É possível enviar um job por
meio de uma API Dataproc jobs.submit
do Dataproc ou de uma solicitação programática, usando a ferramenta de linha de comando gcloud
da Google Cloud CLI em uma janela de terminal local ou no
Cloud Shell ou então pelo Google Cloud console aberto em um navegador local. Também é possível executar SSH na instância mestre do cluster e executar um job diretamente na instância sem usar o serviço Dataproc.
Como enviar um job
Console
Abra a página Enviar um job do Dataproc no console Google Cloud no navegador.
Exemplo de job do Spark
Para enviar um job do Spark de exemplo, preencha os campos na página Enviar um job da seguinte maneira:
- Selecione o nome do Cluster na lista de clusters.
- Defina o Tipo de job para
Spark. - Defina Classe principal ou jar como
org.apache.spark.examples.SparkPi. - Defina Argumentos como o argumento único
1000. - Adicione
file:///usr/lib/spark/examples/jars/spark-examples.jarpara Arquivos jar:file:///indica um esquema de LocalFileSystem do Hadoop. O Dataproc instalou/usr/lib/spark/examples/jars/spark-examples.jarno nó mestre do cluster quando criou o cluster.- Como alternativa, você pode especificar um caminho do Cloud Storage
(
gs://your-bucket/your-jarfile.jar) ou um caminho do sistema de arquivos distribuídos do Hadoop (hdfs://path-to-jar.jar) para um dos seus jars.
Clique em Enviar para iniciar o job. Depois de iniciado, o job será adicionado à lista.
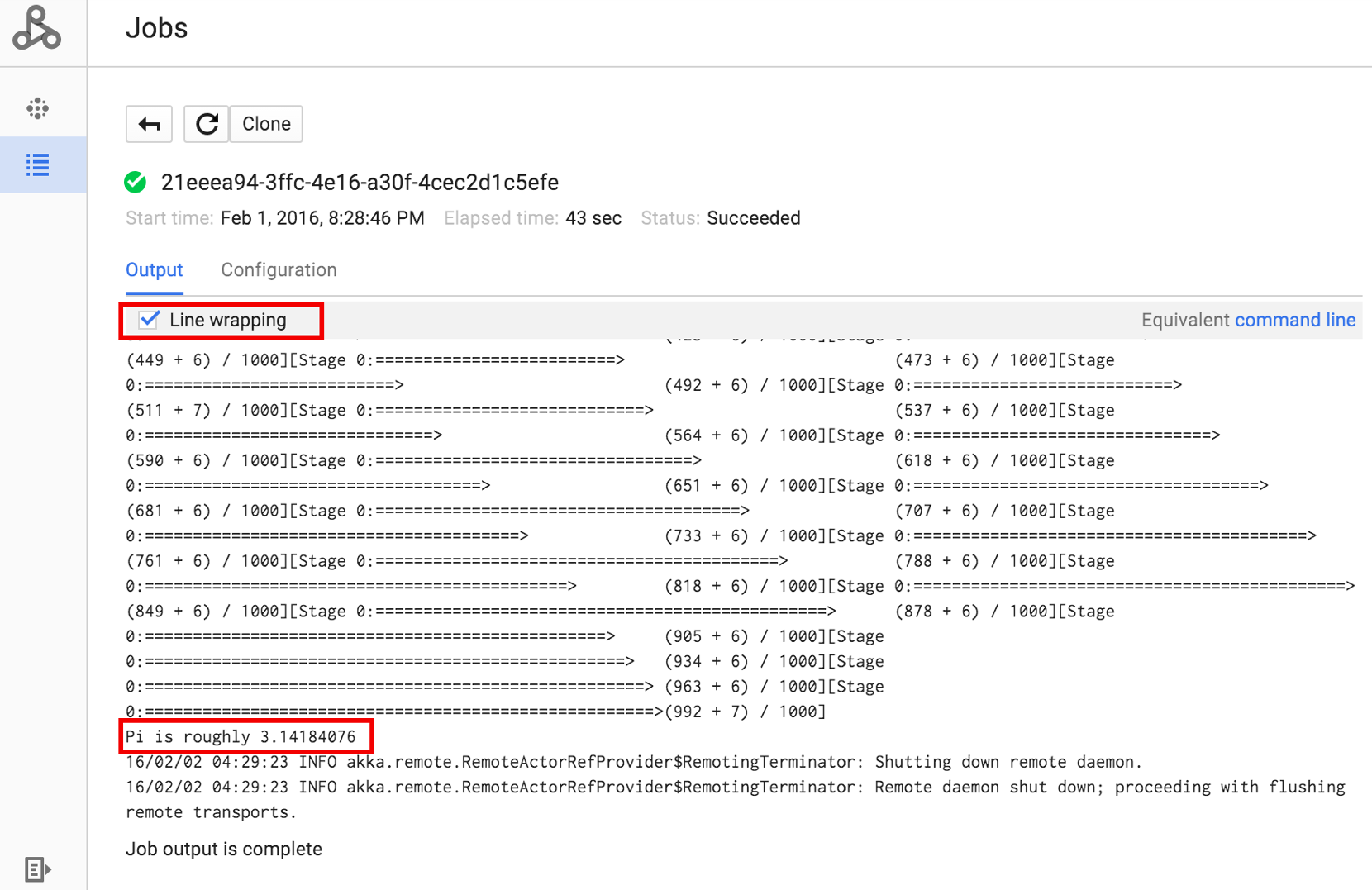
Clique no ID do job para abrir a página Jobs, em que você pode conferir a saída do driver do job. Como este job produz linhas de saída longas que
excedem a largura da janela do navegador, você pode marcar a caixa de Quebra de linha para exibir todo
o texto de saída e mostrar o resultado calculado para pi.
Visualize a saída do driver de job na linha de comando usando o comando
gcloud dataproc jobs wait
mostrado abaixo. Para mais informações, consulte
Ver saída do job – COMANDO GCLOUD.
Copie e cole o código do projeto como o valor para a sinalização --project e o
ID do job (mostrado na lista de jobs) como o argumento final.
gcloud dataproc jobs wait job-id \ --project=project-id \ --region=region
Veja os snippets da saída do driver do job SparkPi
de exemplo enviado acima:
... 2015-06-25 23:27:23,810 INFO [dag-scheduler-event-loop] scheduler.DAGScheduler (Logging.scala:logInfo(59)) - Stage 0 (reduce at SparkPi.scala:35) finished in 21.169 s 2015-06-25 23:27:23,810 INFO [task-result-getter-3] cluster.YarnScheduler (Logging.scala:logInfo(59)) - Removed TaskSet 0.0, whose tasks have all completed, from pool 2015-06-25 23:27:23,819 INFO [main] scheduler.DAGScheduler (Logging.scala:logInfo(59)) - Job 0 finished: reduce at SparkPi.scala:35, took 21.674931 s Pi is roughly 3.14189648 ... Job [c556b47a-4b46-4a94-9ba2-2dcee31167b2] finished successfully. driverOutputUri: gs://sample-staging-bucket/google-cloud-dataproc-metainfo/cfeaa033-749e-48b9-... ...
gcloud
Para enviar um job a um cluster do Dataproc, execute o comando gcloud dataproc jobs submit da CLI gcloud localmente em uma janela de terminal ou no Cloud Shell.
gcloud dataproc jobs submit job-command \ --cluster=cluster-name \ --region=region \ other dataproc-flags \ -- job-args
- Liste os
hello-world.pyacessíveis publicamente localizados no Cloud Storage.gcloud storage cat gs://dataproc-examples/pyspark/hello-world/hello-world.py
#!/usr/bin/python import pyspark sc = pyspark.SparkContext() rdd = sc.parallelize(['Hello,', 'world!']) words = sorted(rdd.collect()) print(words)
- Envie o job do Pyspark para o Dataproc.
gcloud dataproc jobs submit pyspark \ gs://dataproc-examples/pyspark/hello-world/hello-world.py \ --cluster=cluster-name \ --region=region
Waiting for job output... … ['Hello,', 'world!'] Job finished successfully.
- Execute o exemplo SparkPi pré-instalado no nó mestre do
cluster do Dataproc.
gcloud dataproc jobs submit spark \ --cluster=cluster-name \ --region=region \ --class=org.apache.spark.examples.SparkPi \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 1000
Job [54825071-ae28-4c5b-85a5-58fae6a597d6] submitted. Waiting for job output… … Pi is roughly 3.14177148 … Job finished successfully. …
REST
Nesta seção, mostramos como enviar um job do Spark para calcular o valor aproximado de
pi usando a API
jobs.submit do Dataproc.
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
- project-id: Google Cloud ID do projeto
- region: região do cluster
- clusterName: nome do cluster
Método HTTP e URL:
POST https://dataproc.googleapis.com/v1/projects/project-id/regions/region/jobs:submit
Corpo JSON da solicitação:
{
"job": {
"placement": {
"clusterName": "cluster-name"
},
"sparkJob": {
"args": [
"1000"
],
"mainClass": "org.apache.spark.examples.SparkPi",
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
}
}
}
Para enviar a solicitação, expanda uma destas opções:
Você receberá uma resposta JSON semelhante a esta:
{
"reference": {
"projectId": "project-id",
"jobId": "job-id"
},
"placement": {
"clusterName": "cluster-name",
"clusterUuid": "cluster-Uuid"
},
"sparkJob": {
"mainClass": "org.apache.spark.examples.SparkPi",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "2020-10-07T20:16:21.759Z"
},
"jobUuid": "job-Uuid"
}
Java
Python
Go
Node.js
Enviar um trabalho diretamente no cluster
Se você quiser executar um job diretamente no cluster sem usar o serviço do Dataproc, use o SSH no nó mestre do cluster e execute o job no nó mestre.
Depois de estabelecer uma conexão SSH com a instância mestre de VM, execute comandos em uma janela de terminal no nó mestre do cluster para:
- abrir um shell do Spark;
- executar um job do Spark simples para contar o número de linhas em um arquivo "hello-world" do Python (sete linhas) localizado em um arquivo do Cloud Storage acessível publicamente;
sair do shell.
user@cluster-name-m:~$ spark-shell ... scala> sc.textFile("gs://dataproc-examples" + "/pyspark/hello-world/hello-world.py").count ... res0: Long = 7 scala> :quit
Executar jobs de bash no Dataproc
Execute um script bash como job do Dataproc porque os
mecanismos usados não são compatíveis com um tipo de job de nível superior ou porque
você precisa configurar ou calcular os argumentos antes de iniciar
um job usando hadoop ou spark-submit do seu script.
Exemplo de Python
Suponha que você tenha copiado um script hello.sh bash no Cloud Storage:
gcloud storage cp hello.sh gs://${BUCKET}/hello.shComo o comando pig fs usa caminhos do Hadoop, copie o script do
Cloud Storage para um destino especificado como file:/// para garantir
que ele esteja no sistema de arquivos local em vez do HDFS. Os comandos sh subsequentes
fazem referência ao sistema de arquivos local automaticamente e não exigem o prefixo
file:///.
gcloud dataproc jobs submit pig --cluster=${CLUSTER} --region=${REGION} \
-e='fs -cp -f gs://${BUCKET}/hello.sh file:///tmp/hello.sh; sh chmod 750 /tmp/hello.sh; sh /tmp/hello.sh'Como alternativa, como os jobs do Dataproc enviam o argumento --jars e em um
diretório temporário criado durante a vida útil do job, especifique
o script de shell do Cloud Storage como um argumento --jars:
gcloud dataproc jobs submit pig --cluster=${CLUSTER} --region=${REGION} \
--jars=gs://${BUCKET}/hello.sh \
-e='sh chmod 750 ${PWD}/hello.sh; sh ${PWD}/hello.sh'Observe que o argumento --jars também pode fazer referência a um script local:
gcloud dataproc jobs submit pig --cluster=${CLUSTER} --region=${REGION} \
--jars=hello.sh \
-e='sh chmod 750 ${PWD}/hello.sh; sh ${PWD}/hello.sh'