미국, 캐나다 또는 멕시코만 포함
차트의 정보를 미국, 멕시코 또는 캐나다의 데이터로 제한하려 한다고 가정해 보겠습니다. 차트를 선택하고 다음 필터를 추가합니다.
- 포함/제외: 포함
- 측정기준: 국가
- 검색 유형: IN
- 값:
United States, Canada, Mexico
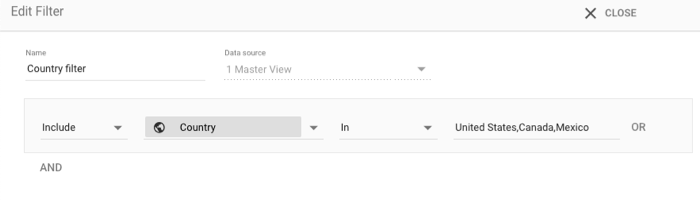
3개의 '또는' 절을 사용해 제한할 수도 있지만, 목록과 함께 '이내'를 사용하는 것이 더 간편합니다.
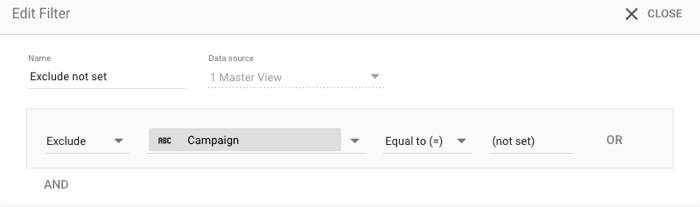
'(설정되지 않음)' 제외
차트에서 '(설정되지 않음)' 값을 제외하려면 제외 필터를 사용합니다. 예를 들면 다음과 같습니다.
- 포함/제외: 제외
- 측정기준: 캠페인
- 검색 유형: 같음
- 값:
(not set)
값의 끝부분에서 데이터 찾기
정규 표현식 일치 및 정규 표현식 포함 연산자를 사용하면 더욱 복잡한 일치를 표현할 수 있습니다. 예를 들어 데이터 끝에 값이 포함된 데이터를 필터링하려면 다음과 같이 행의 끝을 나타내는 $ 기호를 사용할 수 있습니다.
- 포함/제외: 포함
- 측정기준: 매체
- 일치 유형: 정규 표현식 일치
- 값:
*c$
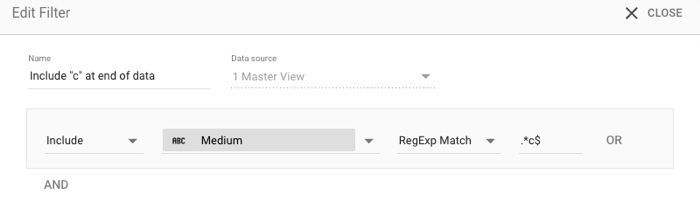
애널리틱스 매체 측정기준에 적용되는 경우 '자연' 및 'CPC'와 같은 값을 포함합니다.
정규 표현식 이해: .*c$
.*은 '모두 일치' (일치 없음 포함)라는 뜻입니다.그런 다음 영문자 'c'가 일치해야 합니다.
$기호는 '행의 끝'을 나타내는 문자입니다. (문자열의 시작을 나타내려면 ^ 기호를 사용하세요.)
또 다른 예는 다음과 같습니다.
^c.*k.*$ 는 영문자 c로 시작하고 이 다음에는 모든 값, 다음에는 영문자 k, 다음에는 문자열 끝까지 모든 값이 나오는 텍스트(예: 'cook', 'cookie', 'cake' 등의 값과 일치합니다.
알파벳 문자로 시작하지 않는 데이터 제외
정규 표현식 문자 클래스는 문자 유형과의 일치를 표현할 수 있는 기능입니다. 예를 들면 다음과 같습니다.
- 포함/제외: 제외
- 일치 유형: 정규 표현식 일치
- 값:
^[[:^alpha:]].*
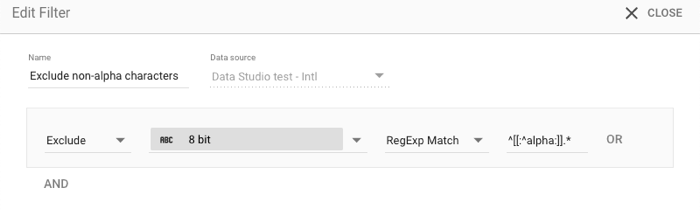
이렇게 하면 영숫자가 아닌 문자가 필터링됩니다(예: 일본어 간지 또는 한글).
정규 표현식 이해: ^[[:^alpha:]].*
^은 '문자열의 시작'을 의미합니다.
[[:alpha:]]는 [A-Za-z] 영문자 클래스입니다. [[:^alpha:]] 는 '영문자가 아닌' 클래스를 뜻합니다.
.*은 '모두 일치'를 의미합니다.