spark-bigquery-connector를 Apache Spark와 함께 사용하여 BigQuery에서 데이터를 읽고 쓸 수 있습니다. 이 커넥터는 BigQuery에서 데이터를 읽을 때 BigQuery Storage API를 활용합니다.
이 튜토리얼에서는 사전 설치된 커넥터의 사용 가능 여부에 관한 정보를 제공하고 Spark 작업에 특정 커넥터 버전을 사용할 수 있도록 하는 방법을 보여줍니다. 예시 코드는 Spark 애플리케이션 내에서 Spark BigQuery 커넥터를 사용하는 방법을 보여줍니다.
사전 설치된 커넥터 사용
Spark BigQuery 커넥터는 이미지 버전 2.1 이상으로 생성된 Dataproc 클러스터에서 실행되는 Spark 작업에 사전 설치되어 있으며 이러한 작업에서 사용할 수 있습니다. 사전 설치된 커넥터 버전은 각 이미지 버전 출시 페이지에 나열됩니다. 예를 들어 2.2.x 이미지 출시 버전 페이지의 BigQuery 커넥터 행에는 최신 2.2 이미지 출시에 설치된 커넥터 버전이 표시됩니다.
Spark 작업에서 특정 커넥터 버전을 사용할 수 있도록 설정
2.1 이상 이미지 버전 클러스터에서 사전 설치된 버전과 다른 커넥터 버전을 사용하거나 2.1 이전 이미지 버전 클러스터에 커넥터를 설치하려면 이 섹션의 안내를 따르세요.
중요: spark-bigquery-connector 버전은 Dataproc 클러스터 이미지 버전과 호환되어야 합니다. 커넥터 및 Dataproc 이미지 호환성 매트릭스를 참고하세요.
2.1 이상 이미지 버전 클러스터
2.1 이상 이미지 버전으로 Dataproc 클러스터를 만들 때 커넥터 버전을 클러스터 메타데이터로 지정합니다.
gcloud CLI 예시:
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --image-version=2.2 \ --metadata=SPARK_BQ_CONNECTOR_VERSION or SPARK_BQ_CONNECTOR_URL\ other flags
참고:
SPARK_BQ_CONNECTOR_VERSION: 커넥터 버전을 지정합니다. Spark BigQuery 커넥터 버전은 GitHub의 spark-bigquery-connector/releases 페이지에 나열되어 있습니다.
예시:
--metadata=SPARK_BQ_CONNECTOR_VERSION=0.42.1
SPARK_BQ_CONNECTOR_URL: Cloud Storage의 jar을 가리키는 URL을 지정합니다. GitHub의 커넥터 다운로드 및 사용에 있는 링크 열에 나열된 커넥터의 URL 또는 커스텀 커넥터 jar을 배치한 Cloud Storage 위치의 경로를 지정할 수 있습니다.
예시:
--metadata=SPARK_BQ_CONNECTOR_URL=gs://spark-lib/bigquery/spark-3.5-bigquery-0.42.1.jar --metadata=SPARK_BQ_CONNECTOR_URL=gs://PATH_TO_CUSTOM_JAR
2.0 이하 이미지 버전 클러스터
다음 방법 중 하나를 사용하여 애플리케이션에서 Spark BigQuery 커넥터를 사용할 수 있습니다.
클러스터를 만들 때 Dataproc 커넥터 초기화 작업을 사용하여 모든 노드의 Spark jars 디렉터리에 spark-bigquery-connector를 설치합니다.
Google Cloud 콘솔, gcloud CLI 또는 Dataproc API를 사용하여 클러스터에 작업을 제출할 때 커넥터 jar URL을 제공합니다.
2.0 이전 이미지 버전 클러스터에서 Spark 작업을 실행할 때 커넥터 jar을 지정하는 방법
- 다음 URI 문자열에서 Scala 및 커넥터 버전 정보를 대체하여 커넥터 jar을 지정합니다.
gs://spark-lib/bigquery/spark-bigquery-with-dependencies_SCALA_VERSION-CONNECTOR_VERSION.jar
- Dataproc 이미지 버전
1.5+와 함께 Scala2.12를 사용합니다.gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-CONNECTOR_VERSION.jar
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-0.23.2.jar \ -- job args
- Dataproc 이미지 버전
1.4이하에서는 Scala2.11을 사용합니다.gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.11-CONNECTOR_VERSION.jar
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.11-0.23.2.jar \ -- job-args
- 다음 URI 문자열에서 Scala 및 커넥터 버전 정보를 대체하여 커넥터 jar을 지정합니다.
Scala 또는 Java Spark 애플리케이션에 있는 커넥터 jar를 종속 항목으로 포함합니다(커넥터에 대한 컴파일 참조).
비용 계산
이 문서에서는 비용이 청구될 수 있는 Google Cloud구성요소( )를 사용합니다.
- Dataproc
- BigQuery
- Cloud Storage
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용합니다.
BigQuery에서 데이터 읽기 및 쓰기
이 예에서는 BigQuery에서 Spark DataFrame으로 데이터를 읽어 들이고 표준 데이터 소스 API를 사용하여 단어 수를 계산합니다.
커넥터는 먼저 모든 데이터를 Cloud Storage 임시 테이블에 버퍼링하여 데이터를 BigQuery에 씁니다. 그런 다음 한 번의 작업으로 모든 데이터를 BigQuery에 복사합니다. 커넥터는 BigQuery 로드 작업이 성공하면 임시 파일을 삭제하고 Spark 애플리케이션이 종료될 때 다시 한 번 삭제합니다.
작업이 실패하면 남아 있는 임시 Cloud Storage 파일을 모두 삭제합니다. 일반적으로 임시 BigQuery 파일은 gs://[bucket]/.spark-bigquery-[jobid]-[UUID]에 있습니다.
결제 구성
기본적으로 사용자 인증 정보나 서비스 계정과 연결된 프로젝트에는 API 사용 요금이 청구됩니다. 다른 프로젝트에 요금을 청구하려면 spark.conf.set("parentProject", "<BILLED-GCP-PROJECT>") 구성을 설정합니다.
.option("parentProject", "<BILLED-GCP-PROJECT>")처럼 읽기 또는 쓰기 작업에 추가할 수도 있습니다.
코드 실행
이 예시를 실행하기 전에 'wordcount_dataset'라는 데이터 세트를 만들거나 코드의 출력 데이터 세트를Google Cloud 프로젝트의 기존 BigQuery 데이터 세트로 변경합니다.
bq 명령어를 사용하여 wordcount_dataset를 만듭니다.
bq mk wordcount_dataset
Google Cloud CLI 명령어를 사용하여 BigQuery로 내보내는 데 사용할 Cloud Storage 버킷을 만듭니다.
gcloud storage buckets create gs://[bucket]
Scala
- 코드를 검토하고 이전에 만든 Cloud Storage 버킷으로 [bucket] 자리표시자를 바꿉니다.
/* * Remove comment if you are not running in spark-shell. * import org.apache.spark.sql.SparkSession val spark = SparkSession.builder() .appName("spark-bigquery-demo") .getOrCreate() */ // Use the Cloud Storage bucket for temporary BigQuery export data used // by the connector. val bucket = "[bucket]" spark.conf.set("temporaryGcsBucket", bucket) // Load data in from BigQuery. See // https://github.com/GoogleCloudDataproc/spark-bigquery-connector/tree/0.17.3#properties // for option information. val wordsDF = spark.read.bigquery("bigquery-public-data:samples.shakespeare") .cache() wordsDF.createOrReplaceTempView("words") // Perform word count. val wordCountDF = spark.sql( "SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word") wordCountDF.show() wordCountDF.printSchema() // Saving the data to BigQuery. (wordCountDF.write.format("bigquery") .save("wordcount_dataset.wordcount_output"))
- 클러스터에서 코드 실행
- SSH를 사용하여 Dataproc 클러스터 마스터 노드에 연결합니다.
- Google Cloud 콘솔에서 Dataproc 클러스터 페이지로 이동한 다음 클러스터 이름을 클릭합니다.
- >클러스터 세부정보 페이지에서 VM 인스턴스 탭을 선택합니다. 그런 다음 클러스터 마스터 노드 이름 오른쪽에 있는
SSH를 클릭합니다 >
마스터 노드의 홈 디렉터리에서 브라우저 창이 열립니다Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Google Cloud 콘솔에서 Dataproc 클러스터 페이지로 이동한 다음 클러스터 이름을 클릭합니다.
- 사전 설치된
vi,vim,nano텍스트 편집기로wordcount.scala을 만든 다음 Scala 코드 목록에서 Scala 코드에 붙여넣습니다.nano wordcount.scala
spark-shellREPL을 실행합니다.$ spark-shell --jars=gs://spark-lib/bigquery/spark-bigquery-latest.jar ... Using Scala version ... Type in expressions to have them evaluated. Type :help for more information. ... Spark context available as sc. ... SQL context available as sqlContext. scala>
:load wordcount.scala명령으로 wordcount.scala를 실행하여 BigQuerywordcount_output테이블을 만듭니다. wordcount 출력의 20줄이 출력 목록에 표시됩니다.:load wordcount.scala ... +---------+----------+ | word|word_count| +---------+----------+ | XVII| 2| | spoil| 28| | Drink| 7| |forgetful| 5| | Cannot| 46| | cures| 10| | harder| 13| | tresses| 3| | few| 62| | steel'd| 5| | tripping| 7| | travel| 35| | ransom| 55| | hope| 366| | By| 816| | some| 1169| | those| 508| | still| 567| | art| 893| | feign| 10| +---------+----------+ only showing top 20 rows root |-- word: string (nullable = false) |-- word_count: long (nullable = true)
출력 테이블을 미리 보려면BigQuery페이지를 열고wordcount_output테이블을 선택한 다음 미리보기를 클릭하세요.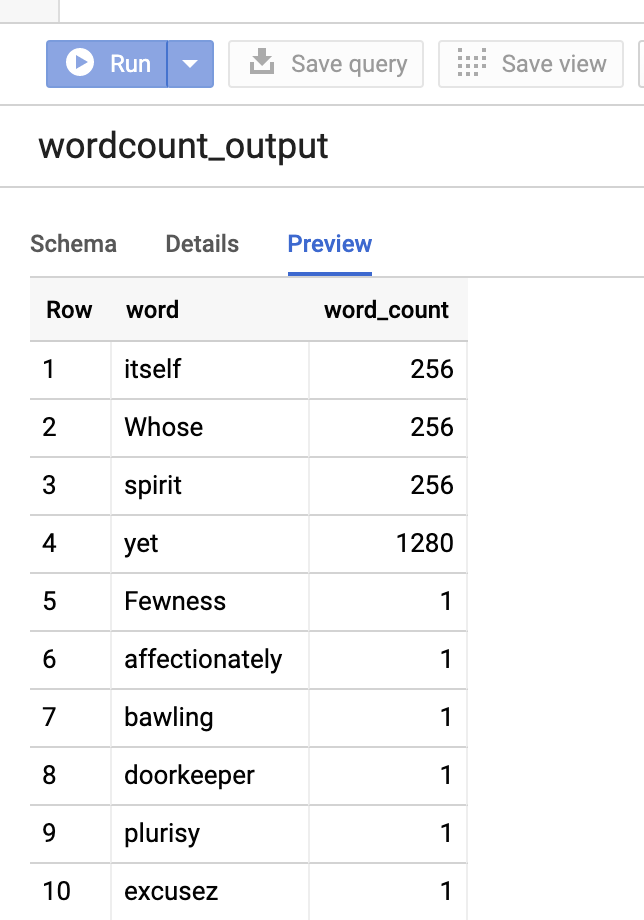
- SSH를 사용하여 Dataproc 클러스터 마스터 노드에 연결합니다.
PySpark
- 코드를 검토하고 이전에 만든 Cloud Storage 버킷으로 [bucket] 자리표시자를 바꿉니다.
#!/usr/bin/env python """BigQuery I/O PySpark example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-bigquery-demo') \ .getOrCreate() # Use the Cloud Storage bucket for temporary BigQuery export data used # by the connector. bucket = "[bucket]" spark.conf.set('temporaryGcsBucket', bucket) # Load data from BigQuery. words = spark.read.format('bigquery') \ .load('bigquery-public-data:samples.shakespeare') \ words.createOrReplaceTempView('words') # Perform word count. word_count = spark.sql( 'SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word') word_count.show() word_count.printSchema() # Save the data to BigQuery word_count.write.format('bigquery') \ .save('wordcount_dataset.wordcount_output')
- 클러스터에서 코드 실행
- SSH를 사용하여 Dataproc 클러스터 마스터 노드에 연결합니다.
- Google Cloud 콘솔에서 Dataproc 클러스터 페이지로 이동한 다음 클러스터 이름을 클릭합니다.
- 클러스터 세부정보 페이지에서 VM 인스턴스 탭을 선택합니다. 그런 다음 클러스터 마스터 노드 이름 오른쪽에 있는
SSH를 클릭합니다
마스터 노드의 홈 디렉터리에서 브라우저 창이 열립니다Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Google Cloud 콘솔에서 Dataproc 클러스터 페이지로 이동한 다음 클러스터 이름을 클릭합니다.
- 사전 설치된
vi,vim,nano텍스트 편집기로wordcount.py을 만든 다음 PySpark 코드 목록에서 PySpark 코드를 붙여넣습니다.nano wordcount.py
spark-submit로 wordcount를 실행하여 BigQuerywordcount_output테이블을 만듭니다. wordcount 출력의 20줄이 출력 목록에 표시됩니다.spark-submit --jars gs://spark-lib/bigquery/spark-bigquery-latest.jar wordcount.py ... +---------+----------+ | word|word_count| +---------+----------+ | XVII| 2| | spoil| 28| | Drink| 7| |forgetful| 5| | Cannot| 46| | cures| 10| | harder| 13| | tresses| 3| | few| 62| | steel'd| 5| | tripping| 7| | travel| 35| | ransom| 55| | hope| 366| | By| 816| | some| 1169| | those| 508| | still| 567| | art| 893| | feign| 10| +---------+----------+ only showing top 20 rows root |-- word: string (nullable = false) |-- word_count: long (nullable = true)
출력 테이블을 미리 보려면BigQuery페이지를 열고wordcount_output테이블을 선택한 다음 미리보기를 클릭하세요.
- SSH를 사용하여 Dataproc 클러스터 마스터 노드에 연결합니다.
문제해결 도움말
Cloud Logging 및 BigQuery 작업 탐색기에서 작업 로그를 검사하여 BigQuery 커넥터를 사용하는 Spark 작업의 문제를 해결할 수 있습니다.
Dataproc 드라이버 로그에는
jobId이 포함된 BigQuery 메타데이터가 있는BigQueryClient항목이 포함됩니다.ClassNotFoundException
INFO BigQueryClient:.. jobId: JobId{project=PROJECT_ID, job=JOB_ID, location=LOCATION} BigQuery 작업에는
Dataproc_job_id및Dataproc_job_uuid라벨이 포함됩니다.- 로깅:
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.labels.dataproc_job_id="JOB_ID" protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.labels.dataproc_job_uuid="JOB_UUID" protoPayload.serviceData.jobCompletedEvent.job.jobName.jobId="JOB_NAME"
- BigQuery 작업 탐색기: 작업 ID를 클릭하여 작업 정보의 라벨에서 작업 세부정보를 확인합니다.
- 로깅:
다음 단계
- BigQuery 스토리지 및 Spark SQL - Python 확인하기
- 외부 데이터 소스용 테이블 정의 파일을 만드는 방법 알아보기
- 외부에서 파티션을 나눈 데이터 쿼리 방법 알아보기
- Spark 작업 미세 조정 팁 참조하기