ihre CI-/CD-Tools bei der Einrichtung automatisierter Pipelines.
Ähnlich wie beim Build-Schritt ist es wichtig, dass die Zugriffsberechtigungen auf Artifact Registry sorgfältig durchdacht sind und das Prinzip der geringsten Berechtigung befolgt wird. Das Paket-Repository kann nicht nur den nicht autorisierten Zugriff einschränken, sondern auch viel mehr bieten. Artifact Registry beispielsweise enthält das Scannen auf Sicherheitslücken, um Ihre Images zu scannen und dafür zu sorgen, dass sie sicher bereitgestellt werden können. Dieser Dienst prüft Images auf eine ständig aktualisierte Sicherheitslückendatenbank, um neue Bedrohungen zu bewerten und kann Sie benachrichtigen, wenn eine Sicherheitslücke entdeckt wird.
Mit diesem Schritt werden zusätzliche Metadaten generiert, einschließlich einer Attestierung, ob die Ergebnisse von Sicherheitslücken eines Artefakts bestimmte Sicherheitsgrenzwerte erfüllen. Diese Informationen werden dann in unserem Analysedienst gespeichert, der die Metadaten des Artefakts strukturiert und organisiert, sodass sie für die Binärautorisierung leicht zugänglich sind. Damit können Sie automatisch verhindern, dass riskante Images in Google Kubernetes Engine (GKE) bereitgestellt werden.
Phasen 4 und 5: Bereitstellung und Ausführung
Die letzten beiden Phasen der Sicherung der Softwarelieferkette sind Bereitstellung und Ausführung. Das sind zwar separate Schritte, es ist jedoch sinnvoll, sie gruppiert zu betrachten, damit nur autorisierte Builds in die Produktion übernommen werden.
Bei Google haben wir Best Practices entwickelt, die bestimmen, welche Builds autorisiert werden sollten. Zuerst müssen Sie darauf achten, dass die Integrität der Lieferkette so sichergestellt ist, dass nur vertrauenswürdige Artefakte erzeugt werden. Als Nächstes wird die Verwaltung von Sicherheitslücken im Rahmen des Lebenszyklus der Softwarebereitstellung einbezogen. Abschließend fassen wir diese beiden Teile zusammen, um Workflows auf der Grundlage von Richtlinien für das Scannen auf Integrität und Sicherheitslücken zu erzwingen.
Wenn Sie zu dieser Phase kommen, sind Sie bereits mit den Code-, Build- und Paketphasen vertraut. Die entlang der Lieferkette erfassten Attestierungen können durch Binärautorisierung auf Authentizität geprüft werden. Im Erzwingungsmodus wird ein Image nur bereitgestellt, wenn die Attestierungen den Richtlinien Ihrer Organisation entsprechen. Im Prüfmodus werden Richtlinienverstöße protokolliert und Benachrichtigungen ausgelöst. Sie können die Binärautorisierung auch verwenden, um die Ausführung von Builds zu beschränken, es sei denn, sie wurden mit dem genehmigten Cloud Build-Prozess erstellt. Mit der Binärautorisierung wird sichergestellt, dass nur ordnungsgemäß geprüfter und autorisierter Code bereitgestellt wird.
Die Bereitstellung Ihrer Images in einer vertrauenswürdigen Laufzeitumgebung ist essenziell. Unsere verwaltete Kubernetes-Plattform GKE verfolgt in Sachen Container einen sicherheitsorientierten Ansatz.
GKE kümmert sich um die wichtigsten Sicherheitsaspekte, die Sie beachten müssen. Mit automatischen Clusterupgrades können Sie Ihren Kubernetes-Release automatisch über Release-Versionen patchen und aktuell halten. Sichere Starts, gesicherte Knoten und Integritätsprüfungen garantieren, dass die Kernel- und Clusterkomponenten Ihres Knotens nicht geändert wurden und so laufen, wie Sie es wünschen. Schädliche Knoten können nicht in den Cluster aufgenommen werden. Schließlich können Sie mit Confidential Computing Cluster mit Knoten ausführen, deren Arbeitsspeicher verschlüsselt ist. Dadurch bleiben die Daten auch während der Verarbeitung vertraulich. Wenn Sie dann noch die Datenverschlüsselung im Ruhezustand und bei der Übertragung über das Netzwerk bedenken, bietet GKE eine sehr sichere, private und vertrauliche Umgebung zum Ausführen containerisierten Arbeitslasten.
Weiter bietet GKE eine optimierte Sicherheit für Ihre Anwendungen durch die Zertifikatsverwaltung für Load-Balancer, Workload Identity und erweiterte Netzwerksfunktionen. Dabei kommen leistungsstarke Methoden zur Konfiguration und Sicherung von in Ihren Cluster eingehenden Traffic zum Tragen. GKE bietet auch in einer Sandbox laufende Umgebungen zum Ausführen nicht vertrauenswürdiger Anwendungen, während Ihre übrigen Arbeitslasten geschützt bleiben.
Mit dem GKE Autopilot werden die Best Practices und Features von GKE automatisch implementiert, was die Angriffsfläche weiter reduziert und das Risiko einer Fehlkonfiguration minimiert, die zu Sicherheitsproblemen führen kann.
Natürlich sind Prüfungen nicht nur bis zur Bereitstellung ein unabdingbarer Faktor. Die Binärautorisierung unterstützt auch die kontinuierliche Validierung, sodass die Einhaltung der definierten Richtlinie auch nach der Bereitstellung durchgesetzt werden kann. Wenn eine ausgeführte Anwendung nicht mit einer vorhandenen oder neu hinzugefügten Richtlinie übereinstimmt, wird eine Benachrichtigung erstellt und protokolliert. Sie können sich also darauf verlassen, dass Ihr Produktionscode genau das tut, was Sie wollen. .
Sicherheitslückenverwaltung
Ein weiterer Aspekt der Sicherheit der Lieferkette besteht darin, Sicherheitslücken schnell zu finden und zu beheben. Angreifer haben sich weiterentwickelt, um Sicherheitslücken in vorgelagerten Projekten aktiv einzusetzen. Die Verwaltung von Sicherheitslücken und die Fehlererkennung sollten in allen Phasen des Softwarebereitstellungszyklus enthalten sein.
Sobald der Code für die Bereitstellung bereit ist, verwenden Sie eine CI-/CD-Pipeline und nutzen Sie die zahlreichen Tools, um einen umfassenden Scan des Quellcodes und der generierten Artefakte durchzuführen. Zu diesen Tools gehören statische Analysegeräte, Fuzzing-Tools und verschiedene Arten von Scannern für Sicherheitslücken.
Nachdem Sie die Arbeitslast in der Produktionsumgebung bereitgestellt haben und während sie in der Produktion ausgeführt wird und für Ihre Nutzer bereitsteht, ist es erforderlich, neue Bedrohungen zu beobachten und Pläne für Sofortmaßnahmen zu haben.
Fazit
Wichtig ist bei der Sicherung einer Softwarelieferkette, Best Practices wie SLSA zu berücksichtigen und vertrauenswürdige verwaltete Dienste für diese Best Practices einzusetzen.
Wichtige Punkte:
- Beginnen Sie mit dem Code und den Abhängigkeiten und prüfen Sie, ob diese Elemente vertrauenswürdig sind.
- Schützen Sie Ihr Build-System und verwenden Sie Attestierungen, um zu prüfen, ob alle erforderlichen Build-Schritte ausgeführt wurden.
- Achten Sie darauf, dass alle Ihre Pakete und Artefakte vertrauenswürdig sind und nicht manipuliert werden können.
- Legen Sie fest, wer Inhalte bereitstellen und einen Audit-Trail verwalten kann. Mit Binärautorisierung können Sie Attestierungen für jedes bereitzustellende Artefakt validieren.
- Führen Sie Ihre Anwendungen in einer vertrauenswürdigen Umgebung aus und achten Sie darauf, dass sie während der Ausführung nicht manipuliert werden können. Achten Sie auf neu entdeckte Sicherheitslücken, um die Bereitstellung zu schützen.
Bei Google integrieren wir Best Practices für jeden der Schritte in unser Produktportfolio, damit Sie auf eine solide Grundlage aufbauen können.
Erste Schritte
Bereit für die Sicherung Ihrer Softwarelieferkette? Nur zur Klarstellung: Wo Sie beginnen, ist weitgehend willkürlich. Es gibt keine Maßnahme, die die gesamte Lieferkette sichert, und es gibt keine Maßnahme, die wichtiger als andere ist, wenn es um umfassende Sicherheit in der Lieferkette geht. Hier sind nun vier Empfehlungen für den Einstieg.
1. Software aktualisieren
Wenn Sie Code in Ihrer Produktionsumgebung mit bekannten Sicherheitslücken bereitgestellt haben, haben Sie die Arbeit des Angreifers bereits für ihn erledigt. Dabei spielt es keine Rolle, wie gut Sie Ihre Softwarelieferkette gesichert haben, denn der Angreifer hat bereits einen Weg gefunden. Patches sind also entscheidend.
2. Behalten Sie die Kontrolle darüber, was in Ihrer Umgebung ausgeführt wird
Sobald Sie mit dem Patchen vertraut sind, können Sie Ihre Softwarelieferkette selbst steuern. Zuerst müssen Sie bestätigen, dass die ausgeführten Aufgaben tatsächlich von Ihren Build-Tools oder vertrauenswürdigen Repositories stammen. So können Sie gezielte Angriffe und versehentliche Fehler verhindern, z. B. wenn ein Entwickler etwas bereitgestellt hat, von dem er nicht wusste, dass es unsicher ist. Dies ist eine solide Grundlage für das Hinzufügen von Tools wie Klicktests und Binärautorisierung.
3. Prüfen, ob Pakete von Drittanbietern sicher sind
Ein neues Problem bei der Lieferkettensicherheit ist die Häufigkeit, mit der die Software von Anbietern manipuliert wird, um Ransomware einzuschleusen oder unautorisierten Zugriff auf die Zielkundenbereitstellung zu ermöglichen. Die Drittanbieterpakete, die Sie in Ihrer Umgebung ausführen, z. B. Systemverwaltungs-, Netzwerkverwaltungs- oder Sicherheitsprodukte, haben häufig hohe Berechtigungen. Wir empfehlen, diese Anbieter aufzufordern, über ihre Standardaussagen hinaus zu gehen, um Ihnen ein höheres Maß an Sicherheit für die von Ihnen verwendeten Pakete zu bieten. Sie können sie fragen, welche SLSA-Konformität sie haben, oder ob sie die Anforderungen der aktuellen Executive Order entsprechen.
4. Erstellen Sie eine Kopie Ihres Quellcodes
Wenn Sie Open-Source-Software nutzen, sollten Sie nie eine Version verwenden, die Sie direkt aus dem Internet abgerufen haben. Stattdessen sollten Sie eine private Kopie patchen, damit Sie bei jedem Build sauber beginnen und zu 100 % sicher sein können, woher der Quellcode stammt.
Weitere Informationen
Best Practices für DevOps
- Sechs Jahre „State of DevOps“-Bericht: Dies ist eine Reihe von Artikeln mit ausführlichen Informationen zu den Kompetenzen, anhand derer sich die Softwarebereitstellungsleistung vorhersagen lässt, und eine Schnellprüfung, damit Sie herausfinden können, wie in Ihrem Unternehmen der Stand der Dinge ist und was Sie tun können, um die Situation zu verbessern.
- Bericht „Accelerate State of DevOps 2021“ von Google Cloud
- Google Cloud-Whitepaper: Re-architecting to cloud native: an evolutionary approach to increasing developer productivity at scale
Softwarelieferkette schützen
- Google Cloud-Blog: What is Zero-Trust Identity Security
- Google-Sicherheitsblog: Introducing SLSA, an end-to-end framework for supply chain integrity
- Google Cloud-Whitepaper: Shifting left on security: Securing software supply chains
Sind Sie bereit für die nächsten Schritte?
Füllen Sie das Formular aus. Wir melden uns bald bei Ihnen. Formular anzeigen











