O Trino (anteriormente Presto) é um mecanismo de consulta SQL distribuído desenvolvido para consultar grandes conjuntos de dados distribuídos em uma ou mais origens de dados heterogêneas. O Trino pode consultar Hive, MySQL, Kafka e outras fontes de dados por meio de conectores. Neste tutorial, mostramos como fazer as seguintes tarefas:
- Instalar o serviço Trino em um cluster do Dataproc
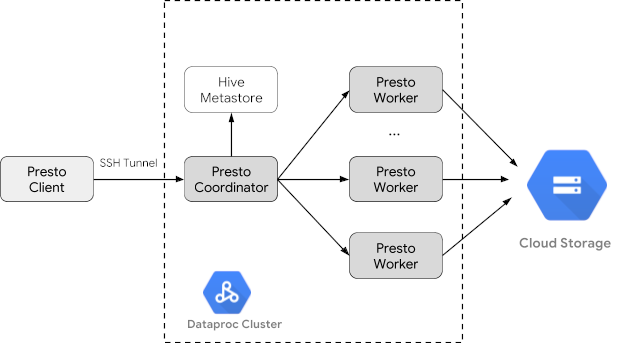
- Consultar dados públicos de um cliente Trino instalado na máquina local que se comunica com um serviço Trino no cluster
- Executar consultas de um aplicativo Java que se comunica com o serviço Trino no cluster pelo driver JDBC do Java para Trino.
Objetivos
- Extrair os dados do BigQuery
- Carregar os dados no Cloud Storage como arquivos CSV
- Transformar dados:
- Expor os dados como uma tabela externa Hive para que o Trino possa fazer consultas neles
- Converter os dados do formato CSV para o formato Parquet para agilizar as consultas
Custos
Neste documento, você usará os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
Antes de começar
Se você ainda não tiver feito isso, crie um projeto do Google Cloud e um bucket do Cloud Storage para armazenar os dados usados neste tutorial. 1. Configurar o projeto- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Compute Engine, Cloud Storage, and BigQuery APIs.
- Install the Google Cloud CLI.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Compute Engine, Cloud Storage, and BigQuery APIs.
- Install the Google Cloud CLI.
-
To initialize the gcloud CLI, run the following command:
gcloud init
- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create bucket.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
- For Name your bucket, enter a name that meets the bucket naming requirements.
-
For Choose where to store your data, do the following:
- Select a Location type option.
- Select a Location option.
- For Choose a default storage class for your data, select a storage class.
- For Choose how to control access to objects, select an Access control option.
- For Advanced settings (optional), specify an encryption method, a retention policy, or bucket labels.
- Click Create.
Criar um cluster do Dataproc
Crie um cluster do Dataproc usando a flag optional-components (disponível na versão de imagem 2.1 e mais recentes) para instalar o componente opcional do Trino no cluster e a flag enable-component-gateway para ativar o Gateway de componentes e permitir que você acesse a IU da Web do Trino no console do Google Cloud.
- Defina variáveis de ambiente.
- PROJECT: ID do projeto
- BUCKET_NAME: o nome do bucket do Cloud Storage que você criou em Antes de começar
- REGION: região onde o cluster usado neste tutorial será criado, por exemplo, "us-west1"
- WORKERS: 3 a 5 workers são recomendados para este tutorial
export PROJECT=project-id export WORKERS=number export REGION=region export BUCKET_NAME=bucket-name
- Execute a Google Cloud CLI na sua máquina local para criar o cluster.
gcloud beta dataproc clusters create trino-cluster \ --project=${PROJECT} \ --region=${REGION} \ --num-workers=${WORKERS} \ --scopes=cloud-platform \ --optional-components=TRINO \ --image-version=2.1 \ --enable-component-gateway
Preparar dados
Exporte o conjunto de dados bigquery-public-data chicago_taxi_trips para o Cloud Storage como arquivos CSV e crie uma tabela externa Hive para fazer referência aos dados.
- Na máquina local, execute o seguinte comando para importar os dados de táxi do BigQuery como arquivos CSV sem cabeçalhos para o bucket do Cloud Storage criado em Antes de começar.
bq --location=us extract --destination_format=CSV \ --field_delimiter=',' --print_header=false \ "bigquery-public-data:chicago_taxi_trips.taxi_trips" \ gs://${BUCKET_NAME}/chicago_taxi_trips/csv/shard-*.csv - Crie tabelas externas do Hive com backup dos arquivos CSV e Parquet em seu bucket do Cloud Storage.
- Crie a tabela externa Hive
chicago_taxi_trips_csv.gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_csv( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE location 'gs://${BUCKET_NAME}/chicago_taxi_trips/csv/';" - Verifique a criação da tabela externa Hive.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_csv;" - Crie outra tabela Hive externa
chicago_taxi_trips_parquetcom as mesmas colunas, mas com dados armazenados no formato Parquet para melhorar o desempenho da consulta.gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_parquet( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) STORED AS PARQUET location 'gs://${BUCKET_NAME}/chicago_taxi_trips/parquet/';" - Carregue os dados da tabela Hive CSV na tabela Hive Parquet.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " INSERT OVERWRITE TABLE chicago_taxi_trips_parquet SELECT * FROM chicago_taxi_trips_csv;" - Verifique se os dados foram carregados corretamente.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_parquet;"
- Crie a tabela externa Hive
Executar consultas
Você pode executar consultas localmente na CLI do Trino ou em um aplicativo.
Consultas de CLI do Trino
Esta seção demonstra como consultar o conjunto de dados de táxi Hive Parquet usando a CLI do Trino.
- Execute o seguinte comando na máquina local para SSH no nó mestre do cluster. O terminal local deixará de responder durante a execução do comando.
gcloud compute ssh trino-cluster-m
- Na janela do terminal SSH no nó mestre do cluster, execute a
CLI do Trino, que se conecta ao servidor Trino em execução no nó
mestre.
trino --catalog hive --schema default
- No prompt
trino:default, verifique se o Trino pode encontrar as tabelas do Hive.show tables;
Table ‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐ chicago_taxi_trips_csv chicago_taxi_trips_parquet (2 rows)
- Execute consultas a partir do prompt
trino:defaulte compare o desempenho da consulta de dados Parquet x CSV.- Consulta de dados Parquet
select count(*) from chicago_taxi_trips_parquet where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171735_00006_2sz8c, FINISHED, 3 nodes Splits: 308 total, 308 done (100.00%) 0:16 [113M rows, 297MB] [6.91M rows/s, 18.2MB/s] - Consulta de dados CSV
select count(*) from chicago_taxi_trips_csv where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171936_00009_2sz8c, FINISHED, 3 nodes Splits: 881 total, 881 done (100.00%) 0:47 [113M rows, 41.5GB] [2.42M rows/s, 911MB/s]
- Consulta de dados Parquet
Consultas de aplicativos Java
Para executar consultas de um aplicativo Java pelo driver JDBC do Java para Trino:
1. Faça o download do
driver JDBC do Java para Trino.
1. Adicione uma dependência trino-jdbc no
pom.xml do Maven.
<dependency> <groupId>io.trino</groupId> <artifactId>trino-jdbc</artifactId> <version>376</version> </dependency>
package dataproc.codelab.trino;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
public class TrinoQuery {
private static final String URL = "jdbc:trino://trino-cluster-m:8080/hive/default";
private static final String SOCKS_PROXY = "localhost:1080";
private static final String USER = "user";
private static final String QUERY =
"select count(*) as count from chicago_taxi_trips_parquet where trip_miles > 50";
public static void main(String[] args) {
try {
Properties properties = new Properties();
properties.setProperty("user", USER);
properties.setProperty("socksProxy", SOCKS_PROXY);
Connection connection = DriverManager.getConnection(URL, properties);
try (Statement stmt = connection.createStatement()) {
ResultSet rs = stmt.executeQuery(QUERY);
while (rs.next()) {
int count = rs.getInt("count");
System.out.println("The number of long trips: " + count);
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}Geração de registros e monitoramento
Logging
Os registros do Trino estão localizados em /var/log/trino/ nos nós mestre e
de trabalho do cluster.
IU da Web
Consulte Como visualizar e acessar URLs do Gateway de componentes para abrir a interface da Web do Trino em execução no nó mestre do cluster no navegador local.
Monitoramento
O Trino expõe informações de ambiente de execução do cluster por meio de tabelas de ambiente de execução.
No prompt (do trino:default) de uma sessão do Trino,
execute a seguinte consulta para conferir os dados da tabela de ambiente de execução:
select * FROM system.runtime.nodes;
Limpar
Depois de concluir o tutorial, você pode limpar os recursos que criou para que eles parem de usar a cota e gerar cobranças. Nas seções a seguir, você aprenderá a excluir e desativar esses recursos.
Exclua o projeto
O jeito mais fácil de evitar cobranças é excluindo o projeto que você criou para o tutorial.
Para excluir o projeto, faça o seguinte:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Excluir o cluster
- Para excluir o cluster:
gcloud dataproc clusters delete --project=${PROJECT} trino-cluster \ --region=${REGION}
Excluir o bucket
- Para excluir o bucket do Cloud Storage criado em Antes de começar, incluindo os arquivos de dados armazenados no bucket:
gcloud storage rm gs://${BUCKET_NAME} --recursive