목표
이 튜토리얼에서는 다음을 수행하는 방법을 보여줍니다.
- Dataproc 클러스터를 만들고 Apache HBase 및 Apache ZooKeeper를 클러스터에 설치합니다.
- Dataproc 클러스터의 마스터 노드에서 실행되는 HBase 셸을 사용하여 HBase 테이블을 만듭니다.
- Cloud Shell을 사용해서 자바 또는 PySpark Spark 작업을 데이터를 기록할 Dataproc 서비스에 제출한 후 HBase 테이블에서 데이터를 읽습니다.
비용
이 문서에서는 비용이 청구될 수 있는 Google Cloud구성요소( )를 사용합니다.
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용합니다.
시작하기 전에
아직 Google Cloud Platform 프로젝트를 만들지 않았으면 먼저 프로젝트를 만듭니다.
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc and Compute Engine APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc and Compute Engine APIs.
Cloud Shell 세션 터미널에서 다음 명령어를 실행하여 다음을 수행합니다.
- HBase 및 ZooKeeper 구성요소를 설치합니다.
- 3개의 워커 노드를 프로비저닝합니다. 이 튜토리얼의 코드를 실행하기 위해서는 3~5개 워커 노드가 권장됩니다.
- 구성요소 게이트웨이를 사용 설정합니다.
- 이미지 버전 2.0을 사용합니다.
--properties플래그를 사용해서 HBase 구성 및 HBase 라이브러리를 Spark 드라이버 및 실행자 클래스 경로에 추가합니다.
Google Cloud 콘솔 또는 Cloud Shell 세션 터미널에서 Dataproc 클러스터 마스터 노드에 SSH로 연결합니다.
마스터 노드에서 Apache HBase Spark 커넥터 설치를 확인합니다.
ls -l /usr/lib/spark/jars | grep hbase-spark
-rw-r--r-- 1 root root size date time hbase-spark-connector.version.jar
SSH 세션 터미널을 열린 상태로 유지합니다.
- HBase 테이블 만들기
- (자바 사용자): 클러스터의 마스터 노드에서 명령어를 실행하여 클러스터에 설치된 구성요소의 버전을 확인합니다.
- 코드 실행 후 Hbase 테이블을 스캔합니다.
HBase 셸을 엽니다.
hbase shell
'cf' column family를 사용해서 HBase 'my-table'을 만듭니다.
create 'my_table','cf'
- 테이블 만들기를 확인하려면 Google Cloud 콘솔의 Google Cloud 콘솔 구성요소 게이트웨이 링크에서 HBase를 클릭하여 Apache HBase UI를 엽니다.
my-table은 홈 페이지에서 테이블 섹션에 나열됩니다.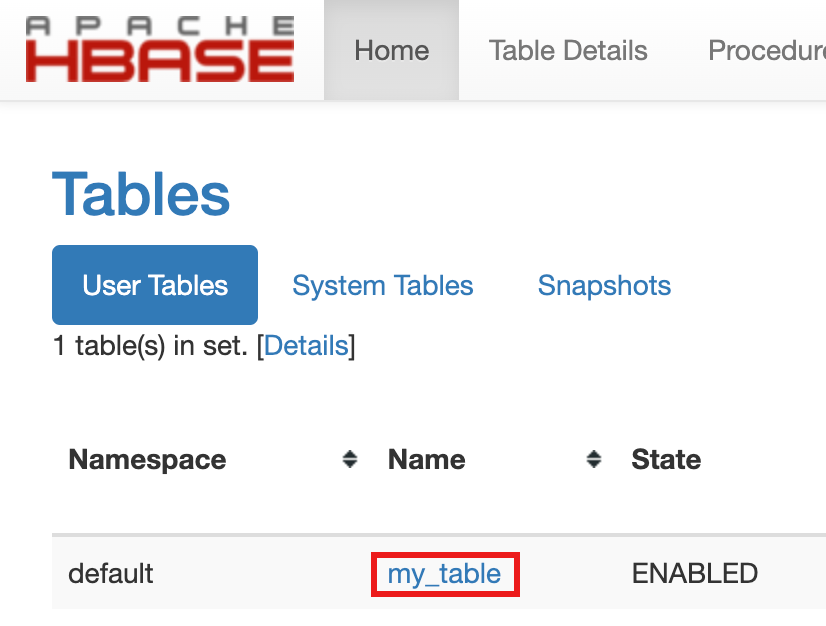
- 테이블 만들기를 확인하려면 Google Cloud 콘솔의 Google Cloud 콘솔 구성요소 게이트웨이 링크에서 HBase를 클릭하여 Apache HBase UI를 엽니다.
Cloud Shell 세션 터미널을 엽니다.
GitHub GoogleCloudDataproc/cloud-dataproc 저장소를 Cloud Shell 세션 터미널에 클론합니다.
git clone https://github.com/GoogleCloudDataproc/cloud-dataproc.git
cloud-dataproc/spark-hbase디렉터리로 변경합니다.cd cloud-dataproc/spark-hbase
user-name@cloudshell:~/cloud-dataproc/spark-hbase (project-id)$
Dataproc 작업을 제출합니다.
pom.xml파일에서 구성요소 버전을 설정합니다.- Dataproc 2.0.x 출시 버전 페이지에는 최신 버전 및 이전 4개의 이미지 2.0 하위 부 버전으로 설치된 Scala, Spark, HBase 구성요소 버전이 나열되어 있습니다.
- 2.0 이미지 버전 클러스터의 하위 부 버전을 찾으려면Google Cloud 콘솔의 클러스터 페이지에서 클러스터 이름을 클릭하여 클러스터 세부정보 페이지를 엽니다. 여기에 클러스터 이미지 버전이 나열되어 있습니다.
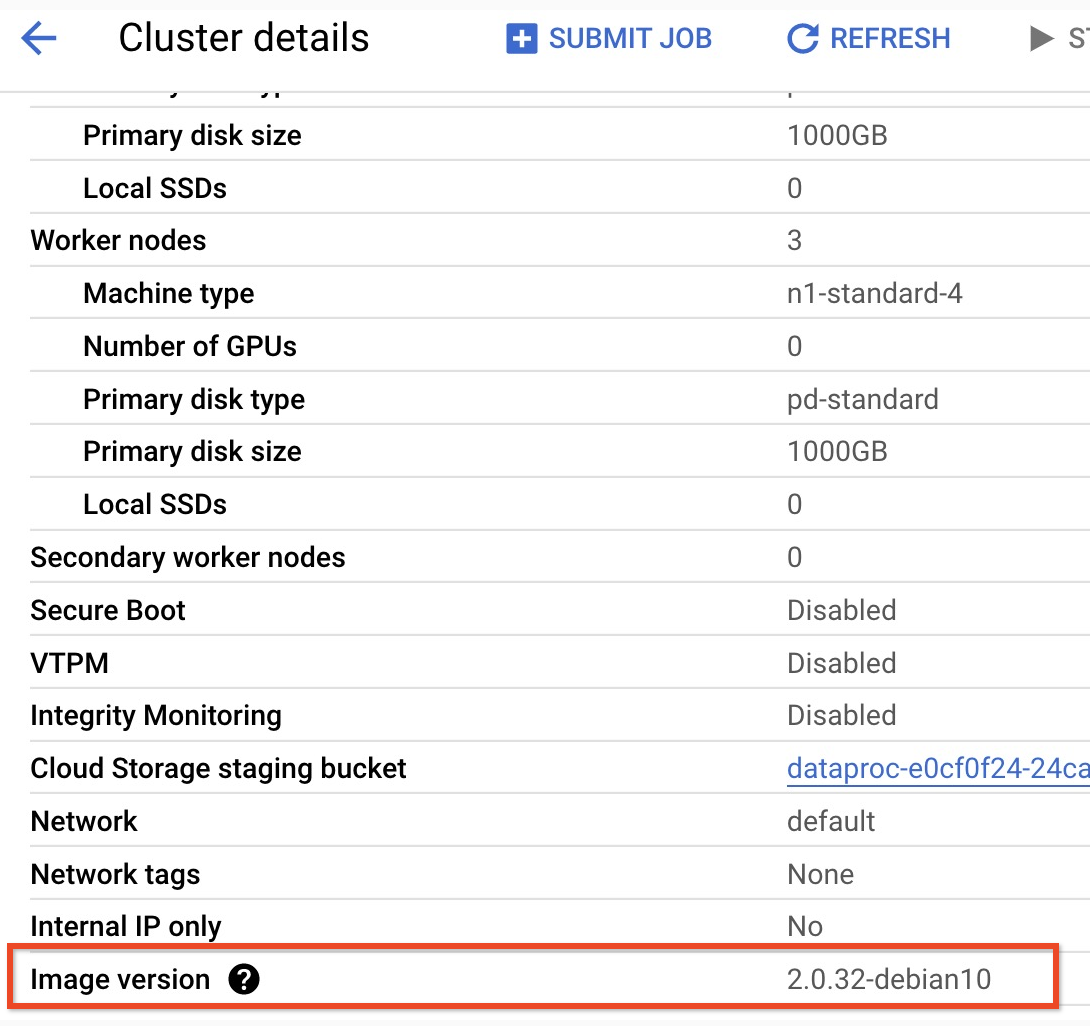
- 2.0 이미지 버전 클러스터의 하위 부 버전을 찾으려면Google Cloud 콘솔의 클러스터 페이지에서 클러스터 이름을 클릭하여 클러스터 세부정보 페이지를 엽니다. 여기에 클러스터 이미지 버전이 나열되어 있습니다.
- 또는 클러스터의 마스터 노드에서 SSH 세션 터미널에서 다음 명령어를 실행하여 구성요소 버전을 확인할 수 있습니다.
- 스칼라 버전을 확인합니다.
scala -version
- Spark 버전을 확인합니다(종료하려면 ctrl+D).
spark-shell
- HBase 버전을 확인합니다.
hbase version
- Maven
pom.xmldptj Spark, Scala, HBase 버전 종속 항목을 확인합니다.<properties> <scala.version>scala full version (for example, 2.12.14)</scala.version> <scala.main.version>scala main version (for example, 2.12)</scala.main.version> <spark.version>spark version (for example, 3.1.2)</spark.version> <hbase.client.version>hbase version (for example, 2.2.7)</hbase.client.version> <hbase-spark.version>1.0.0(the current Apache HBase Spark Connector version)> </properties>
hbase-spark.version은 현재 Spark HBase 커넥터 버전입니다. 이 버전 번호는 변경하지 않은 상태로 두세요.
- 스칼라 버전을 확인합니다.
- Cloud Shell 편집기에서
pom.xml파일을 수정하여 올바른 Scala, Spark, HBase 버전 번호를 삽입합니다. 수정이 완료되었으면 터미널 열기를 클릭하여 Cloud Shell 터미널 명령어로 돌아갑니다.cloudshell edit .
- Cloud Shell에서 자바 8로 전환합니다. 이 JDK 버전은 코드를 빌드하는 데 필요합니다. 플러그인 경고 메시지는 무시해도 됩니다.
sudo update-java-alternatives -s java-1.8.0-openjdk-amd64 && export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
- 자바 8 설치를 확인합니다.
java -version
openjdk version "1.8..."
- Dataproc 2.0.x 출시 버전 페이지에는 최신 버전 및 이전 4개의 이미지 2.0 하위 부 버전으로 설치된 Scala, Spark, HBase 구성요소 버전이 나열되어 있습니다.
jar파일을 빌드합니다.mvn clean package
.jar파일은/target하위 디렉터리에 배치됩니다(예:target/spark-hbase-1.0-SNAPSHOT.jar).작업을 제출합니다.
gcloud dataproc jobs submit spark \ --class=hbase.SparkHBaseMain \ --jars=target/filename.jar \ --region=cluster-region \ --cluster=cluster-name
--jars: 'target/' 뒤와 '.jar' 앞에.jar파일의 이름을 삽입합니다.- 클러스터를 만들 때Spark 드라이버 및 실행기 HBase 클래스 경로를 설정하지 않았으면 작업 제출 명령어에 다음
‑‑properties플래그를 포함하여 각 작업 제출에 따라 이를 설정해야 합니다.--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
Cloud Shell 세션 터미널 출력에서 HBase 테이블 출력을 확인합니다.
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
작업을 제출합니다.
gcloud dataproc jobs submit pyspark scripts/pyspark-hbase.py \ --region=cluster-region \ --cluster=cluster-name
- 클러스터를 만들 때Spark 드라이버 및 실행기 HBase 클래스 경로를 설정하지 않았으면 작업 제출 명령어에 다음
‑‑properties플래그를 포함하여 각 작업 제출에 따라 이를 설정해야 합니다.--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
- 클러스터를 만들 때Spark 드라이버 및 실행기 HBase 클래스 경로를 설정하지 않았으면 작업 제출 명령어에 다음
Cloud Shell 세션 터미널 출력에서 HBase 테이블 출력을 확인합니다.
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
- HBase 셸을 엽니다.
hbase shell
- 'my-table'을 스캔합니다.
scan 'my_table'
ROW COLUMN+CELL key1 column=cf:name, timestamp=1647364013561, value=foo key2 column=cf:name, timestamp=1647364012817, value=bar 2 row(s) Took 0.5009 seconds
삭제
튜토리얼을 완료한 후에는 만든 리소스를 삭제하여 할당량 사용을 중지하고 요금이 청구되지 않도록 할 수 있습니다. 다음 섹션은 이러한 리소스를 삭제하거나 사용 중지하는 방법을 설명합니다.
프로젝트 삭제
비용이 청구되지 않도록 하는 가장 쉬운 방법은 튜토리얼에서 만든 프로젝트를 삭제하는 것입니다.
프로젝트를 삭제하는 방법은 다음과 같습니다.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
클러스터 삭제
- 클러스터를 삭제하는 방법은 다음과 같습니다.
gcloud dataproc clusters delete cluster-name \ --region=${REGION}
Dataproc 클러스터 만들기
gcloud dataproc clusters create cluster-name \ --region=region \ --optional-components=HBASE,ZOOKEEPER \ --num-workers=3 \ --enable-component-gateway \ --image-version=2.0 \ --properties='spark:spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark:spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
커넥터 설치 확인
HBase 테이블 만들기
이전 단계에서 연 마스터 노드 SSH 세션 터미널에서 이 섹션에 나열된 명령어를 실행합니다.
Spark 코드 보기
Java
Python
코드 실행
Java
Python
HBase 테이블 스캔
커넥터 설치 확인에서 연 마스터 노드 SSH 세션 터미널에서 다음 명령어를 실행하여 HBase 테이블의 콘텐츠를 스캔할 수 있습니다.