Objetivos
Este tutorial mostra como:
- Crie um cluster do Dataproc, instalando o Apache HBase e o Apache ZooKeeper no cluster
- Crie uma tabela HBase com o shell HBase em execução no nó principal do cluster Dataproc
- Use o Cloud Shell para enviar uma tarefa do Spark Java ou PySpark para o serviço Dataproc que escreve dados na tabela HBase e, em seguida, lê dados da mesma
Custos
Neste documento, usa os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custos com base na sua utilização projetada,
use a calculadora de preços.
Antes de começar
Se ainda não o fez, crie um projeto da Google Cloud Platform.
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc and Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc and Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Execute o seguinte comando num terminal de sessão do Cloud Shell para:
- Instale os componentes HBase e ZooKeeper
- Aprovisione três nós de trabalho (recomenda-se que tenha entre três e cinco trabalhadores para executar o código neste tutorial)
- Ative o Component Gateway
- Use a versão 2.0 da imagem
- Use a flag
--propertiespara adicionar a configuração do HBase e a biblioteca do HBase aos caminhos de classe do controlador e do executor do Spark.
A partir da Google Cloud consola ou de um terminal de sessão do Cloud Shell, use SSH no nó principal do cluster do Dataproc.
Valide a instalação do conetor Apache HBase Spark no nó principal:
ls -l /usr/lib/spark/jars | grep hbase-spark
-rw-r--r-- 1 root root size date time hbase-spark-connector.version.jar
Mantenha o terminal da sessão SSH aberto para:
- Crie uma tabela HBase
- (Utilizadores de Java): execute comandos no nó principal do cluster para determinar as versões dos componentes instalados no cluster
- Leia a sua tabela Hbase depois de executar o código
Abra a shell do HBase:
hbase shell
Crie uma tabela "my-table" do HBase com uma família de colunas "cf":
create 'my_table','cf'
- Para confirmar a criação da tabela, na Google Cloud consola, clique em HBase
nos Google Cloud links do Component Gateway da consola
para abrir a IU do Apache HBase.
my-tableé apresentado na secção Tabelas da página Página inicial.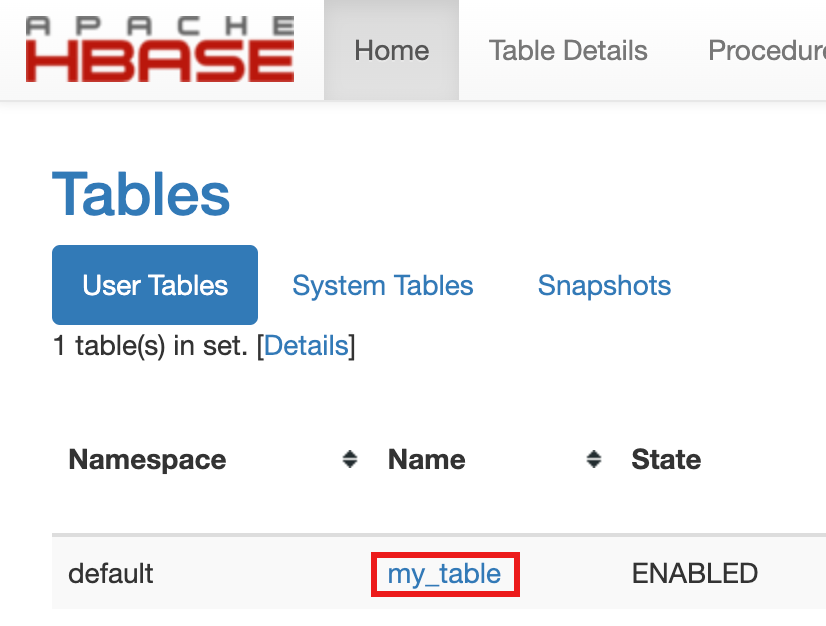
- Para confirmar a criação da tabela, na Google Cloud consola, clique em HBase
nos Google Cloud links do Component Gateway da consola
para abrir a IU do Apache HBase.
Abra um terminal de sessão do Cloud Shell.
Clone o repositório do GitHub GoogleCloudDataproc/cloud-dataproc para o terminal da sessão do Cloud Shell:
git clone https://github.com/GoogleCloudDataproc/cloud-dataproc.git
Altere para o diretório
cloud-dataproc/spark-hbase:cd cloud-dataproc/spark-hbase
user-name@cloudshell:~/cloud-dataproc/spark-hbase (project-id)$
Envie a tarefa do Dataproc.
- Defina as versões dos componentes no ficheiro
pom.xml.- A página Versões de lançamento do Dataproc 2.0.x apresenta as versões dos componentes Scala, Spark e HBase instalados com as quatro subversões 2.0 de imagem mais recentes e a última.
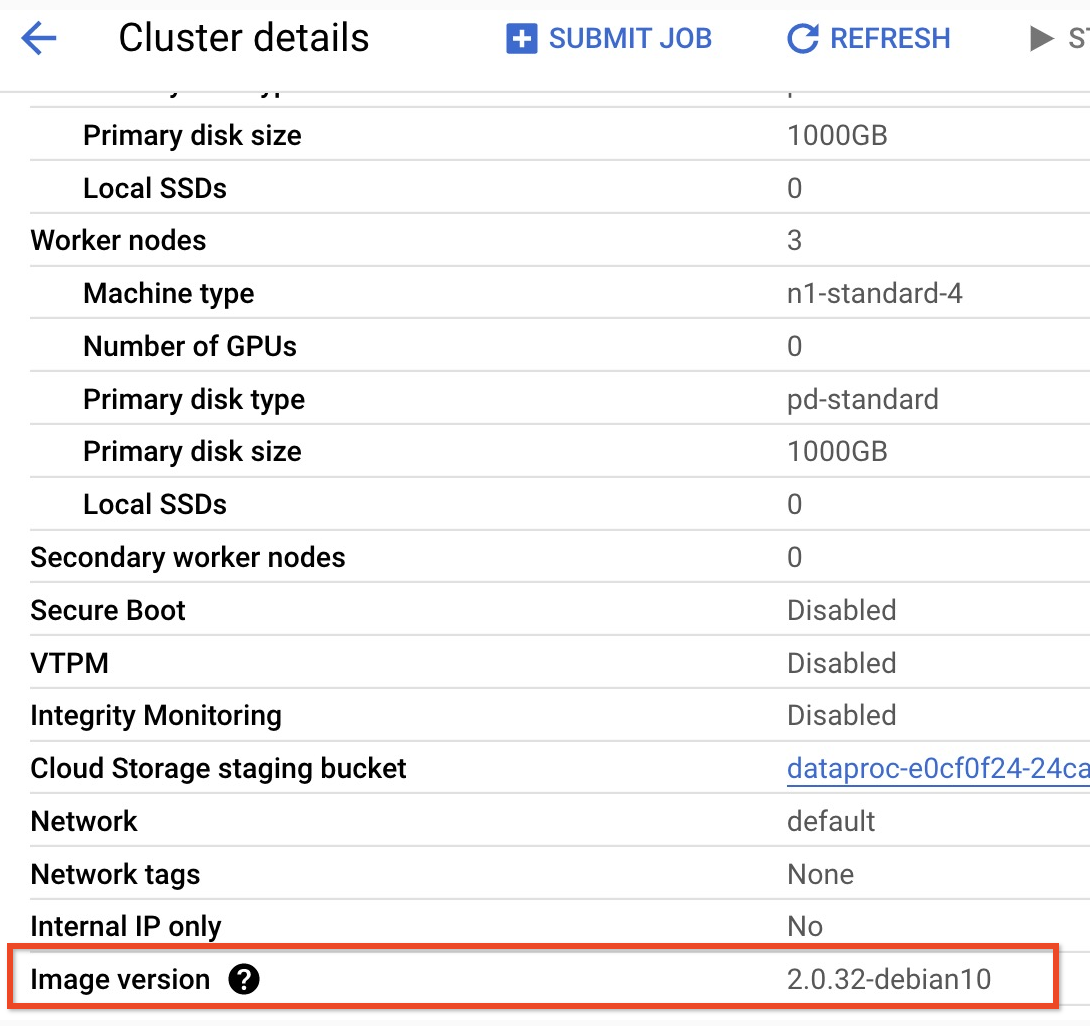
- Para encontrar a versão secundária do cluster da versão de imagem 2.0,
clique no nome do cluster na página
Clusters na
Google Cloud consola para abrir a página Detalhes do cluster, onde a
versão de imagem do cluster é apresentada.
- Para encontrar a versão secundária do cluster da versão de imagem 2.0,
clique no nome do cluster na página
Clusters na
Google Cloud consola para abrir a página Detalhes do cluster, onde a
versão de imagem do cluster é apresentada.
- Em alternativa, pode executar os seguintes comandos num
terminal de sessão SSH
a partir do nó principal do cluster para determinar as versões dos componentes:
- Verifique a versão do Scala:
scala -version
- Verifique a versão do Spark (prima Control + D para sair):
spark-shell
- Verifique a versão do HBase:
hbase version
- Identifique as dependências de versão do Spark, Scala e HBase no Maven
pom.xml:<properties> <scala.version>scala full version (for example, 2.12.14)</scala.version> <scala.main.version>scala main version (for example, 2.12)</scala.main.version> <spark.version>spark version (for example, 3.1.2)</spark.version> <hbase.client.version>hbase version (for example, 2.2.7)</hbase.client.version> <hbase-spark.version>1.0.0(the current Apache HBase Spark Connector version)> </properties>
hbase-spark.versioné a versão atual do conector do Spark HBase; deixe este número da versão inalterado.
- Verifique a versão do Scala:
- Edite o ficheiro
pom.xmlno editor do Cloud Shell para inserir os números de versão corretos do Scala, Spark e HBase. Clique em Abrir terminal quando terminar a edição para voltar à linha de comandos do terminal do Cloud Shell.cloudshell edit .
- Mude para o Java 8 no Cloud Shell. Esta versão do JDK é necessária para criar o código (pode ignorar quaisquer mensagens de aviso de plug-ins):
sudo update-java-alternatives -s java-1.8.0-openjdk-amd64 && export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
- Valide a instalação do Java 8:
java -version
openjdk version "1.8..."
- A página Versões de lançamento do Dataproc 2.0.x apresenta as versões dos componentes Scala, Spark e HBase instalados com as quatro subversões 2.0 de imagem mais recentes e a última.
- Crie o ficheiro
jar:mvn clean package
.jaré colocado no subdiretório/target(por exemplo,target/spark-hbase-1.0-SNAPSHOT.jar. Envie o trabalho.
gcloud dataproc jobs submit spark \ --class=hbase.SparkHBaseMain \ --jars=target/filename.jar \ --region=cluster-region \ --cluster=cluster-name
--jars: insira o nome do ficheiro.jarapós "target/" e antes de ".jar".- Se não definiu os caminhos de classe do HBase do controlador e do executor do Spark quando
criou o cluster,
tem de defini-los com cada envio de tarefa, incluindo a seguinte flag
‑‑propertiesno comando de envio de tarefa:--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
Veja a saída da tabela HBase na saída do terminal da sessão do Cloud Shell:
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
Envie o trabalho.
gcloud dataproc jobs submit pyspark scripts/pyspark-hbase.py \ --region=cluster-region \ --cluster=cluster-name
- Se não definiu os caminhos de classe do HBase do controlador e do executor do Spark quando
criou o cluster,
tem de defini-los com cada envio de tarefa, incluindo a seguinte flag
‑‑propertiesno comando de envio de tarefa:--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
- Se não definiu os caminhos de classe do HBase do controlador e do executor do Spark quando
criou o cluster,
tem de defini-los com cada envio de tarefa, incluindo a seguinte flag
Veja a saída da tabela HBase na saída do terminal da sessão do Cloud Shell:
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
- Abra a shell do HBase:
hbase shell
- Analisar "my-table":
scan 'my_table'
ROW COLUMN+CELL key1 column=cf:name, timestamp=1647364013561, value=foo key2 column=cf:name, timestamp=1647364012817, value=bar 2 row(s) Took 0.5009 seconds
Limpar
Depois de concluir o tutorial, pode limpar os recursos que criou para que deixem de usar a quota e incorrer em custos. As secções seguintes descrevem como eliminar ou desativar estes recursos.
Elimine o projeto
A forma mais fácil de eliminar a faturação é eliminar o projeto que criou para o tutorial.
Para eliminar o projeto:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Elimine o cluster
- Para eliminar o cluster:
gcloud dataproc clusters delete cluster-name \ --region=${REGION}
Crie um cluster do Dataproc
gcloud dataproc clusters create cluster-name \ --region=region \ --optional-components=HBASE,ZOOKEEPER \ --num-workers=3 \ --enable-component-gateway \ --image-version=2.0 \ --properties='spark:spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark:spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
Valide a instalação do conetor
Crie uma tabela HBase
Execute os comandos indicados nesta secção no terminal da sessão SSH do nó principal que abriu no passo anterior.
Veja o código do Spark
Java
Python
Executar o código
Java
Python
Analise a tabela HBase
Pode analisar o conteúdo da sua tabela HBase executando os seguintes comandos no terminal da sessão SSH do nó principal que abriu em Verifique a instalação do conector: