Antes de começar
Se ainda não tiver feito isso, configure um projeto e dois (2)buckets do Cloud Storage.
Crie o projeto
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Compute Engine, Cloud Storage, and Cloud Run functions APIs.
- Install the Google Cloud CLI.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Compute Engine, Cloud Storage, and Cloud Run functions APIs.
- Install the Google Cloud CLI.
-
To initialize the gcloud CLI, run the following command:
gcloud init
Criar ou usar dois (2) buckets do Cloud Storage no projeto
Você precisará de dois buckets do Cloud Storage no projeto: um para arquivos de entrada e outro para saída.
- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create bucket.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
- For Name your bucket, enter a name that meets the bucket naming requirements.
-
For Choose where to store your data, do the following:
- Select a Location type option.
- Select a Location option.
- For Choose a default storage class for your data, select a storage class.
- For Choose how to control access to objects, select an Access control option.
- For Advanced settings (optional), specify an encryption method, a retention policy, or bucket labels.
- Click Create.
Criar um modelo de fluxo de trabalho
Copie e execute os comandos listados abaixo em uma janela de terminal local ou no Cloud Shell para criar e definir um modelo de fluxo de trabalho.
Observações:
- Os comandos especificam a região "us-central1". É possível especificar uma região diferente ou excluir a sinalização
--region, se tiver executadogcloud config set compute/regionanteriormente para definir a propriedade da região. - A sequência "- " (traço traço espaço) transmite argumentos para o arquivo jar.
O comando
wordcount input_bucket output_direxecutará o aplicativo de contagem de palavras do jar em arquivos de texto contidos noinput_bucketdo Cloud Storage e enviará arquivos de contagem de palavras de saída para umoutput_bucket. Você parametrizará o argumento do bucket de entrada da contagem de palavras para permitir que sua função forneça esse argumento.
- Crie o modelo de fluxo de trabalho.
gcloud dataproc workflow-templates create wordcount-template \ --region=us-central1
- Adicione o job de contagem de palavras ao modelo de fluxo de trabalho.
-
Especifique o output-bucket-name antes de executar o comando (a função fornecerá o bucket de entrada).
Depois que você inserir o nome do bucket de saída, o argumento do bucket de saída deverá ler da seguinte maneira:
gs://your-output-bucket/wordcount-output". - O ID da etapa "count" é obrigatório e identifica o job do hadoop adicionado.
gcloud dataproc workflow-templates add-job hadoop \ --workflow-template=wordcount-template \ --step-id=count \ --jar=file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar \ --region=us-central1 \ -- wordcount gs://input-bucket gs://output-bucket-name/wordcount-output
-
Especifique o output-bucket-name antes de executar o comando (a função fornecerá o bucket de entrada).
Depois que você inserir o nome do bucket de saída, o argumento do bucket de saída deverá ler da seguinte maneira:
- Use um cluster gerenciado de nó único para executar o fluxo de trabalho. O Dataproc criará o cluster, executará o fluxo de trabalho nele e excluirá o cluster quando o fluxo de trabalho for concluído.
gcloud dataproc workflow-templates set-managed-cluster wordcount-template \ --cluster-name=wordcount \ --single-node \ --region=us-central1
- Clique no nome do
wordcount-templatena página Fluxos de trabalho do Dataproc no console do Google Cloud para abrir a página Detalhes do modelo de fluxo de trabalho. Confirme os atributos do modelo de contagem de palavras.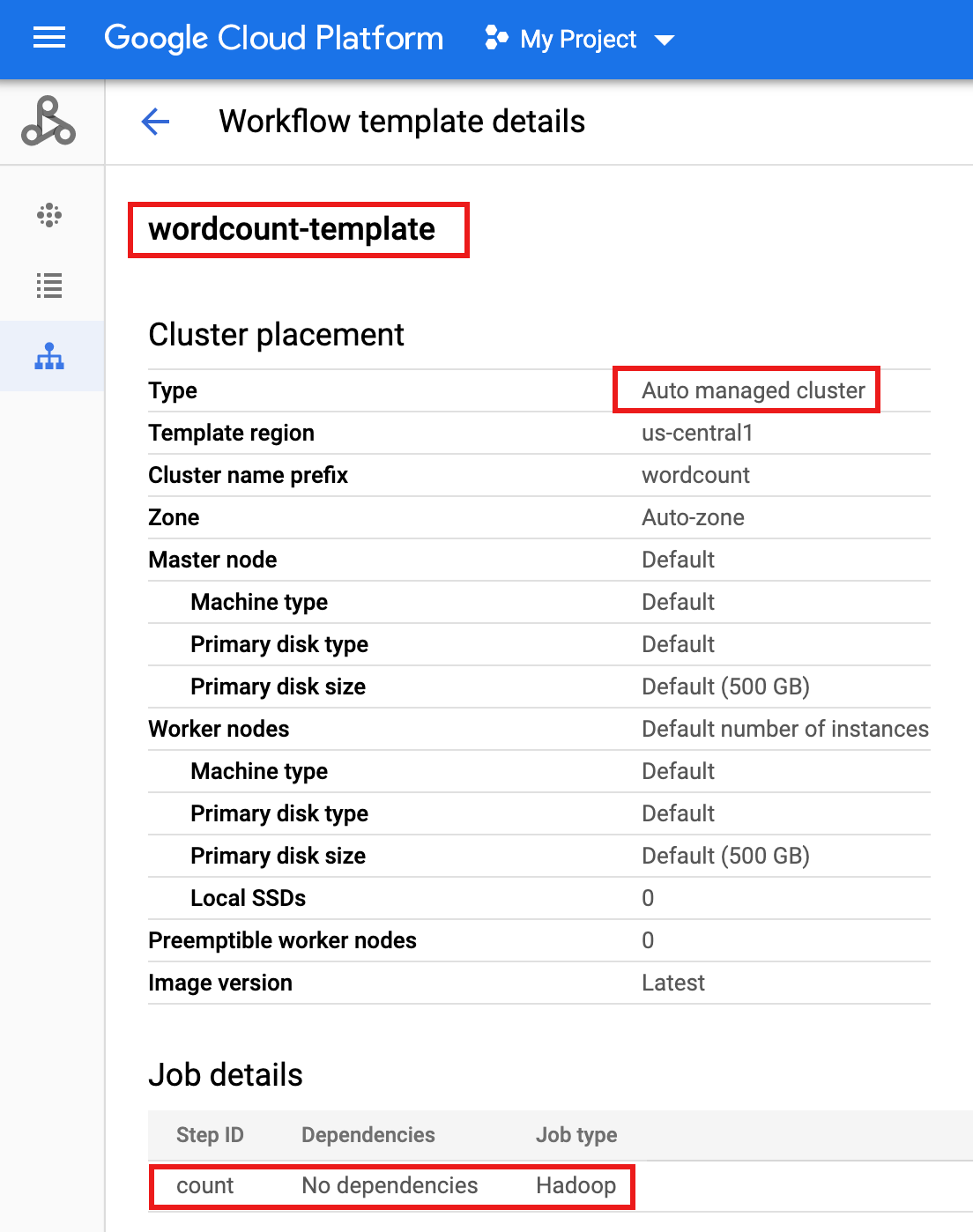
Parametrizar o modelo de fluxo de trabalho.
Parametrize a variável do bucket de entrada que será transmitida para o modelo de fluxo de trabalho.
- Exporte o modelo de fluxo de trabalho para um arquivo de texto
wordcount.yamlpara parametrização.gcloud dataproc workflow-templates export wordcount-template \ --destination=wordcount.yaml \ --region=us-central1
- Usando um editor de texto, abra
wordcount.yamle adicione um blocoparametersao final do arquivo YAML para que o INPUT_BUCKET_URI do Cloud Storage possa ser transmitido comoargs[1]para o binário de contagem de palavras, quando o fluxo de trabalho for acionado.Veja abaixo um exemplo de arquivo YAML exportado. Você pode adotar uma das duas abordagens para atualizar seu modelo:
- Copie e cole o arquivo inteiro para substituir o
wordcount.yamlexportado depois de substituí-lo your-output_bucket pelo nome do bucket de saída, OU - Copie e cole somente a seção
parametersno final do arquivowordcount.yamlexportado.
jobs: - hadoopJob: args: - wordcount - gs://input-bucket - gs://your-output-bucket/wordcount-output mainJarFileUri: file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar stepId: count placement: managedCluster: clusterName: wordcount config: softwareConfig: properties: dataproc:dataproc.allow.zero.workers: 'true' parameters: - name: INPUT_BUCKET_URI description: wordcount input bucket URI fields: - jobs['count'].hadoopJob.args[1] - Copie e cole o arquivo inteiro para substituir o
- Importe o arquivo de texto
wordcount.yamlparametrizado. Digite "Y" quando solicitado para substituir o modelo.gcloud dataproc workflow-templates import wordcount-template \ --source=wordcount.yaml \ --region=us-central1
crie uma função do Cloud
Abra a página Funções do Cloud Run no console do Google Cloud e clique em CRIAR FUNÇÃO.
Na página Criar função, digite ou selecione as seguintes informações:
- Nome: contagem de palavras
- Memória alocada: mantenha a seleção padrão.
- Gatilho:
- Cloud Storage
- Tipo de evento: finalizar/criar
- Bucket: selecione o bucket de entrada. Consulte Criar um bucket do Cloud Storage no projeto. Quando um arquivo é adicionado a esse bucket, a função aciona o fluxo de trabalho. O fluxo de trabalho executará o aplicativo de contagem de palavras, que processará todos os arquivos de texto no bucket.
Código-fonte:
- Editor in-line
- Ambiente de execução: Node.js 8
- Guia
INDEX.JS: substitua o snippet de código padrão pelo código a seguir e edite a linhaconst projectIdpara fornecer -your-project-id- (sem um "-" inicial ou final).
const dataproc = require('@google-cloud/dataproc').v1; exports.startWorkflow = (data) => { const projectId = '-your-project-id-' const region = 'us-central1' const workflowTemplate = 'wordcount-template' const client = new dataproc.WorkflowTemplateServiceClient({ apiEndpoint: `${region}-dataproc.googleapis.com`, }); const file = data; console.log("Event: ", file); const inputBucketUri = `gs://${file.bucket}/${file.name}`; const request = { name: client.projectRegionWorkflowTemplatePath(projectId, region, workflowTemplate), parameters: {"INPUT_BUCKET_URI": inputBucketUri} }; client.instantiateWorkflowTemplate(request) .then(responses => { console.log("Launched Dataproc Workflow:", responses[1]); }) .catch(err => { console.error(err); }); };- Guia
PACKAGE.JSON: substitua o snippet de código padrão pelo código a seguir.
{ "name": "dataproc-workflow", "version": "1.0.0", "dependencies":{ "@google-cloud/dataproc": ">=1.0.0"} }- Função a ser executada: Insert: "startWorkflow".
Clique em CRIAR
Testar a função
Copie o arquivo público
rose.txtpara o bucket para acionar a função. Insira your-input-bucket-name (o bucket usado para acionar a função) no comando.gcloud storage cp gs://pub/shakespeare/rose.txt gs://your-input-bucket-name
Aguarde 30 segundos e execute o seguinte comando para verificar se a função foi concluída.
gcloud functions logs read wordcount
... Function execution took 1348 ms, finished with status: 'ok'
Para conferir os registros de função na página da lista Funções no console do Google Cloud , clique no nome da função
wordcounte em VER LOGS na página Detalhes da função.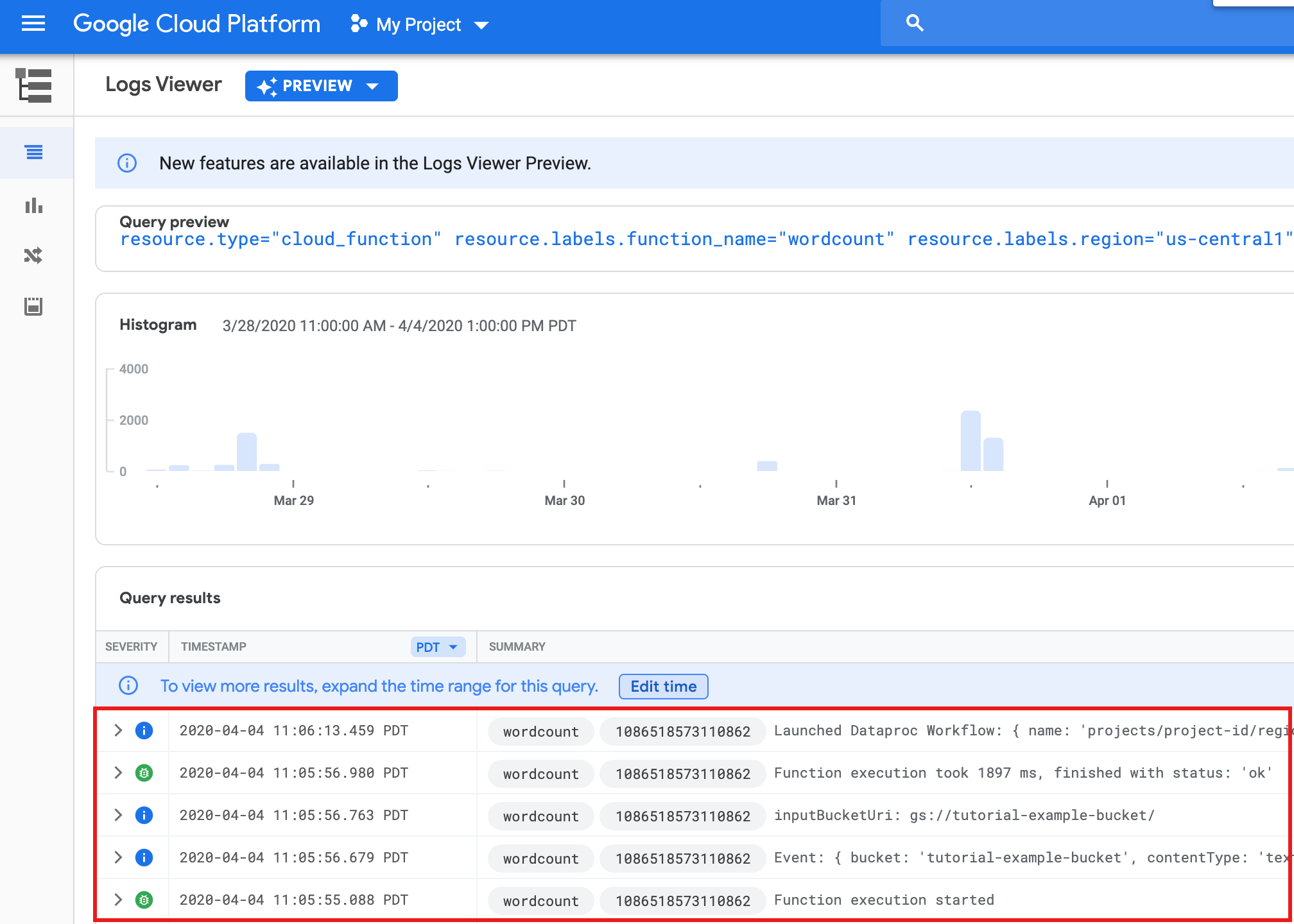
Você pode conferir a pasta
wordcount-outputno bucket de saída na página Navegador de armazenamento no console do Google Cloud .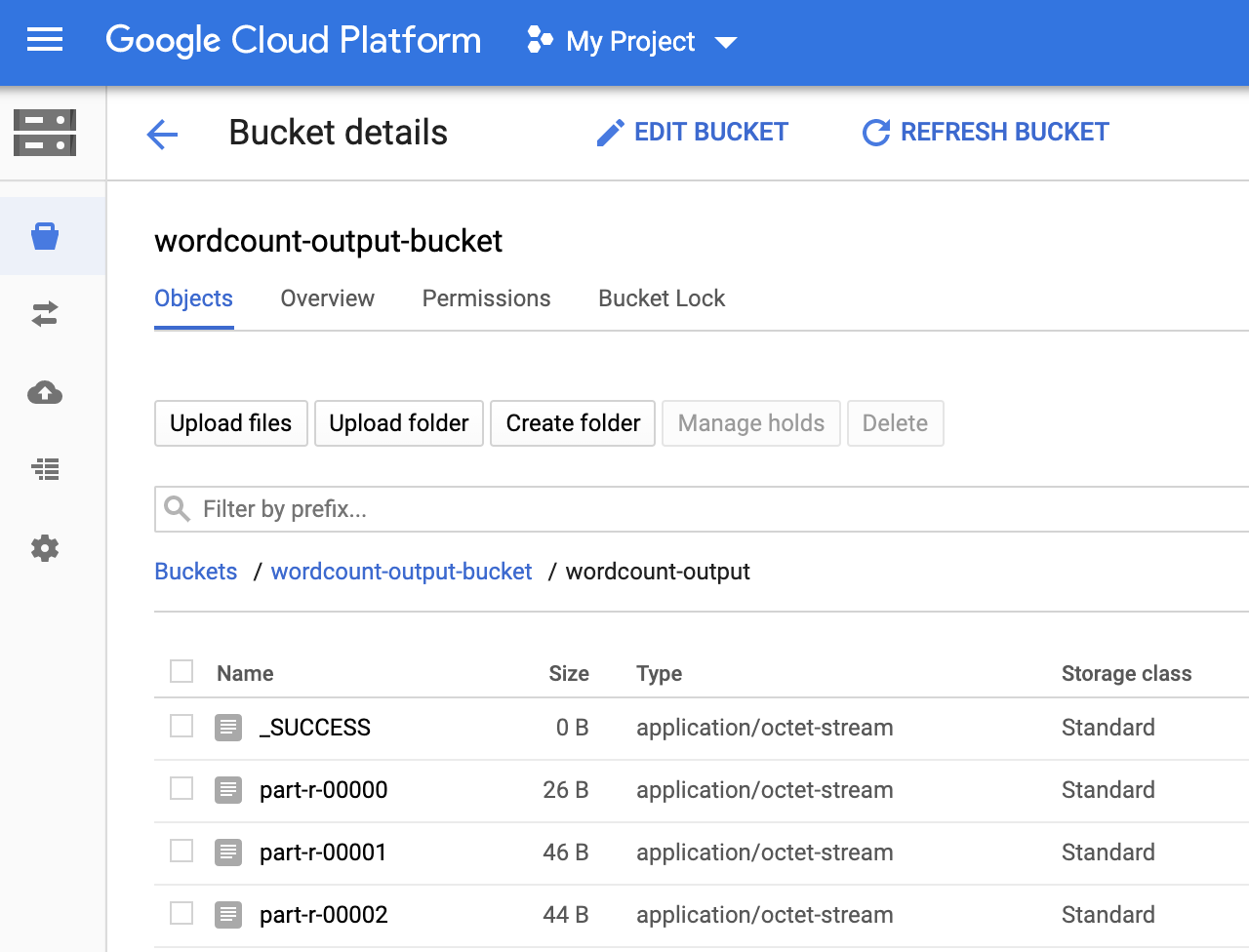
Depois que o fluxo de trabalho é concluído, os detalhes do job permanecem no console do Google Cloud . Clique no job
count...listado na página Jobs do Dataproc para conferir os detalhes do job do fluxo de trabalho.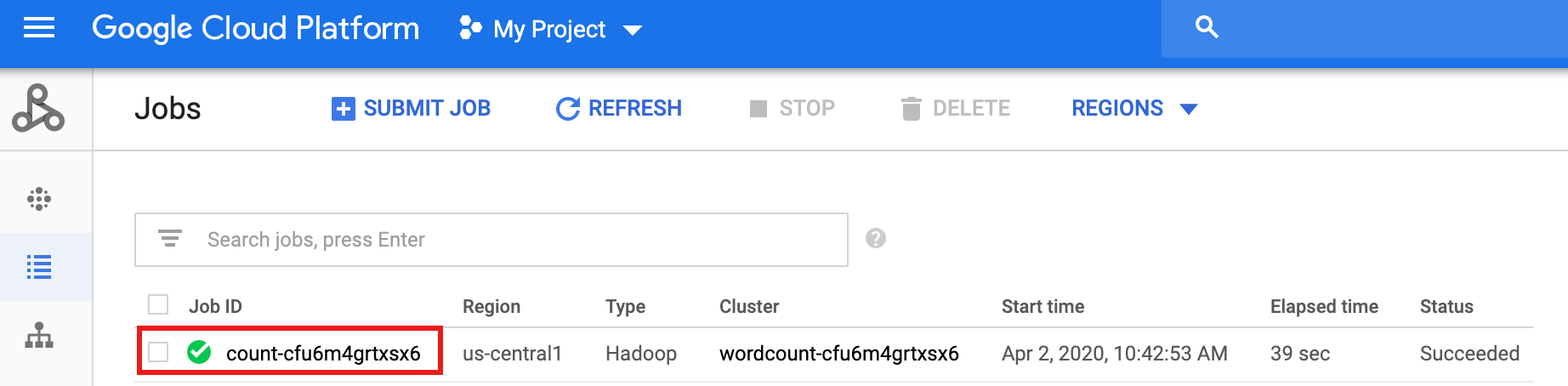
Limpar
O fluxo de trabalho neste tutorial exclui o cluster gerenciado quando o fluxo de trabalho é concluído. Para evitar custos recorrentes, exclua outros recursos associados a este tutorial.
Como excluir um projeto
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Como excluir buckets do Cloud Storage
- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click the checkbox for the bucket that you want to delete.
- To delete the bucket, click Delete, and then follow the instructions.
Como excluir o modelo de fluxo de trabalho
gcloud dataproc workflow-templates delete wordcount-template \ --region=us-central1
Como excluir a função do Cloud
Abra a página Cloud Run functions no console do
Google Cloud , marque a caixa à esquerda da função wordcount e clique em EXCLUIR.
A seguir
- Consulte Visão geral dos modelos de fluxo de trabalho do Dataproc
- Consulte Soluções de programação de fluxo de trabalho