您可以将 spark-bigquery-connector 与 Apache Spark 搭配使用,以从 BigQuery 中读取数据以及将数据写入其中。该连接器在从 BigQuery 读取数据时利用 BigQuery Storage API。
本教程介绍了预安装连接器的可用性,并展示了如何让 Spark 作业使用特定版本的连接器。示例代码展示了如何在 Spark 应用中使用 Spark BigQuery 连接器。
使用预安装的连接器
Spark BigQuery 连接器预安装在使用 2.1 及更高版本映像创建的 Dataproc 集群上,并可供这些集群上的 Spark 作业使用。预安装的连接器版本会列在每个映像版本发布页面上。例如,2.2.x 映像发布版本页面上的 BigQuery 连接器行显示了最新 2.2 映像版本上安装的连接器版本。
让 Spark 作业使用特定版本的连接器
如果您想使用与 2.1 或更高版本映像集群上预安装版本不同的连接器版本,或者想在 2.1 之前的映像版本集群上安装连接器,请按照本部分中的说明操作。
重要提示:spark-bigquery-connector 版本必须与 Dataproc 集群映像版本兼容。请参阅连接器与 Dataproc 映像兼容性矩阵。
2.1 及更高版本的映像版本集群
使用 2.1 或更高版本的映像创建 Dataproc 集群时,将连接器版本指定为集群元数据。
gcloud CLI 示例:
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --image-version=2.2 \ --metadata=SPARK_BQ_CONNECTOR_VERSION or SPARK_BQ_CONNECTOR_URL\ other flags
注意:
SPARK_BQ_CONNECTOR_VERSION:指定连接器版本。GitHub 中的 spark-bigquery-connector/releases 页面上列出了 Spark BigQuery 连接器版本。
示例:
--metadata=SPARK_BQ_CONNECTOR_VERSION=0.42.1
SPARK_BQ_CONNECTOR_URL:指定指向 Cloud Storage 中的 jar 文件的网址。您可以指定 GitHub 中下载和使用连接器页面链接列中列出的连接器的网址,也可以指定您放置自定义连接器 jar 文件的 Cloud Storage 位置的路径。
示例:
--metadata=SPARK_BQ_CONNECTOR_URL=gs://spark-lib/bigquery/spark-3.5-bigquery-0.42.1.jar --metadata=SPARK_BQ_CONNECTOR_URL=gs://PATH_TO_CUSTOM_JAR
2.0 及更早版本的映像版本集群
您可以通过以下任意一种方式将 Spark BigQuery 连接器提供给您的应用:
在创建集群时,使用 Dataproc 连接器初始化操作,在每个节点的 Spark jars 目录中安装 spark-bigquery-connector。
使用 Google API 控制台、gcloud CLI 或 Dataproc API 将作业提交到集群时,请提供连接器 jar 文件网址。
如何在 2.0 之前的映像版本集群上指定连接器 jar 来运行 Spark 作业
- 通过在以下 URI 字符串中替换 Scala 和连接器版本信息来指定连接器 jar:
gs://spark-lib/bigquery/spark-bigquery-with-dependencies_SCALA_VERSION-CONNECTOR_VERSION.jar
- 将 Scala
2.12与 Dataproc 映像版本1.5+搭配使用gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-CONNECTOR_VERSION.jar
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-0.23.2.jar \ -- job args
- 将 Scala
2.11与 Dataproc 映像版本1.4及更低版本搭配使用:gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.11-CONNECTOR_VERSION.jar
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.11-0.23.2.jar \ -- job-args
- 通过在以下 URI 字符串中替换 Scala 和连接器版本信息来指定连接器 jar:
将连接器 jar 作为依赖项添加到 Scala 或 Java Spark 应用中(请参阅针对连接器进行编译)。
计算费用
在本文档中,您将使用 Google Cloud的以下收费组件:
- Dataproc
- BigQuery
- Cloud Storage
如需根据您的预计使用量来估算费用,请使用价格计算器。
从 BigQuery 读取并写入数据
此示例展示如何将 BigQuery 中的数据读取到 Spark DataFrame 中,以使用标准数据源 API执行字数统计操作。
连接器通过先将所有数据缓冲到 Cloud Storage 临时表中,再将数据写入 BigQuery。然后,它通过一次操作将所有数据复制到 BigQuery。在 BigQuery 加载操作成功并且当 Spark 应用终止时再次成功之后,连接器便会尝试删除临时文件。如果作业失败,请移除任何剩余的临时 Cloud Storage 文件。通常,临时 BigQuery 文件位于 gs://[bucket]/.spark-bigquery-[jobid]-[UUID] 中。
配置结算功能
默认情况下,与凭证或服务账号关联的项目将为 API 使用支付费用。要对其他项目计费,请设置以下配置:spark.conf.set("parentProject", "<BILLED-GCP-PROJECT>")。
还可以将其添加到读取或写入操作,如下所示:.option("parentProject", "<BILLED-GCP-PROJECT>")。
运行代码
在运行此示例之前,创建名为“wordcount_dataset”的数据集,或将代码中的输出数据集更改为您Google Cloud 项目中的现有 BigQuery 数据集。
使用 bq 命令创建 wordcount_dataset:
bq mk wordcount_dataset
使用 Google Cloud CLI 命令创建 Cloud Storage 存储桶,并将其用于导出到 BigQuery:
gcloud storage buckets create gs://[bucket]
Scala
- 检查代码,并将 [bucket] 占位符替换为您之前创建的 Cloud Storage 存储桶。
/* * Remove comment if you are not running in spark-shell. * import org.apache.spark.sql.SparkSession val spark = SparkSession.builder() .appName("spark-bigquery-demo") .getOrCreate() */ // Use the Cloud Storage bucket for temporary BigQuery export data used // by the connector. val bucket = "[bucket]" spark.conf.set("temporaryGcsBucket", bucket) // Load data in from BigQuery. See // https://github.com/GoogleCloudDataproc/spark-bigquery-connector/tree/0.17.3#properties // for option information. val wordsDF = spark.read.bigquery("bigquery-public-data:samples.shakespeare") .cache() wordsDF.createOrReplaceTempView("words") // Perform word count. val wordCountDF = spark.sql( "SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word") wordCountDF.show() wordCountDF.printSchema() // Saving the data to BigQuery. (wordCountDF.write.format("bigquery") .save("wordcount_dataset.wordcount_output"))
- 在集群上运行代码
- 使用 SSH 连接到 Dataproc 集群主节点
- 在 API 控制台中前往 Dataproc 集群页面,然后点击集群的名称
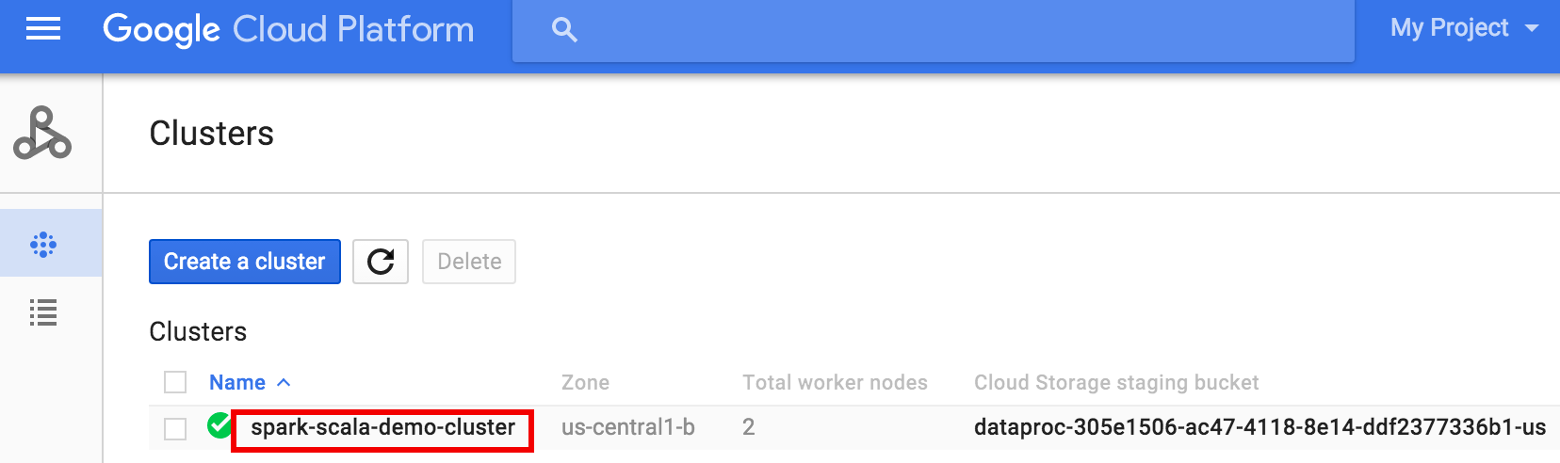
- 在 >集群详情页面上,选择“虚拟机实例”标签页。然后,点击集群主节点名称右侧的
SSH>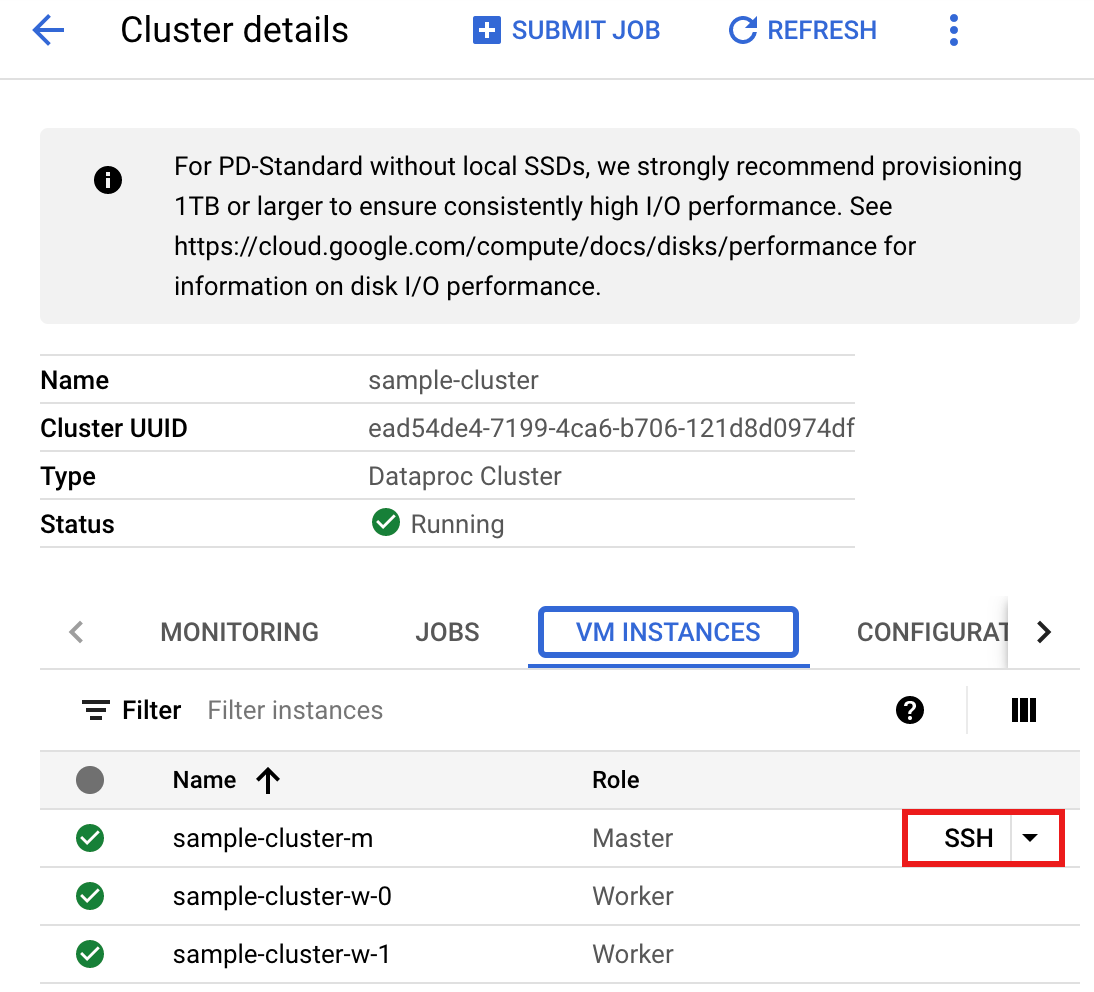
此时会在主节点上的主目录打开一个浏览器窗口Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- 在 API 控制台中前往 Dataproc 集群页面,然后点击集群的名称
- 使用预装的
vi、vim或nano文本编辑器创建wordcount.scala,然后粘贴 Scala 代码列表中的 Scala 代码nano wordcount.scala
- 启动
spark-shellREPL。$ spark-shell --jars=gs://spark-lib/bigquery/spark-bigquery-latest.jar ... Using Scala version ... Type in expressions to have them evaluated. Type :help for more information. ... Spark context available as sc. ... SQL context available as sqlContext. scala>
- 运行 wordcount.scala 并使用
:load wordcount.scala命令创建 BigQuerywordcount_output表。输出列表将显示来自 wordcount 输出的 20 行内容。:load wordcount.scala ... +---------+----------+ | word|word_count| +---------+----------+ | XVII| 2| | spoil| 28| | Drink| 7| |forgetful| 5| | Cannot| 46| | cures| 10| | harder| 13| | tresses| 3| | few| 62| | steel'd| 5| | tripping| 7| | travel| 35| | ransom| 55| | hope| 366| | By| 816| | some| 1169| | those| 508| | still| 567| | art| 893| | feign| 10| +---------+----------+ only showing top 20 rows root |-- word: string (nullable = false) |-- word_count: long (nullable = true)
要预览输出表,请打开BigQuery页面,选择wordcount_output表,然后点击预览。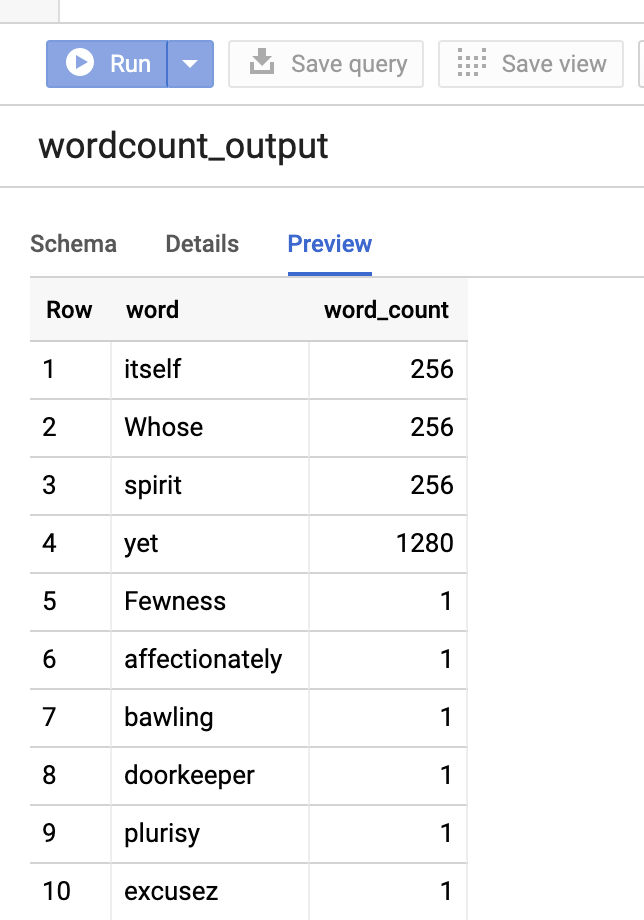
- 使用 SSH 连接到 Dataproc 集群主节点
PySpark
- 检查代码,并将 [bucket] 占位符替换为您之前创建的 Cloud Storage 存储桶。
#!/usr/bin/env python """BigQuery I/O PySpark example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-bigquery-demo') \ .getOrCreate() # Use the Cloud Storage bucket for temporary BigQuery export data used # by the connector. bucket = "[bucket]" spark.conf.set('temporaryGcsBucket', bucket) # Load data from BigQuery. words = spark.read.format('bigquery') \ .load('bigquery-public-data:samples.shakespeare') \ words.createOrReplaceTempView('words') # Perform word count. word_count = spark.sql( 'SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word') word_count.show() word_count.printSchema() # Save the data to BigQuery word_count.write.format('bigquery') \ .save('wordcount_dataset.wordcount_output')
- 在集群上运行代码
- 使用 SSH 连接到 Dataproc 集群主节点
- 在 API 控制台中前往 Dataproc 集群页面,然后点击集群的名称
- 在集群详情页面上,选择“虚拟机实例”标签页。然后,点击集群主节点名称右侧的
SSH
此时会在主节点上的主目录打开一个浏览器窗口Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- 在 API 控制台中前往 Dataproc 集群页面,然后点击集群的名称
- 使用预安装的
vi、vim或nano文本编辑器创建wordcount.py,然后粘贴 PySpark 代码列表中的 PySpark 代码nano wordcount.py
- 使用
spark-submit运行 wordcount 以创建 BigQuerywordcount_output表。输出列表将显示来自 wordcount 输出的 20 行内容。spark-submit --jars gs://spark-lib/bigquery/spark-bigquery-latest.jar wordcount.py ... +---------+----------+ | word|word_count| +---------+----------+ | XVII| 2| | spoil| 28| | Drink| 7| |forgetful| 5| | Cannot| 46| | cures| 10| | harder| 13| | tresses| 3| | few| 62| | steel'd| 5| | tripping| 7| | travel| 35| | ransom| 55| | hope| 366| | By| 816| | some| 1169| | those| 508| | still| 567| | art| 893| | feign| 10| +---------+----------+ only showing top 20 rows root |-- word: string (nullable = false) |-- word_count: long (nullable = true)
要预览输出表,请打开BigQuery页面,选择wordcount_output表,然后点击预览。
- 使用 SSH 连接到 Dataproc 集群主节点
问题排查提示
您可以检查 Cloud Logging 和 BigQuery 作业探索器中的作业日志,以排查使用 BigQuery 连接器的 Spark 作业的问题。
Dataproc 驱动程序日志包含一个
BigQueryClient条目,其中包含 BigQuery 元数据,包括jobId:ClassNotFoundException
INFO BigQueryClient:.. jobId: JobId{project=PROJECT_ID, job=JOB_ID, location=LOCATION} BigQuery 作业包含
Dataproc_job_id和Dataproc_job_uuid标签:- 日志记录:
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.labels.dataproc_job_id="JOB_ID" protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.labels.dataproc_job_uuid="JOB_UUID" protoPayload.serviceData.jobCompletedEvent.job.jobName.jobId="JOB_NAME"
- BigQuery 作业探索器:点击作业 ID,即可在作业信息中的标签下查看作业详情。
- 日志记录:
后续步骤
- 请参阅 BigQuery Storage 和 Spark SQL - Python。
- 了解如何为外部数据源创建表定义文件。
- 了解如何查询外部分区数据。
- 请参阅 Spark 作业调优提示。