Criar um cluster do Dataproc usando bibliotecas de cliente
O código de exemplo abaixo mostra como usar as Bibliotecas de cliente do Cloud para criar um cluster do Dataproc, executar um job no cluster e excluir o cluster.
Também é possível realizar essas tarefas usando:
- Solicitações da API REST em Guia de início rápido: como usar o API Explorer
- o console do Google Cloud em Criar um cluster do Dataproc usando o console do Google Cloud
- a CLI do Google Cloud em Criar um cluster do Dataproc usando a CLI do Google Cloud
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Executar o código
Teste o tutorial:clique em Abrir no Cloud Shell para executar um tutorial das bibliotecas de cliente do Cloud para Python que cria um cluster, executa um job do PySpark e exclui o cluster.
Go
- Instalar a biblioteca de cliente Para saber mais, consulte Como configurar seu ambiente de desenvolvimento.
- Configurar a autenticação
- Clone e execute o código de amostra do GitHub.
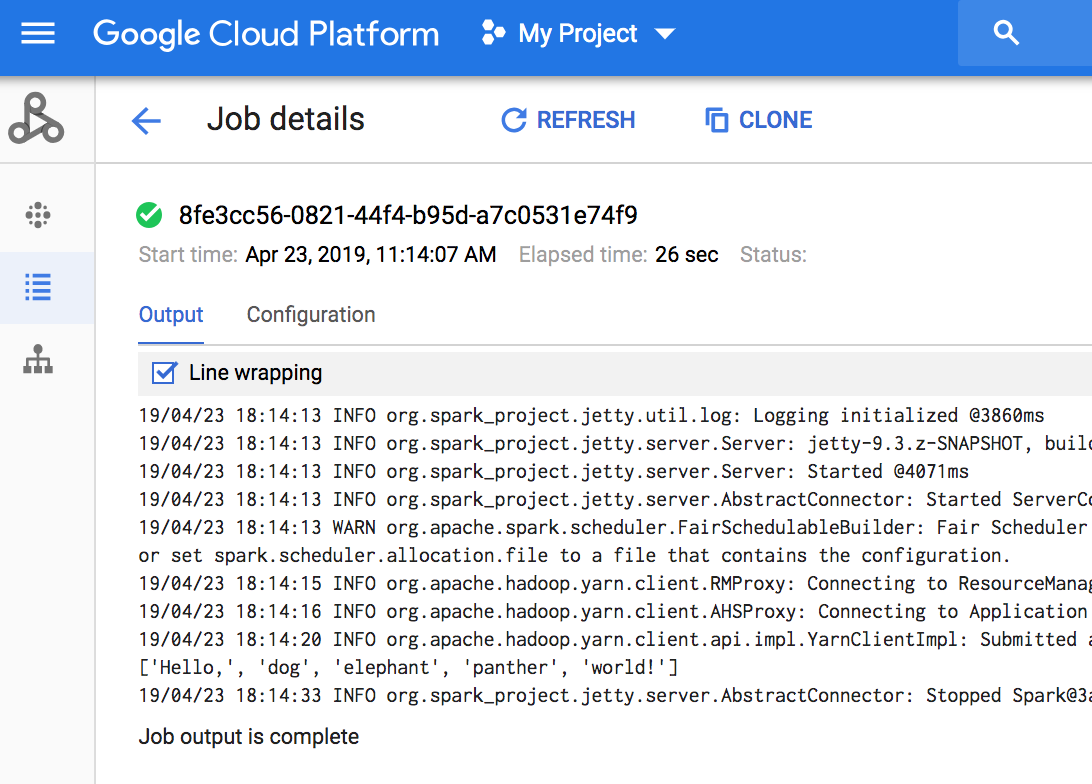
- Veja o resultado. O código gera o registro do driver do job para o
bucket de preparo
padrão do Dataproc
no Cloud Storage. Confira a saída do driver do job no console do Google Cloud
na seção
Jobs do Dataproc do seu projeto. Clique no ID do job para ver a saída do job na
página Detalhes do job.
Java
- Instalar a biblioteca de cliente Para saber mais, consulte Como configurar um ambiente de desenvolvimento do Java.
- Configurar a autenticação
- Clone e execute o código de amostra do GitHub.
- Veja o resultado. O código gera o registro do driver do job para o
bucket de preparo
padrão do Dataproc
no Cloud Storage. Confira a saída do driver do job no console do Google Cloud
na seção
Jobs do Dataproc do seu projeto. Clique no ID do job para ver a saída do job na
página Detalhes do job.
Node.js
- Instalar a biblioteca de cliente Para saber mais, consulte Como configurar um ambiente de desenvolvimento Node.js.
- Configurar a autenticação
- Clone e execute o código de amostra do GitHub.
- Veja o resultado. O código gera o registro do driver do job para o
bucket de preparo
padrão do Dataproc
no Cloud Storage. Confira a saída do driver do job no console do Google Cloud
na seção
Jobs do Dataproc do seu projeto. Clique no ID do job para ver a saída do job na
página Detalhes do job.
Python
- Instalar a biblioteca de cliente Para saber mais, consulte Como configurar um ambiente de desenvolvimento do Python.
- Configurar a autenticação
- Clone e execute o código de amostra do GitHub.
- Veja o resultado. O código gera o registro do driver do job para o
bucket de preparo
padrão do Dataproc
no Cloud Storage. Confira a saída do driver do job no console do Google Cloud
na seção
Jobs do Dataproc do seu projeto. Clique no ID do job para ver a saída do job na
página Detalhes do job.
A seguir
- Consulte Recursos adicionais da biblioteca de cliente do Cloud Dataproc.