spark-bigquery-connector 可搭配 Apache Spark 使用,在 BigQuery 中讀取和寫入資料。從 BigQuery 讀取資料時,連接器會使用 BigQuery Storage API。
本教學課程提供預先安裝的連接器可用性資訊,並說明如何為 Spark 作業提供特定連接器版本。程式碼範例會說明如何在 Spark 應用程式中使用 Spark BigQuery 連接器。
使用預先安裝的連接器
Spark BigQuery 連接器已預先安裝在 Dataproc 叢集上,只要使用 2.1 以上的映像檔版本建立叢集,即可在叢集上執行 Spark 工作。每個映像檔版本發布頁面都會列出預先安裝的連接器版本。舉例來說,「2.2.x 映像檔發布版本」頁面的「BigQuery 連接器」列會顯示最新 2.2 映像檔版本安裝的連接器版本。
讓 Spark 工作使用特定連接器版本
如要使用不同於 2.1 以上版本映像檔叢集預先安裝的連接器版本,或在 2.1 之前的映像檔叢集上安裝連接器,請按照本節的指示操作。
重要事項:spark-bigquery-connector 版本必須與 Dataproc 集群映像檔版本相容。請參閱「Connector to Dataproc Image Compatibility Matrix」。
2.1 以上版本叢集
建立 Dataproc 叢集時,如果使用 2.1 以上版本的映像檔,請將連結器版本指定為叢集中繼資料。
gcloud CLI 範例:
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --image-version=2.2 \ --metadata=SPARK_BQ_CONNECTOR_VERSION or SPARK_BQ_CONNECTOR_URL\ other flags
注意:
SPARK_BQ_CONNECTOR_VERSION:指定連接器版本。 GitHub 的 spark-bigquery-connector/releases 頁面會列出 Spark BigQuery 連接器版本。
範例:
--metadata=SPARK_BQ_CONNECTOR_VERSION=0.42.1
SPARK_BQ_CONNECTOR_URL:指定指向 Cloud Storage 中 JAR 的網址。您可以指定 GitHub 中「下載及使用連接器」連結欄列出的連接器網址,或是您放置自訂連接器 JAR 檔案的 Cloud Storage 位置路徑。
範例:
--metadata=SPARK_BQ_CONNECTOR_URL=gs://spark-lib/bigquery/spark-3.5-bigquery-0.42.1.jar --metadata=SPARK_BQ_CONNECTOR_URL=gs://PATH_TO_CUSTOM_JAR
2.0 和較舊的映像檔版本叢集
您可以透過下列其中一種方式,讓應用程式使用 Spark BigQuery 連接器:
建立叢集時,使用 Dataproc 連接器初始化動作,在每個節點的 Spark JAR 目錄中安裝 spark-bigquery-connector。
使用 Google Cloud 主控台、gcloud CLI 或 Dataproc API 將工作提交至叢集時,請提供連結器 JAR 網址。
如何在 2.0 之前的映像檔版本叢集上執行 Spark 工作時指定連接器 JAR 檔
- 在下列 URI 字串中,代入 Scala 和連接器版本資訊,指定連接器 JAR:
gs://spark-lib/bigquery/spark-bigquery-with-dependencies_SCALA_VERSION-CONNECTOR_VERSION.jar
- 搭配 Dataproc 映像檔版本
1.5+使用 Scala2.12gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-CONNECTOR_VERSION.jar
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-0.23.2.jar \ -- job args
- 搭配 Dataproc 映像檔版本
1.4和更早版本使用 Scala2.11:gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.11-CONNECTOR_VERSION.jar
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.11-0.23.2.jar \ -- job-args
- 在下列 URI 字串中,代入 Scala 和連接器版本資訊,指定連接器 JAR:
在 Scala 或 Java Spark 應用程式中加入連接器 JAR 做為依附元件 (請參閱「針對連接器進行編譯」)。
計算費用
在本文件中,您會使用下列 Google Cloud的計費元件:
- Dataproc
- BigQuery
- Cloud Storage
如要根據預測用量估算費用,請使用 Pricing Calculator。
從 BigQuery 讀取資料,以及將資料寫入 BigQuery
這個範例會使用標準資料來源 API,將 BigQuery 中的資料讀取到 Spark DataFrame,以執行字數計算。
為了在 BigQuery 中寫入資料,連接器會先將所有資料緩衝處理至 Cloud Storage 臨時資料表,然後透過單一作業將所有資料複製到 BigQuery。BigQuery 載入作業成功後,以及 Spark 應用程式終止時,連接器會嘗試刪除暫時檔案。如果工作失敗,請移除任何臨時的 Cloud Storage 檔案。臨時 BigQuery 檔案通常位於 gs://[bucket]/.spark-bigquery-[jobid]-[UUID]。
設定帳單
根據預設,系統會向與憑證或服務帳戶相關聯的專案收取 API 使用費用。如要向其他專案收費,請設定下列設定:spark.conf.set("parentProject", "<BILLED-GCP-PROJECT>")。
也可以新增至讀取或寫入作業,如下所示:
.option("parentProject", "<BILLED-GCP-PROJECT>")。
執行程式碼
執行這個範例之前,請先建立資料集並命名為「wordcount_dataset」,然後在程式碼中將輸出資料集變更為Google Cloud 專案中的現有 BigQuery 資料集。
使用 bq 指令建立 wordcount_dataset:
bq mk wordcount_dataset
使用 Google Cloud CLI 指令建立 Cloud Storage 值區,用於匯出至 BigQuery:
gcloud storage buckets create gs://[bucket]
Scala
- 檢查程式碼,並將 [bucket] 預留位置替換為您稍早建立的 Cloud Storage bucket。
/* * Remove comment if you are not running in spark-shell. * import org.apache.spark.sql.SparkSession val spark = SparkSession.builder() .appName("spark-bigquery-demo") .getOrCreate() */ // Use the Cloud Storage bucket for temporary BigQuery export data used // by the connector. val bucket = "[bucket]" spark.conf.set("temporaryGcsBucket", bucket) // Load data in from BigQuery. See // https://github.com/GoogleCloudDataproc/spark-bigquery-connector/tree/0.17.3#properties // for option information. val wordsDF = spark.read.bigquery("bigquery-public-data:samples.shakespeare") .cache() wordsDF.createOrReplaceTempView("words") // Perform word count. val wordCountDF = spark.sql( "SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word") wordCountDF.show() wordCountDF.printSchema() // Saving the data to BigQuery. (wordCountDF.write.format("bigquery") .save("wordcount_dataset.wordcount_output"))
- 在叢集中執行程式碼
- 使用 SSH 連線至 Dataproc 叢集的主要節點
- 使用預先安裝的
vi、vim或nano文字編輯器建立wordcount.scala,然後貼上從 Scala 程式碼清單中複製而來的 Scala 程式碼nano wordcount.scala
- 啟動
spark-shellREPL。$ spark-shell --jars=gs://spark-lib/bigquery/spark-bigquery-latest.jar ... Using Scala version ... Type in expressions to have them evaluated. Type :help for more information. ... Spark context available as sc. ... SQL context available as sqlContext. scala>
- 使用
:load wordcount.scala指令執行 wordcount.scala,以建立 BigQuerywordcount_output表格。輸出清單會顯示 wordcount 輸出中的 20 行內容。:load wordcount.scala ... +---------+----------+ | word|word_count| +---------+----------+ | XVII| 2| | spoil| 28| | Drink| 7| |forgetful| 5| | Cannot| 46| | cures| 10| | harder| 13| | tresses| 3| | few| 62| | steel'd| 5| | tripping| 7| | travel| 35| | ransom| 55| | hope| 366| | By| 816| | some| 1169| | those| 508| | still| 567| | art| 893| | feign| 10| +---------+----------+ only showing top 20 rows root |-- word: string (nullable = false) |-- word_count: long (nullable = true)
如要預覽輸出資料表,請開啟BigQuery頁面,選取wordcount_output資料表,然後按一下「預覽」。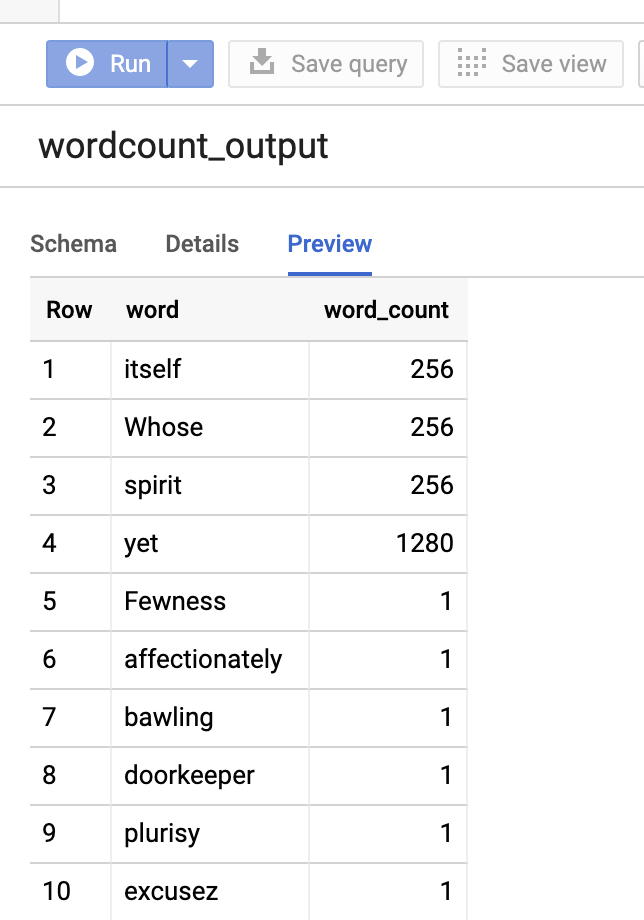
 >
> PySpark
- 檢查程式碼,並將 [bucket] 預留位置替換為您稍早建立的 Cloud Storage bucket。
#!/usr/bin/env python """BigQuery I/O PySpark example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-bigquery-demo') \ .getOrCreate() # Use the Cloud Storage bucket for temporary BigQuery export data used # by the connector. bucket = "[bucket]" spark.conf.set('temporaryGcsBucket', bucket) # Load data from BigQuery. words = spark.read.format('bigquery') \ .load('bigquery-public-data:samples.shakespeare') \ words.createOrReplaceTempView('words') # Perform word count. word_count = spark.sql( 'SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word') word_count.show() word_count.printSchema() # Save the data to BigQuery word_count.write.format('bigquery') \ .save('wordcount_dataset.wordcount_output')
- 在叢集上執行程式碼
- 使用 SSH 連線至 Dataproc 叢集主要節點
- 使用預先安裝的
vi、vim或nano文字編輯器建立wordcount.py,然後貼上從 PySpark 程式碼清單複製而來的 PySpark 程式碼nano wordcount.py
- 使用
spark-submit執行 wordcount,以建立 BigQuerywordcount_output表格。輸出清單會顯示 wordcount 輸出中的 20 行內容。spark-submit --jars gs://spark-lib/bigquery/spark-bigquery-latest.jar wordcount.py ... +---------+----------+ | word|word_count| +---------+----------+ | XVII| 2| | spoil| 28| | Drink| 7| |forgetful| 5| | Cannot| 46| | cures| 10| | harder| 13| | tresses| 3| | few| 62| | steel'd| 5| | tripping| 7| | travel| 35| | ransom| 55| | hope| 366| | By| 816| | some| 1169| | those| 508| | still| 567| | art| 893| | feign| 10| +---------+----------+ only showing top 20 rows root |-- word: string (nullable = false) |-- word_count: long (nullable = true)
如要預覽輸出資料表,請開啟BigQuery頁面,選取wordcount_output資料表,然後按一下「預覽」。
疑難排解提示
您可以檢查 Cloud Logging 和 BigQuery Jobs Explorer 中的工作記錄,排解使用 BigQuery 連接器的 Spark 工作問題。
Dataproc 驅動程式記錄包含
BigQueryClient項目,其中含有 BigQuery 中繼資料,包括jobId:ClassNotFoundException
INFO BigQueryClient:.. jobId: JobId{project=PROJECT_ID, job=JOB_ID, location=LOCATION} BigQuery 工作包含
Dataproc_job_id和Dataproc_job_uuid標籤:- 記錄:
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.labels.dataproc_job_id="JOB_ID" protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.labels.dataproc_job_uuid="JOB_UUID" protoPayload.serviceData.jobCompletedEvent.job.jobName.jobId="JOB_NAME"
- BigQuery 工作探索器:按一下工作 ID,即可在「工作資訊」的「標籤」下方查看工作詳細資料。
- 記錄:
後續步驟
- 請參閱「BigQuery Storage 和 Spark SQL - Python」。
- 瞭解如何針對外部資料來源建立資料表定義檔。
- 瞭解如何查詢外部分區資料。
- 請參閱「Spark 工作調整提示」。