Datastream では、Oracle、MySQL、PostgreSQL データベースから BigQuery データセットへの直接のデータのストリーミングをサポートしています。ただし、データ変換や論理主キーの手動設定など、ストリーム処理ロジックをより詳細に制御する必要がある場合は、Datastream を Dataflow ジョブ テンプレートと統合できます。
このチュートリアルでは、Dataflow ジョブ テンプレートを使用して Datastream を Dataflow と統合し、分析用に BigQuery の最新のマテリアライズド ビューをストリーミングする方法について説明します。
多くの分離されたデータソースを持つ組織では、組織全体の企業データへのアクセスは、特にリアルタイムで制限され、遅くなる可能性があります。これにより、組織の内省力が制限されます。
Datastream は、オンプレミスやクラウドベースのさまざまなデータソースから変更データにほぼリアルタイムでアクセスできるようにします。Datastream には、ストリーミング データの構成をほとんど行う必要のない設定エクスペリエンスが用意されています。Datastream が自動的に構成を行います。Datastream には、統合シナリオを構築するために、組織全体で最新のエンタープライズ データに誰でもアクセスできるようにする統合消費 API もあります。
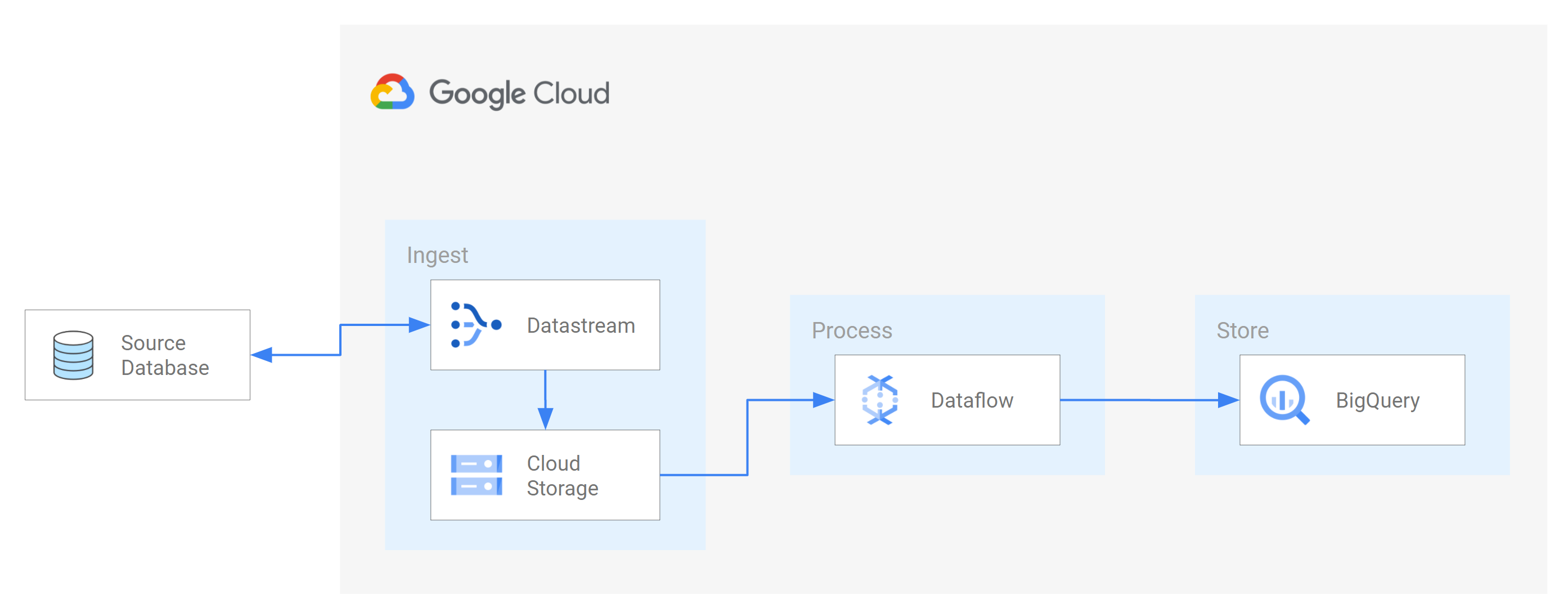
そのようなシナリオの一つは、ソース データベースからクラウドベースのストレージ サービスまたはメッセージング キューにデータを転送することです。Datastream がデータをストリーミングすると、データは他のアプリケーションやサービスが読み取れる形式に変換されます。このチュートリアルでは、Dataflow はストレージ サービスまたはメッセージング キューと通信して Google Cloudのデータをキャプチャして処理するウェブサービスです。
Datastream を使用して、変更(挿入、更新、削除されたデータ)をソースの MySQL データベースから Cloud Storage バケット内のフォルダにストリーミングする方法を学習します。次に、Cloud Storage バケットを構成して、Datastream がソース データベースからストリーミングするデータ変更を含む新しいファイルについて Dataflow が学習するために使用する通知を送信します。Dataflow ジョブはファイルを処理し、変更を BigQuery に転送します。
要件
Datastream には、さまざまな移行元オプション、移行先オプション、ネットワーク接続方法が用意されています。
このチュートリアルでは、スタンドアロンの MySQL データベースと移行先の Cloud Storage サービスを使用していることを前提としています。移行元データベースでは、受信ファイアウォール ルールを追加できるようにネットワークを構成する必要があります。移行元データベースは、オンプレミスまたはクラウド プロバイダにできます。Cloud Storage の宛先の場合、接続構成は必要ありません。
ユーザーの具体的な環境を把握できないため、ネットワーク構成に関する詳細なステップは提供できません。
このチュートリアルでは、ネットワーク接続方法として [IP 許可リスト] を選択します。IP 許可リストは、移行元データベースのデータへのアクセスを信頼できるユーザーのみに制限、制御するためにしばしば使用されるセキュリティ機能です。IP 許可リストを使用すると、ユーザーや Datastream などの他の Google Cloud サービスがこのデータにアクセスできる信頼できる IP アドレスまたは IP 範囲のリストを作成します。IP 許可リストを使用するには、Datastream からの受信接続に対してソース データベースまたはファイアウォールを開く必要があります。
Cloud Storage にバケットを作成します。
Datastream が移行元 MySQL データベースからスキーマ、テーブル、データをストリーミングする移行先バケットを Cloud Storage に作成します。
Google Cloud コンソールで、Cloud Storage の [ブラウザ] ページに移動します。
[バケットを作成] をクリックします。[バケットの作成] ページが表示されます。
[バケットに名前を付ける] 領域のテキスト フィールドにバケットの一意の名前を入力し、[続行] をクリックします。
ページの残りの各領域については、デフォルト設定を受け入れます。各リージョンの最後に、[続行] をクリックします。
[作成] をクリックします。
Cloud Storage バケットの Pub/Sub 通知を有効にする
このセクションでは、作成した Cloud Storage バケットの Pub/Sub 通知を有効にします。これにより、Datastream がバケットに書き込む新しいファイルについて Dataflow に通知するようにバケットを構成します。これらのファイルには、Datastream がソース MySQL データベースからバケットにストリーミングするデータへの変更が含まれています。
作成した Cloud Storage バケットにアクセスします。[バケットの詳細] ページが表示されます。
「Cloud Shell をアクティブにする」をクリックします。
プロンプトが表示されたら、次のコマンドを入力します。
gcloud storage buckets notifications create gs://bucket-name --topic=my_integration_notifs --payload-format=json --object-prefix=integration/tutorial/[Cloud Shell の承認] ウィンドウが表示されたら、[承認] をクリックします。
次のコードの行が表示されていることを確認します。
Created Cloud Pub/Sub topic projects/project-name/topics/my_integration_notifs Created notification config projects/_/buckets/bucket-name/notificationConfigs/1
Google Cloud コンソールで、Pub/Sub の [トピック] ページに移動します。
作成した my_integration_notifs トピックをクリックします。
[my_integration_notifs] ページで、ページの下部に移動します。[サブスクリプション] タブがアクティブになり、「表示するサブスクリプションはありません」というメッセージが表示されることを確認します。
[サブスクリプションを作成] をクリックします。
表示されたメニューで、[サブスクリプションを作成] を選択します。
[サブスクリプションをトピックに追加] ページで次の情報を入力します。
- [サブスクリプション ID] フィールドに「
my_integration_notifs_sub」と入力します。 - [確認応答期限] の値を
120秒に設定します。これにより、Dataflow は処理したファイルを認識するのに十分な時間を確保でき、Dataflow ジョブの全体的なパフォーマンスを向上させることができます。Pub/Sub サブスクリプション プロパティの詳細については、サブスクリプション プロパティをご覧ください。 - 他のデフォルト値はすべてそのままにします。
- [作成] をクリックします。
- [サブスクリプション ID] フィールドに「
このチュートリアルの後半では、Dataflow ジョブを作成します。このジョブの作成の一環として、Dataflow を my_integration_notifs_sub サブスクリプションのサブスクライバーとして割り当てます。これにより、Dataflow は、Datastream が Cloud Storage に書き込む新しいファイルに関する通知を受信し、ファイルを処理して、データ変更を BigQuery に転送できます。
BigQuery でデータセットを作成します
このセクションでは、BigQuery でデータセットを作成します。BigQuery は、Dataflow から受信したデータを格納するためにデータセットを使用します。このデータは、Datastream が Cloud Storage バケットにストリーミングするソース MySQL データベースの変更を表します。
Google Cloud コンソールで、BigQuery の [SQL ワークスペース] ページに移動します。
[エクスプローラ] ペインで、 Google Cloud プロジェクト名の横にある [アクションを表示] をクリックします。
表示されたメニューで、[データセットを作成] を選択します。
[データセットを作成] ウィンドウで、次の操作を行います。
- [データセット ID] フィールドに、データセットの ID を入力します。このチュートリアルでは「
My_integration_dataset_log」と入力します。 - 他のデフォルト値はそべてそのままにします。
- [データセットを作成] をクリックします。
- [データセット ID] フィールドに、データセットの ID を入力します。このチュートリアルでは「
[エクスプローラ] ペインで、 Google Cloud プロジェクト名の横にある [ノードを開く] をクリックし、作成したデータセットが表示されていることを確認します。
この手順に沿って、2 番目のデータセット My_integration_dataset_final を作成します。
各データセットの横にある [ ノードを展開] を展開します。
各データセットが空であることを確認します。
Datastream がソース データベースから Cloud Storage バケットにデータ変更をストリーミングした後、Dataflow ジョブは変更を含むファイルを処理し、変更を BigQuery データセットに転送します。
Datastream で接続プロファイルを作成する
このセクションでは、ソース データベースと宛先の Datastream で接続プロファイルを作成します。接続プロファイルの作成の一環として、移行元接続プロファイルのプロファイル タイプとして MySQL を選択し、移行先接続プロファイルのプロファイル タイプとして Cloud Storage を選択します。
Datastream は、接続プロファイルで定義された情報を使用して移行元と移行先の両方に接続し、移行元データベースから Cloud Storage の移行先バケットにデータをストリーミングできるようにします。
MySQL データベースのソース接続プロファイルを作成する
Google Cloud コンソールで、Datastream の [接続プロファイル] ページに移動します。
[プロファイルの作成] をクリックします。
MySQL データベースのソース接続プロファイルを作成するには、[接続プロファイルの作成] ページで、[MySQL] プロファイル タイプをクリックします。
[MySQL プロファイルの作成] ページの [接続設定の定義] セクションに、次の情報を入力します。
- [接続プロファイル名] フィールドに「
My Source Connection Profile」と入力します。 - 自動生成された接続プロファイル ID を保持します。
接続プロファイルを保存するリージョンを選択します。
接続の詳細を入力します。
- [ホスト名または IP] フィールドに、Datastream がソース データベースへの接続に使用できるホスト名またはパブリック IP アドレスを入力します。このチュートリアルでは、IP 許可リストをネットワーク接続に使用するため、パブリック IP アドレスを指定します。
- [ポート] フィールドに、ソース データベース用に予約されているポート番号を入力します。MySQL データベースの場合、デフォルトのポートは通常
3306です。 - ソース データベースへの認証用に、ユーザー名とパスワードを入力します。
- [接続プロファイル名] フィールドに「
[接続設定の定義] セクションで、[続行] をクリックします。[MySQL プロファイルの作成] ページの [ソースへの接続を保護する] セクションはアクティブです。
[暗号化のタイプ] メニューから [なし] を選択します。このメニューの詳細については、MySQL データベースの接続プロファイルの作成をご覧ください。
[ソースへの接続を保護する] セクションで、[続行] をクリックします。[MySQL プロファイルの作成] ページの [接続方法の定義] セクションはアクティブです。
[接続方法] プルダウンで、Datastream とソース データベースの間の接続を確立するために使用するネットワーク方式を選択します。このチュートリアルでは、接続方法として [IP 許可リスト] を選択します。
表示される Datastream パブリック IP アドレスからの受信接続を許可するように移行元データベースを構成します。
[接続方法の定義] セクションで [続行] をクリックします。[MySQL プロファイルの作成] ページの [テスト接続プロファイル] セクションはアクティブです。
[テストを実行] をクリックして、移行元データベースと Datastream が相互に通信できることを確認します。
[テストに合格] ステータスが表示されていることを確認します。
[作成] をクリックします。
Cloud Storage の宛先接続プロファイルの作成
Google Cloud コンソールで、Datastream の [接続プロファイル] ページに移動します。
[プロファイルの作成] をクリックします。
Cloud Storage の宛先接続プロファイルを作成するには、[接続プロファイルの作成] ページで、[Cloud Storage] プロファイル タイプをクリックします。
[Create Cloud Storage profile] ページで、次の情報を入力します。
- [接続プロファイル名] フィールドに「
My Destination Connection Profile」と入力します。 - 自動生成された接続プロファイル ID を保持します。
- 接続プロファイルを保存するリージョンを選択します。
[接続の詳細] ペインで、[参照] をクリックして、このチュートリアルの前半で作成した Cloud Storage バケットを選択します。これは、Datastream がソース データベースからデータを転送するバケットです。選択したら、[選択] をクリックします。
バケットが、[接続の詳細] ペインの [バケット名] フィールドに表示されます。
[接続プロファイルのパス接頭辞] フィールドに、Datastream がデータを宛先にストリーミングする際にバケット名に追加するパスの接頭辞を指定します。Datastream がバケットのルートフォルダではなく、バケット内のパスにデータを書き込むようにしてください。このチュートリアルでは、Pub/Sub 通知を構成したときに定義したパスを使用します。欄に「
/integration/tutorial」と入力します。
- [接続プロファイル名] フィールドに「
[作成] をクリックします。
MySQL データベースのソース接続プロファイルと Cloud Storage の移行先接続プロファイルを作成した後、それらを使用してストリームを作成できます。
Datastream でストリームを作成する
このセクションでは、ストリームを作成します。このストリームは、接続プロファイルの情報を使用して、ソース MySQL データベースから Cloud Storage のソースバケットにデータを転送します。
ストリームの設定の定義
Google Cloud コンソールで、Datastream の [ストリーム] ページに移動します。
[ストリームを作成] をクリックします。
[ストリームの作成] ページの [ストリームの詳細の定義] パネルで、次の情報を指定します。
- [ストリーム名] フィールドに「
My Stream」と入力します。 - 自動生成されたストリーム ID を保持します。
- [リージョン] メニューから、ソースと送信先の接続プロファイルを作成したリージョンを選択します。
- [ソースタイプ] メニューから [MySQL] プロファイル タイプを選択します。
- [宛先の種類] メニューから、[Cloud Storage] プロファイル タイプを選択します。
- [ストリーム名] フィールドに「
ストリームに環境を準備する方法が反映されるように、自動的に生成される必須の前提条件を確認します。これらの前提条件には、移行元データベースの構成方法や Cloud Storage の移行先バケットに Datastream を接続する方法が含まれます。
[続行] をクリックします。[ストリームの作成] ページの [Define MySQL connection profile] パネルが表示されます。
ソース接続プロファイルに関する情報の指定
このセクションでは、ソースデータベース用に作成した接続プロファイル(ソース接続プロファイル)を選択します。このチュートリアルでは、My Source Connection Profile です。
[ソース接続プロファイル] メニューから、MySQL データベースのソース接続プロファイルを選択します。
[テストを実行] をクリックして、移行元データベースと Datastream が相互に通信できることを確認します。
テストに失敗した場合、接続プロファイルに関連する問題が表示されます。トラブルシューティングの手順については、問題を診断するページを参照してください。必要な変更を行って問題を修正し、再度テストを行います。
[続行] をクリックします。[ストリームの作成] ページの [ストリームのソースの構成] パネルが表示されます。
ストリームのソース データベースに関する情報の構成
このセクションでは、Datastream のソース データベースでテーブルとスキーマを指定して、ストリームのソース データベースに関する情報を構成します。
- 宛先への転送ができる。
- 宛先への転送が制限されている。
また、Datastream が過去のデータをバックフィルするのか、進行中の変更を送信先にストリーミングするのか、データへの変更のみをストリーミングするのかを決定します。
[含めるオブジェクト] メニューを使用して、Datastream が Cloud Storage の宛先バケットのフォルダに転送できるソース データベース内のテーブルとスキーマを指定します。 メニューは、データベースに 5,000 個までのオブジェクトがある場合にのみ読み込まれます。
このチュートリアルでは、Datastream ですべてのテーブルとスキーマを転送します。そのため、メニューから [すべてのテーブル] を選択します。
[除外するオブジェクトを選択] パネルが [なし] に設定されていることを確認します。Datastream によるソース データベースのテーブルやスキーマの Cloud Storage への転送は制限しません。
[履歴データのバックフィル モードを選択 ] パネルが [自動] に設定されていることを確認します。Datastream は、データへの変更に加えて、既存のすべてのデータを送信先にストリーミングします。
[続行] をクリックします。[ストリームの作成] ページの [Define Cloud Storage connection profile] パネルが表示されます。
宛先接続プロファイルの選択
このセクションでは、Cloud Storage 用に作成した接続プロファイル(送信先の接続プロファイル)を選択します。このチュートリアルでは、My Destination Connection Profile です。
[宛先接続プロファイル] メニューから、Cloud Storage の宛先接続プロファイルを選択します。
[続行] をクリックします。[ストリームの作成] ページの [ストリームの移行先の構成] パネルが表示されます。
ストリームの転送先に関する情報の構成
このセクションでは、ストリームの送信先バケットに関する情報を構成します。これには以下の情報が含まれます。
- Cloud Storage に書き込まれるファイルの出力形式。
- Datastream がソース データベースからスキーマ、テーブル、データを転送する送信先バケットのフォルダ。
[出力形式] フィールドで、Cloud Storage に書き込まれるファイルの形式を選択します。Datastream は現在、Avro と JSON の 2 つの出力形式をサポートしています。 このチュートリアルでは、このファイル形式は Avro です。
[続行] をクリックします。[ストリームの作成] ページの [ストリームの詳細の確認と作成] パネルが表示されます。
ストリームの作成
ストリームの詳細と、ストリームがソース MySQL データベースから Cloud Storage の宛先バケットへのデータ転送に使用するソース接続と宛先接続のプロファイルを確認します。
ストリームを検証するには、[検証を実行] をクリックします。ストリームを検証すると、Datastream は移行元が適切に構成されていることを確認し、ストリームが移行元と移行先の両方に接続できること、ストリームのエンドツーエンド構成を検証します。
すべての検証チェックに合格したら、[作成] をクリックします。
[ストリームを作成しますか?] ダイアログ ボックスで、[作成] をクリックします。
ストリームの開始
このチュートリアルでは、移行元データベースの負荷が増大した場合にストリームを個別に作成して開始します。負荷を軽減するには、ストリームを開始せずに作成し、データベースが負荷を処理できるときにストリームを開始します。
ストリームを開始すると、Datastream は移行元データベースから移行先にデータ、スキーマ、テーブルを転送できます。
Google Cloud コンソールで、Datastream の [ストリーム] ページに移動します。
開始するストリームの横にあるチェックボックスをオンにします。このチュートリアルでは、My Stream を使用します。
[開始] をクリックします。
ダイアログで [開始] をクリックします。ストリームのステータスが
Not startedからStarting、そしてRunningに変わります。
ストリームを開始すると、Datastream が移行元データベースから移行先にデータを転送することを確認できます。
ストリームの検証
このセクションでは、Datastream が移行元 MySQL データベースのすべてのテーブルから Cloud Storage の移行先バケットの /integration/tutorial フォルダにデータを転送することを確認します。
Google Cloud コンソールで、Datastream の [ストリーム] ページに移動します。
作成したストリームをクリックします。このチュートリアルでは、My Stream を使用します。
[ストリームの詳細] ページで、bucket-name/integration/tutorial リンクをクリックします。ここで、bucket-name は Cloud Storage バケットに付けた名前です。このリンクは、[書き込み先パス] フィールドの後に表示されます。Cloud Storage の [バケットの詳細] ページが別のタブで開きます。
移行元データベースのテーブルを表すフォルダが表示されていることを確認します。
いずれかのテーブル フォルダをクリックし、各サブフォルダをクリックして、テーブルに関連付けられているデータを表示します。
Dataflow ジョブを作成する
このセクションでは、Dataflow でジョブを作成します。Datastream がソース MySQL データベースから Cloud Storage バケットにデータ変更をストリーミングした後、Pub/Sub は変更を含む新しいファイルに関する通知を Dataflow に送信します。Dataflow ジョブはファイルを処理し、変更を BigQuery に転送します。
Google Cloud コンソールで、Dataflow の [ジョブ] ページに移動します。
[テンプレートからジョブを作成] をクリックします。
[テンプレートからジョブを作成] ページの [ジョブ名] フィールドに、作成する Dataflow ジョブの名前を入力します。このチュートリアルでは「
my-dataflow-integration-job」と入力します。[リージョン エンドポイント] メニューから、ジョブを保存するリージョンを選択します。これは、作成した移行元接続プロファイル、移行先接続プロファイル、ストリームで選択したリージョンと同じです。
[Dataflow テンプレート] メニューから、ジョブの作成に使用するテンプレートを選択します。このチュートリアルでは、[Datastream to BigQuery] を選択します。
こ選択すると、このテンプレートに関連する追加フィールドが表示されます。
[Cloud Storage 内の Datastream ファイル出力のファイル ロケーション] フィールドに、
gs://bucket-nameという形式で Cloud Storage バケットの名前を入力します。[Cloud Storage 通知ポリシーで使用されている Pub/Sub サブスクリプション。] フィールドに、Pub/Sub サブスクリプションの名前を含むパスを入力します。このチュートリアルでは、
projects/project-name/subscriptions/my_integration_notifs_subと入力します。[Datastream output file format (avro/json)] フィールドに「
avro」と入力します。このチュートリアルでは、Avro が Datastream が Cloud Storage に書き込むファイル形式です。[Name or template for the dataset to contain staging tables.] フィールドに「
My_integration_dataset_log」と入力します。Dataflow は、このデータセットを使用して Datastream から受信するデータの変更をステージングします。[Template for the dataset to contain replica tables.] フィールドに「
My_integration_dataset_final」と入力します。これは、My_integration_dataset_log データセットにステージングされた変更を統合してソース データベース内のテーブルの 1 対 1 のレプリカが作成されるデータセットです。[Dead letter queue directory.] フィールドに、Cloud Storage バケットの名前とデッドレター キューのフォルダを含むパスを入力します。ルートフォルダのパスを使用しないようにし、Datastream がデータを書き込むパスとは異なるパスを使用してください。Dataflow が BigQuery に転送できなかったデータ変更はキューに保存されます。Dataflow が再処理できるように、キュー内のコンテンツを修正できます。
このチュートリアルでは、[Dead letter queue directory.] フィールドに「
gs://bucket-name/dlq」と入力します(bucket-name はバケットの名前、dlq はデッドレター キューのフォルダです)。[ジョブを実行] をクリックします。
統合を確認する
このチュートリアルのストリームを確認するセクションで、Datastream がソース MySQL データベースのすべてのテーブルから、Cloud Storage の宛先バケットの /integration/tutorial フォルダにデータを転送することを確認しました。
このセクションでは、Dataflow がこのデータに関連付けられた変更を含むファイルを処理し、変更を BigQuery に転送することを確認します。この結果、Datastream と BigQuery がエンドツーエンドで統合されます。
Google Cloud コンソールで、BigQuery の [SQL ワークスペース] ページに移動します。
[エクスプローラ] ペインで、 Google Cloud プロジェクト名の横にあるノードを開きます。
My_integration_dataset_log データセットと My_integration_dataset_final データセットの横にあるノードを開きます。
各データセットにデータが含まれていることを確認します。これにより、Dataflow が Datastream によって Cloud Storage にストリーミングされたデータに関連付けられた変更を含むファイルを処理し、これらの変更を BigQuery に転送したことが確認されます。